Mapeo de la respuesta a incidentes de NIST para auditorías de 2026
Son las 07:42 de un martes. Anya, CISO de una plataforma fintech en rápido crecimiento, ve la primera alerta: desplazamiento imposible en una cuenta de administrador. Le sigue una ráfaga de inicios de sesión fallidos y, después, una sesión correcta desde un dispositivo no gestionado. Cinco minutos más tarde, el soporte a clientes informa de que los usuarios no pueden acceder a un flujo de trabajo SaaS esencial. A las 08:10, el panel en la nube muestra llamadas anómalas a interfaces de programación de aplicaciones contra un bucket de almacenamiento que puede contener datos personales.
El equipo de seguridad actúa con rapidez. El SIEM dispara la alerta, el ingeniero de nube revoca una sesión y el propietario del servicio empieza a restaurar el acceso. Pero la crisis real no es solo técnica. Es de gobernanza.
Anya debe responder a tres preguntas antes de que termine la primera hora.
Primero, ¿se trata de un incidente de seguridad de la información, una violación de la seguridad de los datos personales, un incidente significativo conforme a NIS2 o un incidente grave relacionado con las TIC conforme a DORA?
Segundo, ¿a quién hay que informar, en qué plazo y con qué evidencias?
Tercero, ¿puede la organización demostrar que su proceso de respuesta a incidentes se ejecutó realmente según lo diseñado?
Ese momento es cuando muchas organizaciones descubren la diferencia entre tener un plan de respuesta a incidentes y disponer de un sistema de gobernanza de la respuesta a incidentes. La respuesta a incidentes de NIST SP 800-61 y NIST CSF 2.0 ya no es solo materia de playbooks del SOC. En 2026, se conecta directamente con la responsabilidad del órgano de administración, las auditorías de ISO/IEC 27001:2022, la notificación por fases de NIS2, la resiliencia operativa de DORA, las decisiones sobre violaciones de la seguridad de los datos personales del RGPD de la UE y la responsabilidad sobre proveedores.
Los programas más sólidos no crean vías de respuesta separadas para cada marco. Usan NIST CSF 2.0 como mapa operativo, ISO/IEC 27001:2022 como columna vertebral del sistema de gestión y un único modelo de evidencias capaz de respaldar NIS2, DORA y el RGPD de la UE al mismo tiempo. Ese es el enfoque de Clarysec: decisiones basadas en políticas, flujos de trabajo probados mediante ejercicios de mesa, paquetes de evidencias preparados para reguladores y mapeo entre marcos mediante Zenith Blueprint: hoja de ruta de 30 pasos para auditores y Zenith Controls: guía de cumplimiento transversal.
El problema de 2026: un incidente, múltiples regímenes de responsabilidad
El incidente al que se enfrenta Anya no es un único problema de cumplimiento. Son varias rutas de decisión solapadas.
Si la organización presta servicios de computación en la nube, SaaS, servicios gestionados, servicios de seguridad gestionados, DNS, centro de datos, servicios de confianza u otros servicios de infraestructura digital, puede aplicarse NIS2. La clasificación como entidad esencial o importante depende del sector, el tamaño y la transposición nacional, pero la dirección es clara: la gestión de incidentes es ahora una responsabilidad de gestión regulada.
Si la organización es una entidad financiera, DORA puede ser el marco principal de resiliencia operativa. DORA es aplicable desde el 17 de enero de 2025 y cubre la gestión del riesgo de las TIC, la notificación de incidentes graves relacionados con las TIC, las pruebas de resiliencia operativa, el intercambio de información, el riesgo de terceros de TIC y la supervisión de proveedores terceros críticos de servicios de TIC. Para las entidades financieras cubiertas que también estén sujetas a NIS2, DORA actúa como el marco sectorial específico para las obligaciones solapadas de riesgo de TIC y notificación de incidentes.
Si se accedió a datos personales, se alteraron, se perdieron, se destruyeron o se divulgaron, el RGPD de la UE pasa a formar parte del árbol de decisión de la respuesta a incidentes. El RGPD de la UE define una violación de la seguridad de los datos personales como una violación de la seguridad que ocasiona la destrucción, pérdida o alteración accidental o ilícita de datos personales, o la comunicación o acceso no autorizados a dichos datos. El RGPD de la UE también exige responsabilidad proactiva, lo que significa que el responsable del tratamiento debe poder demostrar el cumplimiento de los principios del tratamiento, incluida la integridad y confidencialidad.
Si la empresa está certificada en ISO/IEC 27001:2022, o se está preparando para la certificación, el incidente se convierte en evidencia del SGSI. Los auditores examinarán el alcance, las obligaciones legales, los roles, el tratamiento de riesgos, la selección de controles, la ejecución operativa, la información documentada, las lecciones aprendidas y la mejora continua. Las cláusulas 4.1 a 4.4 de ISO/IEC 27001:2022 exigen que el SGSI refleje el contexto, las partes interesadas, las obligaciones, el alcance y las interacciones entre procesos. Las cláusulas 5.1 a 5.3 exigen liderazgo, responsabilidad y responsabilidades asignadas. Las cláusulas 6.1.1 a 6.1.3 exigen evaluación de riesgos de seguridad de la información, tratamiento y una Declaración de Aplicabilidad. Las cláusulas 8.1 a 8.3 exigen operación controlada, evidencias de que los procesos se ejecutaron según lo planificado, control de procesos externalizados e implantación del tratamiento.
El problema de la organización no es la falta de marcos. Es la falta de un modelo operativo único que convierta los marcos en decisiones oportunas y evidencias fiables.
Usar NIST CSF 2.0 como lenguaje común
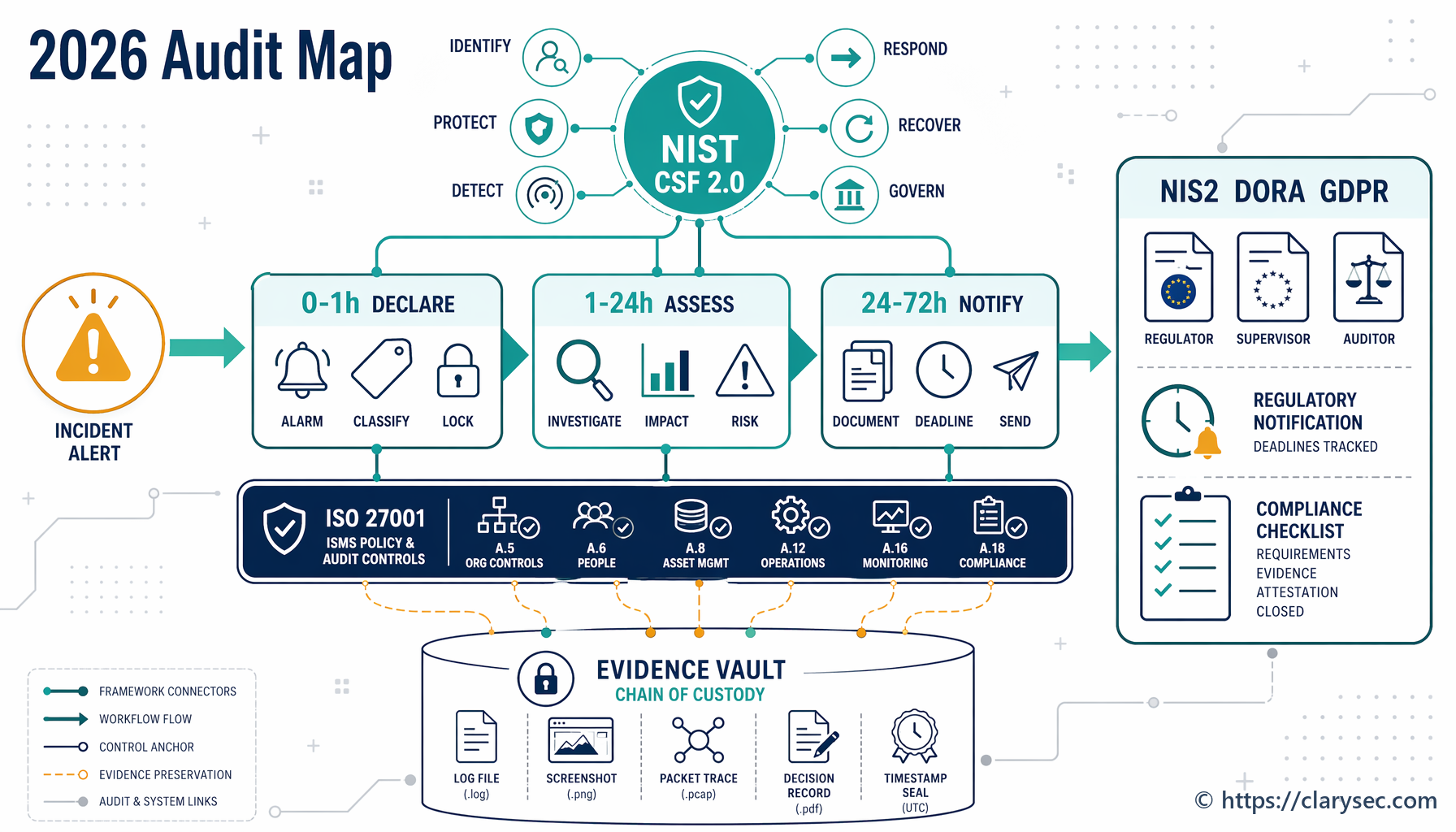
NIST CSF 2.0 es útil porque proporciona a la alta dirección, seguridad, legal, privacidad, operaciones y proveedores un lenguaje común para resultados de ciberseguridad. Su función GOVERN es especialmente importante para la respuesta a incidentes porque obliga a las organizaciones a abordar la supervisión, la política, la estrategia de riesgo, los roles y el riesgo de la cadena de suministro antes de que comience la crisis.
Para la respuesta a incidentes, CSF 2.0 conecta la gobernanza con el ciclo de vida operativo: IDENTIFY, PROTECT, DETECT, RESPOND y RECOVER. Esa estructura ayuda a traducir un incidente ruidoso en un flujo de evidencias controlado.
| Pregunta de respuesta a incidentes | Área de resultados de CSF 2.0 | Evidencia de cumplimiento generada |
|---|---|---|
| ¿Quién es responsable de la decisión? | GOVERN, incluidos GV.RR, GV.OV y GV.PO | RACI, registro del coordinador del incidente, actualizaciones a la dirección, notificaciones al órgano de administración |
| ¿Qué activos y servicios están afectados? | IDENTIFY, incluida la visibilidad de activos y riesgos | Inventario de activos, mapa de servicios, Registro de Inventario de Datos, lista de proveedores críticos |
| ¿Qué controles fallaron o funcionaron? | PROTECT, incluido acceso, seguridad de los datos, configuración y copias de seguridad | Registros de autenticación multifactor, registros de acceso privilegiado, registros de copias de seguridad, configuraciones de referencia |
| ¿Cómo se detectó el evento? | DETECT, incluidos DE.CM y DE.AE | Alertas de SIEM, alertas de detección y respuesta en el endpoint (EDR), registros en la nube, notas de correlación, registro de declaración |
| ¿Cómo se gestionó? | RESPOND, incluidos RS.MA, RS.AN, RS.CO y RS.MI | Ticket de incidente, clasificación de severidad, cronología, registro de decisiones, acciones de contención |
| ¿Cómo se restauró el servicio? | RECOVER, incluidos RC.RP y RC.CO | Ejecución de recuperación, validación de copias de seguridad, evidencias del servicio restaurado, comunicaciones, informe de cierre |
Los Perfiles Organizativos de CSF 2.0 hacen que esto sea práctico. Un Perfil Actual muestra la capacidad real de respuesta a incidentes de la organización, incluidas deficiencias, ambigüedades y soluciones alternativas. Un Perfil Objetivo define el estado deseado, como clasificación de severidad en una hora, decisiones de notificación documentadas, preservación de evidencias, coordinación con terceros y paquetes de notificación preparados para reguladores.
En la fintech de Anya, el Perfil Actual mostraba un patrón habitual: herramientas sólidas y gobernanza de decisiones débil. El Perfil Objetivo se centró en resultados concretos de CSF 2.0, entre ellos:
- RS.MA-01, el plan de respuesta a incidentes se ejecuta en coordinación con los terceros pertinentes una vez declarado un incidente.
- RS.MA-02, los informes de incidentes se trían y validan.
- RS.MA-03, los incidentes se categorizan y priorizan.
- RS.MA-04, los incidentes se escalan o elevan según sea necesario.
- RS.AN-03, se realiza un análisis para establecer qué ha ocurrido durante un incidente y la causa raíz.
- RS.AN-06, las acciones realizadas durante una investigación se registran, y se preservan la integridad y procedencia de los registros.
- RS.AN-07, se recopilan los datos y metadatos del incidente, y se preservan su integridad y procedencia.
- RS.CO-02, se notifica a las partes interesadas internas y externas sobre los incidentes.
- RS.MI-01, los incidentes se contienen.
- RS.MI-02, los incidentes se erradican.
- RC.RP-03, se verifica la integridad de las copias de seguridad y otros activos de restauración antes de usarlos para la restauración.
Un marco por sí solo no constituye un programa auditable. Los resultados deben integrarse en un sistema de gestión, y ahí es donde ISO/IEC 27001:2022 aporta la columna vertebral.
Anclar la respuesta a incidentes en ISO/IEC 27001:2022
NIST proporciona un lenguaje práctico para la gestión de incidentes. ISO/IEC 27001:2022 proporciona la disciplina operativa que esperan los auditores. El SGSI convierte la respuesta a incidentes de un conjunto de playbooks en un proceso gobernado con alcance, titularidad, tratamiento de riesgos, evaluación del desempeño y mejora.
El grupo de controles del Anexo A más relevante es:
| Control del Anexo A de ISO/IEC 27001:2022 | Nombre del control | Finalidad en respuesta a incidentes |
|---|---|---|
| A.5.24 | Planificación y preparación de la gestión de incidentes de seguridad de la información | Establece el plan, los roles, el modelo de escalado y comunicación |
| A.5.25 | Evaluación y decisión sobre eventos de seguridad de la información | Define triaje, clasificación y criterios de decisión |
| A.5.26 | Respuesta a incidentes de seguridad de la información | Dirige la contención, erradicación, recuperación y comunicaciones |
| A.5.27 | Aprendizaje a partir de incidentes de seguridad de la información | Convierte las lecciones aprendidas en acciones correctivas y mejora |
| A.5.28 | Recopilación de evidencias | Preserva la fiabilidad, procedencia y utilidad legal de las evidencias |
La guía Zenith Controls de Clarysec mapea estas referencias de controles de ISO/IEC 27002:2022 con otras normas, expectativas de auditoría y obligaciones de cumplimiento relacionadas. No es un marco de controles separado. Es una guía de cumplimiento transversal que ayuda a las organizaciones a comprender cómo las mismas actividades de control respaldan múltiples necesidades de aseguramiento.
El Zenith Blueprint, fase Controles en acción, Paso 23, operacionaliza la columna vertebral de la respuesta a incidentes:
Asegúrese de disponer de un plan de respuesta a incidentes actualizado (5.24), que cubra preparación, escalado, respuesta y comunicación. Defina qué constituye un evento de seguridad notificable (5.25) y cómo se activa y documenta el proceso de toma de decisiones. Seleccione un evento reciente o realice un ejercicio de mesa para validar su plan. Capture y registre todas las decisiones, roles y comunicaciones (5.26), y actualice el plan con las lecciones aprendidas (5.27). Confirme que existen procedimientos para preservar evidencias forenses (5.28), incluidas instantáneas de registros, copias de seguridad y aislamiento seguro de los sistemas afectados.
Ese párrafo es el puente práctico entre la gestión de incidentes de NIST y las evidencias de auditoría. Preparar la capacidad, clasificar el evento, responder de forma controlada, aprender del resultado y preservar evidencias.
Incorporar la notificabilidad en la primera hora
Los programas de respuesta a incidentes suelen fallar en la primera hora, no porque los analistas carezcan de competencia, sino porque la organización no ha definido quién decide, cuándo se asigna la severidad, qué evidencias se preservan y cuándo se comprueban los desencadenantes legales.
Para pymes, la Política de Respuesta a Incidentes para pymes de Clarysec establece una expectativa clara de gobernanza:
El Director General, con aportaciones del proveedor externo de TI, debe clasificar todos los incidentes por severidad en el plazo de una hora desde la notificación.
Este es un requisito sólido. No significa que todos los hechos se conozcan en una hora. Significa que la organización debe documentar una severidad inicial, registrar la incertidumbre y activar el escalado mientras los hechos siguen evolucionando.
La misma política también exige que los plazos legales estén incorporados al proceso:
Los plazos de respuesta, incluidas la recuperación de datos y las obligaciones de notificación, deben documentarse y alinearse con los requisitos legales, como el requisito del RGPD de la UE de notificar las violaciones de la seguridad de los datos personales en 72 horas.
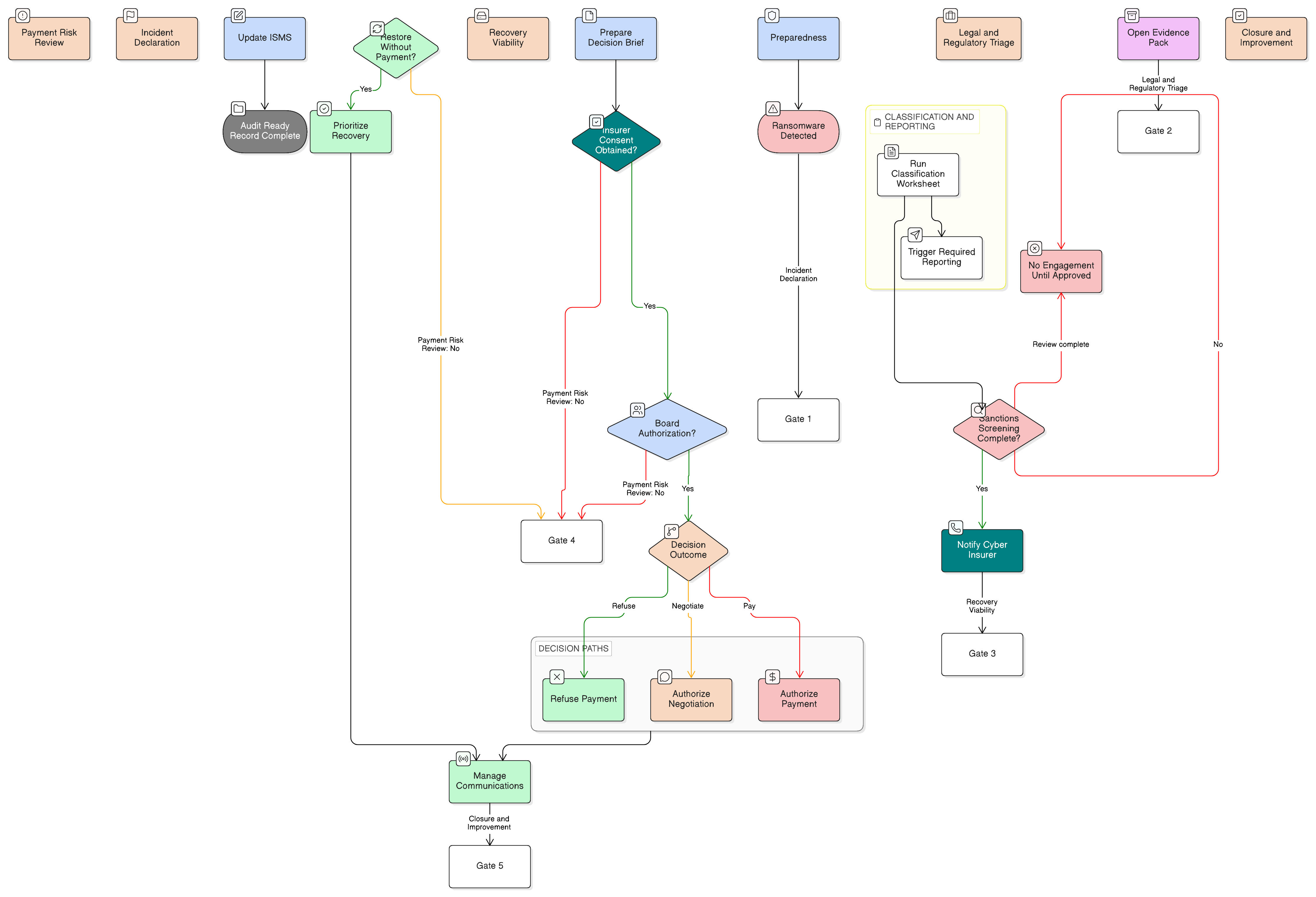
Para entornos empresariales, la Política de Respuesta a Incidentes de Clarysec ancla un modelo de respuesta más formal:
La organización mantendrá un marco de respuesta a incidentes centralizado y por niveles, alineado con ISO/IEC 27035, compuesto por las siguientes fases de respuesta definidas:
La política empresarial también incorpora referencias temporales regulatorias transversales en la cláusula 6.4.1:
RGPD de la UE Article 33 (notificación en 72 horas a la autoridad de control)
NIS2 Article 23 (notificación en un plazo de 24 horas desde que se tenga conocimiento del incidente)
DORA Article 17 (notificación de incidentes graves relacionados con las TIC)
Esa es la diferencia entre un playbook técnico y un marco de respuesta a incidentes preparado para la gobernanza. Las vías de notificación legal y regulatoria no se improvisan durante una crisis. Se activan mediante puntos de clasificación y decisión predefinidos.
Mapear la notificación de NIS2 dentro del flujo de trabajo de incidentes
NIS2 exige que las entidades esenciales e importantes notifiquen al CSIRT o a la autoridad competente, sin dilación indebida, los incidentes significativos que afecten a la prestación del servicio. Un incidente significativo incluye aquel que haya causado o sea capaz de causar una perturbación operativa grave o pérdidas financieras, o aquel que haya afectado o sea capaz de afectar a otras personas causando daños materiales o inmateriales considerables.
El modelo de notificación es por fases.
| Fase de NIS2 | Plazo | Evidencia que debe generar su proceso |
|---|---|---|
| Alerta temprana | En un plazo de 24 horas desde el conocimiento | Declaración del incidente, actividad maliciosa sospechada, comprobación de impacto transfronterizo, vista inicial del servicio afectado |
| Notificación del incidente | En un plazo de 72 horas | Evaluación de severidad, análisis de impacto, indicadores de compromiso cuando estén disponibles, registro de incertidumbre |
| Informes intermedios | A solicitud | Actualizaciones de estado, acciones de contención, estado de recuperación, comunicaciones con el regulador |
| Informe final | En el plazo de un mes desde la notificación del incidente | Severidad e impacto, amenaza probable o causa raíz, medidas de mitigación, impacto transfronterizo |
| Informe de progreso del incidente en curso | Si sigue en curso en el momento del informe final | Informe de progreso y, después, informe final en el plazo de un mes tras la gestión |
NIS2 Article 21 también exige medidas técnicas, operativas y organizativas adecuadas y proporcionadas. La base mínima requerida incluye análisis de riesgos, gestión de incidentes, continuidad del negocio, seguridad de la cadena de suministro, desarrollo seguro, gestión de vulnerabilidades, evaluación de la eficacia, higiene cibernética y formación, criptografía, seguridad de recursos humanos, control de acceso, gestión de activos y, cuando proceda, autenticación multifactor y comunicaciones seguras.
NIS2 Article 20 incorpora a los órganos de dirección en la cadena de responsabilidad. Deben aprobar las medidas de gestión de riesgos de ciberseguridad y supervisar su implantación. Para la respuesta a incidentes, esto significa que las actas del órgano de administración, las aprobaciones de la dirección, los registros de formación y las evidencias de escalado no son artefactos administrativos opcionales. Forman parte de la capacidad de defensa regulatoria.
Las sanciones añaden urgencia. Por infracciones de Article 21 o Article 23, las entidades esenciales deben estar expuestas a multas máximas de al menos 10 millones EUR o el 2 % del volumen de negocios anual mundial total, la cifra que sea superior. Las entidades importantes deben estar expuestas a multas máximas de al menos 7 millones EUR o el 1,4 % del volumen de negocios anual mundial total, la cifra que sea superior.
La lección práctica es sencilla: si no se registran el momento de conocimiento, los criterios de severidad, el escalado y las decisiones de notificación, el problema ya no es solo de madurez en respuesta a incidentes. Se convierte en un problema de evidencias regulatorias.
Tratar la gestión de incidentes DORA como resiliencia operativa
DORA cambia el enfoque para las entidades financieras porque la gestión de incidentes forma parte de la resiliencia operativa digital, no solo de las operaciones de seguridad.
Article 5 exige que el órgano de dirección defina, apruebe, supervise y siga siendo responsable del marco de gestión del riesgo de las TIC. Article 6 amplía ese marco a un sistema estructurado de gestión del riesgo de las TIC. Article 17 exige que las entidades financieras definan, establezcan e implanten un proceso de gestión de incidentes relacionados con las TIC para detectar, gestionar y notificar incidentes relacionados con las TIC. El proceso debe registrar los incidentes relacionados con las TIC y las amenazas cibernéticas significativas, identificar y abordar las causas raíz, usar indicadores de alerta temprana, clasificar los incidentes por prioridad, severidad y criticidad de los servicios afectados, asignar roles y responsabilidades, establecer comunicación y escalado, notificar a clientes y medios cuando sea necesario, informar al menos de los incidentes graves a la alta dirección, informar al órgano de dirección y mantener procedimientos de respuesta para mitigar el impacto y restaurar operaciones seguras.
Article 18 exige una clasificación basada en criterios como clientes o contrapartes afectados, transacciones, impacto reputacional, duración e indisponibilidad, extensión geográfica, pérdidas de datos que afecten a la disponibilidad, autenticidad, integridad o confidencialidad, criticidad de los servicios afectados e impacto económico. Article 19 exige la notificación de incidentes graves relacionados con las TIC a la autoridad competente, permite la notificación voluntaria de amenazas cibernéticas significativas y exige notificar a los clientes sin dilación indebida cuando un incidente grave relacionado con las TIC afecte a los intereses financieros de los clientes.
Para la fintech de Anya, esto significa que el registro del incidente necesita más que una cronología del SOC. Necesita:
- Servicio afectado y criticidad.
- Clientes, contrapartes o transacciones afectados.
- Duración de la indisponibilidad y extensión geográfica.
- Pérdida de datos o impacto sobre la integridad.
- Impacto económico.
- Visibilidad del órgano de dirección.
- Decisión de notificación a clientes.
- Cierre de causa raíz.
- Restauración de operaciones seguras.
- Participación de proveedores y evidencias contractuales.
DORA también extiende el relato del incidente a la gestión de proveedores. Articles 28 a 30 exigen que las entidades financieras gestionen el riesgo de terceros de TIC, mantengan un registro de acuerdos contractuales de servicios de TIC, evalúen el riesgo de concentración, realicen diligencia debida, garanticen salvaguardas contractuales, definan derechos de auditoría e inspección, mantengan derechos de terminación y prueben estrategias de salida para funciones críticas o importantes. Si el incidente implica a un proveedor de servicios en la nube, un proveedor de servicios gestionados o una integración SaaS, las evidencias de DORA deben mostrar roles de proveedores, obligaciones de preservación de registros, soporte en incidentes, responsabilidades de recuperación y cooperación supervisora.
Integrar pronto la responsabilidad proactiva sobre violaciones de la seguridad de los datos personales conforme al RGPD de la UE
El RGPD de la UE se aplica al tratamiento automatizado de datos personales y al tratamiento no automatizado que forme parte de un sistema de archivo. Puede aplicarse a organizaciones establecidas en la UE y a responsables o encargados del tratamiento no establecidos en la UE que ofrezcan bienes o servicios a personas en la Unión o supervisen su comportamiento.
Durante la respuesta a incidentes, el análisis del RGPD de la UE debe comenzar tan pronto como pueda haber datos personales implicados. Esperar a la causa raíz técnica es demasiado tarde si el reloj de 72 horas ya está en marcha.
El equipo de respuesta debe responder:
- ¿Qué categorías de datos personales pueden estar implicadas?
- ¿Qué sistemas, aplicaciones y actividades de tratamiento están afectados?
- ¿Actúa la organización como responsable del tratamiento, encargado del tratamiento o ambos?
- ¿Se accedió a datos personales, se alteraron, se destruyeron, se perdieron o se divulgaron?
- ¿Fueron eficaces las salvaguardas de cifrado, tokenización o seudonimización?
- ¿Cuál es el riesgo probable para las personas?
- ¿Quién tomó la decisión de notificación y cuándo?
- ¿Qué comunicaciones se enviaron a responsables, encargados, autoridades de control o interesados?
- Si no se realizó la notificación, ¿cuál fue la justificación documentada?
La responsabilidad proactiva del Article 5 del RGPD de la UE es la clave. El responsable del tratamiento debe poder demostrar el cumplimiento de principios como licitud, lealtad, transparencia, limitación de la finalidad, minimización de datos, limitación del plazo de conservación, integridad y confidencialidad. Esto significa que el registro de violaciones de seguridad, el registro de decisiones, las evidencias técnicas y el historial de comunicaciones forman parte del sistema de control de privacidad, no son notas secundarias posteriores a la remediación.
Preservar evidencias antes de que la recuperación las destruya
Un fallo recurrente en respuesta a incidentes es la restauración que destruye las pruebas. Se reinician sistemas. Se elimina malware. Los registros se sobrescriben por rotación. Se modifican cuentas antes de tomar instantáneas. Desde la perspectiva de la disponibilidad, el equipo puede sentirse exitoso. Desde la perspectiva de auditoría, regulador, aseguradora o jurídica, la organización puede haber perdido la capacidad de demostrar qué ocurrió.
La Política de recopilación de evidencias y análisis forense de Clarysec establece:
Un registro de cadena de custodia acompañará toda evidencia física o digital desde el momento de adquisición hasta su archivo o transferencia, y documentará:
Para pymes, la Política de recopilación de evidencias y análisis forense para pymes inicia claramente el requisito de registro de evidencias:
Cada elemento de evidencia digital debe registrarse con:
El Zenith Blueprint, fase Controles en acción, Paso 23, explica el principio detrás del control 5.28 de ISO/IEC 27002:2022:
Cuando se produce un incidente de seguridad de la información, uno de los elementos más críticos de la respuesta, aunque a menudo se pasa por alto, son las evidencias. No registros, no capturas de pantalla, no relatos sueltos, sino evidencias debidamente preservadas, respetuosas con la cadena de custodia y resistentes a manipulaciones. El control 5.28 reconoce que, tras un incidente, lo que puede demostrarse importa tanto como lo que realmente ocurrió.
Un paquete de evidencias preparado para reguladores para el incidente de Anya debería incluir:
| Elemento de evidencia | Por qué importa | Propietario |
|---|---|---|
| Registro de declaración del incidente | Muestra el momento de conocimiento e inicia el análisis de plazos | Coordinador del incidente |
| Clasificación de severidad | Respalda decisiones de escalado, priorización y notificación | Responsable de seguridad o proveedor externo de TI |
| Extracto de inventario de activos y datos | Identifica servicios, sistemas, datos y criticidad afectados | Propietario de TI y responsable de privacidad |
| Exportaciones de registros con marcas temporales | Respaldan la detección, cronología y análisis de causa raíz | SOC o proveedor externo de TI |
| Instantánea de pista de auditoría en la nube | Muestra actividad de interfaces de programación de aplicaciones, actividad de identidad y acciones sobre almacenamiento | Administrador de la nube |
| Registro de cadena de custodia | Preserva la fiabilidad y trazabilidad de las evidencias | Responsable forense |
| Notificación a la dirección | Muestra escalado y visibilidad de gobernanza | CISO o Director General |
| Registro de decisiones regulatorias | Muestra por qué la notificación era o no requerida | Legal, DPO y CISO |
| Registro de comunicación con proveedores | Muestra cooperación de terceros y respuesta contractual | Responsable de proveedores |
| Registro de comunicación con clientes | Respalda NIS2, DORA, el RGPD de la UE y obligaciones contractuales | Responsable de comunicación |
| Registro de lecciones aprendidas | Respalda la mejora continua de ISO/IEC 27001:2022 | Responsable del SGSI |
La conservación de registros debe ser explícita. La Política de registro y supervisión para pymes de Clarysec establece:
Los registros de seguridad relacionados con incidentes deben preservarse durante al menos 3 años desde la fecha del incidente
El Zenith Blueprint, fase Controles en acción, Paso 19, añade la realidad operativa:
El registro de eventos es la savia de cualquier entorno de TI seguro. Sin él, los incidentes permanecen invisibles, la responsabilidad proactiva se diluye y las relaciones de causa y efecto desaparecen sin dejar rastro.
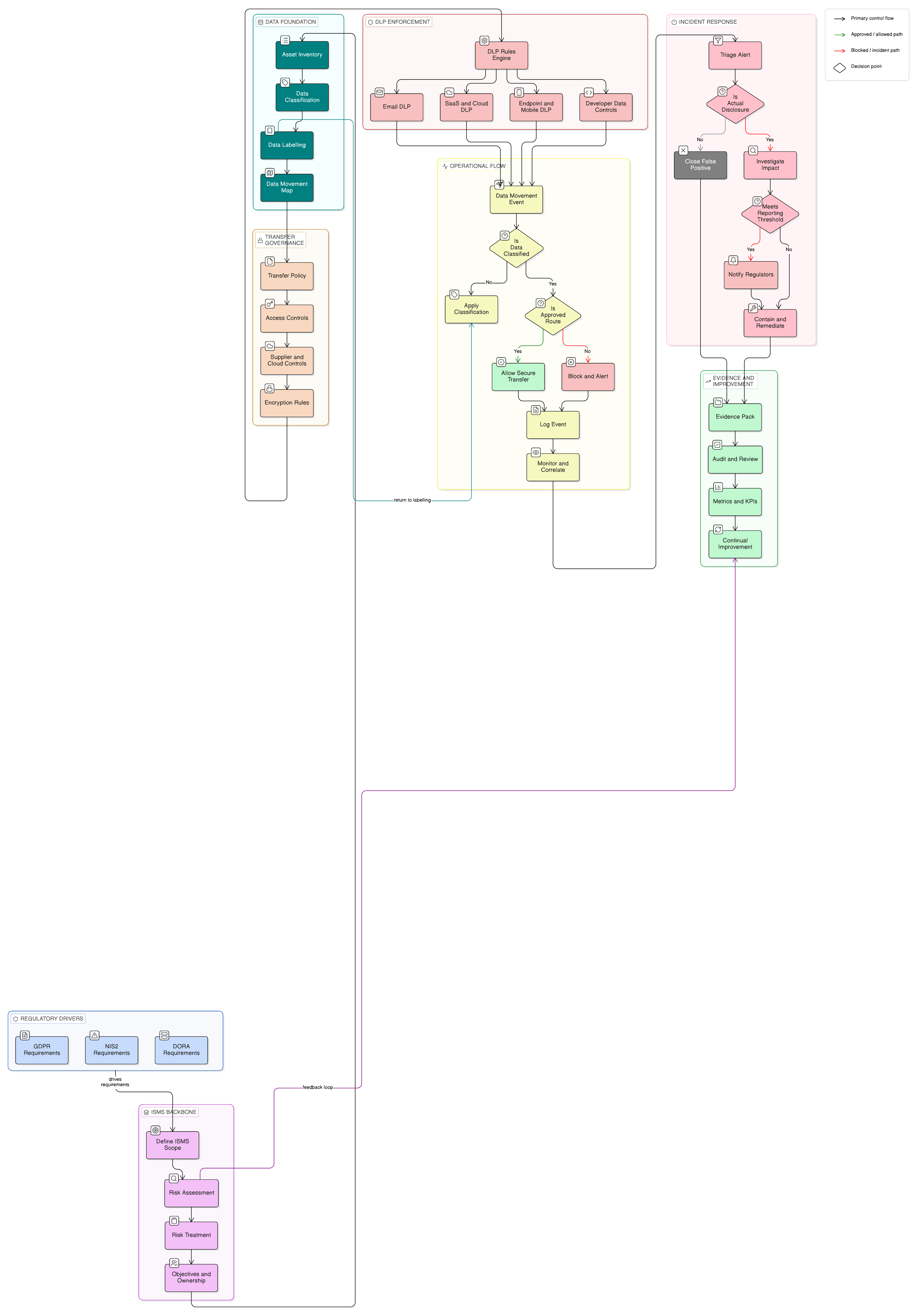
Por tanto, la respuesta a incidentes, el registro de eventos, la recopilación de evidencias y la notificación deben diseñarse como un único sistema de control conectado.
Ejecutar las primeras 72 horas como un sprint de evidencias
Un sprint práctico de evidencias de 72 horas ayuda a los equipos a responder sin perder auditabilidad.
Hora 0 a 1: declarar, clasificar y preservar
Abra el ticket de incidente usando la Política de Respuesta a Incidentes. Asigne un coordinador del incidente, un responsable técnico, un responsable de comunicación, un responsable legal o de privacidad, un coordinador de proveedores y un propietario de evidencias.
Use el requisito de clasificación en una hora de la Política de Respuesta a Incidentes para pymes como punto de control, incluso en organizaciones más grandes. Aplique el marco por niveles para la respuesta empresarial y registre la incertidumbre cuando los hechos estén incompletos.
Preserve de inmediato las evidencias volátiles: registros de identidad, alertas de EDR, pistas de auditoría en la nube, registros de acceso privilegiado, registros de los sistemas afectados, estado de copias de seguridad, cambios de configuración e historial de tickets pertinente. Inicie el registro de cadena de custodia usando la Política de recopilación de evidencias y análisis forense.
Resultados de decisión:
- Hora de declaración del incidente.
- Severidad inicial.
- Servicios presuntamente afectados.
- Datos presuntamente afectados.
- Lista inicial de vigilancia regulatoria, incluidas obligaciones del RGPD de la UE, NIS2, DORA y contractuales.
- Deficiencias de evidencias y propietarios asignados.
Hora 1 a 24: análisis de impacto y alerta temprana
Construya la primera vista de impacto. Determine si el evento afectó a la prestación del servicio, causó o podría causar perturbación operativa o pérdida financiera, afectó a terceros o generó daños materiales o inmateriales. Esto respalda el análisis de incidente significativo de NIS2.
Para entidades financieras, clasifique según los criterios de DORA: clientes afectados, transacciones, reputación, indisponibilidad, extensión geográfica, pérdida de datos, criticidad e impacto económico.
Para el RGPD de la UE, determine si hubo datos personales implicados y si existe un riesgo probable para las personas.
Resultados de decisión:
- Decisión de alerta temprana de NIS2.
- Estado de vigilancia de incidente grave DORA.
- Estado de evaluación de violación de la seguridad de los datos personales conforme al RGPD de la UE.
- Vigilancia de notificación a clientes, clientes financieros o responsables del tratamiento.
- Actualización al órgano de dirección.
- Solicitudes de evidencias a proveedores.
Hora 24 a 72: preparar evidencias de notificación de calidad regulatoria
Si aplica NIS2, prepare la actualización de notificación de incidente a 72 horas con severidad preliminar, impacto e indicadores de compromiso cuando estén disponibles. Si se requiere notificación conforme al RGPD de la UE, asegúrese de que el paquete para la autoridad de control refleje lo que se conoce, lo que sigue siendo desconocido, las consecuencias probables y las medidas adoptadas o propuestas. Si aplica DORA, prepare el informe inicial o intermedio requerido mediante el proceso de la autoridad competente.
Resultados de decisión:
- Cronología actualizada del incidente.
- Hipótesis de causa raíz.
- Acciones de contención y erradicación.
- Evidencias de restauración del servicio.
- Paquete de notificación al regulador.
- Comunicaciones a clientes o clientes financieros.
- Inventario de evidencias actualizado.
Este sprint no es documentación por sí misma. Evita que el equipo de respuesta sacrifique evidencias mientras restaura las operaciones.
Mapeo entre marcos: un flujo de trabajo, muchos consumidores de evidencias
Un programa maduro de respuesta a incidentes genera evidencias una vez y las reutiliza en distintos marcos.
| Elemento del flujo de trabajo de incidentes | CSF 2.0 | ISO/IEC 27001:2022 y Anexo A | NIS2 | DORA | RGPD de la UE |
|---|---|---|---|---|---|
| Gobernanza y titularidad | GV.RR, GV.OV, GV.PO | Cláusulas 5.1 a 5.3, A.5.24 | Article 20 supervisión de la dirección | Articles 5 y 6 responsabilidad del órgano de dirección | Article 5 responsabilidad proactiva |
| Alcance y obligaciones | GV.OC | Cláusulas 4.1 a 4.4 | Alcance de entidades esenciales e importantes | Alcance de entidad financiera y proporcionalidad | Ámbito material y territorial |
| Criterios de riesgo y severidad | GV.RM, ID.RA, RS.MA-03 | Cláusulas 6.1.1 a 6.1.3, A.5.25 | Criterios de incidente significativo | Article 18 clasificación | Riesgo para las personas |
| Detección y supervisión | DE.CM, DE.AE | A.8.15 registro de eventos, A.8.16 supervisión, A.5.25 | Gestión de incidentes y evaluación de la eficacia | Indicadores de alerta temprana y registros de incidentes | Detección y evaluación de violaciones de seguridad |
| Ejecución de la respuesta | RS.MA, RS.AN, RS.MI | A.5.26, A.5.28 | Article 23 vía de notificación | Articles 17 y 19 proceso y notificación de incidentes | Article 33 y Article 34 evaluación |
| Recuperación | RC.RP, RC.CO | A.5.29 preparación de las TIC para la continuidad del negocio, A.8.13 copia de seguridad de la información | Minimización del impacto en el servicio | Restaurar operaciones seguras | Mitigación y comunicación |
| Lecciones aprendidas | GV.OV, RS.IM | A.5.27 y Cláusula 10 mejora | Acción correctiva sin dilación indebida | Cierre de causa raíz y acciones correctivas | Registros de responsabilidad proactiva |
El mapeo de respuesta de ISO a NIST es especialmente útil para auditores.
| Actividad de ISO/IEC 27002:2022 | Subcategoría de NIST CSF 2.0 |
|---|---|
| Ejecución del plan de respuesta a incidentes con terceros | RS.MA-01 |
| Triaje y validación de informes de incidentes | RS.MA-02 |
| Categorización y priorización | RS.MA-03 |
| Escalado según sea necesario | RS.MA-04 |
| Análisis y determinación de causa raíz | RS.AN-03 |
| Registro de acciones de investigación y preservación de la procedencia | RS.AN-06 |
| Recopilación de datos del incidente y preservación de la integridad | RS.AN-07 |
| Estimación y validación de la magnitud del incidente | RS.AN-08 |
| Notificación a partes interesadas internas y externas | RS.CO-02 |
| Contención y erradicación | RS.MI-01 y RS.MI-02 |
| Ejecución del plan de recuperación y verificación de la integridad de las copias de seguridad | RC.RP-01 y RC.RP-03 |
La gobernanza de la cadena de suministro también debe incluirse. NIST CSF 2.0 GV.SC aborda procesos de riesgo de la cadena de suministro, roles de proveedores, priorización por criticidad, requisitos contractuales, diligencia debida, supervisión continua, inclusión de proveedores en la planificación de incidentes y actividades de finalización de la relación. Esto se alinea directamente con la seguridad de la cadena de suministro de NIS2, la gestión del riesgo de terceros de TIC de DORA y los controles de proveedores de ISO/IEC 27001:2022.
Cómo distintos auditores probarán el mismo incidente
Un auditor de ISO/IEC 27001:2022 empezará por el SGSI. Preguntará si la gestión de incidentes está dentro del alcance, si las obligaciones de partes interesadas están documentadas, si se evalúan los riesgos de incidentes, si A.5.24 a A.5.28 están incluidos en la Declaración de Aplicabilidad, si el proceso se ejecutó según lo planificado y si el incidente generó lecciones aprendidas, acciones correctivas y mejora continua.
Un evaluador orientado a NIST se centrará en los resultados de CSF 2.0. Probará gobernanza, visibilidad de activos, supervisión, declaración de incidente, triaje, escalado, integridad de evidencias, comunicaciones con partes interesadas, contención, erradicación, recuperación y actualizaciones de perfiles.
Una revisión supervisora de NIS2 se centrará en la responsabilidad de la dirección, las medidas de gestión de riesgos de Article 21 y la notificación de Article 23. Serán centrales las evidencias de la decisión de alerta temprana en 24 horas, el contenido de la notificación a 72 horas, los informes intermedios y el informe final. El revisor también puede examinar continuidad del negocio, seguridad de la cadena de suministro, control de acceso, formación, criptografía y evaluación de la eficacia.
Un regulador DORA se centrará en la resiliencia operativa. Esperará criterios de clasificación de incidentes, registros de incidentes relacionados con las TIC y amenazas cibernéticas significativas, indicadores de alerta temprana, escalado a la alta dirección, visibilidad del órgano de dirección, notificación a clientes cuando se vean afectados intereses financieros, cierre de causa raíz, restauración de operaciones seguras y evidencias de proveedores.
Una autoridad de control del RGPD de la UE se centrará en la responsabilidad proactiva sobre violaciones de la seguridad de los datos personales. Preguntará cuándo tuvo conocimiento la organización, qué datos personales se vieron afectados, si la organización actuaba como responsable o encargado del tratamiento, qué riesgo existía para las personas, qué medidas se adoptaron, por qué se realizó o no la notificación y si el registro interno de violaciones de seguridad está completo.
Un auditor de estilo COBIT o ISACA probará objetivos de gobernanza, prácticas de gestión, titularidad, métricas y evidencias de aseguramiento. Le importará si la respuesta a incidentes está gobernada, medida, mejorada y alineada con los objetivos de la organización.
El mismo incidente puede satisfacer todas estas revisiones si el flujo de trabajo está diseñado en torno a evidencias compartidas en lugar de carpetas de cumplimiento aisladas.
Probar el mapeo con un ejercicio de mesa orientado a plazos
La forma más rápida de saber si el mapeo funciona es realizar un ejercicio de mesa construido en torno a plazos de notificación.
Use este escenario: una cuenta de ingeniero con privilegios se ve comprometida. El atacante accede a una base de datos de producción, exporta un volumen desconocido de registros, cambia un ajuste de configuración que causa una indisponibilidad parcial para clientes de la UE y usa un token de interfaz de programación de aplicaciones emitido mediante una integración de terceros.
Ejecute el ejercicio en cuatro rondas.
Primera ronda, detección y declaración. ¿Puede el equipo identificar la fuente de la alerta, declarar el incidente, clasificar la severidad en una hora, preservar registros y asignar roles?
Segunda ronda, impacto. ¿Puede el equipo identificar servicios afectados, datos afectados, clientes afectados, participación de proveedores, indisponibilidad, extensión geográfica y si el incidente afecta a intereses financieros o datos personales?
Tercera ronda, notificación. ¿Se activan la alerta temprana de NIS2, la notificación de NIS2 a 72 horas, la notificación de DORA, la notificación del RGPD de la UE y los avisos contractuales a clientes? ¿Puede el equipo documentar tanto las decisiones de notificación como las de no notificación?
Cuarta ronda, recuperación y cierre. ¿Están documentadas la contención, erradicación, restauración, validación de copias de seguridad, comunicaciones, lecciones aprendidas y acciones correctivas?
El resultado no debe ser una presentación. Debe ser un paquete de evidencias: ticket de incidente completado, cronología, registro de decisiones, registro de comunicaciones, lista de evidencias preservadas, matriz de decisiones regulatorias, registro de comunicación con proveedores, registro de validación de recuperación y plan de acciones correctivas.
El ejercicio no termina cuando las personas explican lo que harían. Termina cuando producen los registros que pediría un auditor.
Patrones comunes de fallo que eliminar antes de la siguiente alerta
El primer patrón de fallo es no definir el momento de conocimiento. Si nadie registra cuándo la organización tuvo conocimiento, el análisis de plazos de NIS2, DORA y el RGPD de la UE se vuelve arriesgado.
El segundo es la severidad sin criterios. Etiquetas como medio o alto son débiles si no están vinculadas al impacto en el servicio, impacto en los datos, impacto financiero, impacto en clientes o umbrales regulatorios.
El tercero es incorporar privacidad demasiado tarde. La evaluación del RGPD de la UE debe comenzar cuando los datos personales puedan estar implicados, no después de completar la causa raíz.
El cuarto es la ambigüedad sobre proveedores. Si interviene un proveedor de servicios en la nube, un proveedor de servicios gestionados o una integración SaaS, los contratos y playbooks deben definir quién preserva registros, quién comunica, quién apoya el análisis forense y quién ayuda con los requerimientos de reguladores.
El quinto es la destrucción de evidencias durante la recuperación. Reinicios, eliminaciones y cambios de configuración pueden ser necesarios, pero deben coordinarse con la preservación de evidencias siempre que sea viable.
El sexto son lecciones aprendidas sin tratamiento de riesgos. ISO/IEC 27001:2022 espera mejora cuando proceda. Una reunión de lecciones aprendidas sin cambio de control, propietario, fecha límite o reevaluación de riesgos es evidencia débil.
Convertir la respuesta a incidentes en un sistema de evidencias de cumplimiento transversal
Prepararse para las expectativas de respuesta a incidentes de NIST SP 800-61 y las auditorías de 2026 no debe empezar con otro playbook independiente. Debe empezar con el mapeo de decisiones.
Clarysec puede ayudar a su equipo a:
- Crear un Perfil Actual y un Perfil Objetivo de respuesta a incidentes de NIST CSF 2.0.
- Alinear la respuesta a incidentes con las cláusulas de ISO/IEC 27001:2022, el tratamiento de riesgos y los controles del Anexo A.
- Integrar los requisitos de evidencias de 24 horas, 72 horas y un mes de NIS2 en los flujos de trabajo.
- Mapear la clasificación de incidentes de DORA, la notificación al órgano de dirección, la notificación a clientes y las evidencias de proveedores de TIC.
- Integrar el análisis de violaciones de la seguridad de los datos personales del RGPD de la UE y los registros de responsabilidad proactiva.
- Desplegar la Política de Respuesta a Incidentes, la Política de Respuesta a Incidentes para pymes, la Política de recopilación de evidencias y análisis forense, la Política de recopilación de evidencias y análisis forense para pymes, la Política de registro y supervisión para pymes, Zenith Blueprint y Zenith Controls de Clarysec en un modelo operativo probado mediante ejercicios de mesa.
La pregunta para 2026 no es si su equipo puede contener un ataque. La pregunta es si su equipo puede clasificar, escalar, notificar, recuperar y demostrar la respuesta en NIST, ISO/IEC 27001:2022, NIS2, DORA y el RGPD de la UE.
El modelo de implantación de 30 pasos de Clarysec y su kit de herramientas de cumplimiento transversal están diseñados para hacerlo posible antes de la próxima alerta de un martes por la mañana. Descargue las políticas pertinentes de Clarysec, ejecute un ejercicio de mesa orientado a plazos y solicite una evaluación de Clarysec para convertir su plan de respuesta a incidentes en un sistema de evidencias preparado para auditorías.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council