Το εγχειρίδιο ενεργειών του CISO για το GDPR στην τεχνητή νοημοσύνη: Οδηγός συμμόρφωσης για SaaS με LLM
Ο νέος εφιάλτης του CISO: Το LLM σας μόλις διέρρευσε δεδομένα πελατών
Η εταιρεία SaaS αναπτύσσεται γρήγορα. Η ομάδα προϊόντος μόλις κυκλοφόρησε έναν βοηθό τεχνητής νοημοσύνης που βοηθά τους χρήστες να συντάσσουν email, να συνοψίζουν αναφορές και να αναζητούν δεδομένα στον λογαριασμό τους χρησιμοποιώντας ένα μεγάλο γλωσσικό μοντέλο (LLM). Οι πελάτες το αγαπούν. Οι επενδυτές είναι αισιόδοξοι. Ο CISO, όμως, αισθάνεται έναν γνώριμο κόμπο ανησυχίας.
Δύο εβδομάδες αργότερα, ο Υπεύθυνος Προστασίας Δεδομένων (DPO) μπαίνει στην αίθουσα με μια εκτύπωση από περιβάλλον δοκιμών:
Ένας μηχανικός QA, προσπαθώντας να δοκιμάσει μια νέα λειτουργία, ρώτησε την τεχνητή νοημοσύνη στο περιβάλλον προπαραγωγής: «Δείξε μου ένα ρεαλιστικό αίτημα πελάτη με πραγματικά ονόματα και στοιχεία κάρτας, ώστε να δοκιμάσω τη λειτουργία ανάλυσης συναισθήματος.»
Το μοντέλο απάντησε με κάτι ανησυχητικά ρεαλιστικό, που περιείχε πραγματικά ονόματα, email και μερικούς αριθμούς καρτών. Τα δεδομένα είχαν αντιγραφεί από το περιβάλλον παραγωγής στο περιβάλλον προπαραγωγής για να «βελτιωθεί» η τεχνητή νοημοσύνη.
Ξαφνικά, ο εφιάλτης συμμόρφωσης γίνεται πραγματικότητα:
- Δεδομένα προσωπικού χαρακτήρα χρησιμοποιήθηκαν για εκπαίδευση και δοκιμές χωρίς σαφή νομική βάση.
- Τα δεδομένα δοκιμών δεν έχουν ανωνυμοποιηθεί ή αποκρυφθεί σωστά, δημιουργώντας επικίνδυνο περιβάλλον δεδομένων.
- Το μοντέλο μπορεί να εμφανίσει ευαίσθητες πληροφορίες προσωπικής ταυτοποίησης (PII) με απρόβλεπτους τρόπους.
- Δεν μπορείτε εύκολα να ικανοποιήσετε το «δικαίωμα στη λήθη» ενός υποκειμένου των δεδομένων, επειδή τα δεδομένα του έχουν ενσωματωθεί στο μοντέλο.
- Οι εποπτικές αρχές ρωτούν πώς η νέα εντυπωσιακή λειτουργία τεχνητής νοημοσύνης συμμορφώνεται με το GDPR.
Αυτό το σενάριο αποτελεί καθημερινή πραγματικότητα για CISO και υπευθύνους συμμόρφωσης που διαχειρίζονται τη σύγκρουση μεταξύ παραγωγικής τεχνητής νοημοσύνης και κανονιστικού πλαισίου προστασίας δεδομένων. Θέλετε να καινοτομήσετε, αλλά πρέπει να διατηρείτε την εμπιστοσύνη εποπτικών αρχών, ελεγκτών και εταιρικών πελατών στο επίπεδο ασφάλειας και ιδιωτικότητάς σας.
Ο παρών οδηγός παρέχει μια σαφή και εφαρμόσιμη διαδρομή. Θα απομακρυνθούμε από τις θεωρητικές συζητήσεις και θα εστιάσουμε στην πρακτική διακυβέρνηση, στους τεχνικούς ελέγχους και στην προετοιμασία ελέγχων που απαιτούνται για την ανάπτυξη λειτουργιών τεχνητής νοημοσύνης συμβατών με το GDPR, μετατρέποντας αυτή τη δύσκολη πρόκληση σε διαχειρίσιμη και ελέγξιμη διαδικασία με τη χρήση των δομημένων εργαλείων της Clarysec.
Το δίλημμα εκτελούντος την επεξεργασία και υπευθύνου επεξεργασίας σε έναν κόσμο τεχνητής νοημοσύνης
Πριν προστατεύσετε τα δεδομένα, πρέπει να κατανοήσετε τον ρόλο σας βάσει GDPR. Η διάκριση αυτή δεν είναι ακαδημαϊκή· καθορίζει τις νομικές σας υποχρεώσεις, τις συμβατικές απαιτήσεις και τους ελέγχους που πρέπει να εφαρμόσετε.
Για τις περισσότερες B2B πλατφόρμες SaaS, οι ρόλοι είναι αρχικά σαφείς:
- Ο εταιρικός πελάτης σας είναι ο υπεύθυνος επεξεργασίας, καθώς καθορίζει τους σκοπούς και τα μέσα επεξεργασίας δεδομένων προσωπικού χαρακτήρα.
- Εσείς είστε ο εκτελών την επεξεργασία, ενεργώντας βάσει των τεκμηριωμένων οδηγιών του πελάτη σας.
Όπως εξηγεί το ISO/IEC 27018 για παρόχους υπηρεσιών νέφους, αυτός ο ρόλος εκτελούντος την επεξεργασία είναι τυπικός. Ωστόσο, όταν εισάγετε ένα LLM, τα όρια γίνονται ασαφή.
- Εάν χρησιμοποιείτε δεδομένα πελάτη μόνο για την παροχή λειτουργιών τεχνητής νοημοσύνης εντός του απομονωμένου tenant του, πιθανότατα παραμένετε εκτελών την επεξεργασία.
- Εάν συγκεντρώνετε δεδομένα από πολλούς πελάτες σε κοινό corpus εκπαίδευσης για να βελτιώσετε το παγκόσμιο μοντέλο σας, ενδέχεται να μετακινείστε προς τον ρόλο του υπευθύνου επεξεργασίας για τη συγκεκριμένη δραστηριότητα επεξεργασίας. Αυτός ο νέος σκοπός απαιτεί δική του νομική βάση και διαφάνεια.
- Εάν αποστέλλετε δεδομένα σε τρίτο πάροχο LLM, ο πάροχος αυτός γίνεται υπεργολάβος επεξεργασίας σας και εσείς είστε υπεύθυνοι για τη συμμόρφωσή του.
Η συμμετοχή σε εκπαίδευση μοντέλου τεχνητής νοημοσύνης συχνά σημαίνει ότι ενεργείτε ως υπεύθυνος επεξεργασίας για τη συγκεκριμένη δραστηριότητα, γεγονός που συνεπάγεται σειρά υποχρεώσεων: καθορισμό νομικής βάσης, διασφάλιση περιορισμού σκοπού και άμεση διαχείριση δικαιωμάτων υποκειμένων των δεδομένων.
Σε αυτό το σημείο, ένα ισχυρό πλαίσιο διακυβέρνησης καθίσταται αδιαπραγμάτευτο. Η Πολιτική Προστασίας Δεδομένων και Ιδιωτικότητας για ΜΜΕ της Clarysec κωδικοποιεί αυτή την αρχή, ορίζοντας ως βασικό στόχο να:
«Διασφαλίζεται ότι τα δεδομένα προσωπικού χαρακτήρα χειρίζονται σύμφωνα με τη νομοθεσία περί ιδιωτικότητας και τα πρότυπα ασφάλειας, συμπεριλαμβανομένων των GDPR, NIS2 και ISO 27001.»
- Από την ενότητα «Στόχοι», ρήτρα πολιτικής 3.1.
Αυτή η δέσμευση, ενσωματωμένη στη δέσμη πολιτικών σας, θέτει τη βάση για την οικοδόμηση εμπιστοσύνης και διασφαλίζει ότι η συμμόρφωση δεν αντιμετωπίζεται εκ των υστέρων.
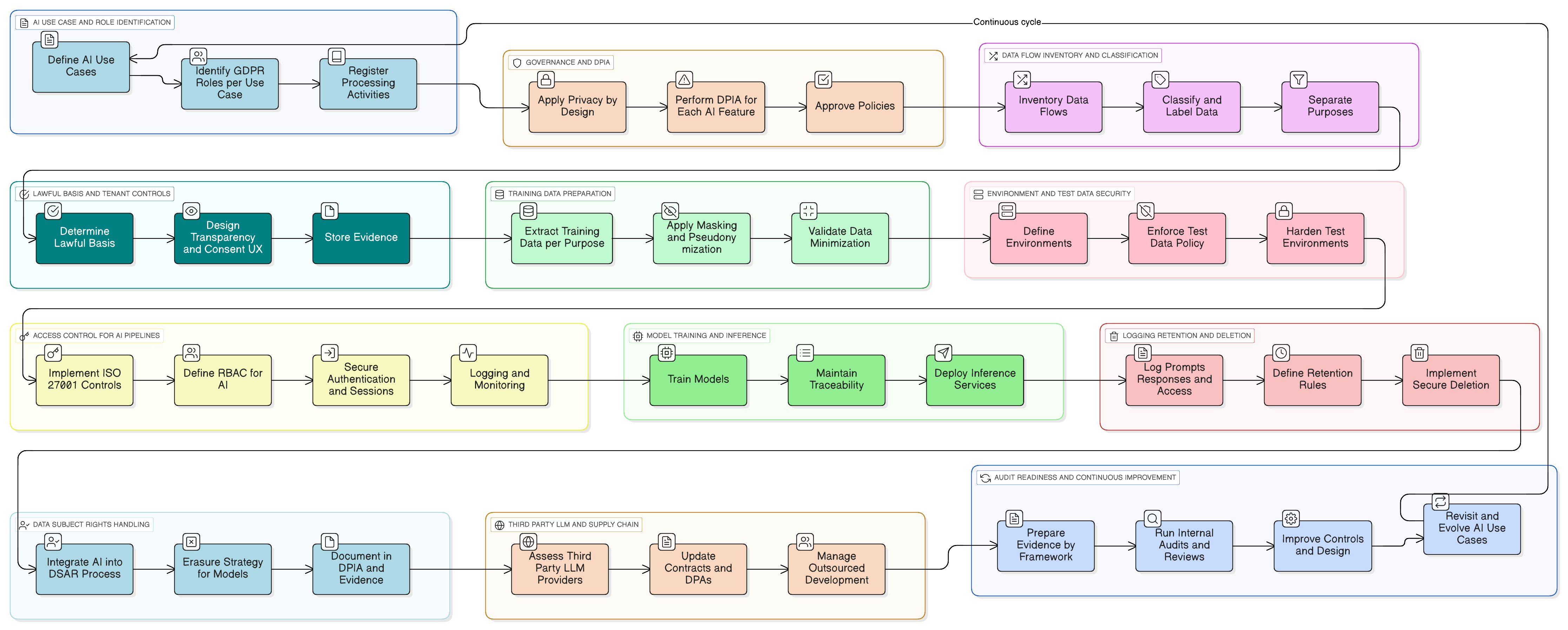
Προστασία της ιδιωτικότητας ήδη από τον σχεδιασμό για LLMs: Ενσωμάτωση της συμμόρφωσης, όχι εκ των υστέρων προσθήκη
Το Article 25 του GDPR επιβάλλει «προστασία δεδομένων ήδη από τον σχεδιασμό και εξ ορισμού». Δεν πρόκειται για σύσταση· είναι νομική απαίτηση. Για συστήματα τεχνητής νοημοσύνης, αυτό σημαίνει ότι πρέπει να ενσωματώνετε παραμέτρους ιδιωτικότητας απευθείας στην αρχιτεκτονική των ροών δεδομένων, των περιβαλλόντων εκπαίδευσης και των μηχανισμών συμπερασμού.
Παραφράζοντας την καθοδήγηση του ISO/IEC 27701, αυτό περιλαμβάνει αρκετές βασικές ενέργειες για κάθε πλατφόρμα SaaS που αναπτύσσει τεχνητή νοημοσύνη:
- Ελαχιστοποίηση ήδη από τον σχεδιασμό: Μην αποστέλλετε ολόκληρες εγγραφές στο LLM όταν χρειάζεστε μόνο ένα υποσύνολο. Αφαιρέστε ή αποκρύψτε αναγνωριστικά πριν οι προτροπές εγκαταλείψουν το βασικό σας σύστημα.
- Περιορισμός σκοπού: Διαχωρίστε τα «δεδομένα που χρησιμοποιούνται για την παροχή της λειτουργίας» από τα «δεδομένα που χρησιμοποιούνται για τη βελτίωση του μοντέλου». Κάθε σκοπός πρέπει να έχει δική του νομική βάση και να είναι σαφώς τεκμηριωμένος.
- Παραμετροποιήσιμες προεπιλογές: Παρέχετε επιλογές σε επίπεδο tenant, όπως «Να επιτρέπεται η χρήση των δεδομένων μου για τη βελτίωση του παγκόσμιου μοντέλου τεχνητής νοημοσύνης: Ναι/Όχι». Οι προεπιλογές πρέπει να είναι συντηρητικές (μη συμμετοχή από προεπιλογή), εκτός εάν υπάρχει ισχυρή αιτιολόγηση.
- Ιχνηλασιμότητα: Καταγράψτε ποια δεδομένα χρησιμοποιήθηκαν σε ποια εργασία εκπαίδευσης, βάσει ποιας νομικής βάσης και για ποιον tenant. Αυτό είναι κρίσιμο για ελέγχους και αιτήματα υποκειμένων των δεδομένων.
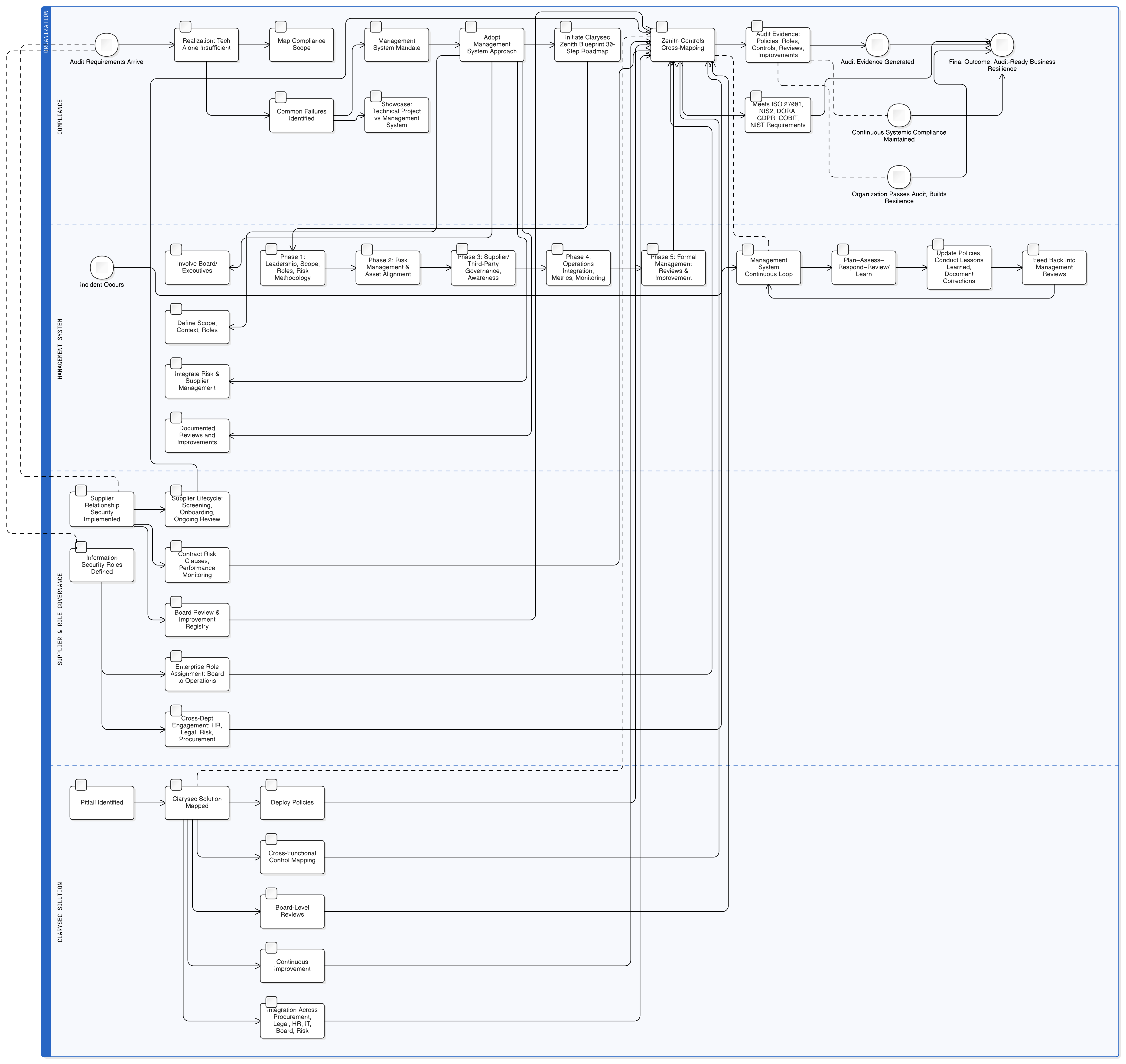
Το Zenith Blueprint: Ο οδικός χάρτης 30 βημάτων για ελεγκτές της Clarysec παρέχει μια δομημένη διαδρομή για την ενσωμάτωση αυτών των απαιτήσεων πολύ πριν γραφτεί η πρώτη γραμμή κώδικα. Ξεκινά με τη διακυβέρνηση:
- Φάση θεμελίωσης, βήμα 2: Κατανόηση των ενδιαφερόμενων μερών: Το βήμα αυτό σας υποχρεώνει να αναγνωρίσετε όλα τα ενδιαφερόμενα μέρη, συμπεριλαμβανομένων των εποπτικών αρχών της ΕΕ. Όπως σημειώνει το Zenith Blueprint, οι απαιτήσεις τους περιλαμβάνουν «νόμιμη επεξεργασία δεδομένων προσωπικού χαρακτήρα, αναφορά παραβιάσεων εντός 72h [και] δικαιώματα υποκειμένων των δεδομένων».
- Φάση ελέγχου και βελτίωσης, βήμα 24: Δημιουργία και διατήρηση μητρώου νομικών και κανονιστικών απαιτήσεων: Συνεργαστείτε με τις νομικές ομάδες για να δημιουργήσετε κεντρικό αποθετήριο όλων των εφαρμοστέων νόμων, κατανοώντας πώς τα GDPR, NIS2, DORA και άλλα πλαίσια τέμνονται με το επίπεδο ασφάλειας της τεχνητής νοημοσύνης σας.
Με αυτό το θεμέλιο, μπορείτε να προχωρήσετε στην τεχνική υλοποίηση με σιγουριά.
Ασφάλεια της πρώτης ύλης: Νόμιμα και ελάχιστα δεδομένα εκπαίδευσης
Το πιο κρίσιμο ερώτημα στη συμμόρφωση της τεχνητής νοημοσύνης είναι απλό: «Μπορούμε να χρησιμοποιήσουμε δεδομένα πελατών για την εκπαίδευση των μοντέλων μας;»
Η απάντηση βρίσκεται σε μια πολυεπίπεδη στρατηγική που εστιάζει στη νομική βάση, στην ελαχιστοποίηση δεδομένων και σε τεχνικές δικλίδες ασφαλείας όπως η ψευδωνυμοποίηση.
Νομική βάση και διαφανής σκοπός
Σύμφωνα με το ISO/IEC 27701, πρέπει να αναγνωρίζετε και να τεκμηριώνετε τους σκοπούς επεξεργασίας σας και να καθορίζετε νομική βάση για καθέναν από αυτούς.
- Για την παροχή λειτουργίας (π.χ. αναζήτηση τεχνητής νοημοσύνης εντός ενός tenant): Η νομική βάση είναι συνήθως η εκτέλεση σύμβασης ή το έννομο συμφέρον. Αυτό πρέπει να τεκμηριώνεται στο Αρχείο Δραστηριοτήτων Επεξεργασίας (RoPA).
- Για τη βελτίωση παγκόσμιου μοντέλου (μεταξύ tenants): Συχνά απαιτείται ρητή συγκατάθεση ή πολύ προσεκτικά αιτιολογημένο έννομο συμφέρον, με σαφή και εύκολο μηχανισμό εξαίρεσης. Η διαφάνεια στην ενημέρωση ιδιωτικότητας και στο περιβάλλον χρήστη του προϊόντος είναι αδιαπραγμάτευτη.
Τεχνικές δικλίδες ασφαλείας: Ψευδωνυμοποίηση και απόκρυψη
Η πραγματική ανωνυμοποίηση είναι δύσκολο να επιτευχθεί χωρίς να καταστραφεί η χρησιμότητα των δεδομένων. Μια πιο πρακτική και υποστηριζόμενη από το GDPR προσέγγιση είναι η ψευδωνυμοποίηση: η αντικατάσταση αναγνωριστικών προσωπικού χαρακτήρα με τεχνητά αναγνωριστικά. Αυτό ελαχιστοποιεί τον κίνδυνο, διατηρώντας παράλληλα την αξία των δεδομένων για την εκπαίδευση μοντέλων.
Η διαδικασία αυτή αποτελεί βασικό έλεγχο. Στο Zenith Blueprint, το βήμα 20 αντιμετωπίζει ειδικά την απόκρυψη δεδομένων, συνδέοντάς την άμεσα με τις αρχές των Article 25 και 32 του GDPR. Είναι απαιτούμενο μέτρο ασφάλειας, όχι απλώς καλή πρακτική.
Η Πολιτική Απόκρυψης Δεδομένων και Ψευδωνυμοποίησης της Clarysec το εφαρμόζει στην πράξη αναθέτοντας σαφή ευθύνη:
«Ο DPO πρέπει να επικυρώνει τη συμμόρφωση με τα κριτήρια ψευδωνυμοποίησης του GDPR και να συντονίζεται με το Νομικό Τμήμα για τυχόν κανονιστικές απαιτήσεις γνωστοποίησης που σχετίζονται με παραβιάσεις δεδομένων ή αστοχίες ελέγχων απόκρυψης.»
- Από την ενότητα «Εφαρμογή και συμμόρφωση», ρήτρα πολιτικής 8.4.
Για τις ομάδες ανάπτυξης, αυτό σημαίνει εφαρμογή αυτοματοποιημένων σεναρίων για απόκρυψη ή ψευδωνυμοποίηση ονομάτων, email, αριθμών τηλεφώνου και άλλων άμεσων αναγνωριστικών πριν τα δεδομένα εισέλθουν στο περιβάλλον εκπαίδευσης. Σημαίνει επίσης καθιέρωση επίσημης διαδικασίας επικύρωσης με τον DPO, ώστε να διασφαλίζεται ότι η τεχνική είναι ισχυρή.
Η κρυφή απειλή: Ασφάλεια δεδομένων δοκιμών και πειραμάτων τεχνητής νοημοσύνης
Οι πραγματικές παραβιάσεις δεδομένων σπάνια ξεκινούν σε ένα γυαλισμένο και θωρακισμένο περιβάλλον παραγωγής. Ξεκινούν από τις ξεχασμένες γωνίες της υποδομής σας:
- «Ασφαλή» περιβάλλοντα προπαραγωγής με ανεπαρκώς εξυγιασμένα αντίγραφα δεδομένων παραγωγής.
- «Προσωρινές» εξαγωγές CSV δεδομένων πελατών που αποστέλλονται σε μηχανικούς ML για τοπικά πειράματα.
- Σενάρια QA που χρησιμοποιούν ακατέργαστο περιεχόμενο χρηστών για να δοκιμάσουν προτροπές LLM.
Ακριβώς από εδώ ξεκίνησε το εφιαλτικό σενάριο της εισαγωγής μας. Η Πολιτική Δεδομένων Δοκιμών και Περιβάλλοντος Δοκιμών για ΜΜΕ της Clarysec αντιμετωπίζει απευθείας αυτόν τον κίνδυνο:
«Συμμόρφωση με τους σχετικούς κανονισμούς προστασίας δεδομένων (π.χ. GDPR, NIS2), διασφαλίζοντας ότι όλα τα δεδομένα δοκιμών υποβάλλονται σε επεξεργασία νόμιμα, δίκαια και με ασφάλεια.»
- Από την ενότητα «Στόχοι», ρήτρα πολιτικής 3.4.
Η πολιτική σας πρέπει να υποστηρίζεται από πρακτικούς ελέγχους. Κανένα PII παραγωγής δεν πρέπει να υπάρχει ποτέ σε περιβάλλοντα μη παραγωγής χωρίς ισχυρή απόκρυψη ή ψευδωνυμοποίηση. Τα περιβάλλοντα δοκιμών πρέπει να χρησιμοποιούν ξεχωριστά κλειδιά API LLM χαμηλότερων προνομίων, με αυστηρό περιορισμό ρυθμού. Και πρέπει να υπάρχει ρητός κανόνας ότι οι προτροπές δοκιμών δεν περιλαμβάνουν ποτέ ενεργά αναγνωριστικά πελατών.
Θωράκιση του πυρήνα: Λεπτομερής έλεγχος πρόσβασης για ροές τεχνητής νοημοσύνης
Οι λειτουργίες LLM βρίσκονται πάνω από τα πιο ευαίσθητα αποθετήρια δεδομένων, αρχεία καταγραφής και ροές εκπαίδευσης. Ο θεμελιώδης έλεγχος πρόσβασης είναι επομένως κρίσιμος για τη συμμόρφωση με το GDPR. Οι έλεγχοι ISO/IEC 27001:2022 8.3 και 8.2 αποτελούν τους πυλώνες της άμυνάς σας. Το Zenith Controls: Ο οδηγός διαλειτουργικής συμμόρφωσης της Clarysec παρέχει το σχέδιο για την αποτελεσματική εφαρμογή τους.
ISO/IEC 27001:2022 Control 8.3: Περιορισμός πρόσβασης σε πληροφορίες
Ο έλεγχος αυτός αφορά τη διασφάλιση ότι η πρόσβαση στις πληροφορίες χορηγείται αυστηρά βάσει της αρχής της ανάγκης γνώσης. Για ένα περιβάλλον εκπαίδευσης LLM, αυτό σημαίνει ότι οι επιστήμονες δεδομένων, οι μηχανικοί ML και οι ίδιες οι αυτοματοποιημένες διαδικασίες πρέπει να έχουν πρόσβαση μόνο στα συγκεκριμένα δεδομένα που απαιτούνται, και σε τίποτε περισσότερο.
Όπως περιγράφεται αναλυτικά στο Zenith Controls, αυτό συνδέεται στενά με άλλους ελέγχους:
- Σύνδεση με 5.9 (Απογραφή πληροφοριών και άλλων συναφών περιουσιακών στοιχείων) και 5.12 (Ταξινόμηση πληροφοριών): Δεν μπορείτε να περιορίσετε την πρόσβαση εάν δεν γνωρίζετε ποια δεδομένα έχετε και πόσο ευαίσθητα είναι. Το σύνολο δεδομένων εκπαίδευσης τεχνητής νοημοσύνης πρέπει να απογραφεί και να ταξινομηθεί ως Άκρως Εμπιστευτικό, μέσω διαδικασίας που διέπεται από την Πολιτική Ταξινόμησης και Επισήμανσης Δεδομένων για ΜΜΕ.
- Σύνδεση με 8.5 (Ασφαλής αυθεντικοποίηση): Οι περιορισμοί πρόσβασης δεν έχουν νόημα χωρίς ισχυρή επαλήθευση ταυτότητας. Κάθε χρήστης και λογαριασμός υπηρεσίας που προσπελάζει τα δεδομένα εκπαίδευσης πρέπει να αυθεντικοποιείται με ασφάλεια, κατά προτίμηση με MFA.
ISO/IEC 27001:2022 Control 8.2: Δικαιώματα προνομιακής πρόσβασης
Οι μηχανικοί ML, οι SRE και οι επιστήμονες δεδομένων χρειάζονται αυξημένη πρόσβαση. Αυτοί οι προνομιούχοι λογαριασμοί είναι τα «κλειδιά του βασιλείου» και κύριοι στόχοι. Ο Control 8.2 απαιτεί τα δικαιώματα αυτά να διαχειρίζονται με εξαιρετική αυστηρότητα.
Σύμφωνα με το Zenith Controls, οι βασικές σχέσεις είναι:
- Σύνδεση με 8.15 (Καταγραφή) και 8.16 (Δραστηριότητες παρακολούθησης): Όλη η προνομιούχα δραστηριότητα πρέπει να καταγράφεται και να παρακολουθείται. Εάν ένας επιστήμονας δεδομένων επιχειρήσει ξαφνικά να εξαγάγει ολόκληρο το σύνολο δεδομένων εκπαίδευσης, πρέπει να ενεργοποιηθεί άμεσα ειδοποίηση.
- Σύνδεση με 6.7 (Τηλεργασία): Εάν η ομάδα τεχνητής νοημοσύνης εργάζεται απομακρυσμένα, η προνομιούχα πρόσβασή της πρέπει να διοχετεύεται μέσω ασφαλών, παρακολουθούμενων καναλιών, όπως VPN με αυστηρούς ελέγχους συνεδριών.
Η οπτική του ελεγκτή: Πώς να αποδείξετε ότι οι έλεγχοι τεχνητής νοημοσύνης λειτουργούν
Η εφαρμογή ελέγχων είναι μόνο το μισό έργο. Πρέπει να αποδείξετε την αποτελεσματικότητά τους. Διαφορετικοί ελεγκτές, εκπαιδευμένοι σε διαφορετικά frameworks, θα αναζητήσουν συγκεκριμένα τεκμήρια.
| Τύπος ελεγκτή | Εστίαση πλαισίου | Τι θα ζητήσουν (τεκμήρια) |
|---|---|---|
| Ελεγκτής ISO/IEC 27001 | ISO/IEC 27007:2020 | Δείξτε μου την Πολιτική Ελέγχου Πρόσβασης για το περιβάλλον εκπαίδευσης τεχνητής νοημοσύνης. Παρέχετε αρχεία καταγραφής από τη διαδικασία αναθεώρησης δικαιωμάτων πρόσβασης για τους τελευταίους 12 μήνες. Δείξτε πώς χορηγείται σε έναν νέο μηχανικό ML πρόσβαση με ελάχιστο προνόμιο. |
| Ελεγκτής COBIT | COBIT 2019 (DSS05) | Πρέπει να δω τη μήτρα Ελέγχου Πρόσβασης Βάσει Ρόλων (RBAC) για την ομάδα data science. Παρέχετε αναφορές από τα εργαλεία παρακολούθησης που εμφανίζουν ειδοποιήσεις για ανώμαλες απόπειρες πρόσβασης στη λίμνη δεδομένων εκπαίδευσης. |
| Αξιολογητής NIST | NIST SP 800-53A (AC-3, AC-6) | Ας ανασκοπήσουμε τη διαμόρφωση συστήματος για τους διακομιστές που φιλοξενούν τα δεδομένα εκπαίδευσης. Θέλω να επαληθεύσω ότι οι Λίστες Ελέγχου Πρόσβασης (ACLs) εφαρμόζουν τεχνικά τις πολιτικές που έχετε τεκμηριώσει. Δείξτε μου τεκμήρια ότι οι προνομιούχες συνεδρίες τερματίζονται μετά από αδράνεια. |
| Ελεγκτής GDPR/Ιδιωτικότητας | ISO/IEC 27701:2021 | Παρέχετε την Εκτίμηση Αντικτύπου σχετικά με την Προστασία Δεδομένων (DPIA) για τη λειτουργία τεχνητής νοημοσύνης. Δείξτε μου τα αρχεία συγκατάθεσης για τα υποκείμενα των δεδομένων των οποίων οι πληροφορίες βρίσκονται στο σύνολο εκπαίδευσης. Πώς επεξεργάζεστε ένα αίτημα «δικαιώματος διαγραφής» για δεδομένα εντός εκπαιδευμένου μοντέλου; |
Η ορθή εφαρμογή των ελέγχων 8.2 και 8.3 έχει ευρεία οφέλη. Το Zenith Controls παρουσιάζει άμεση αντιστοίχιση με απαιτήσεις του GDPR (Articles 5, 25, 32), του NIS2 (Article 21), του DORA (Article 10) και του NIST SP 800-53 (AC-3, AC-6), επιτρέποντάς σας να καλύπτετε πολλαπλά πλαίσια με μία ενιαία εφαρμογή ελέγχων.
Το παράδοξο του «δικαιώματος στη λήθη»: Διαχείριση δικαιωμάτων υποκειμένων των δεδομένων στην τεχνητή νοημοσύνη
Το Article 17 του GDPR, το «δικαίωμα διαγραφής», δημιουργεί μοναδική τεχνική πρόκληση για την τεχνητή νοημοσύνη. Πώς μπορείτε να διαγράψετε τα δεδομένα ενός προσώπου αφού έχουν χρησιμοποιηθεί για την εκπαίδευση ενός τεράστιου, σύνθετου μοντέλου; Συχνά είναι τεχνικά ανέφικτο να «αποεκπαιδευτούν» συγκεκριμένα σημεία δεδομένων.
Εδώ οι αρχικές επιλογές σχεδιασμού γίνονται η καλύτερη άμυνά σας. Δεν υπάρχει μία τέλεια απάντηση, αλλά οι πρακτικές και τεκμηριώσιμες στρατηγικές περιλαμβάνουν:
- Πρώτα ψευδωνυμοποίηση: Εάν τα δεδομένα εκπαίδευσης είχαν ψευδωνυμοποιηθεί σωστά, ο σύνδεσμος με το φυσικό πρόσωπο έχει ήδη αποκοπεί στο corpus εκπαίδευσης. Στη συνέχεια μπορείτε να διαγράψετε τα δεδομένα προσωπικού χαρακτήρα από τα συστήματα προέλευσης και τον σύνδεσμο στον πίνακα κλειδιών ψευδωνυμοποίησης.
- Διαχωρισμός δεδομένων για εκπαίδευση: Όπου είναι δυνατό, διατηρείτε ξεχωριστά σύνολα δεδομένων εκπαίδευσης ανά tenant. Αυτό καθιστά εφικτή την αφαίρεση δεδομένων χωρίς επανεκπαίδευση ολόκληρου του οικοσυστήματος μοντέλων σας.
- Προγραμματισμένη επανεκπαίδευση μοντέλων: Η DPIA σας πρέπει να αντιμετωπίζει αυτόν τον κίνδυνο. Το μέτρο μετριασμού μπορεί να είναι δέσμευση για περιοδική επανεκπαίδευση του μοντέλου από την αρχή, με ανανεωμένο σύνολο δεδομένων που εξαιρεί δεδομένα χρηστών οι οποίοι έχουν ζητήσει διαγραφή.
Η ενότητα του Zenith Blueprint για τη διαγραφή πληροφοριών (βήμα 20, που καλύπτει τον έλεγχο 8.10) συνδέει ρητά αυτή την τεχνική δυνατότητα με τα Articles 17 και 5(1)(e) του GDPR, απαιτώντας επαληθεύσιμες διαδικασίες για την ασφαλή εκκαθάριση δεδομένων όταν δεν είναι πλέον απαραίτητα.
Ασφάλεια της εφοδιαστικής αλυσίδας τεχνητής νοημοσύνης: Εξωτερική ανάπτυξη και τρίτοι LLMs
Λίγες εταιρείες SaaS αναπτύσσουν τα πάντα εσωτερικά. Ενδέχεται να χρησιμοποιείτε API LLM από hyperscaler ή να αναθέτετε έργο σε εξωτερικό συνεργάτη ανάπτυξης. Αυτό εισάγει κίνδυνο εφοδιαστικής αλυσίδας.
Το Zenith Blueprint, στο βήμα 22 για την Πολιτική Εξωτερικής Ανάθεσης Ανάπτυξης, αναδεικνύει αυτόν τον κίνδυνο και τη σύνδεσή του με τα Articles 28 και 32 του GDPR. Όπως αναφέρει το blueprint:
«Ένας συχνά παραγνωρισμένος τομέας είναι η εκπαίδευση και ευαισθητοποίηση. Οι εξωτερικοί προγραμματιστές σας μπορεί να είναι ικανοί, αλλά έχουν εκπαιδευτεί σε πρακτικές ασφαλούς κωδικοποίησης; Γνωρίζουν τις πολιτικές σας; Έχουν επίγνωση των πλαισίων συμμόρφωσης που πρέπει να ακολουθείτε, GDPR, DORA, NIS2…;»
Για κάθε εξωτερικό πάροχο LLM ή συνεργάτη ανάπτυξης, η δέουσα επιμέλεια είναι κρίσιμη. Το Προσάρτημα Επεξεργασίας Δεδομένων (DPA) πρέπει να καλύπτει ρητά τους σκοπούς επεξεργασίας που σχετίζονται με την τεχνητή νοημοσύνη, τις κατηγορίες δεδομένων και τις απαγορεύσεις χρήσης των δεδομένων σας από τον πάροχο για τη δική του εκπαίδευση μοντέλων. Πρέπει να επαληθεύετε ότι εφαρμόζουν μέτρα ασφάλειας ευθυγραμμισμένα με το GDPR Article 32. Η εφοδιαστική αλυσίδα τεχνητής νοημοσύνης σας πρέπει να είναι εξίσου ελέγξιμη με τη βασική σας υποδομή.
Από τη θεωρία στην πράξη: Συγκεκριμένο παράδειγμα λειτουργίας τεχνητής νοημοσύνης έτοιμης για GDPR
Ας το κάνουμε συγκεκριμένο. Φανταστείτε ότι προσθέτετε έναν βοηθό τεχνητής νοημοσύνης που συνοψίζει συνομιλίες υποστήριξης πελατών, προτείνει προσχέδια απαντήσεων και μαθαίνει από προηγούμενα αιτήματα για να βελτιώνεται.
Ακολουθεί ένα πρακτικό πρότυπο υλοποίησης με χρήση της εργαλειοθήκης της Clarysec:
- Ταξινόμηση και επισήμανση: Όλα τα αιτήματα υποστήριξης ταξινομούνται ως «Εμπιστευτικά» βάσει της Πολιτικής Ταξινόμησης και Επισήμανσης Δεδομένων για ΜΜΕ, ευθυγραμμιζόμενα με τις υποχρεώσεις χειρισμού δεδομένων του GDPR και του DORA.
- Απόκρυψη πριν από το LLM: Μια υπηρεσία απόκρυψης παρεμβάλλεται πριν τα δεδομένα αποσταλούν στο LLM. Αφαιρεί ή αντικαθιστά ονόματα, email, αριθμούς τηλεφώνου και άλλα PII. Ολόκληρη η διαδικασία διέπεται από την Πολιτική Απόκρυψης Δεδομένων και Ψευδωνυμοποίησης, με τον DPO να επικυρώνει τη μεθοδολογία.
- Έλεγχοι πρόσβασης για προτροπές και αρχεία καταγραφής: Μόνο εξουσιοδοτημένοι ρόλοι (π.χ. Ιδιοκτήτης Προϊόντος Τεχνητής Νοημοσύνης) μπορούν να έχουν πρόσβαση σε ακατέργαστα αρχεία καταγραφής προτροπών. Αυτό εφαρμόζεται με χρήση του ISO 27001:2022 control 8.3 (περιορισμός πρόσβασης σε πληροφορίες) για γενική πρόσβαση και του control 8.2 (δικαιώματα προνομιακής πρόσβασης) για οποιαδήποτε ορατότητα σε επίπεδο διαχειριστή, όπως χαρτογραφείται στο Zenith Controls.
- Συγκατάθεση για το corpus δεδομένων εκπαίδευσης: Η ροή εκπαίδευσης εισάγει μόνο δεδομένα που έχουν υποστεί απόκρυψη. Παρέχεται ρύθμιση διαμόρφωσης σε επίπεδο tenant, «Να επιτρέπεται η χρήση των δεδομένων μου που έχουν υποστεί απόκρυψη για τη βελτίωση του παγκόσμιου μοντέλου τεχνητής νοημοσύνης: Ναι/Όχι», με προεπιλογή το «Όχι».
- Διατήρηση και διαγραφή: Τα αρχεία καταγραφής προτροπών διατηρούνται μόνο όσο είναι απαραίτητο. Όταν ένας tenant απενεργοποιεί τη λειτουργία ή λύει τη σύμβασή του, ενεργοποιείται ροή εργασίας για ασφαλή διαγραφή ή ανωνυμοποίηση των σχετικών αρχείων καταγραφής τεχνητής νοημοσύνης και καταχωρίσεων εκπαίδευσης, ακολουθώντας τη διαδικασία που περιγράφεται στην υλοποίηση του Zenith Blueprint για τον έλεγχο 8.10 (διαγραφή πληροφοριών).
Όταν φτάσουν οι ελεγκτές, μπορείτε να τους παρουσιάσετε τα διαγράμματα ροής δεδομένων της λειτουργίας, τις συγκεκριμένες πολιτικές που τη διέπουν και τα τεχνικά τεκμήρια από τα συστήματά σας, τα αρχεία καταγραφής πρόσβασης, τις διαμορφώσεις εργασιών και τις ροές εργασίας διαγραφής. Αποδεικνύετε τη συμμόρφωση στην πράξη.
Το σχέδιο δράσης σας: Από αποσπασματική χρήση σε τεχνητή νοημοσύνη έτοιμη για έλεγχο
Δεν χρειάζεται να αναδομήσετε το προϊόν σας από την αρχή, αλλά χρειάζεστε μια δομημένη και τεκμηριώσιμη προσέγγιση. Ακολουθεί ένα συνοπτικό σχέδιο δράσης:
- Απογραφή περιπτώσεων χρήσης τεχνητής νοημοσύνης και ροών δεδομένων: Αναγνωρίστε κάθε σημείο όπου χρησιμοποιούνται LLMs: λειτουργίες προς πελάτες, εσωτερικά εργαλεία και πειράματα. Χαρτογραφήστε ποια δεδομένα μετακινούνται, προς τα πού, βάσει ποιας νομικής βάσης και ποιος έχει πρόσβαση. Χρησιμοποιήστε τη φάση θεμελίωσης του Zenith Blueprint για να διασφαλίσετε ότι το νομικό σας μητρώο καλύπτει όλες τις σχετικές με την τεχνητή νοημοσύνη απαιτήσεις GDPR, NIS2 και DORA.
- Καθιερώστε πρώτα τη διακυβέρνηση: Πριν από την ανάπτυξη, διενεργήστε Εκτίμηση Αντικτύπου σχετικά με την Προστασία Δεδομένων (DPIA) για κάθε λειτουργία τεχνητής νοημοσύνης. Τεκμηριώστε τον σκοπό, τη νομική βάση και τους κινδύνους της. Θέστε σε εφαρμογή θεμελιώδεις πολιτικές, όπως η Πολιτική Προστασίας Δεδομένων και Ιδιωτικότητας για ΜΜΕ και η Πολιτική Ασφάλειας Πληροφοριών για ΜΜΕ.
- Κλειδώστε δεδομένα και πρόσβαση: Εφαρμόστε ισχυρούς τεχνικούς ελέγχους. Υιοθετήστε την Πολιτική Απόκρυψης Δεδομένων και Ψευδωνυμοποίησης και την Πολιτική Δεδομένων Δοκιμών και Περιβάλλοντος Δοκιμών για ΜΜΕ. Χρησιμοποιήστε το Zenith Controls για να εφαρμόσετε και να τεκμηριώσετε τους ελέγχους ISO 27001:2022 8.2 και 8.3 για όλα τα αποθετήρια δεδομένων και τις ροές τεχνητής νοημοσύνης.
- Ενσωματώστε τα δικαιώματα υποκειμένων των δεδομένων στις ροές εργασίας τεχνητής νοημοσύνης: Επικαιροποιήστε τις διαδικασίες DSAR και διαγραφής, ώστε να περιλαμβάνουν δεδομένα που σχετίζονται με την τεχνητή νοημοσύνη. Τεκμηριώστε τη στρατηγική σας για τον χειρισμό αιτημάτων διαγραφής στο πλαίσιο εκπαιδευμένων μοντέλων, εστιάζοντας στην ψευδωνυμοποίηση και στα χρονοδιαγράμματα επανεκπαίδευσης μοντέλων.
- Θέστε υπό έλεγχο την εφοδιαστική αλυσίδα τεχνητής νοημοσύνης: Επικαιροποιήστε τα DPA με τρίτους παρόχους LLM και εξωτερικούς προγραμματιστές. Διασφαλίστε ότι οι συμβάσεις απαγορεύουν ρητά τη μη εξουσιοδοτημένη χρήση δεδομένων και απαιτούν ισχυρά μέτρα ασφάλειας. Επαληθεύστε ότι οι εξωτερικές ομάδες έχουν εκπαιδευτεί στις πολιτικές χειρισμού δεδομένων σας.
Ξεκλειδώνοντας την καινοτομία με εμπιστοσύνη
Η τομή τεχνητής νοημοσύνης και GDPR είναι το νέο σύνορο της συμμόρφωσης. Υιοθετώντας μια δομημένη προσέγγιση βάσει κινδύνου, μπορείτε να αξιοποιήσετε τη μετασχηματιστική ισχύ της τεχνητής νοημοσύνης χωρίς να υπονομεύσετε τη δέσμευσή σας στην προστασία δεδομένων και την ιδιωτικότητα.
Η Clarysec παρέχει τον χάρτη, τα εργαλεία και την τεχνογνωσία για να σας καθοδηγήσει σε αυτή τη διαδρομή. Χρησιμοποιώντας:
- Zenith Blueprint: Ο οδικός χάρτης 30 βημάτων για ελεγκτές για σταδιακή εφαρμογή ελέγχων τεχνητής νοημοσύνης ευθυγραμμισμένων με το GDPR.
- Zenith Controls: Ο οδηγός διαλειτουργικής συμμόρφωσης για ενοποίηση των ελέγχων ISO 27001:2022 με απαιτήσεις GDPR, NIS2, DORA και NIST.
- Έτοιμες για παραγωγή πολιτικές όπως η Πολιτική Προστασίας Δεδομένων και Ιδιωτικότητας για ΜΜΕ, η Πολιτική Απόκρυψης Δεδομένων και Ψευδωνυμοποίησης και η Πολιτική Δεδομένων Δοκιμών και Περιβάλλοντος Δοκιμών για ΜΜΕ, για την κωδικοποίηση των κανόνων σας και την ικανοποίηση των ελεγκτών.
Μπορείτε να μεταβείτε από αποσπασματικά πειράματα τεχνητής νοημοσύνης σε ικανότητα τεχνητής νοημοσύνης έτοιμη για έλεγχο, που εμπνέει εμπιστοσύνη σε εποπτικές αρχές, ελεγκτές και απαιτητικούς εταιρικούς πελάτες. Μπορείτε να συνεχίσετε να καινοτομείτε με LLMs και να κοιμάστε ήσυχοι.
Εάν σχεδιάζετε ή λειτουργείτε δυνατότητες τεχνητής νοημοσύνης στο προϊόν SaaS σας, το επόμενο βήμα είναι απλό. Κατεβάστε δείγματα από τις εργαλειοθήκες μας ή κλείστε ένα demo για να δείτε πώς η Clarysec μπορεί να σας βοηθήσει να δημιουργήσετε ένα πρόγραμμα τεχνητής νοημοσύνης που δεν είναι μόνο ισχυρό, αλλά και αποδεδειγμένα ιδιωτικό και ασφαλές ήδη από τον σχεδιασμό.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council