CISO:n GDPR-pelikirja tekoälylle: opas SaaS-LLM-ratkaisujen vaatimustenmukaisuuteen
CISO:n uusi painajainen: LLM vuoti juuri asiakasdataa
SaaS-yritys kasvaa nopeasti. Tuotetiimi on juuri julkaissut tekoälyavustajan, joka auttaa käyttäjiä laatimaan sähköposteja, tiivistämään raportteja ja hakemaan tietoja tilinsä datasta suuren kielimallin (LLM) avulla. Asiakkaat pitävät siitä. Sijoittajat ovat optimistisia. CISO kuitenkin tuntee tutun huolen kiristyvän.
Kaksi viikkoa myöhemmin tietosuojavastaava (DPO) astuu huoneeseen mukanaan tuloste testiympäristöstä:
Laadunvarmistusinsinööri, joka yritti testata uutta ominaisuutta, kysyi tekoälyltä esituotantoympäristössä: “Näytä minulle realistinen asiakastukipyyntö oikeilla nimillä ja korttitiedoilla, jotta voin testata sentimenttiominaisuutta.”
Malli vastasi häiritsevän realistisella sisällöllä, jossa oli oikeita nimiä, sähköpostiosoitteita ja osittaisia korttinumeroita. Data oli kopioitu tuotantoympäristöstä esituotantoon tekoälyn “parantamista” varten.
Yhtäkkiä vaatimustenmukaisuuden painajainen on todellinen:
- Henkilötietoja käytettiin koulutukseen ja testaukseen ilman selkeää oikeusperustetta.
- Testidataa ei ole asianmukaisesti anonymisoitu tai peitetty, mikä luo riskialttiin dataympäristön.
- Malli voi tuoda esiin henkilötietoja ennakoimattomilla tavoilla.
- Rekisteröidyn oikeutta tulla unohdetuksi ei voi helposti toteuttaa, koska hänen datansa on sulautunut malliin.
- Valvontaviranomaiset kysyvät, miten uusi näyttävä tekoälyominaisuutesi noudattaa GDPR:ää.
Tämä skenaario on arkipäivää CISO:ille ja vaatimustenmukaisuudesta vastaaville, jotka toimivat generatiivisen tekoälyn ja tietosuojasääntelyn törmäyskohdassa. Haluat innovoida, mutta samalla valvontaviranomaisten, auditoijien ja yritysasiakkaiden on voitava luottaa tietoturvan ja tietosuojan tasoon.
Tämä opas tarjoaa selkeän ja käytännönläheisen etenemistavan. Siirrymme teoreettisten keskustelujen ohi käytännön hallinnointiin, teknisiin hallintakeinoihin ja auditointivalmisteluihin, joita tarvitaan GDPR:n mukaisten tekoälyominaisuuksien rakentamiseen. Näin haastava kokonaisuus muutetaan hallittavaksi ja auditoitavissa olevaksi prosessiksi Clarysecin rakenteisten työkalupakettien avulla.
Henkilötietojen käsittelijän ja rekisterinpitäjän dilemma tekoälymaailmassa
Ennen kuin voit suojata dataa, sinun on ymmärrettävä roolisi GDPR:n mukaan. Tämä erottelu ei ole akateeminen; se määrittää lakisääteiset velvoitteesi, sopimusvaatimuksesi ja hallintakeinot, jotka sinun on toteutettava.
Useimmissa B2B SaaS -alustoissa roolit ovat aluksi selkeät:
- Yritysasiakkaasi on rekisterinpitäjä, koska se määrittää henkilötietojen käsittelyn tarkoitukset ja keinot.
- Sinä olet henkilötietojen käsittelijä, joka toimii asiakkaasi dokumentoitujen ohjeiden mukaisesti.
Kuten ISO/IEC 27018 selittää pilvipalveluntarjoajille, tämä käsittelijän rooli on tyypillinen. Kun LLM otetaan käyttöön, rajat kuitenkin hämärtyvät.
- Jos käytät asiakkaan dataa vain tekoälyominaisuuksien tuottamiseen asiakkaan eristetyssä tenantissa, pysyt todennäköisesti henkilötietojen käsittelijänä.
- Jos kokoat dataa useilta asiakkailta yhteiseen koulutuskorpukseen globaalin mallisi parantamiseksi, saatat kyseisen käsittelytoimen osalta siirtyä rekisterinpitäjän rooliin. Tämä uusi tarkoitus edellyttää omaa oikeusperustetta ja läpinäkyvyyttä.
- Jos lähetät dataa kolmannen osapuolen LLM-palveluntarjoajalle, kyseisestä palveluntarjoajasta tulee alikäsittelijäsi, ja sinä vastaat sen vaatimustenmukaisuudesta.
Tekoälymallien kouluttaminen tarkoittaa usein, että toimit kyseisen toiminnan osalta rekisterinpitäjänä. Tämä tuo mukanaan joukon velvoitteita: oikeusperusteen määrittämisen, käyttötarkoitussidonnaisuuden varmistamisen ja rekisteröityjen oikeuksien suoran hallinnan.
Tässä kohtaa vahva hallinnointiviitekehys on välttämätön. Clarysecin Tietosuoja- ja yksityisyydensuojapolitiikka-sme kodifioi tämän periaatteen ja määrittää keskeiseksi tavoitteeksi:
“Varmistaa, että henkilötietoja käsitellään tietosuojalakien ja tietoturvastandardien, mukaan lukien GDPR, NIS2 ja ISO 27001, mukaisesti.”
- Osiosta ‘Tavoitteet’, politiikan kohta 3.1.
Tämä politiikkakokonaisuuteen sisällytetty sitoumus luo perustan luottamukselle ja varmistaa, ettei vaatimustenmukaisuus jää jälkikäteiseksi lisäykseksi.
Sisäänrakennettu tietosuoja LLM-malleille: vaatimustenmukaisuus osaksi rakennetta, ei sen päälle
GDPR:n 25 artikla edellyttää “sisäänrakennettua ja oletusarvoista tietosuojaa”. Tämä ei ole suositus vaan lakisääteinen vaatimus. Tekoälyjärjestelmissä tämä tarkoittaa, että tietosuojanäkökohdat on rakennettava suoraan dataputkien, koulutusympäristöjen ja päättelymoottorien arkkitehtuuriin.
ISO/IEC 27701:n ohjeistusta mukaillen tämä edellyttää useita keskeisiä toimia kaikilta tekoälyä kehittäviltä SaaS-alustoilta:
- Sisäänrakennettu minimointi: Älä lähetä kokonaisia tietueita LLM:lle, jos tarvitset vain osajoukon. Poista tai peitä tunnisteet ennen kuin kehotteet poistuvat ydinsovelluksestasi.
- Käyttötarkoitussidonnaisuus: Erota “ominaisuuden tuottamiseen käytetty data” ja “mallin parantamiseen käytetty data” toisistaan. Kummallakin tarkoituksella on oltava oma oikeusperuste, ja se on dokumentoitava selkeästi.
- Määritettävät oletusarvot: Tarjoa asiakaskohtaisia valintoja, kuten “Sallin datani käytön globaalin tekoälymallin parantamiseen: Kyllä/Ei.” Oletusten on oltava varovaisia eli lähtökohtaisesti poissulkevia, ellei muulle ole vahvaa perustetta.
- Jäljitettävyys: Kirjaa lokiin, mitä dataa käytettiin missä koulutusajossa, millä oikeusperusteella ja minkä tenantin osalta. Tämä on olennaista auditoinneissa ja rekisteröityjen pyyntöjen käsittelyssä.
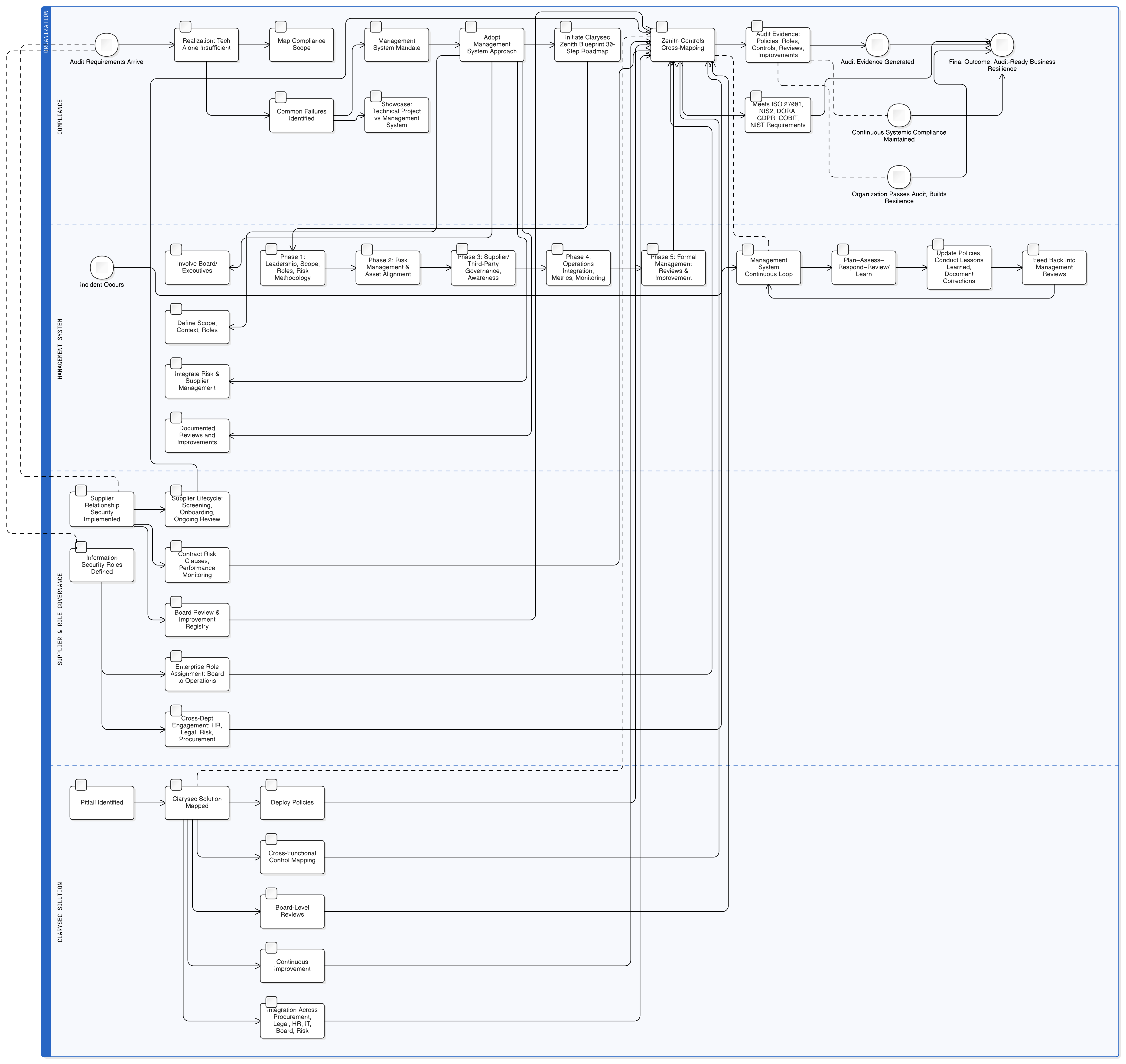
Clarysecin Zenith Blueprint: auditoijan 30-vaiheinen tiekartta tarjoaa rakenteisen etenemistavan näiden vaatimusten sisällyttämiseen jo kauan ennen ensimmäisenkään koodirivin kirjoittamista. Se alkaa hallinnoinnista:
- Perustamisvaihe, vaihe 2: Sidosryhmien ymmärtäminen: Tämä vaihe pakottaa tunnistamaan kaikki sidosryhmät, mukaan lukien EU:n valvontaviranomaiset. Kuten Zenith Blueprint toteaa, niiden vaatimuksiin sisältyvät “henkilötietojen lainmukainen käsittely, tietoturvaloukkauksista ilmoittaminen 72 tunnin kuluessa [sekä] rekisteröityjen oikeudet”.
- Auditointi- ja parantamisvaihe, vaihe 24: lakisääteisten ja sääntelyvaatimusten rekisterin rakentaminen ja ylläpito: Tee yhteistyötä lakitiimien kanssa ja luo keskitetty tietovarasto kaikista sovellettavista laeista sekä ymmärrys siitä, miten GDPR, NIS2, DORA ja muut sääntelykokonaisuudet leikkaavat tekoälyn tietoturvan tilaa.
Tämän perustan avulla tekniseen toteutukseen voidaan edetä luottavaisin mielin.
Polttoaineen suojaaminen: lainmukainen ja minimoitu koulutusdata
Tekoälyn vaatimustenmukaisuuden vaikein kysymys on yksinkertainen: “Voimmeko käyttää asiakasdataa malliemme kouluttamiseen?”
Vastaus löytyy monikerroksisesta strategiasta, jonka ytimessä ovat oikeusperuste, tietojen minimointi ja tekniset suojatoimet, kuten pseudonymisointi.
Oikeusperuste ja läpinäkyvä tarkoitus
ISO/IEC 27701:n mukaisesti sinun on tunnistettava ja dokumentoitava käsittelytarkoituksesi sekä määritettävä oikeusperuste kullekin.
- Ominaisuuden tuottaminen (esim. tekoälyhaku yhden tenantin sisällä): Oikeusperuste on tyypillisesti sopimuksen täytäntöönpano tai oikeutettu etu. Tämä on dokumentoitava käsittelytoimien selosteessa (RoPA).
- Globaalin mallin parantaminen (tenanttien välillä): Tämä edellyttää usein nimenomaista suostumusta tai erittäin huolellisesti perusteltua oikeutettua etua, johon liittyy selkeä ja helppo kieltäytymismekanismi. Läpinäkyvyys tietosuojaselosteessa ja tuotteen käyttöliittymässä on välttämätöntä.
Tekniset suojatoimet: pseudonymisointi ja peittäminen
Todellista anonymisointia on vaikea saavuttaa tuhoamatta datan käyttökelpoisuutta. Käytännöllisempi ja GDPR:n tukema lähestymistapa on pseudonymisointi: henkilötunnisteiden korvaaminen keinotekoisilla tunnisteilla. Tämä pienentää riskiä säilyttäen samalla datan arvon mallin kouluttamisessa.
Tämä prosessi on keskeinen hallintakeino. Zenith Blueprint käsittelee vaiheessa 20 nimenomaisesti tietojen peittämistä ja kytkee sen suoraan GDPR:n 25 ja 32 artiklan periaatteisiin. Kyse on vaaditusta tietoturvatoimenpiteestä, ei pelkästä hyvästä käytännöstä.
Clarysecin Tietojen peittämisen ja pseudonymisoinnin politiikka operatiivistaa tämän määrittämällä selkeän vastuun:
“DPO:n on validoitava vaatimustenmukaisuus GDPR:n pseudonymisointikriteerien kanssa ja koordinoitava lakitoiminnon kanssa kaikki sääntelyyn liittyvät ilmoitusvaatimukset, jotka koskevat tietoturvaloukkauksia tai peittämiskontrollien epäonnistumisia.”
- Osiosta ‘Soveltaminen ja vaatimustenmukaisuus’, politiikan kohta 8.4.
Kehitystiimeillesi tämä tarkoittaa automatisoitujen skriptien toteuttamista nimien, sähköpostiosoitteiden, puhelinnumeroiden ja muiden suorien tunnisteiden peittämiseksi tai pseudonymisoimiseksi ennen kuin data koskaan saapuu koulutusympäristöön. Se tarkoittaa myös muodollisen validointiprosessin luomista DPO:n kanssa, jotta menetelmän vahvuus voidaan varmistaa.
Piilevä uhka: testidatan ja tekoälykokeilujen suojaaminen
Todelliset tietoturvaloukkaukset alkavat harvoin kiillotetusta ja kovennetusta tuotantoympäristöstä. Ne alkavat infrastruktuurin unohdetuista nurkista:
- “Turvallisista” esituotantoympäristöistä, joissa on puutteellisesti puhdistettuja kopioita tuotantodatasta.
- Asiakasdatan “väliaikaisista” CSV-vienneistä, joita lähetetään koneoppimisinsinööreille paikallisia kokeiluja varten.
- Laadunvarmistusskripteistä, jotka käyttävät raakaa käyttäjäsisältöä LLM-kehotteiden testaamiseen.
Juuri tästä johdannossa kuvattu painajaisskenaario alkoi. Clarysecin Testidata- ja testiympäristöpolitiikka-sme käsittelee tätä riskiä suoraan:
“Noudattaa sovellettavia tietosuojasäädöksiä (esim. GDPR, NIS2) varmistamalla, että kaikki testidata käsitellään lainmukaisesti, oikeudenmukaisesti ja turvallisesti.”
- Osiosta ‘Tavoitteet’, politiikan kohta 3.4.
Politiikkaa on tuettava käytännön hallintakeinoilla. Tuotannon henkilötietoja ei saa koskaan olla ei-tuotantoympäristöissä ilman vahvaa peittämistä tai pseudonymisointia. Testiympäristöissä on käytettävä erillisiä, matalamman käyttöoikeustason LLM-API-avaimia tiukoilla nopeusrajoituksilla. Lisäksi nimenomaisena sääntönä on oltava, ettei testikehotteisiin koskaan sisällytetä eläviä asiakastunnisteita.
Ytimen vahvistaminen: hienojakoinen pääsynhallinta tekoälyputkille
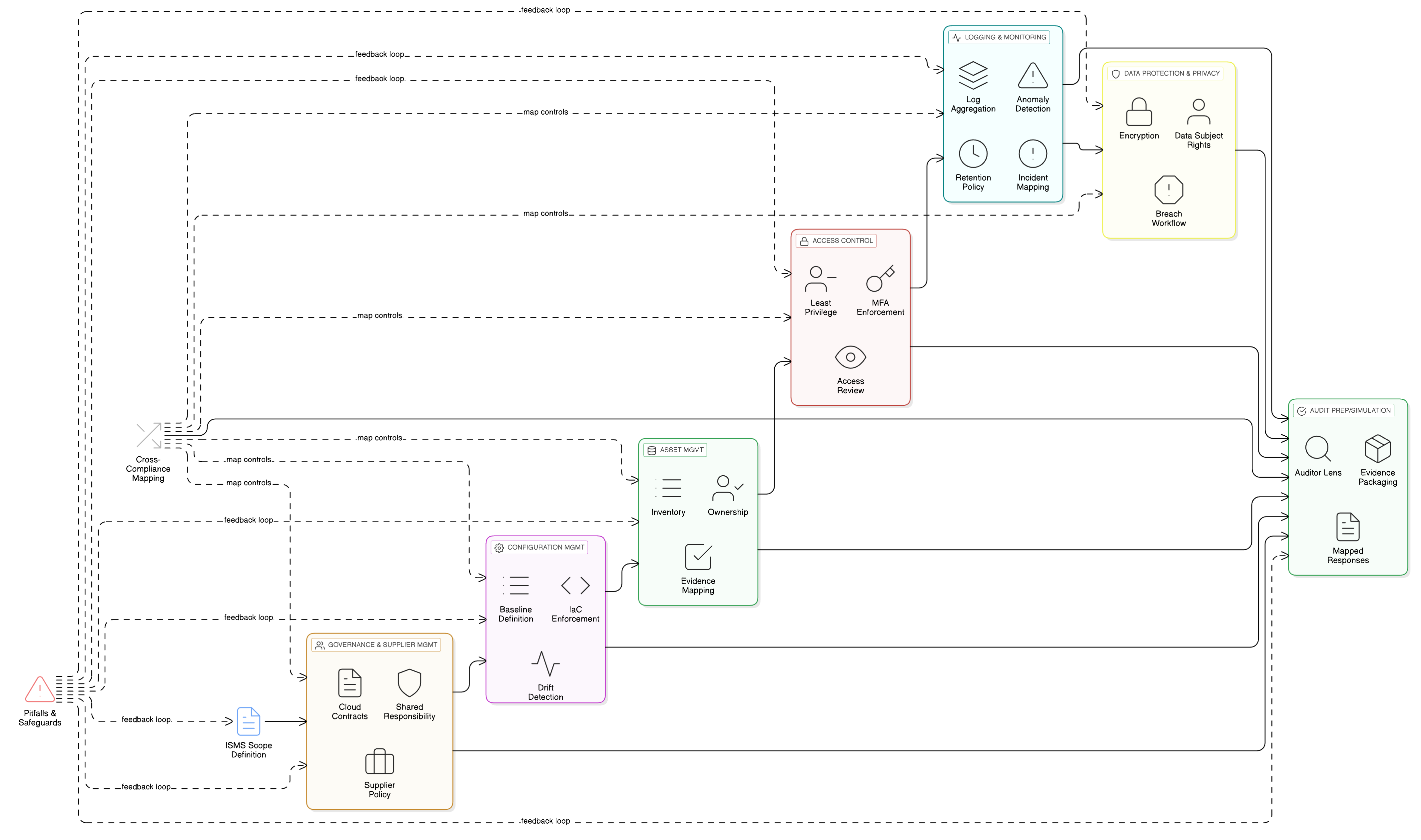
LLM-ominaisuudet toimivat kaikkein arkaluonteisimpien tietovarastojesi, lokiesi ja koulutusputkiesi päällä. Perustason pääsynhallinta on siksi ratkaisevan tärkeää GDPR-vaatimustenmukaisuudelle. ISO/IEC 27001:2022 -hallintakeinot 8.3 ja 8.2 ovat puolustuksesi peruspilarit. Clarysecin Zenith Controls: eri vaatimustenmukaisuusviitekehysten opas tarjoaa suunnitelman niiden tehokkaaseen toteuttamiseen.
ISO/IEC 27001:2022 -hallintakeino 8.3: tiedonsaannin rajoittaminen
Tällä hallintakeinolla varmistetaan, että pääsy tietoihin myönnetään tiukasti tarpeellisuusperiaatteen mukaisesti. LLM-koulutusympäristössä tämä tarkoittaa, että datatieteilijät, koneoppimisinsinöörit ja automatisoidut prosessit pääsevät vain siihen nimenomaiseen dataan, jota ne tarvitsevat, eivätkä mihinkään muuhun.
Kuten Zenith Controls kuvaa, tämä liittyy tiiviisti muihin hallintakeinoihin:
- Yhteys kohtiin 5.9 (Tietojen ja muiden niihin liittyvien omaisuuserien luettelo) ja 5.12 (Tietojen luokittelu): Et voi rajoittaa pääsyä, jos et tiedä, mitä dataa sinulla on ja kuinka arkaluonteista se on. Tekoälyn koulutustietoaineisto on inventoitava ja luokiteltava erittäin luottamukselliseksi prosessissa, jota ohjaa Tiedon luokittelu- ja merkintäpolitiikka-sme.
- Yhteys kohtaan 8.5 (Turvallinen todennus): Pääsyrajoitukset ovat merkityksettömiä ilman vahvaa identiteetin varmentamista. Jokainen käyttäjä ja palvelutili, joka käyttää koulutusdataa, on todennettava turvallisesti, mieluiten MFA:lla.
ISO/IEC 27001:2022 -hallintakeino 8.2: etuoikeutetut käyttöoikeudet
Koneoppimisinsinöörit, SRE:t ja datatieteilijät tarvitsevat korotettuja käyttöoikeuksia. Nämä etuoikeutetut tilit ovat “avaimia valtakuntaan” ja ensisijaisia kohteita. Hallintakeino 8.2 edellyttää, että näitä oikeuksia hallitaan erityisen tiukasti.
Zenith Controls -oppaan mukaan keskeiset yhteydet ovat:
- Yhteys kohtiin 8.15 (Lokitus) ja 8.16 (Toimintojen valvonta): Kaikki etuoikeutettu toiminta on kirjattava lokiin ja sitä on valvottava. Jos datatieteilijä yrittää äkillisesti viedä koko koulutustietoaineiston, hälytyksen on lauettava välittömästi.
- Yhteys kohtaan 6.7 (Etätyö): Jos tekoälytiimi työskentelee etänä, etuoikeutetun pääsyn on kuljettava turvallisten ja valvottujen kanavien, kuten tiukoilla istuntokontrolleilla varustetun VPN:n, kautta.
Auditoijan näkökulma: miten osoitat, että tekoälykontrollit toimivat
Hallintakeinojen toteuttaminen on vain puolet työstä. Niiden tehokkuus on pystyttävä osoittamaan. Eri viitekehyksiin koulutetut auditoijat etsivät tiettyä näyttöä.
| Auditoijatyyppi | Viitekehyksen painopiste | Mitä he pyytävät (näyttö) |
|---|---|---|
| ISO/IEC 27001 -auditoija | ISO/IEC 27007:2020 | Näytä pääsynhallintapolitiikkasi tekoälyn koulutusympäristölle. Toimita lokit käyttöoikeuskatselmointiprosessistasi viimeisen 12 kuukauden ajalta. Osoita, miten uudelle koneoppimisinsinöörille myönnetään vähimmän oikeuden periaatteen mukainen käyttöoikeus. |
| COBIT-auditoija | COBIT 2019 (DSS05) | Tarvitsen nähtäväksi data science -tiimin roolipohjaisen käyttöoikeuksien hallinnan (RBAC) matriisin. Toimita valvontatyökalujesi raportit, jotka näyttävät hälytykset poikkeavista pääsyyrityksistä koulutusdatan data lakeen. |
| NIST-arvioija | NIST SP 800-53A (AC-3, AC-6) | Katselmoidaan koulutusdataa isännöivien palvelinten järjestelmäkonfiguraatio. Haluan varmistaa, että käyttöoikeusluettelot (ACL) panevat teknisesti täytäntöön dokumentoidut politiikat. Näytä näyttö siitä, että etuoikeutetut istunnot päätetään käyttämättömyyden jälkeen. |
| GDPR- ja tietosuoja-auditoija | ISO/IEC 27701:2021 | Toimita tekoälyominaisuutta koskeva tietosuojaa koskeva vaikutustenarviointi (DPIA). Näytä suostumustallenteet rekisteröidyistä, joiden tiedot ovat koulutusaineistossa. Miten käsittelette oikeutta tietojen poistamiseen koskevan pyynnön koulutetussa mallissa olevan datan osalta? |
Hallintakeinojen 8.2 ja 8.3 oikea toteutus tuottaa laajoja hyötyjä. Zenith Controls osoittaa suoran vastaavuuden GDPR:n (5, 25 ja 32 artikla), NIS2:n (21 artikla), DORA:n (10 artikla) ja NIST SP 800-53:n (AC-3, AC-6) vaatimuksiin. Näin voit täyttää useita viitekehyksiä yhdellä yhtenäisellä hallintakeinototeutuksella.
Oikeus tulla unohdetuksi -paradoksi: rekisteröityjen oikeuksien hallinta tekoälyssä
GDPR:n 17 artikla eli “oikeus tietojen poistamiseen” aiheuttaa tekoälylle ainutlaatuisen teknisen haasteen. Miten henkilön data voidaan poistaa, kun sitä on käytetty valtavan ja monimutkaisen mallin kouluttamiseen? Yksittäisten datapisteiden “unohtaminen” on usein teknisesti mahdotonta.
Tässä alkuperäisistä suunnitteluvalinnoista tulee paras puolustuksesi. Yhtä täydellistä vastausta ei ole, mutta käytännöllisiä ja puolustettavissa olevia strategioita ovat:
- Pseudonymisointi ensin: Jos koulutusdata pseudonymisoitiin asianmukaisesti, yhteys henkilöön on jo katkaistu koulutuskorpuksessa. Tämän jälkeen voit poistaa henkilötiedot lähdejärjestelmistä ja yhteyden pseudonymisointiavainten taulusta.
- Koulutusdatan eriyttäminen: Pidä tenanttikohtaiset koulutustietoaineistot erillään aina kun mahdollista. Tämä tekee datan poistamisesta mahdollista ilman koko mallikokonaisuuden uudelleenkouluttamista.
- Aikataulutettu mallin uudelleenkoulutus: DPIA:n tulee käsitellä tämä riski. Lieventämistoimena voi olla sitoumus kouluttaa malli määräajoin uudelleen alusta alkaen käyttäen päivitettyä tietoaineistoa, josta poistopyynnön tehneiden käyttäjien data on suljettu pois.
Zenith Blueprint -oppaan tietojen poistamista koskeva osio (vaihe 20, joka kattaa hallintakeinon 8.10) kytkee tämän teknisen kyvykkyyden nimenomaisesti GDPR:n 17 artiklaan ja 5(1)(e) kohtaan ja edellyttää todennettavia prosesseja datan turvalliseen pyyhintään, kun sitä ei enää tarvita.
Tekoälyn toimitusketjun suojaaminen: ulkoistettu kehittäminen ja kolmannen osapuolen LLM:t
Harva SaaS-yritys rakentaa kaiken itse. Saatat käyttää hyperskaalaajan LLM-rajapintaa tai sopia ulkoistetun kehityskumppanin kanssa. Tämä tuo mukanaan toimitusketjuriskin.
Zenith Blueprint korostaa vaiheessa 22 ulkoistettua kehittämistä koskien tätä riskiä ja sen yhteyttä GDPR:n 28 ja 32 artiklaan. Blueprintin mukaan:
“Yksi usein huomiotta jäävä alue on koulutus ja tietoisuus. Ulkoistetut kehittäjäsi voivat olla päteviä, mutta onko heidät koulutettu turvallisen ohjelmoinnin käytäntöihin? Tuntevatko he politiikkasi? Ovatko he tietoisia vaatimustenmukaisuusviitekehyksistä, joita sinun on noudatettava: GDPR, DORA, NIS2…?”
Kaikkien ulkoisten LLM-palveluntarjoajien tai kehityskumppanien osalta due diligence on kriittistä. Tietojenkäsittelysopimuksen (DPA) on katettava nimenomaisesti tekoälyyn liittyvät käsittelytarkoitukset, tietoluokat ja kiellot, jotka estävät palveluntarjoajaa käyttämästä dataasi omien malliensa kouluttamiseen. Sinun on varmistettava, että ne toteuttavat GDPR:n 32 artiklan mukaiset turvatoimet. Tekoälyn toimitusketjun on oltava yhtä auditoitavissa kuin ydininfrastruktuurisi.
Teoriasta käytäntöön: konkreettinen esimerkki GDPR-valmiista tekoälyominaisuudesta
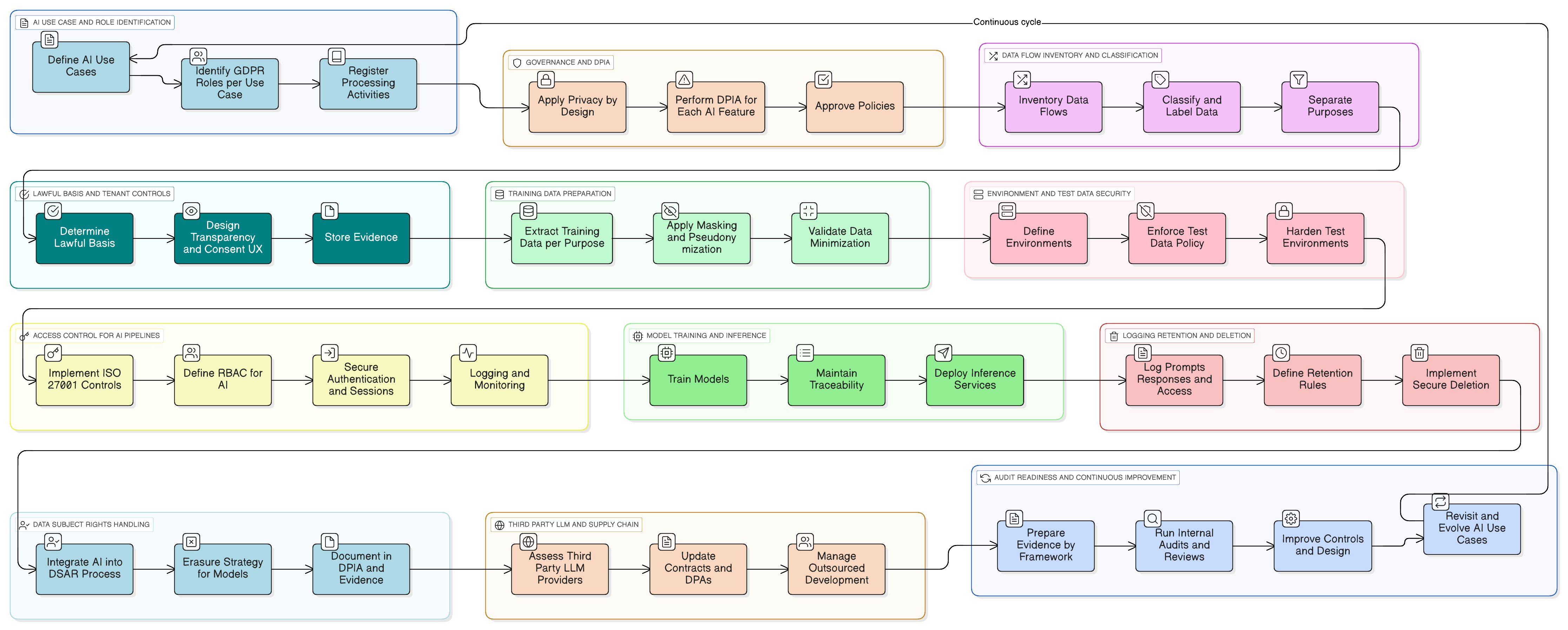
Tehdään tästä konkreettista. Kuvitellaan, että lisäät tekoälyavustajan, joka tiivistää asiakastuen keskusteluja, ehdottaa vastausluonnoksia ja oppii aiemmista tukipyynnöistä parantuakseen.
Tässä on käytännön toteutusmalli Clarysecin työkalupaketilla:
- Luokittelu ja merkintä: Kaikki tukipyynnöt luokitellaan Tiedon luokittelu- ja merkintäpolitiikka-sme -politiikan mukaisesti tasolle “Luottamuksellinen”, mikä on yhdenmukaista GDPR:n ja DORA:n tietojen käsittelyvelvoitteiden kanssa.
- Peittäminen ennen LLM:ää: Peittämispalvelu sieppaa datan ennen sen lähettämistä LLM:lle. Se poistaa tai korvaa nimet, sähköpostiosoitteet, puhelinnumerot ja muut henkilötiedot. Koko prosessia ohjaa Tietojen peittämisen ja pseudonymisoinnin politiikka, ja DPO validoi menetelmän.
- Kehotteiden ja lokien pääsynhallinta: Vain valtuutetut roolit (esim. tekoälytuotteen omistaja) voivat käyttää raakoja kehote- ja lokitietoja. Tämä toteutetaan ISO 27001:2022 -hallintakeinon 8.3 (tiedonsaannin rajoittaminen) avulla yleisen pääsyn osalta ja hallintakeinon 8.2 (etuoikeutetut käyttöoikeudet) avulla minkä tahansa ylläpitäjätason näkyvyyden osalta, kuten Zenith Controls kuvaa.
- Suostumus koulutusdatakorpukselle: Koulutusputki syöttää vain peitettyä dataa. Asiakaskohtainen konfiguraatioasetus “Sallin peitetyn datani käytön globaalin tekoälymallin parantamiseen: Kyllä/Ei” tarjotaan, ja oletusarvona on “Ei”.
- Säilytys ja poistaminen: Kehotelokeja säilytetään vain niin kauan kuin on tarpeen. Kun asiakas poistaa ominaisuuden käytöstä tai päättää sopimuksensa, käynnistetään työnkulku siihen liittyvien tekoälylokien ja koulutusmerkintöjen turvalliseksi poistamiseksi tai anonymisoimiseksi noudattaen prosessia, joka on kuvattu Zenith Blueprint -toteutuksessasi hallintakeinolle 8.10 (tietojen poistaminen).
Kun auditoijat saapuvat, voit käydä heidän kanssaan läpi ominaisuuden tietovirtojen kaaviot, sitä ohjaavat nimenomaiset politiikat sekä teknisen näytön järjestelmistäsi, käyttölokeista, ajokonfiguraatioista ja poistotyönkuluista. Osoitat vaatimustenmukaisuuden käytännössä.
Toimintasuunnitelma: ad hoc -tekoälystä auditointivalmiuteen
Tuotetta ei tarvitse purkaa osiin, mutta tarvitset rakenteisen ja puolustettavissa olevan lähestymistavan. Tässä on tiivis toimintasuunnitelma:
- Inventoi tekoälyn käyttötapaukset ja tietovirrat: Tunnista jokainen paikka, jossa LLM:iä käytetään: asiakasrajapinnan ominaisuudet, sisäiset työkalut ja kokeilut. Kartoita, mikä data kulkee minne, millä oikeusperusteella ja kenellä on pääsy. Käytä Zenith Blueprint -oppaan perustamisvaihetta varmistaaksesi, että lakirekisterisi kattaa kaikki tekoälyyn liittyvät GDPR-, NIS2- ja DORA-vaatimukset.
- Perusta hallinnointi ensin: Ennen rakentamista tee tietosuojaa koskeva vaikutustenarviointi (DPIA) jokaiselle tekoälyominaisuudelle. Dokumentoi sen tarkoitus, oikeusperuste ja riskit. Ota käyttöön perustason politiikat, kuten Tietosuoja- ja yksityisyydensuojapolitiikka-sme ja Tietoturvapolitiikka-sme.
- Lukitse data ja pääsy: Toteuta vahvat tekniset hallintakeinot. Ota käyttöön Tietojen peittämisen ja pseudonymisoinnin politiikka sekä Testidata- ja testiympäristöpolitiikka-sme. Käytä Zenith Controls -opasta ISO 27001:2022 -hallintakeinojen 8.2 ja 8.3 toteuttamiseen ja dokumentointiin kaikille tekoälyn tietovarastoille ja putkille.
- Sisällytä rekisteröityjen oikeudet tekoälyn työnkulkuihin: Päivitä DSAR- ja poistomenettelyt kattamaan tekoälyyn liittyvä data. Dokumentoi strategiasi poistopyyntöjen käsittelemiseksi koulutettujen mallien yhteydessä keskittyen pseudonymisointiin ja mallien uudelleenkoulutusaikatauluihin.
- Ota tekoälyn toimitusketju hallintaan: Päivitä DPA:t kolmannen osapuolen LLM-palveluntarjoajien ja ulkoistettujen kehittäjien kanssa. Varmista, että sopimukset kieltävät nimenomaisesti luvattoman datan käytön ja edellyttävät vahvoja turvatoimia. Varmista, että ulkoiset tiimit on koulutettu tietojen käsittelypolitiikkoihisi.
Innovoinnin vapauttaminen luottamuksella
Tekoälyn ja GDPR:n rajapinta on vaatimustenmukaisuuden uusi etulinja. Ottamalla käyttöön rakenteisen ja riskiperusteisen lähestymistavan voit hyödyntää tekoälyn muutosvoimaa vaarantamatta sitoutumistasi tietosuojaan ja yksityisyyden suojaan.
Clarysec tarjoaa kartan, työkalut ja asiantuntemuksen tälle matkalle. Käyttämällä seuraavia:
- Zenith Blueprint: auditoijan 30-vaiheinen tiekartta GDPR:n kanssa yhdenmukaistettujen tekoälykontrollien vaiheittaiseen toteutukseen.
- Zenith Controls: eri vaatimustenmukaisuusviitekehysten opas ISO 27001:2022 -hallintakeinojen yhdistämiseen GDPR-, NIS2-, DORA- ja NIST-vaatimuksiin.
- Tuotantovalmiit politiikat, kuten Tietosuoja- ja yksityisyydensuojapolitiikka-sme, Tietojen peittämisen ja pseudonymisoinnin politiikka ja Testidata- ja testiympäristöpolitiikka-sme, sääntöjesi kodifioimiseksi ja auditoijien vaatimusten täyttämiseksi.
Voit siirtyä ad hoc -tekoälykokeiluista auditointivalmiiseen tekoälykyvykkyyteen, joka herättää luottamusta valvontaviranomaisissa, auditoijissa ja vaativissa yritysasiakkaissa. Voit jatkaa innovointia LLM:ien avulla ja silti nukkua yösi rauhassa.
Jos suunnittelet tai käytät tekoälyominaisuuksia SaaS-tuotteessasi, seuraava askel on selkeä. Lataa työkalupakettiemme näytteet tai varaa demo nähdäksesi, miten Clarysec voi auttaa sinua rakentamaan tekoälyohjelman, joka ei ole vain tehokas vaan myös todennetusti yksityisyyttä suojaava ja sisäänrakennetusti turvallinen.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council