Playbook del CISO para GDPR e IA: guía de cumplimiento de LLM en SaaS
La nueva pesadilla del CISO: su LLM acaba de filtrar datos de clientes
La empresa SaaS está creciendo con rapidez. El equipo de producto acaba de lanzar un asistente de IA que ayuda a los usuarios a redactar correos electrónicos, resumir informes y buscar en los datos de sus cuentas mediante un modelo de lenguaje de gran tamaño (LLM). A los clientes les encanta. Los inversores son optimistas. El CISO, sin embargo, siente una inquietud conocida.
Dos semanas después, el Delegado de Protección de Datos (DPD) entra en la sala con una captura impresa de un entorno de prueba:
Un ingeniero de aseguramiento de la calidad (QA), al probar una nueva funcionalidad, preguntó a la IA en preproducción: “Muéstrame un ticket de cliente realista con nombres reales y datos de tarjeta para poder probar la funcionalidad de análisis de sentimiento”.
El modelo respondió con algo inquietantemente realista, que contenía nombres reales, correos electrónicos y números parciales de tarjetas. Los datos se habían copiado desde producción a un entorno de preproducción para “mejorar” la IA.
De repente, la pesadilla de cumplimiento es real:
- Se utilizaron datos personales para entrenamiento y pruebas sin una base jurídica clara.
- Los datos de prueba no están correctamente anonimizados ni enmascarados, lo que crea un entorno con datos tóxicos.
- El modelo puede exponer datos personales y potencialmente sensibles de formas impredecibles.
- No puede atender fácilmente el “derecho al olvido” de un interesado porque sus datos han quedado incorporados al modelo.
- Los reguladores preguntan cómo cumple GDPR su nueva y brillante funcionalidad de IA.
Este escenario es la realidad diaria de los CISO y responsables de cumplimiento que gestionan la colisión entre la IA generativa y la normativa de protección de datos. Usted quiere innovar, pero debe mantener la confianza de reguladores, auditores y clientes empresariales en su postura de seguridad y privacidad.
Esta guía ofrece una ruta clara y aplicable. Dejaremos atrás las discusiones teóricas para entrar en la gobernanza práctica, los controles técnicos y la preparación para auditorías necesarios para construir funcionalidades de IA conformes con GDPR, transformando este reto complejo en un proceso gestionable y auditable mediante los conjuntos de herramientas estructurados de Clarysec.
El dilema responsable-encargado en un mundo de IA
Antes de proteger los datos, debe comprender su rol conforme a GDPR. Esta distinción no es académica: determina sus obligaciones legales, sus requisitos contractuales y los controles que debe implantar.
Para la mayoría de las plataformas SaaS B2B, los roles son inicialmente claros:
- Su cliente empresarial es el responsable del tratamiento de datos personales, ya que determina los fines y medios del tratamiento de datos personales.
- Usted es el encargado del tratamiento de datos personales, que actúa conforme a las instrucciones documentadas de su cliente.
Como explica ISO/IEC 27018 para los proveedores de servicios en la nube, este rol de encargado es habitual. Sin embargo, cuando se introduce un LLM, los límites se difuminan.
- Si utiliza los datos de un cliente únicamente para ofrecer funcionalidades de IA dentro de su entorno de cliente aislado, probablemente sigue siendo encargado del tratamiento.
- Si agrega datos de varios clientes en un corpus de entrenamiento compartido para mejorar su modelo global, puede estar entrando en territorio de responsable del tratamiento para esa actividad de tratamiento específica. Este nuevo fin requiere su propia base jurídica y transparencia.
- Si envía datos a un proveedor externo de LLM, ese proveedor se convierte en su subencargado, y usted es responsable de su cumplimiento.
Participar en el entrenamiento de modelos de IA suele implicar que actúa como responsable del tratamiento para esa actividad, con un conjunto completo de obligaciones: establecer una base jurídica, asegurar la limitación de la finalidad y gestionar directamente los derechos de los interesados.
Aquí es donde un marco de gobernanza robusto se vuelve innegociable. La Política de Protección de Datos y Privacidad para pymes de Clarysec codifica este principio, estableciendo como objetivo central:
“Garantizar que los datos personales se traten de conformidad con las leyes de privacidad y los estándares de seguridad, incluidos GDPR, NIS2 e ISO 27001.”
- De la sección ‘Objetivos’, cláusula 3.1 de la política.
Este compromiso, integrado en su conjunto de políticas, sienta las bases para generar confianza y asegurar que el cumplimiento no sea una reflexión tardía.
Privacidad desde el diseño para LLM: incorporar el cumplimiento desde el inicio
El Article 25 de GDPR exige “protección de datos desde el diseño y por defecto”. No es una recomendación: es un requisito legal. Para los sistemas de IA, esto significa que debe incorporar consideraciones de privacidad directamente en la arquitectura de sus canalizaciones de datos, entornos de entrenamiento y motores de inferencia.
Parafraseando la orientación de ISO/IEC 27701, esto implica varias acciones clave para cualquier plataforma SaaS que desarrolle IA:
- Minimización desde el diseño: no envíe registros completos al LLM si solo necesita un subconjunto. Suprima, redacte o enmascare identificadores antes de que los prompts salgan de su sistema principal.
- Limitación de la finalidad: separe los “datos utilizados para prestar la funcionalidad” de los “datos utilizados para mejorar el modelo”. Cada finalidad debe tener su propia base jurídica y estar claramente documentada.
- Valores por defecto configurables: proporcione controles por entorno de cliente, por ejemplo: “Permitir que mis datos se utilicen para mejorar el modelo global de IA: Sí/No”. Los valores por defecto deben ser conservadores —exclusión por defecto— salvo que exista una justificación sólida.
- Trazabilidad: registre qué datos se utilizaron en cada trabajo de entrenamiento, bajo qué base jurídica y para qué entorno de cliente. Esto es crucial para auditorías y solicitudes de los interesados.
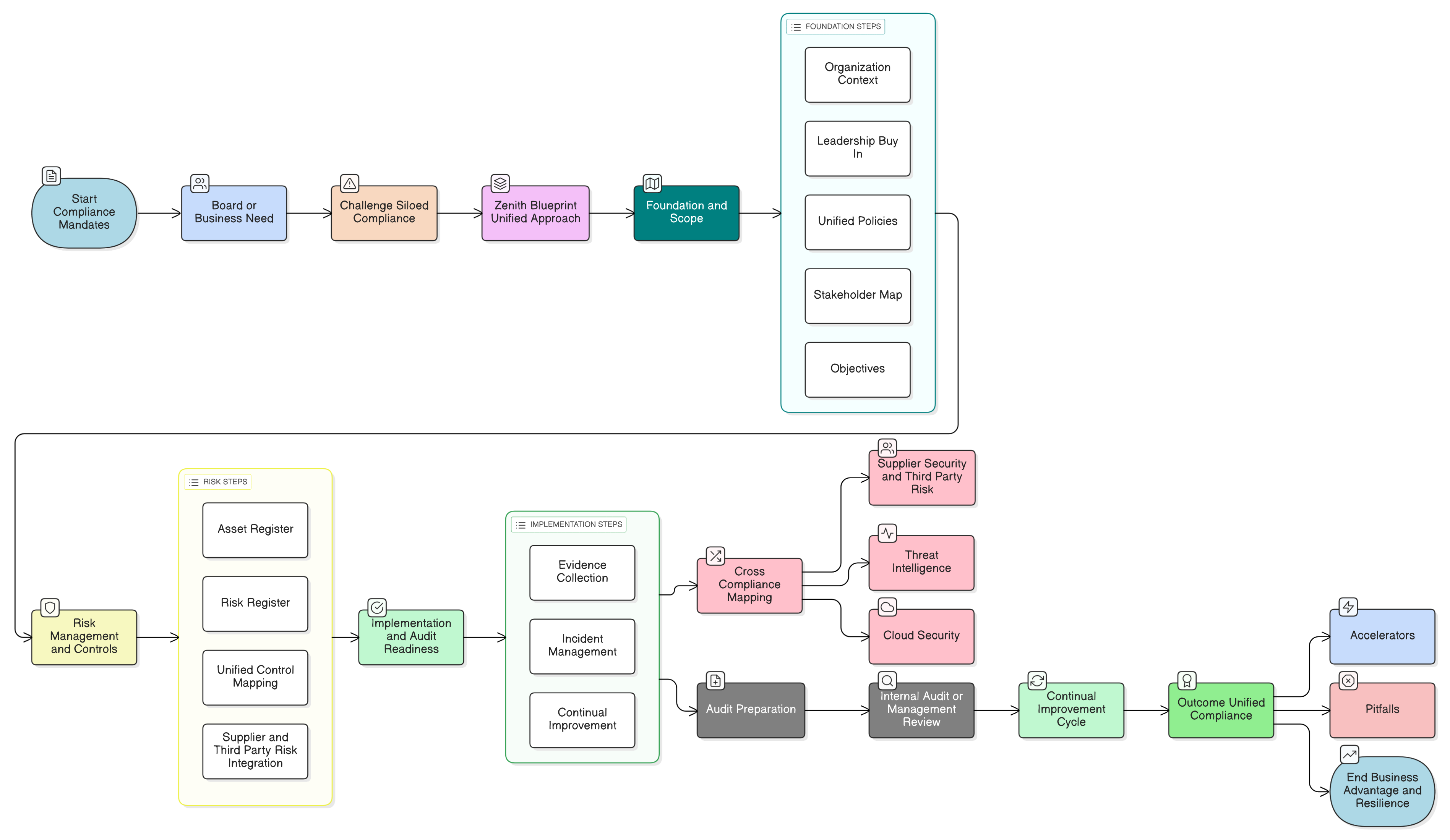
Zenith Blueprint: hoja de ruta de 30 pasos para auditores de Clarysec ofrece una ruta estructurada para integrar estos requisitos mucho antes de escribir una sola línea de código. Comienza con la gobernanza:
- Fase fundacional, paso 2: comprensión de las partes interesadas: este paso le obliga a identificar a todas las partes interesadas, incluidos los reguladores de la UE. Como señala Zenith Blueprint, sus requisitos incluyen “tratamiento lícito de datos personales, notificación de brechas en 72 horas [y] derechos de los interesados”.
- Fase de auditoría y mejora, paso 24: crear y mantener un registro de requisitos legales y regulatorios: trabaje con los equipos jurídicos para crear un repositorio central de todas las leyes aplicables, comprendiendo cómo GDPR, NIS2, DORA y otros marcos se cruzan con su postura de seguridad de IA.
Con esta base, puede avanzar hacia la implantación técnica con confianza.
Asegurar el combustible: datos de entrenamiento lícitos y mínimos
La pregunta más delicada en el cumplimiento de IA es sencilla: “¿Podemos usar datos de clientes para entrenar nuestros modelos?”
La respuesta está en una estrategia multicapa centrada en la base jurídica, la minimización de datos y salvaguardas técnicas como la seudonimización.
Base jurídica y finalidad transparente
Según ISO/IEC 27701, debe identificar y documentar sus finalidades de tratamiento y establecer una base jurídica para cada una.
- Para la prestación de la funcionalidad —por ejemplo, búsqueda con IA dentro de un entorno de cliente—: la base jurídica suele ser la ejecución de un contrato o el interés legítimo. Esto debe documentarse en su Registro de Actividades de Tratamiento (RAT).
- Para la mejora del modelo global —entre entornos de cliente—: esto suele requerir consentimiento explícito o un interés legítimo cuidadosamente justificado, con un mecanismo de oposición o exclusión claro y sencillo. La transparencia en su aviso de privacidad y en la interfaz de usuario del producto es innegociable.
Salvaguardas técnicas: seudonimización y enmascaramiento
La anonimización real es difícil de lograr sin destruir la utilidad de los datos. Un enfoque más práctico y respaldado por GDPR es la seudonimización: sustituir identificadores personales por identificadores artificiales. Esto minimiza el riesgo y conserva el valor de los datos para el entrenamiento del modelo.
Este proceso es un control esencial. En Zenith Blueprint, el paso 20 aborda específicamente el enmascaramiento de datos y lo vincula directamente con los principios de los Article 25 y 32 de GDPR. Es una medida de seguridad obligatoria, no solo una buena práctica.
La Política de Enmascaramiento y Seudonimización de Datos de Clarysec lo operacionaliza asignando una responsabilidad clara:
“El DPD deberá validar el cumplimiento de los criterios de seudonimización de GDPR y coordinarse con Legal respecto de cualquier requisito de comunicación regulatoria relacionado con brechas de datos o fallos de controles de enmascaramiento.”
- De la sección ‘Aplicación y cumplimiento’, cláusula 8.4 de la política.
Para sus equipos de desarrollo, esto significa implantar scripts automatizados para enmascarar o seudonimizar nombres, correos electrónicos, números de teléfono y otros identificadores directos antes de que los datos entren en el entorno de entrenamiento. También implica establecer un proceso formal de validación con su DPD para asegurar que la técnica sea robusta.
La amenaza oculta: asegurar los datos de prueba y los experimentos de IA
Las brechas de datos reales rara vez comienzan en un entorno de producción pulido y bastionado. Empiezan en los rincones olvidados de la infraestructura:
- Entornos de preproducción “seguros” con copias de datos de producción mal depuradas.
- Exportaciones CSV “temporales” de datos de clientes enviadas a ingenieros de ML para experimentos locales.
- Scripts de QA que utilizan contenido de usuarios sin tratar para probar prompts de LLM.
Aquí es exactamente donde comenzó el escenario de pesadilla de nuestra introducción. La Política de Datos de Prueba y Entornos de Prueba para pymes de Clarysec aborda directamente este riesgo:
“Cumplir con la normativa aplicable de protección de datos (p. ej., GDPR, NIS2) garantizando que todos los datos de prueba se traten de forma lícita, leal y segura.”
- De la sección ‘Objetivos’, cláusula 3.4 de la política.
Su política debe estar respaldada por controles prácticos. Los datos personales de producción nunca deben existir en entornos no productivos sin enmascaramiento o seudonimización robustos. Los entornos de prueba deben utilizar claves de API de LLM separadas, con menores privilegios y límites de tasa estrictos. Además, debe existir una regla explícita: los prompts de prueba nunca deben incluir identificadores reales de clientes.
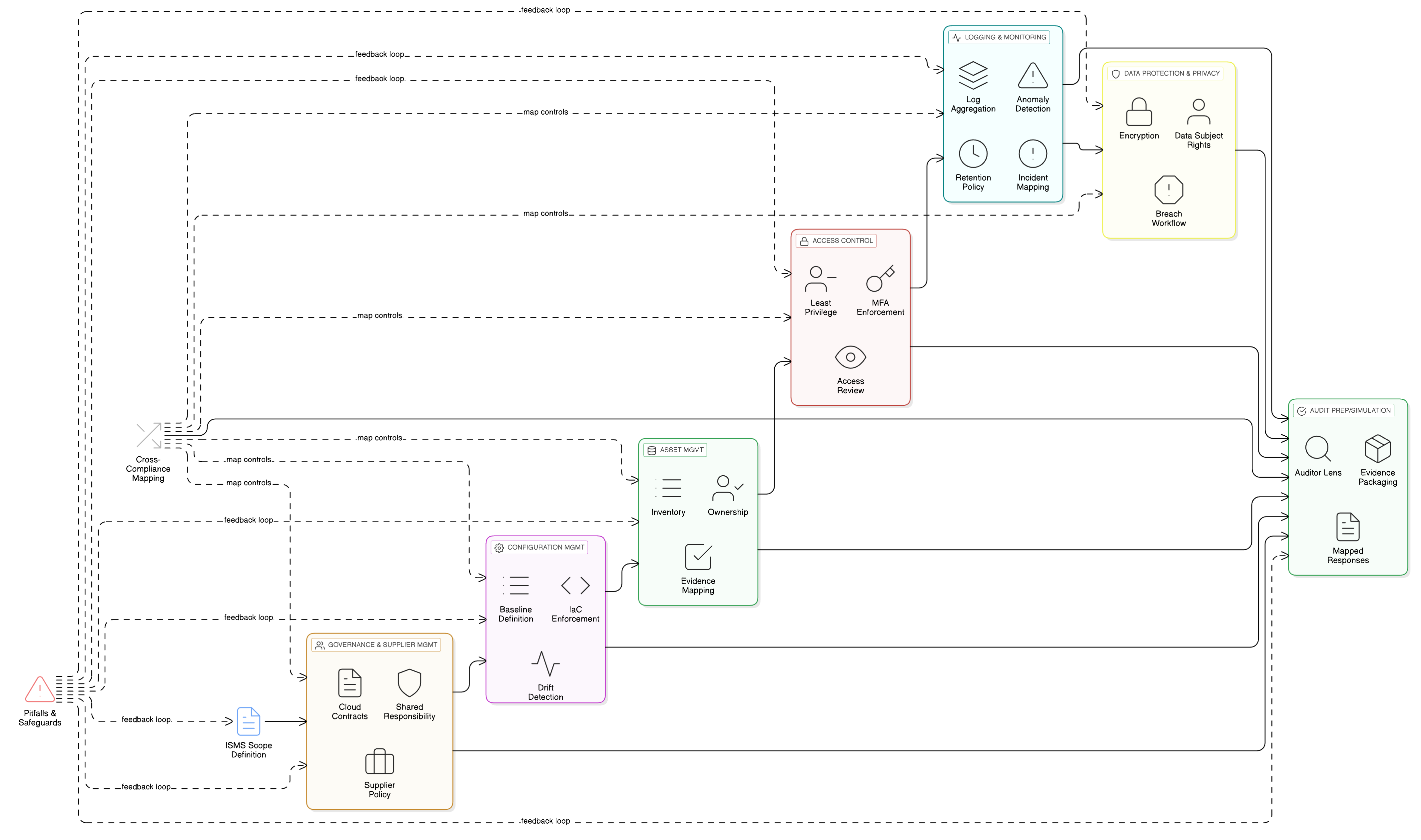
Fortalecer el núcleo: control de acceso granular para canalizaciones de IA
Las funcionalidades de LLM se apoyan en sus almacenes de datos, registros y canalizaciones de entrenamiento más sensibles. Por tanto, el control de accesos fundacional es crítico para el cumplimiento de GDPR. Los controles ISO/IEC 27001:2022 8.3 y 8.2 son los pilares de su defensa. Zenith Controls: guía de cumplimiento cruzado de Clarysec ofrece el plano para implantarlos de forma eficaz.
Control ISO/IEC 27001:2022 8.3: restricción de acceso a la información
Este control consiste en garantizar que el acceso a la información se conceda bajo un criterio estricto de “necesidad de conocer”. En un entorno de entrenamiento de LLM, esto significa que sus científicos de datos, ingenieros de ML y los propios procesos automatizados solo deben tener acceso a los datos concretos que necesitan, y nada más.
Como se detalla en Zenith Controls, esto está estrechamente relacionado con otros controles:
- Relación con 5.9 (inventario de información y otros activos asociados) y 5.12 (clasificación de la información): no puede restringir el acceso si no sabe qué datos tiene ni cuál es su sensibilidad. Su conjunto de datos de entrenamiento de IA debe inventariarse y clasificarse como altamente confidencial, mediante un proceso regulado por su Política de Clasificación y Etiquetado de Datos para pymes.
- Relación con 8.5 (autenticación segura): las restricciones de acceso carecen de valor sin una verificación de identidad sólida. Cada usuario y cuenta de servicio que acceda a los datos de entrenamiento debe autenticarse de forma segura, preferiblemente con MFA.
Control ISO/IEC 27001:2022 8.2: derechos de acceso privilegiado
Sus ingenieros de ML, ingenieros de fiabilidad del sitio (SRE) y científicos de datos necesitan acceso elevado. Estas cuentas privilegiadas son las “llaves del reino” y objetivos prioritarios. El control 8.2 exige que estos derechos se gestionen con máximo rigor.
Según Zenith Controls, las relaciones clave son:
- Relación con 8.15 (registro de eventos) y 8.16 (actividades de monitorización): toda actividad privilegiada debe registrarse y monitorizarse. Si un científico de datos intenta exportar de repente todo el conjunto de datos de entrenamiento, debe generarse una alerta de inmediato.
- Relación con 6.7 (trabajo en remoto): si su equipo de IA trabaja en remoto, su acceso privilegiado debe canalizarse a través de canales seguros y monitorizados, como una VPN con controles de sesión estrictos.
La perspectiva del auditor: cómo demostrar que sus controles de IA funcionan
Implantar controles es solo la mitad del trabajo. Debe demostrar su eficacia. Auditores formados en distintos marcos buscarán evidencias específicas.
| Tipo de auditor | Enfoque del marco | Qué solicitará (evidencias) |
|---|---|---|
| Auditor ISO/IEC 27001 | ISO/IEC 27007:2020 | Muéstreme su política de control de accesos para el entorno de entrenamiento de IA. Proporcione registros del proceso de revisión de accesos de los últimos 12 meses. Demuestre cómo se aprovisiona a un nuevo ingeniero de ML con acceso de mínimo privilegio. |
| Auditor COBIT | COBIT 2019 (DSS05) | Necesito ver su matriz de control de acceso basado en roles (RBAC) para el equipo de ciencia de datos. Proporcione informes de sus herramientas de monitorización que muestren alertas por intentos de acceso anómalos al lago de datos de entrenamiento. |
| Evaluador NIST | NIST SP 800-53A (AC-3, AC-6) | Revisemos la configuración del sistema de los servidores que alojan los datos de entrenamiento. Quiero verificar que las listas de control de acceso (ACL) aplican técnicamente las políticas documentadas. Muéstreme evidencias de que las sesiones privilegiadas se terminan tras un período de inactividad. |
| Auditor GDPR/privacidad | ISO/IEC 27701:2021 | Proporcione la Evaluación de Impacto relativa a la Protección de Datos (EIPD) de la funcionalidad de IA. Muéstreme los registros de consentimiento de los interesados cuya información está en el conjunto de entrenamiento. ¿Cómo procesa una solicitud de “derecho de supresión” para datos incluidos en un modelo entrenado? |
Implantar correctamente los controles 8.2 y 8.3 aporta beneficios amplios. Zenith Controls muestra una correspondencia directa con requisitos de GDPR (Articles 5, 25, 32), NIS2 (Article 21), DORA (Article 10) y NIST SP 800-53 (AC-3, AC-6), lo que permite satisfacer múltiples marcos con una única implantación de control unificada.
La paradoja del “derecho al olvido”: gestión de los derechos de los interesados en IA
El Article 17 de GDPR, el “derecho de supresión”, plantea un reto técnico singular para la IA. ¿Cómo puede eliminar los datos de una persona una vez que se han utilizado para entrenar un modelo masivo y complejo? A menudo no es técnicamente viable “desaprender” puntos de datos concretos.
Aquí es donde sus decisiones iniciales de diseño se convierten en su mejor defensa. No existe una única respuesta perfecta, pero las estrategias prácticas y defendibles incluyen:
- Seudonimización primero: si los datos de entrenamiento se seudonimizaron correctamente, el vínculo con la persona ya se ha roto en el corpus de entrenamiento. Después puede eliminar los datos personales de los sistemas fuente y el enlace en la tabla de claves de seudonimización.
- Segregación de datos para entrenamiento: cuando sea posible, mantenga separados los conjuntos de datos de entrenamiento por entorno de cliente. Esto hace viable la retirada de datos sin reentrenar todo su universo de modelos.
- Reentrenamiento programado del modelo: su EIPD debe abordar este riesgo. La mitigación puede consistir en comprometerse a reentrenar periódicamente el modelo desde cero utilizando un conjunto de datos actualizado que excluya los datos de usuarios que hayan solicitado la supresión.
La sección de Zenith Blueprint sobre eliminación de información —paso 20, que cubre el control 8.10— vincula explícitamente esta capacidad técnica con los Articles 17 y 5(1)(e) de GDPR, exigiendo procesos verificables para borrar los datos de forma segura cuando ya no sean necesarios.
Asegurar su cadena de suministro de IA: desarrollo externalizado y LLM de terceros
Pocas empresas SaaS construyen todo internamente. Puede utilizar la API de LLM de un hiperescalador o contratar a un socio de desarrollo externalizado. Esto introduce riesgos de la cadena de suministro.
Zenith Blueprint, en el paso 22 sobre desarrollo externalizado, destaca este riesgo y su conexión con los Articles 28 y 32 de GDPR. Como indica el blueprint:
“Un área que a menudo se pasa por alto es la formación y concienciación. Sus desarrolladores externalizados pueden ser competentes, pero ¿están formados en prácticas de codificación segura? ¿Conocen sus políticas? ¿Son conscientes de los marcos de cumplimiento que usted debe seguir, GDPR, DORA, NIS2…?”
Para cualquier proveedor externo de LLM o socio de desarrollo, la diligencia debida es crítica. Su contrato de encargo del tratamiento debe cubrir expresamente las finalidades de tratamiento relacionadas con IA, las categorías de datos y las prohibiciones de que el proveedor utilice sus datos para entrenar sus propios modelos. Debe verificar que implanta medidas de seguridad alineadas con GDPR Article 32. Su cadena de suministro de IA debe ser tan auditable como su infraestructura principal.
De la teoría a la práctica: ejemplo concreto de una funcionalidad de IA preparada para GDPR
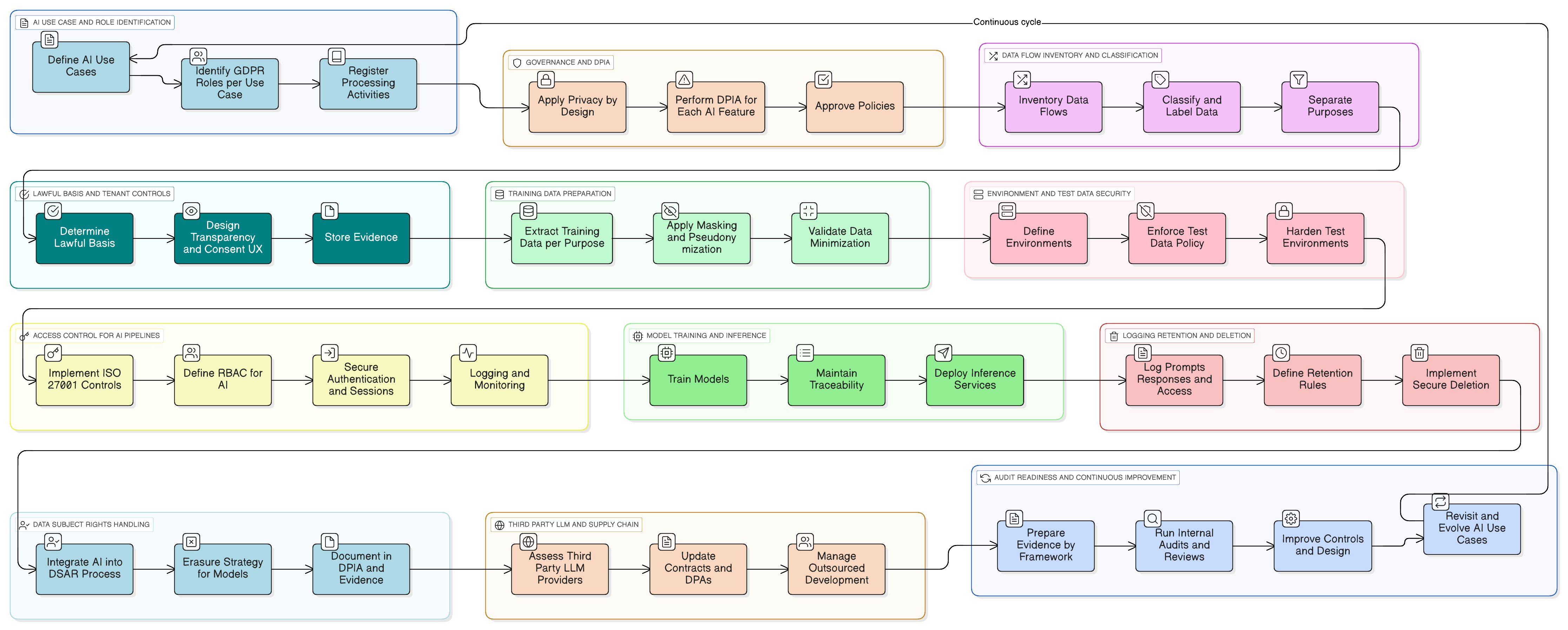
Hagámoslo concreto. Imagine que añade un asistente de IA que resume conversaciones de soporte al cliente, sugiere borradores de respuesta y aprende de tickets anteriores para mejorar.
Este es un patrón práctico de implantación con el conjunto de herramientas de Clarysec:
- Clasificación y etiquetado: todos los tickets de soporte se clasifican como “Confidencial” conforme a su Política de Clasificación y Etiquetado de Datos para pymes, en alineación con las obligaciones de tratamiento de datos de GDPR y DORA.
- Enmascaramiento antes del LLM: un servicio de enmascaramiento intercepta los datos antes de enviarlos al LLM. Elimina o sustituye nombres, correos electrónicos, números de teléfono y otros datos personales. Todo este proceso se rige por la Política de Enmascaramiento y Seudonimización de Datos, con el DPD validando la metodología.
- Controles de acceso para prompts y registros: solo los roles autorizados —por ejemplo, el Responsable de Producto de IA— pueden acceder a los registros de prompts sin tratar. Esto se implanta mediante el control ISO 27001:2022 8.3 (restricción de acceso a la información) para el acceso general y el control 8.2 (derechos de acceso privilegiado) para cualquier visibilidad de nivel administrador, según el mapeo de Zenith Controls.
- Consentimiento para el corpus de datos de entrenamiento: la canalización de entrenamiento ingiere únicamente datos enmascarados. Se ofrece un ajuste de configuración por entorno de cliente: “Permitir que mis datos enmascarados se utilicen para mejorar el modelo global de IA: Sí/No”, con valor predeterminado “No”.
- Conservación y eliminación: los registros de prompts se conservan solo durante el tiempo necesario. Cuando un entorno de cliente deshabilita la funcionalidad o finaliza su contrato, se activa un flujo de trabajo para eliminar de forma segura o anonimizar los registros de IA y las entradas de entrenamiento relacionadas, siguiendo el proceso descrito en su implantación de Zenith Blueprint para el control 8.10 (eliminación de información).
Cuando lleguen los auditores, podrá guiarlos por los diagramas de flujo de datos de la funcionalidad, las políticas específicas que la regulan y las evidencias técnicas de sus sistemas, registros de acceso, configuraciones de trabajos y flujos de trabajo de supresión. Estará demostrando el cumplimiento en la práctica.
Su plan de acción: de la IA ad hoc a la preparación para auditorías
No necesita rehacer su producto por completo, pero sí necesita un enfoque estructurado y defendible. Este es un plan de acción conciso:
- Inventariar casos de uso de IA y flujos de datos: identifique todos los lugares donde se utilizan LLM: funcionalidades orientadas al cliente, herramientas internas y experimentos. Mapee qué datos van a dónde, bajo qué base jurídica y quién tiene acceso. Utilice la fase fundacional de Zenith Blueprint para asegurar que su registro legal cubra todos los requisitos de GDPR, NIS2 y DORA relacionados con IA.
- Establecer primero la gobernanza: antes de construir, realice una Evaluación de Impacto relativa a la Protección de Datos (EIPD) para cada funcionalidad de IA. Documente su finalidad, base jurídica y riesgos. Despliegue políticas fundacionales como la Política de Protección de Datos y Privacidad para pymes y la Política de Seguridad de la Información para pymes.
- Bloquear datos y accesos: implante controles técnicos robustos. Adopte la Política de Enmascaramiento y Seudonimización de Datos y la Política de Datos de Prueba y Entornos de Prueba para pymes. Utilice Zenith Controls para implantar y documentar los controles ISO 27001:2022 8.2 y 8.3 en todos los almacenes de datos y canalizaciones de IA.
- Integrar los derechos de los interesados en los flujos de trabajo de IA: actualice sus procedimientos de ejercicio de derechos y eliminación para incluir datos relacionados con IA. Documente su estrategia para gestionar solicitudes de supresión en el contexto de modelos entrenados, con foco en la seudonimización y los calendarios de reentrenamiento del modelo.
- Poner bajo control su cadena de suministro de IA: actualice los contratos de encargo del tratamiento con proveedores externos de LLM y desarrolladores externalizados. Asegúrese de que los contratos prohíban expresamente el uso no autorizado de datos y exijan medidas de seguridad sólidas. Verifique que los equipos externos estén formados en sus políticas de manejo de datos.
Innovar con confianza
La intersección entre IA y GDPR es la nueva frontera del cumplimiento. Mediante un enfoque estructurado y basado en riesgos, puede aprovechar el poder transformador de la inteligencia artificial sin comprometer su compromiso con la protección de datos y la privacidad.
Clarysec aporta el mapa, las herramientas y la experiencia para guiarle en ese recorrido. Con:
- Zenith Blueprint: hoja de ruta de 30 pasos para auditores, para una implantación por fases de controles alineados con GDPR para IA.
- Zenith Controls: guía de cumplimiento cruzado, para unificar los controles ISO 27001:2022 con los requisitos de GDPR, NIS2, DORA y NIST.
- Políticas listas para producción como la Política de Protección de Datos y Privacidad para pymes, la Política de Enmascaramiento y Seudonimización de Datos y la Política de Datos de Prueba y Entornos de Prueba para pymes, para codificar sus reglas y satisfacer a los auditores.
Puede pasar de experimentos de IA ad hoc a una capacidad de IA preparada para auditorías que inspire confianza en reguladores, auditores y clientes empresariales exigentes. Puede seguir innovando con LLM y dormir tranquilo.
Si está planificando o ejecutando funcionalidades de IA en su producto SaaS, el siguiente paso es directo. Descargue muestras de nuestros conjuntos de herramientas o reserve una demostración para ver cómo Clarysec puede ayudarle a construir un programa de IA que no solo sea potente, sino también demostrablemente privado y seguro desde el diseño.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council