Cartographie de la réponse aux incidents selon NIST pour les audits 2026
Il est 07 h 42 un mardi. Anya, RSSI d’une plateforme fintech en forte croissance, voit apparaître la première alerte : déplacement impossible sur un compte administrateur. Une série de tentatives de connexion échouées suit, puis une session réussie depuis un appareil non géré. Cinq minutes plus tard, le support client signale que les utilisateurs ne peuvent plus accéder à un flux de travail SaaS critique. À 08 h 10, le tableau de bord cloud affiche des appels API anormaux visant un compartiment de stockage susceptible de contenir des données à caractère personnel.
L’équipe de sécurité réagit rapidement. Le SIEM déclenche une alerte, l’ingénieur cloud révoque une session et le responsable de service commence à rétablir l’accès. Mais la véritable crise n’est pas seulement technique. Elle relève de la gouvernance.
Anya doit répondre à trois questions avant la fin de la première heure.
Premièrement, s’agit-il d’un incident de sécurité de l’information, d’une violation de données à caractère personnel, d’un incident significatif NIS2 ou d’un incident majeur lié aux TIC au sens de DORA ?
Deuxièmement, qui doit être informé, dans quel délai et avec quels éléments de preuve ?
Troisièmement, l’organisation peut-elle prouver que son processus de réponse aux incidents a fonctionné comme prévu ?
C’est à ce moment que de nombreuses organisations découvrent la différence entre disposer d’un plan de réponse aux incidents et disposer d’un système de gouvernance de la réponse aux incidents. La réponse aux incidents selon NIST SP 800-61 et NIST CSF 2.0 ne relève plus uniquement des playbooks du SOC. En 2026, elle est directement liée à la responsabilité du conseil d’administration, aux audits ISO/IEC 27001:2022, à la notification progressive NIS2, à la résilience opérationnelle DORA, aux décisions relatives aux violations de données à caractère personnel au titre du GDPR et à la responsabilité des fournisseurs.
Les programmes les plus robustes ne créent pas des parcours de réponse distincts pour chaque référentiel. Ils utilisent NIST CSF 2.0 comme carte opérationnelle, ISO/IEC 27001:2022 comme colonne vertébrale du système de management, et un modèle unique d’éléments de preuve capable de soutenir simultanément NIS2, DORA et GDPR. C’est l’approche Clarysec : des décisions pilotées par les politiques, des processus éprouvés par exercices sur table, des dossiers d’éléments de preuve prêts pour les autorités de régulation et une cartographie inter-référentiels au moyen du Zenith Blueprint : feuille de route en 30 étapes pour l’auditeur et de Zenith Controls : le guide de conformité croisée.
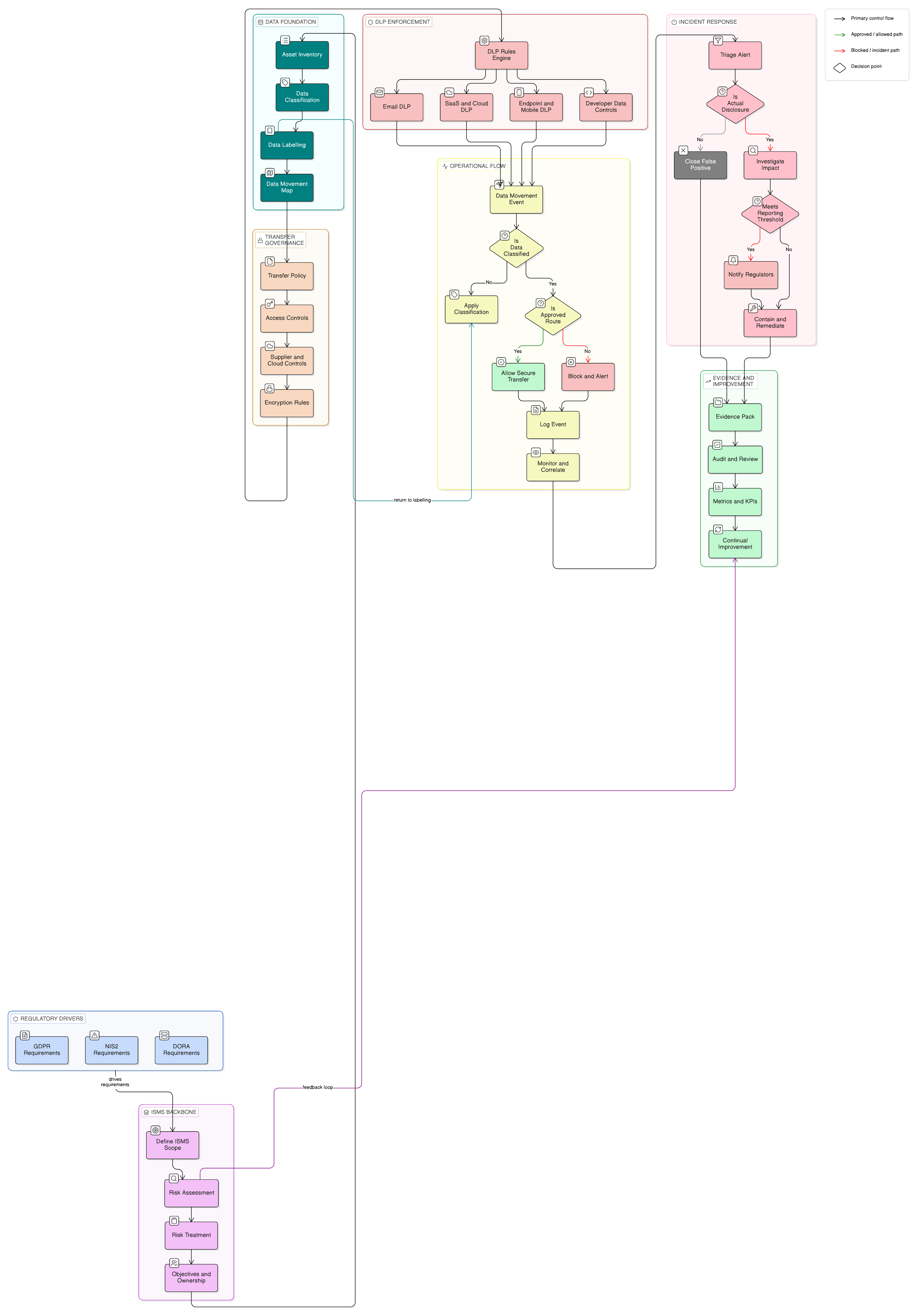
Le problème de 2026 : un incident, plusieurs régimes de responsabilité
L’incident auquel Anya est confrontée n’est pas un seul problème de conformité. Il correspond à plusieurs chaînes de décision qui se recoupent.
Si l’organisation fournit des services d’informatique en nuage, des services SaaS, des services managés, des services de sécurité managés, du DNS, des services de centre de données, des services de confiance ou d’autres services d’infrastructure numérique, NIS2 peut s’appliquer. La classification comme entité essentielle ou importante dépend du secteur, de la taille et de la transposition nationale, mais l’orientation est claire : la gestion des incidents est désormais une responsabilité de direction réglementée.
Si l’organisation est une entité financière, DORA peut constituer le principal référentiel de résilience opérationnelle. DORA s’applique depuis le 17 janvier 2025 et couvre la gestion des risques liés aux TIC, la notification des incidents majeurs liés aux TIC, les tests de résilience opérationnelle, le partage d’informations, le risque lié aux tiers prestataires de services TIC et la supervision des prestataires tiers critiques de services TIC. Pour les entités financières couvertes qui relèvent également de NIS2, DORA joue le rôle de cadre sectoriel pour les obligations qui se recoupent en matière de risques TIC et de notification d’incidents.
Si des données à caractère personnel ont été consultées, modifiées, perdues, détruites ou divulguées, le GDPR entre dans l’arbre de décision de la réponse aux incidents. Le GDPR définit une violation de données à caractère personnel comme une violation de sécurité entraînant, de manière accidentelle ou illicite, la destruction, la perte, l’altération, la divulgation non autorisée de données à caractère personnel ou l’accès non autorisé à celles-ci. Le GDPR impose également une obligation de responsabilité : le responsable du traitement doit être en mesure de démontrer la conformité aux principes de traitement, notamment l’intégrité et la confidentialité.
Si l’entreprise est certifiée ISO/IEC 27001:2022, ou se prépare à la certification, l’incident devient un élément de preuve du SMSI. Les auditeurs examineront le domaine d’application, les obligations légales, les rôles, le traitement des risques, la sélection des mesures de sécurité, l’exécution opérationnelle, les informations documentées, les retours d’expérience et l’amélioration continue. Les clauses 4.1 à 4.4 d’ISO/IEC 27001:2022 exigent que le SMSI reflète le contexte, les parties intéressées, les obligations, le domaine d’application et les interactions entre processus. Les clauses 5.1 à 5.3 exigent le leadership, la responsabilité et l’attribution des responsabilités. Les clauses 6.1.1 à 6.1.3 exigent l’appréciation des risques de sécurité de l’information, leur traitement et une Déclaration d’applicabilité (SoA). Les clauses 8.1 à 8.3 exigent une exploitation maîtrisée, des éléments de preuve montrant que les processus ont été exécutés comme prévu, le contrôle des processus externalisés et la mise en œuvre du traitement.
Le problème métier n’est pas l’absence de référentiels. C’est l’absence d’un modèle opérationnel unique qui transforme ces référentiels en décisions prises à temps et en éléments de preuve fiables.
Utiliser NIST CSF 2.0 comme langage commun
NIST CSF 2.0 est utile parce qu’il donne à la direction, à la sécurité, au juridique, à la protection des données, aux opérations et aux fournisseurs un langage commun pour décrire les résultats de cybersécurité. Sa fonction GOVERN est particulièrement importante pour la réponse aux incidents, car elle oblige les organisations à traiter la supervision, les politiques, la stratégie de risque, les rôles et les risques liés à la chaîne d’approvisionnement avant le début de la crise.
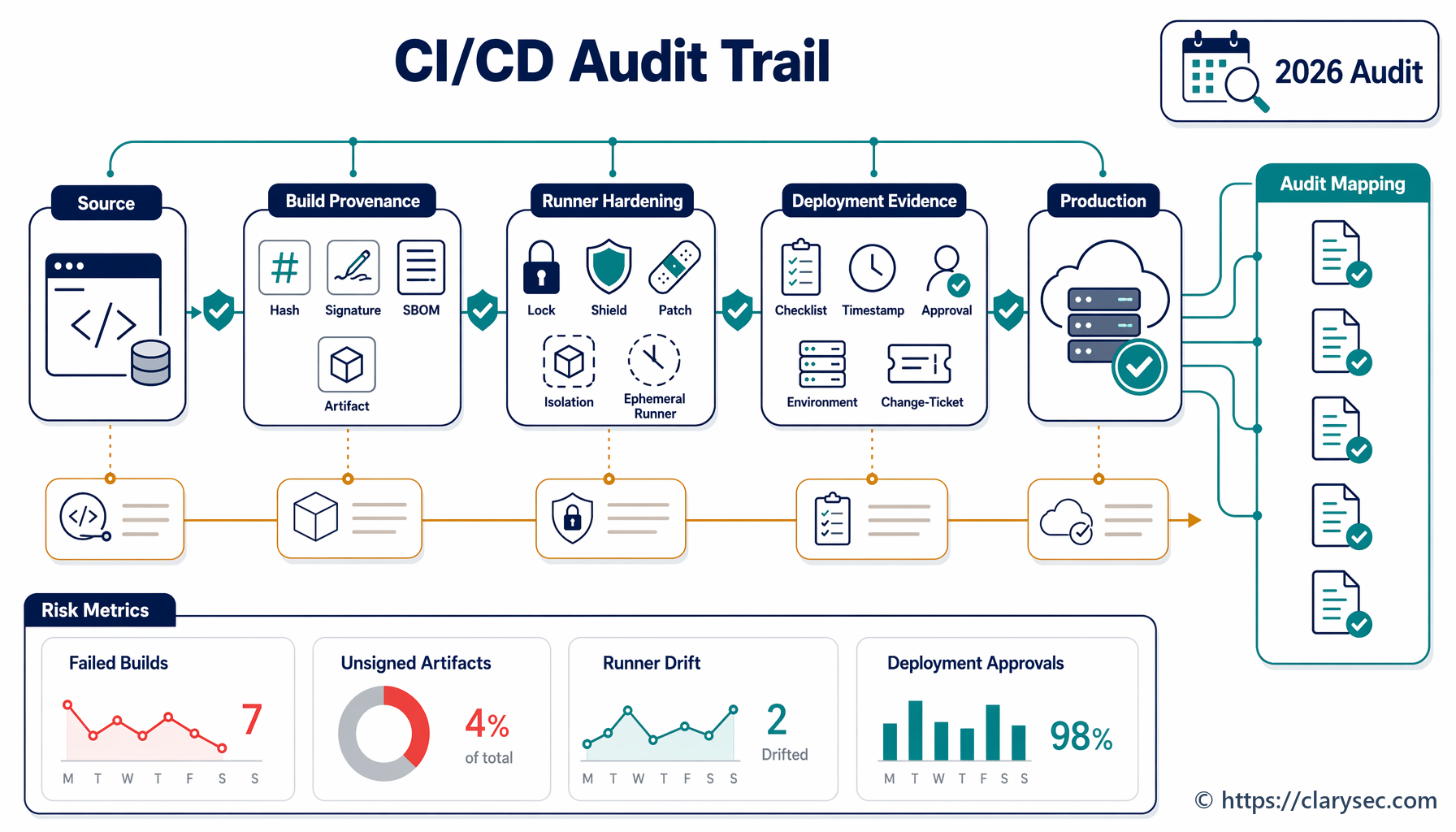
Pour la réponse aux incidents, CSF 2.0 relie la gouvernance au cycle de vie opérationnel : IDENTIFY, PROTECT, DETECT, RESPOND et RECOVER. Cette structure permet de transformer un incident bruyant en flux d’éléments de preuve maîtrisé.
| Question de réponse aux incidents | Domaine de résultats CSF 2.0 | Éléments de preuve de conformité produits |
|---|---|---|
| Qui porte la décision ? | GOVERN, notamment GV.RR, GV.OV et GV.PO | RACI, enregistrement du responsable de l’incident, points de situation à la direction, notifications au conseil d’administration |
| Quels actifs et services sont affectés ? | IDENTIFY, notamment la visibilité sur les actifs et les risques | Inventaire des actifs, cartographie des services, inventaire des données, liste des fournisseurs critiques |
| Quels contrôles ont échoué ou fonctionné ? | PROTECT, notamment les accès, la sécurité des données, la configuration et les sauvegardes | Journaux MFA, enregistrements d’accès à privilèges, enregistrements de sauvegarde, configurations de référence |
| Comment l’événement a-t-il été détecté ? | DETECT, notamment DE.CM et DE.AE | Alertes SIEM, alertes EDR, journaux cloud, notes de corrélation, enregistrement de déclaration |
| Comment a-t-il été traité ? | RESPOND, notamment RS.MA, RS.AN, RS.CO et RS.MI | Ticket d’incident, classification de gravité, chronologie, journal des décisions, actions de confinement |
| Comment le service a-t-il été rétabli ? | RECOVER, notamment RC.RP et RC.CO | Exécution du rétablissement, validation des sauvegardes, éléments de preuve de service rétabli, communications, rapport de clôture |
Les profils organisationnels CSF 2.0 rendent cette approche opérationnelle. Un Current Profile montre la capacité réelle de réponse aux incidents de l’organisation, y compris les lacunes, les ambiguïtés et les contournements. Un Target Profile définit l’état cible, par exemple une classification de gravité en une heure, des décisions de notification documentées, la préservation des éléments de preuve, la coordination avec les tiers et des dossiers de notification prêts pour les autorités de régulation.
Pour la fintech d’Anya, le Current Profile a mis en évidence un schéma classique : des outils solides, mais une gouvernance décisionnelle faible. Le Target Profile s’est concentré sur des résultats CSF 2.0 concrets, notamment :
- RS.MA-01, le plan de réponse aux incidents est exécuté en coordination avec les tiers concernés dès qu’un incident est déclaré.
- RS.MA-02, les signalements d’incident sont triés et validés.
- RS.MA-03, les incidents sont catégorisés et priorisés.
- RS.MA-04, les incidents sont escaladés ou élevés au niveau requis.
- RS.AN-03, une analyse est réalisée pour établir ce qui s’est produit pendant l’incident et en déterminer la cause racine.
- RS.AN-06, les actions réalisées pendant une investigation sont consignées, et l’intégrité ainsi que la provenance des enregistrements sont préservées.
- RS.AN-07, les données et métadonnées d’incident sont collectées, et leur intégrité ainsi que leur provenance sont préservées.
- RS.CO-02, les parties prenantes internes et externes sont notifiées des incidents.
- RS.MI-01, les incidents sont confinés.
- RS.MI-02, les incidents sont éradiqués.
- RC.RP-03, l’intégrité des sauvegardes et des autres actifs de restauration est vérifiée avant leur utilisation pour la restauration.
Un référentiel seul ne constitue pas un programme auditable. Les résultats doivent être intégrés dans un système de management ; c’est là qu’ISO/IEC 27001:2022 fournit la colonne vertébrale.
Ancrer la réponse aux incidents dans ISO/IEC 27001:2022
NIST fournit un langage pratique pour la gestion des incidents. ISO/IEC 27001:2022 fournit la discipline opérationnelle attendue par les auditeurs. Le SMSI transforme la réponse aux incidents, d’un ensemble de playbooks, en un processus gouverné avec domaine d’application, responsabilité, traitement des risques, évaluation de la performance et amélioration.
Le groupe de contrôles de l’Annexe A le plus pertinent est le suivant :
| Contrôle de l’Annexe A ISO/IEC 27001:2022 | Nom du contrôle | Objectif pour la réponse aux incidents |
|---|---|---|
| A.5.24 | Planification et préparation de la gestion des incidents de sécurité de l’information | Établit le plan, les rôles, l’escalade et le modèle de communication |
| A.5.25 | Évaluation des événements de sécurité de l’information et prise de décision | Définit les critères de triage, de classification et de décision |
| A.5.26 | Réponse aux incidents de sécurité de l’information | Pilote le confinement, l’éradication, le rétablissement et les communications |
| A.5.27 | Enseignements tirés des incidents de sécurité de l’information | Transforme les retours d’expérience en actions correctives et en amélioration |
| A.5.28 | Collecte des éléments de preuve | Préserve la fiabilité, la provenance et l’utilisabilité juridique des éléments de preuve |
Le guide Zenith Controls de Clarysec cartographie ces références de contrôles ISO/IEC 27002:2022 avec d’autres normes, les attentes d’audit et les obligations de conformité associées. Il ne s’agit pas d’un référentiel de contrôles distinct. C’est un guide de conformité croisée qui aide les organisations à comprendre comment les mêmes activités de contrôle répondent à plusieurs besoins d’assurance.
Le Zenith Blueprint, phase Controls in Action, étape 23, rend opérationnelle l’ossature de la réponse aux incidents :
Veillez à disposer d’un plan de réponse aux incidents à jour (5.24), couvrant la préparation, l’escalade, la réponse et la communication. Définissez ce qui constitue un événement de sécurité notifiable (5.25) et la manière dont le processus décisionnel est déclenché et documenté. Sélectionnez un événement récent ou réalisez un exercice sur table pour valider votre plan. Capturez et consignez toutes les décisions, tous les rôles et toutes les communications (5.26), puis mettez à jour le plan avec les enseignements tirés (5.27). Confirmez que des procédures sont en place pour préserver les éléments de preuve forensiques (5.28), notamment les instantanés de journaux, les sauvegardes et l’isolement sécurisé des systèmes affectés.
Ce paragraphe constitue le pont pratique entre la gestion des incidents NIST et les éléments de preuve d’audit. Préparer la capacité, classifier l’événement, répondre de manière maîtrisée, tirer les enseignements et préserver les éléments de preuve.
Intégrer l’évaluation du caractère notifiable dès la première heure
Les programmes de réponse aux incidents échouent souvent au cours de la première heure, non parce que les analystes manquent de compétences, mais parce que l’organisation n’a pas défini qui décide, quand la gravité est attribuée, quels éléments de preuve sont préservés et quand les déclencheurs juridiques sont vérifiés.
Pour les PME, la Politique de réponse aux incidents pour PME de Clarysec fixe une attente claire en matière de gouvernance :
Le directeur général, avec l’appui du prestataire informatique, doit classifier tous les incidents par gravité dans l’heure suivant leur notification.
Il s’agit d’une exigence forte. Elle ne signifie pas que tous les faits sont connus dans l’heure. Elle signifie que l’organisation doit documenter une gravité initiale, consigner les incertitudes et déclencher l’escalade alors même que les faits sont encore en cours d’établissement.
La même politique impose également d’intégrer les délais légaux dans le processus :
Les délais de réponse, notamment les obligations de restauration des données et de notification, doivent être documentés et alignés sur les exigences légales, telles que l’obligation de notification des violations de données à caractère personnel dans les 72 heures prévue par le GDPR.
Pour les environnements d’entreprise, la Politique de réponse aux incidents de Clarysec ancre un modèle de réponse plus formel :
L’organisation doit maintenir un cadre de réponse aux incidents centralisé et à plusieurs niveaux, aligné sur ISO/IEC 27035, composé des phases de réponse définies suivantes :
La politique d’entreprise intègre également des références de délais inter-réglementaires à la clause 6.4.1 :
GDPR Article 33 (notification dans les 72 heures à l’autorité de contrôle)
NIS2 Article 23 (notification dans les 24 heures suivant la prise de connaissance de l’incident)
DORA Article 17 (notification des incidents graves liés aux TIC)
C’est ce qui distingue un playbook technique d’un cadre de réponse aux incidents prêt pour la gouvernance. Les circuits de notification légale et réglementaire ne s’improvisent pas pendant une crise. Ils sont déclenchés par des points de classification et de décision prédéfinis.
Intégrer la notification NIS2 dans le processus d’incident
NIS2 impose aux entités essentielles et importantes de notifier sans retard injustifié au CSIRT ou à l’autorité compétente les incidents significatifs affectant la fourniture de services. Un incident significatif comprend un incident ayant causé, ou susceptible de causer, une perturbation opérationnelle grave ou une perte financière, ou ayant affecté, ou susceptible d’affecter, d’autres personnes en causant des dommages matériels ou immatériels considérables.
Le modèle de notification est progressif.
| Étape NIS2 | Délai | Éléments de preuve que le processus doit produire |
|---|---|---|
| Alerte précoce | Dans les 24 heures suivant la prise de connaissance | Déclaration d’incident, activité malveillante suspectée, vérification de l’impact transfrontalier, première vision du service affecté |
| Notification d’incident | Dans les 72 heures | Évaluation de gravité, analyse d’impact, indicateurs de compromission lorsqu’ils sont disponibles, journal des incertitudes |
| Rapports intermédiaires | Sur demande | Points de situation, actions de confinement, état du rétablissement, communications avec l’autorité de régulation |
| Rapport final | Dans le mois suivant la notification d’incident | Gravité et impact, menace probable ou cause racine, mesures d’atténuation, impact transfrontalier |
| Rapport d’avancement si l’incident est toujours en cours | Si l’incident est toujours en cours au moment du rapport final | Rapport d’avancement, puis rapport final dans le mois suivant le traitement |
NIS2 Article 21 exige également des mesures techniques, opérationnelles et organisationnelles appropriées et proportionnées. Le socle requis comprend l’analyse des risques, la gestion des incidents, la continuité d’activité, la sécurité de la chaîne d’approvisionnement, le développement sécurisé, la gestion des vulnérabilités, l’évaluation de l’efficacité, l’hygiène cyber et la formation, la cryptographie, la sécurité RH, le contrôle d’accès, la gestion des actifs et, le cas échéant, l’authentification multifacteur et les communications sécurisées.
NIS2 Article 20 fait entrer les organes de direction dans la chaîne de responsabilité. Ils doivent approuver les mesures de gestion des risques de cybersécurité et superviser leur mise en œuvre. Pour la réponse aux incidents, cela signifie que les comptes rendus du conseil, les approbations de la direction, les enregistrements de formation et les éléments de preuve d’escalade ne sont pas de simples livrables administratifs facultatifs. Ils font partie de la défendabilité réglementaire.
Les sanctions renforcent l’urgence. En cas de manquement à Article 21 ou Article 23, les entités essentielles doivent être exposées à des amendes maximales d’au moins 10 millions d’euros ou 2 % du chiffre d’affaires annuel mondial total, le montant le plus élevé étant retenu. Les entités importantes doivent être exposées à des amendes maximales d’au moins 7 millions d’euros ou 1,4 % du chiffre d’affaires annuel mondial total, le montant le plus élevé étant retenu.
La leçon pratique est simple : si l’heure de prise de connaissance, les critères de gravité, l’escalade et les décisions de notification ne sont pas consignés, le sujet ne relève plus seulement de la maturité de la réponse aux incidents. Il devient un problème d’éléments de preuve réglementaires.
Traiter la gestion des incidents DORA comme de la résilience opérationnelle
DORA change la discussion pour les entités financières, car la gestion des incidents fait partie de la résilience opérationnelle numérique, et non seulement des opérations de sécurité.
Article 5 impose à l’organe de direction de définir, approuver et superviser le cadre de gestion des risques liés aux TIC, et d’en demeurer responsable. Article 6 étend ce cadre à un système structuré de gestion des risques TIC. Article 17 impose aux entités financières de définir, établir et mettre en œuvre un processus de gestion des incidents liés aux TIC afin de détecter, gérer et notifier ces incidents. Ce processus doit enregistrer les incidents liés aux TIC et les cybermenaces significatives, identifier et traiter les causes racines, utiliser des indicateurs d’alerte précoce, classifier les incidents selon la priorité, la gravité et la criticité des services affectés, attribuer les rôles et responsabilités, établir la communication et l’escalade, notifier les clients et les médias lorsque cela est requis, signaler au moins les incidents majeurs à la direction générale, informer l’organe de direction et maintenir des procédures de réponse destinées à atténuer l’impact et à rétablir des opérations sécurisées.
Article 18 exige une classification fondée sur des critères tels que les clients ou contreparties affectés, les transactions, l’impact réputationnel, la durée et l’indisponibilité, l’étendue géographique, les pertes de données affectant la disponibilité, l’authenticité, l’intégrité ou la confidentialité, la criticité des services affectés et l’impact économique. Article 19 impose la notification des incidents majeurs liés aux TIC à l’autorité compétente, permet la notification volontaire des cybermenaces significatives et exige la notification des clients sans retard injustifié lorsqu’un incident majeur lié aux TIC affecte les intérêts financiers des clients.
Pour la fintech d’Anya, cela signifie que l’enregistrement de l’incident doit aller au-delà d’une chronologie SOC. Il doit comprendre :
- Le service affecté et sa criticité.
- Les clients, contreparties ou transactions affectés.
- La durée d’indisponibilité et l’étendue géographique.
- La perte de données ou l’impact sur l’intégrité.
- L’impact économique.
- La visibilité de l’organe de direction.
- La décision de notification aux clients.
- La clôture de la cause racine.
- Le rétablissement d’opérations sécurisées.
- L’implication du fournisseur et les éléments de preuve contractuels.
DORA prolonge également l’histoire de l’incident dans la gestion des fournisseurs. Articles 28 à 30 imposent aux entités financières de gérer le risque lié aux tiers prestataires de services TIC, de maintenir un registre des accords contractuels de services TIC, d’évaluer le risque de concentration, de réaliser des revues de diligence raisonnable, de prévoir des garanties contractuelles, de définir les droits d’audit et d’inspection, de maintenir des droits de résiliation et de tester les stratégies de sortie pour les fonctions critiques ou importantes. Si l’incident implique un prestataire de services cloud, un prestataire de services managés ou une intégration SaaS, les éléments de preuve DORA doivent montrer les rôles du fournisseur, les obligations de préservation des journaux, l’assistance à la gestion de l’incident, les obligations de rétablissement et la coopération avec l’autorité de supervision.
Intégrer tôt la responsabilité GDPR liée aux violations de données à caractère personnel
Le GDPR s’applique au traitement automatisé de données à caractère personnel et au traitement non automatisé qui fait partie d’un système de fichiers. Il peut s’appliquer aux organisations établies dans l’UE ainsi qu’aux responsables du traitement ou sous-traitants non établis dans l’UE qui offrent des biens ou services à des personnes dans l’Union ou qui suivent leur comportement.
Pendant la réponse aux incidents, l’analyse GDPR doit commencer dès que des données à caractère personnel peuvent être concernées. Attendre la cause racine technique est trop tardif si le délai de 72 heures est déjà déclenché.
L’équipe de réponse doit répondre aux questions suivantes :
- Quelles catégories de données à caractère personnel peuvent être concernées ?
- Quels systèmes, applications et activités de traitement sont affectés ?
- L’organisation agit-elle comme responsable du traitement, sous-traitant, ou les deux ?
- Des données à caractère personnel ont-elles été consultées, modifiées, détruites, perdues ou divulguées ?
- Les mesures de protection telles que le chiffrement, la tokenisation ou la pseudonymisation ont-elles été efficaces ?
- Quel est le risque probable pour les personnes concernées ?
- Qui a pris la décision de notification, et quand ?
- Quelles communications ont été envoyées aux responsables du traitement, aux sous-traitants, aux autorités de contrôle ou aux personnes concernées ?
- Si aucune notification n’a été effectuée, quelle justification documentée a été retenue ?
La responsabilité prévue par GDPR Article 5 est centrale. Le responsable du traitement doit être en mesure de démontrer la conformité à des principes tels que la licéité, la loyauté, la transparence, la limitation des finalités, la minimisation des données, la limitation de la conservation, l’intégrité et la confidentialité. Cela signifie que le registre des violations, le journal des décisions, les éléments de preuve techniques et l’historique des communications font partie du système de contrôle de la protection des données, et non de simples notes ajoutées après la remédiation.
Préserver les éléments de preuve avant que la restauration ne les détruise
Un échec récurrent de la réponse aux incidents tient à une restauration qui détruit les preuves. Les systèmes sont redémarrés. Les logiciels malveillants sont supprimés. Les journaux sont écrasés par rotation. Les comptes sont modifiés avant la prise d’instantanés. Du point de vue de la disponibilité, l’équipe peut avoir le sentiment d’avoir réussi. Du point de vue de l’audit, de l’autorité de régulation, de l’assureur ou du juridique, l’organisation peut avoir perdu la capacité de prouver ce qui s’est produit.
La Politique de collecte des éléments de preuve et d’analyse forensique de Clarysec indique :
Un journal de chaîne de conservation doit accompagner tout élément de preuve physique ou numérique depuis son acquisition jusqu’à son archivage ou son transfert, et doit documenter :
Pour les PME, la Politique de collecte des éléments de preuve et d’analyse forensique pour PME formule clairement l’exigence de journal des éléments de preuve :
Chaque élément de preuve numérique doit être consigné avec :
Le Zenith Blueprint, phase Controls in Action, étape 23, explique le principe sous-jacent au contrôle 5.28 d’ISO/IEC 27002:2022 :
Lorsqu’un incident de sécurité de l’information se produit, l’un des éléments les plus critiques de la réponse, bien que souvent négligé, est la preuve. Pas des journaux, pas des captures d’écran, pas des récits épars, mais des éléments de preuve correctement préservés, respectant la chaîne de conservation et protégés contre les altérations. Le contrôle 5.28 reconnaît qu’après un incident, ce que vous pouvez prouver compte autant que ce qui s’est réellement produit.
Un dossier d’éléments de preuve prêt pour l’autorité de régulation concernant l’incident d’Anya doit inclure :
| Élément de preuve | Importance | Responsable |
|---|---|---|
| Enregistrement de déclaration d’incident | Montre l’heure de prise de connaissance et déclenche l’analyse des délais | Responsable de l’incident |
| Classification de gravité | Soutient l’escalade, la priorisation et les décisions de notification | Responsable de la sécurité ou prestataire informatique |
| Extrait de l’inventaire des actifs et des données | Identifie les services, systèmes, données et criticités affectés | Responsable informatique et responsable de la protection des données |
| Exports de journaux horodatés | Soutient la détection, la chronologie et l’analyse de la cause racine | SOC ou prestataire informatique |
| Instantané de la piste d’audit cloud | Montre l’activité API, l’activité d’identité et les actions de stockage | Administrateur cloud |
| Journal de chaîne de conservation | Préserve la fiabilité et la traçabilité des éléments de preuve | Responsable forensique |
| Notification à la direction | Montre l’escalade et la visibilité de gouvernance | RSSI ou directeur général |
| Journal des décisions réglementaires | Montre pourquoi une notification était ou non requise | Juridique, DPO et RSSI |
| Enregistrement des communications fournisseur | Montre la coopération du tiers et la réponse contractuelle | Responsable des fournisseurs |
| Enregistrement des communications clients | Soutient NIS2, DORA, GDPR et les obligations contractuelles | Responsable de la communication |
| Enregistrement des retours d’expérience | Soutient l’amélioration continue ISO/IEC 27001:2022 | Responsable du SMSI |
La conservation des journaux doit être explicite. La Politique de journalisation et de surveillance pour PME de Clarysec précise :
Les journaux de sécurité relatifs aux incidents doivent être conservés pendant au moins 3 ans à compter de la date de l’incident
Le Zenith Blueprint, phase Controls in Action, étape 19, ajoute cette réalité opérationnelle :
La journalisation est le système vital de tout environnement informatique sécurisé. Sans elle, les incidents restent invisibles, la responsabilité s’efface et les relations de cause à effet disparaissent.
La réponse aux incidents, la journalisation, la collecte des éléments de preuve et la notification doivent donc être conçues comme un système de contrôle connecté.
Exécuter les premières 72 heures comme un sprint d’éléments de preuve
Un sprint pratique d’éléments de preuve sur 72 heures aide les équipes à répondre sans perdre l’auditabilité.
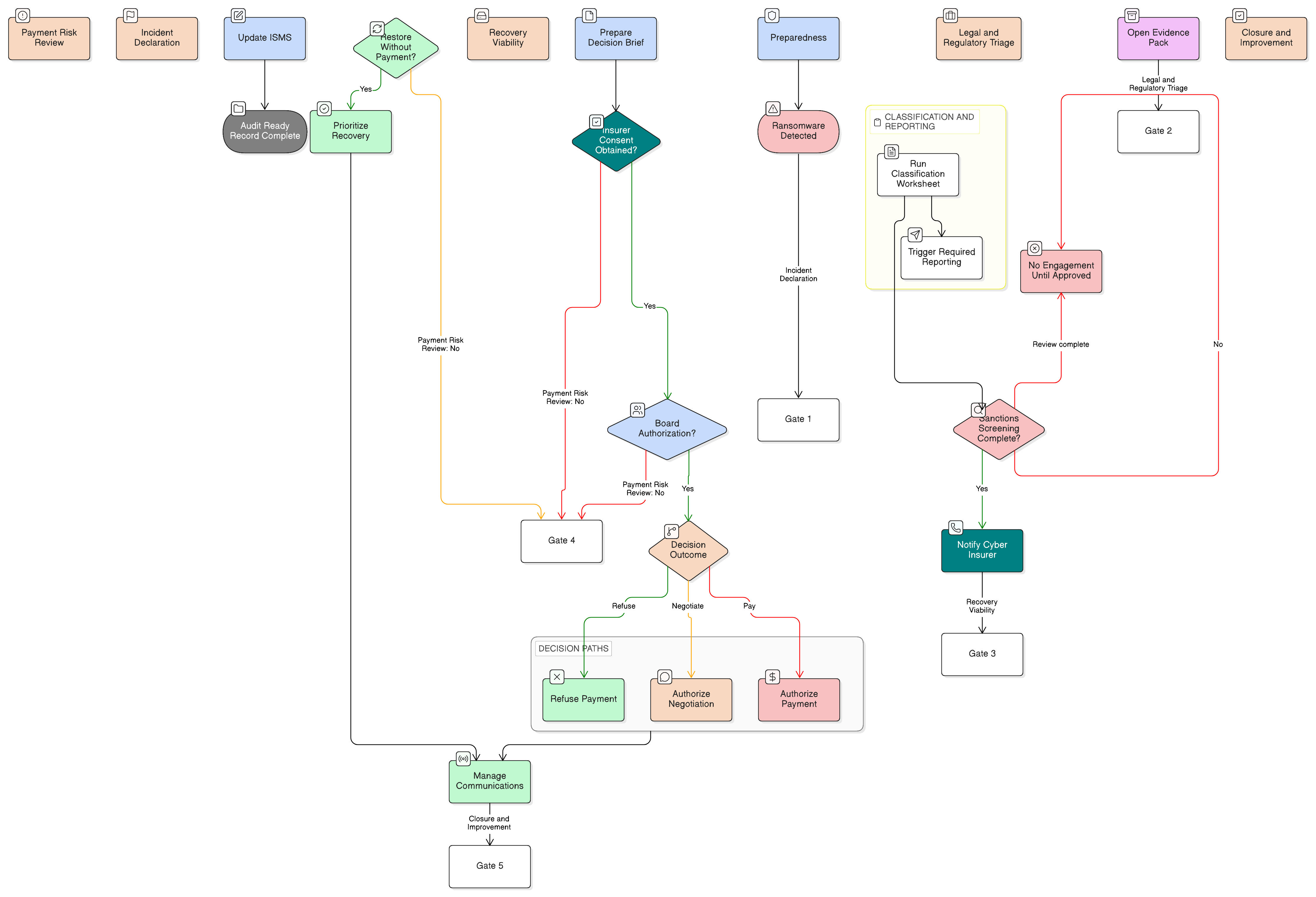
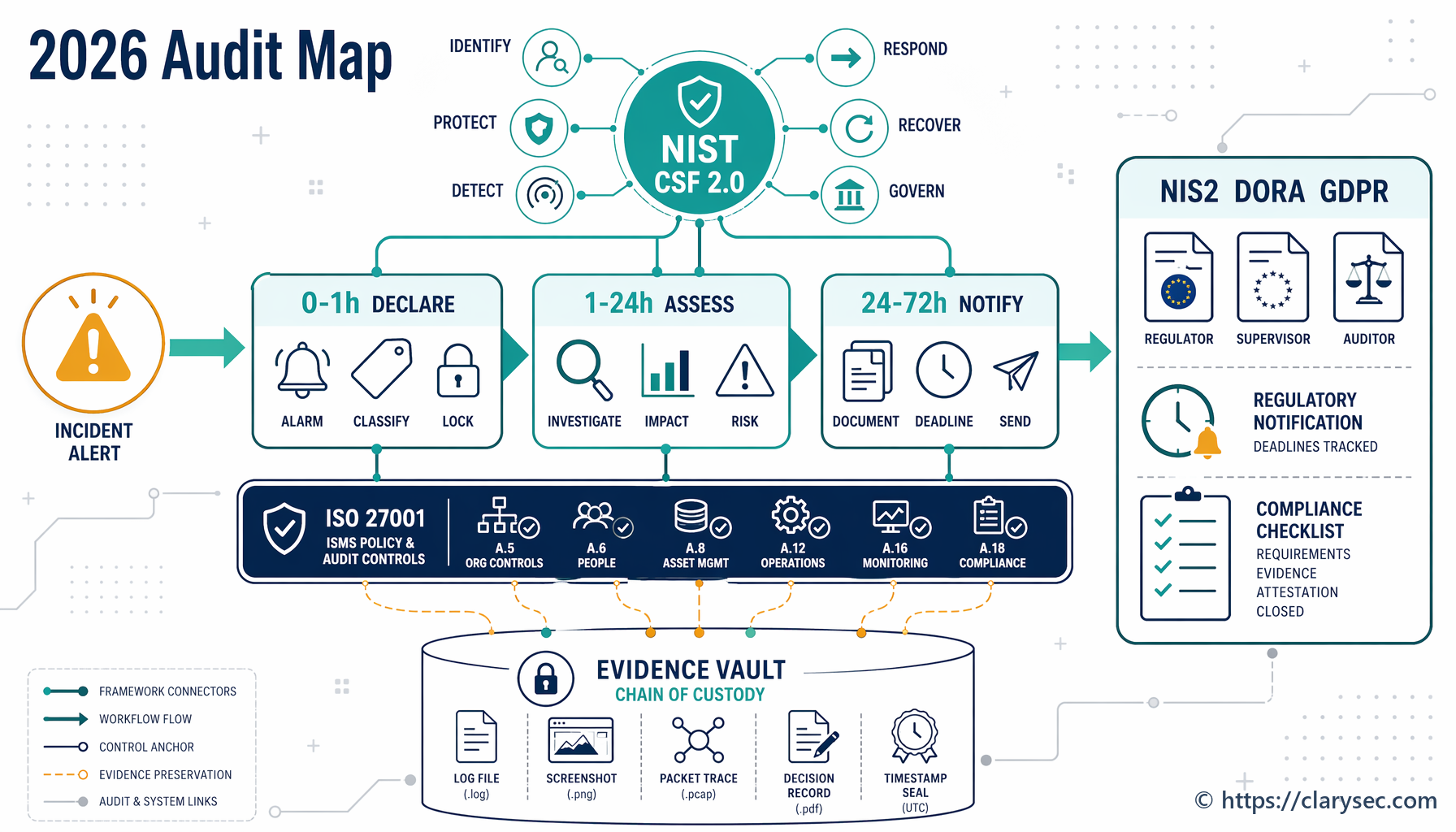
Heure 0 à 1 : déclarer, classifier et préserver
Ouvrez le ticket d’incident en utilisant la Politique de réponse aux incidents. Désignez un responsable de l’incident, un responsable technique, un responsable de la communication, un responsable juridique ou protection des données, un coordinateur fournisseurs et un responsable des éléments de preuve.
Utilisez l’exigence de classification en une heure de la Politique de réponse aux incidents pour PME comme point de contrôle, y compris dans les grandes organisations. Appliquez le cadre à plusieurs niveaux pour la réponse d’entreprise et consignez les incertitudes lorsque les faits sont incomplets.
Préservez immédiatement les éléments de preuve volatils : journaux d’identité, alertes EDR, pistes d’audit cloud, enregistrements d’accès à privilèges, journaux des systèmes affectés, état des sauvegardes, changements de configuration et historique des tickets pertinents. Démarrez le journal de chaîne de conservation en utilisant la Politique de collecte des éléments de preuve et d’analyse forensique.
Sorties décisionnelles :
- Heure de déclaration de l’incident.
- Gravité initiale.
- Services suspectés d’être affectés.
- Données suspectées d’être affectées.
- Première liste de surveillance réglementaire, notamment GDPR, NIS2, DORA et obligations contractuelles.
- Lacunes dans les éléments de preuve et responsables désignés.
Heure 1 à 24 : analyse d’impact et d’alerte précoce
Établissez la première vision de l’impact. Déterminez si l’événement a affecté la fourniture de services, a causé ou pourrait causer une perturbation opérationnelle ou une perte financière, a affecté des tiers ou a créé un préjudice matériel ou immatériel. Cette analyse soutient l’évaluation de l’incident significatif NIS2.
Pour les entités financières, classifiez au regard des critères DORA : clients affectés, transactions, réputation, indisponibilité, étendue géographique, perte de données, criticité et impact économique.
Pour le GDPR, déterminez si des données à caractère personnel sont concernées et s’il existe un risque probable pour les personnes concernées.
Sorties décisionnelles :
- Décision d’alerte précoce NIS2.
- Statut de surveillance d’incident majeur DORA.
- Statut de l’évaluation de violation de données à caractère personnel GDPR.
- Surveillance des notifications aux clients, aux clients finaux ou aux responsables du traitement.
- Mise à jour destinée à l’organe de direction.
- Demandes d’éléments de preuve aux fournisseurs.
Heure 24 à 72 : préparer les éléments de preuve de notification de niveau réglementaire
Si NIS2 s’applique, préparez la mise à jour de notification d’incident à 72 heures avec la gravité préliminaire, l’impact et les indicateurs de compromission disponibles. Si une notification GDPR est requise, veillez à ce que le dossier destiné à l’autorité de contrôle reflète ce qui est connu, ce qui reste inconnu, les conséquences probables et les mesures prises ou proposées. Si DORA s’applique, préparez le rapport initial ou intermédiaire requis selon le processus de l’autorité compétente.
Sorties décisionnelles :
- Chronologie d’incident mise à jour.
- Hypothèse de cause racine.
- Actions de confinement et d’éradication.
- Éléments de preuve de restauration du service.
- Dossier de notification à l’autorité de régulation.
- Communications aux clients ou clients finaux.
- Inventaire des éléments de preuve mis à jour.
Ce sprint n’est pas de la paperasse pour la forme. Il empêche l’équipe de réponse de sacrifier les éléments de preuve pendant le rétablissement des opérations.
Cartographie inter-référentiels : un processus, plusieurs consommateurs d’éléments de preuve
Un programme mature de réponse aux incidents produit les éléments de preuve une seule fois et les réutilise dans plusieurs référentiels.
| Élément du processus d’incident | CSF 2.0 | ISO/IEC 27001:2022 et Annexe A | NIS2 | DORA | GDPR |
|---|---|---|---|---|---|
| Gouvernance et responsabilité | GV.RR, GV.OV, GV.PO | Clauses 5.1 à 5.3, A.5.24 | Supervision de la direction Article 20 | Responsabilité de l’organe de direction Articles 5 et 6 | Responsabilité Article 5 |
| Domaine d’application et obligations | GV.OC | Clauses 4.1 à 4.4 | Domaine des entités essentielles et importantes | Domaine des entités financières et proportionnalité | Champ matériel et territorial |
| Critères de risque et de gravité | GV.RM, ID.RA, RS.MA-03 | Clauses 6.1.1 à 6.1.3, A.5.25 | Critères d’incident significatif | Classification Article 18 | Risque pour les personnes concernées |
| Détection et surveillance | DE.CM, DE.AE | Journalisation A.8.15, surveillance A.8.16, A.5.25 | Gestion des incidents et évaluation de l’efficacité | Indicateurs d’alerte précoce et enregistrements d’incidents | Détection et évaluation des violations |
| Exécution de la réponse | RS.MA, RS.AN, RS.MI | A.5.26, A.5.28 | Circuit de notification Article 23 | Processus et notification d’incident Articles 17 et 19 | Évaluation Article 33 et Article 34 |
| Rétablissement | RC.RP, RC.CO | A.5.29 préparation des TIC à la continuité d’activité, A.8.13 sauvegarde de l’information | Minimisation de l’impact sur les services | Rétablissement d’opérations sécurisées | Atténuation et communication |
| Retours d’expérience | GV.OV, RS.IM | A.5.27 et amélioration Clause 10 | Action corrective sans retard injustifié | Clôture de la cause racine et actions correctives | Enregistrements de responsabilité |
La cartographie de la réponse ISO vers NIST est particulièrement utile pour les auditeurs.
| Activité ISO/IEC 27002:2022 | Sous-catégorie NIST CSF 2.0 |
|---|---|
| Exécution du plan de réponse aux incidents avec les tiers | RS.MA-01 |
| Triage et validation des signalements d’incident | RS.MA-02 |
| Catégorisation et priorisation | RS.MA-03 |
| Escalade selon les besoins | RS.MA-04 |
| Analyse et détermination de la cause racine | RS.AN-03 |
| Enregistrement des actions d’investigation et préservation de la provenance | RS.AN-06 |
| Collecte des données d’incident et préservation de l’intégrité | RS.AN-07 |
| Estimation et validation de l’ampleur de l’incident | RS.AN-08 |
| Notification des parties prenantes internes et externes | RS.CO-02 |
| Confinement et éradication | RS.MI-01 et RS.MI-02 |
| Exécution du plan de rétablissement et vérification de l’intégrité des sauvegardes | RC.RP-01 et RC.RP-03 |
La gouvernance de la chaîne d’approvisionnement doit également être incluse. NIST CSF 2.0 GV.SC couvre les processus de risque liés à la chaîne d’approvisionnement, les rôles des fournisseurs, la priorisation selon la criticité, les exigences contractuelles, les revues de diligence raisonnable, la surveillance continue, l’inclusion des fournisseurs dans la planification des incidents et les activités de fin de relation. Cela s’aligne directement avec la sécurité de la chaîne d’approvisionnement NIS2, la gestion du risque lié aux tiers prestataires de services TIC DORA et les contrôles fournisseurs ISO/IEC 27001:2022.
Comment différents auditeurs testeront le même incident
Un auditeur ISO/IEC 27001:2022 commencera par le SMSI. Il demandera si la gestion des incidents est dans le domaine d’application, si les obligations des parties intéressées sont documentées, si les risques liés aux incidents sont appréciés, si A.5.24 à A.5.28 figurent dans la Déclaration d’applicabilité (SoA), si le processus a fonctionné comme prévu et si l’incident a produit des retours d’expérience, des actions correctives et une amélioration continue.
Un évaluateur orienté NIST se concentrera sur les résultats CSF 2.0. Il testera la gouvernance, la visibilité sur les actifs, la surveillance, la déclaration d’incident, le triage, l’escalade, l’intégrité des éléments de preuve, les communications avec les parties prenantes, le confinement, l’éradication, le rétablissement et les mises à jour de profil.
Une revue de supervision NIS2 se concentrera sur la responsabilité de la direction, les mesures de gestion des risques Article 21 et la notification Article 23. Les éléments de preuve de la décision d’alerte précoce à 24 heures, du contenu de la notification à 72 heures, des rapports intermédiaires et du rapport final seront centraux. Le réviseur peut également examiner la continuité d’activité, la sécurité de la chaîne d’approvisionnement, le contrôle d’accès, la formation, la cryptographie et l’évaluation de l’efficacité.
Une autorité de régulation DORA se concentrera sur la résilience opérationnelle. Elle attendra des critères de classification des incidents, des enregistrements d’incidents liés aux TIC et de cybermenaces significatives, des indicateurs d’alerte précoce, l’escalade vers la direction générale, la visibilité de l’organe de direction, la notification aux clients lorsque leurs intérêts financiers sont affectés, la clôture de la cause racine, le rétablissement d’opérations sécurisées et les éléments de preuve fournisseurs.
Une autorité de contrôle GDPR se concentrera sur la responsabilité liée aux violations de données à caractère personnel. Elle demandera quand l’organisation a pris connaissance de l’incident, quelles données à caractère personnel ont été affectées, si l’organisation était responsable du traitement ou sous-traitant, quel risque existait pour les personnes concernées, quelles mesures ont été prises, pourquoi une notification a été ou non effectuée, et si le registre interne des violations est complet.
Un auditeur de type COBIT ou ISACA testera les objectifs de gouvernance, les pratiques de management, la responsabilité, les métriques et les éléments de preuve d’assurance. Il vérifiera si la réponse aux incidents est gouvernée, mesurée, améliorée et alignée sur les objectifs de l’entreprise.
Le même incident peut satisfaire toutes ces revues si le processus est conçu autour d’éléments de preuve partagés plutôt que de classeurs de conformité cloisonnés.
Tester la cartographie avec un exercice sur table piloté par les délais
Le moyen le plus rapide de savoir si la cartographie fonctionne consiste à réaliser un exercice sur table construit autour des délais de notification.
Utilisez ce scénario : le compte d’un ingénieur à privilèges est compromis. L’attaquant accède à une base de données de production, exporte un volume inconnu d’enregistrements, modifie un paramètre de configuration qui provoque une indisponibilité partielle pour des clients de l’UE et utilise un jeton API émis par une intégration tierce.
Exécutez l’exercice en quatre séquences.
Première séquence, détection et déclaration. L’équipe peut-elle identifier la source de l’alerte, déclarer l’incident, classifier la gravité en moins d’une heure, préserver les journaux et attribuer les rôles ?
Deuxième séquence, impact. L’équipe peut-elle identifier les services affectés, les données affectées, les clients affectés, l’implication du fournisseur, l’indisponibilité, l’étendue géographique et déterminer si l’incident affecte des intérêts financiers ou des données à caractère personnel ?
Troisième séquence, notification. L’alerte précoce NIS2, la notification NIS2 à 72 heures, la notification DORA, la notification GDPR et les avis contractuels aux clients sont-ils déclenchés ? L’équipe peut-elle documenter à la fois les décisions de notification et de non-notification ?
Quatrième séquence, rétablissement et clôture. Le confinement, l’éradication, la restauration, la validation des sauvegardes, les communications, les retours d’expérience et les actions correctives sont-ils documentés ?
La sortie ne doit pas être un jeu de diapositives. Elle doit être un dossier d’éléments de preuve : ticket d’incident complété, chronologie, journal de décisions, journal des communications, liste des éléments de preuve préservés, matrice de décision réglementaire, enregistrement des communications fournisseur, enregistrement de validation du rétablissement et plan d’actions correctives.
L’exercice n’est pas terminé lorsque les participants expliquent ce qu’ils feraient. Il est terminé lorsqu’ils produisent les enregistrements qu’un auditeur demanderait.
Schémas de défaillance à corriger avant la prochaine alerte
Le premier schéma de défaillance est l’absence d’heure de prise de connaissance définie. Si personne ne consigne le moment où l’organisation a pris connaissance de l’incident, l’analyse des délais NIS2, DORA et GDPR devient risquée.
Le deuxième est une gravité sans critères. Des libellés tels que moyen ou élevé sont faibles s’ils ne sont pas reliés à l’impact sur le service, les données, les finances, les clients ou les seuils réglementaires.
Le troisième est l’ajout trop tardif de la protection des données. L’évaluation GDPR doit commencer lorsque des données à caractère personnel peuvent être concernées, et non après la clôture de la cause racine.
Le quatrième est l’ambiguïté fournisseur. Si un prestataire de services cloud, un prestataire de services managés ou une intégration SaaS est impliqué, les contrats et playbooks doivent définir qui préserve les journaux, qui communique, qui soutient l’analyse forensique et qui assiste lors des demandes des autorités de régulation.
Le cinquième est la destruction des éléments de preuve pendant le rétablissement. Les redémarrages, suppressions et changements de configuration peuvent être nécessaires, mais ils doivent être coordonnés avec la préservation des éléments de preuve lorsque cela est possible.
Le sixième est le retour d’expérience sans traitement des risques. ISO/IEC 27001:2022 attend une amélioration lorsque cela est approprié. Une réunion de retour d’expérience sans changement de contrôle, responsable, date d’échéance ou réévaluation des risques constitue un élément de preuve faible.
Transformer la réponse aux incidents en système d’éléments de preuve de conformité croisée
La préparation aux attentes de réponse aux incidents NIST SP 800-61 et aux audits 2026 ne doit pas commencer par un nouveau playbook autonome. Elle doit commencer par une cartographie des décisions.
Clarysec peut aider votre équipe à :
- Construire un Current Profile et un Target Profile NIST CSF 2.0 pour la réponse aux incidents.
- Aligner la réponse aux incidents sur les clauses ISO/IEC 27001:2022, le traitement des risques et les contrôles de l’Annexe A.
- Intégrer les exigences d’éléments de preuve NIS2 à 24 heures, 72 heures et un mois dans les processus.
- Cartographier la classification des incidents DORA, la notification à l’organe de direction, la notification aux clients et les éléments de preuve relatifs aux fournisseurs TIC.
- Intégrer l’analyse des violations de données à caractère personnel GDPR et les enregistrements de responsabilité.
- Déployer les politiques Clarysec Politique de réponse aux incidents, Politique de réponse aux incidents pour PME, Politique de collecte des éléments de preuve et d’analyse forensique, Politique de collecte des éléments de preuve et d’analyse forensique pour PME, Politique de journalisation et de surveillance pour PME, Zenith Blueprint et Zenith Controls dans un modèle opérationnel testé par exercice sur table.
La question pour 2026 n’est pas de savoir si votre équipe peut contenir une attaque. La question est de savoir si votre équipe peut classifier, escalader, notifier, rétablir et prouver la réponse à travers NIST, ISO/IEC 27001:2022, NIS2, DORA et GDPR.
Le modèle de mise en œuvre en 30 étapes de Clarysec et sa boîte à outils de conformité croisée sont conçus pour rendre cela possible avant la prochaine alerte du mardi matin. Téléchargez les politiques Clarysec pertinentes, réalisez un exercice sur table piloté par les délais et demandez une évaluation Clarysec afin de transformer votre plan de réponse aux incidents en système d’éléments de preuve prêt pour l’audit.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council