Anatomi af et sikkerhedsbrud: en produktionsvirksomheds guide til hændelseshåndtering efter ISO 27001
Fremhævet uddrag
Effektiv håndtering af informationssikkerhedshændelser minimerer skader fra sikkerhedsbrud og sikrer driftsmæssig robusthed. Denne guide giver et trin-for-trin-rammeværk baseret på ISO 27001, der hjælper produktionsvirksomheder med at forberede sig på, reagere på og komme sig efter reelle cyberangreb, samtidig med at komplekse compliancekrav som NIS2 og DORA opfyldes.
Indledning
Alarmen blinker kl. 02:17. Den centrale server hos en mellemstor producent af bildele svarer ikke, og monitorerne på produktionslinjerne viser en ransomware-meddelelse. Hvert minuts nedetid koster tusindvis i tabt produktion og indebærer risiko for brud på stramme SLA’er i forsyningskæden. Dette er ikke en øvelse. For informationssikkerhedschefen er det øjeblikket, hvor års planlægning, politikarbejde og træning står sin ultimative prøve.
At have en hændelseshåndteringsplan liggende på en server er én ting; at gennemføre den under ekstremt pres er noget helt andet. For produktionsvirksomheder er indsatsen usædvanligt høj. En cyberhændelse kompromitterer ikke kun data; den stopper produktionen, forstyrrer fysiske forsyningskæder og kan bringe medarbejdernes sikkerhed i fare.
Denne guide går videre end teoretiske playbooks og giver en praktisk, realistisk køreplan for at opbygge og styre et hændelseshåndteringsprogram, der virker. Vi gennemgår anatomien i responsen på et sikkerhedsbrud med afsæt i det robuste rammeværk i ISO/IEC 27001 og viser, hvordan du opbygger et modstandsdygtigt program, der ikke blot genopretter driften efter et angreb, men også tilfredsstiller revisorer og tilsynsmyndigheder.
Hvad er på spil: ringvirkningerne af et sikkerhedsbrud i en produktionsvirksomhed
Når en produktionsvirksomheds systemer kompromitteres, rækker konsekvenserne langt ud over en enkelt server. Den sammenkoblede karakter af moderne produktion, fra lagerstyring til robotstyrede samlebånd, betyder, at et digitalt svigt kan føre til fuldstændigt driftsstop. Konsekvenserne er alvorlige og sammensatte.
For det første er det økonomiske tab øjeblikkeligt og markant. Produktionsstop fører til overskredne deadlines, bodsklausuler fra kunder og omkostninger til en inaktiv arbejdsstyrke. Genopretning af systemer, betaling for eksterne efterforskningseksperter og eventuel håndtering af løsepengekrav kan lamme økonomien i en mellemstor virksomhed.
For det andet kan omdømmeskaden være langvarig. I et B2B-miljø er leveringssikkerhed afgørende. Én større hændelse kan ødelægge tilliden hos centrale partnere, der er afhængige af just-in-time-leverancer. Som vores interne vejledning fremhæver, er et centralt mål med hændelsesstyring at “minimere den forretningsmæssige og økonomiske påvirkning af hændelser og genetablere normal drift så hurtigt som muligt” — et mål, der er helt centralt i produktion.
Endelig kan den regulatoriske reaktion ramme hårdt. Med rammeværker som EU’s NIS2-direktiv og DORA, der træder fuldt i kraft, står organisationer i kritiske sektorer som produktion over for skærpede krav til rapportering af hændelser og risiko for betydelige bøder ved manglende efterlevelse. En dårligt håndteret hændelse er ikke kun et teknisk svigt; den udgør en væsentlig juridisk risiko og compliancerisiko.
Hvordan god praksis ser ud: fra kaos til kontrol
Et effektivt hændelseshåndteringsprogram omsætter en krise fra en kaotisk, reaktiv indsats til en struktureret og kontrolleret proces. Målet er ikke kun at løse det tekniske problem, men at styre hele hændelsen for at beskytte forretningen. Denne ønskede tilstand bygger på principperne i ISO/IEC 27001-rammeværket, særligt kontrollerne for styring af informationssikkerhedshændelser.
Et modent program kendetegnes ved flere centrale resultater:
- Klare roller: Alle ved, hvem de skal kontakte, og hvad deres ansvar er. Hændelseshåndteringsteamet (IRT) er defineret på forhånd med tydelig ledelse og udpegede eksperter fra IT, jura, kommunikation og ledelse.
- Hastighed og præcision: Organisationen kan hurtigt detektere, analysere og inddæmme trusler, så de ikke spreder sig i netværket og standser hele produktionsgulvet.
- Kvalificeret beslutningstagning: Ledelsen modtager rettidige og præcise oplysninger, så den kan træffe kritiske beslutninger om drift, kundekommunikation og regulatorisk underretning.
- Løbende forbedring: Enhver hændelse, stor eller lille, bliver en læringsmulighed. En grundig proces for efterhændelsesgennemgang identificerer svagheder og omsætter dem til forbedringer i sikkerhedsprogrammet.
At opnå denne beredskabstilstand er det centrale formål med de kontroller, der er beskrevet i ISO/IEC 27002:2022. Disse kontroller vejleder organisationer i planlægning og forberedelse (A.5.24), vurdering af og beslutning om hændelser (A.5.25), respons på hændelser (A.5.26) og læring af dem (A.5.28). Det handler om at opbygge et robust system, der forudser svigt og er struktureret til at håndtere dem kontrolleret.
Den praktiske vej: en trin-for-trin-guide til håndtering af sikkerhedshændelser
Opbygning af en robust hændelseshåndteringsevne kræver en dokumenteret og systematisk tilgang. Fundamentet er en klar og handlingsorienteret politik, der beskriver hver fase i processen.
Vores P16S Politik for planlægning og forberedelse af styring af informationssikkerhedshændelser - SME giver en omfattende skabelon, der er tilpasset god praksis i ISO 27001. Lad os gennemgå de kritiske trin med denne politik som guide.
Trin 1: planlægning og forberedelse – fundamentet for robusthed
Man kan ikke udarbejde en responsplan midt i en krise. Forberedelse er afgørende. Denne fase handler om at etablere den struktur, de værktøjer og den viden, der er nødvendig for at handle beslutsomt, når en hændelse opstår.
En central komponent er etableringen af et hændelseshåndteringsteam (IRT). Som angivet i afsnit 5.1 i P16S Politik for planlægning og forberedelse af styring af informationssikkerhedshændelser - SME er politikkens formål at “sikre en ensartet og effektiv tilgang til styring af informationssikkerhedshændelser”. Denne ensartethed starter med et veldefineret team. Politikken kræver, at IRT omfatter medlemmer fra centrale funktioner:
- IT og informationssikkerhed
- Jura og compliance
- HR
- Presse og kommunikation
- Øverste ledelse
Hvert medlem skal have klart definerede roller og ansvarsområder. Hvem har beføjelse til at tage systemer offline? Hvem er den udpegede talsperson over for kunder eller medier? Disse spørgsmål skal besvares og dokumenteres længe før en hændelse.
Trin 2: detektion og rapportering – dit tidlige varslingssystem
Jo hurtigere du får kendskab til en hændelse, desto mindre skade kan den forvolde. Det kræver både teknisk overvågning og en kultur, hvor medarbejdere føler sig bemyndiget og forpligtet til at rapportere mistænkelig aktivitet.
P16S Politik for planlægning og forberedelse af styring af informationssikkerhedshændelser - SME er tydelig på dette punkt. Afsnit 5.3, “Rapportering af informationssikkerhedshændelser”, fastsætter:
“Alle medarbejdere, kontrahenter og andre relevante parter skal hurtigst muligt rapportere alle observerede eller formodede informationssikkerhedshændelser og svagheder til det udpegede kontaktpunkt.”
Dette “udpegede kontaktpunkt” er kritisk. Det kan være IT-servicedesken eller en særskilt sikkerhedshotline. Processen skal være enkel og tydeligt kommunikeret til alle medarbejdere. Medarbejdere skal trænes i, hvad de skal være opmærksomme på, f.eks. phishing-e-mails, usædvanlig systemadfærd eller brud på fysisk sikring.
Trin 3: vurdering og triage – vurder truslens omfang
Når en hændelse er rapporteret, er næste trin hurtigt at vurdere dens karakter og alvorlighed. Er det en falsk alarm, et mindre problem eller en fuldt udviklet krise? Denne triageproces bestemmer det nødvendige responsniveau.
Vores politik beskriver en klar klassificeringsmodel i afsnit 5.2, “Hændelsesklassificering”, der kategoriserer hændelser ud fra deres påvirkning af fortrolighed, integritet og tilgængelighed. En typisk model kan se sådan ud:
- Lav: En enkelt arbejdsstation inficeret med udbredt malware, som let kan inddæmmes.
- Middel: En afdelingsserver er utilgængelig og påvirker en specifik forretningsfunktion, men standser ikke den samlede produktion.
- Høj: Et omfattende ransomware-angreb, der påvirker kritiske produktionssystemer og centrale forretningsdata.
- Kritisk: En hændelse, der involverer et brud på persondatasikkerheden vedrørende følsomme personoplysninger eller immaterielle rettigheder, med betydelige juridiske og omdømmemæssige konsekvenser.
Denne klassificering styrer hastighed, ressourceallokering og eskalationsvej til ledelsen og sikrer, at responsen står mål med truslen.
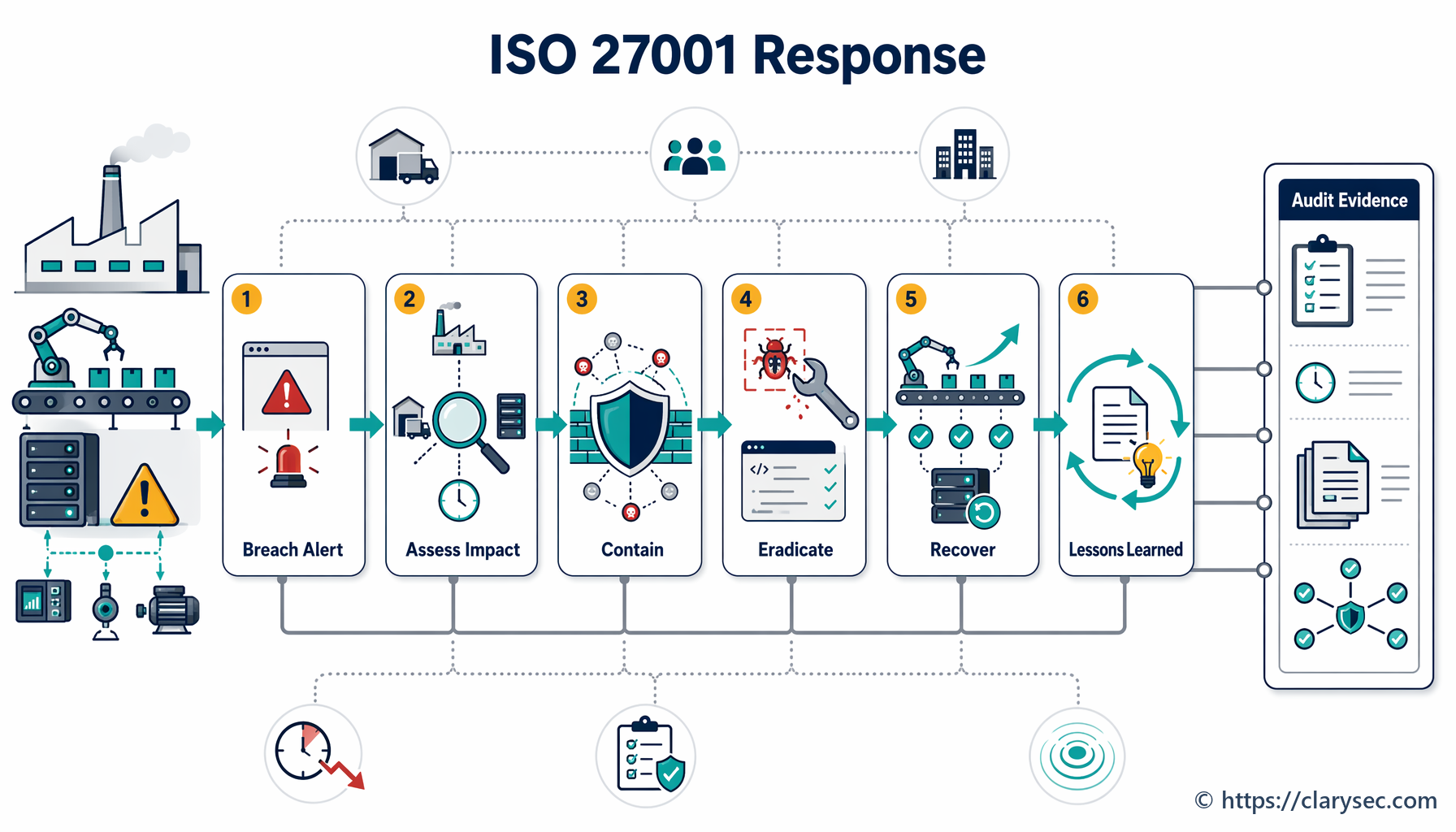
Trin 4: inddæmning, fjernelse og genopretning – bekæmp branden
Dette er den aktive responsfase, hvor IRT arbejder på at kontrollere hændelsen og genetablere normal drift.
- Inddæmning: Den umiddelbare prioritet er at stoppe skaden. Det kan indebære isolering af berørte netværkssegmenter, frakobling af kompromitterede servere eller blokering af ondsindede IP-adresser. Målet er at forhindre hændelsen i at sprede sig og forårsage yderligere skade.
- Fjernelse: Når hændelsen er inddæmmet, skal rodårsagen elimineres. Det kan betyde fjernelse af malware, patchning af udnyttede sårbarheder og deaktivering af kompromitterede brugerkonti.
- Genopretning: Det sidste trin er at gendanne berørte systemer og data. Det omfatter gendannelse fra rene sikkerhedskopier, genopbygning af systemer og omhyggelig overvågning for at sikre, at truslen er fuldt fjernet, før tjenester sættes online igen.
Afsnit 5.4 i P16S Politik for planlægning og forberedelse af styring af informationssikkerhedshændelser - SME, “Respons på informationssikkerhedshændelser”, giver rammeværket for disse handlinger og understreger, at “responsprocedurer skal iværksættes, når en informationssikkerhedshændelse klassificeres som en hændelse”.
Trin 5: aktiviteter efter hændelsen – læring af erfaringerne
Arbejdet er ikke afsluttet, når systemerne igen er online. Efterhændelsesfasen er muligvis den vigtigste fase for at opbygge langsigtet robusthed. Den omfatter to centrale aktiviteter: indsamling af bevismateriale og en lessons-learned-gennemgang.
Politikken understreger betydningen af indsamling af bevismateriale i afsnit 5.5 og angiver, at “procedurer skal etableres og følges for indsamling, erhvervelse og bevaring af bevismateriale relateret til informationssikkerhedshændelser”. Dette er afgørende for interne undersøgelser, retshåndhævelse og eventuelle retlige skridt.
Herefter skal der gennemføres en formel efterhændelsesgennemgang. Dette møde bør omfatte alle IRT-medlemmer og centrale interessenter for at drøfte:
- Hvad skete der, og hvad var tidslinjen for hændelsen?
- Hvad fungerede godt i responsen?
- Hvilke udfordringer opstod?
- Hvad kan gøres for at forebygge en tilsvarende hændelse i fremtiden?
Resultatet af denne gennemgang bør være en handlingsplan med tildelte ejere og frister for forbedring af politikker, procedurer og tekniske kontroller. Det skaber en feedbacksløjfe, der styrker organisationens sikkerhedsniveau over tid.
Sammenhængen: indsigter om tværgående compliance
Opfyldelse af ISO 27001-kravene til hændelsesstyring styrker ikke kun sikkerheden; det giver også et stærkt fundament for compliance med et voksende net af internationale og branchespecifikke regler. Mange af disse rammeværker bygger på de samme kerneprincipper om forberedelse, respons og rapportering.
Som forklaret i Zenith Controls, vores omfattende guide til tværgående compliance, er en robust hændelsesstyringsproces en hjørnesten i digital robusthed. Lad os se på, hvordan ISO 27001’s tilgang stemmer overens med andre væsentlige rammeværker.
ISO/IEC 27002:2022-kontroller: Den seneste version af ISO/IEC 27002-standarden giver detaljeret vejledning om hændelsesstyring gennem et dedikeret sæt kontroller:
- A.5.24 - Planlægning og forberedelse af styring af informationssikkerhedshændelser: Fastlægger behovet for en defineret og dokumenteret tilgang.
- A.5.25 - Vurdering og beslutning om informationssikkerhedshændelser: Sikrer, at hændelser vurderes korrekt for at afgøre, om de er sikkerhedshændelser.
- A.5.26 - Respons på informationssikkerhedshændelser: Dækker aktiviteterne for inddæmning, fjernelse og genopretning.
- A.5.27 - Rapportering af informationssikkerhedshændelser: Definerer, hvordan og hvornår hændelser rapporteres til ledelsen og andre interessenter.
- A.5.28 - Læring af informationssikkerhedshændelser: Kræver en proces for løbende forbedring.
Disse kontroller udgør en komplet livscyklus, der afspejles i andre større reguleringer.
NIS2-direktivet: For operatører af væsentlige tjenester, herunder mange produktionsvirksomheder, pålægger NIS2 strenge forpligtelser til sikkerhed og rapportering af hændelser. Zenith Controls bemærker det direkte overlap:
“Article 21 i NIS2-direktivet kræver, at væsentlige og vigtige enheder implementerer passende og proportionale tekniske, operationelle og organisatoriske foranstaltninger til at styre de risici, der påvirker sikkerheden i net- og informationssystemer. Dette omfatter udtrykkeligt politikker og procedurer for håndtering af hændelser. Derudover etablerer Article 23 en flertrinsproces for hændelsesunderretning, som kræver en tidlig varsling inden for 24 timer og en detaljeret rapport inden for 72 timer til de kompetente myndigheder (CSIRT).”
En hændelseshåndteringsplan, der er tilpasset ISO 27001, leverer præcis de mekanismer, der er nødvendige for at overholde disse stramme rapporteringsfrister.
DORA: Selvom DORA er målrettet den finansielle sektor, er forordningens robusthedsprincipper ved at blive et benchmark for alle brancher. Guiden fremhæver denne forbindelse:
“DORA’s Article 17 kræver, at finansielle enheder har en omfattende proces for styring af IKT-relaterede hændelser til at detektere, håndtere og underrette om IKT-relaterede hændelser. Article 19 kræver klassificering af hændelser baseret på kriterier, der er beskrevet i forordningen, samt rapportering af større hændelser til kompetente myndigheder ved brug af harmoniserede skabeloner. Dette afspejler klassificerings- og rapporteringskravene i ISO 27001.”
GDPR: For enhver hændelse, der involverer personoplysninger, er kravene i GDPR afgørende. En hurtig og struktureret respons er ikke valgfri. Som Zenith Controls forklarer:
“Efter GDPR kræver Article 33, at dataansvarlige underretter tilsynsmyndigheden om et brud på persondatasikkerheden uden unødig forsinkelse og, hvor det er muligt, senest 72 timer efter, at de er blevet bekendt med det. Article 34 kræver meddelelse om bruddet til den registrerede, når det sandsynligvis vil medføre en høj risiko for dennes rettigheder og frihedsrettigheder. En effektiv hændelseshåndteringsplan er afgørende for at indsamle de nødvendige oplysninger, så disse underretninger kan foretages korrekt og rettidigt.”
Ved at bygge dit hændelseshåndteringsprogram på et ISO 27001-fundament opbygger du samtidig de kapaciteter, der kræves for at navigere i de komplekse krav fra disse indbyrdes forbundne reguleringer.
Forberedelse til revision: hvad revisorer vil spørge om
En hændelseshåndteringsplan, der aldrig er blevet testet eller gennemgået, er blot et dokument. Det ved revisorer, og under en ISO 27001-certificeringsrevision vil de gå i dybden for at verificere, at dit program er en levende og operationel del af dit ISMS.
Ifølge Zenith Blueprint, vores køreplan for revisorer, er evaluering af hændelseshåndtering et kritisk trin i revisionsprocessen. Under “Fase 3: feltarbejde og indsamling af bevismateriale” vil revisorer systematisk teste jeres beredskab.
Her er, hvad du kan forvente, at de beder om, baseret på trin 21 i Zenith Blueprint, “Evaluer hændelseshåndtering og forretningskontinuitet”:
“Vis mig jeres hændelseshåndteringsplan og -politik.” Revisorer starter med dokumentationen. De vil gennemgå politikken for fuldstændighed og kontrollere, om roller og ansvarsområder, klassificeringskriterier, kommunikationsplaner og procedurer for hver fase i hændelsens livscyklus er defineret. De vil verificere, at den er formelt godkendt og kommunikeret til relevante medarbejdere.
“Vis mig registreringerne fra jeres seneste tre sikkerhedshændelser.” Det er her, planen møder virkeligheden. Revisorer skal se bevismateriale for, at planen faktisk følges. De forventer at se hændelseslogfiler eller tickets, der dokumenterer:
- Dato og tidspunkt for detektion.
- En beskrivelse af hændelsen.
- Den tildelte prioritet eller det tildelte klassificeringsniveau.
- En log over handlinger udført for inddæmning, fjernelse og genopretning.
- Dato og tidspunkt for løsning.
“Vis mig referatet og handlingsplanen fra jeres seneste efterhændelsesgennemgang.” Som Zenith Blueprint understreger, er løbende forbedring et krav.
“Under revisionen vil vi søge objektivt bevismateriale for, at efterhændelsesgennemgange gennemføres systematisk. Det omfatter gennemgang af mødereferater, handlingslogfiler og bevismateriale for, at identificerede forbedringer er implementeret, f.eks. opdaterede procedurer eller nye tekniske kontroller. Uden denne feedbacksløjfe kan ISMS ikke anses for at være ’løbende forbedret’ som krævet af standarden.”
“Vis mig bevismateriale for, at I har testet jeres plan.” Revisorer vil se, at I proaktivt tester jeres kapaciteter og ikke blot venter på en reel hændelse. Dette bevismateriale kan antage mange former, fra tabletop-øvelser med ledelsen til tekniske fuldskalasimuleringer. De vil se en rapport fra disse tests med beskrivelse af scenariet, deltagerne, resultaterne og eventuelle læringspunkter.
Når du er forberedt med dette bevismateriale, dokumenterer det, at dit hændelseshåndteringsprogram ikke kun er til pynt, men er en robust, operationel og effektiv komponent i dit ISMS.
Almindelige faldgruber, der bør undgås
Selv med en veldokumenteret plan fejler mange organisationer under en reel hændelse. Her er nogle af de mest almindelige faldgruber, du bør være opmærksom på:
- “Planen på hylden”-syndromet: Den mest almindelige fejl er at have en flot skrevet plan, som ingen har læst, forstået eller øvet. Regelmæssig træning og test er den eneste modgift.
- Udefineret beslutningskompetence: Under en krise er uklarhed din fjende. Hvis IRT ikke har forhåndsgodkendt beføjelse til at handle beslutsomt, f.eks. tage et kritisk produktionssystem offline, vil responsen blive lammet af ubeslutsomhed, mens skaden breder sig.
- Dårlig kommunikation: Manglende styring af kommunikation er en opskrift på katastrofe. Det omfatter manglende orientering af ledelsen, uklare budskaber til medarbejdere eller fejlhåndtering af kommunikation med kunder og tilsynsmyndigheder. En forhåndsgodkendt kommunikationsplan med skabeloner er afgørende.
- Manglende bevaring af bevismateriale: I hastværket med at genetablere tjenesten kan det tekniske team utilsigtet destruere afgørende forensisk bevismateriale. Det kan gøre det umuligt at fastslå rodårsagen, forebygge gentagelse eller understøtte retlige skridt.
- Manglende læring: At betragte en hændelse som “afsluttet”, når systemet er online igen, er en forspildt mulighed. Uden en grundig efterhændelsesanalyse er organisationen dømt til at gentage sine fejl.
Næste skridt
At gå fra teori til praksis er det mest kritiske skridt. Et robust hændelseshåndteringsprogram er en rejse med løbende forbedring, ikke en sluttilstand. Sådan kan du komme i gang:
- Formaliser jeres tilgang: Hvis I ikke har en formel hændelseshåndteringspolitik, er det nu, den skal etableres. Brug vores P16S Politik for planlægning og forberedelse af styring af informationssikkerhedshændelser - SME som skabelon til at opbygge et omfattende rammeværk.
- Forstå jeres compliancelandskab: Kortlæg jeres hændelseshåndteringsprocedurer mod de specifikke krav i reguleringer som NIS2, DORA og GDPR. Vores guide, Zenith Controls, giver de krydshenvisninger, I har brug for for at sikre fuld dækning.
- Forbered jer på revision: Brug revisors perspektiv til at stressteste programmet. Zenith Blueprint giver et indblik indefra i, hvad revisorer vil kræve, så I kan indsamle jeres bevismateriale og være klar til at dokumentere effektiviteten.
Konklusion
For en moderne produktionsvirksomhed er håndtering af informationssikkerhedshændelser ikke et IT-anliggende; det er en central funktion for forretningskontinuitet. Forskellen mellem en mindre driftsforstyrrelse og et katastrofalt svigt ligger i forberedelse, øvelse og forpligtelse til en struktureret, gentagelig proces.
Ved at forankre programmet i det globalt anerkendte rammeværk ISO 27001 opbygger du ikke kun en defensiv kapacitet, men en robust organisation. Du etablerer et system, der kan modstå chokket fra et sikkerhedsbrud, styre krisen med kontrol og præcision og komme styrket og mere sikker ud på den anden side. Tidspunktet for forberedelse er nu — før alarmen kl. 02:17 bliver jeres virkelighed.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council