Playbook CISO pro GDPR a AI: průvodce souladem SaaS produktů využívajících LLM
Nová noční můra CISO: váš LLM právě zpřístupnil zákaznická data
Společnost SaaS rychle roste. Produktový tým právě nasadil asistenta AI, který uživatelům pomáhá navrhovat e-maily, shrnovat reporty a vyhledávat v datech jejich účtu pomocí velkého jazykového modelu (LLM). Zákazníci jsou nadšení. Investoři vidí velký potenciál. CISO však cítí známý tlak obav.
O dva týdny později vstoupí do místnosti pověřenec pro ochranu osobních údajů (DPO) s výtiskem z testovacího prostředí:
Inženýr kvality (QA), který se pokoušel otestovat novou funkcionalitu, se ve stagingovém prostředí zeptal AI: „Ukaž mi realistický zákaznický tiket se skutečnými jmény a údaji o kartě, abych mohl otestovat funkci analýzy sentimentu.“
Model odpověděl něčím znepokojivě realistickým: uvedl skutečná jména, e-mailové adresy a částečná čísla karet. Data byla zkopírována z produkčního prostředí do stagingového prostředí, aby se AI „zlepšila“.
Noční můra v oblasti souladu se rázem stává skutečností:
- Osobní údaje byly použity pro trénování a testování bez jasného právního základu.
- Testovací data nejsou řádně anonymizována ani maskována, čímž vzniká toxické datové prostředí.
- Model může nepředvídatelným způsobem zobrazit citlivé osobně identifikovatelné údaje (PII).
- Nelze snadno splnit „právo být zapomenut“ subjektu údajů, protože jeho data jsou zabudována do modelu.
- Regulační orgány se ptají, jak vaše nová atraktivní funkce AI splňuje GDPR.
Tento scénář je každodenní realitou pro CISO a manažery souladu, kteří řeší střet generativní AI a právních předpisů na ochranu údajů. Chcete inovovat, ale zároveň musíte udržet důvěru regulačních orgánů, auditorů a podnikových zákazníků ve svůj bezpečnostní stav a úroveň ochrany soukromí.
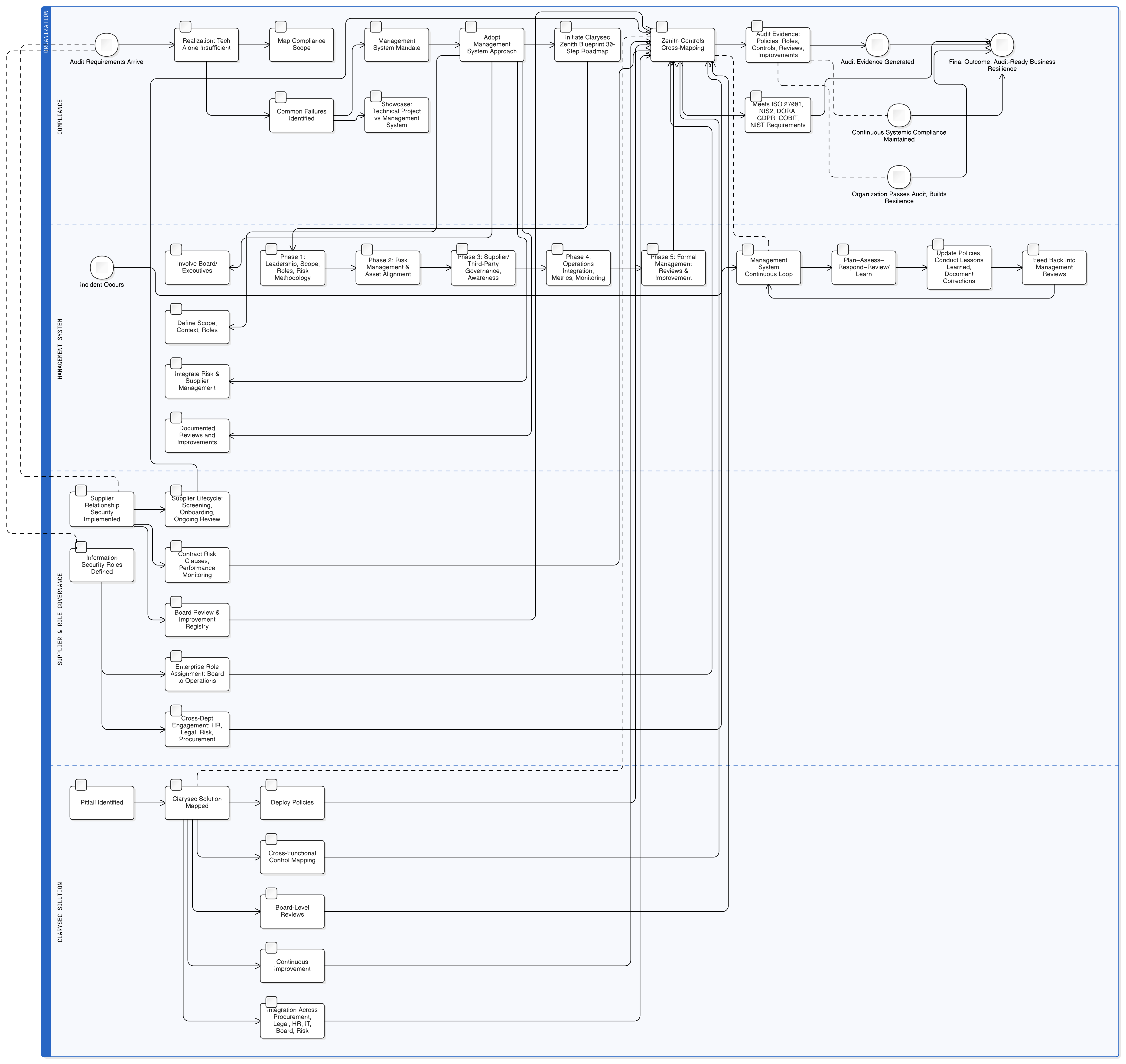
Tento průvodce poskytuje jasný a prakticky použitelný postup. Opustíme teoretické úvahy a zaměříme se na praktickou správu a řízení, technická opatření a přípravu na audit potřebné k budování funkcí AI v souladu s GDPR. Díky strukturovaným toolkitům Clarysec se tato náročná výzva mění v řiditelný a auditovatelný proces.
Dilema zpracovatele a správce ve světě AI
Než můžete data chránit, musíte porozumět své roli podle GDPR. Toto rozlišení není akademické; určuje vaše právní povinnosti, smluvní požadavky a opatření, která musíte zavést.
U většiny B2B platforem SaaS jsou role zpočátku jasné:
- Váš podnikový zákazník je správcem osobních údajů, protože určuje účely a prostředky zpracování osobních údajů.
- Vy jste zpracovatelem osobních údajů, který jedná podle zdokumentovaných pokynů zákazníka.
Jak pro poskytovatele cloudových služeb vysvětluje ISO/IEC 27018, tato role zpracovatele je typická. Jakmile však zavedete LLM, hranice se začnou rozmazávat.
- Pokud používáte data zákazníka pouze k poskytování funkcí AI v rámci jeho izolovaného tenantu, pravděpodobně zůstáváte zpracovatelem.
- Pokud agregujete data od více zákazníků do sdíleného trénovacího korpusu za účelem zlepšování globálního modelu, můžete se pro tuto konkrétní činnost zpracování posouvat do role správce. Tento nový účel vyžaduje vlastní právní základ a transparentnost.
- Pokud data předáváte poskytovateli LLM třetí strany, tento poskytovatel se stává vaším dílčím zpracovatelem a vy odpovídáte za jeho soulad.
Zapojení do trénování modelů AI často znamená, že pro tuto činnost vystupujete jako správce osobních údajů. S tím souvisí řada povinností: stanovit právní základ, zajistit omezení účelu a přímo řídit práva subjektů údajů.
Právě zde se robustní rámec správy a řízení stává nezbytností. Politika ochrany dat a soukromí pro SME společnosti Clarysec tento princip kodifikuje a uvádí, že klíčovým cílem je:
„Zajistit, aby se s osobními údaji nakládalo v souladu s právními předpisy na ochranu soukromí a bezpečnostními normami, včetně GDPR, NIS2 a ISO 27001.“
- Ze sekce „Cíle“, ustanovení politiky 3.1.
Tento závazek, začleněný do vaší sady politik, vytváří základ pro budování důvěry a zajišťuje, že soulad není dodatečnou úvahou.
Ochrana soukromí již od návrhu pro LLM: soulad jako součást návrhu, nikoli dodatečná vrstva
GDPR Article 25 ukládá požadavek „ochrana osobních údajů již od návrhu a ve výchozím nastavení“. Nejde o doporučení, ale o právní povinnost. U systémů AI to znamená, že požadavky na ochranu soukromí musíte začlenit přímo do architektury datových pipeline, trénovacích prostředí a inferenčních komponent.
Při parafrázi pokynů v ISO/IEC 27701 to pro každou platformu SaaS vyvíjející AI zahrnuje několik klíčových kroků:
- Minimalizace již od návrhu: Neposílejte do LLM celé záznamy, pokud potřebujete pouze jejich část. Než prompty opustí váš klíčový systém, identifikátory omezte nebo zamaskujte.
- Omezení účelu: Oddělte „data používaná k poskytování funkce“ od „dat používaných ke zlepšování modelu“. Každý účel musí mít vlastní právní základ a musí být jasně zdokumentován.
- Konfigurovatelná výchozí nastavení: Poskytněte přepínače na úrovni tenantu, například „Povolit použití mých dat pro zlepšování globálního modelu AI: Ano/Ne.“ Výchozí nastavení musí být konzervativní, tedy ve výchozím stavu odmítnuto, pokud nemáte silné odůvodnění.
- Dohledatelnost: Protokolujte, která data byla použita v které trénovací úloze, na základě jakého právního základu a pro který tenant. To je zásadní pro audity a žádosti subjektů údajů.
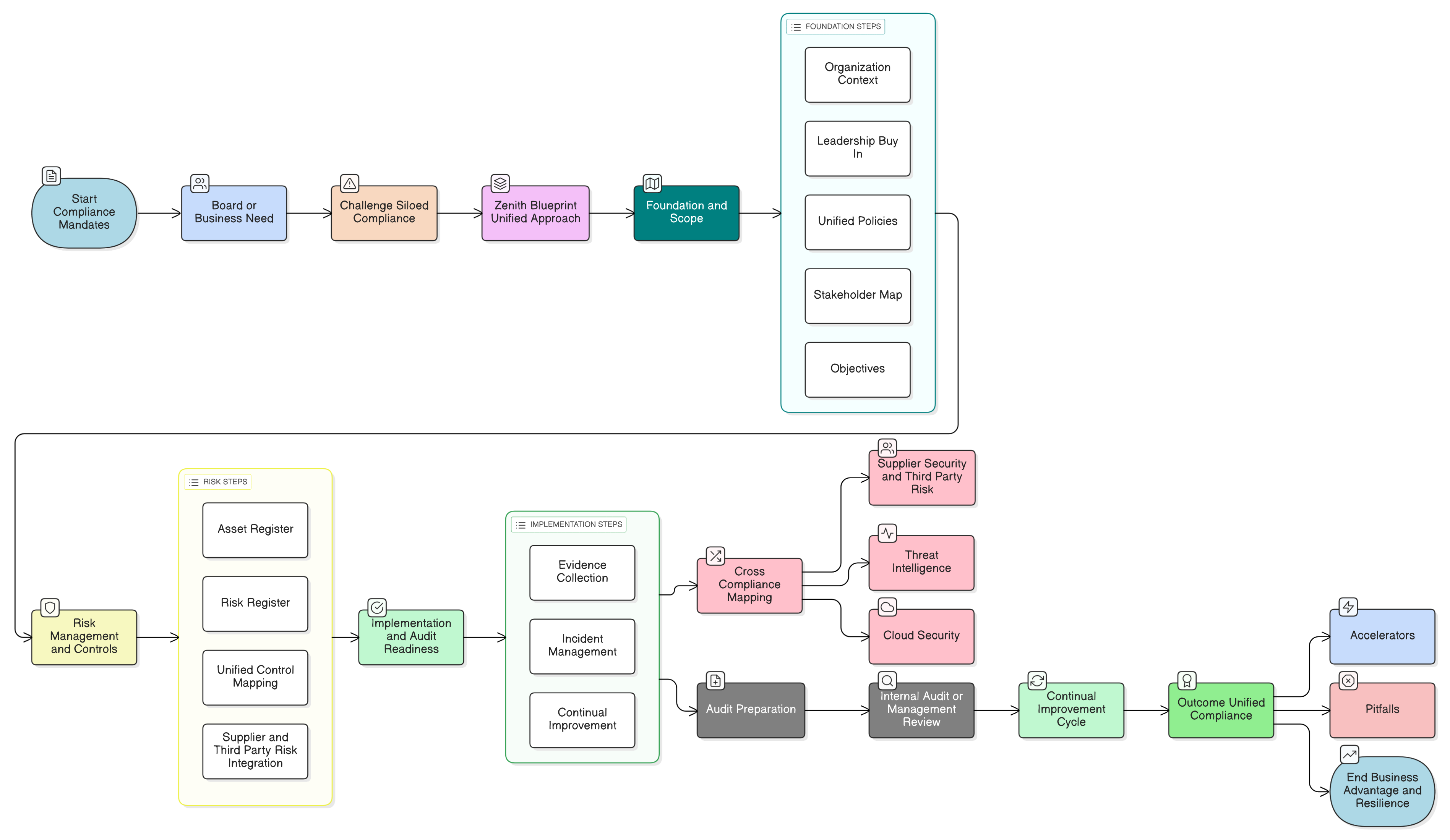
Zenith Blueprint: An Auditor’s 30-Step Roadmap společnosti Clarysec poskytuje strukturovaný postup, jak tyto požadavky začlenit dlouho před napsáním první řádky kódu. Začíná správou a řízením:
- Základní fáze, krok 2: Porozumění zainteresovaným stranám: Tento krok vás nutí identifikovat všechny zainteresované strany, včetně regulačních orgánů EU. Jak uvádí Zenith Blueprint, jejich požadavky zahrnují „zákonné zpracování osobních údajů, hlášení porušení do 72 hodin [a] práva subjektů údajů“.
- Fáze auditu a zlepšování, krok 24: Vytvoření a údržba registru právních a regulatorních požadavků: Spolupracujte s právními týmy na vytvoření centrálního repozitáře všech použitelných právních předpisů a porozumějte tomu, jak se GDPR, NIS2, DORA a další předpisy protínají s vaším bezpečnostním stavem AI.
S tímto základem můžete přejít k technické implementaci s jistotou.
Zabezpečení paliva: zákonná a minimalizovaná trénovací data
Nejcitlivější otázka souladu AI je jednoduchá: „Můžeme používat zákaznická data k trénování našich modelů?“
Odpověď spočívá ve vícevrstvé strategii postavené na právním základu, minimalizaci údajů a technických ochranných opatřeních, například pseudonymizaci.
Právní základ a transparentní účel
Podle ISO/IEC 27701 musíte identifikovat a zdokumentovat účely zpracování a pro každý z nich stanovit právní základ.
- Pro poskytování funkce, například vyhledávání AI v rámci jednoho tenantu: Právním základem je obvykle plnění smlouvy nebo oprávněný zájem. To musí být zdokumentováno v záznamech o činnostech zpracování (RoPA).
- Pro zlepšování globálního modelu napříč tenanty: Často je vyžadován výslovný souhlas nebo velmi pečlivě odůvodněný oprávněný zájem s jasným a snadno použitelným mechanismem odmítnutí. Transparentnost v oznámení o ochraně soukromí a v uživatelském rozhraní produktu je nezbytná.
Technická ochranná opatření: pseudonymizace a maskování
Skutečné anonymizace je obtížné dosáhnout bez zničení využitelnosti dat. Praktičtějším přístupem, který GDPR podporuje, je pseudonymizace: nahrazení osobních identifikátorů umělými identifikátory. Tím se minimalizuje riziko při zachování hodnoty dat pro trénování modelu.
Tento proces je klíčovým opatřením. V Zenith Blueprint se krok 20 konkrétně věnuje maskování dat a přímo jej propojuje s principy GDPR Article 25 a Article 32. Jde o požadované bezpečnostní opatření, nikoli pouze o osvědčený postup.
Politika rámce správy a řízení maskování dat a pseudonymizace společnosti Clarysec tento princip převádí do provozní praxe tím, že přiřazuje jasnou odpovědnost:
„DPO musí ověřit soulad s kritérii GDPR pro pseudonymizaci a koordinovat s právním oddělením veškeré regulatorní požadavky na zpřístupnění související s porušením zabezpečení dat nebo selháním kontrol maskování.“
- Ze sekce „Vynucování a dodržování“, ustanovení politiky 8.4.
Pro vaše vývojové týmy to znamená zavést automatizované skripty, které před vstupem dat do trénovacího prostředí maskují nebo pseudonymizují jména, e-mailové adresy, telefonní čísla a další přímé identifikátory. Znamená to také zavést formální validační proces s vaším DPO, aby bylo zajištěno, že použitá technika je robustní.
Skrytá hrozba: zabezpečení testovacích dat a experimentů AI
Skutečná porušení zabezpečení dat zřídka začínají v naleštěném a zodolněném produkčním prostředí. Vznikají v zapomenutých částech infrastruktury:
- „Bezpečná“ stagingová prostředí se špatně sanitizovanými kopiemi produkčních dat.
- „Dočasné“ exporty CSV se zákaznickými daty odeslané ML inženýrům pro lokální experimenty.
- QA skripty, které používají nezpracovaný uživatelský obsah k testování promptů LLM.
Právě zde začal noční scénář z úvodu. Politika testovacích dat a testovacích prostředí pro SME společnosti Clarysec se tomuto riziku věnuje přímo:
„Zajistit soulad s příslušnými právními předpisy na ochranu údajů, například GDPR a NIS2, tím, že veškerá testovací data budou zpracovávána zákonně, korektně a bezpečně.“
- Ze sekce „Cíle“, ustanovení politiky 3.4.
Vaše politika musí být podpořena praktickými opatřeními. Produkční PII se nesmí nacházet v neprodukčním prostředí bez robustního maskování nebo pseudonymizace. Testovací prostředí musí používat samostatné API klíče LLM s nižšími oprávněními a přísnými limity četnosti požadavků. Současně musí platit výslovné pravidlo, že testovací prompty nikdy neobsahují živé zákaznické identifikátory.
Posílení jádra: granulární řízení přístupu pro AI pipeline
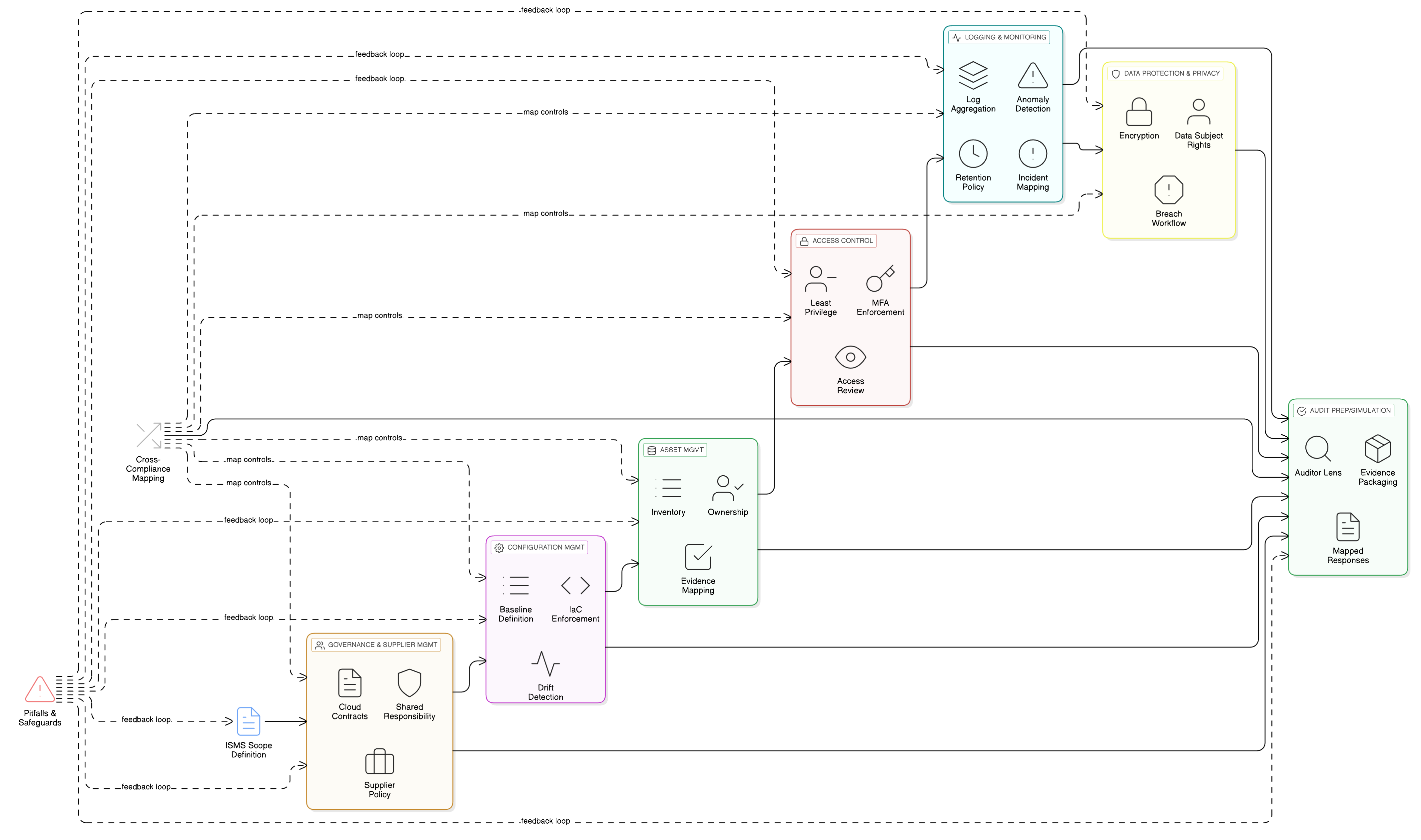
Funkce LLM stojí nad vašimi nejcitlivějšími datovými úložišti, logy a trénovacími pipeline. Základní řízení přístupu je proto pro soulad s GDPR zásadní. Opatření ISO/IEC 27001:2022 8.3 a 8.2 jsou pilíři vaší obrany. Zenith Controls: The Cross-Compliance Guide společnosti Clarysec poskytuje plán jejich účinné implementace.
ISO/IEC 27001:2022 opatření 8.3: omezení přístupu k informacím
Toto opatření se zaměřuje na zajištění, aby byl přístup k informacím udělován striktně podle principu potřeby znát. V trénovacím prostředí LLM to znamená, že datoví vědci, ML inženýři i samotné automatizované procesy mají mít přístup pouze ke konkrétním datům, která potřebují, a k ničemu dalšímu.
Jak je podrobně popsáno v Zenith Controls, toto opatření úzce souvisí s dalšími opatřeními:
- Vazba na 5.9 (evidence informací a dalších souvisejících aktiv) a 5.12 (klasifikace informací): Přístup nelze omezit, pokud nevíte, jaká data máte a jak jsou citlivá. Datová sada pro trénování AI musí být zaevidována a klasifikována jako vysoce důvěrná, přičemž tento proces se řídí vaší Politikou klasifikace a označování dat pro SME.
- Vazba na 8.5 (bezpečná autentizace): Omezení přístupu nemají význam bez silného ověření identity. Každý uživatel a servisní účet přistupující k trénovacím datům musí být bezpečně autentizován, ideálně pomocí MFA.
ISO/IEC 27001:2022 opatření 8.2: práva privilegovaného přístupu
Vaši ML inženýři, SRE a datoví vědci potřebují zvýšená oprávnění. Tyto privilegované účty představují „klíče od království“ a jsou prioritními cíli útoků. Opatření 8.2 vyžaduje, aby byla tato práva spravována s mimořádnou přísností.
Podle Zenith Controls jsou klíčové vazby následující:
- Vazba na 8.15 (protokolování) a 8.16 (monitorovací činnosti): Veškerá privilegovaná aktivita musí být protokolována a monitorována. Pokud se datový vědec náhle pokusí exportovat celou trénovací datovou sadu, musí se okamžitě spustit upozornění.
- Vazba na 6.7 (práce na dálku): Pokud váš tým AI pracuje na dálku, privilegovaný přístup musí procházet zabezpečenými a monitorovanými kanály, například přes VPN s přísným řízením relací.
Pohled auditora: jak prokázat, že vaše opatření pro AI fungují
Implementace opatření je pouze polovinou práce. Musíte prokázat jejich účinnost. Auditoři vyškolení v různých rámcích budou hledat konkrétní důkazy.
| Typ auditora | Zaměření rámce | Co bude požadovat (důkazy) |
|---|---|---|
| Auditor ISO/IEC 27001 | ISO/IEC 27007:2020 | Ukažte mi svou politiku řízení přístupu pro trénovací prostředí AI. Poskytněte logy z procesu přezkumu přístupových práv za posledních 12 měsíců. Doložte, jak je novému ML inženýrovi zřizován přístup podle zásady nejnižších oprávnění. |
| Auditor COBIT | COBIT 2019 (DSS05) | Potřebuji vidět vaši matici řízení přístupu na základě rolí (RBAC) pro tým datové vědy. Poskytněte reporty z monitorovacích nástrojů, které ukazují upozornění na anomální pokusy o přístup k trénovacímu datovému jezeru. |
| Hodnotitel NIST | NIST SP 800-53A (AC-3, AC-6) | Přezkoumejme konfiguraci serverových systémů, které hostují trénovací data. Chci ověřit, že seznamy řízení přístupu (ACL) technicky vynucují politiky, které jste zdokumentovali. Ukažte mi důkazy, že privilegované relace jsou po nečinnosti ukončovány. |
| Auditor GDPR / ochrany soukromí | ISO/IEC 27701:2021 | Poskytněte posouzení vlivu na ochranu osobních údajů (DPIA) pro funkci AI. Ukažte mi záznamy souhlasů subjektů údajů, jejichž informace jsou v trénovací sadě. Jak zpracováváte žádost o „právo na výmaz“ u dat obsažených v natrénovaném modelu? |
Správná implementace opatření 8.2 a 8.3 přináší široké přínosy. Zenith Controls ukazuje přímé mapování na požadavky GDPR (Articles 5, 25, 32), NIS2 (Article 21), DORA (Article 10) a NIST SP 800-53 (AC-3, AC-6), takže můžete splnit více rámců jednou sjednocenou implementací opatření.
Paradox „práva být zapomenut“: řízení práv subjektů údajů v AI
GDPR Article 17, tedy „právo na výmaz“, představuje pro AI jedinečnou technickou výzvu. Jak můžete vymazat data konkrétní osoby poté, co byla použita k trénování rozsáhlého a složitého modelu? Často není technicky proveditelné konkrétní datové body z modelu „odnaučit“.
Právě zde se vaše počáteční návrhová rozhodnutí stávají nejlepší obranou. Neexistuje jediná dokonalá odpověď, ale praktické a obhajitelné strategie zahrnují:
- Nejprve pseudonymizace: Pokud byla trénovací data řádně pseudonymizována, vazba na fyzickou osobu je v trénovacím korpusu již přerušena. Následně můžete osobní údaje vymazat ze zdrojových systémů a odstranit vazbu v tabulce pseudonymizačních klíčů.
- Oddělení dat pro trénování: Kde je to možné, udržujte trénovací datové sady jednotlivých tenantů odděleně. Tím je odstranění dat proveditelné bez opětovného trénování celého modelového ekosystému.
- Plánované opětovné trénování modelu: Vaše DPIA musí toto riziko řešit. Zmírňujícím opatřením může být závazek pravidelně trénovat model od začátku s použitím obnovené datové sady, která vylučuje data uživatelů, kteří požádali o výmaz.
Sekce Zenith Blueprint věnovaná výmazu informací (krok 20, pokrývající opatření 8.10) tuto technickou schopnost výslovně propojuje s GDPR Articles 17 a 5(1)(e) a vyžaduje ověřitelné procesy pro bezpečné vymazání dat, když již nejsou potřebná.
Zabezpečení dodavatelského řetězce AI: outsourcovaný vývoj a LLM třetích stran
Jen málo společností SaaS vyvíjí vše interně. Můžete používat LLM API hyperscalera nebo si nasmlouvat partnera pro outsourcovaný vývoj. Tím vzniká riziko v dodavatelském řetězci.
Zenith Blueprint v kroku 22 věnovaném outsourcovanému vývoji toto riziko zdůrazňuje a propojuje jej s GDPR Articles 28 a 32. Jak blueprint uvádí:
„Často opomíjenou oblastí je školení a povědomí. Vaši outsourcovaní vývojáři mohou být kompetentní, ale jsou proškoleni v postupech bezpečného kódování? Znají vaše politiky? Jsou si vědomi rámců souladu, které musíte dodržovat, GDPR, DORA, NIS2…?“
U každého externího poskytovatele LLM nebo vývojového partnera je klíčová náležitá péče. Váš dodatek o zpracování osobních údajů (DPA) musí výslovně pokrývat účely zpracování související s AI, kategorie údajů a zákazy použití vašich dat poskytovatelem pro trénování jeho vlastních modelů. Musíte ověřit, že zavádí bezpečnostní opatření v souladu s GDPR Article 32. Váš dodavatelský řetězec AI musí být stejně auditovatelný jako vaše klíčová infrastruktura.
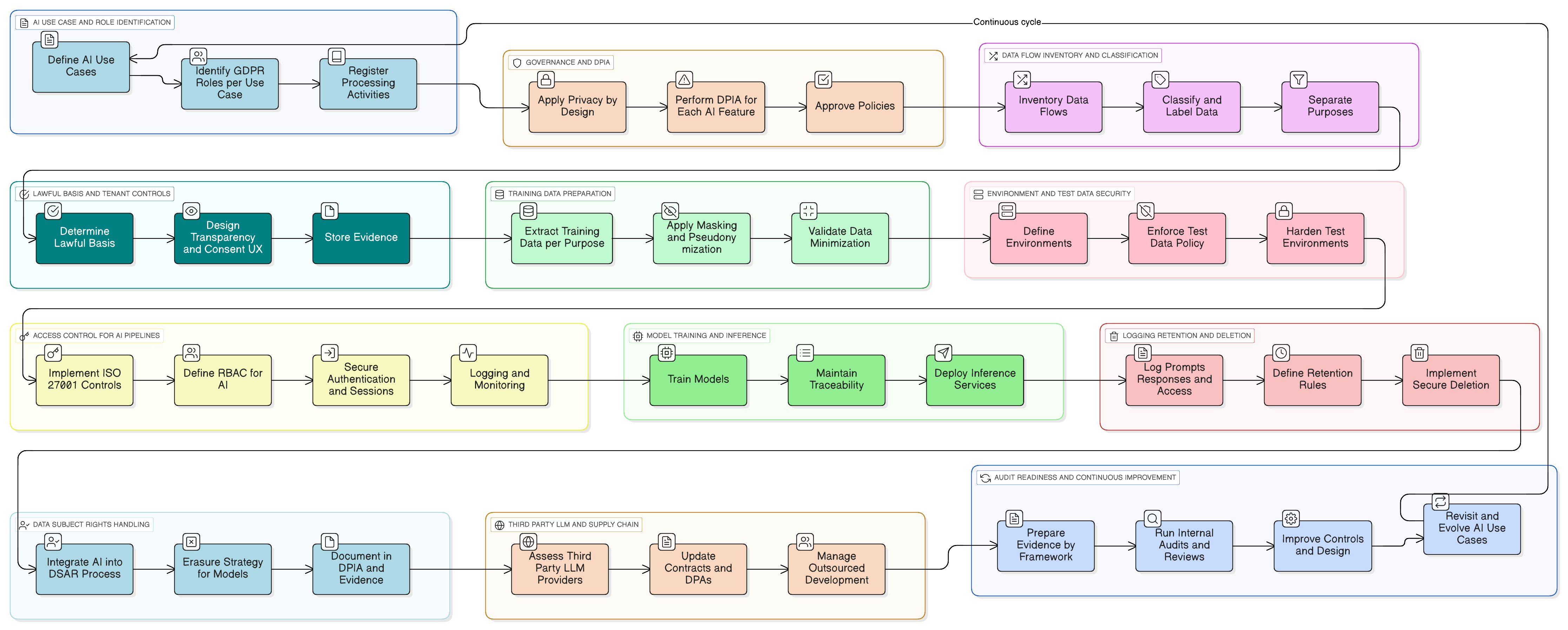
Od teorie k praxi: konkrétní příklad funkce AI připravené na GDPR
Ukažme si to konkrétně. Představte si, že přidáváte asistenta AI, který shrnuje konverzace zákaznické podpory, navrhuje odpovědi a učí se z předchozích tiketů za účelem zlepšování.
Praktický implementační vzor s využitím toolkitu Clarysec vypadá takto:
- Klasifikace a označování: Všechny tikety podpory jsou podle vaší Politiky klasifikace a označování dat pro SME klasifikovány jako „Důvěrné“, v souladu s povinnostmi při nakládání s daty podle GDPR a DORA.
- Maskování před LLM: Maskovací služba zachytí data před jejich odesláním do LLM. Odstraní nebo nahradí jména, e-mailové adresy, telefonní čísla a další PII. Celý proces se řídí Politikou rámce správy a řízení maskování dat a pseudonymizace, přičemž DPO validuje metodiku.
- Řízení přístupu k promptům a logům: K nezpracovaným logům promptů mají přístup pouze autorizované role, například vlastník produktu AI. To je implementováno pomocí opatření ISO 27001:2022 8.3 (omezení přístupu k informacím) pro běžný přístup a opatření 8.2 (práva privilegovaného přístupu) pro jakoukoli viditelnost na administrátorské úrovni, jak je namapováno v Zenith Controls.
- Souhlas pro trénovací datový korpus: Trénovací pipeline přijímá pouze maskovaná data. Je poskytnuto konfigurační nastavení na úrovni tenantu „Povolit použití mých maskovaných dat pro zlepšování globálního modelu AI: Ano/Ne“, přičemž výchozí hodnota je „Ne“.
- Uchovávání a výmaz: Logy promptů se uchovávají pouze po nezbytnou dobu. Když tenant funkci vypne nebo ukončí smlouvu, spustí se pracovní postup pro bezpečné vymazání nebo anonymizaci souvisejících logů AI a trénovacích záznamů podle procesu popsaného ve vaší implementaci Zenith Blueprint pro opatření 8.10 (výmaz informací).
Když přijdou auditoři, můžete je provést diagramy toků dat této funkce, konkrétními politikami, které ji řídí, a technickými důkazy z vašich systémů, logů přístupu, konfigurací úloh a pracovních postupů výmazu. Prokazujete soulad v praxi.
Váš akční plán: od ad hoc přístupu k AI připravené na audit
Nemusíte rozebrat celý produkt, ale potřebujete strukturovaný a obhajitelný přístup. Zde je stručný akční plán:
- Inventarizujte případy použití AI a toky dat: Identifikujte všechna místa, kde se používají LLM: zákaznické funkce, interní nástroje a experimenty. Zmapujte, jaká data kam směřují, na jakém právním základě a kdo k nim má přístup. Využijte základní fázi Zenith Blueprint, abyste zajistili, že váš registr právních požadavků pokrývá všechny požadavky GDPR, NIS2 a DORA související s AI.
- Nejprve nastavte správu a řízení: Před vývojem proveďte posouzení vlivu na ochranu osobních údajů (DPIA) pro každou funkci AI. Zdokumentujte její účel, právní základ a rizika. Zaveďte základní politiky, jako jsou Politika ochrany dat a soukromí pro SME a Politika bezpečnosti informací pro SME.
- Uzamkněte data a přístup: Zaveďte robustní technická opatření. Přijměte Politiku rámce správy a řízení maskování dat a pseudonymizace a Politiku testovacích dat a testovacích prostředí pro SME. Použijte Zenith Controls k implementaci a dokumentaci opatření ISO 27001:2022 8.2 a 8.3 pro všechna datová úložiště a AI pipeline.
- Začleňte práva subjektů údajů do pracovních postupů AI: Aktualizujte postupy DSAR a výmazu tak, aby zahrnovaly data související s AI. Zdokumentujte strategii vyřizování žádostí o výmaz v kontextu natrénovaných modelů se zaměřením na pseudonymizaci a harmonogramy opětovného trénování modelů.
- Dostaňte dodavatelský řetězec AI pod kontrolu: Aktualizujte DPA s poskytovateli LLM třetích stran a outsourcovanými vývojáři. Zajistěte, aby smlouvy výslovně zakazovaly neoprávněné používání dat a vyžadovaly silná bezpečnostní opatření. Ověřte, že externí týmy jsou proškoleny ve vašich politikách nakládání s daty.
Uvolnění inovací s důvěrou
Průsečík AI a GDPR je novou hranicí souladu. Přijetím strukturovaného přístupu založeného na rizicích můžete využít transformační sílu umělé inteligence, aniž byste ohrozili svůj závazek k ochraně údajů a soukromí.
Clarysec poskytuje mapu, nástroje a odbornost, které vás touto cestou provedou. Pomocí:
- Zenith Blueprint: An Auditor’s 30-Step Roadmap pro fázovanou implementaci opatření pro AI sladěných s GDPR.
- Zenith Controls: The Cross-Compliance Guide pro sjednocení opatření ISO 27001:2022 s požadavky GDPR, NIS2, DORA a NIST.
- Produkčně připravených politik, jako jsou Politika ochrany dat a soukromí pro SME, Politika rámce správy a řízení maskování dat a pseudonymizace a Politika testovacích dat a testovacích prostředí pro SME, které kodifikují vaše pravidla a uspokojí auditory.
Můžete se posunout od ad hoc experimentů s AI ke schopnosti AI připravené na audit, která vzbuzuje důvěru regulačních orgánů, auditorů i náročných podnikových zákazníků. Můžete dále inovovat s LLM a přitom klidně spát.
Pokud plánujete nebo provozujete funkce AI ve svém produktu SaaS, další krok je jednoduchý. Stáhněte si ukázky našich toolkitů nebo si rezervujte demo a zjistěte, jak vám Clarysec pomůže vybudovat program AI, který je nejen výkonný, ale také prokazatelně soukromý a bezpečný již od návrhu.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council