Du chaos à la maîtrise : guide ISO 27001 de la réponse aux incidents pour les entreprises industrielles
Un plan de réponse aux incidents efficace est indispensable pour les entreprises industrielles exposées à des cybermenaces susceptibles d’arrêter la production. Ce guide présente une démarche progressive pour mettre en place une capacité robuste de gestion des incidents, alignée sur ISO 27001, renforcer la résilience opérationnelle et satisfaire aux exigences strictes de conformité issues de cadres tels que NIS2 et DORA.
Introduction
Le bourdonnement des machines dans l’atelier est le son même de l’activité. Pour une entreprise industrielle de taille intermédiaire, il incarne le chiffre d’affaires, la stabilité de la chaîne d’approvisionnement et la confiance des clients. Imaginez maintenant que ce son soit remplacé par un silence inquiétant. Une seule alerte s’affiche sur un écran du centre opérationnel de sécurité (SOC) : “Activité réseau inhabituelle détectée — segment réseau de production”. En quelques minutes, les systèmes de contrôle ne répondent plus. La ligne de production s’arrête. Ce scénario n’a rien d’hypothétique : c’est la réalité d’un cyberincident moderne dans le secteur industriel, où la convergence entre les technologies de l’information (IT) et les technologies opérationnelles (OT) a créé un paysage de menaces nouveau et à forts enjeux.
Un incident de sécurité de l’information n’est plus seulement un problème informatique ; c’est une interruption critique de l’activité, capable de paralyser les opérations. Pour les RSSI et les dirigeants d’entreprises industrielles, la question n’est pas de savoir si un incident se produira, mais comment l’organisation y répondra lorsqu’il surviendra. Une réaction chaotique et improvisée entraîne une indisponibilité prolongée, des sanctions réglementaires et une atteinte irréversible à la réputation. À l’inverse, une réponse structurée et régulièrement exercée peut transformer une catastrophe potentielle en événement maîtrisé, démontrant résilience et maîtrise. C’est le principe central de la gestion des incidents de sécurité de l’information, composante critique de tout système de management de la sécurité de l’information (SMSI) robuste fondé sur ISO/IEC 27001.
Les enjeux
Pour une entreprise industrielle, l’impact d’un incident de sécurité dépasse largement la perte de données. Le principal risque est l’interruption des activités opérationnelles critiques. Lorsque des systèmes OT sont compromis, les conséquences sont immédiates et concrètes : lignes de production arrêtées, expéditions retardées et engagements non tenus dans la chaîne d’approvisionnement. L’hémorragie financière commence instantanément, avec des coûts liés à l’indisponibilité, aux actions de remédiation et aux éventuelles pénalités contractuelles.
Le paysage réglementaire ajoute un niveau supplémentaire de pression. Un incident mal géré peut déclencher des amendes importantes au titre de différents cadres. Comme le souligne le guide complet de Clarysec, Zenith Controls, les enjeux sont particulièrement élevés :
“L’objectif principal de la gestion des incidents est de minimiser l’impact négatif des incidents de sécurité sur les activités opérationnelles et d’assurer une réponse rapide, efficace et ordonnée. Une gestion inefficace des incidents peut entraîner des pertes financières significatives, un préjudice réputationnel et des sanctions réglementaires.”
Il ne s’agit pas d’une seule réglementation. L’interconnexion de la conformité moderne signifie qu’un incident unique peut produire des conséquences réglementaires en cascade. Une violation de données impliquant des informations relatives aux salariés ou aux clients peut contrevenir au GDPR. Une interruption de services pour des clients du secteur financier peut attirer l’attention au titre de DORA. Pour les entités qualifiées d’essentielles ou d’importantes, NIS2 impose des délais stricts de notification des incidents et des exigences de sécurité.
Au-delà des impacts financiers et réglementaires immédiats se trouve l’érosion de la confiance. Les clients, partenaires et fournisseurs dépendent de la capacité de l’entreprise industrielle à livrer. Un incident qui perturbe ce flux entame la confiance et peut entraîner des pertes commerciales. Reconstruire cette réputation est souvent plus long et plus difficile que restaurer les systèmes affectés. Le coût ultime ne se limite pas à la somme des amendes et des heures de production perdues ; il inclut l’impact à long terme sur la position de marché et l’intégrité de la marque de l’entreprise.
À quoi ressemble un dispositif efficace
Face à des risques aussi significatifs, à quoi ressemble une capacité efficace de réponse aux incidents ? C’est un état de préparation organisée, dans lequel le chaos est remplacé par un processus clair et méthodique. C’est la capacité à détecter un incident, à y répondre et à s’en rétablir de manière à minimiser les dommages et à soutenir la continuité d’activité. Cet état cible repose sur les fondations définies par ISO/IEC 27001, notamment dans ses contrôles de l’Annexe A.
Un programme mature de gestion des incidents, encadré par une politique formelle, garantit que chacun connaît son rôle. Notre P16S Politique de gestion des incidents de sécurité de l’information - PME met l’accent sur cette clarté dans son énoncé d’objet :
“L’objet de cette politique est d’établir un cadre structuré et efficace pour gérer les incidents de sécurité de l’information. Ce cadre assure une réponse coordonnée et dans les délais aux événements de sécurité, en minimisant leur impact sur les opérations, les actifs et la réputation de l’organisation, tout en respectant les exigences légales, statutaires, réglementaires et contractuelles.”
Ce cadre structuré produit des bénéfices concrets :
- Réduction de l’indisponibilité : un plan bien défini permet un confinement et un rétablissement plus rapides, afin de remettre les lignes de production en service plus tôt.
- Maîtrise des coûts : en réduisant la durée et l’impact de l’incident, les coûts associés à la remédiation, à la perte de revenus et aux amendes potentielles diminuent significativement.
- Résilience renforcée : l’organisation tire des enseignements de chaque incident, en utilisant les revues post-incident pour renforcer les défenses et améliorer les réponses futures. Cette approche s’inscrit dans la logique d’amélioration continue d’ISO 27001.
- Conformité démontrable : un processus de réponse aux incidents documenté et testé fournit aux auditeurs et aux autorités de régulation des éléments de preuve clairs montrant que l’organisation prend ses obligations de sécurité au sérieux.
- Confiance des parties prenantes : une réponse professionnelle et efficace rassure les clients, partenaires et assureurs sur la fiabilité et la sécurité de l’organisation.
En définitive, un dispositif efficace se reconnaît à une organisation qui n’est pas seulement réactive, mais proactive, et qui considère la gestion des incidents non comme une tâche technique, mais comme une fonction métier essentielle à sa survie et à sa croissance dans un monde numérique.
La démarche pratique : guide étape par étape
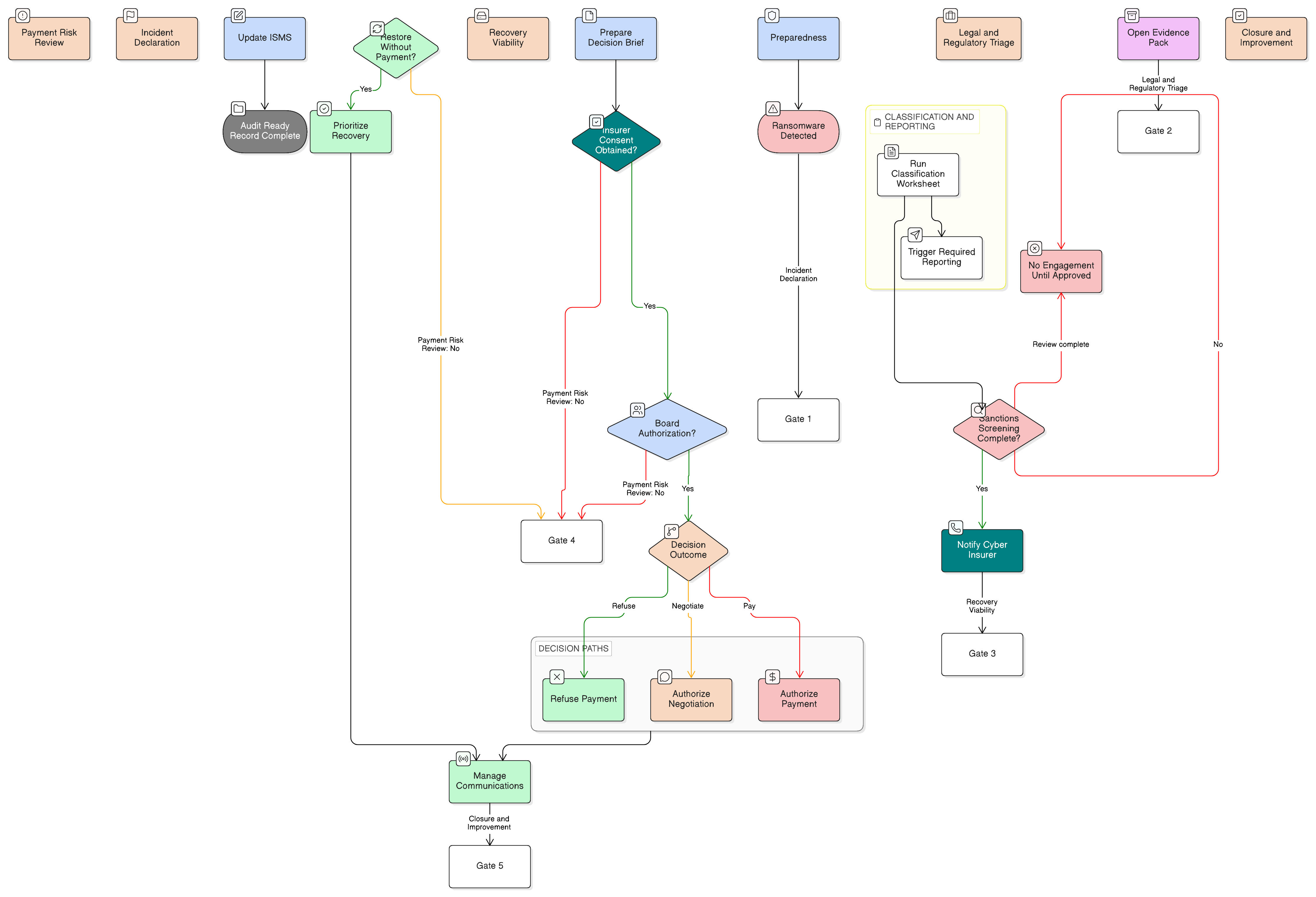
Mettre en place une capacité résiliente de réponse aux incidents exige plus qu’un document ; cela requiert un plan pratique et actionnable, intégré à la culture de l’organisation. Ce processus peut être structuré selon le cycle de vie classique de la gestion des incidents, chaque phase étant soutenue par des politiques et procédures claires.
Phase 1 : préparation et planification
Il s’agit de la phase la plus critique. Une réponse efficace est impossible sans préparation approfondie. La base est une politique complète qui définit le cadre de toutes les actions ultérieures. La P16S Politique de gestion des incidents de sécurité de l’information - PME présente la première étape essentielle à la section 5.1, “Plan de gestion des incidents” :
“L’organisation doit élaborer, mettre en œuvre et maintenir un plan de gestion des incidents de sécurité de l’information. Ce plan doit être intégré aux plans de continuité d’activité et de reprise après sinistre afin d’assurer une réponse cohérente aux événements perturbateurs.”
Ce plan n’est pas un document statique. Il doit définir l’ensemble du processus, de la détection initiale à la résolution finale. Un élément clé consiste à mettre en place une équipe dédiée de réponse aux incidents (IRT). Les rôles et responsabilités de cette équipe doivent être explicitement définis afin d’éviter toute confusion pendant une crise. La politique le précise à la section 5.2, “Rôles de l’équipe de réponse aux incidents (IRT)”, en indiquant : “L’IRT doit être composée de membres issus des départements concernés, notamment l’informatique, la sécurité, le juridique, les ressources humaines et les relations publiques. Les rôles et responsabilités de chaque membre pendant un incident doivent être clairement documentés.”
La préparation implique également de s’assurer que l’équipe dispose des outils et ressources nécessaires, notamment des canaux de communication sécurisés, des logiciels d’analyse et un accès à des capacités d’investigation numérique.
Phase 2 : détection et analyse
Un incident ne peut pas être géré s’il n’est pas détecté. Cette phase vise à identifier et à valider les incidents de sécurité potentiels. Selon notre P16S Politique de gestion des incidents de sécurité de l’information - PME, la section 5.3, “Détection et notification des incidents”, impose que “tous les employés, prestataires et autres parties concernées soient tenus de signaler sans délai toute faiblesse ou menace de sécurité de l’information observée ou suspectée”.
Cela nécessite une combinaison de surveillance technique et de sensibilisation humaine. Les systèmes automatisés tels que les solutions de Security Information and Event Management (SIEM) sont essentiels pour repérer les anomalies, mais un personnel bien formé reste la première ligne de défense. Notre P08S Politique de sensibilisation et de formation à la sécurité de l’information - PME le renforce en précisant dans son énoncé de politique : “Tous les employés et, le cas échéant, les prestataires doivent recevoir une sensibilisation et une formation appropriées, ainsi que des mises à jour régulières sur les politiques et procédures de l’organisation, en fonction de leur fonction exercée.”
Une fois un événement signalé, l’IRT doit l’analyser et le classifier rapidement afin de déterminer sa gravité et son impact potentiel. Ce triage initial est indispensable pour prioriser l’effort de réponse.
Phase 3 : confinement, éradication et rétablissement
Lorsqu’un incident est confirmé, l’objectif immédiat est de limiter les dommages. La stratégie de confinement est déterminante, en particulier dans un environnement industriel. Elle peut consister à isoler le segment réseau affecté qui contrôle les machines de production, afin d’empêcher la propagation d’un logiciel malveillant du réseau IT vers le réseau OT.
Après le confinement, l’IRT procède à l’éradication de la menace. Cela peut inclure la suppression de logiciels malveillants, la désactivation de comptes utilisateurs compromis et l’application de correctifs aux vulnérabilités. La dernière étape de cette phase est le rétablissement, au cours duquel les systèmes sont restaurés en fonctionnement normal. Cette étape doit être menée méthodiquement, en s’assurant que la menace a été entièrement supprimée avant la remise en ligne des systèmes. Comme l’indique la section 5.5 de la P16S Politique de gestion des incidents de sécurité de l’information - PME, “les activités de rétablissement doivent être priorisées sur la base de l’analyse d’impact sur l’activité (BIA) afin de restaurer les fonctions métier critiques aussi rapidement que possible”.
Tout au long de cette phase, la collecte des éléments de preuve est primordiale. Le traitement approprié des éléments de preuve numériques est essentiel pour l’analyse post-incident et pour toute action juridique ou réglementaire éventuelle. Notre politique, à la section 5.6, “Collecte et traitement des éléments de preuve”, précise que “tous les éléments de preuve liés à un incident de sécurité de l’information doivent être collectés, traités et conservés selon des méthodes d’investigation numérique préservant leur recevabilité afin d’en garantir l’intégrité”.
Phase 4 : activités post-incident et amélioration continue
Le travail ne s’arrête pas lorsque les systèmes sont de nouveau en ligne. La phase post-incident est celle où les enseignements les plus précieux sont tirés. Une revue post-incident formelle, ou réunion de retour d’expérience, est indispensable. Comme le précise notre guide de mise en œuvre, l’objectif est d’analyser l’incident et la réponse apportée afin d’identifier les axes d’amélioration.
“Les enseignements tirés de l’analyse et de la résolution des incidents de sécurité de l’information doivent être utilisés pour améliorer la détection, la réponse et la prévention des incidents futurs. Cela inclut la mise à jour des appréciations des risques, des politiques, des procédures et des contrôles techniques.”
Cette boucle de retour d’expérience est le moteur de l’amélioration continue, pilier du cadre ISO 27001. Les constats issus de cette revue doivent être utilisés pour mettre à jour le plan de réponse aux incidents, affiner les contrôles de sécurité et renforcer la formation des employés. L’organisation devient ainsi plus solide et plus résiliente après chaque incident, en transformant un événement négatif en catalyseur positif de changement.
Relier les exigences : points clés de conformité transverse
Un plan de réponse aux incidents efficace ne satisfait pas seulement ISO 27001 ; il constitue l’ossature de la conformité à un nombre croissant de réglementations qui se chevauchent. Les cadres modernes reconnaissent qu’une réponse rapide et structurée est fondamentale pour protéger les données, les services et les infrastructures critiques. Les RSSI et responsables conformité doivent comprendre ces interactions pour bâtir un programme véritablement complet.
Les contrôles centraux d’ISO/IEC 27002:2022 relatifs à la gestion des incidents (5.24, 5.25, 5.26 et 5.27) fournissent une base universelle. Ils couvrent la planification et la préparation, l’appréciation et la décision sur les événements, la réponse aux incidents et l’apprentissage qui en découle. Cette structure se retrouve dans d’autres réglementations majeures.
Directive NIS2 : pour les entreprises industrielles considérées comme entités essentielles ou importantes, NIS2 change la donne. Elle impose des mesures de sécurité strictes et la notification des incidents. Clarysec Zenith Controls met en évidence ce lien direct :
“NIS2 exige que les organisations disposent de capacités de gestion des incidents, notamment de procédures de notification des incidents significatifs aux autorités compétentes dans des délais stricts, par exemple une alerte précoce dans les 24 heures.”
Cela signifie que le plan de réponse d’une entreprise industrielle aligné sur ISO 27001 doit intégrer les workflows de notification et les délais spécifiques exigés par NIS2.
DORA (Digital Operational Resilience Act) : bien que centré sur le secteur financier, DORA étend son influence aux prestataires tiers critiques de services TIC, qui peuvent inclure des entreprises industrielles fournissant des technologies ou des services à des entités financières. DORA met fortement l’accent sur la gestion des incidents liés aux TIC. Comme l’explique Clarysec Zenith Controls :
“DORA impose un processus complet de gestion des incidents liés aux TIC. Cela inclut la classification des incidents selon des critères spécifiques et la notification des incidents majeurs aux autorités de régulation. L’objectif est d’assurer la résilience des opérations numériques dans l’ensemble de l’écosystème financier.”
GDPR (General Data Protection Regulation) : tout incident impliquant des données à caractère personnel déclenche immédiatement des obligations au titre du GDPR. Une violation de données à caractère personnel doit être notifiée à l’autorité de contrôle dans un délai de 72 heures. Un plan de réponse aux incidents efficace doit prévoir un processus clair pour déterminer si des données à caractère personnel sont concernées et lancer sans délai le processus de notification GDPR.
NIST Cybersecurity Framework (CSF) : le NIST CSF est largement adopté, et ses cinq fonctions (Identifier, Protect, Detect, Respond, Recover) s’alignent parfaitement sur le cycle de vie de la gestion des incidents. Les fonctions “Respond” et “Recover” sont entièrement dédiées aux activités de gestion des incidents, ce qui fait d’un plan fondé sur ISO 27001 un contributeur direct à la mise en œuvre du NIST CSF.
COBIT 2019 : ce framework de gouvernance et de gestion informatique met également l’accent sur la réponse aux incidents. Clarysec Zenith Controls relève cet alignement :
“Le domaine ‘Deliver, Service and Support’ (DSS) de COBIT 2019 comprend le processus DSS02, ‘Manage service requests and incidents’. Ce processus garantit que les incidents sont résolus dans les délais et ne perturbent pas les activités opérationnelles, en s’alignant directement sur les objectifs des contrôles de gestion des incidents d’ISO 27001.”
En construisant un programme robuste de gestion des incidents fondé sur ISO 27001, les organisations ne se contentent pas d’atteindre la conformité à une seule norme ; elles créent une capacité opérationnelle résiliente qui répond aux exigences essentielles de plusieurs cadres réglementaires superposés.
Se préparer à l’examen : ce que demanderont les auditeurs
Un plan de réponse aux incidents ne vaut que par son exécution et sa documentation. Lorsqu’un auditeur intervient, il recherche des éléments de preuve concrets montrant que le plan n’est pas un document dormant, mais une composante vivante de la posture de sécurité de l’organisation. Il veut constater un processus mature et reproductible.
Le processus d’audit lui-même est structuré et méthodique. Selon la feuille de route complète présentée dans Zenith Blueprint, les auditeurs testeront systématiquement l’efficacité de vos contrôles de gestion des incidents. Au cours de la phase 2, “Travaux sur site et collecte des éléments de preuve”, ils consacreront des étapes spécifiques à ce domaine.
Étape 15 : revue des procédures de gestion des incidents : Les auditeurs commenceront par demander le plan formel de gestion des incidents et les procédures associées. Ils examineront ces documents pour en vérifier l’exhaustivité et la clarté. Comme l’indique le Zenith Blueprint pour cette étape :
“Examiner les procédures documentées de gestion des incidents de sécurité de l’information de l’organisation. Vérifier que les procédures définissent les rôles, les responsabilités et les plans de communication pour la gestion des incidents.”
Ils demanderont :
- Existe-t-il un plan de réponse aux incidents formellement documenté ?
- Une équipe de réponse aux incidents (IRT) est-elle définie avec des rôles et des coordonnées clairs ?
- Existe-t-il des procédures claires pour signaler, classifier et escalader les incidents ?
- Le plan comprend-il des protocoles de communication pour les parties prenantes internes et externes ?
Étape 16 : évaluation des tests de réponse aux incidents : Un plan qui n’a jamais été testé est un plan susceptible d’échouer. Les auditeurs exigeront la preuve que le plan est viable. Le Zenith Blueprint insiste sur ce point :
“Vérifier que le plan de réponse aux incidents est testé régulièrement au moyen d’exercices tels que des simulations sur table ou des exercices grandeur nature. Examiner les résultats de ces tests et vérifier si les enseignements tirés ont été utilisés pour mettre à jour le plan.”
Ils demanderont :
- Les enregistrements des exercices sur table ou des simulations.
- Les rapports post-test détaillant ce qui a bien fonctionné et ce qui devait être amélioré.
- Les éléments de preuve montrant que le plan de réponse aux incidents a été mis à jour sur la base de ces constats.
Étape 17 : inspection des journaux et rapports d’incidents : Enfin, les auditeurs voudront voir le plan en action en examinant les enregistrements des incidents passés. C’est le test ultime de l’efficacité du programme. Ils analyseront les journaux d’incidents, les enregistrements de communication de l’IRT et les rapports de revue post-incident. L’objectif est de vérifier que l’organisation a suivi ses propres procédures lors d’un événement réel.
Ils demanderont :
- Pouvez-vous fournir un journal de tous les incidents de sécurité survenus au cours des 12 derniers mois ?
- Pour une sélection d’incidents, pouvez-vous présenter l’enregistrement complet, de la détection à la résolution ?
- Existe-t-il des rapports post-incident analysant la cause racine et identifiant les actions correctives ?
- Les éléments de preuve ont-ils été traités conformément à la procédure documentée ?
Être prêt à répondre à ces questions avec une documentation bien organisée et des enregistrements clairs est la clé d’un audit réussi et démontre une véritable culture de résilience en matière de sécurité.
Pièges courants
Même avec un plan en place, de nombreuses organisations trébuchent lors d’un incident réel. Éviter ces pièges courants est aussi important que disposer d’un bon plan.
- Absence de plan formel et testé : l’échec le plus fréquent consiste à ne pas avoir de plan, ou à disposer d’un plan qui n’a jamais été testé. Un plan non testé n’est qu’un ensemble d’hypothèses qui risquent d’être démenties au pire moment.
- Rôles et responsabilités mal définis : en situation de crise, l’ambiguïté est l’ennemie. Si les membres de l’équipe ne savent pas exactement ce qu’ils doivent faire, la réponse sera lente, chaotique et inefficace.
- Défaillance de la communication : laisser les parties prenantes dans l’ignorance crée de la panique et de la défiance. Un plan de communication clair pour les employés, les clients, les autorités de régulation et même les médias est indispensable pour maîtriser le récit et maintenir la confiance.
- Conservation insuffisante des éléments de preuve : dans la précipitation pour restaurer les services, les équipes détruisent souvent des éléments de preuve numériques essentiels. Cela entrave non seulement l’investigation post-incident, mais peut aussi avoir de graves conséquences juridiques et de conformité.
- Oubli du retour d’expérience : la plus grande erreur consiste à ne pas apprendre de l’incident. Sans revue post-incident approfondie et sans engagement à mettre en œuvre des actions correctives, l’organisation est condamnée à répéter ses échecs passés.
- Ignorance de l’environnement OT : pour les entreprises industrielles, traiter la réponse aux incidents comme un sujet purement informatique est une erreur critique. Le plan doit traiter explicitement les défis propres à l’environnement OT, notamment les implications de sûreté et les protocoles de rétablissement spécifiques aux systèmes de contrôle industriel.
Prochaines étapes
Passer d’une posture réactive à un état de préparation proactive est un cheminement que toute organisation industrielle doit entreprendre. La voie à suivre suppose un engagement à construire une capacité de gestion des incidents structurée et pilotée par la politique.
Nous recommandons de commencer par une base solide. Nos modèles de politiques fournissent un point de départ complet pour définir votre cadre de gestion des incidents.
- Établissez un plan clair et actionnable avec la P16S Politique de gestion des incidents de sécurité de l’information - PME.
- Assurez la préparation de votre équipe en mettant en œuvre la P08S Politique de sensibilisation et de formation à la sécurité de l’information - PME.
Pour mieux comprendre comment ces contrôles s’inscrivent dans un paysage de conformité plus large et comment se préparer à des audits rigoureux, nos guides experts constituent des ressources précieuses.
- Cartographiez vos contrôles entre plusieurs cadres avec Zenith Controls.
- Préparez-vous à l’examen des auditeurs avec Zenith Blueprint.
Conclusion
Pour une entreprise industrielle de taille intermédiaire, le silence d’une ligne de production à l’arrêt est le son le plus coûteux au monde. Dans l’environnement interconnecté actuel, la gestion des incidents de sécurité de l’information n’est plus une fonction technique déléguée au département informatique ; elle constitue un pilier fondamental de la résilience opérationnelle et de la continuité d’activité.
En adoptant l’approche structurée d’ISO 27001, les organisations peuvent passer d’une réaction chaotique à une réponse maîtrisée et méthodique. Un plan de réponse aux incidents bien documenté, régulièrement testé et soutenu par un personnel formé et sensibilisé constitue la protection ultime. Il réduit l’indisponibilité, maîtrise les coûts, assure la conformité à un réseau complexe de réglementations telles que NIS2 et DORA et, surtout, préserve la confiance des clients et des partenaires. L’investissement dans cette capacité n’est pas un coût ; c’est un investissement dans la viabilité future et la résilience même de l’entreprise.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council