Tests de restauration auditables pour ISO 27001, NIS2 et DORA
Il est 7 h 40 un lundi matin, et Sarah, RSSI d’une fintech en forte croissance, voit une crise se former en temps réel. Le directeur financier ne parvient pas à ouvrir la plateforme d’approbation des paiements. Le centre de services suspecte un problème de stockage. L’équipe infrastructure soupçonne un rançongiciel, car plusieurs partages de fichiers affichent désormais des noms de fichiers chiffrés. Le directeur général veut savoir si la paie est protégée. Le service juridique demande s’il faut notifier les autorités de régulation.
Sarah ouvre le tableau de bord des sauvegardes. Il est rempli de coches vertes.
Cela devrait être rassurant, mais ce n’est pas le cas. Une tâche de sauvegarde réussie ne prouve pas une restauration réussie. C’est comme voir un extincteur au mur sans savoir s’il est chargé, accessible et utilisable sous pression.
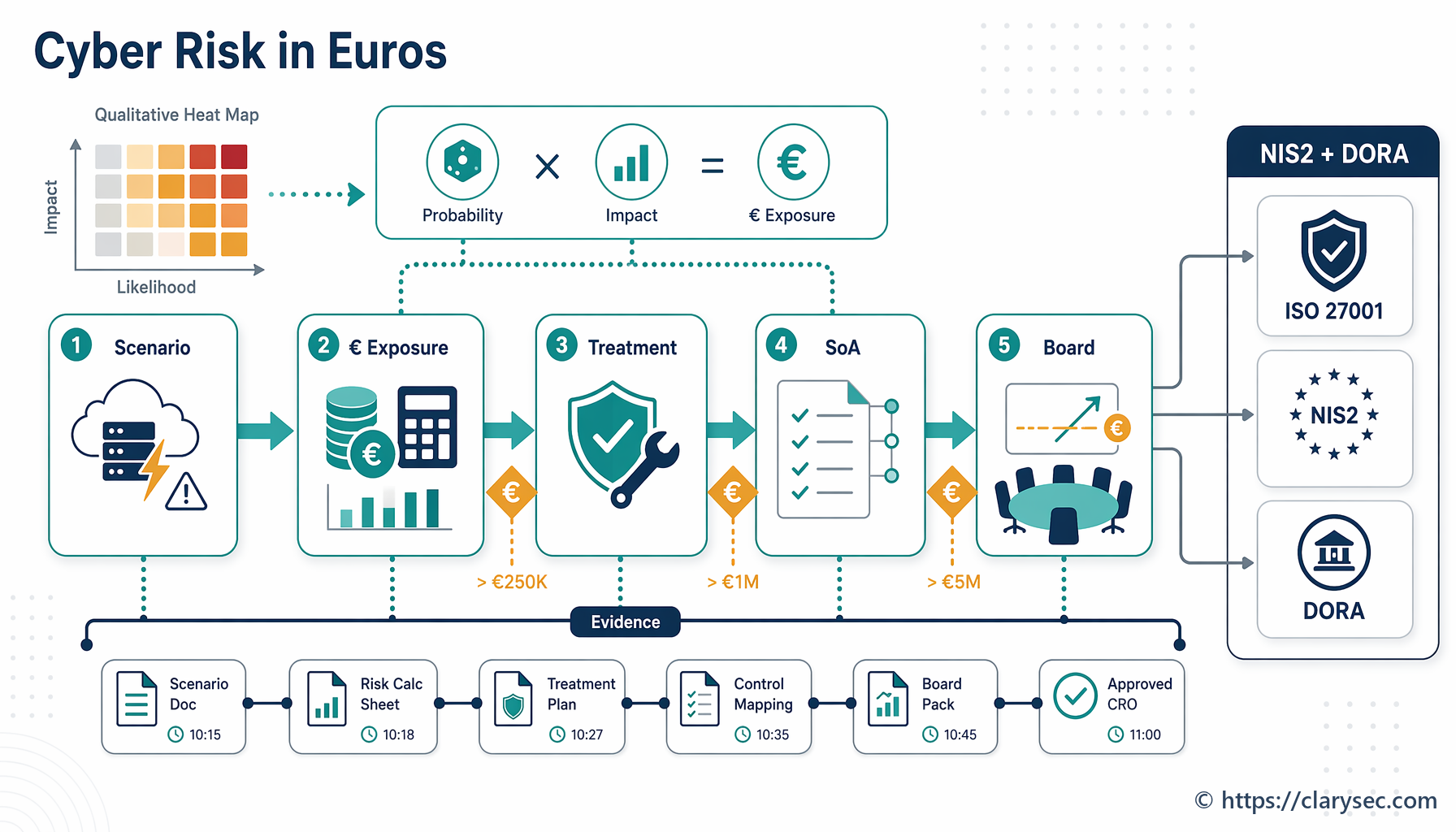
L’entreprise de Sarah entre dans le domaine d’application d’ISO 27001:2022, est considérée comme une entité importante au titre de NIS2 et est soumise à DORA en tant qu’entité financière. La question n’est plus de savoir si l’organisation exécute des sauvegardes. La question est de savoir si elle peut restaurer les bons systèmes, au bon point dans le temps, dans les objectifs de temps de reprise et les objectifs de point de reprise approuvés, avec des éléments probants suffisamment solides pour un auditeur, une autorité de régulation, un client, un assureur et le conseil d’administration.
C’est là que de nombreux programmes de sauvegarde échouent. Ils disposent de tâches de sauvegarde. Ils disposent de tableaux de bord. Ils disposent d’instantanés de sauvegarde. Ils peuvent même disposer de stockage cloud. Mais lorsque la pression survient, ils ne peuvent pas démontrer que les systèmes critiques sont restaurables, que des tests de restauration ont été réalisés, que les tests échoués ont déclenché des actions correctives et que les éléments probants se rattachent clairement aux attentes d’ISO 27001:2022, NIS2, DORA, NIST et COBIT 2019.
Les tests de sauvegarde et de restauration sont devenus un sujet de résilience opérationnelle au niveau du conseil d’administration. NIS2 renforce les attentes en matière de gestion des risques de cybersécurité et de continuité d’activité. DORA fait de la résilience opérationnelle numérique une obligation centrale pour les entités financières et leurs prestataires tiers de services TIC critiques. ISO 27001:2022 fournit la structure de système de management pour le domaine d’application, les risques, la sélection des contrôles, les éléments probants, l’audit et l’amélioration continue.
Le défi pratique consiste à transformer un test technique de restauration en éléments probants auditables.
Une sauvegarde ne constitue pas un élément probant tant que la restauration n’est pas démontrée
Une tâche de sauvegarde achevée avec succès n’est qu’un signal partiel. Elle indique que les données ont été copiées quelque part. Elle ne prouve pas que les données peuvent être restaurées, que les dépendances applicatives sont intactes, que les clés de chiffrement sont disponibles, que les services d’identité fonctionnent toujours ni que le système restauré prend en charge les opérations métier réelles.
Les auditeurs le savent. Les autorités de régulation le savent. Les attaquants le savent.
Un auditeur techniquement mature ne s’arrêtera pas à une capture d’écran indiquant 97 % de réussite des tâches de sauvegarde. Il demandera :
- Quels systèmes sont critiques ou à fort impact ?
- Quels RTO et RPO s’appliquent à chaque système ?
- Quand le dernier test de restauration a-t-il été réalisé ?
- Le test était-il complet, partiel, au niveau applicatif, au niveau base de données ou au niveau fichier ?
- Qui a validé le processus métier après restauration ?
- Les échecs ont-ils été enregistrés comme non-conformités ou actions d’amélioration ?
- Pendant combien de temps les journaux et les enregistrements de tests de restauration sont-ils conservés ?
- Les copies de sauvegarde sont-elles séparées entre plusieurs emplacements ?
- Comment les éléments probants sont-ils rattachés au registre des risques et à la Déclaration d’applicabilité ?
C’est pourquoi la formulation des politiques Clarysec est volontairement directe. La Politique de sauvegarde et de restauration pour PME [BRP-SME], section Exigences de gouvernance, clause de politique 5.3.3, exige :
Les tests de restauration sont réalisés au moins trimestriellement, et les résultats sont documentés afin de vérifier la capacité de restauration
Cette seule phrase change la discussion d’audit. Elle fait passer l’organisation de « nous avons des sauvegardes » à « nous vérifions la capacité de restauration selon une périodicité définie et conservons les résultats ».
La même Politique de sauvegarde et de restauration pour PME, section Application et conformité, clause de politique 8.2.2, renforce l’obligation relative aux éléments probants :
Les journaux et les enregistrements de tests de restauration sont conservés aux fins d’audit
Cette clause évite que les tests de restauration deviennent une connaissance informelle non documentée. Si un ingénieur infrastructure déclare : « Nous avons testé cela en mars », mais qu’aucun enregistrement n’existe, il ne s’agit pas d’un élément probant exploitable en audit.
La même politique traite également de la capacité de survie grâce à la diversité des emplacements de stockage. Dans la section Exigences de mise en œuvre de la politique, clause de politique 6.3.1.1, les sauvegardes doivent être :
Stockées dans au moins deux emplacements (local et cloud)
Il s’agit d’un référentiel minimal pratique. Il ne remplace pas une appréciation des risques, mais il réduit la probabilité qu’un même domaine de défaillance physique ou logique détruise à la fois les données de production et les données de sauvegarde.
La chaîne des éléments probants ISO 27001:2022 commence avant le test
Les organisations traitent souvent la conformité des sauvegardes comme un sujet d’exploitation informatique. Au sens d’ISO 27001:2022, cette approche est trop étroite. Les tests de sauvegarde et de restauration doivent être intégrés au système de management de la sécurité de l’information (SMSI) et reliés au domaine d’application, aux risques, à la sélection des contrôles, à la surveillance, à l’audit interne et à l’amélioration continue.
Le Zenith Blueprint : feuille de route d’audit en 30 étapes de Clarysec [ZB] lance cette chaîne d’éléments probants avant tout test de restauration.
Dans la phase Fondations et leadership du SMSI, étape 2, Besoins des parties prenantes et domaine d’application du SMSI, le Zenith Blueprint demande aux organisations de définir ce qui relève du SMSI :
Action 4.3 : Rédiger une déclaration du domaine d’application du SMSI. Lister ce qui est inclus (unités métier, sites, systèmes) et toute exclusion. Partager ce projet avec la haute direction pour avis : elle doit accepter les parties de l’activité qui seront soumises au SMSI. Il est également prudent de vérifier la cohérence de ce domaine d’application avec la liste précédente des exigences des parties prenantes : votre domaine d’application couvre-t-il toutes les zones nécessaires pour satisfaire ces exigences ?
Pour les tests de restauration, le domaine d’application définit l’univers de reprise. Si la plateforme de paiement, le fournisseur d’identité, la base de données ERP, le serveur de gestion des terminaux et le stockage d’objets cloud sont dans le périmètre, les éléments probants de restauration doivent les inclure ou justifier leur absence. Si un système est exclu, cette exclusion doit être défendable au regard des exigences des parties prenantes, des obligations contractuelles, des obligations réglementaires et des besoins de continuité d’activité.
Le lien suivant est le risque. Dans la phase Gestion des risques, étape 11, Constitution et documentation du registre des risques, le Zenith Blueprint décrit le registre des risques comme l’enregistrement maître des risques, actifs, menaces, vulnérabilités, contrôles en place, propriétaires et décisions de traitement.
Une entrée de risque liée aux sauvegardes doit être opérationnelle, et non théorique.
| Élément de risque | Exemple d’entrée |
|---|---|
| Actif | Plateforme d’approbation des paiements et base de données associée |
| Menace | Chiffrement par rançongiciel ou action destructrice d’un administrateur |
| Vulnérabilité | Sauvegardes non restaurées trimestriellement et dépendances applicatives non validées |
| Impact | Retard de paie, exposition réglementaire, atteinte à la confiance des clients |
| Contrôles en place | Tâches de sauvegarde quotidiennes, stockage cloud immuable, test de restauration trimestriel |
| Propriétaire du risque | Responsable infrastructure |
| Décision de traitement | Réduire le risque au moyen de sauvegardes testées, d’éléments probants de restauration documentés et de mises à jour du PCA |
C’est à ce stade que la sauvegarde devient auditable. Il ne s’agit plus de « nous avons des sauvegardes ». Il s’agit de « nous avons identifié un risque métier, sélectionné des contrôles, attribué la responsabilité, testé le contrôle et conservé les éléments probants ».
Le Zenith Blueprint, phase Gestion des risques, étape 13, Planification du traitement des risques et Déclaration d’applicabilité, ferme la boucle de traçabilité :
Rattacher les contrôles aux risques et aux clauses (traçabilité)
Maintenant que vous disposez à la fois du plan de traitement des risques et de la SoA :
✓ Rattacher les contrôles aux risques : dans le plan de traitement de votre registre des risques, vous avez listé certains contrôles pour chaque risque. Vous pouvez ajouter une colonne « Référence de contrôle Annexe A » à chaque risque et y lister les numéros de contrôle.
Pour les tests de sauvegarde et de restauration, la Déclaration d’applicabilité doit relier le scénario de risque aux contrôles de l’Annexe A d’ISO/IEC 27001:2022, en particulier 8.13 Sauvegarde de l’information, 5.30 Préparation des TIC à la continuité d’activité, 8.14 Redondance des installations de traitement de l’information et 5.29 Sécurité de l’information pendant une perturbation.
La SoA ne doit pas simplement indiquer que ces contrôles sont applicables. Elle doit expliquer pourquoi ils sont applicables, quels éléments probants de mise en œuvre existent, qui est responsable du contrôle et comment les exceptions sont gérées.
La cartographie des contrôles que les auditeurs s’attendent à voir
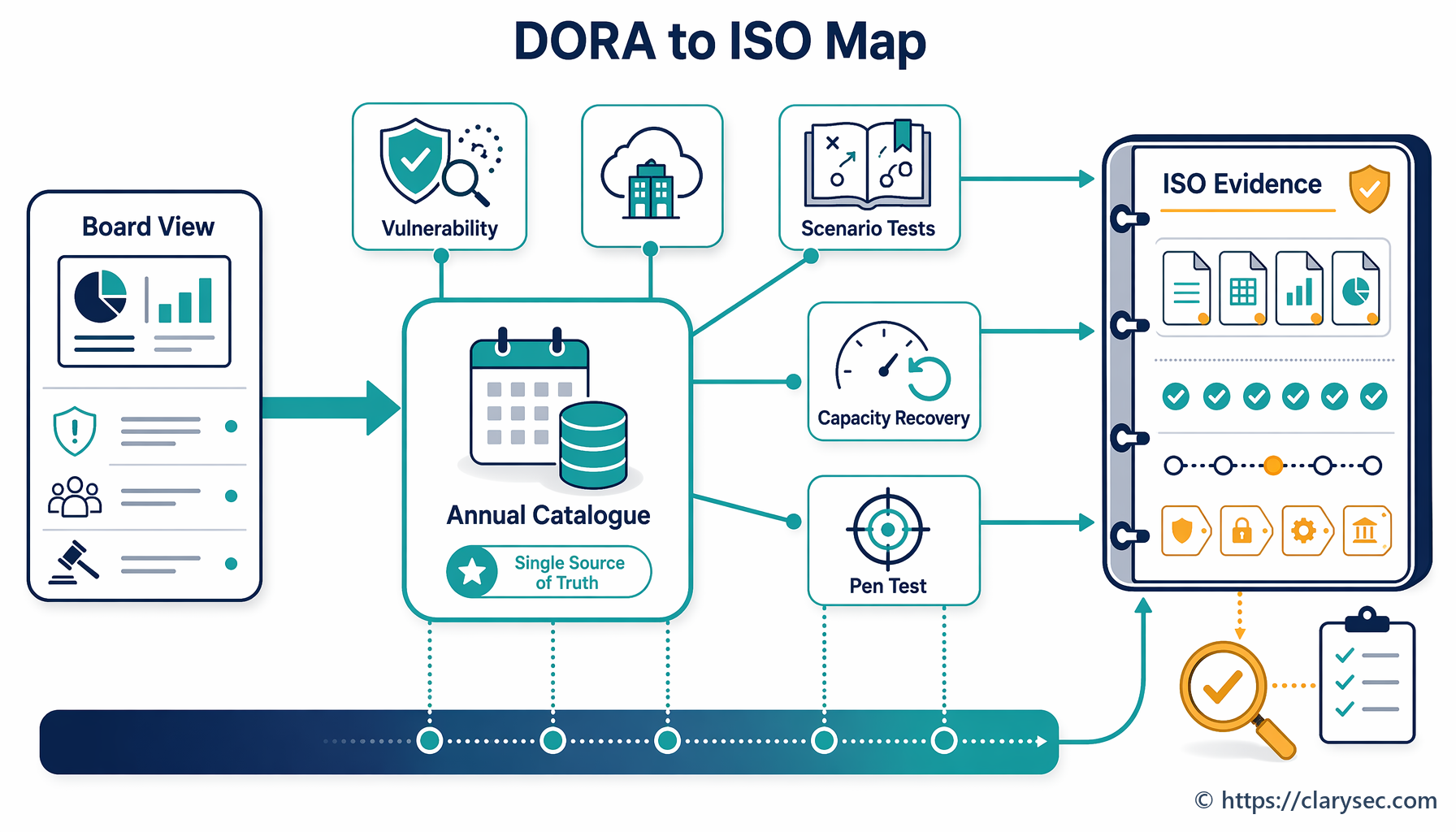
Le Zenith Controls : guide de conformité croisée de Clarysec [ZC] ne crée pas de contrôles séparés ou propriétaires. Il organise les normes et référentiels officiels dans une vue pratique de conformité croisée afin que les organisations comprennent comment une pratique opérationnelle, telle que les tests de restauration, soutient plusieurs obligations.
Pour le contrôle ISO/IEC 27002:2022 8.13 Sauvegarde de l’information, Zenith Controls classe le contrôle comme correctif, lié à l’intégrité et à la disponibilité, aligné sur le concept de cybersécurité Recover, soutenant la capacité opérationnelle de continuité et relevant du domaine de sécurité Protection. Ce profil repositionne les sauvegardes comme une capacité de reprise, et non comme un simple processus de stockage.
Pour le contrôle ISO/IEC 27002:2022 5.30 Préparation des TIC à la continuité d’activité, Zenith Controls classe le contrôle comme correctif, centré sur la disponibilité, aligné sur Respond, soutenant la continuité et positionné dans le domaine de sécurité Résilience. C’est là que les tests de restauration se rattachent directement à la résilience opérationnelle.
Pour le contrôle ISO/IEC 27002:2022 8.14 Redondance des installations de traitement de l’information, Zenith Controls identifie un contrôle préventif centré sur la disponibilité, aligné sur Protect, soutenant la continuité et la gestion des actifs, et lié aux domaines Protection et Résilience. Redondance et sauvegardes ne sont pas équivalentes. La redondance contribue à prévenir l’interruption. Les sauvegardes permettent la reprise après perte, corruption ou attaque.
Pour le contrôle ISO/IEC 27002:2022 5.29 Sécurité de l’information pendant une perturbation, Zenith Controls présente un profil plus large : préventif et correctif, couvrant la confidentialité, l’intégrité et la disponibilité, aligné sur Protect et Respond, soutenant la continuité, et lié à Protection et Résilience. Ce point est important lors d’une reprise après rançongiciel, car la restauration ne doit pas créer de nouvelles défaillances de sécurité, comme la restauration d’images vulnérables, le contournement de la journalisation ou la réactivation de privilèges excessifs.
| Contrôle de l’Annexe A ISO/IEC 27001:2022 | Rôle dans la résilience | Éléments probants attendus par les auditeurs |
|---|---|---|
| 8.13 Sauvegarde de l’information | Démontre que les données et systèmes peuvent être restaurés après une perte, une corruption ou une attaque | Calendrier de sauvegarde, enregistrements de tests de restauration, critères de réussite, journaux, exceptions, éléments probants de conservation |
| 5.30 Préparation des TIC à la continuité d’activité | Montre que les capacités TIC soutiennent les objectifs de continuité | BIA, cartographie RTO/RPO, procédures opérationnelles de reprise, rapports de test, enseignements tirés |
| 8.14 Redondance des installations de traitement de l’information | Réduit la dépendance à une seule installation de traitement ou à un seul chemin de service | Schémas d’architecture, résultats de tests de basculement, revue de capacité, cartographie des dépendances |
| 5.29 Sécurité de l’information pendant une perturbation | Maintient la sécurité pendant les opérations dégradées et la reprise | Enregistrements d’accès de crise, approbations de changements d’urgence, journalisation, chronologie des incidents, validation de sécurité post-restauration |
La leçon pratique est simple. Un test de restauration n’est pas un contrôle isolé. Il constitue un élément probant au sein d’une chaîne de résilience.
La lacune d’audit cachée : RTO et RPO sans preuve
L’un des constats d’audit de continuité les plus courants est l’écart entre les RTO/RPO documentés et la capacité réelle de restauration.
Le plan de continuité d’activité peut indiquer que le portail client a un RTO de quatre heures et un RPO d’une heure. La plateforme de sauvegarde peut s’exécuter toutes les heures. Mais lors du premier exercice réaliste de restauration, l’équipe découvre que la restauration de la base de données prend trois heures, que les modifications DNS nécessitent une heure supplémentaire, que le certificat applicatif a expiré et que l’intégration avec l’identité n’a jamais été incluse dans la procédure opérationnelle. Le temps réel de reprise est de huit heures.
Le RTO documenté était fictif.
La Politique de continuité d’activité et de reprise après sinistre pour PME de Clarysec [BCDR-SME], section Exigences de gouvernance, clause de politique 5.2.1.4, rend l’exigence de continuité explicite :
Objectifs de temps de reprise (RTO) et objectifs de point de reprise (RPO) pour chaque système
C’est important, car « restaurer rapidement les services critiques » n’est pas mesurable. « Restaurer la base de données d’approbation des paiements en moins de quatre heures avec une perte de données maximale d’une heure » est mesurable.
La même Politique de continuité d’activité et de reprise après sinistre pour PME, section Exigences de mise en œuvre de la politique, clause 6.4.2, transforme les tests en amélioration :
Tous les résultats de test doivent être documentés, et les enseignements tirés doivent être enregistrés et utilisés pour mettre à jour le PCA.
Une restauration échouée n’est pas automatiquement une catastrophe d’audit. Une restauration échouée sans enseignement documenté, responsable désigné, correction et nouveau test l’est.
Pour les environnements d’entreprise, la Politique de sauvegarde et de restauration de Clarysec [BRP] fournit une gouvernance plus formelle. Dans la section Exigences de gouvernance, clause de politique 5.1, elle précise :
Un calendrier maître des sauvegardes doit être maintenu et revu annuellement. Il doit préciser :
Cette exigence initiale établit le livrable central de gouvernance. Un calendrier maître des sauvegardes doit identifier les systèmes, les jeux de données, la fréquence de sauvegarde, la conservation, l’emplacement, la propriété, la classification, les dépendances et la cadence des tests.
La même Politique de sauvegarde et de restauration, section Exigences de gouvernance, clause de politique 5.2, relie les attentes de sauvegarde à l’impact métier :
Tous les systèmes et applications classés comme critiques ou à fort impact dans l’analyse d’impact sur l’activité (BIA) doivent :
C’est là que la BIA et la gouvernance des sauvegardes convergent. Les systèmes critiques et à fort impact exigent une assurance de reprise renforcée, des tests plus fréquents, une meilleure cartographie des dépendances et des éléments probants plus rigoureux.
Un modèle unique d’éléments probants pour ISO 27001:2022, NIS2, DORA, NIST et COBIT 2019
Les équipes conformité rencontrent souvent des difficultés liées à la duplication entre référentiels. ISO 27001:2022 demande une sélection des contrôles fondée sur les risques et des éléments probants. NIS2 attend des mesures de gestion des risques de cybersécurité, y compris la continuité d’activité. DORA attend une résilience opérationnelle numérique, des capacités de réponse et de rétablissement, des politiques et procédures de sauvegarde et de restauration, ainsi que des tests de résilience opérationnelle numérique. NIST et COBIT 2019 utilisent encore un autre vocabulaire.
La réponse ne consiste pas à construire des programmes de sauvegarde séparés pour chaque référentiel. Elle consiste à construire un modèle unique d’éléments probants pouvant être examiné selon plusieurs angles d’audit.
| Angle de référentiel | Ce que prouvent les tests de sauvegarde et de restauration | Éléments probants à conserver pour répondre à un audit |
|---|---|---|
| ISO 27001:2022 | Les risques sont traités au moyen de contrôles sélectionnés, testés, surveillés et améliorés dans le SMSI | Domaine d’application, registre des risques, SoA, calendrier de sauvegarde, enregistrements de restauration, résultats d’audit interne, journal CAPA |
| NIS2 | Les services essentiels ou importants peuvent résister à une perturbation cyber et s’en rétablir | Plans de continuité d’activité, procédures de crise, tests de sauvegarde, liens avec la réponse aux incidents, supervision par la direction |
| DORA | Les services TIC soutenant des fonctions critiques ou importantes sont résilients et restaurables | Cartographie des actifs TIC, RTO/RPO, rapports de tests de restauration, éléments probants des dépendances vis-à-vis de tiers, procédures de reprise |
| NIST CSF | Les capacités de reprise soutiennent des résultats de cybersécurité résilients | Plans de reprise, contrôles d’intégrité des sauvegardes, procédures de communication, enseignements tirés |
| COBIT 2019 | Les objectifs de gouvernance et de management sont soutenus par des contrôles mesurables et une responsabilité définie | Responsabilité des processus, métriques, performance des contrôles, suivi des problèmes, reporting à la direction |
Pour NIS2, la référence la plus directe est Article 21 sur les mesures de gestion des risques de cybersécurité. Article 21(2)(c) inclut spécifiquement la continuité d’activité, comme la gestion des sauvegardes, la reprise après sinistre et la gestion de crise. Article 21(2)(f) est également important, car il vise les politiques et procédures permettant d’évaluer l’efficacité des mesures de gestion des risques de cybersécurité. Les tests de restauration sont précisément cela : l’élément probant que la mesure fonctionne.
Pour DORA, les liens les plus forts sont Article 11 sur la réponse et le rétablissement, Article 12 sur les politiques et procédures de sauvegarde, les procédures et méthodes de restauration et de rétablissement, et Article 24 sur les exigences générales relatives aux tests de résilience opérationnelle numérique. Pour les entités financières, un test de restauration de base de données seul peut être insuffisant si le service métier dépend de l’identité cloud, de la connectivité à une passerelle de paiement, d’un hébergement externalisé ou d’une surveillance managée. Les éléments probants de type DORA doivent être au niveau service, et non seulement au niveau serveur.
| Contrôle ISO/IEC 27001:2022 | Lien avec DORA | Lien avec NIS2 |
|---|---|---|
| 8.13 Sauvegarde de l’information | Article 12 exige des politiques de sauvegarde, ainsi que des procédures et méthodes de restauration et de rétablissement | Article 21(2)(c) inclut la gestion des sauvegardes et la reprise après sinistre comme mesures de continuité d’activité |
| 5.30 Préparation des TIC à la continuité d’activité | Article 11 exige une capacité de réponse et de rétablissement, et Article 24 exige des tests de résilience | Article 21(2)(c) inclut la continuité d’activité et la gestion de crise |
| 8.14 Redondance des installations de traitement de l’information | Articles 6 et 9 soutiennent la gestion des risques liés aux TIC, la protection, la prévention et la réduction des points de défaillance uniques | Article 21 exige des mesures appropriées et proportionnées pour gérer les risques pesant sur les réseaux et systèmes d’information |
| 5.29 Sécurité de l’information pendant une perturbation | Article 11 sur la réponse et le rétablissement exige une reprise maîtrisée pendant les incidents | Les mesures de gestion des risques d’Article 21 exigent la continuité sans abandon des contrôles de sécurité |
C’est l’efficacité d’une stratégie de conformité unifiée. Un test trimestriel de restauration d’un système de paiement peut soutenir les éléments probants de l’Annexe A d’ISO 27001:2022, les attentes de continuité de NIS2, les exigences de reprise TIC de DORA, les résultats Recover de NIST CSF et le reporting de gouvernance COBIT 2019, si les éléments probants sont correctement structurés.
Un test de restauration pratique qui devient un élément probant auditable
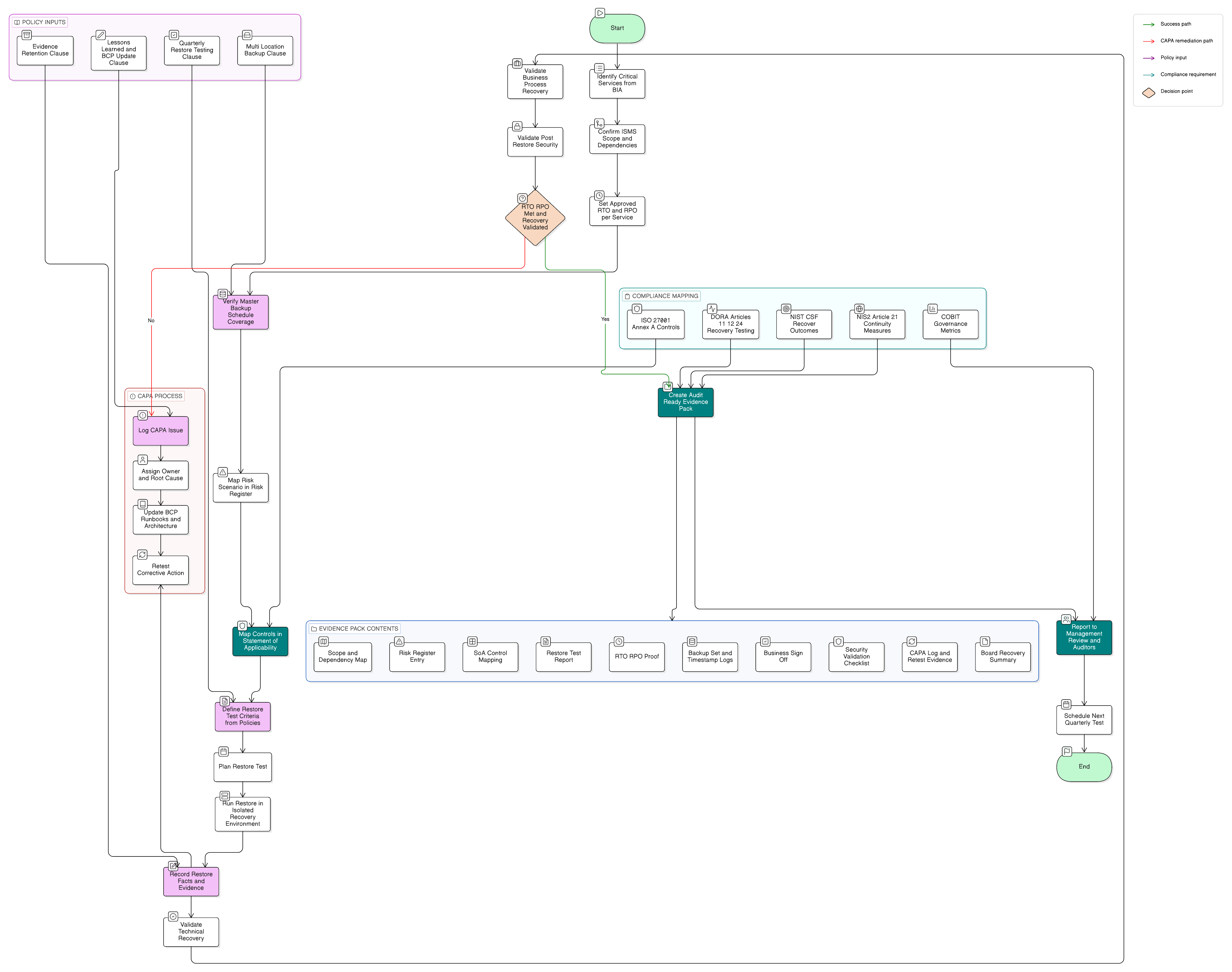
Revenons au scénario du lundi matin de Sarah, mais imaginons que son organisation se soit préparée avec la boîte à outils Clarysec.
La plateforme d’approbation des paiements est classée critique dans la BIA. Le RTO approuvé est de quatre heures. Le RPO approuvé est d’une heure. La plateforme dépend d’un cluster de bases de données, d’un fournisseur d’identité, d’un coffre-fort de secrets, d’un pipeline de journalisation, du DNS, de certificats et d’un relais de courrier électronique sortant.
L’équipe de Sarah construit un test de restauration trimestriel en six étapes.
Étape 1 : confirmer le domaine d’application et les dépendances
En utilisant l’étape 2 du Zenith Blueprint, Sarah confirme que la plateforme de paiement, la base de données, l’intégration avec l’identité, l’infrastructure de sauvegarde et l’environnement de reprise sont inclus dans le domaine d’application du SMSI. Le service juridique confirme la pertinence réglementaire. La finance confirme l’impact métier. L’informatique confirme les dépendances.
Cela évite l’erreur classique consistant à restaurer uniquement la base de données tout en ignorant le service d’authentification nécessaire pour accéder à l’application.
Étape 2 : rattacher le test au registre des risques
En utilisant l’étape 11 du Zenith Blueprint, le registre des risques inclut le scénario suivant : « La perte ou le chiffrement des données de la plateforme d’approbation des paiements empêche les opérations de paiement et crée une exposition réglementaire. »
Les contrôles en place incluent des sauvegardes quotidiennes, un stockage cloud immuable, des copies de sauvegarde multi-emplacements, des tests de restauration trimestriels et des procédures opérationnelles de reprise documentées. Le propriétaire du risque est le responsable infrastructure. Le propriétaire métier est les opérations financières. La décision de traitement est la réduction du risque.
Étape 3 : rattacher le traitement à la SoA
En utilisant l’étape 13 du Zenith Blueprint, la SoA rattache le risque aux contrôles de l’Annexe A d’ISO/IEC 27001:2022 8.13, 5.30, 8.14 et 5.29. La SoA explique que les tests de sauvegarde fournissent une capacité corrective de reprise, que les procédures de continuité TIC soutiennent la continuité d’activité, que la redondance réduit la probabilité d’interruption et que la sécurité pendant une perturbation empêche les raccourcis de reprise non sécurisés.
Étape 4 : utiliser les clauses de politique comme critères de test
L’équipe utilise la clause 5.3.3 de la Politique de sauvegarde et de restauration pour PME pour les tests de restauration trimestriels, la clause 8.2.2 pour la conservation des éléments probants et la clause 6.3.1.1 pour le stockage multi-emplacements. Elle utilise la clause 5.2.1.4 de la Politique de continuité d’activité et de reprise après sinistre pour PME pour les objectifs RTO/RPO et la clause 6.4.2 pour les enseignements tirés et les mises à jour du PCA.
| Critère de test | Cible | Élément probant |
|---|---|---|
| Périodicité de restauration | Trimestrielle | Calendrier de test et planning approuvé |
| RTO | 4 heures | Heure de début, heure de fin, durée de reprise écoulée |
| RPO | 1 heure | Horodatage de la sauvegarde et validation des transactions |
| Emplacements | Sources de sauvegarde locales et cloud disponibles | Rapport du référentiel de sauvegarde |
| Intégrité | Contrôles de cohérence de la base de données réussis | Journaux de validation |
| Application | Un utilisateur finance peut approuver un paiement de test | Validation formelle métier |
| Sécurité | Journalisation, contrôles d’accès et secrets validés après restauration | Liste de contrôle de sécurité et captures d’écran |
Étape 5 : exécuter la restauration et consigner les faits
La restauration est effectuée dans un environnement de reprise isolé. L’équipe consigne les horodatages, les identifiants du jeu de sauvegarde, les étapes de restauration, les erreurs, les résultats de validation et les approbations.
Un enregistrement solide de test de restauration doit inclure :
| Champ du test de restauration | Exemple |
|---|---|
| Identifiant du test | Q2-2026-PAY-RESTORE |
| Système testé | Plateforme d’approbation des paiements |
| Jeu de sauvegarde utilisé | Sauvegarde de la plateforme de paiement depuis le point de reprise approuvé |
| Emplacement de restauration | Environnement de reprise isolé |
| Objectif RTO | 4 heures |
| Objectif RPO | 1 heure |
| Temps réel de reprise | 2 heures 45 minutes |
| Point réel de reprise | 42 minutes |
| Validation d’intégrité | Contrôles de cohérence de la base de données réussis |
| Validation métier | Un utilisateur finance a approuvé un paiement de test |
| Validation de sécurité | Journalisation, contrôles d’accès, secrets et surveillance confirmés |
| Résultat | Réussite avec réserve |
| Validation formelle | RSSI, responsable infrastructure, propriétaire des opérations financières |
Pendant le test, l’équipe découvre un problème. L’application restaurée ne peut pas envoyer de courriels de notification, car la liste d’autorisation du relais de messagerie n’inclut pas le sous-réseau de reprise. L’approbation principale des paiements fonctionne, mais le workflow est dégradé.
Étape 6 : enregistrer les enseignements tirés et l’action corrective
C’est ici que de nombreuses organisations s’arrêtent trop tôt. L’approche Clarysec pousse le problème dans le système d’amélioration.
Dans la phase Audit, revue et amélioration, étape 29, Amélioration continue, le Zenith Blueprint utilise un journal CAPA pour suivre la description du problème, la cause racine, l’action corrective, le responsable, la date cible et le statut.
| Champ CAPA | Exemple |
|---|---|
| Description du problème | La plateforme de paiement restaurée ne pouvait pas envoyer de notifications par courriel depuis le sous-réseau de reprise |
| Cause racine | Réseau de reprise non inclus dans la conception de la liste d’autorisation du relais de messagerie |
| Action corrective | Mettre à jour l’architecture de reprise et la procédure de liste d’autorisation du relais de messagerie |
| Responsable | Responsable infrastructure |
| Date cible | 15 jours ouvrés |
| Statut | Ouvert, en attente de nouveau test |
Ce test de restauration unique produit désormais une chaîne d’éléments probants auditables : exigence de politique, confirmation du domaine d’application, cartographie des risques, cartographie SoA, plan de test, enregistrement d’exécution, validation métier, validation de sécurité, enregistrement du problème, action corrective et mise à jour du PCA.
Comment différents auditeurs examinent les mêmes éléments probants
Un dossier d’éléments probants robuste anticipe l’angle de l’auditeur.
Un auditeur ISO 27001:2022 commencera généralement par le système de management. Il demandera si les exigences de sauvegarde et de restauration sont cadrées dans le domaine d’application, fondées sur les risques, mises en œuvre, surveillées, auditées en interne et améliorées. Il attendra une traçabilité depuis le registre des risques vers la SoA puis vers les enregistrements opérationnels. Il pourra également relier les tests échoués et les actions correctives à la clause 10.2 d’ISO/IEC 27001:2022 relative aux non-conformités et aux actions correctives.
Un examinateur DORA se concentrera sur la résilience opérationnelle numérique pour les fonctions critiques ou importantes. Il voudra voir une reprise au niveau service, les dépendances TIC vis-à-vis de tiers, des tests fondés sur des scénarios, la supervision par l’organe de direction et des éléments probants montrant que les procédures de restauration sont efficaces.
Une perspective de supervision NIS2 recherchera des mesures de gestion des risques de cybersécurité appropriées et proportionnées. Les éléments probants de sauvegarde et de reprise après sinistre doivent montrer que les services essentiels ou importants peuvent maintenir ou rétablir leurs opérations après des incidents, avec une direction informée du risque résiduel.
Un évaluateur orienté NIST se concentrera sur les résultats de cybersécurité à travers Identify, Protect, Detect, Respond et Recover. Il pourra poser des questions sur les sauvegardes immuables, les accès à privilèges aux référentiels de sauvegarde, la restauration dans des environnements propres, les communications et les enseignements tirés.
Un auditeur COBIT 2019 ou de type ISACA mettra l’accent sur la gouvernance, la responsabilité des processus, les métriques, le reporting à la direction et le suivi des problèmes. Une restauration techniquement élégante l’impressionnera peu si la responsabilité et le reporting ne sont pas clairs.
Les mêmes éléments probants peuvent satisfaire toutes ces perspectives, mais seulement s’ils sont complets.
Échecs fréquents des tests de restauration qui génèrent des constats d’audit
Clarysec observe régulièrement les mêmes lacunes évitables dans les éléments probants.
| Schéma d’échec | Pourquoi cela crée un risque d’audit | Correctif pratique |
|---|---|---|
| Une sauvegarde réussie est traitée comme une restauration réussie | L’achèvement de la copie ne prouve pas la capacité de restauration | Réaliser des tests de restauration documentés avec validation |
| Les RTO et RPO sont définis mais non testés | Les objectifs de continuité peuvent être irréalistes | Mesurer le temps réel de reprise et le point réel de reprise pendant les tests |
| Seule l’infrastructure valide la restauration | Le processus métier peut rester inutilisable | Exiger la validation formelle du propriétaire métier pour les systèmes critiques |
| Les enregistrements de test sont dispersés | Les auditeurs ne peuvent pas vérifier la cohérence | Utiliser un modèle standard de rapport de test de restauration et un dossier d’éléments probants |
| Les tests échoués sont discutés mais non suivis | Aucun élément probant d’amélioration continue | Enregistrer les problèmes dans le CAPA avec responsable, échéance et nouveau test |
| Les sauvegardes sont stockées dans un seul domaine de défaillance logique | Un rançongiciel ou une mauvaise configuration peut détruire la capacité de restauration | Utiliser des emplacements séparés, du stockage immuable et le contrôle d’accès |
| Les dépendances sont exclues | Les applications restaurées peuvent ne pas fonctionner | Cartographier l’identité, le DNS, les secrets, les certificats, les intégrations et la journalisation |
| La sécurité est ignorée pendant la reprise | Les services restaurés peuvent être vulnérables ou non surveillés | Inclure une validation de sécurité post-restauration |
L’objectif n’est pas la bureaucratie. L’objectif est une reprise fiable sous pression et des éléments probants défendables en audit.
Constituer un dossier d’éléments probants de reprise pour le conseil d’administration
Les dirigeants n’ont pas besoin de journaux bruts de sauvegarde. Ils ont besoin d’une assurance indiquant que les services critiques sont restaurables, que les exceptions sont connues et que les actions d’amélioration progressent.
Pour chaque service critique, rapporter :
- Nom du service et propriétaire métier
- Criticité issue de la BIA
- RTO et RPO approuvés
- Date du dernier test de restauration
- RTO et RPO atteints
- Résultat du test
- Actions correctives ouvertes
- Dépendances vis-à-vis de tiers affectant la reprise
- Déclaration de risque résiduel
- Prochain test planifié
| Service critique | RTO/RPO | Dernier test | Résultat | Problème ouvert | Message à la direction |
|---|---|---|---|---|---|
| Plateforme d’approbation des paiements | 4h/1h | 2026-04-12 | Réussite avec réserve | Liste d’autorisation du sous-réseau de reprise pour le relais de messagerie | Approbation principale des paiements restaurée dans l’objectif, remédiation du workflow de notification en cours |
| Portail client | 8h/2h | 2026-03-20 | Échec | La restauration de la base de données a dépassé le RTO de 90 minutes | Amélioration de la capacité et du processus de restauration requise |
| Reprise du fournisseur d’identité | 2h/15m | 2026-04-05 | Réussite | Aucun | Soutient la reprise des services critiques dépendants |
Ce style de reporting crée un pont entre les équipes techniques, les auditeurs et la direction. Il soutient également la revue de direction du SMSI et la supervision de la résilience au titre de NIS2 et DORA.
Liste de contrôle d’audit pratique pour les 30 à 90 prochains jours
Si votre audit approche, commencez par les éléments probants dont vous disposez déjà et comblez d’abord les lacunes les plus risquées.
- Identifier tous les systèmes critiques et à fort impact issus de la BIA.
- Confirmer le RTO et le RPO de chaque système critique.
- Vérifier que chaque système critique figure dans le calendrier maître des sauvegardes.
- Confirmer les emplacements de sauvegarde, y compris les référentiels locaux, cloud, immuables ou séparés.
- Sélectionner au moins un test de restauration récent par service critique ou planifier immédiatement un test.
- S’assurer que les enregistrements de tests de restauration indiquent le périmètre, les horodatages, le jeu de sauvegarde, le résultat, les RTO/RPO atteints et la validation.
- Obtenir la validation formelle du propriétaire métier pour la reprise au niveau applicatif.
- Valider la sécurité après restauration, y compris le contrôle d’accès, la journalisation, la surveillance, les secrets, les certificats et l’exposition aux vulnérabilités.
- Rattacher les éléments probants au registre des risques et à la SoA.
- Enregistrer les problèmes dans le CAPA, désigner les responsables et suivre le nouveau test.
- Synthétiser les résultats pour la revue de direction.
- Préparer une vue de conformité croisée pour les discussions d’audit ISO 27001:2022, NIS2, DORA, NIST CSF et COBIT 2019.
Si vous ne pouvez pas achever tous les éléments avant l’audit, soyez transparent. Les auditeurs réagissent généralement mieux à une lacune documentée assortie d’un plan d’actions correctives qu’à des affirmations vagues de maturité.
Faire des tests de restauration votre élément probant de résilience le plus solide
Les tests de sauvegarde et de restauration constituent l’un des moyens les plus clairs de prouver la résilience opérationnelle. Ils sont tangibles, mesurables, pertinents pour l’activité et directement liés à ISO 27001:2022, NIS2, DORA, NIST, COBIT 2019, au reporting au conseil d’administration, aux programmes d’assurance demandés par les clients et aux attentes des assureurs.
Mais uniquement s’ils sont correctement documentés.
Clarysec aide les organisations à transformer les opérations de sauvegarde en éléments probants auditables grâce à la Politique de sauvegarde et de restauration, la Politique de sauvegarde et de restauration pour PME, la Politique de continuité d’activité et de reprise après sinistre pour PME, Zenith Blueprint et Zenith Controls.
Votre prochaine action pratique est simple. Choisissez un service critique cette semaine. Exécutez un test de restauration au regard de ses RTO et RPO approuvés. Documentez le résultat. Rattachez-le au registre des risques et à la SoA. Consignez chaque enseignement tiré.
Si vous voulez que ce processus soit répétable pour ISO 27001:2022, NIS2, DORA, NIST et COBIT 2019, la boîte à outils Clarysec vous fournit la structure nécessaire pour démontrer la reprise sans construire de labyrinthe de conformité à partir de zéro.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council