Anatomie bezpečnostního incidentu: průvodce výrobní firmy reakcí na incidenty podle ISO 27001
Doporučený úryvek
Účinná reakce na incidenty informační bezpečnosti minimalizuje škody způsobené porušením bezpečnosti a zajišťuje provozní odolnost. Tento průvodce poskytuje výrobcům praktický rámec krok za krokem založený na ISO 27001, který jim pomáhá připravit se na reálné kybernetické útoky, reagovat na ně, obnovit provoz a současně splnit komplexní požadavky na soulad, například podle NIS2 a DORA.
Úvod
Výstraha se rozsvítí ve 2:17 ráno. Centrální server středně velkého výrobce automobilových dílů neodpovídá a monitory výrobní linky zobrazují ransomwarovou zprávu. Každá minuta výpadku stojí tisíce v ušlé výrobě a zvyšuje riziko porušení přísných SLA v dodavatelském řetězci. Nejde o cvičení. Pro CISO je to okamžik, kdy se roky plánování, tvorby politik a školení podrobují nejvyšší zkoušce.
Mít plán reakce na incidenty uložený na serveru je jedna věc; provést jej pod extrémním tlakem je věc zcela jiná. U výrobců jsou dopady mimořádně závažné. Kybernetický incident neohrožuje jen data; zastavuje výrobu, narušuje fyzické dodavatelské řetězce a může ohrozit bezpečnost pracovníků.
Tento průvodce jde nad rámec teoretických playbooků a nabízí praktický, reálný plán pro vybudování a řízení funkčního programu reakce na incidenty. Rozebereme anatomii reakce na porušení bezpečnosti, opřenou o robustní rámec ISO/IEC 27001, a ukážeme, jak vybudovat odolný program, který se z útoku nejen zotaví, ale obstojí i před auditory a regulačními orgány.
Co je v sázce: řetězový dopad incidentu ve výrobě
Když jsou systémy výrobce kompromitovány, dopad sahá daleko za jeden server. Propojenost moderní výroby, od řízení zásob po robotické montážní linky, znamená, že digitální selhání může způsobit úplné zastavení provozu. Důsledky jsou závažné a vícevrstvé.
Zaprvé, finanční ztráty vznikají okamžitě a intenzivně. Zastavení výroby vede k nedodržení termínů, smluvním pokutám od zákazníků a nákladům na nečinnou pracovní sílu. Obnova systémů, úhrada forenzních expertů a případné řešení požadavků na výkupné mohou ochromit finance středně velké společnosti.
Zadruhé, poškození dobré pověsti může být dlouhodobé. V prostředí B2B je spolehlivost klíčová. Jediný závažný incident může narušit důvěru klíčových partnerů, kteří jsou závislí na dodávkách just-in-time. Jak zdůrazňují naše interní pokyny, klíčovým cílem řízení incidentů je „minimalizovat obchodní a finanční dopad incidentů a obnovit běžný provoz co nejrychleji“, což je ve výrobě zásadní.
Nakonec může tvrdě dopadnout i regulatorní postih. S plným nástupem rámců, jako je směrnice EU o bezpečnosti sítí a informací (NIS2) a nařízení o digitální provozní odolnosti (DORA), čelí organizace v kritických odvětvích, včetně výroby, přísným požadavkům na hlášení incidentů a hrozbě významných pokut za nesoulad. Špatně zvládnutý incident není pouze technické selhání; představuje významné právní riziko i riziko nesouladu.
Jak vypadá dobrý stav: od chaosu ke kontrole
Účinný program reakce na incidenty promění krizi z chaotického, reaktivního hašení problémů ve strukturovaný a řízený proces. Cílem není jen odstranit technický problém, ale řídit celou událost tak, aby byla chráněna organizace. Tento cílový stav stojí na zásadách uvedených v rámci ISO/IEC 27001, zejména na opatřeních pro řízení incidentů informační bezpečnosti.
Vyspělý program se vyznačuje několika klíčovými výsledky:
- Jasné role: Každý ví, komu zavolat a jaké jsou jeho odpovědnosti. Tým pro reakci na incidenty (IRT) je předem definován, má jasné vedení a určené odborníky z IT, právního oddělení, komunikace a vrcholového vedení.
- Rychlost a přesnost: Organizace dokáže rychle detekovat, analyzovat a omezit hrozby, zabránit jejich šíření v síti a zamezit zastavení celé výrobní haly.
- Informované rozhodování: Vedení dostává včasné a přesné informace, aby mohlo přijímat kritická rozhodnutí o provozu, komunikaci se zákazníky a regulatorních oznámeních.
- Neustálé zlepšování: Každý incident, velký i malý, se stává příležitostí k učení. Důkladný proces přezkoumání po incidentu identifikuje slabiny a promítá zlepšení zpět do bezpečnostního programu.
Dosažení této připravenosti je hlavním účelem opatření popsaných v ISO/IEC 27002:2022. Tato opatření vedou organizace při plánování a přípravě (A.5.24), posuzování a rozhodování o událostech (A.5.25), reakci na incidenty (A.5.26) a poučení z nich (A.5.28). Jde o vybudování odolného systému, který počítá se selháním a je strukturován tak, aby je zvládl řízeně.
Praktická cesta: podrobný průvodce reakcí na incidenty
Vybudování robustní schopnosti reakce na incidenty vyžaduje dokumentovaný a systematický přístup. Jeho základem je jasná a použitelná politika, která popisuje každou fázi procesu.
Naše P16S Politika plánování a přípravy řízení incidentů informační bezpečnosti – SME poskytuje komplexní vzor, který je v souladu s osvědčenými postupy ISO 27001. Projděme si klíčové kroky s využitím této politiky jako vodítka.
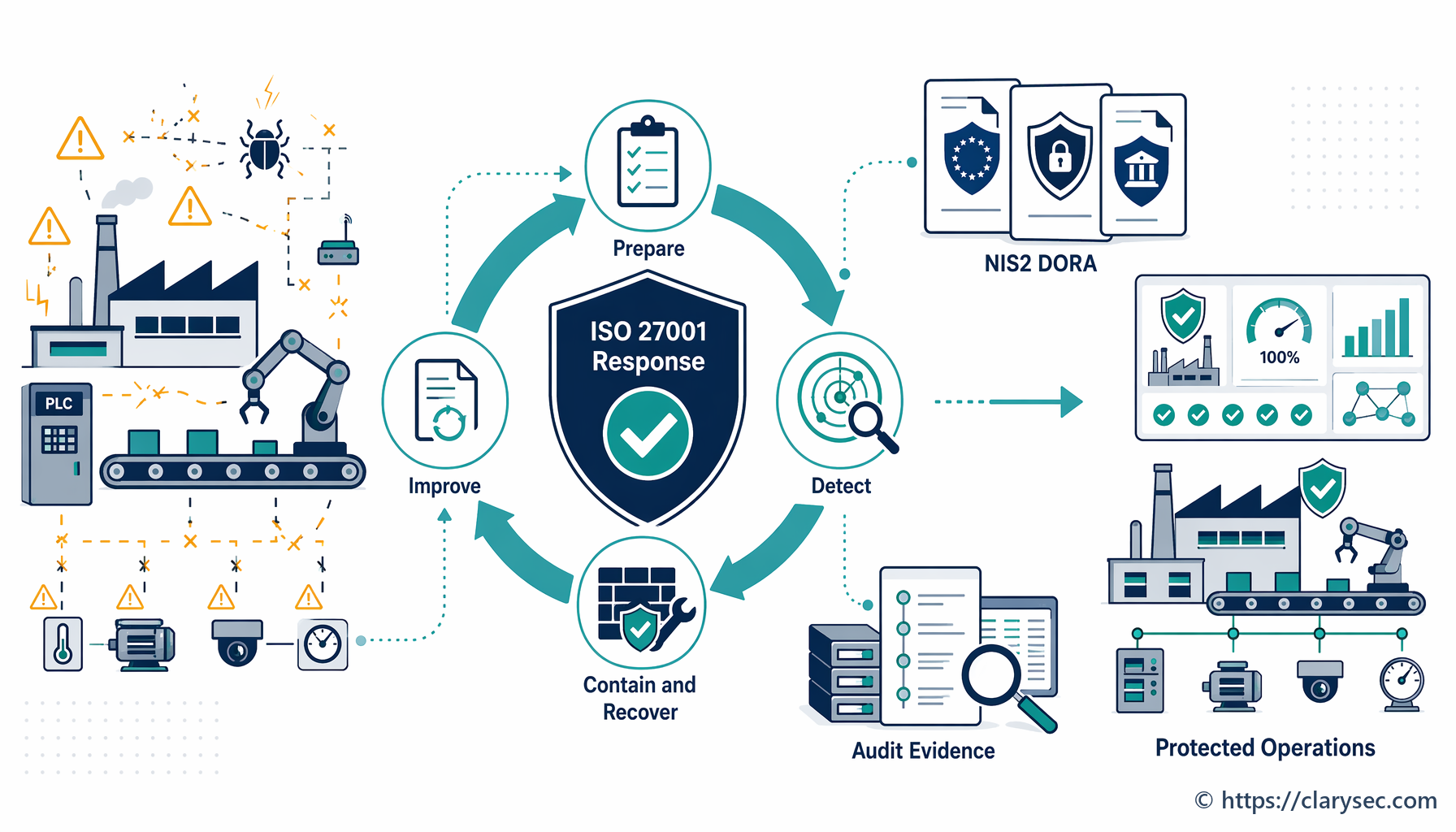
Krok 1: plánování a příprava – základ odolnosti
Plán reakce nelze vytvářet uprostřed krize. Příprava je rozhodující. Tato fáze spočívá ve vytvoření struktury, nástrojů a znalostí potřebných k rozhodnému jednání při vzniku incidentu.
Základní součástí je ustavení týmu pro reakci na incidenty (IRT). Jak je uvedeno v kapitole 5.1 P16S Politiky plánování a přípravy řízení incidentů informační bezpečnosti – SME, účelem politiky je „zajistit konzistentní a účinný přístup k řízení incidentů informační bezpečnosti“. Tato konzistence začíná dobře definovaným týmem. Politika stanoví, že IRT má zahrnovat členy z klíčových útvarů:
- IT a informační bezpečnost
- Právní oddělení a compliance
- Lidské zdroje
- Public relations/komunikace
- Vrcholové vedení
Každý člen musí mít jasně definované role a odpovědnosti. Kdo má pravomoc odstavit systémy? Kdo je určeným mluvčím pro komunikaci se zákazníky nebo médii? Tyto otázky musí být zodpovězeny a zdokumentovány dlouho před incidentem.
Krok 2: detekce a hlášení – systém včasného varování
Čím dříve o incidentu víte, tím menší škodu může způsobit. Vyžaduje to technické monitorování i kulturu, ve které zaměstnanci vědí, že jsou oprávněni a povinni hlásit podezřelou aktivitu.
P16S Politika plánování a přípravy řízení incidentů informační bezpečnosti – SME je v tomto bodě jednoznačná. Kapitola 5.3, „Hlášení událostí informační bezpečnosti“, stanoví:
„Všichni zaměstnanci, dodavatelé a další relevantní strany jsou povinni co nejrychleji hlásit jakékoli pozorované nebo podezřelé události informační bezpečnosti a slabiny určenému kontaktnímu místu.“
Toto „určené kontaktní místo“ je kritické. Může jím být IT service desk nebo vyhrazená bezpečnostní linka. Proces musí být jednoduchý a dobře komunikovaný všem pracovníkům. Zaměstnanci musí být školeni v tom, čeho si všímat, například phishingových e-mailů, neobvyklého chování systému nebo porušení fyzické bezpečnosti.
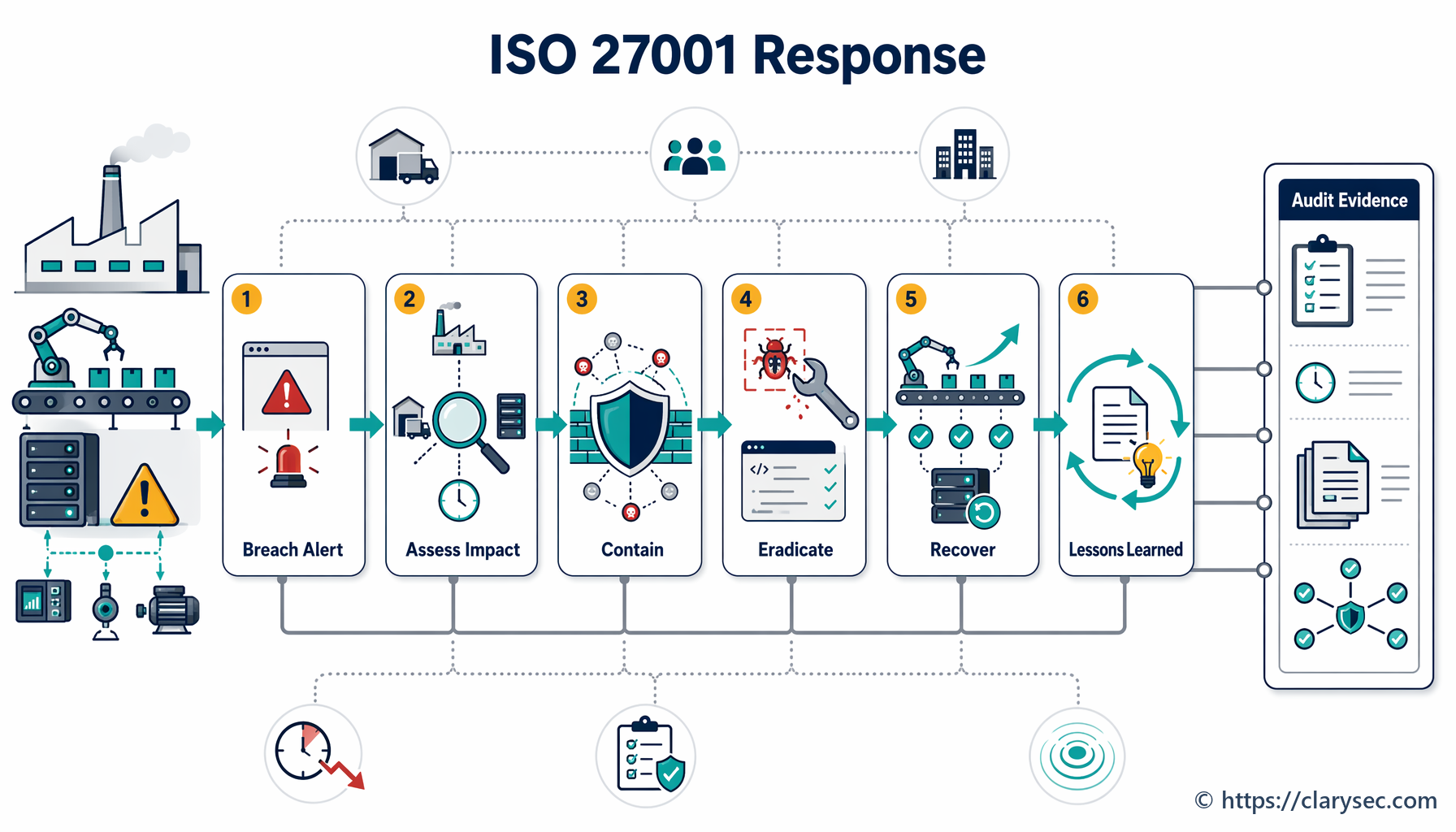
Krok 3: posouzení a triáž – určení rozsahu hrozby
Jakmile je událost nahlášena, dalším krokem je rychlé posouzení její povahy a závažnosti. Jde o falešný poplach, drobný problém, nebo plnohodnotnou krizi? Tento proces triáže určuje požadovanou úroveň reakce.
Naše politika v kapitole 5.2, „Klasifikace incidentů“, stanoví jasné klasifikační schéma pro kategorizaci incidentů podle jejich dopadu na důvěrnost, integritu a dostupnost. Typické schéma může vypadat takto:
- Nízká: Jedna pracovní stanice infikovaná běžným malwarem, snadno izolovatelná.
- Střední: Server oddělení je nedostupný, což ovlivňuje konkrétní podnikovou funkci, ale nezastavuje celkovou výrobu.
- Vysoká: Rozsáhlý ransomwarový útok ovlivňující kritické výrobní systémy a klíčová podniková data.
- Kritická: Incident zahrnující porušení zabezpečení citlivých osobních údajů nebo duševního vlastnictví s významnými právními a reputačními dopady.
Tato klasifikace určuje naléhavost, přidělené zdroje a eskalační cestu vůči vedení, aby byla reakce přiměřená hrozbě.
Krok 4: zamezení šíření, eradikace a obnova – hašení požáru
Jde o aktivní fázi reakce, ve které IRT pracuje na zvládnutí incidentu a obnovení běžného provozu.
- Zamezení šíření: Bezprostřední prioritou je zastavit škody. Může jít o izolaci dotčených síťových segmentů, odpojení kompromitovaných serverů nebo blokování škodlivých IP adres. Cílem je zabránit šíření incidentu a dalším škodám.
- Eradikace: Po zamezení šíření musí být odstraněna kořenová příčina incidentu. Může to znamenat odstranění malwaru, záplatování zneužitých zranitelností a deaktivaci kompromitovaných uživatelských účtů.
- Obnova: Posledním krokem je obnova dotčených systémů a dat. Zahrnuje obnovu z čistých záloh, opětovné sestavení systémů a pečlivé monitorování, aby bylo před opětovným uvedením služeb do provozu potvrzeno úplné odstranění hrozby.
Kapitola 5.4 P16S Politiky plánování a přípravy řízení incidentů informační bezpečnosti – SME, „Reakce na incidenty informační bezpečnosti“, poskytuje rámec pro tyto kroky a zdůrazňuje, že „postupy reakce musí být zahájeny po klasifikaci události informační bezpečnosti jako incidentu“.
Krok 5: činnosti po incidentu – získané poznatky
Práce nekončí ve chvíli, kdy jsou systémy opět online. Fáze po incidentu je pravděpodobně nejdůležitější pro budování dlouhodobé odolnosti. Zahrnuje dvě klíčové činnosti: sběr důkazů a přezkum získaných poznatků.
Politika zdůrazňuje význam sběru důkazů v kapitole 5.5, kde uvádí, že „musí být vytvořeny a dodržovány postupy pro sběr, získávání a uchovávání důkazů souvisejících s incidenty informační bezpečnosti“. To je zásadní pro interní vyšetřování, dotazy orgánů činných v trestním řízení a případné právní kroky.
Následně musí proběhnout formální přezkoumání po incidentu. Tohoto jednání se musí účastnit všichni členové IRT a klíčové zainteresované strany a musí projednat:
- Co se stalo a jaká byla časová osa událostí?
- Co v reakci fungovalo dobře?
- Jaké překážky se objevily?
- Co lze udělat, aby se podobnému incidentu v budoucnu předešlo?
Výstupem tohoto přezkumu musí být akční plán s přiřazenými vlastníky a termíny pro zlepšení politik, postupů a technických opatření. Tím vzniká zpětná vazba, která v čase posiluje bezpečnostní stav organizace.
Propojení souvislostí: poznatky ke křížovému souladu
Splnění požadavků ISO 27001 na řízení incidentů neposiluje jen bezpečnost; poskytuje pevný základ pro soulad s rostoucí sítí mezinárodních a odvětvových předpisů. Mnoho těchto rámců sdílí stejné základní principy přípravy, reakce a hlášení.
Jak vysvětluje Zenith Controls, náš komplexní průvodce křížovým souladem, robustní proces řízení incidentů je základním pilířem digitální odolnosti. Podívejme se, jak přístup podle ISO 27001 odpovídá dalším významným rámcům.
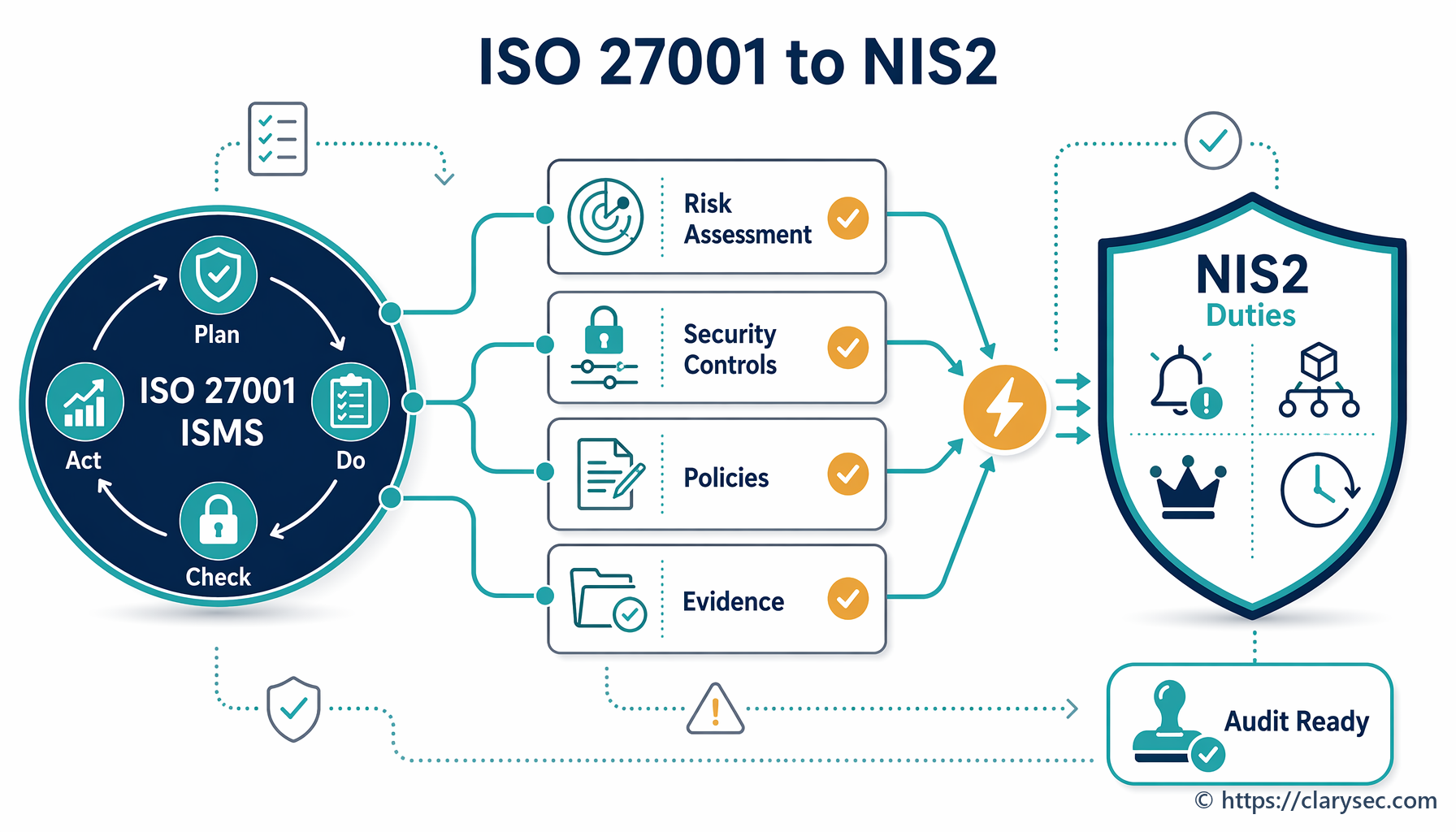
Opatření ISO/IEC 27002:2022: Nejnovější verze normy ISO/IEC 27002 poskytuje podrobné pokyny k řízení incidentů prostřednictvím specializované sady opatření:
- A.5.24 – Plánování a příprava řízení incidentů informační bezpečnosti: Stanoví potřebu definovaného a dokumentovaného přístupu.
- A.5.25 – Posouzení a rozhodnutí o událostech informační bezpečnosti: Zajišťuje řádné vyhodnocení událostí s cílem určit, zda jde o incidenty.
- A.5.26 – Reakce na incidenty informační bezpečnosti: Pokrývá činnosti zamezení šíření, eradikace a obnovy.
- A.5.27 – Hlášení incidentů informační bezpečnosti: Definuje, jak a kdy jsou incidenty hlášeny vedení a dalším zainteresovaným stranám.
- A.5.28 – Poučení z incidentů informační bezpečnosti: Vyžaduje proces neustálého zlepšování.
Tato opatření tvoří úplný životní cyklus, který se promítá i do dalších významných předpisů.
Směrnice NIS2: Pro provozovatele základních služeb, včetně mnoha výrobců, ukládá NIS2 přísné bezpečnostní a oznamovací povinnosti týkající se incidentů. Zenith Controls upozorňuje na přímý překryv:
„Article 21 směrnice NIS2 vyžaduje, aby základní a významné subjekty zavedly vhodná a přiměřená technická, provozní a organizační opatření k řízení rizik pro bezpečnost sítí a informačních systémů. To výslovně zahrnuje politiky a postupy pro zvládání incidentů. Article 23 dále stanoví vícefázový proces oznamování incidentů, který vyžaduje včasné varování do 24 hodin a podrobnou zprávu do 72 hodin příslušným orgánům (CSIRT).“
Plán reakce na incidenty sladěný s ISO 27001 poskytuje přesně ty mechanismy, které jsou nutné ke splnění těchto krátkých oznamovacích lhůt.
Nařízení o digitální provozní odolnosti (DORA): Ačkoli se DORA zaměřuje na finanční sektor, její principy odolnosti se stávají měřítkem pro všechna odvětví. Průvodce zdůrazňuje tuto souvislost:
„Article 17 DORA vyžaduje, aby finanční subjekty měly komplexní proces řízení incidentů souvisejících s ICT pro detekci, řízení a oznamování incidentů souvisejících s ICT. Article 19 vyžaduje klasifikaci incidentů podle kritérií podrobně stanovených v nařízení a hlášení závažných incidentů příslušným orgánům prostřednictvím harmonizovaných šablon. To odpovídá požadavkům na klasifikaci a hlášení obsaženým v ISO 27001.“
Obecné nařízení o ochraně osobních údajů (GDPR): U jakéhokoli incidentu zahrnujícího osobní údaje jsou požadavky GDPR zásadní. Rychlá a strukturovaná reakce není volitelná. Jak vysvětluje Zenith Controls:
„Podle GDPR vyžaduje Article 33, aby správci údajů oznámili dozorovému úřadu porušení zabezpečení osobních údajů bez zbytečného odkladu a pokud možno nejpozději do 72 hodin poté, co se o něm dozvěděli. Article 34 ukládá oznámení porušení subjektu údajů, pokud je pravděpodobné, že povede k vysokému riziku pro jeho práva a svobody. Účinný plán reakce na incidenty je nezbytný pro shromáždění informací potřebných k přesnému a včasnému provedení těchto oznámení.“
Tím, že svůj program reakce na incidenty postavíte na základech ISO 27001, současně budujete schopnosti potřebné k zvládnutí komplexních požadavků těchto vzájemně propojených předpisů.
Příprava na prověrku: na co se budou auditoři ptát
Plán reakce na incidenty, který nebyl nikdy otestován ani přezkoumán, je pouze dokument. Auditoři to vědí a během certifikačního auditu ISO 27001 budou podrobně ověřovat, že váš program je živou a funkční součástí ISMS.
Podle Zenith Blueprint, našeho plánu pro auditora, je hodnocení reakce na incidenty kritickým krokem v procesu auditu. Během „Fáze 3: práce v terénu a sběr důkazů“ budou auditoři systematicky testovat vaši připravenost.
Níže je uvedeno, co můžete očekávat, že si vyžádají, na základě kroku 21 Zenith Blueprint, „Vyhodnocení reakce na incidenty a kontinuity činností“:
„Ukažte mi svůj plán a politiku reakce na incidenty.“ Auditoři začnou dokumentací. Posoudí úplnost politiky, ověří definované role a odpovědnosti, klasifikační kritéria, komunikační plány a postupy pro každou fázi životního cyklu incidentu. Ověří, že byla formálně schválena a komunikována relevantním pracovníkům.
„Ukažte mi záznamy z vašich posledních tří bezpečnostních incidentů.“ Zde se ukáže provozní realita. Auditoři potřebují vidět důkazy, že se plán skutečně dodržuje. Budou očekávat logy incidentů nebo tikety, které dokumentují:
- Datum a čas detekce.
- Popis incidentu.
- Přiřazenou prioritu nebo úroveň klasifikace.
- Log kroků provedených pro zamezení šíření, eradikaci a obnovu.
- Datum a čas vyřešení.
„Ukažte mi zápis a akční plán z vašeho posledního přezkoumání po incidentu.“ Jak zdůrazňuje Zenith Blueprint, neustálé zlepšování je nezbytné.
„Během auditu budeme požadovat objektivní důkazy, že přezkoumání po incidentu probíhají systematicky. To zahrnuje kontrolu zápisů z jednání, logů opatření a důkazů, že identifikovaná zlepšení byla implementována, například aktualizované postupy nebo nová technická opatření. Bez této zpětné vazby nelze ISMS považovat za systém, který se ‚neustále zlepšuje‘, jak vyžaduje norma.“
„Ukažte mi důkazy, že jste svůj plán otestovali.“ Auditoři chtějí vidět, že své schopnosti testujete proaktivně a nečekáte pouze na skutečný incident. Tyto důkazy mohou mít mnoho podob, od tabletop cvičení s vedením až po technické simulace v plném rozsahu. Budou chtít vidět zprávu z těchto testů, která popisuje scénář, účastníky, výsledky a získané poznatky.
Připravenost s těmito důkazy prokazuje, že váš program reakce na incidenty není jen formální dokument, ale robustní, provozní a účinná součást vašeho ISMS.
Časté chyby, kterým se vyhnout
I s dobře dokumentovaným plánem mnoho organizací při skutečném incidentu selže. Níže jsou uvedeny nejčastější chyby, na které je třeba si dát pozor:
- Syndrom „plánu v šuplíku“: Nejčastějším selháním je dokonale napsaný plán, který nikdo nečetl, nepochopil ani neprocvičil. Pravidelné školení a testování jsou jedinou účinnou prevencí.
- Nejasná pravomoc: Během krize je nejednoznačnost nepřítelem. Pokud IRT nemá předem schválenou pravomoc k rozhodným krokům, například k odstavení kritického výrobního systému, reakce se ochromí nerozhodností, zatímco škody se šíří.
- Špatná komunikace: Nezvládnutá komunikace je receptem na katastrofu. Zahrnuje neinformování vedení, poskytování nejasných sdělení zaměstnancům nebo nesprávnou komunikaci se zákazníky a regulačními orgány. Předem schválený komunikační plán se šablonami je nezbytný.
- Opomenutí uchování důkazů: Ve snaze rychle obnovit službu může technický tým neúmyslně zničit klíčové forenzní důkazy. To může znemožnit určení kořenové příčiny, zabránění opakování nebo podporu právních kroků.
- Neschopnost poučit se: Považovat incident za „uzavřený“ ve chvíli, kdy je systém opět online, znamená promarněnou příležitost. Bez důsledné analýzy po incidentu je organizace odsouzena k opakování stejných chyb.
Další kroky
Přechod od teorie k praxi je nejkritičtějším krokem. Robustní program reakce na incidenty je cesta neustálého zlepšování, nikoli cílový stav. Začít můžete takto:
- Formalizujte svůj přístup: Pokud nemáte formální politiku reakce na incidenty, nyní je čas ji vytvořit. Použijte naši P16S Politiku plánování a přípravy řízení incidentů informační bezpečnosti – SME jako šablonu pro vybudování komplexního rámce.
- Porozumějte svému prostředí souladu: Namapujte své postupy reakce na incidenty na konkrétní požadavky předpisů, jako jsou NIS2, DORA a GDPR. Náš průvodce Zenith Controls poskytuje křížové odkazy, které potřebujete k zajištění úplného pokrytí.
- Připravte se na audit: Využijte pohled auditora k zátěžovému ověření svého programu. Zenith Blueprint vám poskytne interní pohled na to, co budou auditoři požadovat, abyste mohli shromáždit důkazy a byli připraveni doložit účinnost.
Závěr
Pro moderního výrobce není reakce na incidenty informační bezpečnosti otázkou IT; jde o základní funkci kontinuity činností. Rozdíl mezi menším narušením a katastrofálním selháním spočívá v přípravě, procvičování a závazku ke strukturovanému, opakovatelnému procesu.
Tím, že svůj program opřete o celosvětově uznávaný rámec ISO 27001, nebudujete pouze obrannou schopnost, ale odolnou organizaci. Vytváříte systém, který dokáže ustát dopad incidentu, řídit krizi kontrolovaně a přesně a vyjít z ní silnější a bezpečnější. Čas na přípravu je nyní, dříve než se výstraha ve 2:17 ráno stane vaší realitou.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council