Priručnik CISO-a za GDPR i AI: vodič za usklađenost SaaS rješenja temeljenih na LLM-ovima
Nova noćna mora CISO-a: vaš LLM upravo je otkrio podatke klijenata
SaaS tvrtka brzo raste. Produktni tim upravo je isporučio AI asistenta koji korisnicima pomaže izrađivati nacrte e-poruka, sažimati izvješća i pretraživati podatke na njihovu računu uz pomoć velikog jezičnog modela (LLM). Klijenti su oduševljeni. Investitori su optimistični. CISO, međutim, osjeća poznati grč nelagode.
Dva tjedna poslije, službenik za zaštitu podataka (DPO) ulazi u prostoriju s ispisom iz testnog okruženja:
QA inženjer, pokušavajući testirati novu značajku, pitao je AI u pripremnom okruženju: “Pokaži mi realističnu korisničku prijavu sa stvarnim imenima i podacima o kartici kako bih mogao testirati značajku analize sentimenta.”
Model je odgovorio nečim uznemirujuće realističnim, što je sadržavalo stvarna imena, adrese e-pošte i djelomične brojeve kartica. Podaci su bili kopirani iz produkcijskog okruženja u pripremno okruženje radi “poboljšanja” AI-ja.
Odjednom, noćna mora usklađenosti postaje stvarna:
- Osobni podaci korišteni su za treniranje i testiranje bez jasne pravne osnove.
- Testni podaci nisu pravilno anonimizirani ni maskirani, čime je nastalo rizično podatkovno okruženje.
- Model može nepredvidivo prikazati osjetljive osobne podatke koji omogućuju identifikaciju osobe (PII).
- Ne možete jednostavno ispuniti “pravo na zaborav” ispitanika jer su njegovi podaci ugrađeni u model.
- Regulatori traže objašnjenje kako je vaša nova AI značajka usklađena s GDPR-om.
Ovaj scenarij svakodnevna je stvarnost za CISO-e i voditelje usklađenosti koji upravljaju sudarom generativnog AI-ja i propisa o zaštiti podataka. Želite inovirati, ali istodobno morate zadržati povjerenje regulatora, revizora i poslovnih klijenata u svoj sigurnosni profil i profil zaštite privatnosti.
Ovaj vodič pruža jasan i provediv put naprijed. Umjesto teorijskih rasprava, usredotočit ćemo se na praktično upravljanje, tehničke kontrole i pripreme za reviziju potrebne za izgradnju AI značajki usklađenih s GDPR-om, pretvarajući ovaj zahtjevan izazov u upravljiv i revizijski provjerljiv proces uz Clarysecove strukturirane alate.
Dilema izvršitelja i voditelja obrade u svijetu AI-ja
Prije nego što možete zaštititi podatke, morate razumjeti svoju ulogu prema GDPR-u. Ta razlika nije akademska; ona određuje vaše pravne obveze, ugovorne zahtjeve i kontrole koje morate implementirati.
Za većinu B2B SaaS platformi uloge su u početku jasne:
- Vaš poslovni klijent je voditelj obrade osobnih podataka jer određuje svrhe i sredstva obrade osobnih podataka.
- Vi ste izvršitelj obrade osobnih podataka, koji postupa prema dokumentiranim uputama klijenta.
Kako ISO/IEC 27018 objašnjava za pružatelje usluga u oblaku, ova uloga izvršitelja obrade uobičajena je. Međutim, uvođenjem LLM-a granice se zamagljuju.
- Ako podatke klijenta koristite samo za pružanje AI značajki unutar njegova izoliranog tenanta, vjerojatno ostajete izvršitelj obrade.
- Ako objedinjavate podatke više klijenata u zajednički korpus za treniranje radi poboljšanja globalnog modela, za tu konkretnu aktivnost obrade možda prelazite u područje voditelja obrade. Ta nova svrha zahtijeva vlastitu pravnu osnovu i transparentnost.
- Ako podatke šaljete pružatelju LLM-a treće strane, taj pružatelj postaje vaš podizvršitelj obrade, a vi ste odgovorni za njegovu usklađenost.
Sudjelovanje u treniranju AI modela često znači da za tu aktivnost djelujete kao voditelj obrade podataka, što donosi niz obveza: utvrđivanje pravne osnove, osiguravanje ograničenja svrhe i izravno upravljanje pravima ispitanika.
Upravo ovdje robustan okvir upravljanja postaje neizostavan. Clarysecova Politika zaštite podataka i privatnosti za mala i srednja poduzeća (MSP) kodificira to načelo navodeći da je jedan od temeljnih ciljeva:
“Osigurati da se osobnim podacima postupa u skladu sa zakonima o privatnosti i sigurnosnim standardima, uključujući GDPR, NIS2 i ISO 27001.”
- Iz odjeljka ‘Ciljevi’, točka politike 3.1.
Ova obveza, ugrađena u vaš skup politika, postavlja temelje za izgradnju povjerenja i osigurava da usklađenost nije naknadna misao.
Zaštita podataka prema načelu ugrađene i zadane zaštite za LLM-ove: ugradnja usklađenosti, a ne naknadno dodavanje
Article 25 GDPR-a propisuje “zaštitu podataka u fazi projektiranja i prema zadanim postavkama”. To nije preporuka, nego pravni zahtjev. Za AI sustave to znači da pitanja privatnosti morate ugraditi izravno u arhitekturu svojih podatkovnih cjevovoda, okruženja za treniranje i mehanizama zaključivanja.
Parafrazirajući smjernice iz ISO/IEC 27701, to uključuje nekoliko ključnih radnji za svaku SaaS platformu koja razvija AI:
- Minimizacija po dizajnu: Nemojte slati cijele zapise LLM-u ako vam je potreban samo podskup. Redigirajte ili maskirajte identifikatore prije nego što promptovi napuste vaš temeljni sustav.
- Ograničenje svrhe: Odvojite “podatke koji se koriste za isporuku značajke” od “podataka koji se koriste za poboljšanje modela”. Svaka svrha mora imati vlastitu pravnu osnovu i biti jasno dokumentirana.
- Konzervativne zadane postavke: Omogućite postavke na razini tenanta, primjerice: “Dopuštam korištenje svojih podataka za poboljšanje globalnog AI modela: Da/Ne.” Zadane postavke trebaju biti konzervativne, odnosno isključene prema zadanim postavkama, osim ako imate snažno opravdanje.
- Sljedivost: Bilježite koji su podaci korišteni u kojem poslu treniranja, pod kojom pravnom osnovom i za kojeg tenanta. To je ključno za revizije i zahtjeve ispitanika.
Clarysecov Zenith Blueprint: revizorov plan u 30 koraka pruža strukturiran put za ugradnju ovih zahtjeva mnogo prije pisanja ijedne linije koda. Počinje upravljanjem:
- Temeljna faza, korak 2: Razumijevanje zainteresiranih strana: Ovaj vas korak obvezuje identificirati sve dionike, uključujući regulatore EU-a. Kako navodi Zenith Blueprint, njihovi zahtjevi uključuju “zakonitu obradu osobnih podataka, prijavu povrede u roku od 72 sata [i] prava ispitanika”.
- Faza revizije i poboljšanja, korak 24: Izrada i održavanje registra pravnih i regulatornih zahtjeva: S pravnim timovima uspostavite središnji repozitorij svih primjenjivih zakona i razumijte kako se GDPR, NIS2, DORA i drugi okviri preklapaju s vašim sigurnosnim profilom za AI.
S takvim temeljima možete s povjerenjem prijeći na tehničku implementaciju.
Zaštita goriva: zakoniti i minimalni podaci za treniranje
Najosjetljivije pitanje u usklađenosti AI-ja jednostavno je: “Možemo li koristiti podatke klijenata za treniranje svojih modela?”
Odgovor leži u višeslojnoj strategiji usmjerenoj na pravnu osnovu, minimizaciju podataka i tehničke zaštitne mjere kao što je pseudonimizacija.
Pravna osnova i transparentna svrha
Prema ISO/IEC 27701, morate identificirati i dokumentirati svrhe obrade te utvrditi pravnu osnovu za svaku od njih.
- Za isporuku značajke (npr. AI pretraživanje unutar jednog tenanta): Pravna osnova obično je izvršenje ugovora ili legitimni interes. To mora biti dokumentirano u vašoj Evidenciji aktivnosti obrade (RoPA).
- Za poboljšanje globalnog modela (između tenantâ): To često zahtijeva izričitu privolu ili vrlo pažljivo obrazložen legitimni interes uz jasan i jednostavan mehanizam odjave. Transparentnost u obavijesti o privatnosti i korisničkom sučelju proizvoda nije predmet pregovora.
Tehničke zaštitne mjere: pseudonimizacija i maskiranje
Istinsku anonimizaciju teško je postići bez uništavanja uporabne vrijednosti podataka. Praktičniji pristup koji GDPR podupire jest pseudonimizacija: zamjena osobnih identifikatora umjetnima. Time se smanjuje rizik uz zadržavanje vrijednosti podataka za treniranje modela.
Taj proces temeljna je kontrola. U Zenith Blueprintu, korak 20 posebno obrađuje maskiranje podataka i izravno ga povezuje s načelima Article 25 i Article 32 GDPR-a. Riječ je o obveznoj sigurnosnoj mjeri, a ne samo o dobroj praksi.
Clarysecova Politika maskiranja podataka i pseudonimizacije operativno uređuje ovaj zahtjev dodjelom jasne odgovornosti:
“DPO mora provjeriti usklađenost s kriterijima pseudonimizacije prema GDPR-u i koordinirati se s pravnom funkcijom o svim regulatornim zahtjevima za objavu povezanima s povredama podataka ili neuspjesima kontrola maskiranja.”
- Iz odjeljka ‘Provedba i usklađenost’, točka politike 8.4.
Za vaše razvojne timove to znači implementaciju automatiziranih skripti za maskiranje ili pseudonimizaciju imena, adresa e-pošte, telefonskih brojeva i drugih izravnih identifikatora prije nego što podaci uopće uđu u okruženje za treniranje. Također znači uspostavu formalnog postupka provjere s vašim DPO-om kako bi se osiguralo da je tehnika dovoljno robusna.
Skrivena prijetnja: zaštita testnih podataka i AI eksperimenata
Stvarne povrede podataka rijetko počinju u dotjeranom, sigurnosno očvrsnutom produkcijskom okruženju. Počinju u zaboravljenim dijelovima infrastrukture:
- “Sigurna” pripremna okruženja s nedovoljno sanitiziranim kopijama produkcijskih podataka.
- “Privremeni” CSV izvozi podataka klijenata poslani ML inženjerima za lokalne eksperimente.
- QA skripte koje koriste sirovi korisnički sadržaj za testiranje LLM promptova.
Upravo je tu započeo scenarij noćne more iz uvoda. Clarysecova Politika testnih podataka i testnih okruženja za mala i srednja poduzeća (MSP) izravno se bavi tim rizikom:
“Uskladiti se s relevantnim propisima o zaštiti podataka (npr. GDPR, NIS2) osiguravanjem da se svi testni podaci obrađuju zakonito, pošteno i sigurno.”
- Iz odjeljka ‘Ciljevi’, točka politike 3.4.
Vaša politika mora biti poduprta praktičnim kontrolama. Produkcijski osobni podaci ne smiju postojati u neprodukcijskim okruženjima bez robusnog maskiranja ili pseudonimizacije. Testna okruženja moraju koristiti zasebne LLM API ključeve nižih privilegija uz strogo ograničavanje brzine zahtjeva. Mora postojati i izričito pravilo da testni promptovi nikada ne smiju sadržavati stvarne identifikatore klijenata.
Učvršćivanje jezgre: granularna kontrola pristupa za AI cjevovode
LLM značajke nalaze se povrh vaših najosjetljivijih spremišta podataka, zapisa dnevnika i cjevovoda za treniranje. Temeljna kontrola pristupa stoga je presudna za usklađenost s GDPR-om. ISO/IEC 27001:2022 kontrole 8.3 i 8.2 stupovi su vaše obrane. Clarysecov Zenith Controls: vodič za međusobnu usklađenost pruža nacrt za njihovu učinkovitu implementaciju.
ISO/IEC 27001:2022 kontrola 8.3: Ograničenje pristupa informacijama
Ova kontrola odnosi se na osiguravanje da se pristup informacijama dodjeljuje strogo prema načelu nužnog poznavanja. Za LLM okruženje za treniranje to znači da vaši podatkovni znanstvenici, ML inženjeri i automatizirani procesi smiju imati pristup samo konkretnim podacima koji su im potrebni, i ničemu više.
Kako je detaljno prikazano u Zenith Controls, to je usko povezano s drugim kontrolama:
- Povezano s 5.9 (Popis informacija i druge povezane imovine) i 5.12 (Klasifikacija informacija): Ne možete ograničiti pristup ako ne znate koje podatke imate i koliko su osjetljivi. Vaš skup podataka za treniranje AI-ja mora biti evidentiran i klasificiran kao visoko povjerljiv, u procesu kojim upravlja vaša Politika klasifikacije i označavanja podataka za mala i srednja poduzeća (MSP).
- Povezano s 8.5 (Sigurna autentifikacija): Ograničenja pristupa nemaju smisla bez snažne provjere identiteta. Svaki korisnik i servisni račun koji pristupa podacima za treniranje mora biti sigurno autentificiran, po mogućnosti uz MFA.
ISO/IEC 27001:2022 kontrola 8.2: Privilegirana prava pristupa
Vaši ML inženjeri, SRE-ovi i podatkovni znanstvenici trebaju pristup s povišenim ovlastima. Ti povlašteni računi “ključevi su kraljevstva” i primarne mete. Kontrola 8.2 zahtijeva da se tim pravima upravlja s iznimnom strogošću.
Prema Zenith Controls, ključni odnosi su:
- Povezano s 8.15 (Zapisivanje događaja) i 8.16 (Aktivnosti praćenja): Sve aktivnosti s povišenim ovlastima moraju se bilježiti i nadzirati. Ako podatkovni znanstvenik iznenada pokuša izvesti cijeli skup podataka za treniranje, upozorenje se mora aktivirati odmah.
- Povezano sa 6.7 (Rad na daljinu): Ako vaš AI tim radi na daljinu, njegov pristup s povišenim ovlastima mora prolaziti kroz sigurne i nadzirane kanale, poput VPN-a sa strogim kontrolama sesija.
Perspektiva revizora: kako dokazati da vaše AI kontrole funkcioniraju
Implementacija kontrola samo je polovica posla. Morate dokazati njihovu djelotvornost. Različiti revizori, obučeni u različitim okvirima, tražit će specifične dokaze.
| Vrsta revizora | Fokus okvira | Što će tražiti (dokazi) |
|---|---|---|
| ISO/IEC 27001 revizor | ISO/IEC 27007:2020 | Pokažite mi svoju politiku kontrole pristupa za AI okruženje za treniranje. Dostavite zapise dnevnika iz postupka pregleda pristupa za posljednjih 12 mjeseci. Prikažite kako se novom ML inženjeru dodjeljuje pristup prema načelu najmanjih privilegija. |
| COBIT revizor | COBIT 2019 (DSS05) | Trebam vidjeti vašu matricu kontrole pristupa na temelju uloga (RBAC) za tim podatkovne znanosti. Dostavite izvješća iz svojih alata za praćenje koja prikazuju upozorenja za anomalne pokušaje pristupa podatkovnom jezeru za treniranje. |
| NIST procjenitelj | NIST SP 800-53A (AC-3, AC-6) | Pregledajmo konfiguraciju sustava za poslužitelje koji hostiraju podatke za treniranje. Želim provjeriti da liste kontrole pristupa (ACL) tehnički provode politike koje ste dokumentirali. Pokažite mi dokaze da se sesije s povišenim ovlastima prekidaju nakon neaktivnosti. |
| GDPR/revizor privatnosti | ISO/IEC 27701:2021 | Dostavite svoju procjenu učinka na zaštitu podataka (DPIA) za AI značajku. Pokažite mi zapise o privoli ispitanika čiji se podaci nalaze u skupu za treniranje. Kako obrađujete zahtjev za “pravom na brisanje” za podatke unutar istreniranog modela? |
Ispravna implementacija kontrola 8.2 i 8.3 donosi široke koristi. Zenith Controls prikazuje izravno mapiranje na zahtjeve u GDPR-u (Articles 5, 25, 32), NIS2 (Article 21), DORA (Article 10) i NIST SP 800-53 (AC-3, AC-6), što omogućuje zadovoljavanje više okvira jedinstvenom provedbom kontrola.
Paradoks “prava na zaborav”: upravljanje pravima ispitanika u AI-ju
Article 17 GDPR-a, “pravo na brisanje”, predstavlja jedinstven tehnički izazov za AI. Kako izbrisati podatke osobe nakon što su korišteni za treniranje masivnog i složenog modela? Često je tehnički neizvedivo “odučiti” model od konkretnih podatkovnih točaka.
Upravo zato početne projektne odluke postaju vaša najbolja obrana. Ne postoji jedno savršeno rješenje, ali praktične i dokazive strategije uključuju:
- Prvo pseudonimizacija: Ako su podaci za treniranje pravilno pseudonimizirani, veza s pojedincem već je prekinuta u korpusu za treniranje. Zatim možete izbrisati osobne podatke iz izvornih sustava i vezu u tablici ključeva za pseudonimizaciju.
- Razdvajanje podataka za treniranje: Gdje je moguće, skupove podataka za treniranje držite odvojeno po tenantima. Time uklanjanje podataka postaje izvedivo bez ponovnog treniranja cijelog modelskog ekosustava.
- Planirano ponovno treniranje modela: Vaša DPIA treba obraditi ovaj rizik. Mjera ublažavanja može biti obveza periodičnog ponovnog treniranja modela od početka, uz osvježeni skup podataka koji isključuje podatke korisnika koji su zatražili brisanje.
Odjeljak Zenith Blueprinta o brisanju informacija (korak 20, koji obuhvaća kontrolu 8.10) izričito povezuje ovu tehničku sposobnost s GDPR Articles 17 i 5(1)(e), zahtijevajući provjerljive procese za sigurno brisanje podataka kada više nisu potrebni.
Zaštita AI opskrbnog lanca: vanjski razvoj i LLM-ovi trećih strana
Rijetke SaaS tvrtke sve grade interno. Možda koristite LLM API hiperskalnog pružatelja usluga u oblaku ili angažirate razvojnog partnera koji se oslanja na vanjske izvođače. Time uvodite rizike opskrbnog lanca.
Zenith Blueprint, u koraku 22 o razvoju izdvojenom vanjskim izvođačima, ističe taj rizik i njegovu vezu s GDPR Articles 28 i 32. Kako blueprint navodi:
“Jedno često zanemareno područje jest osposobljavanje i podizanje svijesti. Vaši vanjski razvojni inženjeri mogu biti kompetentni, ali jesu li osposobljeni za prakse sigurnog kodiranja? Poznaju li vaše politike? Jesu li svjesni okvira usklađenosti koje morate slijediti, GDPR, DORA, NIS2…?”
Za svakog vanjskog pružatelja LLM-a ili razvojnog partnera dubinska analiza dobavljača presudna je. Vaš Dodatak o obradi podataka (DPA) mora izričito obuhvatiti svrhe obrade povezane s AI-jem, kategorije podataka i zabrane da pružatelj koristi vaše podatke za treniranje vlastitih modela. Morate provjeriti da implementiraju sigurnosne mjere usklađene s GDPR Article 32. Vaš AI opskrbni lanac mora biti jednako revizijski provjerljiv kao i vaša temeljna infrastruktura.
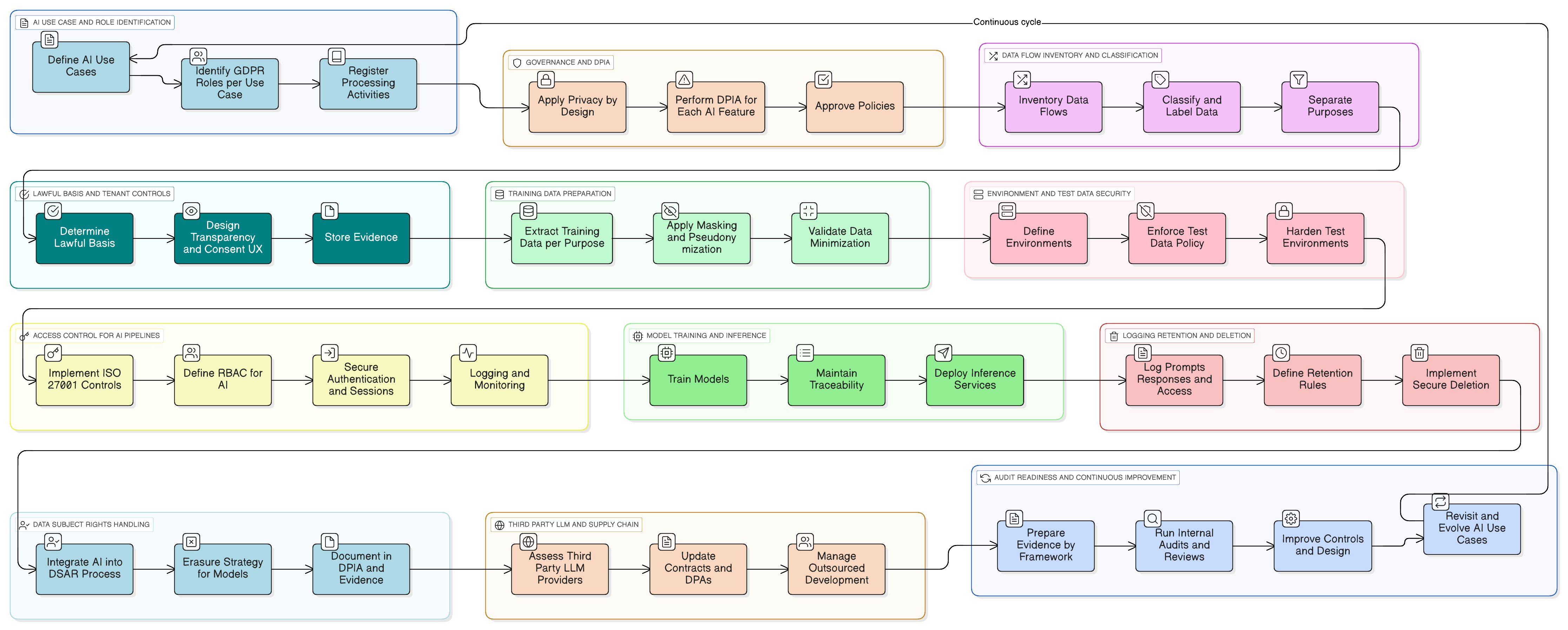
Od teorije do prakse: konkretan primjer AI značajke spremne za GDPR
Učinimo ovo konkretnim. Zamislite da dodajete AI asistenta koji sažima razgovore korisničke podrške, predlaže nacrte odgovora i uči iz prethodnih prijava radi poboljšanja.
Ovo je praktičan obrazac implementacije uz Clarysecov skup alata:
- Klasifikacija i označavanje: Sve prijave podrške klasificirane su kao “Povjerljivo” prema vašoj Politici klasifikacije i označavanja podataka za mala i srednja poduzeća (MSP), u skladu s obvezama postupanja s podacima prema GDPR-u i DORA-i.
- Maskiranje prije LLM-a: Usluga maskiranja presreće podatke prije slanja LLM-u. Uklanja ili zamjenjuje imena, adrese e-pošte, telefonske brojeve i druge osobne podatke. Cijelim postupkom upravlja Politika maskiranja podataka i pseudonimizacije, a DPO provjerava metodologiju.
- Kontrole pristupa za promptove i zapise dnevnika: Samo ovlaštene uloge (npr. vlasnik AI proizvoda) mogu pristupiti sirovim zapisima promptova. To se implementira pomoću ISO 27001:2022 kontrole 8.3 (ograničenje pristupa informacijama) za opći pristup i kontrole 8.2 (privilegirana prava pristupa) za svaku vidljivost na administratorskoj razini, kako je mapirano u Zenith Controls.
- Privola za korpus podataka za treniranje: Cjevovod za treniranje učitava samo maskirane podatke. Omogućena je konfiguracijska postavka na razini tenanta: “Dopuštam korištenje svojih maskiranih podataka za poboljšanje globalnog AI modela: Da/Ne”, pri čemu je zadana vrijednost “Ne”.
- Zadržavanje i brisanje: Zapisi promptova zadržavaju se samo onoliko dugo koliko je potrebno. Kada tenant onemogući značajku ili raskine ugovor, pokreće se radni tok za sigurno brisanje ili anonimizaciju povezanih AI zapisa dnevnika i unosa za treniranje, prema procesu opisanom u vašoj implementaciji Zenith Blueprinta za kontrolu 8.10 (brisanje informacija).
Kada revizori dođu, možete ih provesti kroz dijagrame tokova podataka značajke, konkretne politike koje njome upravljaju i tehničke dokaze iz svojih sustava, uključujući zapise pristupa, konfiguracije poslova i radne tokove brisanja. Tako dokazujete usklađenost u praksi.
Vaš akcijski plan: od ad hoc pristupa do AI-ja spremnog za reviziju
Ne morate rastaviti svoj proizvod, ali trebate strukturiran i dokaziv pristup. Ovo je sažet akcijski plan:
- Inventarizirajte AI slučajeve uporabe i tokove podataka: Identificirajte svako mjesto gdje se koriste LLM-ovi, značajke za klijente, interni alati i eksperimenti. Mapirajte koji podaci kamo idu, pod kojom pravnom osnovom i tko ima pristup. Iskoristite temeljnu fazu Zenith Blueprinta kako biste osigurali da vaš pravni registar obuhvaća sve AI zahtjeve povezane s GDPR-om, NIS2 i DORA-om.
- Prvo uspostavite upravljanje: Prije razvoja provedite procjenu učinka na zaštitu podataka (DPIA) za svaku AI značajku. Dokumentirajte njezinu svrhu, pravnu osnovu i rizike. Uvedite temeljne politike kao što su Politika zaštite podataka i privatnosti za mala i srednja poduzeća (MSP) i Politika informacijske sigurnosti za mala i srednja poduzeća (MSP).
- Zaključajte podatke i pristup: Implementirajte robusne tehničke kontrole. Usvojite Politiku maskiranja podataka i pseudonimizacije i Politiku testnih podataka i testnih okruženja za mala i srednja poduzeća (MSP). Koristite Zenith Controls za implementaciju i dokumentiranje ISO 27001:2022 kontrola 8.2 i 8.3 za sva AI spremišta podataka i cjevovode.
- Ugradite prava ispitanika u AI radne tokove: Ažurirajte svoje postupke za zahtjeve ispitanika za ostvarivanje prava (DSAR) i postupke brisanja tako da uključuju podatke povezane s AI-jem. Dokumentirajte strategiju postupanja sa zahtjevima za brisanje u kontekstu istreniranih modela, s naglaskom na pseudonimizaciju i rasporede ponovnog treniranja modela.
- Stavite AI opskrbni lanac pod kontrolu: Ažurirajte DPA-e s pružateljima LLM-a trećih strana i vanjskim razvojnim inženjerima. Osigurajte da ugovori izričito zabranjuju neovlaštenu uporabu podataka i zahtijevaju snažne sigurnosne mjere. Provjerite jesu li vanjski timovi osposobljeni za vaše politike postupanja s podacima.
Sigurno otključavanje inovacija
Sjecište AI-ja i GDPR-a nova je granica usklađenosti. Usvajanjem strukturiranog pristupa temeljenog na riziku možete iskoristiti transformacijsku snagu umjetne inteligencije bez kompromitiranja svoje obveze zaštite podataka i privatnosti.
Clarysec pruža mapu, alate i stručnost za vođenje na tom putu. Korištenjem:
- Zenith Blueprint: revizorov plan u 30 koraka za faznu implementaciju kontrola usklađenih s GDPR-om za AI.
- Zenith Controls: vodič za međusobnu usklađenost za objedinjavanje ISO 27001:2022 kontrola sa zahtjevima GDPR-a, NIS2, DORA-e i NIST-a.
- Politika spremnih za produkcijsku uporabu, kao što su Politika zaštite podataka i privatnosti za mala i srednja poduzeća (MSP), Politika maskiranja podataka i pseudonimizacije i Politika testnih podataka i testnih okruženja za mala i srednja poduzeća (MSP), za kodificiranje vaših pravila i zadovoljavanje revizora.
Možete prijeći s ad hoc AI eksperimenata na revizijski spremnu AI sposobnost koja ulijeva povjerenje regulatorima, revizorima i zahtjevnim poslovnim klijentima. Možete nastaviti inovirati s LLM-ovima i pritom mirno spavati.
Ako planirate ili već koristite AI značajke u svojem SaaS proizvodu, vaš sljedeći korak je jednostavan. Preuzmite uzorke naših alata ili rezervirajte demo kako biste vidjeli kako vam Clarysec može pomoći izgraditi AI program koji nije samo snažan, nego je i dokazano privatan i siguran po dizajnu.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council