Vom Chaos zur Kontrolle: Ein Leitfaden für Hersteller zur Incident Response nach ISO 27001
Ein wirksamer Incident-Response-Plan ist für Hersteller, die Cyberbedrohungen mit potenziellen Produktionsstillständen ausgesetzt sind, unverzichtbar. Dieser Leitfaden beschreibt Schritt für Schritt, wie eine robuste, an ISO 27001 ausgerichtete Fähigkeit zum Management von Informationssicherheitsvorfällen aufgebaut wird, wie operative Resilienz sichergestellt und wie anspruchsvolle, übergreifende Compliance-Anforderungen aus Regelwerken wie NIS2 und DORA erfüllt werden.
Einleitung
Das Summen der Maschinen in der Fertigungshalle ist der Klang des Geschäfts. Für einen mittelständischen Hersteller steht es für Umsatz, stabile Lieferketten und Kundenvertrauen. Stellen Sie sich nun vor, dieses Geräusch würde durch eine beunruhigende Stille ersetzt. Im Security Operations Center (SOC) erscheint eine einzelne Warnmeldung auf dem Bildschirm: „Ungewöhnliche Netzwerkaktivität erkannt – Segment des Produktionsnetzwerks.“ Innerhalb weniger Minuten reagieren Steuerungssysteme nicht mehr. Die Produktionslinie kommt zum Stillstand. Dies ist kein hypothetisches Szenario, sondern die Realität eines modernen Cybervorfalls im Fertigungssektor, in dem die Konvergenz von Informationstechnik (IT) und Operational Technology (OT) eine neue Bedrohungslage mit hohen Auswirkungen geschaffen hat.
Ein Informationssicherheitsvorfall ist längst nicht mehr nur ein IT-Problem; er ist eine kritische Betriebsunterbrechung mit dem Potenzial, die Organisation handlungsunfähig zu machen. Für CISOs und Geschäftsleitungen in der Fertigung lautet die Frage nicht, ob ein Vorfall eintritt, sondern wie die Organisation reagiert, wenn er eintritt. Eine chaotische Ad-hoc-Reaktion führt zu verlängerten Ausfallzeiten, Bußgeldern und irreparablen Reputationsschäden. Eine strukturierte und eingeübte Reaktion kann eine potenzielle Katastrophe dagegen in ein kontrolliertes Ereignis überführen und Resilienz sowie Kontrolle nachweisen. Dies ist das Kernprinzip des Managements von Informationssicherheitsvorfällen, eines kritischen Bestandteils jedes robusten Informationssicherheits-Managementsystems (ISMS) auf Basis von ISO/IEC 27001.
Worum es geht
Für einen Hersteller reichen die Auswirkungen eines Sicherheitsvorfalls weit über Datenverlust hinaus. Das zentrale Risiko ist die Unterbrechung der Kernprozesse. Werden OT-Systeme kompromittiert, sind die Folgen unmittelbar und greifbar: stillstehende Produktionslinien, verzögerte Lieferungen und nicht eingehaltene Lieferkettenzusagen. Die finanziellen Schäden entstehen sofort; Kosten durch Ausfallzeiten, Abhilfemaßnahmen und mögliche Vertragsstrafen summieren sich schnell.
Die regulatorische Landschaft erhöht den Druck zusätzlich. Ein schlecht gesteuerter Vorfall kann nach verschiedenen Regelwerken erhebliche Bußgelder auslösen. Wie der umfassende Leitfaden von Clarysec, Zenith Controls, hervorhebt, ist die Tragweite erheblich:
„Das primäre Ziel des Vorfallmanagements besteht darin, die negativen Auswirkungen von Sicherheitsvorfällen auf die Geschäftsprozesse zu minimieren und eine schnelle, wirksame und geordnete Reaktion sicherzustellen. Ein unzureichendes Management von Vorfällen kann zu erheblichen finanziellen Verlusten, Reputationsschäden und regulatorischen Sanktionen führen.“
Es geht dabei nicht nur um eine einzelne Vorschrift. Die Verflechtung moderner Compliance-Anforderungen bedeutet, dass ein einzelner Vorfall kaskadierende regulatorische Folgen haben kann. Eine Datenpanne mit Mitarbeiter- oder Kundeninformationen könnte gegen GDPR verstoßen. Eine Störung von Leistungen für Kunden im Finanzsektor könnte eine Prüfung nach DORA nach sich ziehen. Für Organisationen, die als wesentliche oder wichtige Einrichtungen eingestuft sind, schreibt NIS2 strenge Fristen für die Vorfallsmeldung und Sicherheitsanforderungen vor.
Über die unmittelbaren finanziellen und regulatorischen Folgen hinaus steht der Vertrauensverlust. Kunden, Partner und Lieferanten verlassen sich auf die Lieferfähigkeit des Herstellers. Ein Vorfall, der diesen Ablauf stört, beschädigt Vertrauen und kann zu Geschäftsverlusten führen. Die Wiederherstellung dieser Reputation ist häufig langwieriger und schwieriger als die Wiederherstellung der betroffenen Systeme. Die tatsächlichen Kosten bestehen daher nicht nur aus Bußgeldern und verlorenen Produktionsstunden, sondern auch aus den langfristigen Auswirkungen auf Marktposition und Markenintegrität des Unternehmens.
Wie ein guter Zielzustand aussieht
Wie sieht angesichts solcher erheblichen Risiken eine wirksame Incident-Response-Fähigkeit aus? Sie ist ein Zustand vorbereiteter Handlungsfähigkeit, in dem Chaos durch einen klaren, methodischen Prozess ersetzt wird. Sie beschreibt die Fähigkeit, einen Vorfall so zu erkennen, darauf zu reagieren und sich davon zu erholen, dass Schäden minimiert und die Aufrechterhaltung des Geschäftsbetriebs unterstützt werden. Dieser Zielzustand baut auf den Grundlagen von ISO/IEC 27001 auf, insbesondere auf den Maßnahmen in Anhang A.
Ein ausgereiftes Vorfallmanagementprogramm, das durch eine formale Richtlinie gesteuert wird, stellt sicher, dass alle Beteiligten ihre Rolle kennen. Unsere P16S Richtlinie zum Management von Informationssicherheitsvorfällen – KMU betont diese Klarheit in ihrer Zweckbeschreibung:
„Zweck dieser Richtlinie ist es, ein strukturiertes und wirksames Rahmenwerk für das Management von Informationssicherheitsvorfällen festzulegen. Dieses Rahmenwerk stellt eine zeitnahe und koordinierte Reaktion auf Sicherheitsereignisse sicher, minimiert deren Auswirkungen auf Betrieb, Assets und Reputation der Organisation und erfüllt zugleich gesetzliche, regulatorische und vertragliche Anforderungen.“
Dieses strukturierte Rahmenwerk führt zu konkreten Vorteilen:
- Reduzierte Ausfallzeiten: Ein klar definierter Plan ermöglicht schnellere Eindämmung und Wiederherstellung, sodass Produktionslinien früher wieder anlaufen können.
- Kontrollierte Kosten: Durch die Minimierung von Dauer und Auswirkungen des Vorfalls sinken die verbundenen Kosten durch Abhilfemaßnahmen, entgangenen Umsatz und mögliche Bußgelder erheblich.
- Erhöhte Resilienz: Die Organisation lernt aus jedem Vorfall und nutzt die Nachbereitung von Vorfällen, um Schutzmaßnahmen zu stärken und künftige Reaktionen zu verbessern. Dies entspricht dem ISO 27001-Grundsatz der kontinuierlichen Verbesserung.
- Nachweisbare Compliance: Ein dokumentierter und getesteter Incident-Response-Prozess liefert Auditoren und Aufsichtsbehörden klare Nachweise dafür, dass die Organisation ihre Sicherheitsverpflichtungen ernst nimmt.
- Vertrauen interessierter Parteien: Eine professionelle und wirksame Reaktion gibt Kunden, Partnern und Versicherern Sicherheit, dass die Organisation ein zuverlässiger und sicherer Geschäftspartner ist.
Letztlich bedeutet „gut“, dass eine Organisation nicht nur reaktiv, sondern proaktiv handelt und Vorfallmanagement nicht als rein technische Aufgabe, sondern als zentrale Geschäftsfunktion behandelt, die für Überleben und Wachstum in einer digitalen Welt unerlässlich ist.
Der praktische Weg: Schritt-für-Schritt-Anleitung
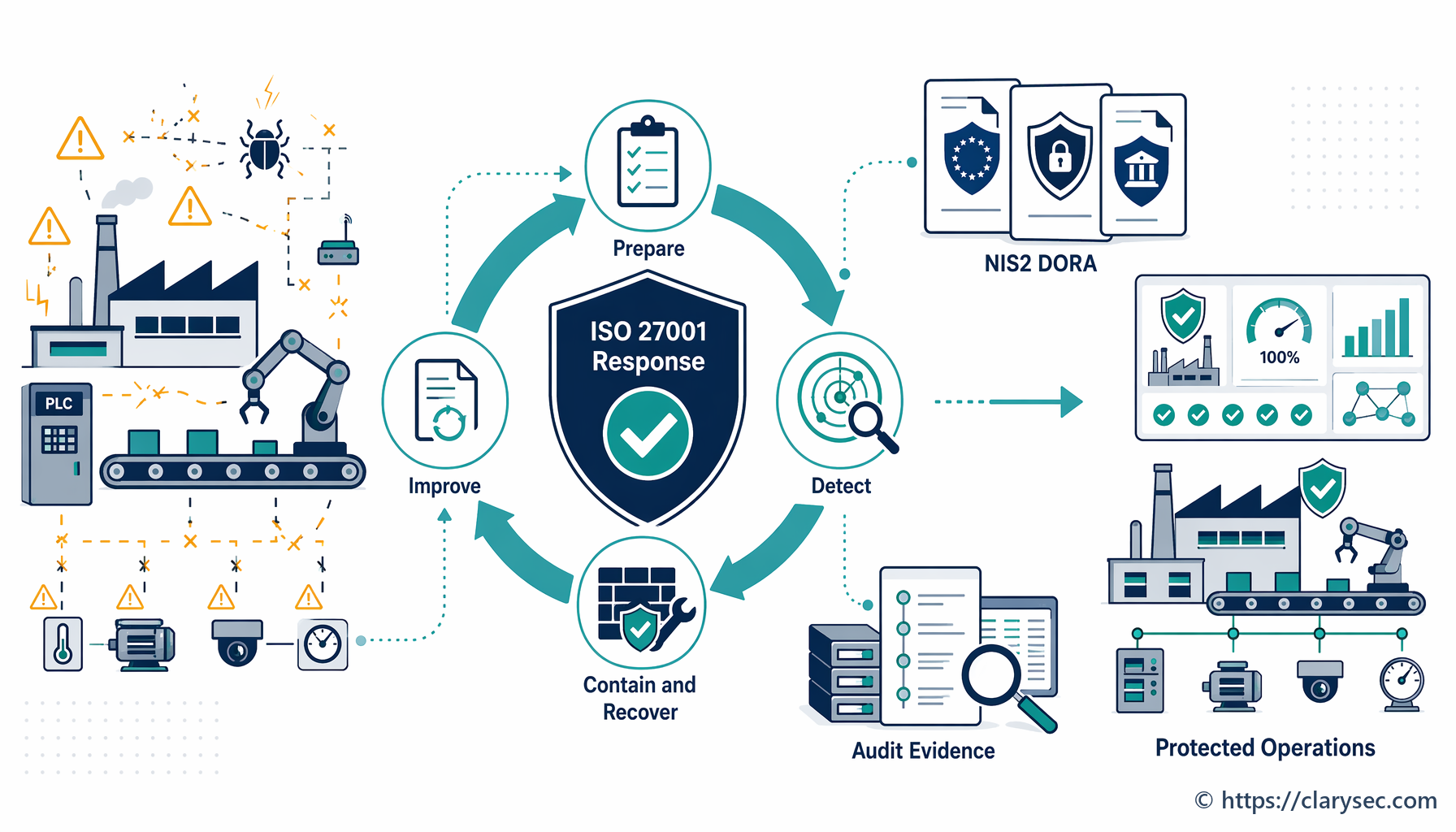
Der Aufbau einer resilienten Incident-Response-Fähigkeit erfordert mehr als ein Dokument; erforderlich ist ein praktischer, umsetzbarer Plan, der in die Kultur der Organisation integriert ist. Dieser Prozess lässt sich in den klassischen Lebenszyklus des Vorfallmanagements unterteilen, wobei jede Phase durch klare Richtlinien und Verfahren unterstützt wird.
Phase 1: Vorbereitung und Planung
Dies ist die kritischste Phase. Eine wirksame Reaktion ist ohne gründliche Vorbereitung nicht möglich. Grundlage ist eine umfassende Richtlinie, die den Rahmen für alle nachfolgenden Maßnahmen setzt. Die P16S Richtlinie zum Management von Informationssicherheitsvorfällen – KMU beschreibt den wesentlichen ersten Schritt in Abschnitt 5.1, „Plan für das Management von Informationssicherheitsvorfällen“:
„Die Organisation muss einen Plan für das Management von Informationssicherheitsvorfällen entwickeln, umsetzen und aufrechterhalten. Dieser Plan muss mit den Plänen zur Aufrechterhaltung des Geschäftsbetriebs und zur Notfallwiederherstellung integriert sein, um eine kohärente Reaktion auf störende Ereignisse sicherzustellen.“
Dieser Plan ist kein statisches Dokument. Er muss den gesamten Prozess definieren, von der ersten Erkennung bis zur abschließenden Behebung. Ein zentraler Bestandteil ist die Einrichtung eines dedizierten Incident-Response-Teams (IRT). Die Rollen und Verantwortlichkeiten dieses Teams müssen ausdrücklich festgelegt werden, um Verwirrung in einer Krise zu vermeiden. Die Richtlinie stellt dies in Abschnitt 5.2, „Rollen des Incident-Response-Teams (IRT)“, weiter klar: „Das IRT muss aus Mitgliedern relevanter Abteilungen bestehen, darunter IT, Sicherheit, Recht, Personalwesen und Kommunikation. Die Rollen und Verantwortlichkeiten jedes Mitglieds während eines Vorfalls müssen klar dokumentiert sein.“
Zur Vorbereitung gehört auch, sicherzustellen, dass das Team über die erforderlichen Werkzeuge und Ressourcen verfügt, einschließlich sicherer Kommunikationskanäle, Analysesoftware und Zugang zu forensischen Fähigkeiten.
Phase 2: Erkennung und Analyse
Ein Vorfall kann nicht gesteuert werden, wenn er nicht erkannt wird. Diese Phase konzentriert sich auf die Identifizierung und Validierung potenzieller Sicherheitsvorfälle. Gemäß unserer P16S Richtlinie zum Management von Informationssicherheitsvorfällen – KMU schreibt Abschnitt 5.3, „Vorfallserkennung und -meldung“, vor: „Alle Mitarbeiter, Auftragnehmer und sonstigen relevanten Parteien sind verpflichtet, beobachtete oder vermutete Schwachstellen oder Bedrohungen der Informationssicherheit unverzüglich zu melden.“
Dies erfordert eine Kombination aus technischer Überwachung und menschlicher Sensibilisierung. Automatisierte Systeme wie Security Information and Event Management (SIEM) sind für die Erkennung von Anomalien entscheidend, doch gut geschulte Mitarbeitende bilden die erste Verteidigungslinie. Unsere P08S Richtlinie zur Sensibilisierung und Schulung für Informationssicherheit – KMU bekräftigt dies in ihrer Richtlinienaussage: „Alle Mitarbeiter und, soweit relevant, Auftragnehmer müssen angemessene Sensibilisierungsmaßnahmen und Schulungen sowie regelmäßige Aktualisierungen zu Organisationsrichtlinien und -verfahren erhalten, soweit dies für ihre Funktion relevant ist.“
Sobald ein Ereignis gemeldet wurde, muss das IRT es schnell analysieren und klassifizieren, um Schweregrad und potenzielle Auswirkungen zu bestimmen. Diese erste Sicherheitsvorfall-Triage ist entscheidend, um die Reaktionsmaßnahmen zu priorisieren.
Phase 3: Eindämmung, Beseitigung und Wiederherstellung
Bei einem bestätigten Vorfall besteht das unmittelbare Ziel darin, den Schaden zu begrenzen. Die Eindämmungsstrategie ist insbesondere in einer Fertigungsumgebung entscheidend. Dies kann bedeuten, das betroffene Netzwerksegment, das die Produktionsmaschinen steuert, zu isolieren, um eine Ausbreitung von Schadsoftware vom IT-Netzwerk in das OT-Netzwerk zu verhindern.
Nach der Eindämmung arbeitet das IRT daran, die Bedrohung zu beseitigen. Dies kann das Entfernen von Schadsoftware, die Deaktivierung kompromittierter Benutzerkonten und das Einspielen von Patches für Schwachstellen umfassen. Der letzte Schritt in dieser Phase ist die Wiederherstellung, bei der Systeme in den Normalbetrieb zurückgeführt werden. Dies muss methodisch erfolgen; bevor Systeme wieder online gehen, muss sichergestellt sein, dass die Bedrohung vollständig entfernt wurde. Wie in Abschnitt 5.5 der P16S Richtlinie zum Management von Informationssicherheitsvorfällen – KMU festgelegt: „Wiederherstellungsmaßnahmen müssen auf Grundlage der Business-Impact-Analyse (BIA) priorisiert werden, um kritische Geschäftsfunktionen so schnell wie möglich wiederherzustellen.“
Während dieser Phase ist die Beweissicherung von zentraler Bedeutung. Der ordnungsgemäße Umgang mit digitalen Beweismitteln ist für die Analyse nach dem Vorfall sowie für mögliche rechtliche oder regulatorische Maßnahmen unerlässlich. Unsere Richtlinie legt in Abschnitt 5.6, „Beweissicherung und Umgang mit Beweismitteln“, fest: „Alle Beweismittel im Zusammenhang mit einem Informationssicherheitsvorfall müssen forensisch einwandfrei erhoben, gehandhabt und aufbewahrt werden, um ihre Integrität zu wahren.“
Phase 4: Aktivitäten nach dem Vorfall und kontinuierliche Verbesserung
Die Arbeit endet nicht, sobald die Systeme wieder online sind. In der Phase nach dem Vorfall findet das wertvollste Lernen statt. Eine formale Nachbereitung des Vorfalls oder ein „Lessons Learned“-Termin ist unerlässlich. Ziel ist es, wie in unserer Umsetzungshilfe beschrieben, den Vorfall und die Reaktion zu analysieren, um Verbesserungsbereiche zu identifizieren.
„Die aus der Analyse und Behebung von Informationssicherheitsvorfällen gewonnenen Erkenntnisse sollten genutzt werden, um Erkennung, Reaktion und Prävention künftiger Vorfälle zu verbessern. Dazu gehören die Aktualisierung von Risikobeurteilungen, Richtlinien, Verfahren und technischen Kontrollen.“
Diese Rückkopplungsschleife ist der Motor der kontinuierlichen Verbesserung, eines Eckpfeilers des ISO 27001-Rahmens. Die Feststellungen aus dieser Überprüfung sollten genutzt werden, um den Incident-Response-Plan zu aktualisieren, Sicherheitskontrollen zu verfeinern und Mitarbeiterschulungen zu verbessern. So wird sichergestellt, dass die Organisation nach jedem Vorfall stärker und resilienter wird und ein negatives Ereignis in einen positiven Auslöser für Veränderung verwandelt.
Verbindungen herstellen: Erkenntnisse zur übergreifenden Compliance
Ein wirksamer Incident-Response-Plan erfüllt nicht nur ISO 27001; er bildet das Rückgrat für die Compliance mit einer wachsenden Zahl sich überschneidender Vorschriften. Moderne Regelwerke erkennen an, dass eine schnelle und strukturierte Reaktion grundlegend für den Schutz von Daten, Services und kritischer Infrastruktur ist. CISOs und Compliance-Manager müssen diese Zusammenhänge verstehen, um ein wirklich umfassendes Programm aufzubauen.
Die zentralen ISO/IEC 27002:2022-Maßnahmen zum Vorfallmanagement (5.24, 5.25, 5.26 und 5.27) bieten eine universelle Grundlage. Diese Maßnahmen umfassen Planung und Vorbereitung, Bewertung und Entscheidung zu Ereignissen, Reaktion auf Vorfälle und Lernen aus ihnen. Diese Struktur findet sich auch in anderen wichtigen Regelwerken wieder.
NIS2-Richtlinie: Für Hersteller, die als wesentliche oder wichtige Einrichtungen gelten, ist NIS2 ein Wendepunkt. Sie schreibt strenge Sicherheitsmaßnahmen und Vorfallmeldungen vor. Clarysec Zenith Controls hebt diese direkte Verbindung hervor:
„NIS2 verlangt von Organisationen Fähigkeiten zum Umgang mit Vorfällen, einschließlich Verfahren zur Meldung erheblicher Vorfälle an zuständige Behörden innerhalb strenger Fristen (z. B. eine Frühwarnung innerhalb von 24 Stunden).“
Das bedeutet, dass der an ISO 27001 ausgerichtete Reaktionsplan eines Herstellers die spezifischen Benachrichtigungs-Workflows und Fristen nach NIS2 enthalten muss.
DORA (Digital Operational Resilience Act): Obwohl DORA auf den Finanzsektor ausgerichtet ist, erstreckt sich seine Wirkung auf kritische IKT-Drittdienstleister. Dazu können auch Hersteller gehören, die Technologie oder Services für Finanzunternehmen bereitstellen. DORA legt besonderen Schwerpunkt auf das Management IKT-bezogener Vorfälle. Wie Clarysec Zenith Controls erläutert:
„DORA schreibt einen umfassenden Prozess für das Management IKT-bezogener Vorfälle vor. Dazu gehören die Klassifizierung von Vorfällen anhand spezifischer Kriterien und die Meldung wesentlicher Vorfälle an Aufsichtsbehörden. Der Fokus liegt darauf, die Resilienz digitaler Abläufe im gesamten Finanzökosystem sicherzustellen.“
GDPR (General Data Protection Regulation): Jeder Vorfall, der personenbezogene Daten betrifft, löst unmittelbar GDPR-Verpflichtungen aus. Eine Verletzung des Schutzes personenbezogener Daten muss der Aufsichtsbehörde innerhalb von 72 Stunden gemeldet werden. Ein wirksamer Incident-Response-Plan muss einen klaren Prozess enthalten, um festzustellen, ob personenbezogene Daten betroffen sind, und das GDPR-Meldeverfahren ohne Verzögerung einzuleiten.
NIST Cybersecurity Framework (CSF): Das NIST CSF ist weit verbreitet, und seine fünf Funktionen (Identify, Protect, Detect, Respond, Recover) passen exakt zum Lebenszyklus des Vorfallmanagements. Die Funktionen „Respond“ und „Recover“ sind vollständig Aktivitäten des Vorfallmanagements gewidmet. Ein auf ISO 27001 basierender Plan leistet damit einen direkten Beitrag zur Umsetzung des NIST CSF.
COBIT 2019: Dieses Rahmenwerk für IT-Governance und IT-Management betont ebenfalls Incident Response. Clarysec Zenith Controls weist auf die Ausrichtung hin:
„Die COBIT 2019-Domäne ‚Deliver, Service and Support‘ (DSS) umfasst den Prozess DSS02, ‚Manage service requests and incidents‘. Dieser Prozess stellt sicher, dass Vorfälle zeitnah gelöst werden und den Geschäftsbetrieb nicht unterbrechen; er ist damit direkt an den Zielen der Maßnahmen zum Vorfallmanagement nach ISO 27001 ausgerichtet.“
Durch den Aufbau eines robusten Vorfallmanagementprogramms auf Basis von ISO 27001 erreichen Organisationen nicht nur die Compliance mit einem einzelnen Standard; sie schaffen eine resiliente operative Fähigkeit, die die Kernanforderungen mehrerer, sich überschneidender regulatorischer Rahmenwerke erfüllt.
Vorbereitung auf Prüfungen: Was Auditoren fragen werden
Ein Incident-Response-Plan ist nur so gut wie seine Umsetzung und Dokumentation. Wenn ein Auditor eintrifft, sucht er nach konkreten Nachweisen, dass der Plan nicht nur ein „Shelfware“-Dokument ist, sondern ein gelebter Bestandteil des Informationssicherheits-Risikoprofils der Organisation. Erwartet wird ein ausgereifter, wiederholbarer Prozess.
Der Auditprozess selbst ist strukturiert und methodisch. Gemäß der umfassenden Roadmap in Zenith Blueprint werden Auditoren die Wirksamkeit Ihrer Maßnahmen zum Vorfallmanagement systematisch testen. In Phase 2, „Vor-Ort-Prüfung und Nachweiserhebung“, widmen Auditoren diesem Bereich konkrete Schritte.
Schritt 15: Verfahren zum Vorfallmanagement prüfen: Auditoren beginnen in der Regel mit der Anforderung des formalen Plans zum Vorfallmanagement und der zugehörigen Verfahren. Sie prüfen diese Dokumente auf Vollständigkeit und Klarheit. Wie Zenith Blueprint für diesen Schritt ausführt:
„Prüfen Sie die dokumentierten Verfahren der Organisation zum Management von Informationssicherheitsvorfällen. Verifizieren Sie, dass die Verfahren Rollen, Verantwortlichkeiten und Kommunikationspläne für das Management von Vorfällen definieren.“
Sie werden fragen:
- Gibt es einen formal dokumentierten Incident-Response-Plan?
- Ist ein Incident-Response-Team (IRT) mit klaren Rollen und Kontaktinformationen definiert?
- Gibt es klare Verfahren für Meldung, Klassifizierung und Eskalation von Vorfällen?
- Enthält der Plan Kommunikationsprotokolle für interne und externe interessierte Parteien?
Schritt 16: Tests der Incident Response bewerten: Ein Plan, der nie getestet wurde, wird mit hoher Wahrscheinlichkeit scheitern. Auditoren verlangen Nachweise dafür, dass der Plan praxistauglich ist. Zenith Blueprint betont dies:
„Verifizieren Sie, dass der Incident-Response-Plan regelmäßig durch Übungen wie Tabletop-Simulationen oder Vollübungen getestet wird. Prüfen Sie die Ergebnisse dieser Tests und kontrollieren Sie, ob Lessons Learned zur Aktualisierung des Plans genutzt wurden.“
Sie werden anfordern:
- Aufzeichnungen zu Tabletop-Übungen oder Simulationsübungen.
- Berichte nach Tests, die darstellen, was gut funktioniert hat und was verbessert werden musste.
- Nachweise, dass der Incident-Response-Plan auf Grundlage dieser Feststellungen aktualisiert wurde.
Schritt 17: Vorfallsprotokolle und Berichte prüfen: Abschließend wollen Auditoren sehen, wie der Plan in der Praxis funktioniert, indem sie Aufzeichnungen vergangener Vorfälle prüfen. Dies ist der entscheidende Test für die Wirksamkeit des Programms. Sie untersuchen Vorfallsprotokolle, Kommunikationsaufzeichnungen des IRT und Nachbereitungsberichte. Ziel ist es zu verifizieren, dass die Organisation während eines realen Ereignisses ihre eigenen Verfahren eingehalten hat.
Sie werden fragen:
- Können Sie ein Protokoll aller Sicherheitsvorfälle der vergangenen 12 Monate bereitstellen?
- Können Sie für ausgewählte Vorfälle die vollständige Aufzeichnung von der Erkennung bis zur Behebung vorlegen?
- Gibt es Berichte nach Vorfällen, die die Ursachenanalyse enthalten und Korrekturmaßnahmen identifizieren?
- Wurden Beweismittel gemäß dem dokumentierten Verfahren behandelt?
Auf diese Fragen mit gut strukturierter Dokumentation und klaren Aufzeichnungen vorbereitet zu sein, ist der Schlüssel zu einem erfolgreichen Audit und belegt eine echte Kultur der Sicherheitsresilienz.
Häufige Fallstricke
Selbst mit einem vorhandenen Plan geraten viele Organisationen während eines tatsächlichen Vorfalls ins Straucheln. Diese häufigen Fallstricke zu vermeiden, ist genauso wichtig wie einen guten Plan zu haben.
- Fehlender formaler und getesteter Plan: Der häufigste Fehler besteht darin, gar keinen Plan zu haben oder einen Plan, der nie getestet wurde. Ein ungetesteter Plan ist eine Sammlung von Annahmen, die im ungünstigsten Moment widerlegt werden kann.
- Unklar definierte Rollen und Verantwortlichkeiten: In einer Krise ist Mehrdeutigkeit der Gegner. Wenn Teammitglieder nicht genau wissen, was sie tun sollen, wird die Reaktion langsam, chaotisch und unwirksam.
- Mangelhafte Kommunikation: Interessierte Parteien im Unklaren zu lassen, erzeugt Panik und Misstrauen. Ein klarer Kommunikationsplan für Mitarbeiter, Kunden, Aufsichtsbehörden und gegebenenfalls Medien ist unerlässlich, um die Kommunikation zu steuern und Vertrauen zu erhalten.
- Unzureichende Sicherung von Beweismitteln: Im Bestreben, Services schnell wiederherzustellen, vernichten Teams häufig entscheidende forensische Beweismittel. Dies behindert nicht nur die Untersuchung nach dem Vorfall, sondern kann auch schwerwiegende rechtliche und Compliance-bezogene Folgen haben.
- Vergessen der „Lessons Learned“: Der größte Einzelfehler besteht darin, aus einem Vorfall nicht zu lernen. Ohne gründliche Nachbereitung und die Verpflichtung zur Umsetzung von Korrekturmaßnahmen ist die Organisation dazu verurteilt, frühere Fehler zu wiederholen.
- Ignorieren der OT-Umgebung: Für Hersteller ist es ein kritischer Fehler, Incident Response als reines IT-Thema zu behandeln. Der Plan muss die besonderen Herausforderungen der OT-Umgebung ausdrücklich adressieren, einschließlich der Auswirkungen auf die Betriebssicherheit und abweichender Wiederherstellungsprotokolle für industrielle Steuerungssysteme.
Nächste Schritte
Der Weg von einer reaktiven Haltung zu proaktiver Handlungsfähigkeit ist ein Prozess, den jede Fertigungsorganisation durchlaufen muss. Der weitere Weg erfordert die Verpflichtung, eine strukturierte, richtlinienbasierte Fähigkeit zum Vorfallmanagement aufzubauen.
Wir empfehlen, mit einem soliden Fundament zu beginnen. Unsere Richtlinienvorlagen bieten einen umfassenden Ausgangspunkt für die Definition Ihres Rahmenwerks zum Vorfallmanagement.
- Etablieren Sie mit der P16S Richtlinie zum Management von Informationssicherheitsvorfällen – KMU einen klaren und umsetzbaren Plan.
- Stellen Sie sicher, dass Ihr Team vorbereitet ist, indem Sie die P08S Richtlinie zur Sensibilisierung und Schulung für Informationssicherheit – KMU umsetzen.
Für ein vertieftes Verständnis, wie diese Kontrollen in eine breitere Compliance-Landschaft passen und wie Sie sich auf anspruchsvolle Audits vorbereiten, sind unsere Expertenleitfäden wertvolle Ressourcen.
- Ordnen Sie Ihre Kontrollen mit Zenith Controls mehreren Rahmenwerken zu.
- Bereiten Sie sich mit Zenith Blueprint auf die Prüfung durch Auditoren vor.
Fazit
Für einen mittelständischen Hersteller ist die Stille einer stillstehenden Produktionslinie das teuerste Geräusch der Welt. In der heutigen vernetzten Umgebung ist das Management von Informationssicherheitsvorfällen keine technische Funktion mehr, die an die IT-Abteilung delegiert wird; es ist eine grundlegende Säule operativer Resilienz und der Aufrechterhaltung des Geschäftsbetriebs.
Durch die Übernahme des strukturierten Ansatzes von ISO 27001 können Organisationen von chaotischer Reaktion zu kontrollierter, methodischer Incident Response übergehen. Ein gut dokumentierter, regelmäßig getesteter Incident-Response-Plan, unterstützt durch geschulte und sensibilisierte Mitarbeitende, ist die zentrale Schutzmaßnahme. Er minimiert Ausfallzeiten, kontrolliert Kosten, stellt die Compliance mit einem komplexen Geflecht von Vorschriften wie NIS2 und DORA sicher und bewahrt vor allem das Vertrauen von Kunden und Partnern. Die Investition in den Aufbau dieser Fähigkeit ist kein Kostenblock; sie ist eine Investition in die Zukunftsfähigkeit und Resilienz des Unternehmens selbst.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council