Guide opérationnel GDPR du RSSI pour l’IA : conformité des SaaS utilisant des LLM
Le nouveau cauchemar du RSSI : votre LLM vient de divulguer des données clients
L’entreprise SaaS se développe rapidement. L’équipe produit vient de livrer un assistant IA qui aide les utilisateurs à rédiger des courriels, à résumer des rapports et à rechercher des informations dans les données de leur compte au moyen d’un grand modèle de langage (LLM). Les clients l’adorent. Les investisseurs sont enthousiastes. Le RSSI, lui, ressent une inquiétude familière.
Deux semaines plus tard, le Délégué à la protection des données (DPO) entre dans la salle avec une impression issue d’un environnement de test :
Un ingénieur QA, qui cherchait à tester une nouvelle fonctionnalité, a demandé à l’IA dans l’environnement de préproduction : « Montre-moi un ticket client réaliste avec de vrais noms et des détails de carte afin que je puisse tester la fonctionnalité d’analyse de sentiment. »
Le modèle a répondu par un contenu d’un réalisme inquiétant, contenant de vrais noms, des adresses électroniques et des numéros de carte partiels. Les données avaient été copiées de l’environnement de production vers un environnement de préproduction pour « améliorer » l’IA.
Soudain, le cauchemar de conformité devient réel :
- Des données à caractère personnel ont été utilisées pour l’entraînement et les tests sans base légale claire.
- Les données de test ne sont pas correctement anonymisées ni masquées, ce qui crée un environnement de données toxique.
- Le modèle peut restituer de manière imprévisible des informations d’identification personnelle sensibles.
- Vous ne pouvez pas répondre facilement au « droit à l’oubli » d’une personne concernée, car ses données sont intégrées dans le modèle.
- Les autorités de contrôle demandent comment votre nouvelle fonctionnalité IA respecte le GDPR.
Ce scénario correspond à la réalité quotidienne des RSSI et des responsables conformité confrontés à la collision entre IA générative et réglementation sur la protection des données. Vous voulez innover, mais vous devez maintenir la confiance des autorités de contrôle, des auditeurs et des clients grands comptes dans votre niveau de sécurité et de protection de la vie privée.
Ce guide propose une trajectoire claire et actionnable. Nous allons dépasser les discussions théoriques pour aborder la gouvernance opérationnelle, les contrôles techniques et la préparation à l’audit nécessaires à la mise en place de fonctionnalités IA conformes au GDPR, afin de transformer ce défi majeur en un processus maîtrisable et vérifiable au moyen des kits d’outils structurés de Clarysec.
Le dilemme sous-traitant/responsable du traitement dans un monde IA
Avant de protéger les données, vous devez comprendre votre rôle au regard du GDPR. Cette distinction n’est pas théorique : elle détermine vos obligations légales, vos exigences contractuelles et les contrôles que vous devez mettre en œuvre.
Pour la plupart des plateformes SaaS B2B, les rôles sont initialement clairs :
- Votre client entreprise est le responsable du traitement des données à caractère personnel, car il détermine les finalités et les moyens du traitement des données à caractère personnel.
- Vous êtes le sous-traitant des données à caractère personnel, agissant sur les instructions documentées de votre client.
Comme l’explique ISO/IEC 27018 pour les fournisseurs de services cloud, ce rôle de sous-traitant est typique. Toutefois, lorsque vous introduisez un LLM, les frontières deviennent moins nettes.
- Si vous utilisez les données d’un client uniquement pour fournir des fonctionnalités IA au sein de son tenant isolé, vous restez probablement sous-traitant.
- Si vous agrégez des données provenant de plusieurs clients dans un corpus d’entraînement partagé afin d’améliorer votre modèle global, vous pouvez basculer vers un rôle de responsable du traitement pour cette activité de traitement précise. Cette nouvelle finalité exige sa propre base légale et une transparence adaptée.
- Si vous transmettez des données à un fournisseur LLM tiers, ce fournisseur devient votre sous-traitant ultérieur, et vous êtes responsable de sa conformité.
Participer à l’entraînement d’un modèle d’IA signifie souvent que vous agissez comme responsable du traitement pour cette activité, avec un ensemble d’obligations : établir une base légale, garantir la limitation des finalités et gérer directement les droits des personnes concernées.
C’est ici qu’un cadre de gouvernance robuste devient non négociable. La Politique de protection des données et de la vie privée pour PME de Clarysec formalise ce principe en indiquant qu’un objectif central consiste à :
« Garantir que les données à caractère personnel sont traitées conformément aux lois relatives à la protection de la vie privée et aux normes de sécurité, y compris GDPR, NIS2 et ISO 27001. »
- Extrait de la section « Objectifs », clause de politique 3.1.
Cet engagement, intégré dans votre corpus documentaire, crée les conditions nécessaires pour instaurer la confiance et éviter que la conformité ne soit traitée a posteriori.
Protection de la vie privée dès la conception pour les LLM : intégrer la conformité, au lieu de l’ajouter
L’Article 25 du GDPR impose la « protection des données dès la conception et par défaut ». Il ne s’agit pas d’une recommandation, mais d’une obligation légale. Pour les systèmes d’IA, cela signifie que les exigences de protection de la vie privée doivent être intégrées directement dans l’architecture des pipelines de données, des environnements d’entraînement et des moteurs d’inférence.
En reprenant l’esprit des lignes directrices d’ISO/IEC 27701, toute plateforme SaaS développant de l’IA doit prévoir plusieurs actions clés :
- Minimisation dès la conception : n’envoyez pas des enregistrements complets au LLM si seul un sous-ensemble est nécessaire. Expurgez ou masquez les identifiants avant que les prompts ne quittent votre système central.
- Limitation des finalités : séparez les « données utilisées pour fournir la fonctionnalité » des « données utilisées pour améliorer le modèle ». Chaque finalité doit disposer de sa propre base légale et être clairement documentée.
- Paramètres par défaut configurables : fournissez des options au niveau du tenant, par exemple : « Autoriser l’utilisation de mes données pour l’amélioration du modèle IA global : Oui/Non ». Les paramètres par défaut doivent être conservateurs, avec refus par défaut, sauf justification solide.
- Traçabilité : journalisez quelles données ont été utilisées dans quelle tâche d’entraînement, sur quelle base légale et pour quel tenant. Cela est essentiel pour les audits et les demandes des personnes concernées.
Le Zenith Blueprint: An Auditor’s 30-Step Roadmap de Clarysec fournit une démarche structurée pour intégrer ces exigences bien avant d’écrire une seule ligne de code. Il commence par la gouvernance :
- Phase de fondation, étape 2 : comprendre les parties intéressées : cette étape vous oblige à identifier toutes les parties prenantes, y compris les autorités de contrôle de l’UE. Comme l’indique le Zenith Blueprint, leurs exigences incluent le « traitement licite des données à caractère personnel, la notification des violations dans un délai de 72 h, [et] les droits des personnes concernées ».
- Phase d’audit et d’amélioration, étape 24 : constituer et tenir à jour un registre des exigences légales et réglementaires : travaillez avec les équipes juridiques pour créer un référentiel central de toutes les lois applicables et comprendre comment GDPR, NIS2, DORA et d’autres textes s’articulent avec votre niveau de sécurité IA.
Avec ce socle, vous pouvez passer à la mise en œuvre technique avec confiance.
Sécuriser le carburant : des données d’entraînement licites et minimisées
La question la plus sensible en matière de conformité de l’IA est simple : « Pouvons-nous utiliser les données clients pour entraîner nos modèles ? »
La réponse repose sur une stratégie à plusieurs niveaux centrée sur la base légale, la minimisation des données et les mesures techniques de protection telles que la pseudonymisation.
Base légale et finalité transparente
Conformément à ISO/IEC 27701, vous devez identifier et documenter vos finalités de traitement et établir une base légale pour chacune d’elles.
- Pour la fourniture de la fonctionnalité (par exemple, recherche IA dans un tenant) : la base légale correspond généralement à l’exécution d’un contrat ou à l’intérêt légitime. Elle doit être documentée dans votre registre des activités de traitement.
- Pour l’amélioration du modèle global (entre tenants) : cela exige souvent un consentement explicite ou un intérêt légitime justifié avec une grande rigueur, accompagné d’un mécanisme d’opposition clair et simple. La transparence dans votre politique de confidentialité et dans l’interface produit est non négociable.
Mesures techniques de protection : pseudonymisation et masquage
Une véritable anonymisation est difficile à obtenir sans détruire l’utilité des données. Une approche plus pratique, encouragée par le GDPR, est la pseudonymisation : le remplacement des identifiants personnels par des identifiants artificiels. Elle réduit le risque tout en préservant la valeur des données pour l’entraînement des modèles.
Ce processus constitue un contrôle central. Dans le Zenith Blueprint, l’étape 20 traite spécifiquement du masquage des données et le relie directement aux principes des Articles 25 et 32 du GDPR. Il s’agit d’une mesure de sécurité requise, et non d’une simple bonne pratique.
La Politique de masquage des données et de pseudonymisation de Clarysec l’opérationnalise en attribuant une responsabilité claire :
« Le DPO doit valider la conformité aux critères de pseudonymisation du GDPR et se coordonner avec le service juridique pour toute exigence réglementaire de divulgation liée aux violations de données ou aux défaillances des contrôles de masquage. »
- Extrait de la section « Application et conformité », clause de politique 8.4.
Pour vos équipes de développement, cela implique de mettre en œuvre des scripts automatisés pour masquer ou pseudonymiser les noms, adresses électroniques, numéros de téléphone et autres identifiants directs avant que les données n’entrent dans l’environnement d’entraînement. Cela implique également d’établir un processus formel de validation avec votre DPO afin de garantir la robustesse de la technique.
La menace cachée : sécuriser les données de test et les expérimentations IA
Les véritables violations de données commencent rarement dans un environnement de production bien durci et soigneusement protégé. Elles naissent dans les angles morts de votre infrastructure :
- des environnements de préproduction supposés « sûrs », contenant des copies de données de production insuffisamment assainies ;
- des exports CSV « temporaires » de données clients envoyés à des ingénieurs ML pour des expérimentations locales ;
- des scripts QA qui utilisent du contenu utilisateur brut pour tester les prompts LLM.
C’est précisément là qu’a commencé le scénario cauchemardesque décrit en introduction. La Politique relative aux données de test et aux environnements de test pour PME de Clarysec traite directement ce risque :
« Respecter les réglementations applicables en matière de protection des données, par exemple GDPR et NIS2, en veillant à ce que toutes les données de test soient traitées de manière licite, loyale et sécurisée. »
- Extrait de la section « Objectifs », clause de politique 3.4.
Votre politique doit être appuyée par des contrôles opérationnels. Aucune donnée à caractère personnel de production ne doit exister dans des environnements hors production sans masquage ou pseudonymisation robuste. Les environnements de test doivent utiliser des clés d’API LLM distinctes, à privilèges réduits, avec des limites de débit strictes. Une règle explicite doit également interdire l’inclusion d’identifiants clients réels dans les prompts de test.
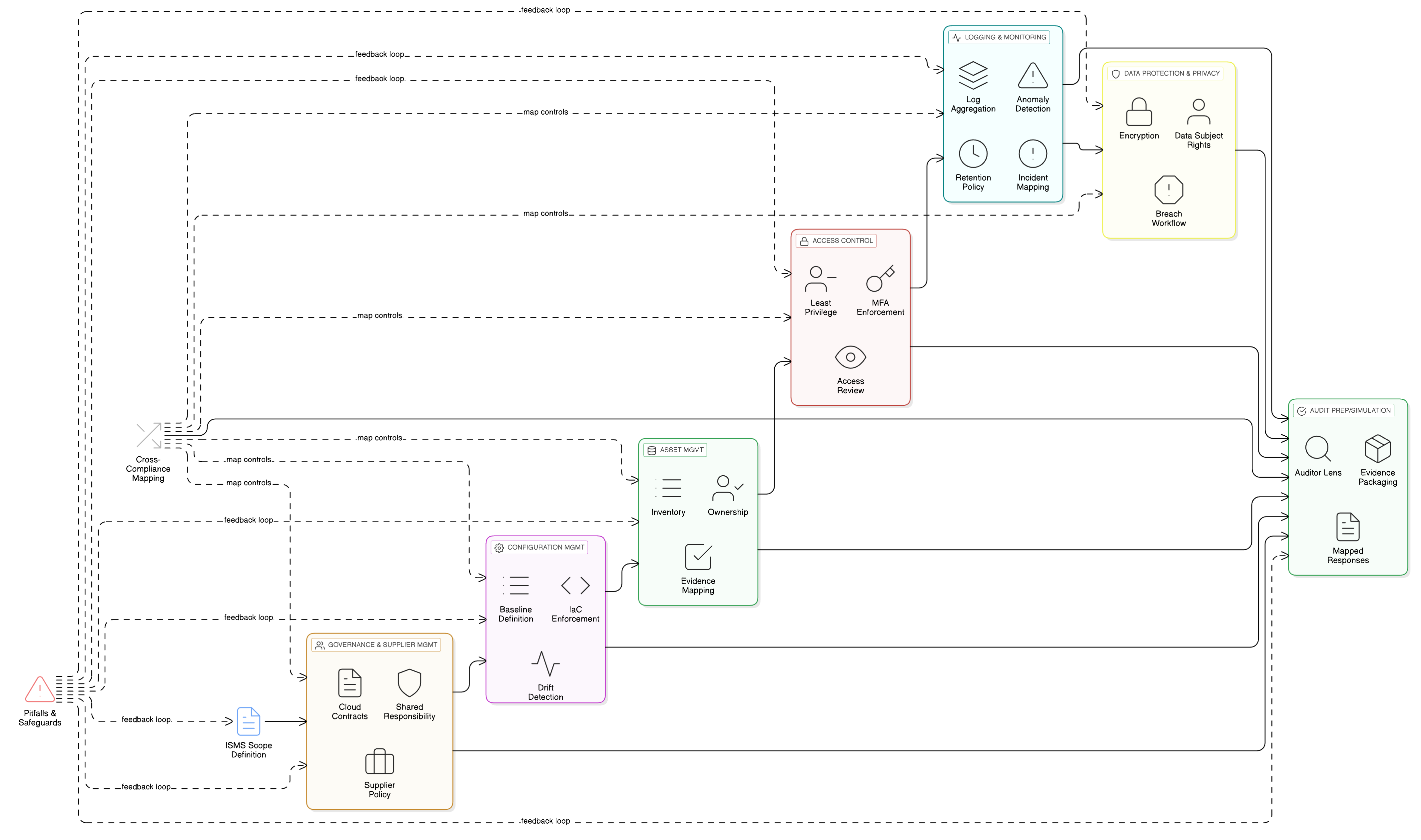
Renforcer le noyau : contrôle d’accès granulaire pour les pipelines IA
Les fonctionnalités LLM reposent sur vos entrepôts de données, journaux et pipelines d’entraînement les plus sensibles. Un contrôle d’accès robuste est donc essentiel à la conformité GDPR. Les contrôles ISO/IEC 27001:2022 8.3 et 8.2 constituent les piliers de votre dispositif de défense. Le Zenith Controls: The Cross-Compliance Guide de Clarysec fournit le plan de mise en œuvre efficace.
ISO/IEC 27001:2022 Contrôle 8.3 : restriction d’accès à l’information
Ce contrôle vise à garantir que l’accès à l’information est accordé selon un strict principe du « besoin d’en connaître ». Pour un environnement d’entraînement LLM, cela signifie que vos data scientists, ingénieurs ML et processus automatisés ne doivent accéder qu’aux données spécifiques dont ils ont besoin, et à rien d’autre.
Comme le détaille Zenith Controls, ce contrôle est étroitement lié à d’autres contrôles :
- Articulation avec 5.9 (Inventaire des informations et autres actifs associés) et 5.12 (Classification de l’information) : vous ne pouvez pas restreindre l’accès si vous ne savez pas quelles données vous détenez ni quel est leur niveau de sensibilité. Votre jeu de données d’entraînement IA doit être inventorié et classé comme hautement confidentiel, selon un processus régi par votre Politique de classification et d’étiquetage des données pour PME.
- Articulation avec 8.5 (Authentification sécurisée) : les restrictions d’accès sont inutiles sans vérification d’identité robuste. Chaque utilisateur et chaque compte de service accédant aux données d’entraînement doit être authentifié de manière sécurisée, de préférence avec une authentification multifacteur.
ISO/IEC 27001:2022 Contrôle 8.2 : droits d’accès à privilèges
Vos ingénieurs ML, ingénieurs SRE et data scientists ont besoin d’accès élevés. Ces comptes à privilèges sont les « clés du royaume » et des cibles prioritaires. Le contrôle 8.2 impose une gestion extrêmement stricte de ces droits.
Selon Zenith Controls, les principales relations sont les suivantes :
- Articulation avec 8.15 (Journalisation) et 8.16 (Activités de surveillance) : toute activité à privilèges doit être journalisée et surveillée. Si un data scientist tente soudainement d’exporter l’intégralité du jeu de données d’entraînement, une alerte doit être déclenchée immédiatement.
- Articulation avec 6.7 (Télétravail) : si votre équipe IA travaille à distance, ses accès à privilèges doivent transiter par des canaux sécurisés et surveillés, comme un VPN avec des contrôles de session stricts.
Le point de vue de l’auditeur : comment prouver que vos contrôles IA fonctionnent
Mettre en œuvre des contrôles ne représente que la moitié du travail. Vous devez prouver leur efficacité. Des auditeurs formés à différents référentiels rechercheront des éléments de preuve spécifiques.
| Type d’auditeur | Référentiel principal | Ce qui sera demandé (éléments de preuve) |
|---|---|---|
| Auditeur ISO/IEC 27001 | ISO/IEC 27007:2020 | Montrez-moi votre politique de contrôle d’accès pour l’environnement d’entraînement IA. Fournissez les journaux issus de votre processus de revue des accès sur les 12 derniers mois. Démontrez comment un nouvel ingénieur ML reçoit un accès fondé sur le moindre privilège. |
| Auditeur COBIT | COBIT 2019 (DSS05) | J’ai besoin de voir votre matrice de contrôle d’accès basé sur les rôles (RBAC) pour l’équipe data science. Fournissez les rapports de vos outils de surveillance montrant les alertes relatives aux tentatives d’accès anormales au lac de données d’entraînement. |
| Évaluateur NIST | NIST SP 800-53A (AC-3, AC-6) | Examinons la configuration système des serveurs hébergeant les données d’entraînement. Je souhaite vérifier que les listes de contrôle d’accès (ACL) appliquent techniquement les politiques que vous avez documentées. Montrez-moi les éléments de preuve démontrant que les sessions à privilèges sont interrompues après une période d’inactivité. |
| Auditeur GDPR/Protection des données | ISO/IEC 27701:2021 | Fournissez votre analyse d’impact relative à la protection des données (DPIA) pour la fonctionnalité IA. Montrez-moi les registres de consentement des personnes concernées dont les informations figurent dans le jeu d’entraînement. Comment traitez-vous une demande de « droit à l’effacement » portant sur des données incluses dans un modèle entraîné ? |
Une mise en œuvre correcte des contrôles 8.2 et 8.3 produit des bénéfices étendus. Zenith Controls montre une correspondance directe avec les exigences du GDPR (Articles 5, 25, 32), de NIS2 (Article 21), de DORA (Article 10) et de NIST SP 800-53 (AC-3, AC-6), ce qui permet de satisfaire plusieurs référentiels au moyen d’une mise en œuvre de contrôle unique et cohérente.
Le paradoxe du « droit à l’oubli » : gérer les droits des personnes concernées dans l’IA
L’Article 17 du GDPR, le « droit à l’effacement », crée un défi technique spécifique pour l’IA. Comment supprimer les données d’une personne une fois qu’elles ont servi à entraîner un modèle massif et complexe ? Il est souvent techniquement impossible de faire « désapprendre » à un modèle des points de données précis.
C’est ici que vos choix de conception initiaux deviennent votre meilleure défense. Il n’existe pas de réponse parfaite unique, mais les stratégies pratiques et défendables incluent :
- Pseudonymisation en premier : si les données d’entraînement ont été correctement pseudonymisées, le lien avec la personne est déjà rompu dans le corpus d’entraînement. Vous pouvez alors supprimer les données à caractère personnel des systèmes sources ainsi que le lien dans la table des clés de pseudonymisation.
- Ségrégation des données pour l’entraînement : lorsque c’est possible, conservez des jeux de données d’entraînement distincts par tenant. Cela rend la suppression des données réalisable sans réentraîner l’ensemble de votre univers de modèles.
- Réentraînement planifié des modèles : votre DPIA doit traiter ce risque. La mesure d’atténuation peut consister à s’engager à réentraîner périodiquement le modèle à partir de zéro au moyen d’un jeu de données actualisé excluant les données des utilisateurs ayant demandé l’effacement.
La section du Zenith Blueprint consacrée à la suppression de l’information (étape 20, couvrant le contrôle 8.10) relie explicitement cette capacité technique aux Articles 17 et 5(1)(e) du GDPR, en exigeant des processus vérifiables pour effacer les données de manière sécurisée lorsqu’elles ne sont plus nécessaires.
Sécuriser votre chaîne d’approvisionnement IA : développement externalisé et LLM tiers
Peu d’entreprises SaaS développent tout en interne. Vous pouvez utiliser l’API LLM d’un hyperscaler ou contractualiser avec un partenaire de développement externalisé. Cela introduit des risques liés à la chaîne d’approvisionnement.
Le Zenith Blueprint, à l’étape 22 sur le développement externalisé, met en évidence ce risque et son lien avec les Articles 28 et 32 du GDPR. Comme l’indique le blueprint :
« Un domaine souvent négligé est la formation et sensibilisation. Vos développeurs externalisés peuvent être compétents, mais sont-ils formés aux pratiques de codage sécurisé ? Connaissent-ils vos politiques ? Ont-ils conscience des référentiels de conformité que vous devez respecter, GDPR, DORA, NIS2… ? »
Pour tout fournisseur LLM externe ou partenaire de développement, vos diligences préalables sont essentielles. Votre contrat de sous-traitance doit couvrir explicitement les finalités de traitement liées à l’IA, les catégories de données et les interdictions faites au fournisseur d’utiliser vos données pour l’entraînement de ses propres modèles. Vous devez vérifier qu’il met en œuvre des mesures de sécurité alignées sur l’Article 32 du GDPR. Votre chaîne d’approvisionnement IA doit être aussi vérifiable que votre infrastructure centrale.
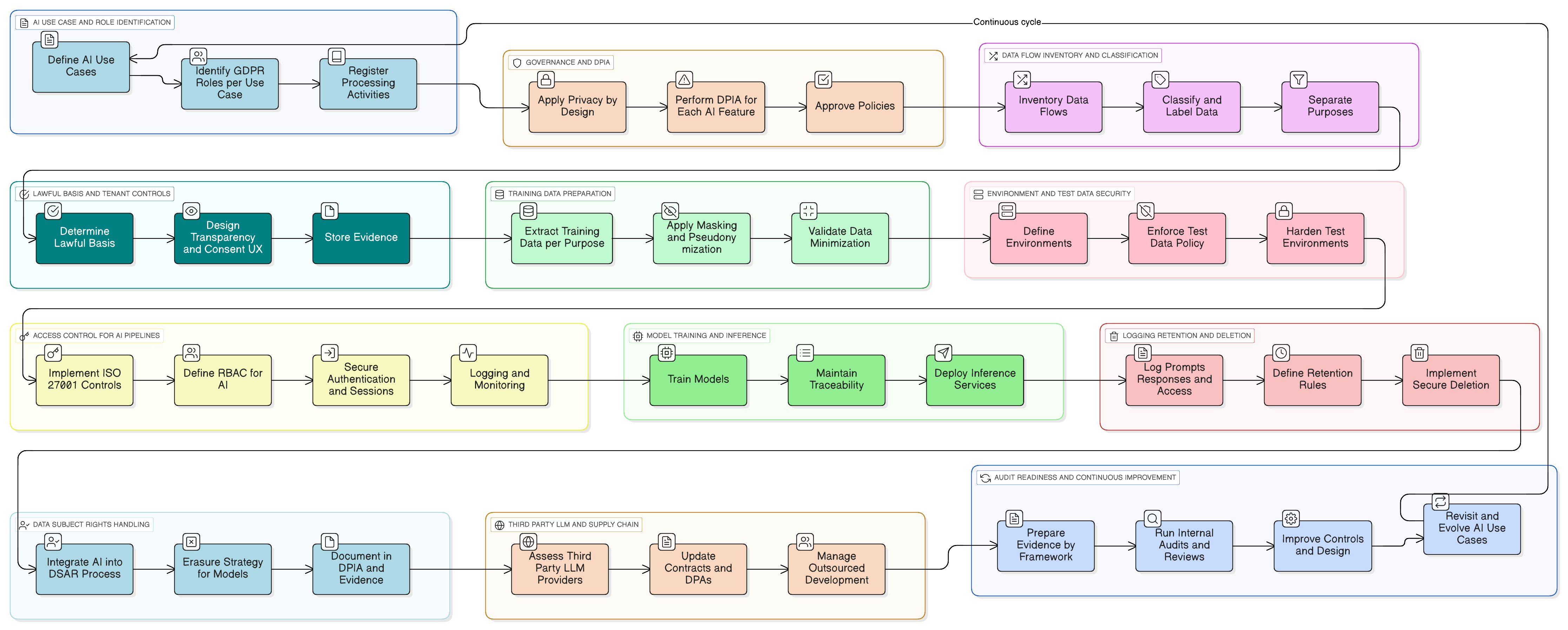
De la théorie à la pratique : exemple concret d’une fonctionnalité IA prête pour le GDPR
Rendons cela concret. Imaginez que vous ajoutiez un assistant IA qui résume les conversations du support client, suggère des projets de réponse et apprend à partir des tickets précédents pour s’améliorer.
Voici un schéma de mise en œuvre opérationnel utilisant le kit d’outils de Clarysec :
- Classification et étiquetage : tous les tickets de support sont classés « Confidentiel » au titre de votre Politique de classification et d’étiquetage des données pour PME, en cohérence avec les obligations de traitement des données prévues par GDPR et DORA.
- Masquage avant le LLM : un service de masquage intercepte les données avant leur envoi au LLM. Il supprime ou remplace les noms, adresses électroniques, numéros de téléphone et autres données à caractère personnel. L’ensemble de ce processus est régi par la Politique de masquage des données et de pseudonymisation, avec validation de la méthodologie par le DPO.
- Contrôles d’accès aux prompts et aux journaux : seuls les rôles autorisés, par exemple le propriétaire produit IA, peuvent accéder aux journaux de prompts bruts. Cela est mis en œuvre au moyen du contrôle ISO 27001:2022 8.3 (restriction d’accès à l’information) pour les accès généraux et du contrôle 8.2 (droits d’accès à privilèges) pour toute visibilité de niveau administrateur, comme le décrit Zenith Controls.
- Consentement pour le corpus de données d’entraînement : le pipeline d’entraînement n’ingère que les données masquées. Un paramètre de configuration au niveau du tenant, « Autoriser l’utilisation de mes données masquées pour l’amélioration du modèle IA global : Oui/Non », est fourni et réglé par défaut sur « Non ».
- Conservation et suppression : les journaux de prompts ne sont conservés que pendant la durée nécessaire. Lorsqu’un tenant désactive la fonctionnalité ou met fin à son contrat, un workflow est déclenché afin de supprimer ou d’anonymiser de manière sécurisée les journaux IA et les entrées d’entraînement associés, conformément au processus décrit dans votre mise en œuvre du Zenith Blueprint pour le contrôle 8.10 (suppression de l’information).
Lorsque les auditeurs arrivent, vous pouvez leur présenter les diagrammes de flux de données de la fonctionnalité, les politiques spécifiques qui l’encadrent et les éléments de preuve techniques issus de vos systèmes, journaux d’accès, configurations de tâches et workflows d’effacement. Vous démontrez la conformité en action.
Votre plan d’action : de l’expérimentation ad hoc à une IA prête pour l’audit
Vous n’avez pas besoin de déconstruire votre produit, mais vous devez adopter une approche structurée et défendable. Voici un plan d’action concis :
- Inventorier les cas d’usage IA et les flux de données : identifiez chaque endroit où des LLM sont utilisés : fonctionnalités orientées clients, outils internes et expérimentations. Cartographiez quelles données vont où, sur quelle base légale et avec quels accès. Utilisez la phase de fondation du Zenith Blueprint pour garantir que votre registre juridique couvre toutes les exigences GDPR, NIS2 et DORA liées à l’IA.
- Établir la gouvernance en premier : avant de construire, réalisez une analyse d’impact relative à la protection des données (DPIA) pour chaque fonctionnalité IA. Documentez sa finalité, sa base légale et ses risques. Déployez des politiques de référence comme la Politique de protection des données et de la vie privée pour PME et la Politique de sécurité de l’information pour PME.
- Verrouiller les données et les accès : mettez en œuvre des contrôles techniques robustes. Adoptez la Politique de masquage des données et de pseudonymisation ainsi que la Politique relative aux données de test et aux environnements de test pour PME. Utilisez Zenith Controls pour mettre en œuvre et documenter les contrôles ISO 27001:2022 8.2 et 8.3 pour tous les entrepôts de données et pipelines IA.
- Intégrer les droits des personnes concernées dans les workflows IA : mettez à jour vos procédures relatives aux demandes d’exercice des droits des personnes concernées et à la suppression afin d’y inclure les données liées à l’IA. Documentez votre stratégie de traitement des demandes d’effacement dans le contexte des modèles entraînés, en mettant l’accent sur la pseudonymisation et les calendriers de réentraînement des modèles.
- Mettre sous contrôle votre chaîne d’approvisionnement IA : mettez à jour les contrats de sous-traitance avec les fournisseurs LLM tiers et les développeurs externalisés. Veillez à ce que les contrats interdisent explicitement toute utilisation non autorisée des données et imposent des mesures de sécurité robustes. Vérifiez que les équipes externes sont formées à vos politiques de traitement des données.
Innover avec confiance
L’intersection entre IA et GDPR constitue la nouvelle frontière de la conformité. En adoptant une approche structurée et fondée sur les risques, vous pouvez exploiter le potentiel transformateur de l’intelligence artificielle sans compromettre votre engagement en matière de protection des données et de vie privée.
Clarysec fournit la carte, les outils et l’expertise pour vous guider dans ce parcours. En utilisant :
- Zenith Blueprint: An Auditor’s 30-Step Roadmap pour une mise en œuvre progressive de contrôles alignés sur le GDPR pour l’IA ;
- Zenith Controls: The Cross-Compliance Guide pour unifier les contrôles ISO 27001:2022 avec les exigences GDPR, NIS2, DORA et NIST ;
- des politiques prêtes pour la production, comme la Politique de protection des données et de la vie privée pour PME, la Politique de masquage des données et de pseudonymisation et la Politique relative aux données de test et aux environnements de test pour PME, afin de formaliser vos règles et de répondre aux attentes des auditeurs.
Vous pouvez passer d’expérimentations IA ad hoc à une capacité IA compatible avec les exigences d’audit, qui inspire confiance aux autorités de contrôle, aux auditeurs et aux clients grands comptes exigeants. Vous pouvez continuer à innover avec des LLM tout en dormant tranquille.
Si vous planifiez ou exploitez des fonctionnalités IA dans votre produit SaaS, l’étape suivante est simple. Téléchargez des exemples de nos kits d’outils ou réservez une démonstration pour voir comment Clarysec peut vous aider à construire un programme IA non seulement puissant, mais aussi démontrablement privé et sécurisé dès la conception.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council