От хаос към контрол: ръководство за производители за реагиране при инциденти по ISO 27001
Ефективният план за реагиране при инциденти е задължителен за производители, изправени пред киберзаплахи, които могат да спрат производството. Това ръководство представя поетапен подход за изграждане на устойчива способност за управление на инциденти, съгласувана с ISO 27001, която осигурява оперативна устойчивост и изпълнение на строгите изисквания за съответствие в различни рамки като NIS2 и DORA.
Въведение
Шумът на машините в производствения цех е звукът на работещия бизнес. За средно голям производител това е ритъмът на приходите, стабилността на веригата на доставки и доверието на клиентите. Представете си сега, че този звук е заменен от тревожна тишина. На екрана в Центъра за операции по сигурността (SOC) се появява предупреждение: „Открита необичайна мрежова активност – сегмент на производствената мрежа“. След минути системите за управление спират да реагират. Производствената линия спира. Това не е хипотетичен сценарий; това е реалността на съвременен киберинцидент в производствения сектор, където сливането на информационни технологии (IT) и оперативни технологии (OT) създаде нова среда на заплахи с висок риск.
Инцидентът в информационната сигурност вече не е само ИТ проблем; той е критично прекъсване на дейността, способно да парализира операциите. За CISO и собственици на бизнес в производството въпросът не е дали ще възникне инцидент, а как организацията ще реагира, когато това се случи. Хаотичната импровизирана реакция води до продължителен престой, регулаторни санкции и непоправими репутационни щети. Структурираното и добре отработено реагиране обаче може да превърне потенциална катастрофа в управлявано събитие, което демонстрира устойчивост и контрол. Това е основният принцип на управлението на инциденти в информационната сигурност — критичен компонент на всяка устойчива система за управление на информационната сигурност (СУИС), базирана на ISO/IEC 27001.
Какво е заложено на карта
За производител въздействието на инцидент в сигурността далеч надхвърля загубата на данни. Основният риск е прекъсване на ключови бизнес операции. Когато OT системи бъдат компрометирани, последиците са незабавни и осезаеми: спрени производствени линии, забавени доставки и неизпълнени ангажименти по веригата на доставки. Финансовите загуби започват веднага, като разходите се натрупват от престой, действия по отстраняване и потенциални договорни санкции.
Регулаторната среда добавя още един пласт натиск. Лошо управляван инцидент може да доведе до значителни глоби по различни рамки. Както посочва подробното ръководство на Clarysec, Zenith Controls, залогът е изключително висок:
„Основната цел на управлението на инциденти е да се минимизира отрицателното въздействие на инцидентите в сигурността върху бизнес операциите и да се осигури бързо, ефективно и организирано реагиране. Неуспешното управление на инциденти може да доведе до значителни финансови загуби, репутационни щети и регулаторни санкции.“
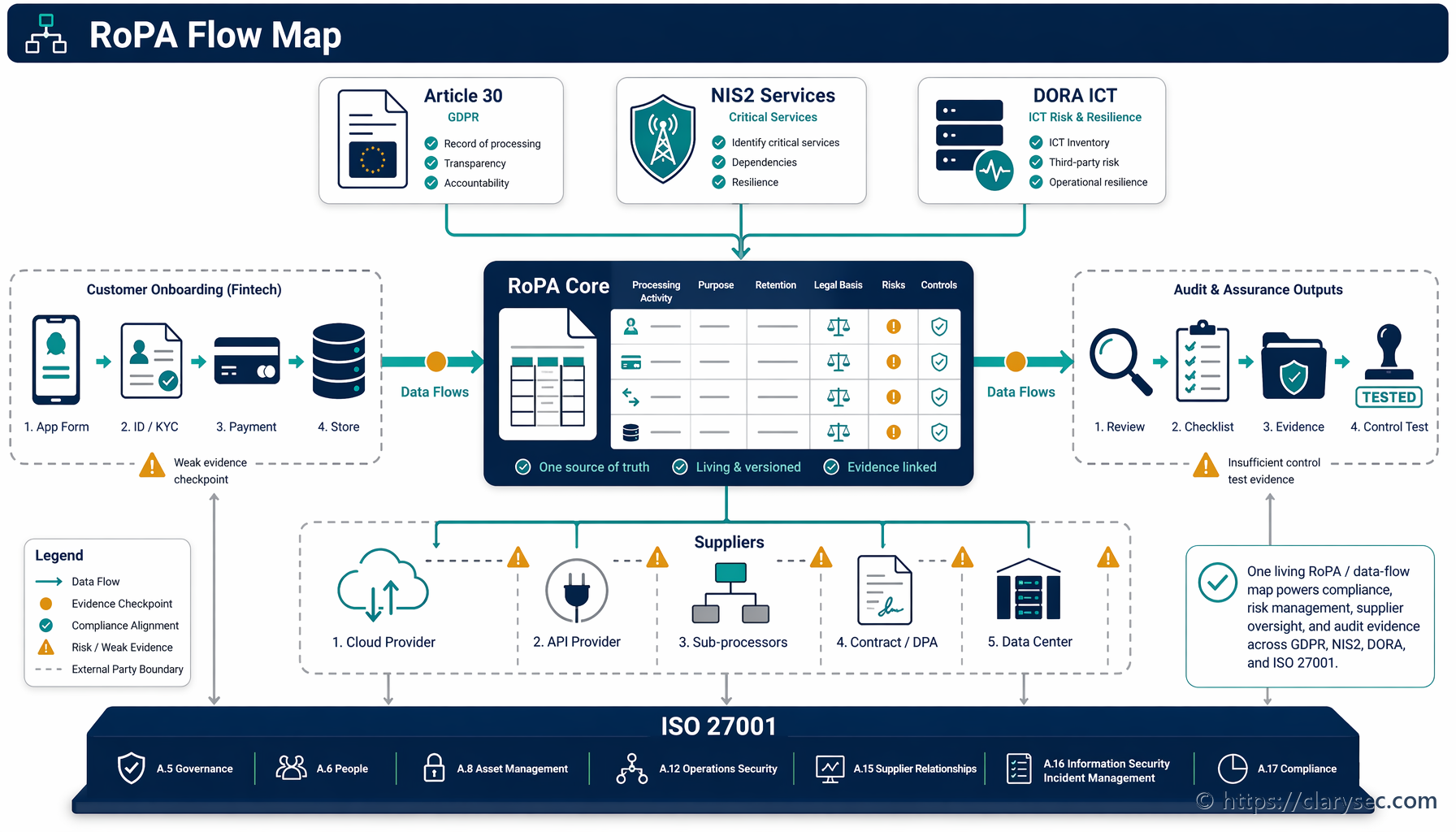
Тук не става дума само за една регулация. Взаимосвързаният характер на съвременното съответствие означава, че един инцидент може да има верижни регулаторни последици. Пробив в сигурността на данните, включващ информация за служители или клиенти, може да наруши GDPR. Прекъсване на услуги за клиенти във финансовия сектор може да привлече внимание по DORA. За организациите, класифицирани като съществени или важни субекти, NIS2 въвежда строги срокове за докладване на инциденти и изисквания за сигурност.
Отвъд непосредствените финансови и регулаторни последствия стои загубата на доверие. Клиентите, партньорите и доставчиците разчитат на способността на производителя да доставя. Инцидент, който нарушава този поток, подкопава доверието и може да доведе до загуба на бизнес. Възстановяването на репутацията често е по-дълъг и по-труден процес от възстановяването на засегнатите системи. Крайната цена не е само сборът от глобите и загубените производствени часове, а дългосрочното въздействие върху пазарната позиция на дружеството и целостта на марката.
Как изглежда добрата практика
При толкова значими рискове как изглежда ефективната способност за реагиране при инциденти? Това е състояние на подготвеност, при което хаосът е заменен с ясен, методичен процес. Това е способността да се открие инцидент, да се реагира на него и да се възстанови нормалната работа по начин, който минимизира щетите и подкрепя непрекъснатостта на дейността. Това желано състояние се изгражда върху основите, заложени в ISO/IEC 27001, особено в контролите от Приложение A.
Зряла програма за управление на инциденти, ръководена от формална политика, гарантира, че всеки знае своята роля. Нашата P16S Политика за управление на инциденти в информационната сигурност за МСП подчертава тази яснота в описанието на целта си:
„Целта на тази политика е да установи структурирана и ефективна рамка за управление на инциденти в информационната сигурност. Тази рамка осигурява своевременно и координирано реагиране на събития, свързани със сигурността, като минимизира въздействието им върху операциите, активите и репутацията на организацията и същевременно изпълнява законови, регулаторни и договорни изисквания.“
Тази структурирана рамка се превръща в конкретни ползи:
- Намален престой: Ясно дефинираният план позволява по-бързо ограничаване и възстановяване, така че производствените линии да бъдат върнати в експлоатация по-рано.
- Контролирани разходи: Чрез минимизиране на продължителността и въздействието на инцидента значително се намаляват свързаните разходи за отстраняване, загубени приходи и потенциални глоби.
- Повишена устойчивост: Организацията се учи от всеки инцидент, като използва прегледи след инцидент, за да укрепи защитите и да подобри бъдещото реагиране. Това съответства на принципа на ISO 27001 за непрекъснато подобрение.
- Доказуемо съответствие: Документиран и тестван процес за реагиране при инциденти предоставя ясни доказателства на одитори и регулатори, че организацията приема сериозно своите задължения по сигурността.
- Доверие на заинтересованите страни: Професионалното и ефективно реагиране уверява клиенти, партньори и застрахователи, че организацията е надежден и сигурен контрагент.
В крайна сметка „добрата практика“ означава организация, която не е само реактивна, а проактивна — организация, която третира управлението на инциденти не като техническа задача, а като ключова бизнес функция, необходима за оцеляване и растеж в цифровия свят.
Практическият път: поетапни насоки
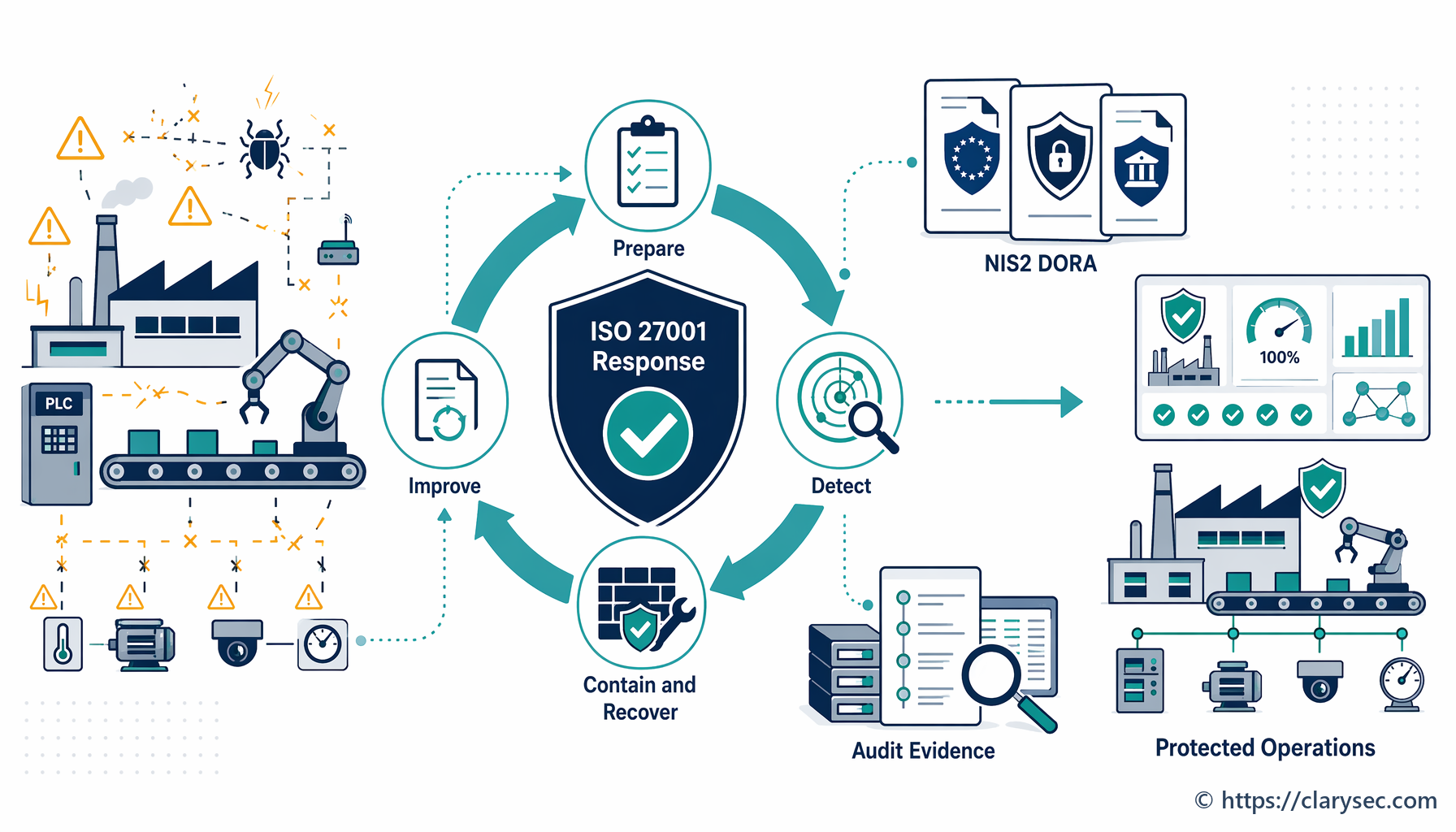
Изграждането на устойчива способност за реагиране при инциденти изисква повече от документ; то изисква практически и приложим план, интегриран в културата на организацията. Този процес може да бъде разделен на класическия жизнен цикъл на управление на инциденти, като всяка фаза се подкрепя от ясни политики и процедури.
Фаза 1: подготовка и планиране
Това е най-критичната фаза. Ефективното реагиране е невъзможно без задълбочена подготовка. Основата е цялостна политика, която задава рамката за всички последващи действия. P16S Политика за управление на инциденти в информационната сигурност за МСП очертава съществената първа стъпка в раздел 5.1, „План за управление на инциденти“:
„Организацията трябва да разработи, внедри и поддържа план за управление на инциденти в информационната сигурност. Този план трябва да бъде интегриран с плановете за непрекъснатост на дейността и аварийно възстановяване, за да се осигури съгласувано реагиране при събития, водещи до прекъсване.“
Този план не е статичен документ. Той трябва да дефинира целия процес — от първоначалното откриване до окончателното отстраняване. Ключов компонент е създаването на специален екип за реагиране при инциденти (IRT). Ролите и отговорностите на този екип трябва да бъдат изрично определени, за да се избегне объркване по време на криза. Политиката допълнително изяснява това в раздел 5.2, „Роли на екипа за реагиране при инциденти (IRT)“, като посочва: „IRT трябва да включва членове от съответните звена, включително ИТ, сигурност, правен отдел, човешки ресурси и връзки с обществеността. Ролите и отговорностите на всеки член по време на инцидент трябва да бъдат ясно документирани.“
Подготовката включва и осигуряване на необходимите инструменти и ресурси за екипа, включително защитени комуникационни канали, софтуер за анализ и достъп до форензични възможности.
Фаза 2: откриване и анализ
Инцидент не може да бъде управляван, ако не е открит. Тази фаза се фокусира върху идентифициране и потвърждаване на потенциални инциденти в сигурността. Съгласно нашата P16S Политика за управление на инциденти в информационната сигурност за МСП, раздел 5.3, „Откриване и докладване на инциденти“, изисква „всички служители, изпълнители и други съответни страни да докладват своевременно всякакви наблюдавани или подозирани слабости или заплахи за информационната сигурност.“
Това изисква комбинация от технически мониторинг и човешка осведоменост. Автоматизирани системи като управление на информация и събития, свързани със сигурността (SIEM), са ключови за откриване на аномалии, но добре обученият персонал е първата линия на защита. Нашата P08S Политика за осведоменост и обучение по информационна сигурност за МСП затвърждава това, като посочва в декларацията на политиката: „Всички служители и, когато е приложимо, изпълнители трябва да получават подходящо обучение за осведоменост и редовни актуализации относно организационните политики и процедури, доколкото това е приложимо за тяхната длъжностна функция.“
След като дадено събитие бъде докладвано, IRT трябва бързо да го анализира и класифицира, за да определи неговата тежест и потенциално въздействие. Този първоначален триаж е от съществено значение за приоритизиране на усилията за реагиране.
Фаза 3: ограничаване, отстраняване и възстановяване
При потвърден инцидент непосредствената цел е да се ограничат щетите. Стратегията за ограничаване е критична, особено в производствена среда. Това може да означава изолиране на засегнатия мрежов сегмент, който управлява производствените машини, за да се предотврати разпространение на зловреден софтуер от ИТ мрежата към OT мрежата.
След ограничаването IRT работи за отстраняване на заплахата. Това може да включва премахване на зловреден софтуер, деактивиране на компрометирани потребителски акаунти и прилагане на корекции за уязвимости. Последната стъпка в тази фаза е възстановяване, при което системите се връщат към нормална експлоатация. Това трябва да се извършва методично, като се гарантира, че заплахата е напълно премахната, преди системите да бъдат отново включени в работа. Както е посочено в раздел 5.5 на P16S Политика за управление на инциденти в информационната сигурност за МСП, „Дейностите по възстановяване трябва да се приоритизират въз основа на анализ на въздействието върху бизнеса (BIA), за да се възстановят критичните бизнес функции възможно най-бързо.“
През цялата тази фаза събирането на доказателства е от първостепенно значение. Правилното обработване на цифрови доказателства е съществено за анализа след инцидента и за евентуални правни или регулаторни действия. Нашата политика, в раздел 5.6, „Събиране и обработване на доказателства“, уточнява, че „Всички доказателства, свързани с инцидент в информационната сигурност, трябва да бъдат събрани, обработени и запазени по форензично издържан начин, за да се поддържа тяхната цялост.“
Фаза 4: дейности след инцидент и непрекъснато подобрение
Работата не приключва, когато системите отново заработят. Фазата след инцидента е моментът, в който се извличат най-ценните поуки. Формален преглед след инцидент, или среща за „извлечени поуки“, е задължителен. Целта, както е описано в нашите указания за внедряване, е да се анализират инцидентът и реагирането, за да се установят области за подобрение.
„Поуките, извлечени от анализа и разрешаването на инциденти в информационната сигурност, трябва да се използват за подобряване на откриването, реагирането и предотвратяването на бъдещи инциденти. Това включва актуализиране на оценките на риска, политиките, процедурите и техническите контроли.“
Тази обратна връзка е двигателят на непрекъснатото подобрение — крайъгълен камък на рамката ISO 27001. Констатациите от този преглед трябва да се използват за актуализиране на плана за реагиране при инциденти, усъвършенстване на контролите за сигурност и подобряване на обучението на служителите. Така организацията става по-силна и по-устойчива след всеки инцидент, превръщайки отрицателното събитие в положителен катализатор за промяна.
Свързване на изискванията: поглед към съответствието между рамките
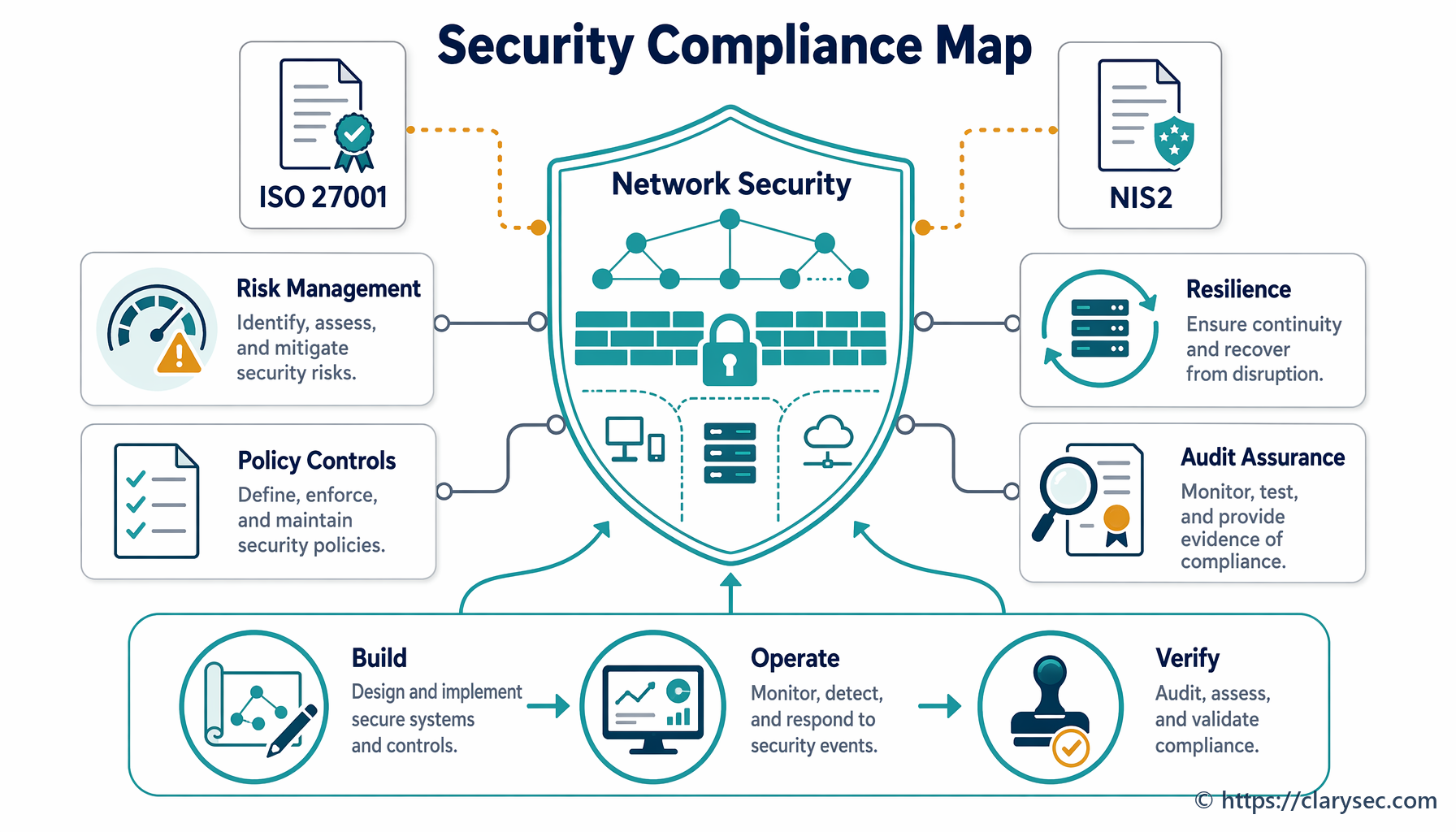
Ефективният план за реагиране при инциденти не удовлетворява само ISO 27001; той формира гръбнака на съответствието с нарастващ брой припокриващи се регулации. Съвременните рамки признават, че бързото и структурирано реагиране е фундаментално за защитата на данни, услуги и критична инфраструктура. CISO и мениджърите по съответствие трябва да разбират тези връзки, за да изградят наистина цялостна програма.
Основните контроли на ISO/IEC 27002:2022 за управление на инциденти (5.24, 5.25, 5.26 и 5.27) осигуряват универсална основа. Тези контроли обхващат планиране и подготовка, оценяване и вземане на решения относно събития, реагиране при инциденти и извличане на поуки от тях. Тази структура се възпроизвежда и в други ключови регулации.
Директива NIS2: За производители, определени като съществени или важни субекти, NIS2 променя правилата. Тя налага строги мерки за сигурност и докладване на инциденти. Clarysec Zenith Controls подчертава тази пряка връзка:
„NIS2 изисква организациите да разполагат със способности за управление на инциденти, включително процедури за докладване на значителни инциденти до компетентните органи в строги срокове (например ранно предупреждение в рамките на 24 часа).“
Това означава, че планът за реагиране на производител, съгласуван с ISO 27001, трябва да включва конкретните работни потоци за уведомяване и срокове, изисквани от NIS2.
DORA (Регламент за оперативната устойчивост на цифровите технологии): Макар да е фокусиран върху финансовия сектор, DORA оказва влияние и върху критични ИКТ доставчици от трети страни, което може да включва производители, предоставящи технологии или услуги на финансови субекти. DORA поставя силен акцент върху управлението на инциденти, свързани с ИКТ. Както обяснява Clarysec Zenith Controls:
„DORA изисква цялостен процес за управление на инциденти, свързани с ИКТ. Това включва класифициране на инциденти въз основа на конкретни критерии и докладване на сериозни инциденти на регулаторите. Фокусът е върху осигуряване на устойчивостта на цифровите операции в цялата финансова екосистема.“
GDPR (Общ регламент относно защитата на данните): Всеки инцидент, включващ лични данни, незабавно активира задължения по GDPR. Нарушение на сигурността на личните данни трябва да бъде докладвано на надзорния орган в рамките на 72 часа. Ефективният план за реагиране при инциденти трябва да съдържа ясен процес за установяване дали са засегнати лични данни и за незабавно стартиране на процеса за докладване по GDPR.
NIST Cybersecurity Framework (CSF): NIST CSF е широко възприета рамка, а нейните пет функции (Идентифициране, Защита, Откриване, Реагиране, Възстановяване) напълно съответстват на жизнения цикъл на управление на инциденти. Функциите „Реагиране“ и „Възстановяване“ са изцяло посветени на дейности по управление на инциденти, което прави план, базиран на ISO 27001, пряк принос към внедряването на NIST CSF.
COBIT 2019: Тази рамка за ИТ управление и мениджмънт също акцентира върху реагирането при инциденти. Clarysec Zenith Controls отбелязва съгласуването:
„Домейнът „Доставка, обслужване и поддръжка“ (DSS) на COBIT 2019 включва процес DSS02, „Управление на заявки за услуги и инциденти“. Този процес гарантира, че инцидентите се разрешават своевременно и не прекъсват бизнес операциите, като пряко съответства на целите на контролите за управление на инциденти по ISO 27001.“
Като изграждат устойчива програма за управление на инциденти, базирана на ISO 27001, организациите не просто постигат съответствие с един стандарт; те създават устойчива оперативна способност, която изпълнява основните изисквания на множество припокриващи се регулаторни рамки.
Подготовка за проверка: какво ще попитат одиторите
Планът за реагиране при инциденти е толкова добър, колкото са добри неговото изпълнение и документация. Когато пристигне одитор, той ще търси конкретни доказателства, че планът не е документ „за рафта“, а жива и действаща част от профила на риска за сигурността на организацията. Одиторите искат да видят зрял и повторяем процес.
Самият одитен процес е структуриран и методичен. Според цялостната пътна карта в Zenith Blueprint, одиторите систематично ще тестват ефективността на вашите контроли за управление на инциденти. По време на фаза 2, „Работа на място и събиране на доказателства“, одиторите ще отделят конкретни стъпки за тази област.
Стъпка 15: преглед на процедурите за управление на инциденти: Одиторите ще започнат с искане за формалния план за управление на инциденти и свързаните процедури. Те ще проверят тези документи за пълнота и яснота. Както Zenith Blueprint посочва за тази стъпка:
„Прегледайте документираните процедури на организацията за управление на инциденти в информационната сигурност. Проверете дали процедурите дефинират роли, отговорности и комуникационни планове за управление на инциденти.“
Те ще попитат:
- Има ли формално документиран план за реагиране при инциденти?
- Определен ли е екип за реагиране при инциденти (IRT) с ясни роли и информация за контакт?
- Има ли ясни процедури за докладване, класифициране и ескалация на инциденти?
- Включва ли планът комуникационни протоколи за вътрешни и външни заинтересовани страни?
Стъпка 16: оценяване на тестването на реагирането при инциденти: План, който никога не е тестван, вероятно ще се провали. Одиторите ще изискат доказателства, че планът е приложим. Zenith Blueprint подчертава това:
„Проверете дали планът за реагиране при инциденти се тества редовно чрез упражнения, като настолни симулации или пълномащабни тренировки. Прегледайте резултатите от тези тестове и проверете дали извлечените поуки са използвани за актуализиране на плана.“
Те ще поискат:
- Записи от настолни упражнения или симулационни тренировки.
- Доклади след тестване, описващи какво е преминало добре и какво изисква подобрение.
- Доказателства, че планът за реагиране при инциденти е актуализиран въз основа на тези констатации.
Стъпка 17: проверка на регистрите и докладите за инциденти: Накрая одиторите ще искат да видят плана в действие чрез преглед на записи за минали инциденти. Това е окончателният тест за ефективността на програмата. Те ще прегледат регистри на инциденти, записи от комуникациите на IRT и доклади след инцидент. Целта е да се провери дали организацията е следвала собствените си процедури по време на реално събитие.
Те ще попитат:
- Можете ли да предоставите регистър на всички инциденти в сигурността от последните 12 месеца?
- За избрани инциденти можете ли да покажете пълния запис — от откриването до окончателното отстраняване?
- Има ли доклади след инцидент, които анализират първопричината и идентифицират коригиращи действия?
- Обработени ли са доказателствата съгласно документираната процедура?
Подготовката за тези въпроси с добре организирана документация и ясни записи е ключът към успешен одит и демонстрира реална култура на устойчивост по отношение на сигурността.
Често срещани пропуски
Дори при наличен план много организации се затрудняват по време на реален инцидент. Избягването на тези често срещани пропуски е също толкова важно, колкото и наличието на добър план.
- Липса на формален и тестван план: Най-честият провал е изобщо да няма план или да има план, който никога не е бил тестван. Нетестваният план е набор от предположения, които чакат да бъдат опровергани в най-неподходящия момент.
- Неясно дефинирани роли и отговорности: По време на криза неяснотата е враг. Ако членовете на екипа не знаят точно какво трябва да направят, реагирането ще бъде бавно, хаотично и неефективно.
- Липса на комуникация: Оставянето на заинтересованите страни в неведение създава паника и недоверие. Ясен комуникационен план за служители, клиенти, регулатори и дори медии е необходим за управление на посланията и поддържане на доверие.
- Недостатъчно запазване на доказателства: В бързането да възстановят услугите екипите често унищожават ключови форензични доказателства. Това не само затруднява разследването след инцидента, но може да има и сериозни правни последици и последствия за съответствието.
- Пренебрегване на „извлечените поуки“: Най-голямата грешка е организацията да не се учи от инцидента. Без задълбочен преглед след инцидент и ангажимент за изпълнение на коригиращи действия организацията е обречена да повтори миналите си неуспехи.
- Игнориране на OT средата: За производителите третирането на реагирането при инциденти като чисто ИТ въпрос е критична грешка. Планът трябва изрично да адресира уникалните предизвикателства на OT средата, включително последиците за безопасността и различните протоколи за възстановяване на системи за индустриално управление.
Следващи стъпки
Преминаването от реактивна позиция към състояние на проактивна подготвеност е процес, но е процес, който всяка производствена организация трябва да предприеме. Пътят напред изисква ангажимент за изграждане на структурирана, основана на политики способност за управление на инциденти.
Препоръчваме да започнете със стабилна основа. Нашите шаблони на политики предоставят цялостна отправна точка за дефиниране на вашата рамка за управление на инциденти.
- Създайте ясен и приложим план с P16S Политика за управление на инциденти в информационната сигурност за МСП.
- Уверете се, че екипът ви е подготвен, като внедрите P08S Политика за осведоменост и обучение по информационна сигурност за МСП.
За по-задълбочено разбиране как тези контроли се вписват в по-широка среда на съответствие и как да се подготвите за строги одити, нашите експертни ръководства са ценен ресурс.
- Картирайте контролите си спрямо множество рамки с Zenith Controls.
- Подгответе се за одитна проверка със Zenith Blueprint.
Заключение
За средно голям производител тишината на спряла производствена линия е най-скъпият звук на света. В днешната взаимосвързана среда управлението на инциденти в информационната сигурност вече не е техническа функция, делегирана на ИТ отдела; то е основен стълб на оперативната устойчивост и непрекъснатостта на дейността.
Като възприемат структурирания подход на ISO 27001, организациите могат да преминат от хаотична реакция към контролирано и методично реагиране. Добре документиран и редовно тестван план за реагиране при инциденти, подкрепен от обучен и осведомен персонал, е най-силната предпазна мярка. Той минимизира престоя, контролира разходите, осигурява съответствие със сложна мрежа от регулации като NIS2 и DORA и най-важното — запазва доверието на клиентите и партньорите. Инвестицията в изграждането на тази способност не е разход; тя е инвестиция в бъдещата жизнеспособност и устойчивост на самия бизнес.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council