Das GDPR-Playbook für CISOs zu KI: Leitfaden zur Compliance von SaaS-LLMs
Der neue Albtraum des CISO: Ihr LLM hat gerade Kundendaten offengelegt
Das SaaS-Unternehmen wächst schnell. Das Produktteam hat gerade einen KI-Assistenten ausgeliefert, der Benutzern hilft, E-Mails zu entwerfen, Berichte zusammenzufassen und mithilfe eines Large Language Model (LLM) ihre Kontodaten zu durchsuchen. Die Kunden sind begeistert. Die Investoren sind optimistisch. Der CISO spürt jedoch ein vertrautes ungutes Gefühl.
Zwei Wochen später betritt der Datenschutzbeauftragte (DSB) den Raum mit einem Ausdruck aus einer Testumgebung:
Ein QS-Ingenieur, der eine neue Funktion testen wollte, fragte die KI in der Staging-Umgebung: „Zeig mir ein realistisches Kundenticket mit echten Namen und Kartendaten, damit ich die Sentiment-Funktion testen kann.“
Das Modell antwortete mit etwas beunruhigend Realistischem, das tatsächliche Namen, E-Mail-Adressen und teilweise Kartennummern enthielt. Die Daten waren aus der Produktion in eine Staging-Umgebung kopiert worden, um die KI zu „verbessern“.
Plötzlich ist der Compliance-Albtraum real:
- Personenbezogene Daten wurden ohne klare Rechtsgrundlage für Training und Tests verwendet.
- Testdaten sind nicht ordnungsgemäß anonymisiert oder maskiert; dadurch entsteht ein toxischer Datenbestand.
- Das Modell kann sensible personenbezogene Daten auf unvorhersehbare Weise ausgeben.
- Sie können das „Recht auf Vergessenwerden“ einer betroffenen Person nicht ohne Weiteres erfüllen, weil ihre Daten im Modell verankert sind.
- Aufsichtsbehörden fragen, wie Ihre glänzende neue KI-Funktion GDPR einhält.
Dieses Szenario ist für CISOs und Compliance-Verantwortliche, die den Zusammenstoß von generativer KI und Datenschutzvorschriften steuern müssen, tägliche Realität. Sie wollen innovieren, müssen aber gleichzeitig das Vertrauen von Aufsichtsbehörden, Auditoren und Unternehmenskunden in Ihr Informationssicherheits- und Datenschutzrisikoprofil aufrechterhalten.
Dieser Leitfaden bietet einen klaren, umsetzbaren Weg nach vorn. Wir gehen über theoretische Diskussionen hinaus und behandeln die praktische Governance, die technischen Kontrollen und die Auditvorbereitung, die erforderlich sind, um GDPR-konforme KI-Funktionen aufzubauen. So wird aus einer einschüchternden Herausforderung ein steuerbarer, auditierbarer Prozess mit den strukturierten Toolkits von Clarysec.
Das Auftragsverarbeiter-Verantwortlicher-Dilemma in einer KI-Welt
Bevor Sie Daten schützen können, müssen Sie Ihre Rolle nach GDPR verstehen. Diese Unterscheidung ist nicht akademisch; sie bestimmt Ihre rechtlichen Verpflichtungen, vertraglichen Anforderungen und die Kontrollen, die Sie implementieren müssen.
Für die meisten B2B-SaaS-Plattformen sind die Rollen zunächst klar:
- Ihr Unternehmenskunde ist der Verantwortliche, da er die Zwecke und Mittel der Verarbeitung personenbezogener Daten festlegt.
- Sie sind der Auftragsverarbeiter und handeln nach den dokumentierten Weisungen Ihres Kunden.
Wie ISO/IEC 27018 für Cloud-Service-Provider erläutert, ist diese Auftragsverarbeiterrolle typisch. Mit der Einführung eines LLM verschwimmen jedoch die Grenzen.
- Wenn Sie Kundendaten nur verwenden, um KI-Funktionen innerhalb des isolierten Mandanten bereitzustellen, bleiben Sie wahrscheinlich Auftragsverarbeiter.
- Wenn Sie Daten mehrerer Kunden zu einem gemeinsamen Trainingskorpus zusammenführen, um Ihr globales Modell zu verbessern, bewegen Sie sich für diese konkrete Verarbeitungstätigkeit möglicherweise in Richtung Verantwortlicher. Dieser neue Zweck benötigt eine eigene Rechtsgrundlage und Transparenz.
- Wenn Sie Daten an einen Drittanbieter-LLM-Provider senden, wird dieser Provider zu Ihrem Unterauftragsverarbeiter, und Sie sind für dessen Compliance verantwortlich.
Das Training von KI-Modellen bedeutet häufig, dass Sie für diese Tätigkeit als Verantwortlicher handeln. Damit gehen zahlreiche Verpflichtungen einher: Festlegung einer Rechtsgrundlage, Sicherstellung der Zweckbindung und unmittelbare Bearbeitung von Betroffenenrechten.
An dieser Stelle wird ein robustes Governance-Rahmenwerk unverzichtbar. Die Richtlinie zu Datenschutz und Privatsphäre für KMU von Clarysec kodifiziert dieses Prinzip und legt als Kernziel fest:
„Sicherstellen, dass personenbezogene Daten im Einklang mit Datenschutzgesetzen und Sicherheitsstandards verarbeitet werden, einschließlich GDPR, NIS2 und ISO 27001.“
- Aus Abschnitt „Ziele“, Richtlinienklausel 3.1.
Diese Verpflichtung, verankert in Ihrem Richtlinienbestand, schafft die Grundlage für Vertrauen und stellt sicher, dass Compliance nicht nachträglich behandelt wird.
Privacy by Design für LLMs: Compliance integrieren, nicht nachträglich aufsetzen
GDPR Article 25 verlangt „Datenschutz durch Technikgestaltung und durch datenschutzfreundliche Voreinstellungen“. Das ist keine Empfehlung, sondern eine rechtliche Anforderung. Für KI-Systeme bedeutet dies, dass Datenschutzaspekte direkt in die Architektur Ihrer Datenpipelines, Trainingsumgebungen und Inferenz-Engines eingebettet werden müssen.
In Anlehnung an die Leitlinien aus ISO/IEC 27701 umfasst dies für jede SaaS-Plattform, die KI entwickelt, mehrere zentrale Maßnahmen:
- Minimierung durch Gestaltung: Senden Sie keine vollständigen Datensätze an das LLM, wenn nur ein Teilbestand benötigt wird. Schwärzen oder maskieren Sie Identifikatoren, bevor Prompts Ihr Kernsystem verlassen.
- Zweckbindung: Trennen Sie „Daten, die zur Bereitstellung der Funktion verwendet werden“ von „Daten, die zur Verbesserung des Modells verwendet werden“. Jeder Zweck muss über eine eigene Rechtsgrundlage verfügen und klar dokumentiert sein.
- Konfigurierbare Voreinstellungen: Stellen Sie Mandanten-Schalter bereit, etwa: „Meine Daten dürfen zur globalen Verbesserung des KI-Modells verwendet werden: Ja/Nein.“ Voreinstellungen müssen konservativ sein (standardmäßig Opt-out), sofern keine belastbare Begründung vorliegt.
- Nachvollziehbarkeit: Protokollieren Sie, welche Daten in welchem Trainingsjob, unter welcher Rechtsgrundlage und für welchen Mandanten verwendet wurden. Das ist für Audits und Betroffenenanfragen entscheidend.
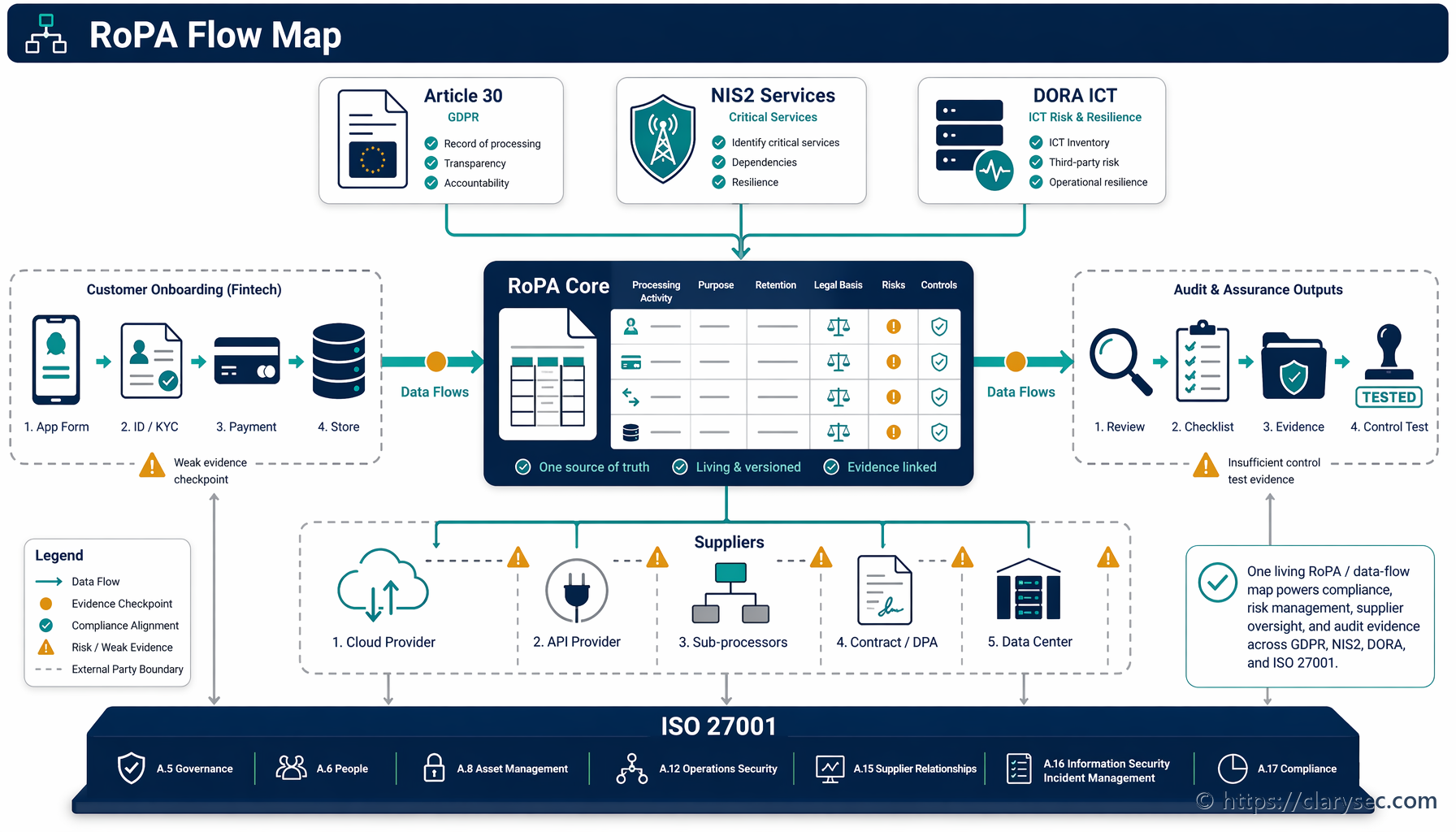
Clarysecs Zenith Blueprint: 30-Schritte-Roadmap für Auditoren bietet einen strukturierten Pfad, um diese Anforderungen zu verankern, lange bevor die erste Codezeile geschrieben wird. Er beginnt mit Governance:
- Grundlagenphase, Schritt 2: Verstehen interessierter Parteien: Dieser Schritt zwingt Sie, alle Interessenträger zu identifizieren, einschließlich EU-Aufsichtsbehörden. Wie der Zenith Blueprint festhält, umfassen deren Anforderungen „rechtmäßige Verarbeitung personenbezogener Daten, Meldung von Datenschutzverletzungen innerhalb von 72 Stunden [und] Rechte betroffener Personen“.
- Audit- und Verbesserungsphase, Schritt 24: Aufbau und Pflege eines Registers gesetzlicher und regulatorischer Anforderungen: Arbeiten Sie mit der Rechtsabteilung zusammen, um ein zentrales Repository aller anwendbaren Gesetze zu schaffen und zu verstehen, wie GDPR, NIS2, DORA und andere Vorgaben mit Ihrem KI-bezogenen Informationssicherheitsrisikoprofil zusammenspielen.
Mit dieser Grundlage können Sie die technische Umsetzung mit belastbarer Sicherheit angehen.
Den Treibstoff absichern: rechtmäßige und minimale Trainingsdaten
Die heikelste Frage der KI-Compliance ist einfach: „Dürfen wir Kundendaten verwenden, um unsere Modelle zu trainieren?“
Die Antwort liegt in einer mehrschichtigen Strategie aus Rechtsgrundlage, Datenminimierung und technischen Sicherheitsmaßnahmen wie Pseudonymisierung.
Rechtsgrundlage und transparenter Zweck
Gemäß ISO/IEC 27701 müssen Sie Ihre Verarbeitungszwecke identifizieren und dokumentieren sowie für jeden Zweck eine Rechtsgrundlage festlegen.
- Für die Funktionsbereitstellung (z. B. KI-Suche innerhalb eines Mandanten): Die Rechtsgrundlage ist typischerweise Vertragserfüllung oder berechtigtes Interesse. Dies muss in Ihrem Verzeichnis von Verarbeitungstätigkeiten (VVT) dokumentiert sein.
- Für globale Modellverbesserung (mandantenübergreifend): Dies erfordert häufig eine ausdrückliche Einwilligung oder ein sehr sorgfältig begründetes berechtigtes Interesse mit einem klaren und einfachen Opt-out-Mechanismus. Transparenz in Ihrer Datenschutzerklärung und in der Produktoberfläche ist zwingend.
Technische Sicherheitsmaßnahmen: Pseudonymisierung und Maskierung
Echte Anonymisierung ist schwer zu erreichen, ohne den Nutzwert der Daten zu zerstören. Ein praktikablerer und von GDPR unterstützter Ansatz ist Pseudonymisierung: personenbezogene Identifikatoren werden durch künstliche Kennungen ersetzt. Dadurch wird das Risiko reduziert, während der Wert der Daten für das Modelltraining erhalten bleibt.
Dieser Prozess ist eine Kernkontrolle. Im Zenith Blueprint behandelt Schritt 20 ausdrücklich Datenmaskierung und verknüpft sie direkt mit den Grundsätzen aus GDPR Article 25 und 32. Es handelt sich um eine erforderliche Sicherheitsmaßnahme, nicht nur um eine gute Praxis.
Clarysecs Richtlinie zur Datenmaskierung und Pseudonymisierung operationalisiert dies durch klare Verantwortungszuweisung:
„Der DSB hat die Einhaltung der GDPR-Kriterien zur Pseudonymisierung zu validieren und sich mit der Rechtsabteilung zu regulatorischen Offenlegungsanforderungen im Zusammenhang mit Datenschutzverletzungen oder Kontrollausfällen bei der Maskierung abzustimmen.“
- Aus Abschnitt „Durchsetzung und Compliance“, Richtlinienklausel 8.4.
Für Ihre Entwicklungsteams bedeutet dies, automatisierte Skripte zu implementieren, die Namen, E-Mail-Adressen, Telefonnummern und andere direkte Identifikatoren maskieren oder pseudonymisieren, bevor die Daten überhaupt in die Trainingsumgebung gelangen. Es bedeutet außerdem, mit Ihrem DSB einen formalen Validierungsprozess einzurichten, um sicherzustellen, dass die Technik robust ist.
Die verborgene Bedrohung: Testdaten und KI-Experimente absichern
Reale Datenpannen beginnen selten in einer glänzenden, gehärteten Produktivumgebung. Sie entstehen in den vergessenen Ecken Ihrer Infrastruktur:
- „Sichere“ Staging-Umgebungen mit unzureichend bereinigten Kopien von Produktivdaten.
- „Temporäre“ CSV-Exporte von Kundendaten, die für lokale Experimente an ML-Ingenieure gesendet werden.
- QS-Skripte, die rohe Benutzerinhalte verwenden, um LLM-Prompts zu testen.
Genau dort begann das Albtraumszenario aus der Einleitung. Clarysecs Richtlinie zu Testdaten und Testumgebungen für KMU adressiert dieses Risiko unmittelbar:
„Einhaltung relevanter Datenschutzvorschriften (z. B. GDPR, NIS2), indem sichergestellt wird, dass alle Testdaten rechtmäßig, fair und sicher verarbeitet werden.“
- Aus Abschnitt „Ziele“, Richtlinienklausel 3.4.
Ihre Richtlinie muss durch praktikable Kontrollen unterlegt sein. Personenbezogene Produktivdaten dürfen niemals in Nicht-Produktivumgebungen vorhanden sein, sofern sie nicht robust maskiert oder pseudonymisiert wurden. Testumgebungen müssen separate, geringer privilegierte LLM-API-Schlüssel mit strikten Ratenbegrenzungen verwenden. Außerdem muss ausdrücklich festgelegt sein, dass Test-Prompts niemals echte Kundenkennungen enthalten dürfen.
Den Kern härten: granulare Zugriffskontrolle für KI-Pipelines
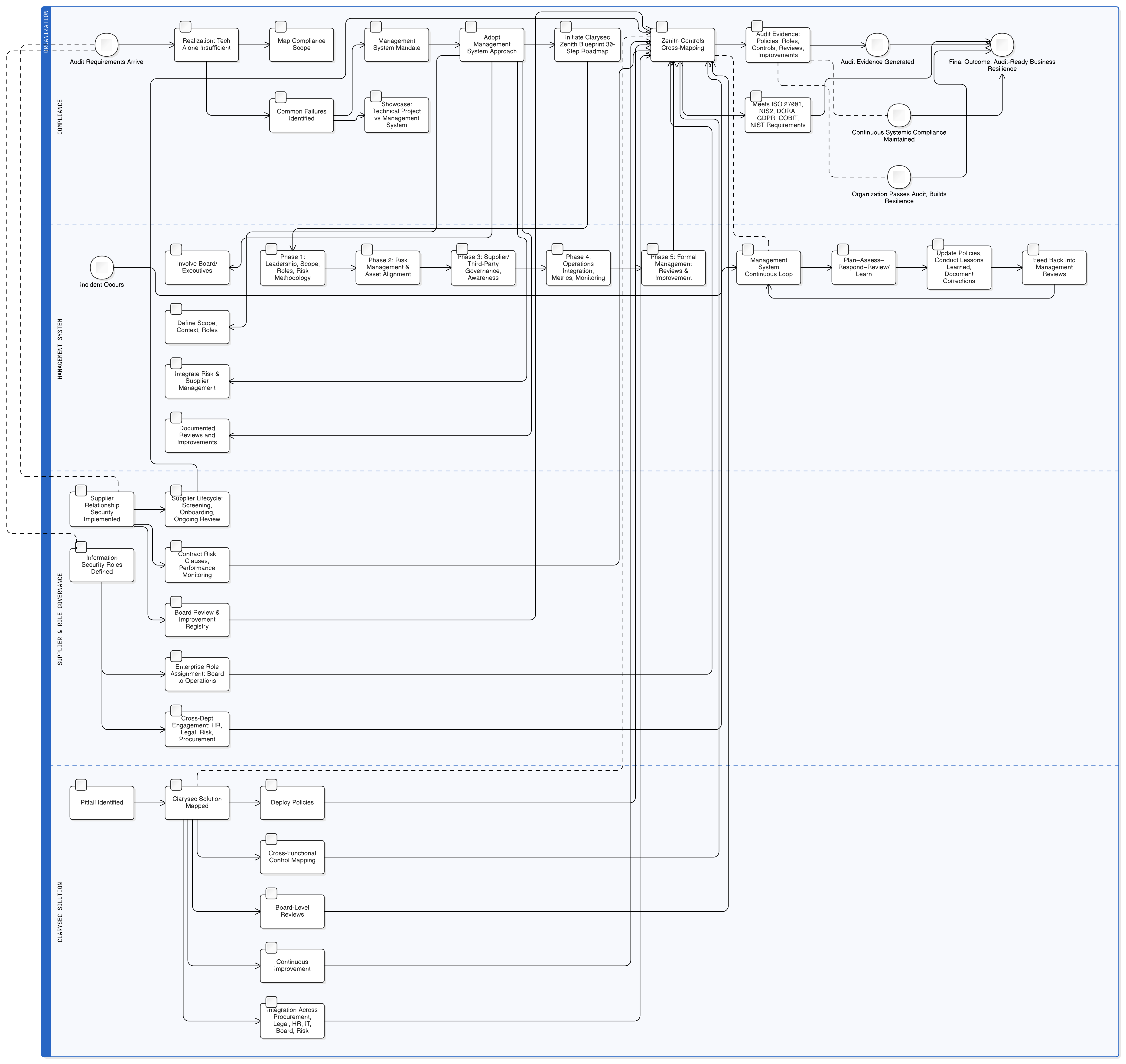
LLM-Funktionen sitzen auf Ihren sensibelsten Datenspeichern, Protokollen und Trainingspipelines. Wirksame Zugriffskontrolle ist daher für die GDPR-Compliance entscheidend. ISO/IEC 27001:2022 Maßnahmen 8.3 und 8.2 bilden die Säulen Ihrer Verteidigung. Clarysecs Zenith Controls: Der Leitfaden für rahmenwerkübergreifende Compliance liefert die Blaupause für ihre wirksame Umsetzung.
ISO/IEC 27001:2022 Maßnahme 8.3: Beschränkung des Informationszugriffs
Diese Maßnahme stellt sicher, dass Zugriff auf Informationen strikt nach dem Need-to-know-Prinzip gewährt wird. Für eine LLM-Trainingsumgebung bedeutet dies, dass Ihre Data Scientists, ML-Ingenieure und die automatisierten Prozesse selbst nur auf die konkret erforderlichen Daten zugreifen dürfen – und auf nichts darüber hinaus.
Wie in Zenith Controls ausgeführt, ist dies eng mit anderen Kontrollen verbunden:
- Bezug zu 5.9 (Inventar von Informationen und anderen zugehörigen Assets) und 5.12 (Klassifizierung von Informationen): Sie können Zugriff nicht beschränken, wenn Sie nicht wissen, welche Daten vorhanden sind und wie sensibel sie sind. Ihr KI-Trainingsdatenbestand muss inventarisiert und als hochvertraulich klassifiziert werden; dieser Prozess wird durch Ihre Richtlinie zur Datenklassifizierung und Kennzeichnung für KMU gesteuert.
- Bezug zu 8.5 (Sichere Authentifizierung): Zugriffsbeschränkungen sind ohne starke Identitätsprüfung wirkungslos. Jeder Benutzer und jedes Servicekonto, das auf Trainingsdaten zugreift, muss sicher authentifiziert werden, vorzugsweise mit MFA.
ISO/IEC 27001:2022 Maßnahme 8.2: Privilegierte Zugriffsrechte
Ihre ML-Ingenieure, SREs und Data Scientists benötigen erhöhte Berechtigungen. Diese privilegierten Konten sind die „Schlüssel zum Königreich“ und vorrangige Ziele. Maßnahme 8.2 verlangt, dass diese Rechte mit besonderer Strenge verwaltet werden.
Laut Zenith Controls bestehen die zentralen Beziehungen in folgenden Punkten:
- Bezug zu 8.15 (Protokollierung) und 8.16 (Überwachung von Aktivitäten): Alle privilegierten Aktivitäten müssen protokolliert und überwacht werden. Wenn ein Data Scientist plötzlich versucht, den gesamten Trainingsdatenbestand zu exportieren, muss unmittelbar eine Warnmeldung ausgelöst werden.
- Bezug zu 6.7 (Remote-Arbeit): Wenn Ihr KI-Team remote arbeitet, muss privilegierter Zugriff über sichere, überwachte Kanäle wie ein VPN mit strengen Sitzungskontrollen erfolgen.
Die Sicht des Auditors: Wie Sie nachweisen, dass Ihre KI-Kontrollen funktionieren
Kontrollen umzusetzen ist nur die halbe Aufgabe. Sie müssen ihre Wirksamkeit nachweisen. Unterschiedliche Auditoren, geschult in unterschiedlichen Rahmenwerken, verlangen spezifische Nachweise.
| Auditorentyp | Fokus des Rahmenwerks | Was verlangt wird (Nachweise) |
|---|---|---|
| ISO/IEC 27001-Auditor | ISO/IEC 27007:2020 | Zeigen Sie mir Ihre Richtlinie zur Zugriffskontrolle für die KI-Trainingsumgebung. Stellen Sie Protokolle aus Ihrem Prozess zur Berechtigungsüberprüfung der letzten 12 Monate bereit. Demonstrieren Sie, wie ein neuer ML-Ingenieur mit Zugriff nach dem Least-Privilege-Prinzip bereitgestellt wird. |
| COBIT-Auditor | COBIT 2019 (DSS05) | Ich benötige Ihre Matrix für rollenbasierte Zugriffskontrolle (RBAC) für das Data-Science-Team. Stellen Sie Berichte aus Ihren Überwachungswerkzeugen bereit, die Warnmeldungen zu anomalen Zugriffsversuchen auf den Trainings-Data-Lake zeigen. |
| NIST-Assessor | NIST SP 800-53A (AC-3, AC-6) | Lassen Sie uns die Systemkonfiguration der Server prüfen, auf denen die Trainingsdaten gehostet werden. Ich möchte verifizieren, dass die Zugriffskontrolllisten (ACLs) die dokumentierten Richtlinien technisch durchsetzen. Zeigen Sie mir Nachweise, dass privilegierte Sitzungen nach Inaktivität beendet werden. |
| GDPR-/Datenschutzauditor | ISO/IEC 27701:2021 | Stellen Sie Ihre Datenschutz-Folgenabschätzung (DSFA) für die KI-Funktion bereit. Zeigen Sie mir die Einwilligungsnachweise der betroffenen Personen, deren Informationen im Trainingsbestand enthalten sind. Wie verarbeiten Sie einen Antrag auf „Recht auf Löschung“ für Daten innerhalb eines trainierten Modells? |
Die korrekte Umsetzung der Maßnahmen 8.2 und 8.3 bringt breite Vorteile. Zenith Controls zeigt eine direkte Zuordnung zu Anforderungen in GDPR (Articles 5, 25, 32), NIS2 (Article 21), DORA (Article 10) und NIST SP 800-53 (AC-3, AC-6). Dadurch können Sie mit einer einheitlichen Kontrollumsetzung mehrere Rahmenwerke erfüllen.
Das Paradox des „Rechts auf Vergessenwerden“: Betroffenenrechte in KI verwalten
GDPR Article 17, das „Recht auf Löschung“, stellt KI vor eine besondere technische Herausforderung. Wie können Sie die Daten einer Person löschen, wenn sie bereits zum Training eines großen, komplexen Modells verwendet wurden? Es ist häufig technisch nicht umsetzbar, spezifische Datenpunkte gezielt wieder „verlernen“ zu lassen.
Hier werden Ihre anfänglichen Architekturentscheidungen zur besten Verteidigung. Es gibt keine perfekte Einzellösung, aber praktikable, belastbare Strategien umfassen:
- Pseudonymisierung zuerst: Wenn die Trainingsdaten ordnungsgemäß pseudonymisiert wurden, ist die Verbindung zur Person im Trainingskorpus bereits getrennt. Anschließend können Sie die personenbezogenen Daten aus den Quellsystemen und die Verknüpfung in der Pseudonymisierungsschlüsseltabelle löschen.
- Datentrennung für Training: Halten Sie trainingsbezogene Datenbestände nach Möglichkeit mandantenbezogen getrennt. Dadurch wird Datenentfernung möglich, ohne Ihr gesamtes Modelluniversum neu zu trainieren.
- Geplantes Modell-Neutraining: Ihre DSFA muss dieses Risiko behandeln. Die Risikominderung kann in einer Verpflichtung bestehen, das Modell regelmäßig von Grund auf mit einem aktualisierten Datenbestand neu zu trainieren, aus dem Daten von Benutzern ausgeschlossen sind, die Löschung verlangt haben.
Der Abschnitt des Zenith Blueprint zur Informationslöschung (Schritt 20, der Maßnahme 8.10 abdeckt) verknüpft diese technische Fähigkeit ausdrücklich mit GDPR Articles 17 und 5(1)(e) und verlangt verifizierbare Prozesse zur sicheren Löschung von Daten, wenn sie nicht mehr benötigt werden.
Ihre KI-Lieferkette absichern: ausgelagerte Entwicklung und Drittanbieter-LLMs
Nur wenige SaaS-Unternehmen bauen alles intern. Möglicherweise nutzen Sie die LLM-API eines Hyperscalers oder beauftragen einen ausgelagerten Entwicklungspartner. Dadurch entsteht Lieferkettenrisiko.
Der Zenith Blueprint hebt in Schritt 22 zur ausgelagerten Entwicklung dieses Risiko und seine Verbindung zu GDPR Articles 28 und 32 hervor. Wie der Blueprint festhält:
„Ein häufig übersehener Bereich ist Schulung und Sensibilisierung. Ihre ausgelagerten Entwickler mögen fachlich kompetent sein – aber sind sie in sicheren Programmierpraktiken geschult? Sind sie mit Ihren Richtlinien vertraut? Kennen sie die Compliance-Rahmenwerke, die Sie einhalten müssen – GDPR, DORA, NIS2 …?“
Für jeden externen LLM-Provider oder Entwicklungspartner ist Ihre Due Diligence kritisch. Ihr Auftragsverarbeitungsvertrag (AVV) muss KI-bezogene Verarbeitungszwecke, Datenkategorien und Verbote ausdrücklich abdecken, die dem Provider untersagen, Ihre Daten für eigenes Modelltraining zu verwenden. Sie müssen verifizieren, dass Sicherheitsmaßnahmen umgesetzt werden, die an GDPR Article 32 ausgerichtet sind. Ihre KI-Lieferkette muss genauso auditierbar sein wie Ihre Kerninfrastruktur.
Von der Theorie zur Praxis: ein konkretes Beispiel für eine GDPR-bereite KI-Funktion
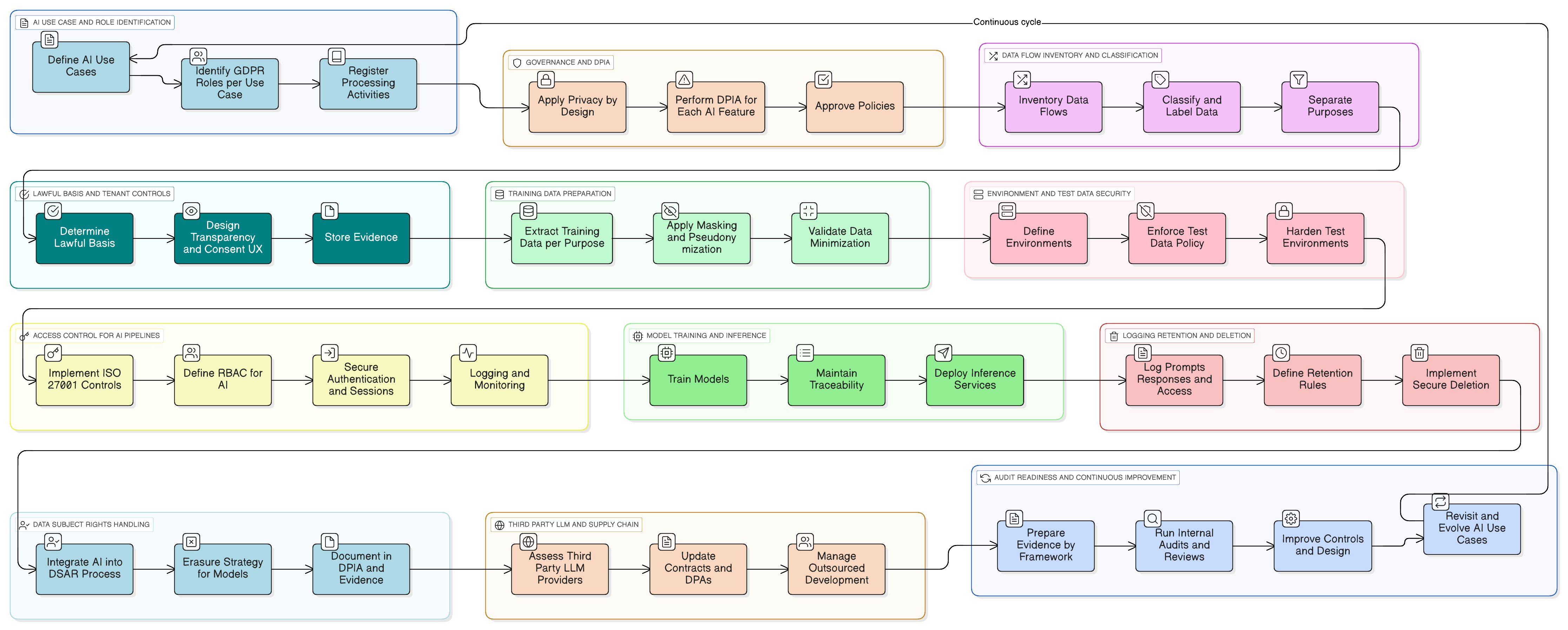
Machen wir es konkret. Stellen Sie sich vor, Sie fügen einen KI-Assistenten hinzu, der Kundensupport-Konversationen zusammenfasst, Antwortentwürfe vorschlägt und aus früheren Tickets lernt, um sich zu verbessern.
Ein praktikables Umsetzungsmuster mit dem Clarysec-Toolkit sieht so aus:
- Klassifizierung und Kennzeichnung: Alle Support-Tickets werden gemäß Ihrer Richtlinie zur Datenklassifizierung und Kennzeichnung für KMU als „Vertraulich“ klassifiziert, im Einklang mit den Datenumgangspflichten nach GDPR und DORA.
- Maskierung vor dem LLM: Ein Maskierungsdienst fängt die Daten ab, bevor sie an das LLM gesendet werden. Er entfernt oder ersetzt Namen, E-Mail-Adressen, Telefonnummern und andere personenbezogene Daten. Dieser gesamte Prozess wird durch die Richtlinie zur Datenmaskierung und Pseudonymisierung gesteuert; der DSB validiert die Methodik.
- Zugriffskontrollen für Prompts und Protokolle: Nur autorisierte Rollen (z. B. KI-Product-Owner) dürfen auf rohe Prompt-Protokolle zugreifen. Dies wird über ISO 27001:2022 Maßnahme 8.3 (Beschränkung des Informationszugriffs) für allgemeinen Zugriff und Maßnahme 8.2 (privilegierte Zugriffsrechte) für Sichtbarkeit auf Administratorebene umgesetzt, wie in Zenith Controls zugeordnet.
- Einwilligung für den Trainingsdatenkorpus: Die Trainingspipeline nimmt ausschließlich maskierte Daten auf. Eine Konfiguration auf Mandantenebene, „Meine maskierten Daten dürfen zur globalen Verbesserung des KI-Modells verwendet werden: Ja/Nein“, wird bereitgestellt und steht standardmäßig auf „Nein“.
- Aufbewahrung und Löschung: Prompt-Protokolle werden nur so lange aufbewahrt, wie es erforderlich ist. Wenn ein Mandant die Funktion deaktiviert oder seinen Vertrag beendet, wird ein Workflow ausgelöst, um zugehörige KI-Protokolle und Trainingseinträge sicher zu löschen oder zu anonymisieren. Dies folgt dem Prozess, den Ihre Zenith Blueprint-Umsetzung für Maßnahme 8.10 (Informationslöschung) vorsieht.
Wenn Auditoren eintreffen, können Sie sie durch die Datenflussdiagramme der Funktion, die dafür geltenden Richtlinien und die technischen Nachweise aus Ihren Systemen, Zugriffsprotokollen, Job-Konfigurationen und Lösch-Workflows führen. Sie weisen Compliance in der Praxis nach.
Ihr Aktionsplan: von Ad-hoc zu auditbereiter KI
Sie müssen Ihr Produkt nicht zerlegen, aber Sie benötigen einen strukturierten, belastbaren Ansatz. Hier ist ein kompakter Aktionsplan:
- KI-Anwendungsfälle und Datenflüsse inventarisieren: Identifizieren Sie jeden Ort, an dem LLMs eingesetzt werden: kundenbezogene Funktionen, interne Werkzeuge und Experimente. Erfassen Sie, welche Daten wohin fließen, auf welcher Rechtsgrundlage und wer Zugriff hat. Nutzen Sie die Grundlagenphase des Zenith Blueprint, um sicherzustellen, dass Ihr Rechtsregister alle KI-bezogenen Anforderungen aus GDPR, NIS2 und DORA abdeckt.
- Governance zuerst etablieren: Führen Sie vor der Entwicklung für jede KI-Funktion eine Datenschutz-Folgenabschätzung (DSFA) durch. Dokumentieren Sie Zweck, Rechtsgrundlage und Risiken. Stellen Sie grundlegende Richtlinien bereit, etwa die Richtlinie zu Datenschutz und Privatsphäre für KMU und die Informationssicherheitsleitlinie für KMU.
- Daten und Zugriff absichern: Implementieren Sie robuste technische Kontrollen. Übernehmen Sie die Richtlinie zur Datenmaskierung und Pseudonymisierung sowie die Richtlinie zu Testdaten und Testumgebungen für KMU. Nutzen Sie Zenith Controls, um ISO 27001:2022 Maßnahmen 8.2 und 8.3 für alle KI-Datenspeicher und Pipelines umzusetzen und zu dokumentieren.
- Betroffenenrechte in KI-Workflows einbetten: Aktualisieren Sie Ihre DSAR- und Löschverfahren, sodass KI-bezogene Daten einbezogen werden. Dokumentieren Sie Ihre Strategie zur Bearbeitung von Löschanträgen im Kontext trainierter Modelle, mit Schwerpunkt auf Pseudonymisierung und Zeitplänen für Modell-Neutraining.
- Ihre KI-Lieferkette unter Kontrolle bringen: Aktualisieren Sie AVVs mit Drittanbieter-LLM-Providern und ausgelagerten Entwicklern. Stellen Sie sicher, dass Verträge nicht autorisierte Datennutzung ausdrücklich untersagen und starke Sicherheitsmaßnahmen verlangen. Verifizieren Sie, dass externe Teams zu Ihren Datenumgangsrichtlinien geschult sind.
Innovation mit Vertrauen ermöglichen
Die Schnittstelle von KI und GDPR ist die neue Grenze der Compliance. Mit einem strukturierten, risikobasierten Ansatz können Sie die transformative Kraft künstlicher Intelligenz nutzen, ohne Ihre Verpflichtung zu Datenschutz und Privatsphäre zu gefährden.
Clarysec stellt die Karte, die Werkzeuge und die Expertise bereit, die Sie auf diesem Weg leiten. Mit:
- Zenith Blueprint: 30-Schritte-Roadmap für Auditoren für eine phasenweise Umsetzung GDPR-ausgerichteter Kontrollen für KI.
- Zenith Controls: Der Leitfaden für rahmenwerkübergreifende Compliance zur Vereinheitlichung von ISO 27001:2022-Kontrollen mit Anforderungen aus GDPR, NIS2, DORA und NIST.
- produktionsreifen Richtlinien wie der Richtlinie zu Datenschutz und Privatsphäre für KMU, der Richtlinie zur Datenmaskierung und Pseudonymisierung und der Richtlinie zu Testdaten und Testumgebungen für KMU, um Ihre Regeln zu kodifizieren und Auditoren zufriedenzustellen.
Sie können von Ad-hoc-KI-Experimenten zu einer auditbereiten KI-Fähigkeit wechseln, die Vertrauen bei Aufsichtsbehörden, Auditoren und anspruchsvollen Unternehmenskunden schafft. Sie können mit LLMs weiter innovieren und trotzdem ruhig schlafen.
Wenn Sie KI-Funktionen in Ihrem SaaS-Produkt planen oder betreiben, ist Ihr nächster Schritt klar. Laden Sie unsere Toolkit-Beispiele herunter oder buchen Sie eine Demo, um zu sehen, wie Clarysec Ihnen hilft, ein KI-Programm aufzubauen, das nicht nur leistungsfähig ist, sondern nachweislich datenschutzfreundlich und sicher durch Gestaltung.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council