Anatomía de una brecha de seguridad: guía para fabricantes sobre respuesta a incidentes conforme a ISO 27001
Fragmento destacado
Una respuesta eficaz a incidentes de seguridad de la información minimiza el daño derivado de las brechas de seguridad y asegura la resiliencia operativa. Esta guía proporciona un marco paso a paso basado en ISO 27001 para ayudar a los fabricantes a prepararse, responder y recuperarse ante ciberataques reales, al tiempo que cumplen exigencias complejas de cumplimiento normativo como NIS2 y DORA.
Introducción
La alerta aparece a las 2:17 AM. El servidor central de un fabricante mediano de piezas de automoción no responde y los monitores de la línea de producción muestran una nota de ransomware. Cada minuto de indisponibilidad cuesta miles en producción perdida y aumenta el riesgo de incumplir acuerdos de nivel de servicio estrictos de la cadena de suministro. No es un simulacro. Para el director de seguridad de la información, este es el momento en el que años de planificación, redacción de políticas y formación se someten a la prueba definitiva.
Tener un plan de respuesta a incidentes almacenado en un servidor es una cosa; ejecutarlo bajo presión extrema es otra muy distinta. Para los fabricantes, el nivel de exposición es especialmente alto. Un incidente de ciberseguridad no solo compromete datos; detiene la producción, interrumpe cadenas de suministro físicas y puede poner en peligro la seguridad de los trabajadores.
Esta guía va más allá de los procedimientos operativos teóricos para ofrecer una hoja de ruta práctica, basada en escenarios reales, para crear y gestionar un programa de respuesta a incidentes que funcione. Analizaremos la anatomía de la respuesta ante una brecha de seguridad, apoyándonos en el sólido marco de ISO/IEC 27001, y mostraremos cómo construir un programa resiliente que no solo permita recuperarse de un ataque, sino que también satisfaga a auditores y reguladores.
Qué está en juego: el efecto dominó de una brecha de seguridad en fabricación
Cuando los sistemas de un fabricante se ven comprometidos, el impacto va mucho más allá de un único servidor. La naturaleza interconectada de la producción moderna, desde la gestión de inventario hasta las líneas de ensamblaje robotizadas, implica que un fallo digital puede provocar una paralización operativa completa. Las consecuencias son graves y multifacéticas.
En primer lugar, el impacto financiero es inmediato e intenso. Las paradas de producción provocan incumplimientos de plazos, cláusulas de penalización con clientes y costes de personal inactivo. Restaurar sistemas, contratar expertos forenses y, potencialmente, gestionar demandas de rescate puede comprometer seriamente las finanzas de una empresa mediana.
En segundo lugar, el daño reputacional puede ser duradero. En un entorno B2B, la fiabilidad lo es todo. Un único incidente grave puede quebrar la confianza de socios clave que dependen de entregas justo a tiempo. Como destaca nuestra guía interna, un objetivo clave de la gestión de incidentes es “minimizar el impacto operativo y financiero de los incidentes y restaurar las operaciones normales lo antes posible”, un objetivo crítico en fabricación.
Por último, la presión regulatoria puede ser contundente. Con marcos como la Directiva NIS2 de la UE y DORA de la UE en plena aplicación, las organizaciones de sectores críticos como la fabricación afrontan requisitos estrictos de notificación de incidentes y el riesgo de multas sustanciales por incumplimiento. Un incidente mal gestionado no es solo un fallo técnico; supone una exposición legal y de cumplimiento significativa.
Cómo es un buen resultado: del caos al control
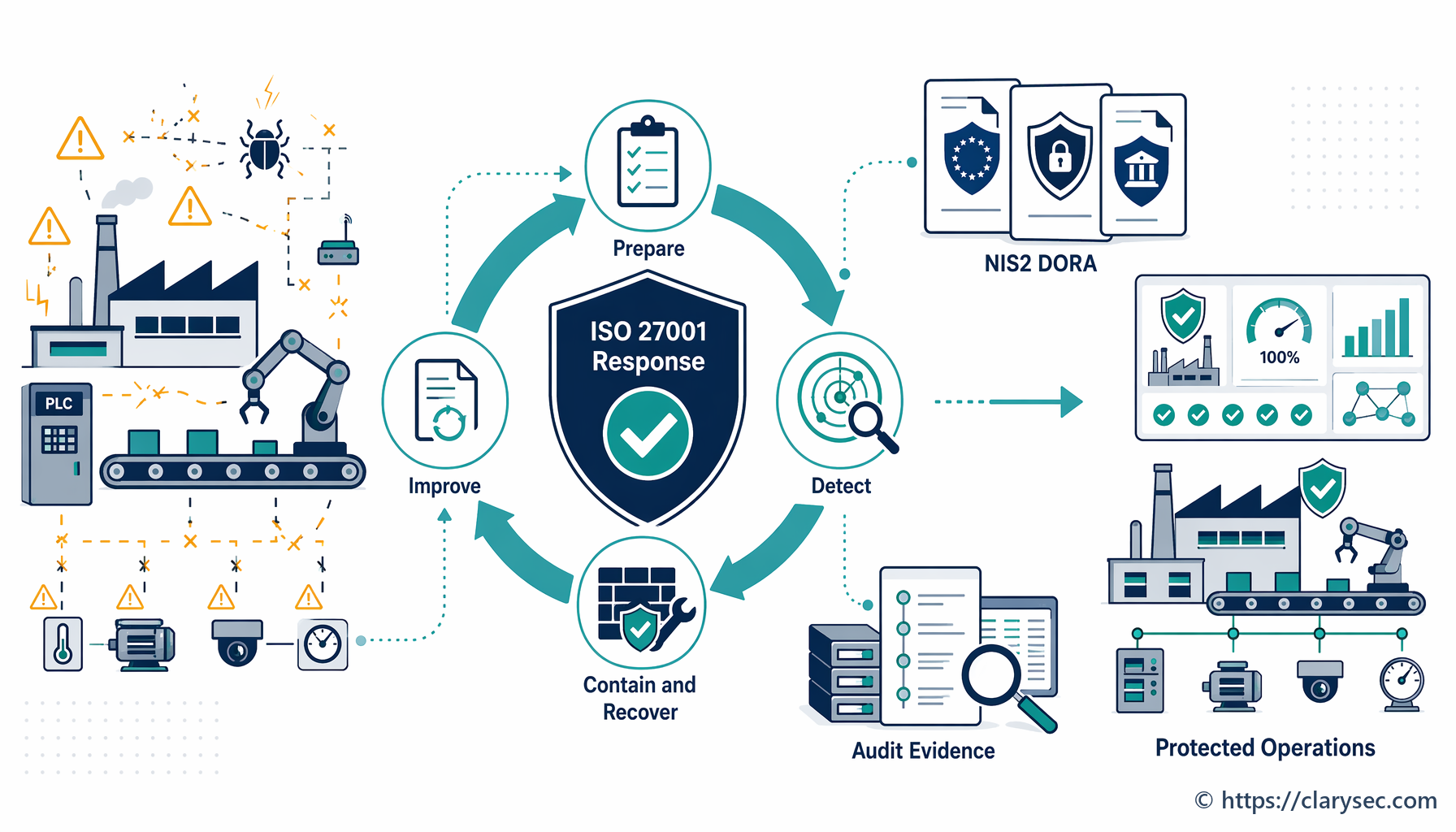
Un programa eficaz de respuesta a incidentes transforma una crisis, que de otro modo sería una reacción caótica e improvisada, en un proceso estructurado y controlado. El objetivo no es solo resolver el problema técnico, sino gestionar todo el evento para proteger a la organización. Este estado objetivo se construye sobre los principios definidos en el marco ISO/IEC 27001, en particular sus controles para la gestión de incidentes de seguridad de la información.
Un programa maduro se caracteriza por varios resultados clave:
- Claridad de roles: Todos saben a quién llamar y cuáles son sus responsabilidades. El equipo de respuesta a incidentes (ERI) está definido previamente, con liderazgo claro y expertos designados de TI, asesoría jurídica, comunicaciones y dirección.
- Rapidez y precisión: La organización puede detectar, analizar y contener amenazas con rapidez, evitando que se propaguen por la red y paralicen toda la planta de producción.
- Toma de decisiones informada: La dirección recibe información oportuna y precisa, lo que permite adoptar decisiones críticas sobre operaciones, comunicación con clientes y notificación regulatoria.
- Mejora continua: Todo incidente, grande o pequeño, se convierte en una oportunidad de aprendizaje. Un proceso riguroso de revisión posterior al incidente identifica debilidades y retroalimenta el programa de seguridad con mejoras.
Alcanzar este nivel de preparación es el propósito central de los controles detallados en ISO/IEC 27002:2022. Estos controles guían a las organizaciones en la planificación y preparación (A.5.24), la evaluación y decisión sobre eventos (A.5.25), la respuesta a incidentes (A.5.26) y el aprendizaje derivado de ellos (A.5.28). Se trata de construir un sistema resiliente que anticipe el fallo y esté estructurado para gestionarlo de forma controlada.
El camino práctico: guía paso a paso para la respuesta a incidentes
Construir una capacidad sólida de respuesta a incidentes requiere un enfoque documentado y sistemático. La base es una política clara y aplicable que describa cada fase del proceso.
Nuestra Política P16S de planificación y preparación para la gestión de incidentes de seguridad de la información - pyme proporciona un modelo integral alineado con las mejores prácticas de ISO 27001. Recorramos los pasos críticos utilizando esta política como guía.
Paso 1: Planificación y preparación: la base de la resiliencia
No se puede crear un plan de respuesta en plena crisis. La preparación lo es todo. Esta fase consiste en establecer la estructura, las herramientas y el conocimiento necesarios para actuar con decisión cuando se produce un incidente.
Un componente esencial es la constitución de un equipo de respuesta a incidentes (ERI). Tal como se indica en la sección 5.1 de la Política P16S de planificación y preparación para la gestión de incidentes de seguridad de la información - pyme, el propósito de la política es “asegurar un enfoque coherente y eficaz para la gestión de incidentes de seguridad de la información”. Esta coherencia empieza por un equipo bien definido. La política exige que el ERI incluya miembros de áreas clave:
- TI y seguridad de la información
- Asesoría jurídica y cumplimiento normativo
- Recursos Humanos
- Relaciones Públicas/Comunicaciones
- Alta dirección
Cada miembro debe tener roles y responsabilidades claramente definidos. ¿Quién tiene autoridad para desconectar sistemas? ¿Quién es el portavoz designado para comunicarse con clientes o medios? Estas preguntas deben estar respondidas y documentadas mucho antes de que ocurra un incidente.
Paso 2: Detección y notificación: el sistema de alerta temprana
Cuanto antes se conozca un incidente, menor será el daño que pueda causar. Esto exige tanto supervisión técnica como una cultura en la que los empleados se sientan facultados y obligados a notificar actividad sospechosa.
La Política P16S de planificación y preparación para la gestión de incidentes de seguridad de la información - pyme es clara en este punto. La sección 5.3, “Notificación de eventos de seguridad de la información”, exige:
“Todos los empleados, contratistas y otras partes pertinentes deben notificar cualquier evento o debilidad de seguridad de la información observado o sospechado, lo antes posible, al punto de contacto designado.”
Este “punto de contacto designado” es crítico. Puede ser la mesa de servicio de TI o una línea directa específica de seguridad. El proceso debe ser sencillo y comunicarse adecuadamente a todo el personal. Los empleados deben recibir formación sobre qué deben identificar, como correos de phishing, comportamiento inusual de los sistemas o brechas de seguridad física.
Paso 3: Evaluación y triaje: dimensionar la amenaza
Una vez notificado un evento, el siguiente paso es evaluar rápidamente su naturaleza y gravedad. ¿Es una falsa alarma, un problema menor o una crisis de gran alcance? Este proceso de triaje determina el nivel de respuesta requerido.
Nuestra política describe un esquema de clasificación claro en la sección 5.2, “Clasificación de incidentes”, para categorizar los incidentes en función de su impacto en la confidencialidad, la integridad y la disponibilidad. Un esquema típico podría ser el siguiente:
- Bajo: Una estación de trabajo individual infectada con malware común, fácilmente contenible.
- Medio: Un servidor departamental no está disponible, lo que afecta a una función concreta de la organización, pero no detiene la producción general.
- Alto: Un ataque de ransomware extendido que afecta a sistemas críticos de producción y datos esenciales de la organización.
- Crítico: Un incidente que implica una brecha de datos de información personal sensible o propiedad intelectual, con implicaciones legales y reputacionales significativas.
Esta clasificación determina la urgencia, los recursos asignados y la vía de escalado a la dirección, asegurando que la respuesta sea proporcional a la amenaza.
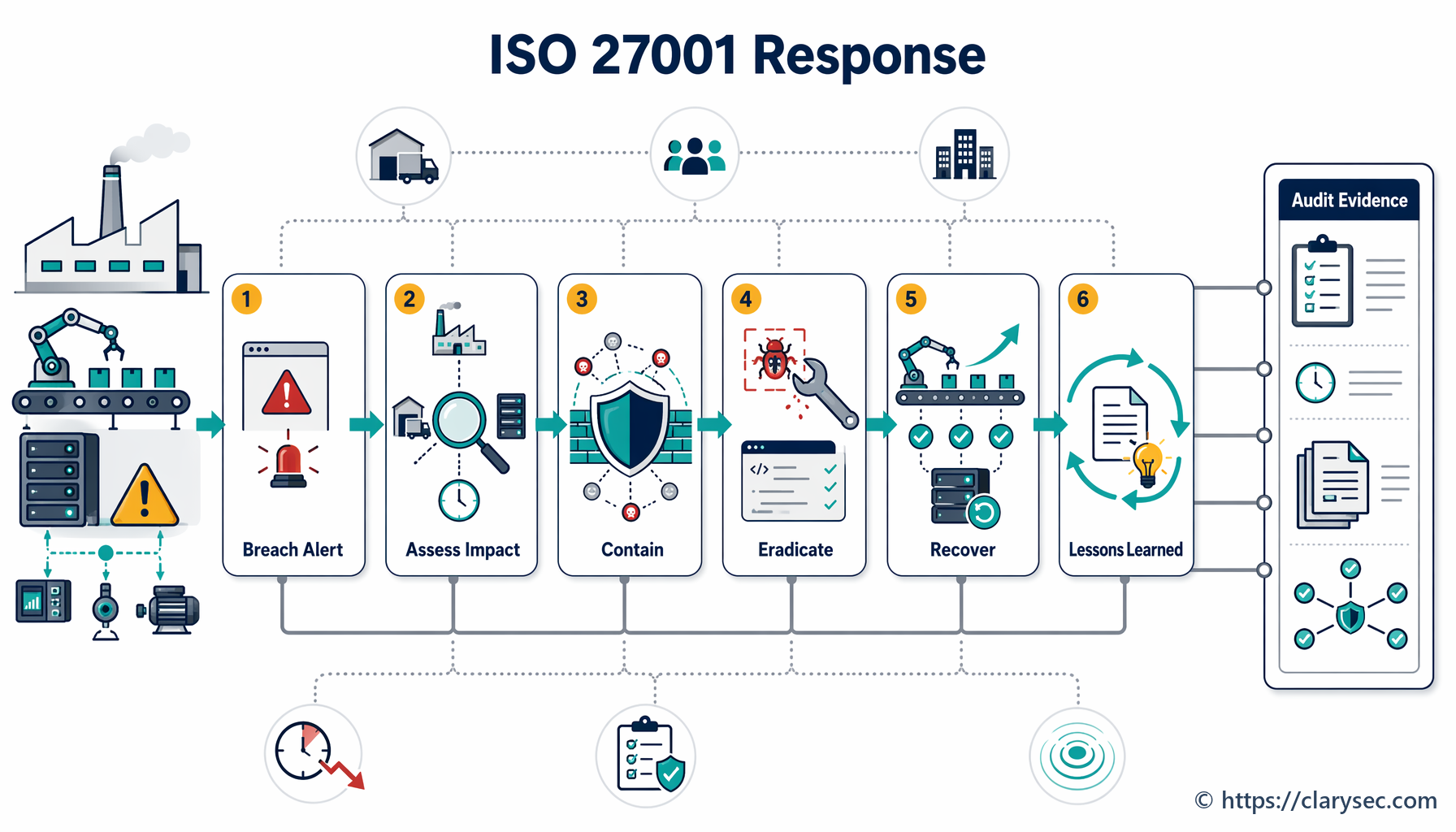
Paso 4: Contención, erradicación y recuperación: apagar el incendio
Esta es la fase activa de respuesta, en la que el ERI trabaja para controlar el incidente y restaurar las operaciones normales.
- Contención: La prioridad inmediata es detener el daño. Esto puede implicar aislar segmentos de red afectados, desconectar servidores comprometidos o bloquear direcciones IP maliciosas. El objetivo es impedir que el incidente se propague y cause daños adicionales.
- Erradicación: Una vez contenido, debe eliminarse la causa raíz del incidente. Esto puede incluir eliminar malware, aplicar parches a vulnerabilidades explotadas y deshabilitar cuentas de usuario comprometidas.
- Recuperación: El paso final es restaurar los sistemas y datos afectados. Esto implica restaurar desde copias de seguridad limpias, reconstruir sistemas y supervisar cuidadosamente para asegurar que la amenaza se ha eliminado por completo antes de volver a poner los servicios en línea.
La sección 5.4 de la Política P16S de planificación y preparación para la gestión de incidentes de seguridad de la información - pyme, “Respuesta a incidentes de seguridad de la información”, proporciona el marco para estas acciones y enfatiza que “los procedimientos de respuesta deben iniciarse cuando un evento de seguridad de la información sea clasificado como incidente”.
Paso 5: Actividades posteriores al incidente: aprender las lecciones
El trabajo no termina cuando los sistemas vuelven a estar en línea. La fase posterior al incidente es, probablemente, la más importante para construir resiliencia a largo plazo. Incluye dos actividades clave: recopilación de evidencias y revisión de lecciones aprendidas.
La política destaca la importancia de la recopilación de evidencias en la sección 5.5, al señalar que “deben establecerse y seguirse procedimientos para la recopilación, adquisición y preservación de evidencias relacionadas con incidentes de seguridad de la información”. Esto es crucial para la investigación interna, los requerimientos de las autoridades competentes y posibles acciones legales.
A continuación, debe realizarse una revisión formal posterior al incidente. Esta reunión debe incluir a todos los miembros del ERI y a las partes interesadas clave para tratar:
- ¿Qué ocurrió y cuál fue la cronología de los eventos?
- ¿Qué funcionó bien en la respuesta?
- ¿Qué dificultades se encontraron?
- ¿Qué puede hacerse para prevenir un incidente similar en el futuro?
El resultado de esta revisión debe ser un plan de acción con responsables asignados y fechas límite para mejorar políticas, procedimientos y controles técnicos. Esto crea un ciclo de retroalimentación que fortalece con el tiempo la postura de seguridad de la organización.
Conectar los puntos: perspectivas de cumplimiento cruzado
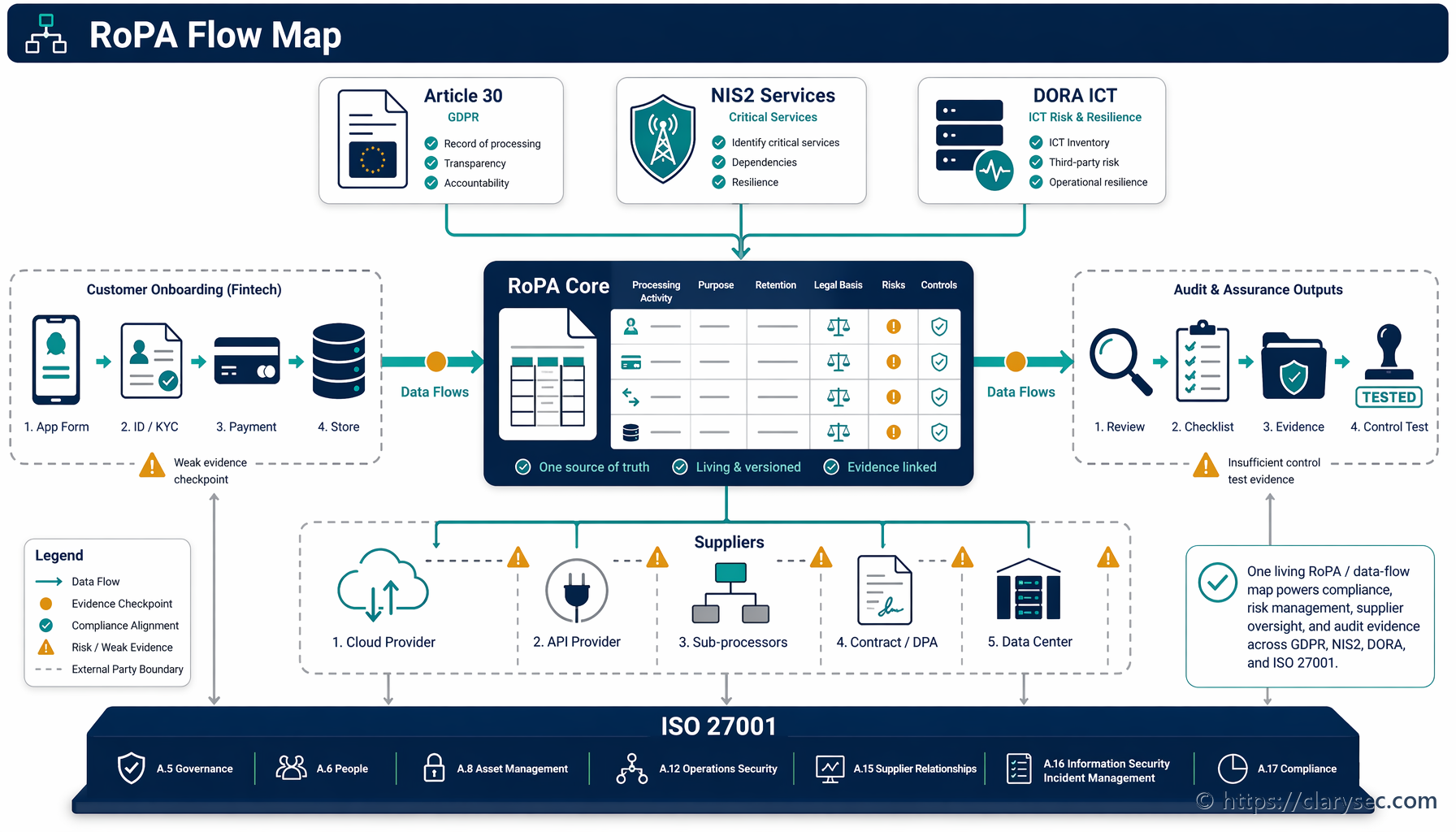
Cumplir los requisitos de ISO 27001 para la gestión de incidentes no solo refuerza la seguridad; proporciona una base sólida para cumplir un conjunto creciente de regulaciones internacionales y sectoriales. Muchos de estos marcos comparten los mismos principios esenciales de preparación, respuesta y notificación.
Como se explica en Zenith Controls, nuestra guía integral de cumplimiento cruzado, un proceso robusto de gestión de incidentes es una piedra angular de la resiliencia digital. Veamos cómo el enfoque de ISO 27001 se alinea con otros marcos principales.
Controles ISO/IEC 27002:2022: La versión más reciente de la norma ISO/IEC 27002 proporciona orientación detallada sobre gestión de incidentes mediante un conjunto específico de controles:
- A.5.24 - Planificación y preparación para la gestión de incidentes de seguridad de la información: Establece la necesidad de un enfoque definido y documentado.
- A.5.25 - Evaluación y decisión sobre eventos de seguridad de la información: Asegura que los eventos se evalúen adecuadamente para determinar si constituyen incidentes.
- A.5.26 - Respuesta a incidentes de seguridad de la información: Cubre las actividades de contención, erradicación y recuperación.
- A.5.27 - Notificación de incidentes de seguridad de la información: Define cómo y cuándo se notifican los incidentes a la dirección y a otras partes interesadas.
- A.5.28 - Aprendizaje a partir de incidentes de seguridad de la información: Exige un proceso de mejora continua.
Estos controles conforman un ciclo de vida completo que se refleja en otras regulaciones principales.
Directiva NIS2: Para los operadores de servicios esenciales, incluidos muchos fabricantes, NIS2 impone obligaciones estrictas de seguridad y notificación de incidentes. Zenith Controls señala la superposición directa:
“Article 21 de la Directiva NIS2 exige a las entidades esenciales e importantes implantar medidas técnicas, operativas y organizativas adecuadas y proporcionadas para gestionar los riesgos que afectan a la seguridad de las redes y sistemas de información. Esto incluye explícitamente políticas y procedimientos de gestión de incidentes. Además, Article 23 establece un proceso de notificación de incidentes por fases, que exige una alerta temprana en un plazo de 24 horas y un informe detallado en un plazo de 72 horas a las autoridades competentes (CSIRT).”
Un plan de respuesta a incidentes alineado con ISO 27001 proporciona los mecanismos exactos necesarios para cumplir estos plazos de notificación exigentes.
Reglamento de Resiliencia Operativa Digital (DORA): Aunque se centra en el sector financiero, los principios de resiliencia de DORA se están convirtiendo en una referencia para todos los sectores. La guía destaca esta conexión:
“Article 17 de DORA exige que las entidades financieras dispongan de un proceso integral de gestión de incidentes relacionados con las TIC para detectar, gestionar y notificar incidentes relacionados con las TIC. Article 19 exige la clasificación de incidentes conforme a los criterios detallados en la regulación y la notificación de incidentes graves a las autoridades competentes mediante plantillas armonizadas. Esto refleja los requisitos de clasificación y notificación presentes en ISO 27001.”
Reglamento General de Protección de Datos (RGPD de la UE): Para cualquier incidente que implique datos personales, los requisitos del RGPD de la UE son prioritarios. Una respuesta rápida y estructurada no es opcional. Como explica Zenith Controls:
“Conforme al RGPD de la UE, Article 33 exige a los responsables del tratamiento notificar a la autoridad de control una violación de la seguridad de los datos personales sin dilación indebida y, cuando sea posible, a más tardar 72 horas después de haber tenido constancia de ella. Article 34 exige comunicar la violación de seguridad al interesado cuando sea probable que entrañe un alto riesgo para sus derechos y libertades. Un plan eficaz de respuesta a incidentes es esencial para recopilar la información necesaria y realizar estas notificaciones de forma precisa y en plazo.”
Al construir el programa de respuesta a incidentes sobre una base ISO 27001, se desarrollan simultáneamente las capacidades necesarias para gestionar las complejas exigencias de estas regulaciones interconectadas.
Prepararse para el escrutinio: qué preguntarán los auditores
Un plan de respuesta a incidentes que nunca se ha probado ni revisado es solo un documento. Los auditores lo saben y, durante una auditoría de certificación ISO 27001, profundizarán para verificar que el programa forma parte viva y operativa del SGSI.
Según Zenith Blueprint, nuestra hoja de ruta para auditores, la evaluación de la respuesta a incidentes es un paso crítico del proceso de auditoría. Durante la “Fase 3: Trabajo de campo y recopilación de evidencias”, los auditores comprobarán sistemáticamente la preparación.
Esto es lo que puede esperarse que soliciten, con base en el paso 21 de Zenith Blueprint, “Evaluar la respuesta a incidentes y la continuidad del negocio”:
“Muéstreme su plan y su política de respuesta a incidentes.” Los auditores empezarán por la documentación. Examinarán la política para comprobar que está completa, revisando la definición de roles y responsabilidades, los criterios de clasificación, los planes de comunicación y los procedimientos para cada fase del ciclo de vida del incidente. Verificarán que ha sido aprobada formalmente y comunicada al personal pertinente.
“Muéstreme los registros de sus tres últimos incidentes de seguridad.” Aquí es donde se comprueba la aplicación real del proceso. Los auditores necesitan ver evidencias de que el plan se sigue efectivamente. Esperarán encontrar registros de incidentes o tickets que documenten:
- La fecha y hora de detección.
- Una descripción del incidente.
- La prioridad asignada o el nivel de clasificación.
- Un registro de las acciones realizadas para contención, erradicación y recuperación.
- La fecha y hora de resolución.
“Muéstreme las actas y el plan de acción de su última revisión posterior al incidente.” Como enfatiza Zenith Blueprint, la mejora continua no es negociable.
“Durante la auditoría, buscaremos evidencias objetivas de que las revisiones posteriores al incidente se realizan de forma sistemática. Esto incluye revisar actas de reunión, registros de acciones y evidencias de que se han implantado las mejoras identificadas, como procedimientos actualizados o nuevos controles técnicos. Sin este ciclo de retroalimentación, no puede considerarse que el SGSI esté ‘mejorando continuamente’ como exige la norma.”
“Muéstreme evidencias de que ha probado su plan.” Los auditores quieren comprobar que la organización prueba proactivamente sus capacidades, no que simplemente espera a un incidente real. Estas evidencias pueden adoptar muchas formas, desde ejercicios de mesa con la dirección hasta simulaciones técnicas a escala completa. Querrán ver un informe de estas pruebas que detalle el escenario, los participantes, los resultados y las lecciones aprendidas.
Estar preparado con estas evidencias demuestra que el programa de respuesta a incidentes no es solo una formalidad, sino un componente robusto, operativo y eficaz del SGSI.
Errores comunes que deben evitarse
Incluso con un plan bien documentado, muchas organizaciones tropiezan durante un incidente real. Estos son algunos de los errores más comunes que conviene vigilar:
- El síndrome del “plan en la estantería”: El fallo más común es disponer de un plan perfectamente redactado que nadie ha leído, entendido ni practicado. La formación y las pruebas periódicas son el único antídoto.
- Autoridad indefinida: Durante una crisis, la ambigüedad es el enemigo. Si el ERI no tiene autoridad preaprobada para adoptar medidas decisivas, como desconectar un sistema crítico de producción, la respuesta quedará paralizada por la indecisión mientras el daño se propaga.
- Comunicación deficiente: No gestionar las comunicaciones es una receta para el desastre. Esto incluye no informar a la dirección, proporcionar mensajes confusos a los empleados o gestionar de forma inadecuada la comunicación con clientes y reguladores. Es esencial contar con un plan de comunicación preaprobado y con plantillas.
- Descuidar la preservación de evidencias: En la urgencia por restaurar el servicio, el equipo técnico puede destruir inadvertidamente evidencias forenses cruciales. Esto puede impedir determinar la causa raíz, prevenir la recurrencia o respaldar acciones legales.
- No aprender: Tratar un incidente como “cerrado” cuando el sistema vuelve a estar en línea es una oportunidad perdida. Sin un análisis posterior riguroso, la organización está condenada a repetir sus errores.
Próximos pasos
Pasar de la teoría a la práctica es el paso más crítico. Un programa robusto de respuesta a incidentes es un recorrido de mejora continua, no un destino. Puede empezar así:
- Formalice su enfoque: Si no dispone de una política formal de respuesta a incidentes, este es el momento de crearla. Utilice nuestra Política P16S de planificación y preparación para la gestión de incidentes de seguridad de la información - pyme como plantilla para construir un marco integral.
- Comprenda su panorama de cumplimiento: Mapee sus procedimientos de respuesta a incidentes con los requisitos específicos de regulaciones como NIS2, DORA y el RGPD de la UE. Nuestra guía, Zenith Controls, proporciona las referencias cruzadas necesarias para asegurar una cobertura completa.
- Prepárese para su auditoría: Utilice la perspectiva del auditor para someter a presión su programa. Zenith Blueprint le ofrece una visión interna de lo que exigirán los auditores, para que pueda recopilar sus evidencias y estar preparado para demostrar eficacia.
Conclusión
Para un fabricante moderno, la respuesta a incidentes de seguridad de la información no es un asunto de TI; es una función esencial de continuidad del negocio. La diferencia entre una interrupción menor y un fallo catastrófico reside en la preparación, la práctica y el compromiso con un proceso estructurado y repetible.
Al basar el programa en el marco reconocido internacionalmente de ISO 27001, no solo se construye una capacidad defensiva, sino una organización resiliente. Se crea un sistema capaz de resistir el impacto de una brecha de seguridad, gestionar la crisis con control y precisión, y salir reforzado y más seguro. El momento de prepararse es ahora, antes de que la alerta de las 2:17 AM se convierta en su realidad.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council