Anatomie eines Sicherheitsvorfalls: Ein Leitfaden für Hersteller zur Incident Response nach ISO 27001
Hervorgehobener Auszug
Eine wirksame Reaktion auf Informationssicherheitsvorfälle minimiert Schäden durch Sicherheitsverletzungen und stellt die operative Resilienz sicher. Dieser Leitfaden bietet ein schrittweises Framework auf Basis von ISO 27001 und unterstützt Hersteller dabei, sich auf reale Cyberangriffe vorzubereiten, darauf zu reagieren und sich davon zu erholen – bei gleichzeitiger Erfüllung komplexer Compliance-Anforderungen aus NIS2 und DORA.
Einleitung
Der Alarm erscheint um 2:17 Uhr. Der zentrale Server eines mittelständischen Herstellers von Automobilteilen reagiert nicht mehr, und auf den Monitoren der Produktionslinie wird eine Ransomware-Nachricht angezeigt. Jede Minute Stillstand kostet Tausende durch Produktionsausfälle und birgt das Risiko, strenge SLAs in der Lieferkette zu verletzen. Das ist keine Übung. Für den CISO ist dies der Moment, in dem Jahre der Planung, Richtlinienarbeit und Schulung auf die entscheidende Probe gestellt werden.
Einen Incident-Response-Plan auf einem Server abzulegen, ist das eine; ihn unter massivem Druck umzusetzen, ist etwas völlig anderes. Für Hersteller steht besonders viel auf dem Spiel. Ein Cybervorfall kompromittiert nicht nur Daten; er stoppt die Produktion, unterbricht physische Lieferketten und kann die Sicherheit der Beschäftigten gefährden.
Dieser Leitfaden geht über theoretische Playbooks hinaus und bietet eine praxisnahe Roadmap für den Aufbau und Betrieb eines wirksamen Incident-Response-Programms. Wir zerlegen die Anatomie einer Reaktion auf einen Sicherheitsvorfall, gestützt auf das robuste Framework von ISO/IEC 27001, und zeigen, wie Sie ein resilientes Programm aufbauen, das sich nicht nur von einem Angriff erholt, sondern auch den Anforderungen von Auditoren und Aufsichtsbehörden standhält.
Was auf dem Spiel steht: Die Kettenwirkung eines Sicherheitsvorfalls in der Fertigung
Wenn die Systeme eines Herstellers kompromittiert werden, reichen die Auswirkungen weit über einen einzelnen Server hinaus. Die Vernetzung moderner Produktion – von der Lagerverwaltung bis zu robotergestützten Montagelinien – bedeutet, dass ein digitaler Ausfall einen vollständigen Betriebsstillstand verursachen kann. Die Folgen sind schwerwiegend und vielschichtig.
Erstens ist der finanzielle Schaden unmittelbar und erheblich. Produktionsstopps führen zu verpassten Fristen, Vertragsstrafen von Kunden und Kosten für ungenutzte Arbeitskapazität. Die Wiederherstellung von Systemen, der Einsatz forensischer Experten und der mögliche Umgang mit Lösegeldforderungen können die Finanzen eines mittelständischen Unternehmens massiv belasten.
Zweitens kann Reputationsschaden langfristig wirken. In einem B2B-Umfeld ist Verlässlichkeit entscheidend. Ein einzelner wesentlicher Vorfall kann das Vertrauen wichtiger Partner erschüttern, die auf Just-in-time-Lieferungen angewiesen sind. Wie unsere interne Leitlinie hervorhebt, besteht ein zentrales Ziel des Vorfallmanagements darin, „die geschäftlichen und finanziellen Auswirkungen von Vorfällen zu minimieren und den Normalbetrieb so schnell wie möglich wiederherzustellen“ – ein Ziel, das in der Fertigung von höchster Bedeutung ist.
Schließlich können regulatorische Folgen erheblich sein. Mit Frameworks wie NIS2 und DORA, die vollständig wirksam werden, unterliegen Organisationen in kritischen Sektoren wie der Fertigung strengen Meldepflichten für Vorfälle und dem Risiko erheblicher Bußgelder bei Nichteinhaltung. Ein schlecht gesteuerter Vorfall ist nicht nur ein technisches Versagen; er begründet erhebliche rechtliche und Compliance-Risiken.
Zielbild: Von Chaos zu Kontrolle
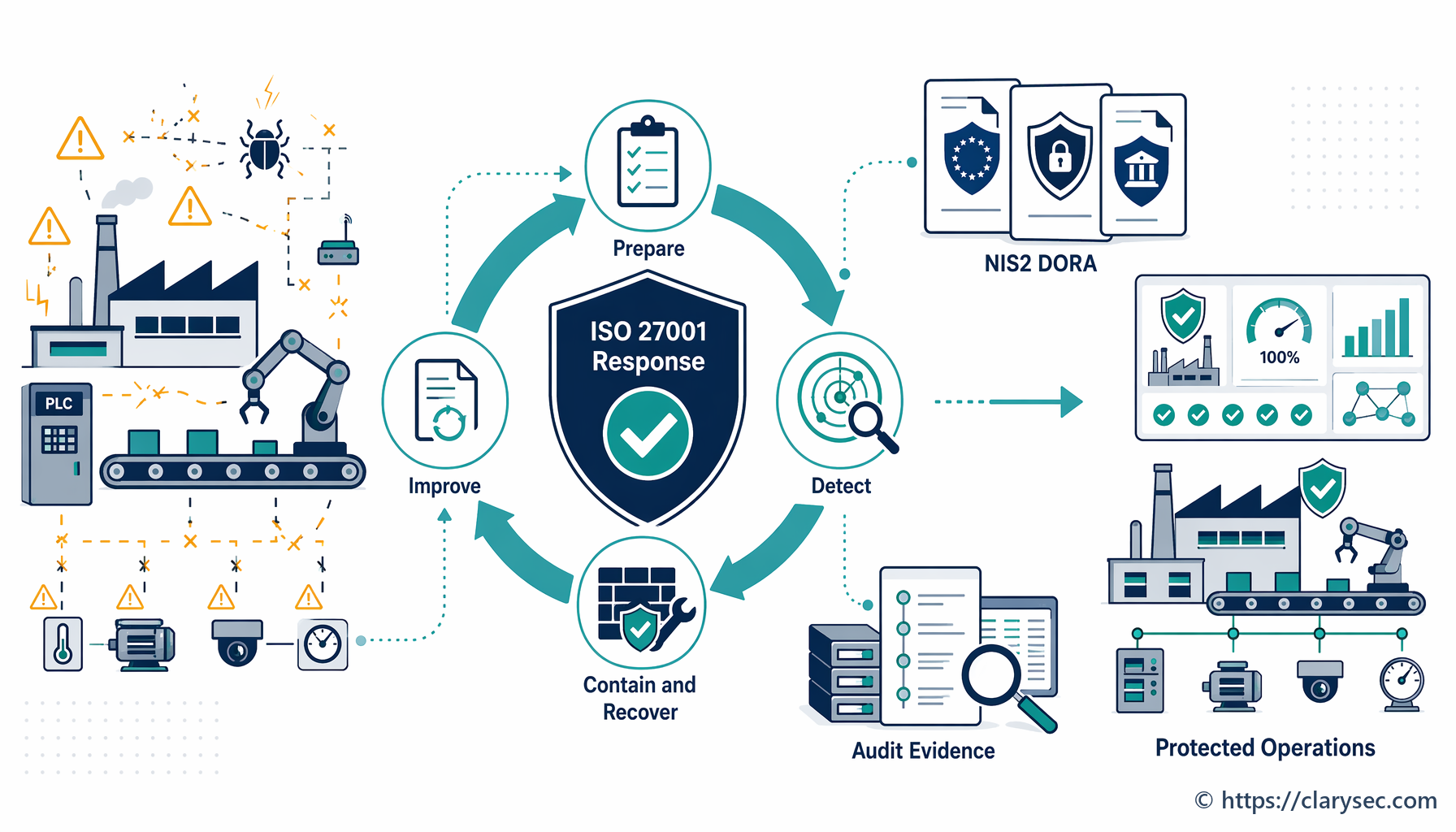
Ein wirksames Incident-Response-Programm verwandelt eine Krise von chaotischem, reaktivem Aktionismus in einen strukturierten und kontrollierten Prozess. Ziel ist nicht nur die Behebung des technischen Problems, sondern die Steuerung des gesamten Ereignisses zum Schutz des Unternehmens. Dieser Zielzustand basiert auf den Grundsätzen des ISO/IEC 27001-Frameworks, insbesondere auf den Maßnahmen zum Management von Informationssicherheitsvorfällen.
Ein ausgereiftes Programm zeichnet sich durch mehrere zentrale Ergebnisse aus:
- Klare Rollen: Alle wissen, wen sie kontaktieren müssen und welche Verantwortlichkeiten sie haben. Das Incident-Response-Team (IRT) ist vorab festgelegt, mit klarer Leitung und benannten Fachleuten aus IT, Recht, Kommunikation und Management.
- Geschwindigkeit und Präzision: Die Organisation kann Bedrohungen schnell erkennen, analysieren und eindämmen, bevor sie sich im Netzwerk ausbreiten und die gesamte Produktionsumgebung zum Stillstand bringen.
- Fundierte Entscheidungsfindung: Das Management erhält zeitnahe und präzise Informationen, damit kritische Entscheidungen zu Betrieb, Kundenkommunikation und regulatorischer Offenlegung getroffen werden können.
- Kontinuierliche Verbesserung: Jeder Vorfall, ob groß oder klein, wird zu einer Lernmöglichkeit. Ein gründlicher Prozess zur Nachbereitung des Vorfalls identifiziert Schwachstellen und führt Verbesserungen in das Sicherheitsprogramm zurück.
Diesen Bereitschaftsgrad zu erreichen, ist der Kernzweck der in ISO/IEC 27002:2022 beschriebenen Maßnahmen. Diese Maßnahmen leiten Organisationen bei Planung und Vorbereitung (A.5.24), Bewertung und Entscheidung zu Ereignissen (A.5.25), Reaktion auf Vorfälle (A.5.26) und Lernen aus Vorfällen (A.5.28). Es geht darum, ein resilientes System aufzubauen, das mit Ausfällen rechnet und darauf ausgelegt ist, sie kontrolliert zu bewältigen.
Der praktische Weg: Ein Schritt-für-Schritt-Leitfaden zur Incident Response
Der Aufbau einer robusten Incident-Response-Fähigkeit erfordert einen dokumentierten, systematischen Ansatz. Grundlage dafür ist eine klare und umsetzbare Richtlinie, die jede Phase des Prozesses beschreibt.
Unsere P16S Information Security Incident Management Planning and Preparation Policy - SME bietet eine umfassende Vorlage, die an Best Practices nach ISO 27001 ausgerichtet ist. Gehen wir die kritischen Schritte anhand dieser Richtlinie durch.
Schritt 1: Planung und Vorbereitung – Grundlage der Resilienz
Ein Reaktionsplan kann nicht erst mitten in der Krise erstellt werden. Vorbereitung ist entscheidend. In dieser Phase werden Struktur, Werkzeuge und Wissen etabliert, die erforderlich sind, um bei Eintritt eines Vorfalls entschlossen zu handeln.
Ein zentraler Bestandteil ist die Einrichtung eines Incident-Response-Teams (IRT). Wie in Abschnitt 5.1 der P16S Information Security Incident Management Planning and Preparation Policy - SME festgelegt, besteht der Zweck der Richtlinie darin, „einen konsistenten und wirksamen Ansatz für das Management von Informationssicherheitsvorfällen sicherzustellen“. Diese Konsistenz beginnt mit einem klar definierten Team. Die Richtlinie schreibt vor, dass das IRT Mitglieder aus zentralen Bereichen umfassen muss:
- IT und Informationssicherheit
- Recht und Compliance
- Personalwesen
- Öffentlichkeitsarbeit/Kommunikation
- oberes Management
Jedes Mitglied muss klar definierte Rollen und Verantwortlichkeiten haben. Wer hat die Befugnis, Systeme vom Netz zu nehmen? Wer ist als Sprecher für die Kommunikation mit Kunden oder Medien benannt? Diese Fragen müssen lange vor einem Vorfall beantwortet und dokumentiert sein.
Schritt 2: Erkennung und Meldung – Ihr Frühwarnsystem
Je schneller ein Vorfall erkannt wird, desto geringer ist der mögliche Schaden. Dafür braucht es sowohl technische Überwachung als auch eine Kultur, in der Mitarbeiter befähigt und verpflichtet sind, verdächtige Aktivitäten zu melden.
Die P16S Information Security Incident Management Planning and Preparation Policy - SME ist in diesem Punkt eindeutig. Abschnitt 5.3, „Meldung von Informationssicherheitsereignissen“, schreibt vor:
„Alle Mitarbeiter, Auftragnehmer und sonstigen relevanten Parteien sind verpflichtet, beobachtete oder vermutete Informationssicherheitsereignisse und Schwachstellen so schnell wie möglich an die benannte Kontaktstelle zu melden.“
Diese „benannte Kontaktstelle“ ist kritisch. Sie kann der IT-Service-Desk oder eine dedizierte Sicherheits-Hotline sein. Der Prozess muss einfach sein und gegenüber sämtlichem Personal klar kommuniziert werden. Mitarbeiter müssen geschult werden, worauf sie achten müssen, etwa Phishing-E-Mails, ungewöhnliches Systemverhalten oder Verletzungen der physischen Sicherheit.
Schritt 3: Bewertung und Triage – Die Bedrohung richtig einordnen
Sobald ein Ereignis gemeldet ist, besteht der nächste Schritt darin, Art und Schwere schnell zu bewerten. Handelt es sich um einen Fehlalarm, ein geringfügiges Problem oder eine voll ausgeprägte Krise? Dieser Triage-Prozess bestimmt das erforderliche Reaktionsniveau.
Unsere Richtlinie beschreibt in Abschnitt 5.2, „Klassifizierung von Vorfällen“, ein klares Klassifizierungsschema, um Vorfälle anhand ihrer Auswirkungen auf Vertraulichkeit, Integrität und Verfügbarkeit einzuordnen. Ein typisches Schema kann wie folgt aussehen:
- Niedrig: Ein einzelner Arbeitsplatzrechner ist mit weit verbreiteter Schadsoftware infiziert und leicht einzudämmen.
- Mittel: Ein Abteilungsserver ist nicht verfügbar und beeinträchtigt eine bestimmte Geschäftsfunktion, ohne die Gesamtproduktion anzuhalten.
- Hoch: Ein weitreichender Ransomware-Angriff betrifft kritische Produktionssysteme und zentrale Geschäftsdaten.
- Kritisch: Ein Vorfall umfasst eine Datenschutzverletzung mit sensiblen personenbezogenen Daten oder geistigem Eigentum und hat erhebliche rechtliche und reputationsbezogene Auswirkungen.
Diese Klassifizierung bestimmt Dringlichkeit, zugewiesene Ressourcen und den Eskalationsweg an das Management und stellt sicher, dass die Reaktion im Verhältnis zur Bedrohung steht.
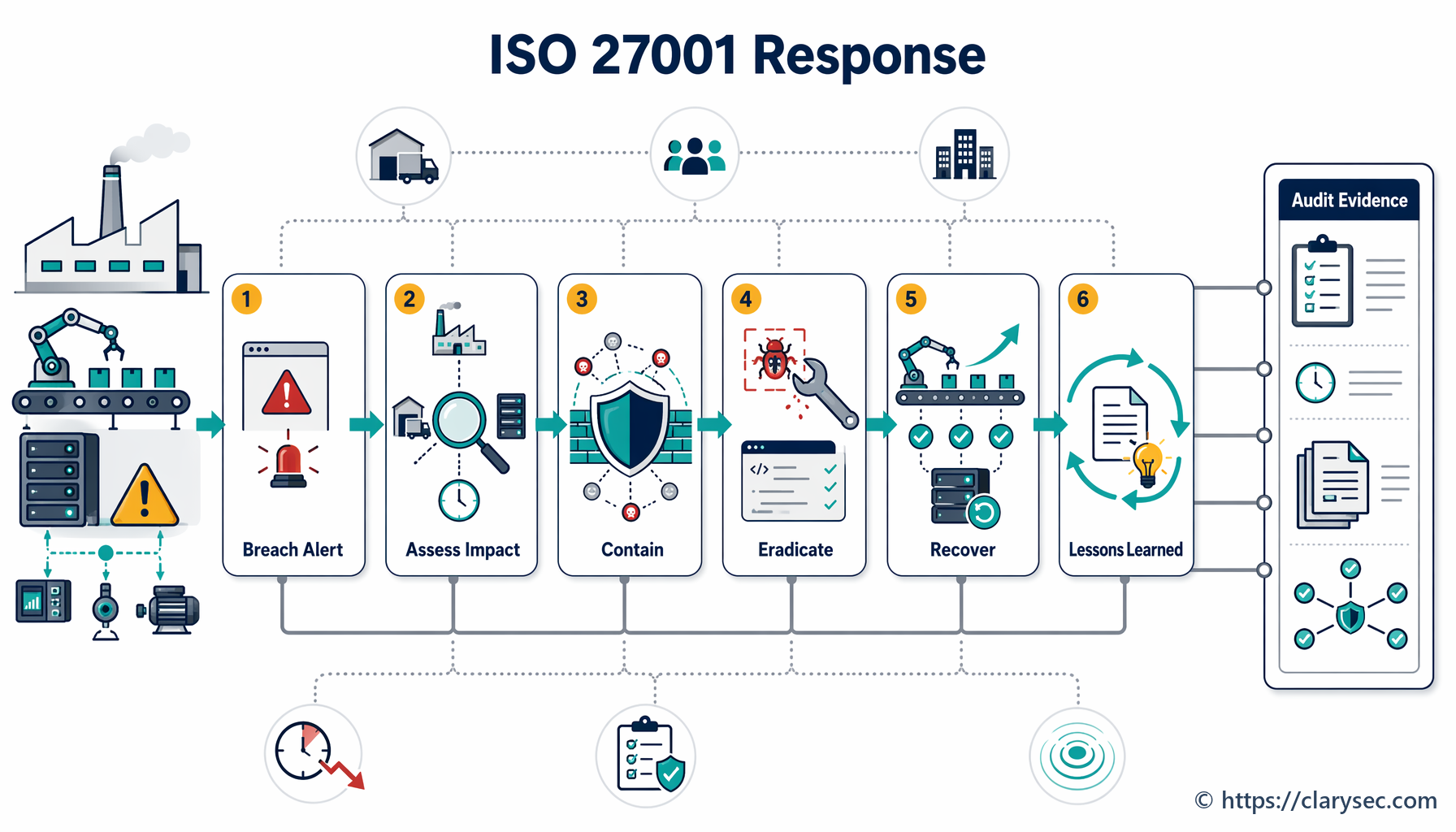
Schritt 4: Eindämmung, Beseitigung und Wiederherstellung – Den Brand bekämpfen
Dies ist die aktive Reaktionsphase, in der das IRT daran arbeitet, den Vorfall zu kontrollieren und den Normalbetrieb wiederherzustellen.
- Eindämmung: Die unmittelbare Priorität besteht darin, weiteren Schaden zu stoppen. Dies kann die Isolierung betroffener Netzwerksegmente, das Trennen kompromittierter Server oder das Blockieren bösartiger IP-Adressen umfassen. Ziel ist es, eine Ausbreitung des Vorfalls und weitere Schäden zu verhindern.
- Beseitigung: Nach der Eindämmung muss die Ursache des Vorfalls beseitigt werden. Dazu kann das Entfernen von Schadsoftware, das Schließen ausgenutzter Schwachstellen und das Deaktivieren kompromittierter Benutzerkonten gehören.
- Wiederherstellung: Der letzte Schritt besteht darin, betroffene Systeme und Daten wiederherzustellen. Dies umfasst die Wiederherstellung aus sauberen Backups, den Neuaufbau von Systemen und eine sorgfältige Überwachung, um sicherzustellen, dass die Bedrohung vollständig entfernt wurde, bevor Services wieder online genommen werden.
Abschnitt 5.4 der P16S Information Security Incident Management Planning and Preparation Policy - SME, „Reaktion auf Informationssicherheitsvorfälle“, stellt das Framework für diese Maßnahmen bereit und betont, dass „Reaktionsverfahren eingeleitet werden müssen, sobald ein Informationssicherheitsereignis als Vorfall klassifiziert wurde“.
Schritt 5: Aktivitäten nach dem Vorfall – Lessons Learned ableiten
Die Arbeit ist nicht beendet, sobald die Systeme wieder online sind. Die Phase nach dem Vorfall ist für den Aufbau langfristiger Resilienz möglicherweise die wichtigste. Sie umfasst zwei zentrale Aktivitäten: die Sicherung von Nachweisen und eine Lessons-Learned-Überprüfung.
Die Richtlinie betont in Abschnitt 5.5 die Bedeutung der Nachweissicherung und stellt fest, dass „Verfahren zur Sammlung, Erfassung und Aufbewahrung von Nachweisen im Zusammenhang mit Informationssicherheitsvorfällen eingerichtet und befolgt werden müssen“. Dies ist entscheidend für interne Untersuchungen, Strafverfolgung und mögliche rechtliche Schritte.
Im Anschluss muss eine formelle Nachbereitung des Vorfalls durchgeführt werden. An dieser Besprechung müssen alle IRT-Mitglieder und wichtigen Stakeholder teilnehmen, um zu diskutieren:
- Was ist geschehen, und wie verlief die Zeitachse der Ereignisse?
- Was lief in der Reaktion gut?
- Welche Herausforderungen traten auf?
- Was kann getan werden, um einen ähnlichen Vorfall künftig zu verhindern?
Das Ergebnis dieser Überprüfung muss ein Maßnahmenplan mit zugewiesenen Verantwortlichen und Fristen zur Verbesserung von Richtlinien, Verfahren und technischen Kontrollen sein. Dadurch entsteht ein Rückkopplungsprozess, der das Risikoprofil der Informationssicherheit der Organisation im Zeitverlauf stärkt.
Zusammenhänge herstellen: Erkenntnisse zur übergreifenden Compliance
Die Erfüllung der Anforderungen von ISO 27001 an das Vorfallmanagement stärkt nicht nur Ihre Sicherheit; sie schafft eine belastbare Grundlage für die Einhaltung eines wachsenden Netzes internationaler und branchenspezifischer Vorschriften. Viele dieser Frameworks teilen dieselben Kernprinzipien: Vorbereitung, Reaktion und Meldung.
Wie in Zenith Controls, unserem umfassenden Leitfaden zur übergreifenden Compliance, erläutert, ist ein robuster Vorfallmanagementprozess ein Eckpfeiler digitaler Resilienz. Betrachten wir, wie der Ansatz von ISO 27001 mit anderen wichtigen Frameworks zusammenpasst.
Maßnahmen nach ISO/IEC 27002:2022: Die neueste Version des Standards ISO/IEC 27002 bietet detaillierte Leitlinien zum Vorfallmanagement durch einen dedizierten Maßnahmenkatalog:
- A.5.24 - Planung und Vorbereitung des Managements von Informationssicherheitsvorfällen: Legt die Notwendigkeit eines definierten und dokumentierten Ansatzes fest.
- A.5.25 - Bewertung von und Entscheidung über Informationssicherheitsereignisse: Stellt sicher, dass Ereignisse ordnungsgemäß bewertet werden, um festzustellen, ob es sich um Vorfälle handelt.
- A.5.26 - Reaktion auf Informationssicherheitsvorfälle: Deckt Maßnahmen zur Eindämmung, Beseitigung und Wiederherstellung ab.
- A.5.27 - Meldung von Informationssicherheitsvorfällen: Definiert, wie und wann Vorfälle an Management und weitere Stakeholder gemeldet werden.
- A.5.28 - Lernen aus Informationssicherheitsvorfällen: Schreibt einen Prozess zur kontinuierlichen Verbesserung vor.
Diese Maßnahmen bilden einen vollständigen Lebenszyklus, der sich in anderen wichtigen Vorschriften widerspiegelt.
NIS2: Für Betreiber wesentlicher Dienste, darunter viele Hersteller, legt NIS2 strenge Sicherheits- und Meldepflichten für Vorfälle fest. Zenith Controls weist auf die direkte Überschneidung hin:
„Article 21 der NIS2 verlangt von wesentlichen und wichtigen Einrichtungen, geeignete und verhältnismäßige technische, operative und organisatorische Maßnahmen umzusetzen, um die Risiken für die Sicherheit von Netzwerk- und Informationssystemen zu steuern. Dies umfasst ausdrücklich Richtlinien und Verfahren zum Umgang mit Informationssicherheitsvorfällen. Darüber hinaus legt Article 23 ein mehrstufiges Benachrichtigungsverfahren für Vorfälle fest, das eine Frühwarnung innerhalb von 24 Stunden und einen detaillierten Bericht innerhalb von 72 Stunden an die zuständigen Behörden (CSIRT) verlangt.“
Ein an ISO 27001 ausgerichteter Incident-Response-Plan stellt genau die Mechanismen bereit, die zur Einhaltung dieser engen Meldefristen erforderlich sind.
DORA: Obwohl DORA auf den Finanzsektor ausgerichtet ist, werden seine Resilienzprinzipien zunehmend zu einem Maßstab für alle Branchen. Der Leitfaden hebt diesen Zusammenhang hervor:
„Article 17 von DORA verpflichtet Finanzunternehmen, einen umfassenden Prozess für das Management IKT-bezogener Vorfälle vorzuhalten, um IKT-bezogene Vorfälle zu erkennen, zu steuern und zu melden. Article 19 verlangt die Klassifizierung von Vorfällen auf Grundlage der in der Verordnung festgelegten Kriterien sowie die Meldung schwerwiegender Vorfälle an zuständige Behörden unter Verwendung harmonisierter Vorlagen. Dies entspricht den Klassifizierungs- und Meldeanforderungen in ISO 27001.“
GDPR: Bei jedem Vorfall mit personenbezogenen Daten sind die Anforderungen von GDPR maßgeblich. Eine schnelle und strukturierte Reaktion ist nicht optional. Wie Zenith Controls erläutert:
„Nach GDPR verlangt Article 33 von Verantwortlichen, die Aufsichtsbehörde unverzüglich und, soweit möglich, spätestens 72 Stunden nach Bekanntwerden über eine Verletzung des Schutzes personenbezogener Daten zu benachrichtigen. Article 34 schreibt die Benachrichtigung der betroffenen Person vor, wenn die Verletzung voraussichtlich ein hohes Risiko für ihre Rechte und Freiheiten zur Folge hat. Ein wirksamer Incident-Response-Plan ist entscheidend, um die erforderlichen Informationen zu erfassen und diese Meldungen korrekt und fristgerecht vorzunehmen.“
Wenn Sie Ihr Incident-Response-Programm auf einer Grundlage von ISO 27001 aufbauen, schaffen Sie zugleich die Fähigkeiten, die erforderlich sind, um die komplexen Anforderungen dieser miteinander verknüpften Vorschriften zu erfüllen.
Vorbereitung auf die Prüfung: Was Auditoren fragen werden
Ein Incident-Response-Plan, der nie getestet oder überprüft wurde, ist lediglich ein Dokument. Auditoren wissen das, und während eines Zertifizierungsaudits nach ISO 27001 werden sie genau prüfen, ob Ihr Programm ein gelebter Bestandteil Ihres ISMS ist.
Laut Zenith Blueprint, unserer Roadmap aus Auditorensicht, ist die Bewertung der Incident Response ein kritischer Schritt im Auditprozess. Während „Phase 3: Vor-Ort-Prüfung und Nachweiserhebung“ werden Auditoren Ihre Vorbereitung systematisch testen.
Auf Grundlage von Schritt 21 des Zenith Blueprint, „Incident Response und Aufrechterhaltung des Geschäftsbetriebs bewerten“, können Sie folgende Anforderungen erwarten:
„Zeigen Sie mir Ihren Incident-Response-Plan und Ihre Richtlinie.“ Auditoren beginnen mit der Dokumentation. Sie prüfen die Richtlinie auf Vollständigkeit, insbesondere definierte Rollen und Verantwortlichkeiten, Klassifizierungskriterien, Kommunikationspläne und Verfahren für jede Phase des Vorfalllebenszyklus. Sie verifizieren, dass sie formell genehmigt und dem relevanten Personal kommuniziert wurde.
„Zeigen Sie mir die Aufzeichnungen zu Ihren letzten drei Sicherheitsvorfällen.“ Hier zeigt sich, ob der Prozess tatsächlich funktioniert. Auditoren müssen Nachweise sehen, dass der Plan tatsächlich befolgt wird. Erwartet werden Vorfallsprotokolle oder Tickets, die Folgendes dokumentieren:
- Datum und Uhrzeit der Erkennung.
- Eine Beschreibung des Vorfalls.
- Die zugewiesene Priorität oder Klassifizierungsstufe.
- Ein Protokoll der Maßnahmen zur Eindämmung, Beseitigung und Wiederherstellung.
- Datum und Uhrzeit der Lösung.
„Zeigen Sie mir das Protokoll und den Maßnahmenplan aus Ihrer letzten Nachbereitung eines Vorfalls.“ Wie Zenith Blueprint betont, ist kontinuierliche Verbesserung nicht verhandelbar.
„Während des Audits werden wir objektive Nachweise dafür verlangen, dass Nachbereitungen von Vorfällen systematisch durchgeführt werden. Dazu gehören die Prüfung von Sitzungsprotokollen, Maßnahmenprotokollen und Nachweisen, dass identifizierte Verbesserungen umgesetzt wurden, etwa aktualisierte Verfahren oder neue technische Kontrollen. Ohne diesen Rückkopplungsprozess kann das ISMS nicht als ‚kontinuierlich verbessert‘ im Sinne des Standards angesehen werden.“
„Zeigen Sie mir Nachweise, dass Sie Ihren Plan getestet haben.“ Auditoren wollen sehen, dass Sie Ihre Fähigkeiten proaktiv testen und nicht nur auf einen echten Vorfall warten. Diese Nachweise können verschiedene Formen annehmen, von Tabletop-Übungen mit dem Management bis zu umfassenden technischen Simulationen. Erwartet wird ein Bericht zu diesen Tests, der Szenario, Teilnehmende, Ergebnisse und Lessons Learned beschreibt.
Wenn Sie diese Nachweise bereithalten, zeigen Sie, dass Ihr Incident-Response-Programm nicht nur auf dem Papier besteht, sondern ein robuster, operativer und wirksamer Bestandteil Ihres ISMS ist.
Häufige Fallstricke, die Sie vermeiden sollten
Selbst mit einem gut dokumentierten Plan geraten viele Organisationen während eines echten Vorfalls ins Stolpern. Dies sind einige der häufigsten Fallstricke, auf die Sie achten sollten:
- Das „Plan im Regal“-Syndrom: Der häufigste Fehler besteht darin, einen hervorragend geschriebenen Plan zu haben, den niemand gelesen, verstanden oder geübt hat. Regelmäßige Schulungen und Tests sind das einzige Gegenmittel.
- Unklare Befugnisse: In einer Krise ist Mehrdeutigkeit Ihr Gegner. Wenn das IRT keine vorab genehmigte Befugnis hat, entschlossene Maßnahmen zu ergreifen – etwa ein kritisches Produktionssystem offline zu nehmen –, wird die Reaktion durch Unentschlossenheit blockiert, während sich der Schaden ausbreitet.
- Schlechte Kommunikation: Kommunikation nicht zu steuern, ist ein Rezept für den Ernstfall. Dazu gehören ausbleibende Information der Leitung, unklare Botschaften an Mitarbeiter oder unsachgemäße Kommunikation mit Kunden und Aufsichtsbehörden. Ein vorab genehmigter Kommunikationsplan mit Vorlagen ist unerlässlich.
- Vernachlässigung der Nachweissicherung: In der Eile, den Service wiederherzustellen, kann das technische Team unbeabsichtigt entscheidende forensische Nachweise zerstören. Dadurch kann es unmöglich werden, die Ursache zu bestimmen, eine Wiederholung zu verhindern oder rechtliche Schritte zu unterstützen.
- Fehlendes Lernen: Einen Vorfall als „beendet“ zu betrachten, sobald das System wieder online ist, ist eine verpasste Chance. Ohne rigorose Nachbetrachtung ist die Organisation dazu verurteilt, ihre Fehler zu wiederholen.
Nächste Schritte
Der Übergang von der Theorie zur Praxis ist der wichtigste Schritt. Ein robustes Incident-Response-Programm ist eine Reise der kontinuierlichen Verbesserung, kein Endzustand. So können Sie beginnen:
- Formalisieren Sie Ihren Ansatz: Wenn Sie noch keine formelle Incident-Response-Richtlinie haben, ist jetzt der richtige Zeitpunkt, eine zu erstellen. Nutzen Sie unsere P16S Information Security Incident Management Planning and Preparation Policy - SME als Vorlage, um ein umfassendes Framework aufzubauen.
- Verstehen Sie Ihre regulatorische Landschaft: Ordnen Sie Ihre Incident-Response-Verfahren den spezifischen Anforderungen von Vorschriften wie NIS2, DORA und GDPR zu. Unser Leitfaden Zenith Controls stellt die Querverweise bereit, die Sie benötigen, um eine vollständige Abdeckung sicherzustellen.
- Bereiten Sie Ihr Audit vor: Nutzen Sie die Auditorenperspektive, um Ihr Programm einem Belastungstest zu unterziehen. Zenith Blueprint gibt Ihnen einen Einblick, was Auditoren verlangen werden, damit Sie Ihre Nachweise zusammenstellen und bereit sind, Wirksamkeit zu belegen.
Fazit
Für einen modernen Hersteller ist die Reaktion auf Informationssicherheitsvorfälle kein reines IT-Thema; sie ist eine zentrale Funktion zur Aufrechterhaltung des Geschäftsbetriebs. Der Unterschied zwischen einer geringfügigen Störung und einem katastrophalen Ausfall liegt in Vorbereitung, Übung und dem Bekenntnis zu einem strukturierten, wiederholbaren Prozess.
Indem Sie Ihr Programm auf dem weltweit anerkannten Framework von ISO 27001 aufbauen, schaffen Sie nicht nur eine Abwehrfähigkeit, sondern eine resiliente Organisation. Sie etablieren ein System, das den Schock eines Sicherheitsvorfalls verkraften, die Krise kontrolliert und präzise steuern und gestärkt sowie sicherer daraus hervorgehen kann. Die Zeit zur Vorbereitung ist jetzt – bevor der Alarm um 2:17 Uhr Ihre Realität wird.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council