Наръчникът на CISO за GDPR и AI: ръководство за съответствие за SaaS продукти с LLM
Новият кошмар на CISO: вашият LLM току-що разкри клиентски данни
SaaS компанията расте бързо. Продуктовият екип току-що е пуснал AI асистент, който помага на потребителите да съставят имейли, да обобщават отчети и да търсят в данните на своя акаунт чрез голям езиков модел (LLM). Клиентите го харесват. Инвеститорите са оптимистично настроени. CISO обаче усеща познатото напрежение.
Две седмици по-късно длъжностното лице по защита на данните (DPO) влиза в залата с разпечатка от тестова среда:
QA инженер, докато тества нова функция, е попитал AI в тестова среда: „Покажи ми реалистичен клиентски тикет с истински имена и данни за карти, за да мога да тествам функцията за анализ на настроението.“
Моделът е върнал нещо обезпокоително реалистично, съдържащо действителни имена, имейли и частични номера на карти. Данните са били копирани от продукционна среда в тестова среда, за да се „подобри“ AI.
Изведнъж кошмарът за съответствието става реален:
- Лични данни са използвани за обучение и тестване без ясно правно основание.
- Тестовите данни не са правилно анонимизирани или маскирани, което създава токсична среда с данни.
- Моделът може да извежда чувствителна лично идентифицираща информация (PII) по непредвидими начини.
- Не можете лесно да изпълните „правото да бъдеш забравен“ на субект на данни, защото данните му са заложени в модела.
- Регулаторите питат как вашата нова AI функция отговаря на GDPR.
Този сценарий е ежедневна реалност за CISO и мениджърите по съответствието, които управляват сблъсъка между генеративния AI и регулациите за защита на данните. Искате да въвеждате иновации, но трябва да запазите доверието на регулатори, одитори и корпоративни клиенти във вашата позиция по отношение на риска за сигурността и поверителността.
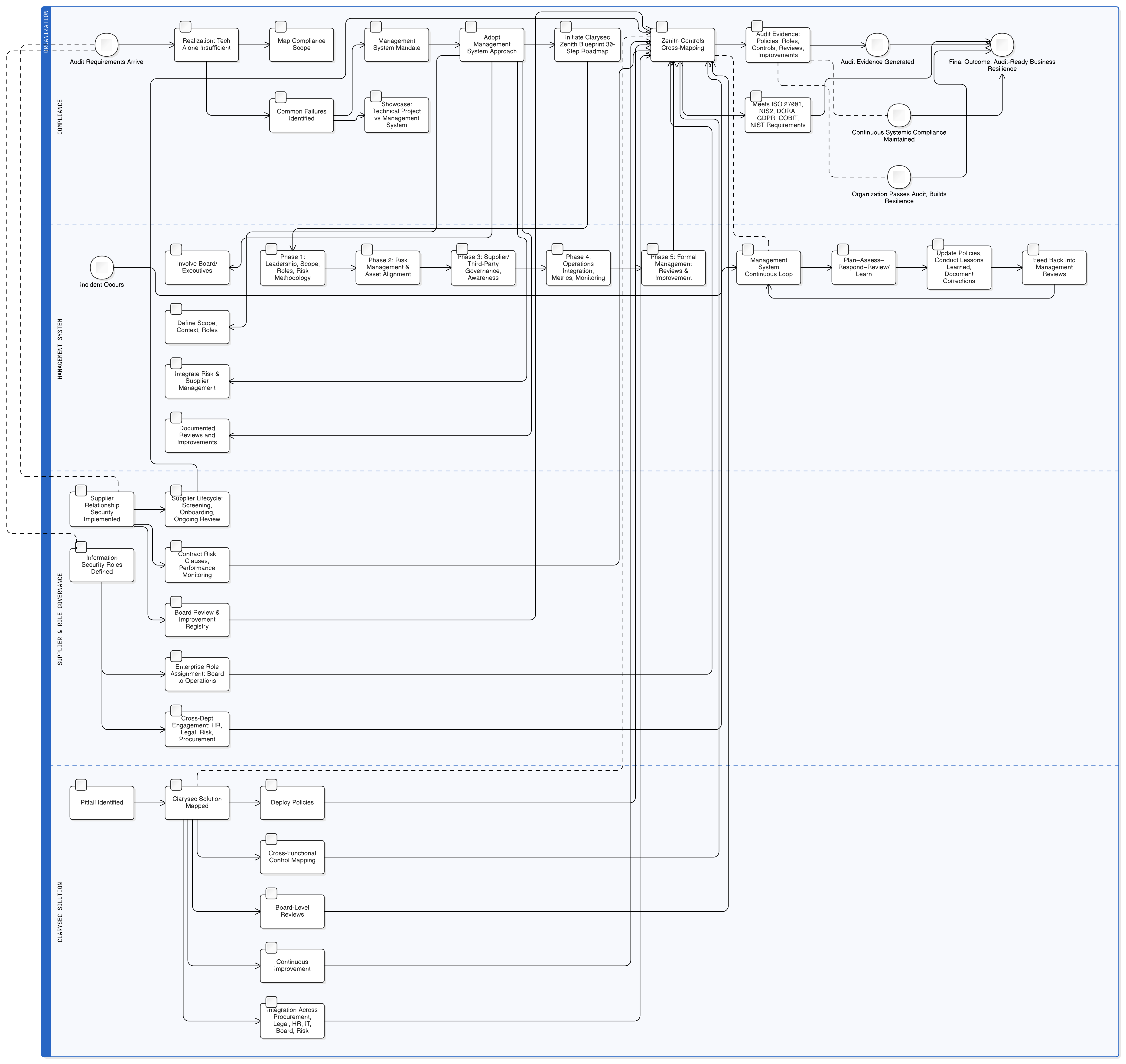
Това ръководство предоставя ясен и приложим път напред. Ще надхвърлим теоретичните дискусии и ще разгледаме практическото управление, техническите контроли и подготовката за одит, необходими за изграждане на AI функции, съответстващи на GDPR, като превърнем това сериозно предизвикателство в управляем и одитируем процес с помощта на структурираните инструменти на Clarysec.
Дилемата обработващ–администратор в света на AI
Преди да можете да защитите данните, трябва да разберете ролята си по GDPR. Това разграничение не е академично; то определя вашите правни задължения, договорни изисквания и контролите, които трябва да внедрите.
За повечето B2B SaaS платформи ролите първоначално са ясни:
- Вашият корпоративен клиент е администратор на лични данни, тъй като определя целите и средствата за обработване на лични данни.
- Вие сте обработващ лични данни, който действа съгласно документираните указания на клиента.
Както ISO/IEC 27018 обяснява за доставчиците на облачни услуги, тази роля на обработващ е типична. Когато обаче въведете LLM, границите се размиват.
- Ако използвате данните на клиента само за предоставяне на AI функции в рамките на неговия изолиран тенант, вероятно оставате обработващ.
- Ако агрегирате данни от множество клиенти в общ корпус за обучение, за да подобрите глобалния си модел, може да навлизате в ролята на администратор за тази конкретна дейност по обработване. Тази нова цел изисква собствено правно основание и прозрачност.
- Ако изпращате данни към външен доставчик на LLM, този доставчик става ваш подизпълнител по обработване, а вие носите отговорност за неговото съответствие.
Участието в обучение на AI модел често означава, че действате като администратор на данни за тази дейност, което води до редица задължения: определяне на правно основание, осигуряване на ограничение на целите и пряко управление на правата на субектите на данни.
Тук надеждната рамка за управление става задължителна. Политика за защита на данните и поверителност за МСП на Clarysec кодифицира този принцип, като посочва, че основна цел е да:
„Гарантира, че личните данни се обработват в съответствие със законите за поверителност и стандартите за сигурност, включително GDPR, NIS2 и ISO 27001.“
- От раздел „Цели“, клауза 3.1 на политиката.
Този ангажимент, вграден във вашия набор от политики, създава основа за изграждане на доверие и гарантира, че съответствието не е последваща мисъл.
Поверителност още при проектирането за LLM: вграждане на съответствието, а не добавяне впоследствие
GDPR Article 25 изисква „защита на данните на етапа на проектирането и по подразбиране“. Това не е препоръка; това е правно изискване. За AI системите това означава, че съображенията за поверителност трябва да бъдат вградени директно в архитектурата на вашите пайплайни за данни, среди за обучение и механизми за инференция.
Перифразирайки насоките в ISO/IEC 27701, това включва няколко ключови действия за всяка SaaS платформа, разработваща AI:
- Минимизиране още при проектирането: Не изпращайте цели записи към LLM, ако е необходим само поднабор. Редактирайте или маскирайте идентификаторите, преди промптовете да напуснат основната ви система.
- Ограничение на целите: Разделете „данните, използвани за предоставяне на функцията“, от „данните, използвани за подобряване на модела“. Всяка цел трябва да има собствено правно основание и да бъде ясно документирана.
- Конфигурируеми настройки по подразбиране: Предоставете превключватели на ниво тенант, например: „Разрешавам данните ми да се използват за подобряване на глобалния AI модел: Да/Не.“ Настройките по подразбиране трябва да са консервативни (отказ по подразбиране), освен ако нямате силна обосновка.
- Проследимост: Журнализирайте кои данни са използвани в коя задача за обучение, на какво правно основание и за кой тенант. Това е критично за одити и искания от субекти на данни.
Zenith Blueprint: 30-стъпкова пътна карта за одитори на Clarysec предоставя структуриран път за вграждане на тези изисквания много преди да напишете първия ред код. Той започва с управлението:
- Основополагаща фаза, стъпка 2: разбиране на заинтересованите страни: Тази стъпка ви задължава да идентифицирате всички заинтересовани страни, включително регулаторите от ЕС. Както отбелязва Zenith Blueprint, техните изисквания включват „законосъобразно обработване на лични данни, докладване на нарушения в срок до 72 часа [и] права на субектите на данни“.
- Фаза „Одит и подобрение“, стъпка 24: изграждане и поддържане на регистър на правните и регулаторните изисквания: Работете с правните екипи за създаване на централен регистър на всички приложими закони, като разберете как GDPR, NIS2, DORA и други се пресичат с вашата позиция по отношение на риска за AI сигурността.
С тази основа можете уверено да преминете към техническото внедряване.
Защита на горивото: законосъобразни и минимални данни за обучение
Най-деликатният въпрос в съответствието на AI е прост: „Можем ли да използваме клиентски данни за обучение на нашите модели?“
Отговорът се крие в многослойна стратегия, съсредоточена върху правно основание, минимизиране на данните и технически предпазни мерки като псевдонимизация.
Правно основание и прозрачна цел
Съгласно ISO/IEC 27701 трябва да идентифицирате и документирате целите на обработването и да определите правно основание за всяка от тях.
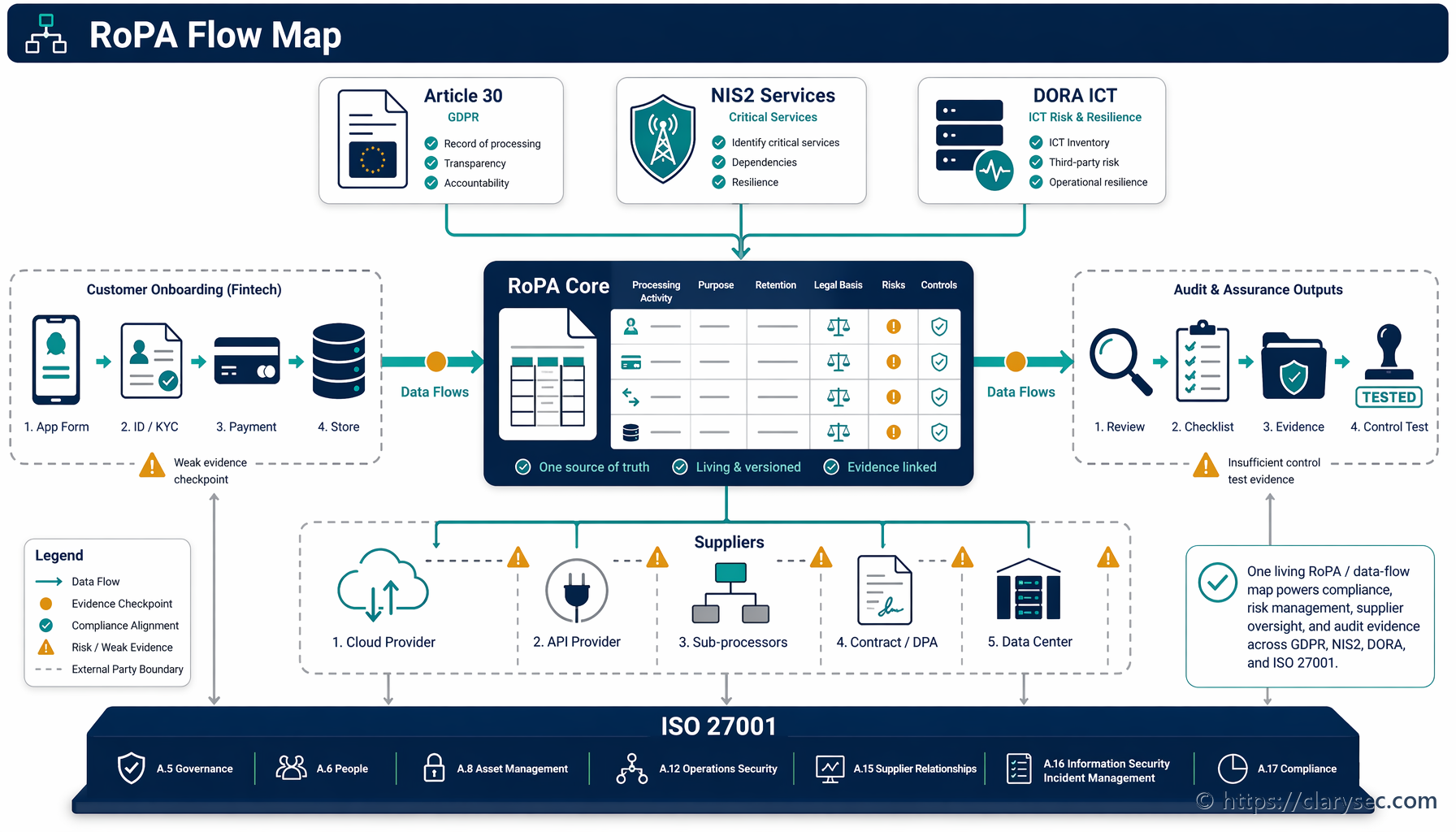
- За предоставяне на функцията (напр. AI търсене в рамките на един тенант): Правното основание обикновено е изпълнение на договор или легитимен интерес. Това трябва да бъде документирано във вашия Регистър на дейностите по обработване (RoPA).
- За подобряване на глобалния модел (между тенанти): Това често изисква изрично съгласие или много внимателно обоснован легитимен интерес с ясен и лесен механизъм за отказ. Прозрачността във вашето уведомление за поверителност и потребителския интерфейс на продукта е задължителна.
Технически предпазни мерки: псевдонимизация и маскиране
Истинската анонимизация е трудна за постигане, без да се унищожи полезността на данните. По-практичен и подкрепян от GDPR подход е псевдонимизацията: замяна на личните идентификатори с изкуствени идентификатори. Това намалява риска, като същевременно запазва стойността на данните за обучение на модела.
Този процес е основен контрол. В Zenith Blueprint стъпка 20 разглежда конкретно маскирането на данни, като го свързва пряко с принципите на GDPR Article 25 and 32. Това е задължителна мярка за сигурност, а не просто добра практика.
Политика за маскиране на данни и псевдонимизация на Clarysec операционализира това чрез ясно възлагане на отговорност:
„DPO трябва да валидира съответствието с критериите на GDPR за псевдонимизация и да координира с правния отдел всички регулаторни изисквания за оповестяване, свързани с нарушения на сигурността на данните или откази на контроли за маскиране.“
- От раздел „Прилагане и съответствие“, клауза 8.4 на политиката.
За вашите екипи за разработка това означава внедряване на автоматизирани скриптове за маскиране или псевдонимизиране на имена, имейли, телефонни номера и други преки идентификатори, преди данните изобщо да влязат в средата за обучение. Това също означава установяване на формален процес за валидиране с вашия DPO, за да се гарантира, че техниката е надеждна.
Скритата заплаха: защита на тестовите данни и AI експериментите
Реалните нарушения на сигурността на данните рядко започват в лъскава, укрепена продукционна среда. Те започват в забравените ъгли на вашата инфраструктура:
- „Безопасни“ тестови среди с лошо санирани копия на продукционни данни.
- „Временни“ CSV експорти на клиентски данни, изпратени на ML инженери за локални експерименти.
- QA скриптове, които използват сурово потребителско съдържание за тестване на LLM промптове.
Точно там започна кошмарният сценарий от въведението. Политика за тестови данни и тестови среди за МСП на Clarysec адресира директно този риск:
„Спазване на приложимите регулации за защита на данните (напр. GDPR, NIS2), като се гарантира, че всички тестови данни се обработват законосъобразно, добросъвестно и сигурно.“
- От раздел „Цели“, клауза 3.4 на политиката.
Вашата политика трябва да бъде подкрепена с практически контроли. Продукционни лични данни не трябва никога да съществуват в непродукционни среди без надеждно маскиране или псевдонимизация. Тестовите среди трябва да използват отделни LLM API ключове с по-ниски привилегии и строги ограничения на честотата на заявките. Освен това трябва да има изрично правило, че тестовите промптове никога не включват реални клиентски идентификатори.
Укрепване на ядрото: детайлен контрол на достъпа за AI пайплайни
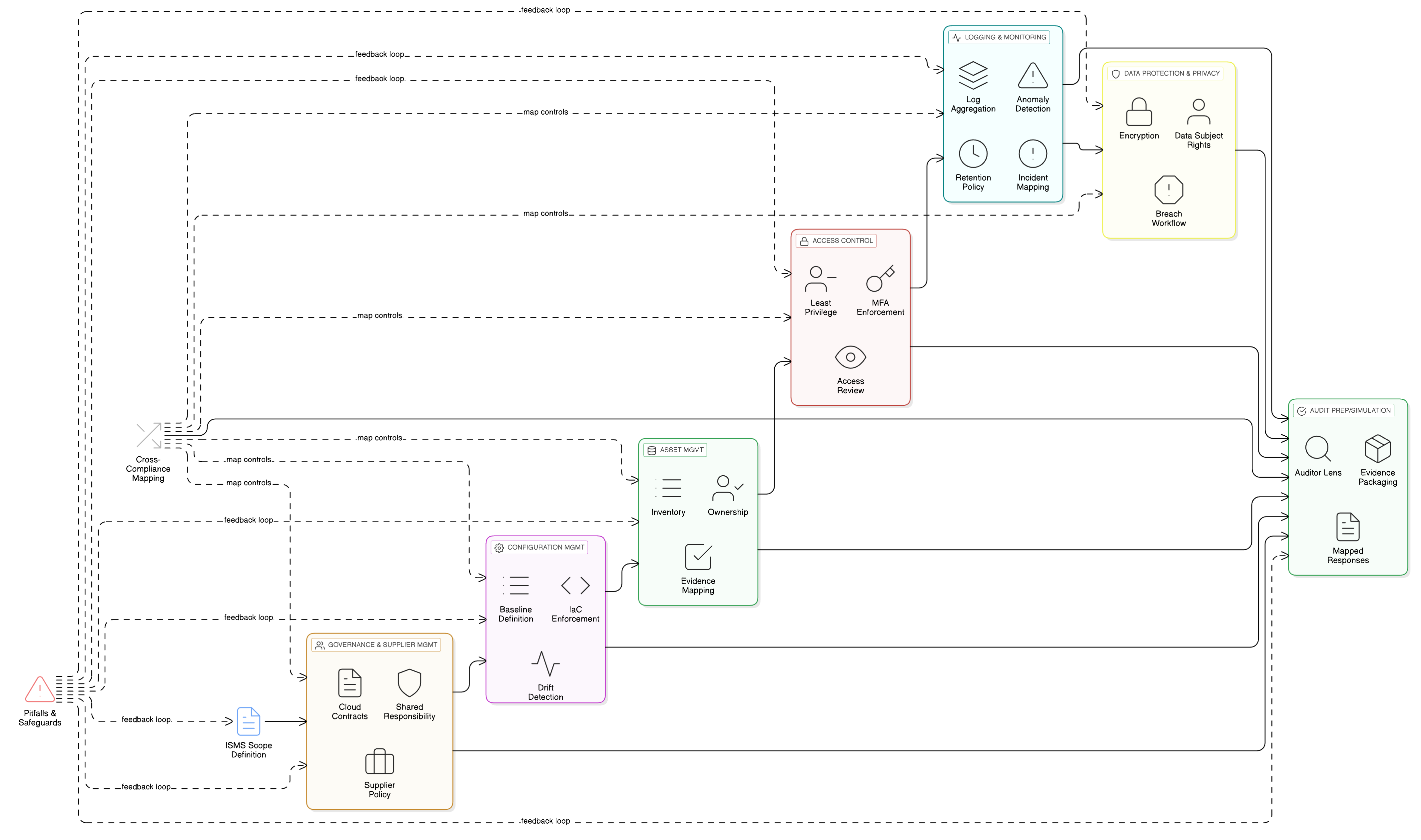
LLM функциите се разполагат върху най-чувствителните ви хранилища на данни, журнали и пайплайни за обучение. Поради това базовият контрол на достъпа е от първостепенно значение за съответствието с GDPR. ISO/IEC 27001:2022 контроли 8.3 и 8.2 са стълбовете на вашата защита. Zenith Controls: ръководство за съответствие между рамки на Clarysec предоставя план за ефективното им внедряване.
ISO/IEC 27001:2022 Контрол 8.3: ограничаване на достъпа до информация
Този контрол е насочен към гарантиране, че достъпът до информация се предоставя строго на принципа „необходимост да се знае“. За среда за обучение на LLM това означава, че вашите специалисти по данни, ML инженери и самите автоматизирани процеси трябва да имат достъп само до конкретните данни, които са им необходими, и до нищо повече.
Както е описано в Zenith Controls, това е тясно свързано с други контроли:
- Връзка с 5.9 (Инвентар на информацията и други свързани активи) и 5.12 (Класификация на информацията): Не можете да ограничите достъпа, ако не знаете с какви данни разполагате и колко чувствителни са те. Вашият набор от данни за обучение на AI трябва да бъде инвентаризиран и класифициран като строго поверителна информация — процес, управляван от вашата Политика за класификация и етикетиране на данни за МСП.
- Връзка с 8.5 (сигурна автентикация): Ограниченията на достъпа са безсмислени без силна проверка на идентичността. Всеки потребител и служебен акаунт, който има достъп до данните за обучение, трябва да бъде сигурно автентикиран, за предпочитане с MFA.
ISO/IEC 27001:2022 Контрол 8.2: права за привилегирован достъп
Вашите ML инженери, SRE и специалисти по данни се нуждаят от повишен достъп. Тези привилегировани акаунти са „ключовете към кралството“ и основни цели за атака. Контрол 8.2 изисква тези права да се управляват с изключително висока строгост.
Според Zenith Controls ключовите взаимовръзки са:
- Връзка с 8.15 (журнализиране) и 8.16 (дейности по мониторинг): Всяка привилегирована дейност трябва да се журнализира и наблюдава. Ако специалист по данни внезапно се опита да експортира целия набор от данни за обучение, предупреждението трябва да се задейства незабавно.
- Връзка с 6.7 (дистанционна работа): Ако вашият AI екип работи дистанционно, неговият привилегирован достъп трябва да преминава през сигурни и наблюдавани канали като VPN със строги контроли на сесиите.
Перспективата на одитора: как да докажете, че AI контролите работят
Внедряването на контроли е само половината от задачата. Трябва да докажете тяхната ефективност. Различните одитори, обучени по различни рамки, ще търсят конкретни доказателства.
| Тип одитор | Фокус на рамката | Какво ще поискат (доказателства) |
|---|---|---|
| Одитор по ISO/IEC 27001 | ISO/IEC 27007:2020 | Покажете ми вашата политика за контрол на достъпа за средата за обучение на AI. Предоставете журнали от процеса за преглед на достъпа за последните 12 месеца. Демонстрирайте как на нов ML инженер се предоставя достъп с минимални привилегии. |
| Одитор по COBIT | COBIT 2019 (DSS05) | Трябва да видя вашата матрица за ролеви контрол на достъпа (RBAC) за екипа по data science. Предоставете отчети от инструментите за мониторинг, които показват предупреждения за аномални опити за достъп до езерото с данни за обучение. |
| Оценител по NIST | NIST SP 800-53A (AC-3, AC-6) | Нека прегледаме системната конфигурация на сървърите, хостващи данните за обучение. Искам да проверя дали списъците за контрол на достъпа (ACL) технически прилагат документираните от вас политики. Покажете ми доказателства, че привилегированите сесии се прекратяват след неактивност. |
| Одитор по GDPR/поверителност | ISO/IEC 27701:2021 | Предоставете вашата оценка на въздействието върху защитата на данните (DPIA) за AI функцията. Покажете ми записите за съгласие на субектите на данни, чиято информация е в набора за обучение. Как обработвате искане за „право на изтриване“ за данни в обучен модел? |
Правилното внедряване на контроли 8.2 и 8.3 носи широки ползи. Zenith Controls показва пряко съпоставяне с изискванията в GDPR (Articles 5, 25, 32), NIS2 (Article 21), DORA (Article 10) и NIST SP 800-53 (AC-3, AC-6), което ви позволява да удовлетворите множество рамки чрез единно внедряване на контроли.
Парадоксът на „правото да бъдеш забравен“: управление на правата на субектите на данни в AI
GDPR Article 17, „правото на изтриване“, представлява уникално техническо предизвикателство за AI. Как можете да изтриете данните на дадено лице, след като те са били използвани за обучение на масивен и сложен модел? Често е технически невъзможно конкретни точки от данни да бъдат „отучени“ от модела.
Тук първоначалните ви проектни решения се превръщат в най-добрата ви защита. Няма един-единствен перфектен отговор, но практичните и защитими стратегии включват:
- Първо псевдонимизация: Ако данните за обучение са били правилно псевдонимизирани, връзката с лицето вече е прекъсната в корпуса за обучение. След това можете да изтриете личните данни от изходните системи и връзката в таблицата с ключове за псевдонимизация.
- Разделяне на данните за обучение: Когато е възможно, поддържайте отделни набори от данни за обучение за всеки тенант. Това прави премахването на данни осъществимо без повторно обучение на цялата ви екосистема от модели.
- Планирано повторно обучение на модела: Вашата DPIA трябва да адресира този риск. Мярката за смекчаване може да бъде ангажимент за периодично повторно обучение на модела от нулата с обновен набор от данни, който изключва данните на потребители, поискали изтриване.
Разделът на Zenith Blueprint за изтриване на информация (стъпка 20, обхващаща контрол 8.10) изрично свързва тази техническа способност с GDPR Articles 17 and 5(1)(e), като изисква проверими процеси за сигурно изтриване на данни, когато вече не са необходими.
Защита на вашата AI верига на доставки: външна разработка и LLM от трети страни
Малко SaaS компании изграждат всичко вътрешно. Може да използвате LLM API на hyperscaler или да сключите договор с партньор за разработка, възложена на външен изпълнител. Това въвежда риск за веригата на доставки.
Zenith Blueprint, в стъпка 22 относно външната разработка, подчертава този риск и връзката му с GDPR Articles 28 and 32. Както се посочва в blueprint-а:
„Една често пренебрегвана област е обучението и осведомеността. Вашите външни разработчици може да са компетентни, но обучени ли са в практики за сигурно разработване? Познават ли вашите политики? Наясно ли са с рамките за съответствие, които трябва да спазвате — GDPR, DORA, NIS2…?“
За всеки външен доставчик на LLM или партньор за разработка надлежната проверка е критична. Вашето Споразумение за обработване на лични данни (DPA) трябва изрично да обхваща целите на обработване, свързани с AI, категориите данни и забраните доставчикът да използва вашите данни за обучение на свои модели. Трябва да проверите, че той прилага мерки за сигурност, съгласувани с GDPR Article 32. Вашата AI верига на доставки трябва да бъде толкова одитируема, колкото и основната ви инфраструктура.
От теория към практика: конкретен пример за AI функция, готова за GDPR
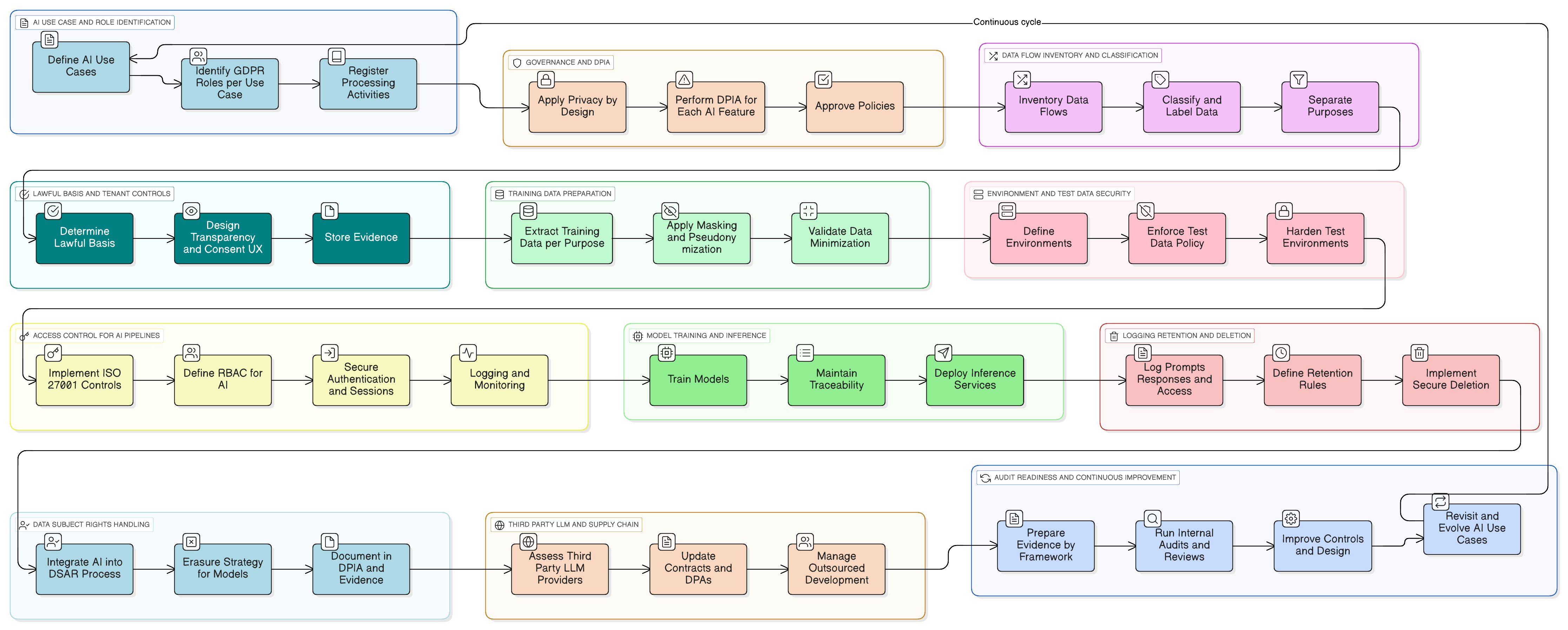
Нека го направим конкретно. Представете си, че добавяте AI асистент, който обобщава разговори с клиентската поддръжка, предлага чернови на отговори и се учи от предходни тикети, за да се подобрява.
Ето практичен модел за внедряване с помощта на инструментариума на Clarysec:
- Класификация и етикетиране: Всички тикети към поддръжката се класифицират като „Поверителна информация“ съгласно вашата Политика за класификация и етикетиране на данни за МСП, в съответствие със задълженията по GDPR и DORA за боравене с данни.
- Маскиране преди LLM: Услуга за маскиране прихваща данните, преди да бъдат изпратени към LLM. Тя премахва или заменя имена, имейли, телефонни номера и друга PII. Целият процес се управлява от Политика за маскиране на данни и псевдонимизация, като DPO валидира методологията.
- Контроли на достъпа за промптове и журнали: Само оторизирани роли (напр. собственик на AI продукт) могат да имат достъп до необработени журнали на промптове. Това се внедрява чрез ISO 27001:2022 контрол 8.3 (ограничаване на достъпа до информация) за общия достъп и контрол 8.2 (права за привилегирован достъп) за всяка видимост на административно ниво, както е картографирано в Zenith Controls.
- Съгласие за корпуса от данни за обучение: Пайплайнът за обучение поглъща само маскирани данни. Предоставя се конфигурационна настройка на ниво тенант: „Разрешавам моите маскирани данни да се използват за подобряване на глобалния AI модел: Да/Не“, като стойността по подразбиране е „Не“.
- Съхранение и изтриване: Журналите на промптове се съхраняват само толкова дълго, колкото е необходимо. Когато тенант деактивира функцията или прекрати договора си, се задейства работен поток за сигурно изтриване или анонимизиране на свързаните AI журнали и записи за обучение, съгласно процеса, описан във вашето внедряване на Zenith Blueprint за контрол 8.10 (изтриване на информация).
Когато одиторите пристигнат, можете да ги преведете през диаграмите на потоците от данни на функцията, конкретните политики, които я управляват, и техническите доказателства от вашите системи, журнали за достъп, конфигурации на задачи и работни потоци за изтриване. Така доказвате съответствието в действие.
Вашият план за действие: от ad hoc към готов за одит AI
Не е нужно да разглобявате продукта си, но ви е необходим структуриран и защитим подход. Ето кратък план за действие:
- Инвентаризирайте AI случаите на употреба и потоците от данни: Идентифицирайте всяко място, където се използват LLM — функции за клиенти, вътрешни инструменти и експерименти. Картирайте кои данни къде отиват, на какво правно основание и кой има достъп. Използвайте основополагащата фаза на Zenith Blueprint, за да гарантирате, че вашият правен регистър обхваща всички свързани с AI изисквания на GDPR, NIS2 и DORA.
- Първо установете управление: Преди изграждане извършете оценка на въздействието върху защитата на данните (DPIA) за всяка AI функция. Документирайте нейната цел, правно основание и рискове. Внедрете основни политики като Политика за защита на данните и поверителност за МСП и Политика за информационна сигурност за МСП.
- Ограничете данните и достъпа: Внедрете надеждни технически контроли. Приемете Политика за маскиране на данни и псевдонимизация и Политика за тестови данни и тестови среди за МСП. Използвайте Zenith Controls, за да внедрите и документирате ISO 27001:2022 контроли 8.2 и 8.3 за всички AI хранилища на данни и пайплайни.
- Вградете правата на субектите на данни в AI работните потоци: Актуализирайте процедурите си за DSAR и изтриване, така че да включват данни, свързани с AI. Документирайте стратегията си за обработване на искания за изтриване в контекста на обучени модели, с фокус върху псевдонимизацията и графиците за повторно обучение на моделите.
- Поставете AI веригата на доставки под контрол: Актуализирайте DPA с външни доставчици на LLM и външни разработчици. Уверете се, че договорите изрично забраняват неоторизирано използване на данни и изискват силни мерки за сигурност. Проверете дали външните екипи са обучени по вашите политики за боравене с данни.
Отключване на иновации с увереност
Пресечната точка между AI и GDPR е новата граница на съответствието. Като възприемете структуриран, основан на риска подход, можете да отключите трансформиращата сила на изкуствения интелект, без да компрометирате ангажимента си към защитата на данните и поверителността.
Clarysec предоставя картата, инструментите и експертизата, за да ви води по този път. Чрез:
- Zenith Blueprint: 30-стъпкова пътна карта за одитори за поетапно внедряване на контроли за AI, съгласувани с GDPR.
- Zenith Controls: ръководство за съответствие между рамки за обединяване на ISO 27001:2022 контролите с изискванията на GDPR, NIS2, DORA и NIST.
- Готови за продукционна употреба политики като Политика за защита на данните и поверителност за МСП, Политика за маскиране на данни и псевдонимизация и Политика за тестови данни и тестови среди за МСП, за да кодифицирате правилата си и да удовлетворите одиторите.
Можете да преминете от ad hoc AI експерименти към готова за одит AI способност, която вдъхва доверие на регулатори, одитори и взискателни корпоративни клиенти. Можете да продължите да въвеждате иновации с LLM и въпреки това да спите спокойно.
Ако планирате или вече използвате AI функции във вашия SaaS продукт, следващата ви стъпка е ясна. Изтеглете примерни материали от нашия инструментариум или запазете демонстрация, за да видите как Clarysec може да ви помогне да изградите AI програма, която е не само мощна, но и доказуемо поверителна и сигурна още при проектирането.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council