Анатомия на пробив: ръководство за производители за реагиране при инциденти по ISO 27001
Кратък откъс
Ефективното реагиране при инциденти в информационната сигурност минимизира щетите от пробиви в сигурността и осигурява оперативна устойчивост. Това ръководство предоставя поетапна рамка, базирана на ISO 27001, която помага на производителите да се подготвят за реални кибератаки, да реагират на тях и да възстановят дейността си, като едновременно изпълняват сложни изисквания за съответствие като NIS2 и DORA.
Въведение
Предупреждението се появява в 2:17 ч. Централният сървър на средно голям производител на автомобилни компоненти не отговаря, а мониторите на производствените линии показват съобщение за рансъмуер. Всяка минута престой струва хиляди заради загубено производство и създава риск от нарушение на строгите SLA във веригата на доставки. Това не е учение. За директора по информационна сигурност това е моментът, в който години планиране, разработване на политики и обучение преминават през решаващия тест.
Да имате план за реагиране при инциденти, съхранен на сървър, е едно; да го изпълните под екстремен натиск е съвсем друго. При производителите залозите са особено високи. Киберинцидентът не компрометира само данни; той спира производството, нарушава физическите вериги за доставки и може да застраши безопасността на работниците.
Това ръководство излиза извън теоретичните наръчници и представя практическа пътна карта за изграждане и управление на работеща програма за реагиране при инциденти в реална среда. Ще разгледаме анатомията на реакцията при пробив, стъпвайки върху стабилната рамка на ISO/IEC 27001, и ще покажем как да изградите устойчива програма, която не само възстановява дейността след атака, но и удовлетворява изискванията на одиторите и регулаторите.
Какъв е залогът: верижният ефект от пробив в производствена среда
Когато системите на производител бъдат компрометирани, въздействието далеч надхвърля един сървър. Взаимосвързаният характер на съвременното производство — от управлението на складовите наличности до роботизираните монтажни линии — означава, че цифров отказ може да доведе до пълно оперативно спиране. Последиците са сериозни и многопластови.
Първо, финансовите загуби са незабавни и значителни. Спирането на производството води до пропуснати срокове, договорни неустойки от клиенти и разходи за неактивна работна сила. Възстановяването на системите, ангажирането на експерти по дигитална форензика и евентуалното управление на искания за откуп могат да поставят финансите на средно голяма компания под сериозен натиск.
Второ, репутационният ущърб може да бъде дълготраен. В B2B среда надеждността е решаваща. Един-единствен сериозен инцидент може да разруши доверието на ключови партньори, които разчитат на доставки по модела just-in-time. Както подчертават нашите вътрешни насоки, ключова цел на управлението на инциденти е „да се минимизира бизнес и финансовото въздействие на инцидентите и нормалните операции да бъдат възстановени възможно най-бързо“ — цел, която е от първостепенно значение в производството.
Накрая, регулаторните последици могат да бъдат тежки. С влизането в пълна сила на рамки като Директивата на ЕС за мрежова и информационна сигурност (NIS2) и Регламента за цифрова оперативна устойчивост (DORA), организациите в критични сектори като производството са изправени пред строги изисквания за докладване на инциденти и заплаха от значителни глоби при несъответствие. Лошо управляван инцидент не е просто технически отказ; той е съществен правен риск и риск за съответствието.
Как изглежда добрата практика: от хаос към контрол
Ефективната програма за реагиране при инциденти превръща кризата от хаотична, реактивна надпревара в структуриран и контролиран процес. Целта не е само да се отстрани техническият проблем, а да се управлява цялото събитие така, че бизнесът да бъде защитен. Това целево състояние се изгражда върху принципите, заложени в рамката ISO/IEC 27001, особено върху контролите за управление на инциденти в информационната сигурност.
Зрялата програма се характеризира с няколко ключови резултата:
- Яснота на ролите: Всеки знае към кого да се обърне и какви са неговите отговорности. Екипът за реагиране при инциденти (IRT) е предварително определен, с ясно ръководство и назначени експерти от ИТ, правния отдел, комуникациите и ръководството.
- Бързина и прецизност: Организацията може бързо да открива, анализира и ограничава заплахи, като предотвратява разпространението им в мрежата и спирането на цялата производствена площадка.
- Информирано вземане на решения: Ръководството получава своевременна и точна информация, което му позволява да взема критични решения относно операциите, комуникацията с клиенти и регулаторното оповестяване.
- Непрекъснато подобрение: Всеки инцидент, голям или малък, се превръща във възможност за учене. Задълбоченият процес за преглед след инцидент идентифицира слабости и връща подобрения обратно в програмата за сигурност.
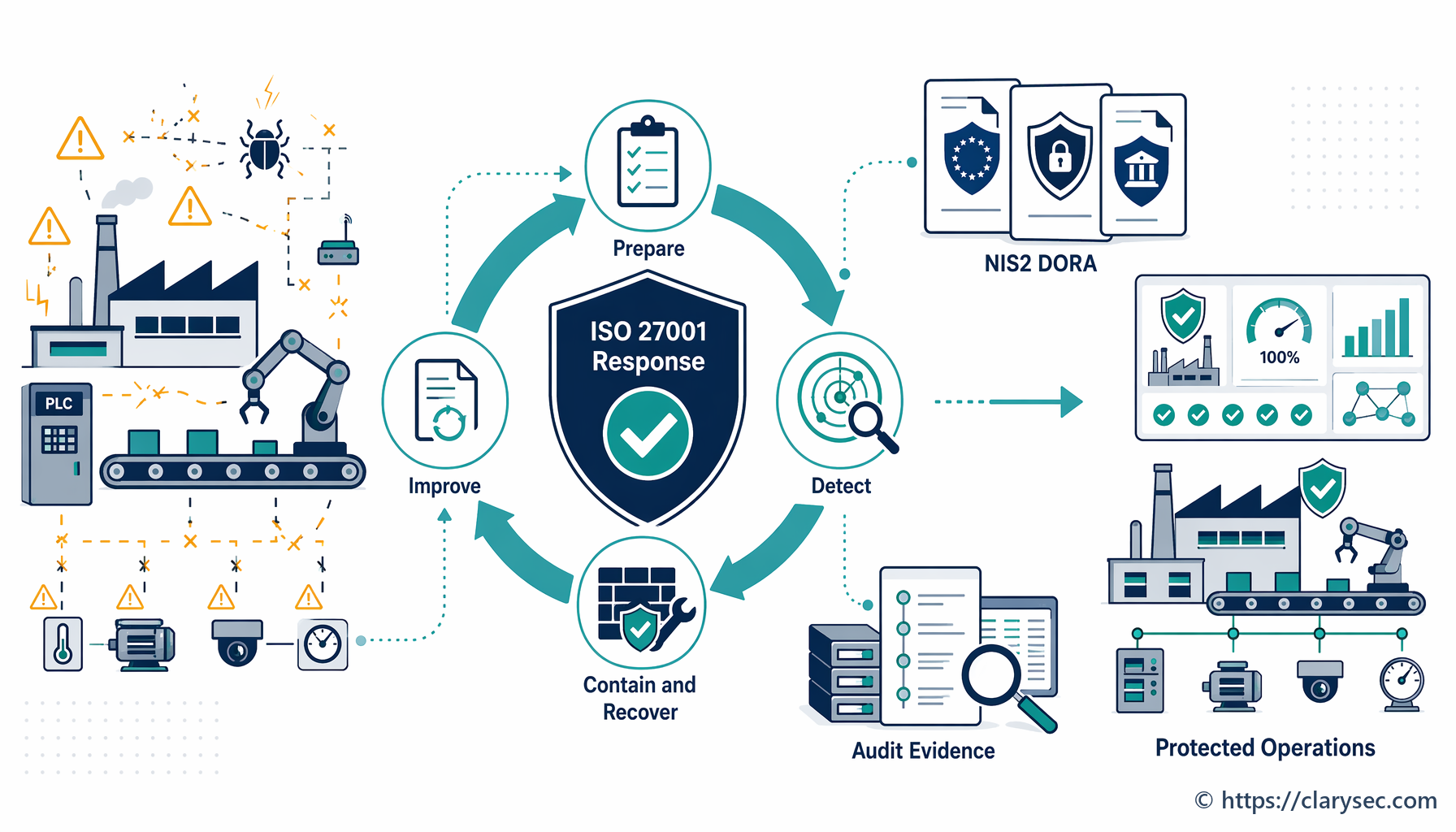
Постигането на това ниво на готовност е основната цел на контролите, описани в ISO/IEC 27002:2022. Тези контроли насочват организациите при планиране и подготовка (A.5.24), оценка и вземане на решения относно събития (A.5.25), реагиране при инциденти (A.5.26) и извличане на поуки от тях (A.5.28). Става дума за изграждане на устойчива система, която предвижда откази и е структурирана така, че да ги овладява контролирано.
Практическият път: поетапно ръководство за реагиране при инциденти
Изграждането на надеждна способност за реагиране при инциденти изисква документиран и систематичен подход. Основата за това е ясна и приложима политика, която описва всяка фаза на процеса.
Нашата P16S Политика за планиране и подготовка за управление на инциденти в информационната сигурност - SME предоставя цялостен модел, съгласуван с добрите практики по ISO 27001. Нека преминем през критичните стъпки, използвайки тази политика като ориентир.
Стъпка 1: Планиране и подготовка — основата на устойчивостта
Не можете да създадете план за реагиране в разгара на криза. Подготовката е решаваща. Тази фаза включва установяване на структурата, инструментите и знанията, необходими за решителни действия при настъпване на инцидент.
Основен компонент е създаването на екип за реагиране при инциденти (IRT). Както е посочено в раздел 5.1 на P16S Политика за планиране и подготовка за управление на инциденти в информационната сигурност - SME, целта на политиката е „да осигури последователен и ефективен подход към управлението на инциденти в информационната сигурност“. Тази последователност започва с добре дефиниран екип. Политиката изисква IRT да включва членове от ключови звена:
- ИТ и информационна сигурност
- Правен отдел и съответствие
- Човешки ресурси
- Връзки с обществеността/комуникации
- Висше ръководство
Всеки член трябва да има ясно определени роли и отговорности. Кой има правомощия да изключи системи от експлоатация? Кой е определеният говорител за комуникация с клиенти или медии? Тези въпроси трябва да бъдат отговорени и документирани много преди настъпването на инцидент.
Стъпка 2: Откриване и докладване — вашата система за ранно предупреждение
Колкото по-бързо разберете за инцидент, толкова по-малко щети може да причини той. Това изисква както технически мониторинг, така и култура, в която служителите са овластени и задължени да докладват подозрителна дейност.
P16S Политика за планиране и подготовка за управление на инциденти в информационната сигурност - SME е категорична по този въпрос. Раздел 5.3, „Докладване на събития в информационната сигурност“, изисква:
„Всички служители, външни изпълнители и други релевантни страни са длъжни да докладват възможно най-бързо всички наблюдавани или подозирани събития и слабости, свързани с информационната сигурност, на определения контакт.“
Този „определен контакт“ е критичен. Това може да бъде ИТ сервизно бюро или специална гореща линия за сигурност. Процесът трябва да бъде прост и ясно комуникиран до целия персонал. Служителите следва да бъдат обучени какво да разпознават — например фишинг имейли, необичайно поведение на системите или пробиви във физическата сигурност.
Стъпка 3: Оценка и триаж — определяне на мащаба на заплахата
След като дадено събитие бъде докладвано, следващата стъпка е бързо да се оцени неговият характер и критичност. Дали е фалшива тревога, незначителен проблем или пълномащабна криза? Този процес на триаж определя необходимото ниво на реагиране.
Нашата политика описва ясна схема за класификация в раздел 5.2, „Класификация на инциденти“, за категоризиране на инциденти според въздействието им върху поверителността, целостта и наличността. Типична схема може да изглежда така:
- Нисък: Една работна станция е заразена с масов зловреден софтуер, който може лесно да бъде ограничен.
- Среден: Сървър на отдел е недостъпен, което засяга конкретна бизнес функция, но не спира цялостното производство.
- Висок: Широко разпространена рансъмуер атака засяга критични производствени системи и основни бизнес данни.
- Критичен: Инцидент, включващ нарушение на сигурността на данните, свързано с чувствителна лична информация или интелектуална собственост, със значителни правни и репутационни последици.
Тази класификация определя спешността, разпределените ресурси и пътя за ескалация към ръководството, като гарантира, че реакцията е пропорционална на заплахата.
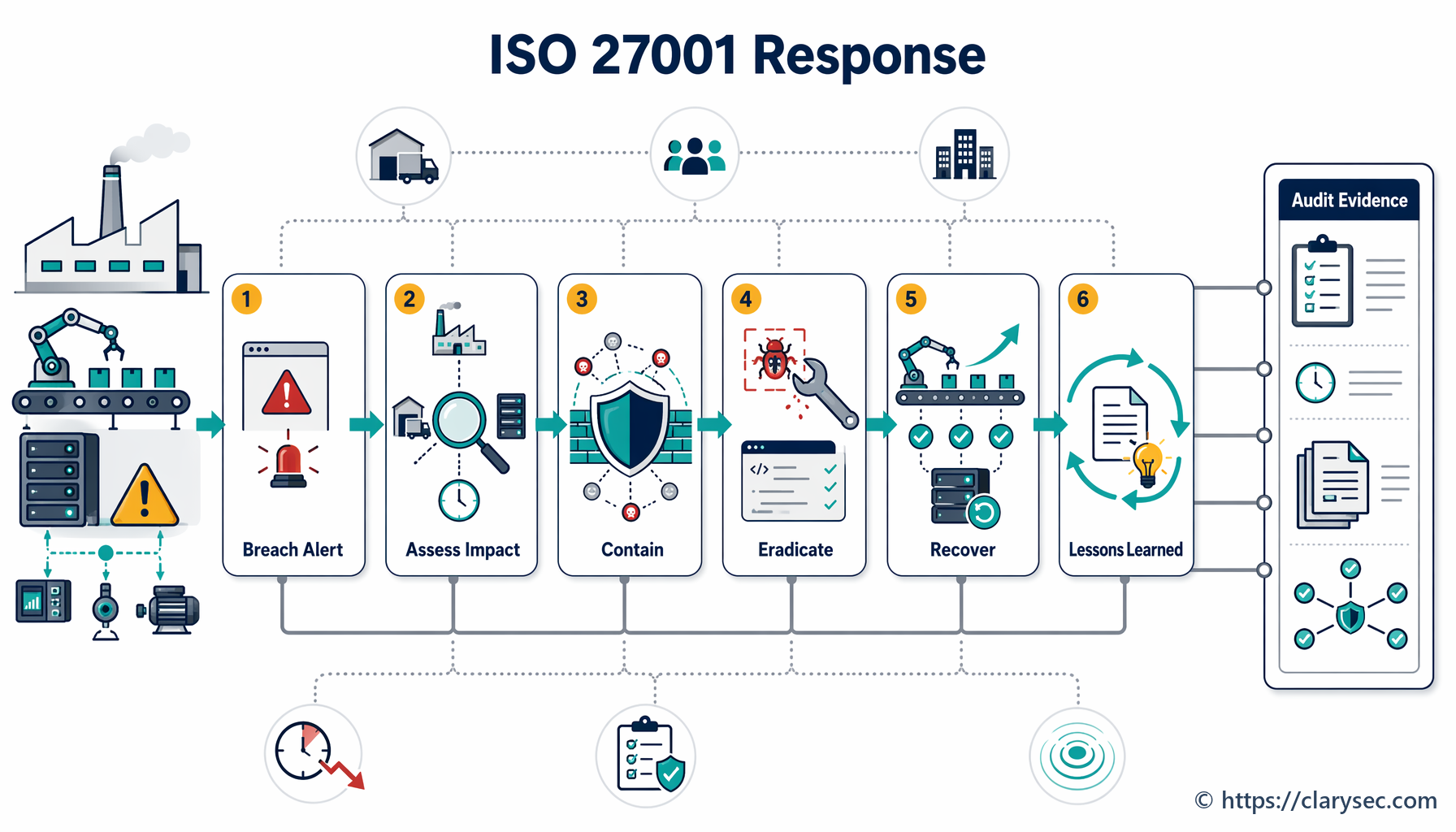
Стъпка 4: Ограничаване, отстраняване и възстановяване — овладяване на пожара
Това е активната фаза на реагиране, в която IRT работи за овладяване на инцидента и възстановяване на нормалните операции.
- Ограничаване: Непосредственият приоритет е да се спре разрастването на щетите. Това може да включва изолиране на засегнати мрежови сегменти, изключване на компрометирани сървъри или блокиране на злонамерени IP адреси. Целта е инцидентът да не се разпространи и да не причини допълнителни щети.
- Отстраняване: След ограничаването трябва да бъде отстранена първопричината за инцидента. Това може да означава премахване на зловреден софтуер, прилагане на корекции за експлоатирани уязвимости и деактивиране на компрометирани потребителски акаунти.
- Възстановяване: Последната стъпка е възстановяване на засегнатите системи и данни. Това включва възстановяване от чисти резервни копия, преизграждане на системи и внимателен мониторинг, за да се потвърди, че заплахата е напълно отстранена, преди услугите да бъдат върнати в експлоатация.
Раздел 5.4 на P16S Политика за планиране и подготовка за управление на инциденти в информационната сигурност - SME, „Реагиране при инциденти в информационната сигурност“, предоставя рамката за тези действия, като подчертава, че „процедурите за реагиране се задействат при класифициране на събитие в информационната сигурност като инцидент“.
Стъпка 5: Дейности след инцидент — извличане на поуки
Работата не приключва, когато системите отново са в експлоатация. Фазата след инцидента вероятно е най-важната за изграждане на дългосрочна устойчивост. Тя включва две ключови дейности: събиране на доказателства и преглед на извлечените поуки.
Политиката подчертава значението на събирането на доказателства в раздел 5.5, като посочва, че „следва да бъдат създадени и спазвани процедури за събиране, придобиване и запазване на доказателства, свързани с инциденти в информационната сигурност“. Това е от решаващо значение за вътрешно разследване, запитвания от правоохранителни органи и потенциални правни действия.
След това трябва да се проведе формален преглед след инцидент. В тази среща следва да участват всички членове на IRT и ключовите заинтересовани страни, за да обсъдят:
- Какво се случи и каква беше хронологията на събитията?
- Какво сработи добре при реагирането?
- Какви предизвикателства възникнаха?
- Какво може да се направи, за да се предотврати подобен инцидент в бъдеще?
Резултатът от този преглед следва да бъде план за действие с определени отговорници и срокове за подобряване на политики, процедури и технически контроли. Това създава обратна връзка, която с времето укрепва рисковия профил на организацията по отношение на сигурността.
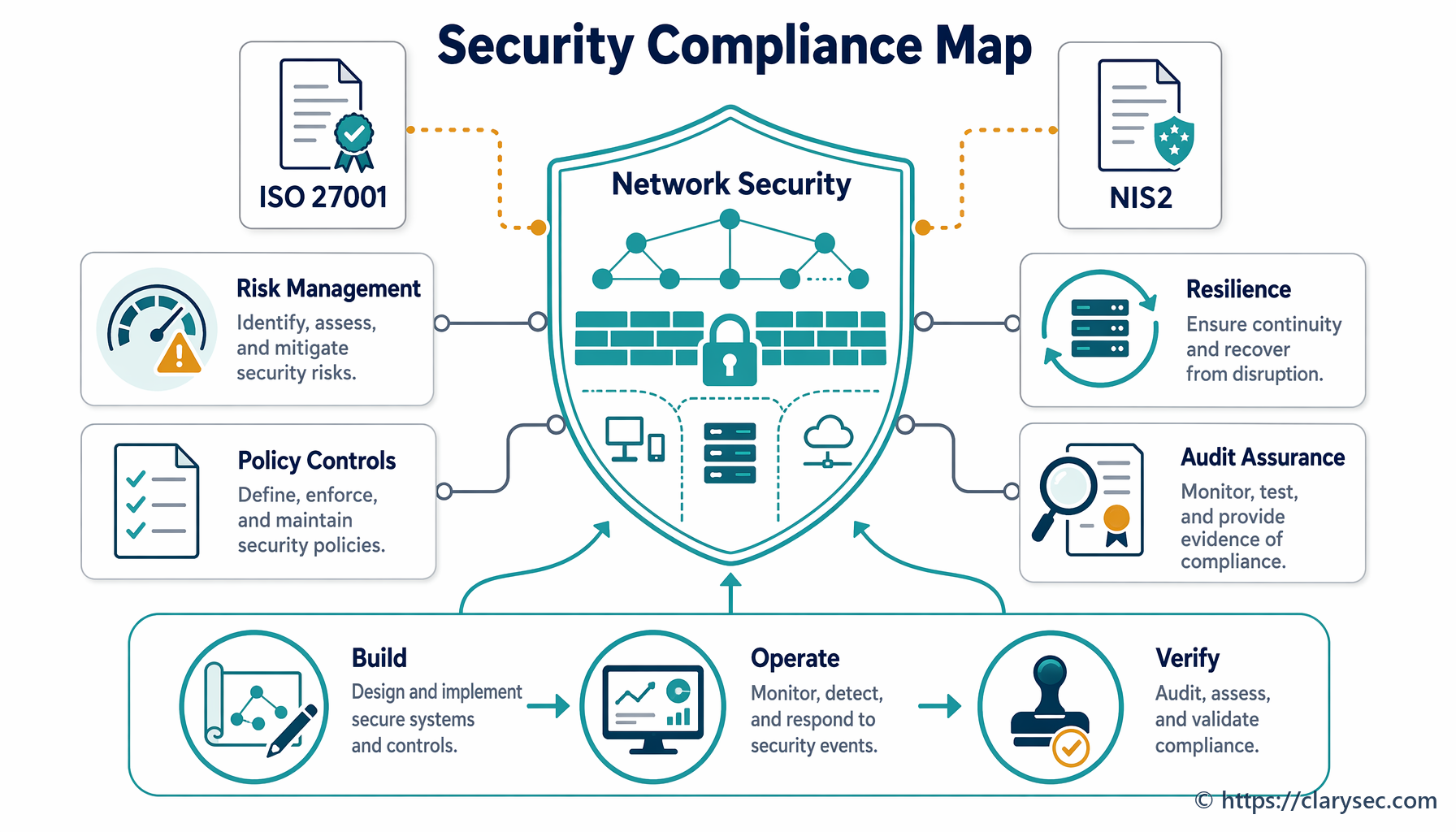
Съпоставяне на изискванията: насоки за съответствие между рамките
Изпълнението на изискванията на ISO 27001 за управление на инциденти не само укрепва сигурността; то осигурява силна основа за съответствие с нарастваща мрежа от международни и секторни регулации. Много от тези рамки споделят едни и същи основни принципи: подготовка, реагиране и докладване.
Както е обяснено в Zenith Controls, нашето цялостно ръководство за съответствие между рамки, надеждният процес за управление на инциденти е крайъгълен камък на цифровата устойчивост. Нека разгледаме как подходът на ISO 27001 се съгласува с други основни рамки.
Контроли по ISO/IEC 27002:2022: Последната версия на стандарта ISO/IEC 27002 предоставя подробни насоки за управление на инциденти чрез специален набор от контроли:
- A.5.24 - Планиране и подготовка за управление на инциденти в информационната сигурност: Установява необходимостта от дефиниран и документиран подход.
- A.5.25 - Оценка и решение относно събития в информационната сигурност: Гарантира, че събитията се оценяват правилно, за да се определи дали представляват инциденти.
- A.5.26 - Реагиране при инциденти в информационната сигурност: Обхваща дейностите по ограничаване, отстраняване и възстановяване.
- A.5.27 - Докладване на инциденти в информационната сигурност: Определя как и кога инцидентите се докладват на ръководството и други заинтересовани страни.
- A.5.28 - Извличане на поуки от инциденти в информационната сигурност: Изисква процес за непрекъснато подобрение.
Тези контроли формират пълен жизнен цикъл, който се отразява и в други основни регулации.
Директива NIS2: За операторите на основни услуги, включително много производители, NIS2 въвежда строги задължения за сигурност и докладване на инциденти. Zenith Controls отбелязва прякото припокриване:
„Article 21 от директивата NIS2 изисква съществените и важните субекти да прилагат подходящи и пропорционални технически, оперативни и организационни мерки за управление на рисковете за сигурността на мрежовите и информационните системи. Това изрично включва политики и процедури за обработване на инциденти. Освен това Article 23 установява многоетапен процес за уведомяване за инциденти, като изисква ранно предупреждение в рамките на 24 часа и подробен доклад в рамките на 72 часа до компетентните органи (CSIRT).“
План за реагиране при инциденти, съгласуван с ISO 27001, предоставя точните механизми, необходими за спазване на тези кратки срокове за докладване.
Регламент за цифрова оперативна устойчивост (DORA): Макар DORA да е фокусиран върху финансовия сектор, неговите принципи за устойчивост се превръщат в ориентир за всички индустрии. Ръководството подчертава тази връзка:
„Article 17 от DORA изисква финансовите субекти да имат цялостен процес за управление на инциденти, свързани с ИКТ, за откриване, управление и уведомяване за инциденти, свързани с ИКТ. Article 19 изисква класификация на инцидентите въз основа на критерии, подробно описани в регламента, и докладване на съществени инциденти до компетентните органи чрез хармонизирани шаблони. Това отразява изискванията за класификация и докладване, заложени в ISO 27001.“
Общ регламент относно защитата на данните (GDPR): За всеки инцидент, който включва лични данни, изискванията на GDPR са от първостепенно значение. Бързата и структурирана реакция не е по избор. Както обяснява Zenith Controls:
„Съгласно GDPR, Article 33 изисква администраторите на данни да уведомят надзорния орган за нарушение на сигурността на личните данни без неоправдано забавяне и, когато е възможно, не по-късно от 72 часа след узнаването за него. Article 34 изисква съобщаване на нарушението на субекта на данни, когато има вероятност то да доведе до висок риск за неговите права и свободи. Ефективният план за реагиране при инциденти е съществен за събирането на необходимата информация, така че тези уведомления да бъдат точни и навременни.“
Като изграждате програмата си за реагиране при инциденти върху основата на ISO 27001, едновременно изграждате способностите, необходими за управление на сложните изисквания на тези взаимосвързани регулации.
Подготовка за проверка: какво ще поискат одиторите
План за реагиране при инциденти, който никога не е тестван или преглеждан, е просто документ. Одиторите знаят това и по време на сертификационен одит по ISO 27001 ще проверят задълбочено дали програмата ви е действаща част от вашата СУИС.
Според Zenith Blueprint, нашата пътна карта за одитори, оценката на реагирането при инциденти е критична стъпка в одитния процес. По време на „Фаза 3: Работа на място и събиране на доказателства“ одиторите систематично ще тестват вашата готовност.
Ето какво можете да очаквате да поискат, въз основа на стъпка 21 от Zenith Blueprint, „Оценка на реагирането при инциденти и непрекъсваемостта на дейността“:
„Покажете ми вашия план и политика за реагиране при инциденти.“ Одиторите ще започнат с документацията. Те ще прегледат политиката за пълнота, като проверят дали са дефинирани роли и отговорности, критерии за класификация, комуникационни планове и процедури за всяка фаза от жизнения цикъл на инцидента. Ще проверят дали политиката е формално одобрена и комуникирана до релевантния персонал.
„Покажете ми записите от последните три инцидента по сигурността.“ Тук се вижда дали процесът работи на практика. Одиторите трябва да видят доказателства, че планът действително се следва. Те ще очакват регистри за инциденти или тикети, които документират:
- Датата и часа на откриване.
- Описание на инцидента.
- Присвоения приоритет или ниво на класификация.
- Регистър на предприетите действия за ограничаване, отстраняване и възстановяване.
- Датата и часа на отстраняване.
„Покажете ми протокола и плана за действие от последния преглед след инцидент.“ Както подчертава Zenith Blueprint, непрекъснатото подобрение не подлежи на компромис.
„По време на одита ще търсим обективни доказателства, че прегледите след инцидент се провеждат систематично. Това включва преглед на протоколи от срещи, регистри на действия и доказателства, че идентифицираните подобрения са внедрени, например актуализирани процедури или нови технически контроли. Без тази обратна връзка СУИС не може да се счита за система, която „непрекъснато се подобрява“, както изисква стандартът.“
„Покажете ми доказателства, че сте тествали плана си.“ Одиторите искат да видят, че проактивно тествате способностите си, а не просто чакате реален инцидент. Тези доказателства могат да приемат различни форми — от настолни упражнения с ръководството до пълномащабни технически симулации. Те ще поискат доклад от тези тестове, който описва сценария, участниците, резултатите и всички извлечени поуки.
Подготовката с тези доказателства показва, че програмата ви за реагиране при инциденти не е само формална, а е надежден, оперативен и ефективен компонент на вашата СУИС.
Често срещани грешки, които да избягвате
Дори при добре документиран план много организации се затрудняват по време на реален инцидент. Ето някои от най-често срещаните грешки, за които трябва да внимавате:
- Синдромът „планът на рафта“: Най-честият провал е наличието на отлично написан план, който никой не е прочел, разбрал или упражнил. Редовното обучение и тестване са единственото противодействие.
- Неясни правомощия: По време на криза неяснотата е вашият враг. Ако IRT няма предварително одобрени правомощия да предприема решителни действия, например да изключи критична производствена система от експлоатация, реакцията ще бъде блокирана от нерешителност, докато щетите се разпространяват.
- Слаба комуникация: Неспособността да се управляват комуникациите е рецепта за бедствие. Това включва липса на информиране на ръководството, объркващи съобщения към служителите или неправилна комуникация с клиенти и регулатори. Предварително одобрен комуникационен план с шаблони е задължителен.
- Пренебрегване на запазването на доказателства: В бързането за възстановяване на услугата техническият екип може неволно да унищожи критични форензични доказателства. Това може да направи невъзможно установяването на първопричината, предотвратяването на повторение или подкрепата на правни действия.
- Липса на извличане на поуки: Третирането на инцидента като „приключен“, когато системата отново е в експлоатация, е пропусната възможност. Без задълбочен анализ след инцидент организацията е обречена да повтори грешките си.
Следващи стъпки
Преминаването от теория към практика е най-критичната стъпка. Надеждната програма за реагиране при инциденти е път на непрекъснато подобрение, а не крайна точка. Ето как можете да започнете:
- Формализирайте подхода си: Ако нямате формална политика за реагиране при инциденти, сега е моментът да създадете такава. Използвайте нашата P16S Политика за планиране и подготовка за управление на инциденти в информационната сигурност - SME като шаблон за изграждане на цялостна рамка.
- Разберете средата си за съответствие: Съпоставете процедурите си за реагиране при инциденти със специфичните изисквания на регулации като NIS2, DORA и GDPR. Нашето ръководство Zenith Controls предоставя необходимите кръстосани препратки, за да осигурите пълно покритие.
- Подгответе се за одита: Използвайте гледната точка на одитора, за да подложите програмата си на стрес тест. Zenith Blueprint ви дава вътрешен поглед към това какво ще изискват одиторите, за да можете да съберете доказателствата си и да сте готови да демонстрирате ефективност.
Заключение
За съвременния производител реагирането при инциденти в информационната сигурност не е ИТ въпрос; то е основна функция за непрекъсваемост на дейността. Разликата между незначително прекъсване и катастрофален отказ се крие в подготовката, практиката и ангажимента към структуриран, повторяем процес.
Като изграждате програмата си върху глобално признатата рамка на ISO 27001, създавате не само защитна способност, а устойчива организация. Изграждате система, която може да устои на шока от пробив, да управлява кризата с контрол и прецизност и да излезе от нея по-силна и по-сигурна. Времето за подготовка е сега — преди предупреждението в 2:17 ч. да стане ваша реалност.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council