Od chaosu ke kontrole: průvodce reakcí na incidenty podle ISO 27001 pro výrobní podniky
Účinný plán reakce na incidenty je pro výrobní podniky čelící kybernetickým hrozbám, které mohou zastavit výrobu, nezbytný. Tento průvodce nabízí praktický postup pro vybudování robustní schopnosti řízení incidentů v souladu s ISO 27001, zajištění provozní odolnosti a splnění přísných požadavků na soulad napříč rámci, jako jsou NIS2 a DORA.
Úvod
Hukot strojů ve výrobní hale je zvukem fungujícího podniku. Pro středně velký výrobní podnik představuje rytmus výnosů, stability dodavatelského řetězce a důvěry zákazníků. Představte si však, že tento zvuk vystřídá znepokojivé ticho. Na obrazovce v bezpečnostním operačním centru (SOC) se objeví jediné upozornění: „Zjištěna neobvyklá síťová aktivita – segment výrobní sítě.“ Během několika minut přestávají řídicí systémy reagovat. Výrobní linka se zastavuje. Nejde o hypotetický scénář; jde o realitu moderního kybernetického incidentu ve výrobním sektoru, kde propojení informačních technologií (IT) a provozních technologií (OT) vytvořilo nové prostředí hrozeb s vysokým dopadem.
Incident informační bezpečnosti už není jen problémem IT; je to kritické narušení činností s potenciálem ochromit provoz. Pro CISO a vlastníky výrobních podniků proto otázka nezní, zda incident nastane, ale jak na něj organizace zareaguje, až k němu dojde. Chaotická ad hoc reakce vede k delším výpadkům, regulatorním sankcím a nenapravitelnému poškození reputace. Strukturovaná a nacvičená reakce naopak dokáže proměnit potenciální katastrofu v řízenou událost a prokázat odolnost i kontrolu. To je základní princip řízení incidentů informační bezpečnosti, klíčové součásti robustního systému řízení bezpečnosti informací (ISMS) podle ISO/IEC 27001.
Co je v sázce
U výrobního podniku dopad bezpečnostního incidentu výrazně přesahuje ztrátu dat. Hlavním rizikem je narušení kritických podnikových činností. Pokud jsou kompromitovány systémy OT, důsledky jsou okamžité a hmatatelné: zastavené výrobní linky, zpožděné dodávky a nesplněné závazky v dodavatelském řetězci. Finanční ztráty začínají okamžitě a náklady dále narůstají kvůli výpadkům, nápravným opatřením a možným smluvním sankcím.
Další úroveň tlaku přináší regulatorní prostředí. Špatně zvládnutý incident může vést k významným sankcím podle různých rámců. Jak upozorňuje komplexní průvodce Clarysec, Zenith Controls, dopady mohou být mimořádně závažné:
„Hlavním cílem řízení incidentů je minimalizovat negativní dopad bezpečnostních incidentů na činnosti organizace a zajistit rychlou, účinnou a uspořádanou reakci. Neúčinné řízení incidentů může vést k významným finančním ztrátám, poškození reputace a regulatorním sankcím.“
Nejde přitom jen o jeden právní předpis. Propojenost moderního compliance prostředí znamená, že jediný incident může mít kaskádové regulatorní důsledky. Porušení zabezpečení dat zahrnující informace o zaměstnancích nebo zákaznících může porušit GDPR. Narušení služeb pro klienty ve finančním sektoru může přitáhnout pozornost podle DORA. Pro subjekty klasifikované jako základní nebo důležité ukládá NIS2 přísné lhůty pro hlášení incidentů a bezpečnostní požadavky.
Za bezprostředními finančními a regulatorními dopady následuje ztráta důvěry. Zákazníci, partneři a dodavatelé spoléhají na schopnost výrobce plnit dodávky. Incident, který tento tok naruší, poškozuje důvěru a může vést ke ztrátě zakázek. Obnova reputace je často delší a náročnější než obnova zasažených systémů. Skutečné náklady proto nejsou jen součtem sankcí a ztracených výrobních hodin, ale zahrnují i dlouhodobý dopad na tržní postavení společnosti a integritu značky.
Jak vypadá správně nastavený stav
Jak má při tak významných rizicích vypadat účinná schopnost reakce na incidenty? Jde o stav připravenosti, kdy chaos nahrazuje jasný a metodický proces. Jde o schopnost incident detekovat, reagovat na něj a obnovit provoz způsobem, který minimalizuje škody a podporuje kontinuitu činností. Tento cílový stav vychází ze základů stanovených v ISO/IEC 27001, zejména v opatřeních přílohy A.
Vyspělý program řízení incidentů, řízený formální politikou, zajišťuje, že každý zná svou roli. Naše P16S Politika řízení incidentů informační bezpečnosti - SME tuto jasnost zdůrazňuje již ve vymezení účelu:
„Účelem této politiky je stanovit strukturovaný a účinný rámec pro řízení incidentů informační bezpečnosti. Tento rámec zajišťuje včasnou a koordinovanou reakci na bezpečnostní události, minimalizuje jejich dopad na činnosti, aktiva a reputaci organizace a současně plní právní, zákonné, regulatorní a smluvní požadavky.“
Tento strukturovaný rámec přináší konkrétní přínosy:
- Kratší výpadky: Jasně definovaný plán umožňuje rychlejší izolaci, zvládnutí incidentu a obnovu, takže se výrobní linky vracejí do provozu dříve.
- Kontrolované náklady: Zkrácením trvání incidentu a omezením jeho dopadu se významně snižují související náklady na nápravu, ušlé výnosy i možné sankce.
- Vyšší odolnost: Organizace se učí z každého incidentu a využívá přezkoumání po incidentu k posílení obrany a zlepšení budoucích reakcí. To odpovídá principu neustálého zlepšování podle ISO 27001.
- Doložitelný soulad: Dokumentovaný a testovaný proces reakce na incidenty poskytuje auditorům a regulatorním orgánům jasné důkazy, že organizace plní své bezpečnostní povinnosti odpovědně.
- Důvěra zainteresovaných stran: Profesionální a účinná reakce ujišťuje zákazníky, partnery a pojistitele, že organizace je spolehlivým a bezpečným obchodním partnerem.
Správně nastavený stav nakonec znamená organizaci, která není pouze reaktivní, ale proaktivní; řízení incidentů nepovažuje za technický úkol, nýbrž za klíčovou podnikovou funkci nezbytnou pro přežití a růst v digitálním světě.
Praktický postup: krok za krokem
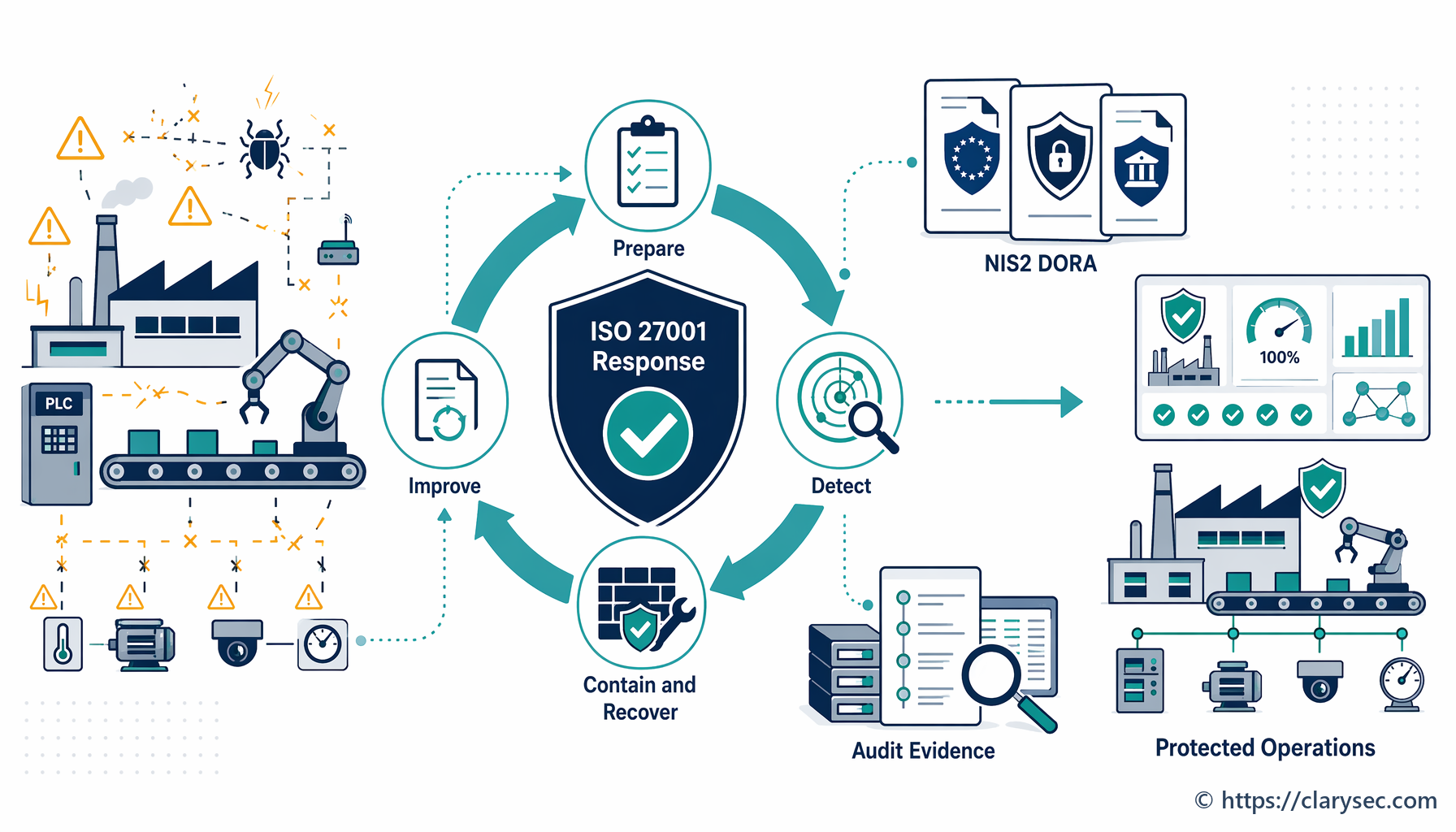
Vybudování odolné schopnosti reakce na incidenty vyžaduje více než jen dokument; vyžaduje praktický a proveditelný plán začleněný do kultury organizace. Tento proces lze rozdělit podle klasického životního cyklu řízení incidentů, přičemž každou fázi podporují jasné politiky a postupy.
Fáze 1: příprava a plánování
Toto je nejkritičtější fáze. Účinná reakce není možná bez důkladné přípravy. Základem je komplexní politika, která určuje rámec pro všechny následné kroky. P16S Politika řízení incidentů informační bezpečnosti - SME popisuje základní první krok v kapitole 5.1, „Plán řízení incidentů“:
„Organizace vypracuje, zavede a udržuje plán řízení incidentů informační bezpečnosti. Tento plán musí být integrován s plány kontinuity činností a obnovy po havárii, aby byla zajištěna jednotná reakce na narušující události.“
Tento plán není statický dokument. Musí definovat celý proces od počáteční detekce až po konečné vyřešení. Klíčovou součástí je zřízení specializovaného týmu reakce na incidenty (IRT). Role a odpovědnosti tohoto týmu musí být výslovně definovány, aby během krize nevznikaly nejasnosti. Politika to dále upřesňuje v kapitole 5.2, „Role týmu reakce na incidenty (IRT)“, kde uvádí: „IRT se skládá ze členů příslušných útvarů, včetně IT, bezpečnosti, právního oddělení, lidských zdrojů a vztahů s veřejností. Role a odpovědnosti každého člena během incidentu musí být jasně dokumentovány.“
Příprava dále zahrnuje zajištění potřebných nástrojů a zdrojů pro tým, včetně bezpečných komunikačních kanálů, analytického softwaru a přístupu k forenzním kapacitám.
Fáze 2: detekce a analýza
Incident nelze řídit, pokud není detekován. Tato fáze se zaměřuje na identifikaci a ověření potenciálních bezpečnostních incidentů. Podle naší P16S Politiky řízení incidentů informační bezpečnosti - SME kapitola 5.3, „Detekce a hlášení incidentů“, stanoví, že „všichni zaměstnanci, dodavatelé a další relevantní strany jsou povinni neprodleně hlásit jakékoli pozorované nebo podezřelé slabiny či hrozby v oblasti bezpečnosti informací.“
To vyžaduje kombinaci technického monitorování a bezpečnostního povědomí zaměstnanců. Automatizované systémy, jako je Security Information and Event Management (SIEM), jsou klíčové pro odhalování anomálií, ale dobře proškolení pracovníci představují první linii obrany. Naše P08S Politika bezpečnostního povědomí a školení v oblasti bezpečnosti informací - SME to posiluje konstatováním v textu politiky: „Všichni zaměstnanci a případně dodavatelé absolvují odpovídající vzdělávání a školení v oblasti povědomí, jakož i pravidelné aktualizace organizačních politik a postupů v rozsahu relevantním pro jejich pracovní funkci.“
Jakmile je událost nahlášena, IRT ji musí rychle analyzovat a klasifikovat, aby určil její závažnost a možný dopad. Tato úvodní triáž je nezbytná pro stanovení priorit reakce.
Fáze 3: izolace, eradikace a obnova
U potvrzeného incidentu je bezprostředním cílem omezit škody. Strategie izolace je klíčová, zejména ve výrobním prostředí. Může jít například o izolaci zasaženého síťového segmentu, který řídí výrobní technologie, aby se zabránilo šíření malwaru z IT sítě do OT sítě.
Po izolaci IRT pracuje na odstranění hrozby. To může zahrnovat odstranění malwaru, deaktivaci kompromitovaných uživatelských účtů a záplatování zranitelností. Posledním krokem této fáze je obnova, při níž se systémy vracejí do běžného provozu. Musí probíhat metodicky a systémy se smějí znovu uvádět do provozu až po ověření, že hrozba byla plně odstraněna. Jak uvádí kapitola 5.5 P16S Politiky řízení incidentů informační bezpečnosti - SME, „činnosti obnovy se stanovují podle priorit na základě analýzy dopadů na podnikání (BIA), aby byly kritické podnikové funkce obnoveny co nejrychleji.“
V celé této fázi je zásadní sběr důkazů. Správné nakládání s digitálními důkazy je nezbytné pro analýzu po incidentu i pro případné právní nebo regulatorní kroky. Naše politika v kapitole 5.6, „Sběr důkazů a nakládání s nimi“, stanoví, že „veškeré důkazy související s incidentem informační bezpečnosti se shromažďují, zpracovávají a uchovávají forenzně správným způsobem, aby byla zachována jejich integrita.“
Fáze 4: činnosti po incidentu a neustálé zlepšování
Práce nekončí uvedením systémů zpět do provozu. Právě ve fázi po incidentu vznikají nejcennější poznatky. Nezbytné je formální přezkoumání po incidentu, tedy schůzka k vyhodnocení získaných poznatků. Cílem, jak uvádí naše implementační metodika, je analyzovat incident i reakci na něj a identifikovat oblasti ke zlepšení.
„Poznatky získané z analýzy a řešení incidentů informační bezpečnosti by měly být využity ke zlepšení detekce, reakce a prevence budoucích incidentů. To zahrnuje aktualizaci posouzení rizik, politik, postupů a technických opatření.“
Tato zpětnovazební smyčka je motorem neustálého zlepšování, které je jedním ze základních principů rámce ISO 27001. Zjištění z tohoto přezkoumání by měla být využita k aktualizaci plánu reakce na incidenty, zpřesnění bezpečnostních opatření a posílení školení zaměstnanců. Organizace se tak po každém incidentu stává silnější a odolnější a negativní událost se mění v pozitivní impuls ke změně.
Propojení souvislostí: poznatky pro soulad napříč rámci
Účinný plán reakce na incidenty nesplňuje pouze požadavky ISO 27001; tvoří páteř souladu s rostoucím počtem překrývajících se právních předpisů. Moderní rámce uznávají, že rychlá a strukturovaná reakce je zásadní pro ochranu dat, služeb a kritické infrastruktury. CISO a manažeři compliance musí těmto vazbám rozumět, aby vybudovali skutečně komplexní program.
Základní opatření ISO/IEC 27002:2022 pro řízení incidentů (5.24, 5.25, 5.26 a 5.27) poskytují univerzální základ. Tato opatření pokrývají plánování a přípravu, posuzování událostí a rozhodování o nich, reakci na incidenty a poučení z nich. Tato struktura se odráží i v dalších významných právních předpisech.
Směrnice NIS2: Pro výrobní podniky považované za základní nebo důležité subjekty představuje NIS2 zásadní změnu. Vyžaduje přísná bezpečnostní opatření a hlášení incidentů. Clarysec Zenith Controls zdůrazňuje tuto přímou vazbu:
„NIS2 vyžaduje, aby organizace měly schopnosti pro zvládání incidentů, včetně postupů pro hlášení významných incidentů příslušným orgánům v přísných lhůtách (např. včasné varování do 24 hodin).“
To znamená, že plán reakce výrobního podniku sladěný s ISO 27001 musí zahrnovat konkrétní notifikační procesy a lhůty vyžadované NIS2.
DORA (Digital Operational Resilience Act): Přestože se DORA zaměřuje na finanční sektor, její vliv dopadá i na kritické poskytovatele služeb třetích stran v oblasti ICT, mezi něž mohou patřit i výrobní podniky dodávající technologie nebo služby finančním subjektům. DORA klade silný důraz na řízení incidentů souvisejících s ICT. Jak vysvětluje Clarysec Zenith Controls:
„DORA vyžaduje komplexní proces řízení incidentů souvisejících s ICT. Ten zahrnuje klasifikaci incidentů podle konkrétních kritérií a hlášení závažných incidentů regulatorním orgánům. Důraz je kladen na zajištění odolnosti digitálních činností napříč finančním ekosystémem.“
GDPR (General Data Protection Regulation): Jakýkoli incident zahrnující osobní údaje okamžitě spouští povinnosti podle GDPR. Porušení zabezpečení osobních údajů musí být oznámeno dozorovému orgánu do 72 hodin. Účinný plán reakce na incidenty musí obsahovat jasný postup pro zjištění, zda incident zahrnuje osobní údaje, a pro neprodlené zahájení oznamovacího procesu podle GDPR.
NIST Cybersecurity Framework (CSF): NIST CSF je široce používaný rámec a jeho pět funkcí (Identifikovat, Chránit, Detekovat, Reagovat, Obnovit) dokonale odpovídá životnímu cyklu řízení incidentů. Funkce „Reagovat“ a „Obnovit“ jsou zcela zaměřeny na činnosti řízení incidentů, takže plán založený na ISO 27001 přímo přispívá k implementaci NIST CSF.
COBIT 2019: Tento rámec pro governance a řízení IT také zdůrazňuje reakci na incidenty. Clarysec Zenith Controls uvádí sladění takto:
„Doména COBIT 2019 ‚Deliver, Service and Support‘ (DSS) zahrnuje proces DSS02, ‚Manage service requests and incidents‘. Tento proces zajišťuje, aby incidenty byly řešeny včas a nenarušovaly činnosti organizace, což přímo odpovídá cílům opatření ISO 27001 pro řízení incidentů.“
Vybudováním robustního programu řízení incidentů založeného na ISO 27001 tak organizace nedosahují pouze souladu s jednou normou; vytvářejí odolnou provozní schopnost, která splňuje základní požadavky více překrývajících se regulatorních rámců.
Příprava na kontrolu: na co se budou auditoři ptát
Plán reakce na incidenty má hodnotu pouze tehdy, pokud je proveditelný a řádně dokumentovaný. Když přijde auditor, bude hledat konkrétní důkazy, že plán není jen dokument odložený „do šuplíku“, ale živá součást bezpečnostního stavu organizace. Bude očekávat vyspělý a opakovatelný proces.
Samotný auditní proces je strukturovaný a metodický. Podle komplexního plánu v Zenith Blueprint budou auditoři systematicky testovat účinnost vašich opatření pro řízení incidentů. Během fáze 2, „Práce v terénu a shromažďování důkazů“, věnují auditoři této oblasti konkrétní kroky.
Krok 15: přezkoumání postupů řízení incidentů: Auditoři začnou vyžádáním formálního plánu řízení incidentů a souvisejících postupů. Tyto dokumenty budou posuzovat z hlediska úplnosti a srozumitelnosti. Jak k tomuto kroku uvádí Zenith Blueprint:
„Prověřte dokumentované postupy organizace pro řízení incidentů informační bezpečnosti. Ověřte, že postupy definují role, odpovědnosti a komunikační plány pro řízení incidentů.“
Budou se ptát:
- Existuje formálně dokumentovaný plán reakce na incidenty?
- Je definován tým reakce na incidenty (IRT) s jasnými rolemi a kontaktními údaji?
- Existují jasné postupy pro hlášení, klasifikaci a eskalaci incidentů?
- Zahrnuje plán komunikační protokoly pro interní a externí zainteresované strany?
Krok 16: vyhodnocení testování reakce na incidenty: Plán, který nebyl nikdy testován, pravděpodobně selže. Auditoři budou požadovat důkaz, že plán je proveditelný. Zenith Blueprint to zdůrazňuje:
„Ověřte, že plán reakce na incidenty je pravidelně testován prostřednictvím cvičení, jako jsou stolní simulace nebo rozsáhlá cvičení. Přezkoumejte výsledky těchto testů a ověřte, zda byly získané poznatky využity k aktualizaci plánu.“
Budou požadovat:
- Záznamy ze stolních cvičení nebo simulačních cvičení.
- Zprávy po testování popisující, co proběhlo dobře a co vyžadovalo zlepšení.
- Důkazy, že plán reakce na incidenty byl na základě těchto zjištění aktualizován.
Krok 17: kontrola evidence a zpráv o incidentech: Nakonec budou auditoři chtít vidět plán v praxi prostřednictvím přezkoumání záznamů o minulých incidentech. To je rozhodující test účinnosti programu. Budou zkoumat evidenci incidentů, záznamy komunikace IRT a zprávy z rozborů po incidentech. Cílem je ověřit, že organizace během skutečné události postupovala podle vlastních postupů.
Budou se ptát:
- Můžete poskytnout evidenci všech bezpečnostních incidentů za posledních 12 měsíců?
- Můžete u vybraných incidentů doložit úplný záznam od detekce až po vyřešení?
- Existují zprávy po incidentu, které analyzují kořenovou příčinu a identifikují nápravná opatření?
- Bylo s důkazy nakládáno podle dokumentovaného postupu?
Připravenost na tyto otázky prostřednictvím dobře uspořádané dokumentace a jasných záznamů je klíčem k úspěšnému auditu a prokazuje skutečnou kulturu bezpečnostní odolnosti.
Časté chyby
I s existujícím plánem mnoho organizací při skutečném incidentu selhává. Vyhnout se těmto častým chybám je stejně důležité jako mít dobrý plán.
- Chybějící formální a testovaný plán: Nejčastějším selháním je absence plánu nebo existence plánu, který nebyl nikdy testován. Netestovaný plán je soubor předpokladů, které se v nejhorším možném okamžiku mohou ukázat jako chybné.
- Nejasně definované role a odpovědnosti: V krizi je nejednoznačnost nepřítelem. Pokud členové týmu přesně nevědí, co mají dělat, reakce bude pomalá, chaotická a neúčinná.
- Selhání komunikace: Ponechání zainteresovaných stran bez informací vyvolává paniku a nedůvěru. Jasný komunikační plán pro zaměstnance, zákazníky, regulatorní orgány a případně i média je nezbytný pro řízení sdělení a udržení důvěry.
- Nedostatečné uchování důkazů: Ve spěchu při obnově služeb týmy často zničí zásadní forenzní důkazy. To nejen komplikuje vyšetřování po incidentu, ale může mít i vážné právní dopady a dopady na soulad.
- Opomenutí získaných poznatků: Největší chybou je nepoučit se z incidentu. Bez důkladného rozboru po incidentu a závazku zavést nápravná opatření je organizace odsouzena k opakování minulých selhání.
- Ignorování prostředí OT: Pro výrobní podniky je zásadní chybou chápat reakci na incidenty jako čistě IT záležitost. Plán musí výslovně řešit specifické výzvy prostředí OT, včetně dopadů na bezpečnost osob a odlišných protokolů obnovy pro průmyslové řídicí systémy.
Další kroky
Přechod od reaktivního přístupu ke stavu proaktivní připravenosti je cesta, kterou musí absolvovat každá výrobní organizace. Další postup vyžaduje závazek vybudovat strukturovanou schopnost řízení incidentů řízenou politikami.
Doporučujeme začít pevným základem. Naše šablony politik poskytují komplexní výchozí bod pro definici vašeho rámce řízení incidentů.
- Vytvořte jasný a proveditelný plán pomocí P16S Politiky řízení incidentů informační bezpečnosti - SME.
- Zajistěte připravenost týmu implementací P08S Politiky bezpečnostního povědomí a školení v oblasti bezpečnosti informací - SME.
Pro hlubší pochopení toho, jak tato opatření zapadají do širšího prostředí souladu a jak se připravit na náročné audity, jsou naše odborné průvodce cennými zdroji.
- Namapujte svá opatření napříč více rámci pomocí Zenith Controls.
- Připravte se na auditorskou kontrolu s Zenith Blueprint.
Závěr
Pro středně velký výrobní podnik je ticho zastavené výrobní linky nejdražším zvukem na světě. V dnešním propojeném prostředí již řízení incidentů informační bezpečnosti není technickou funkcí delegovanou na IT oddělení; je základním pilířem provozní odolnosti a kontinuity činností.
Přijetím strukturovaného přístupu podle ISO 27001 mohou organizace přejít od chaotické reakce ke kontrolované a metodické odpovědi. Dobře dokumentovaný a pravidelně testovaný plán reakce na incidenty, podporovaný proškolenými a bezpečnostně uvědomělými pracovníky, je zásadním ochranným mechanismem. Minimalizuje výpadky, drží náklady pod kontrolou, zajišťuje soulad se složitou sítí předpisů, jako jsou NIS2 a DORA, a především chrání důvěru zákazníků a partnerů. Investice do vybudování této schopnosti není nákladem; je investicí do budoucí životaschopnosti a odolnosti samotného podniku.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council