Anatomia di una violazione: guida per le aziende manifatturiere alla risposta agli incidenti secondo ISO 27001
Estratto in evidenza
Una risposta efficace agli incidenti di sicurezza delle informazioni riduce al minimo i danni derivanti da violazioni della sicurezza e garantisce la resilienza operativa. Questa guida fornisce un quadro operativo basato su ISO 27001, aiutando le aziende manifatturiere a prepararsi ad attacchi informatici reali, a rispondervi e a ripristinare l’operatività, rispettando al contempo requisiti di conformità complessi come NIS2 e DORA.
Introduzione
L’allerta compare alle 2:17. Il server centrale di un’azienda manifatturiera di medie dimensioni che produce componenti automobilistici non risponde e i monitor della linea di produzione mostrano una nota di ransomware. Ogni minuto di fermo costa migliaia di euro in produzione persa e comporta il rischio di violare rigorosi SLA della catena di fornitura. Non è un’esercitazione. Per il CISO, questo è il momento in cui anni di pianificazione, redazione di politiche e formazione vengono sottoposti alla prova definitiva.
Avere un piano di risposta agli incidenti archiviato su un server è una cosa; eseguirlo sotto pressione estrema è tutt’altra. Per le aziende manifatturiere, la posta in gioco è particolarmente elevata. Un incidente informatico non compromette solo i dati: ferma la produzione, interrompe le catene fisiche di fornitura e può mettere a rischio la sicurezza dei lavoratori.
Questa guida va oltre le procedure operative teoriche e fornisce un percorso pratico, basato su scenari reali, per costruire e gestire un programma efficace di risposta agli incidenti. Analizzeremo l’anatomia della risposta a una violazione, fondata sul solido quadro di riferimento di ISO/IEC 27001, e mostreremo come realizzare un programma resiliente che non solo consenta il ripristino dopo un attacco, ma soddisfi anche le aspettative di auditor e autorità di regolamentazione.
Cosa è in gioco: l’effetto a catena di una violazione nel settore manifatturiero
Quando i sistemi di un’azienda manifatturiera vengono compromessi, l’impatto va ben oltre un singolo server. La natura interconnessa della produzione moderna, dalla gestione dell’inventario alle linee di assemblaggio robotizzate, fa sì che un guasto digitale possa causare un arresto operativo completo. Le conseguenze sono gravi e articolate.
In primo luogo, l’emorragia finanziaria è immediata e intensa. I fermi di produzione comportano scadenze non rispettate, penali contrattuali verso i clienti e costi per personale inattivo. Il ripristino dei sistemi, il ricorso a esperti di analisi forense e l’eventuale gestione di richieste di riscatto possono mettere sotto pressione le finanze di un’azienda di medie dimensioni.
In secondo luogo, il danno reputazionale può durare a lungo. In un contesto B2B, l’affidabilità è tutto. Un singolo incidente rilevante può compromettere la fiducia dei partner chiave che dipendono da consegne just-in-time. Come evidenziano le nostre linee guida interne, un obiettivo fondamentale della gestione degli incidenti è “ridurre al minimo l’impatto aziendale e finanziario degli incidenti e ripristinare le normali operazioni il più rapidamente possibile”, un obiettivo essenziale nel settore manifatturiero.
Infine, l’intervento regolatorio può essere severo. Con quadri normativi come la direttiva dell’UE sulla sicurezza delle reti e dei sistemi informativi (NIS2) e il Digital Operational Resilience Act (DORA) ormai pienamente applicabili, le organizzazioni in settori critici come quello manifatturiero devono rispettare requisiti stringenti di notifica degli incidenti e sono esposte a sanzioni rilevanti in caso di non conformità. Un incidente gestito male non è solo un fallimento tecnico: rappresenta una responsabilità significativa sul piano legale e della conformità.
Come dovrebbe funzionare: dal caos al controllo
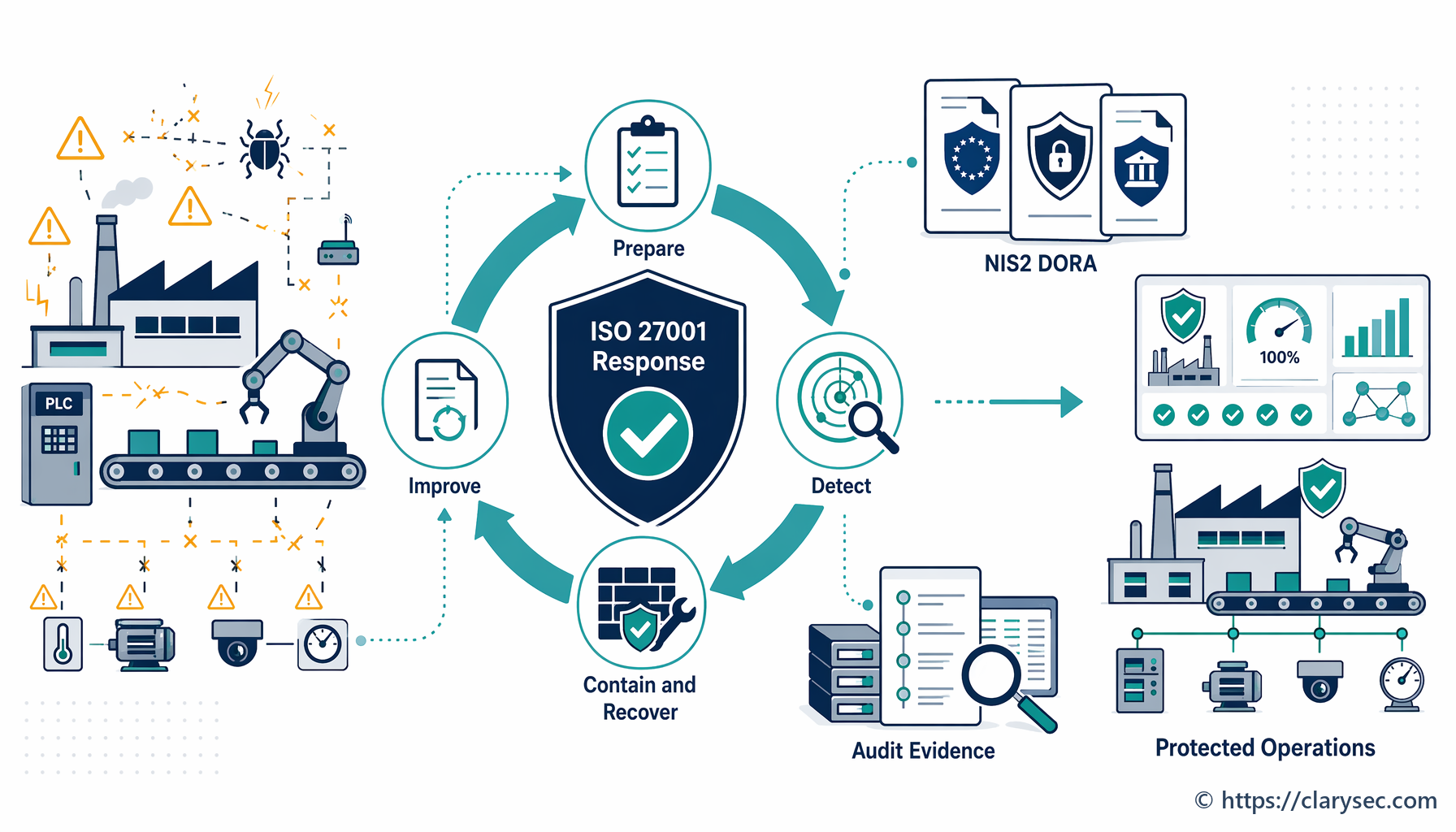
Un programma efficace di risposta agli incidenti trasforma una crisi da rincorsa caotica e reattiva in un processo strutturato e controllato. L’obiettivo non è solo risolvere il problema tecnico, ma gestire l’intero evento per proteggere l’organizzazione. Questo stato ideale si fonda sui principi delineati nel quadro di riferimento ISO/IEC 27001, in particolare sui controlli relativi alla gestione degli incidenti di sicurezza delle informazioni.
Un programma maturo è caratterizzato da diversi risultati chiave:
- Chiarezza dei ruoli: tutti sanno chi contattare e quali sono le proprie responsabilità. Il team di risposta agli incidenti (IRT) è definito in anticipo, con una leadership chiara ed esperti designati provenienti da IT, sicurezza delle informazioni, funzione legale, comunicazione e direzione.
- Rapidità e precisione: l’organizzazione è in grado di rilevare, analizzare e contenere rapidamente le minacce, impedendo che si propaghino nella rete e blocchino l’intero reparto produttivo.
- Decisioni informate: la direzione riceve informazioni tempestive e accurate, che consentono decisioni critiche su operazioni, comunicazioni ai clienti e comunicazioni regolatorie.
- Miglioramento continuo: ogni incidente, grande o piccolo, diventa un’opportunità di apprendimento. Un processo rigoroso di riesame post-incidente identifica le debolezze e reimmette i miglioramenti nel programma di sicurezza.
Raggiungere questo livello di preparazione è la finalità principale dei controlli descritti in ISO/IEC 27002:2022. Tali controlli guidano le organizzazioni nella pianificazione e preparazione (A.5.24), nella valutazione e decisione sugli eventi (A.5.25), nella risposta agli incidenti (A.5.26) e nell’apprendimento dagli stessi (A.5.28). Si tratta di costruire un sistema resiliente, capace di anticipare i guasti e strutturato per gestirli in modo controllato.
Il percorso operativo: guida passo-passo alla risposta agli incidenti
Costruire una capacità solida di risposta agli incidenti richiede un approccio documentato e sistematico. La base è una politica chiara e applicabile che descriva ogni fase del processo.
La nostra P16S Politica di pianificazione e preparazione per la gestione degli incidenti di sicurezza delle informazioni - PMI fornisce un modello completo allineato alle migliori pratiche ISO 27001. Esaminiamo i passaggi critici utilizzando questa politica come guida.
Passaggio 1: pianificazione e preparazione - le basi della resilienza
Non è possibile creare un piano di risposta nel pieno di una crisi. La preparazione è tutto. Questa fase consiste nel definire la struttura, gli strumenti e le conoscenze necessari per agire con decisione quando si verifica un incidente.
Un componente essenziale è l’istituzione di un team di risposta agli incidenti (IRT). Come indicato nella sezione 5.1 della P16S Politica di pianificazione e preparazione per la gestione degli incidenti di sicurezza delle informazioni - PMI, la finalità della politica è “garantire un approccio coerente ed efficace alla gestione degli incidenti di sicurezza delle informazioni”. Questa coerenza inizia da un team ben definito. La politica richiede che l’IRT includa membri delle funzioni chiave:
- IT e sicurezza delle informazioni
- Funzione legale e conformità
- Risorse Umane
- Relazioni pubbliche/comunicazione
- Alta direzione
Ogni membro deve avere ruoli e responsabilità chiaramente definiti. Chi ha l’autorità per scollegare i sistemi? Chi è il portavoce designato per comunicare con clienti o media? Queste domande devono ricevere risposta ed essere documentate molto prima che si verifichi un incidente.
Passaggio 2: rilevazione e segnalazione - il sistema di allerta precoce
Quanto prima si viene a conoscenza di un incidente, tanto minori saranno i danni. Ciò richiede sia monitoraggio tecnico sia una cultura in cui i dipendenti si sentano autorizzati e tenuti a segnalare attività sospette.
La P16S Politica di pianificazione e preparazione per la gestione degli incidenti di sicurezza delle informazioni - PMI è chiara su questo punto. La sezione 5.3, “Segnalazione degli eventi di sicurezza delle informazioni”, stabilisce:
“Tutti i dipendenti, i contraenti e le altre parti rilevanti sono tenuti a segnalare il più rapidamente possibile al punto di contatto designato qualsiasi evento o debolezza di sicurezza delle informazioni osservati o sospetti.”
Questo “punto di contatto designato” è critico. Può essere il service desk IT o un canale dedicato alla sicurezza. Il processo deve essere semplice e comunicato in modo efficace a tutto il personale. I dipendenti devono essere formati su cosa osservare, ad esempio e-mail di phishing, comportamenti anomali dei sistemi o violazioni della sicurezza fisica.
Passaggio 3: valutazione e triage - dimensionare la minaccia
Una volta segnalato un evento, il passaggio successivo consiste nel valutarne rapidamente natura e gravità. È un falso allarme, una problematica minore o una crisi conclamata? Questo processo di triage determina il livello di risposta necessario.
La nostra politica definisce nella sezione 5.2, “Classificazione degli incidenti”, uno schema chiaro per categorizzare gli incidenti in base al loro impatto su riservatezza, integrità e disponibilità. Uno schema tipico potrebbe essere il seguente:
- Basso: una singola workstation infettata da malware comune, facilmente contenibile.
- Medio: un server dipartimentale non disponibile, con impatto su una specifica funzione aziendale ma senza arresto della produzione complessiva.
- Alto: un attacco ransomware diffuso che colpisce sistemi critici di produzione e dati aziendali essenziali.
- Critico: un incidente che comporta una violazione di dati personali sensibili o della proprietà intellettuale, con significative implicazioni legali e reputazionali.
Questa classificazione determina urgenza, risorse assegnate e percorso di escalation verso la direzione, assicurando che la risposta sia proporzionata alla minaccia.
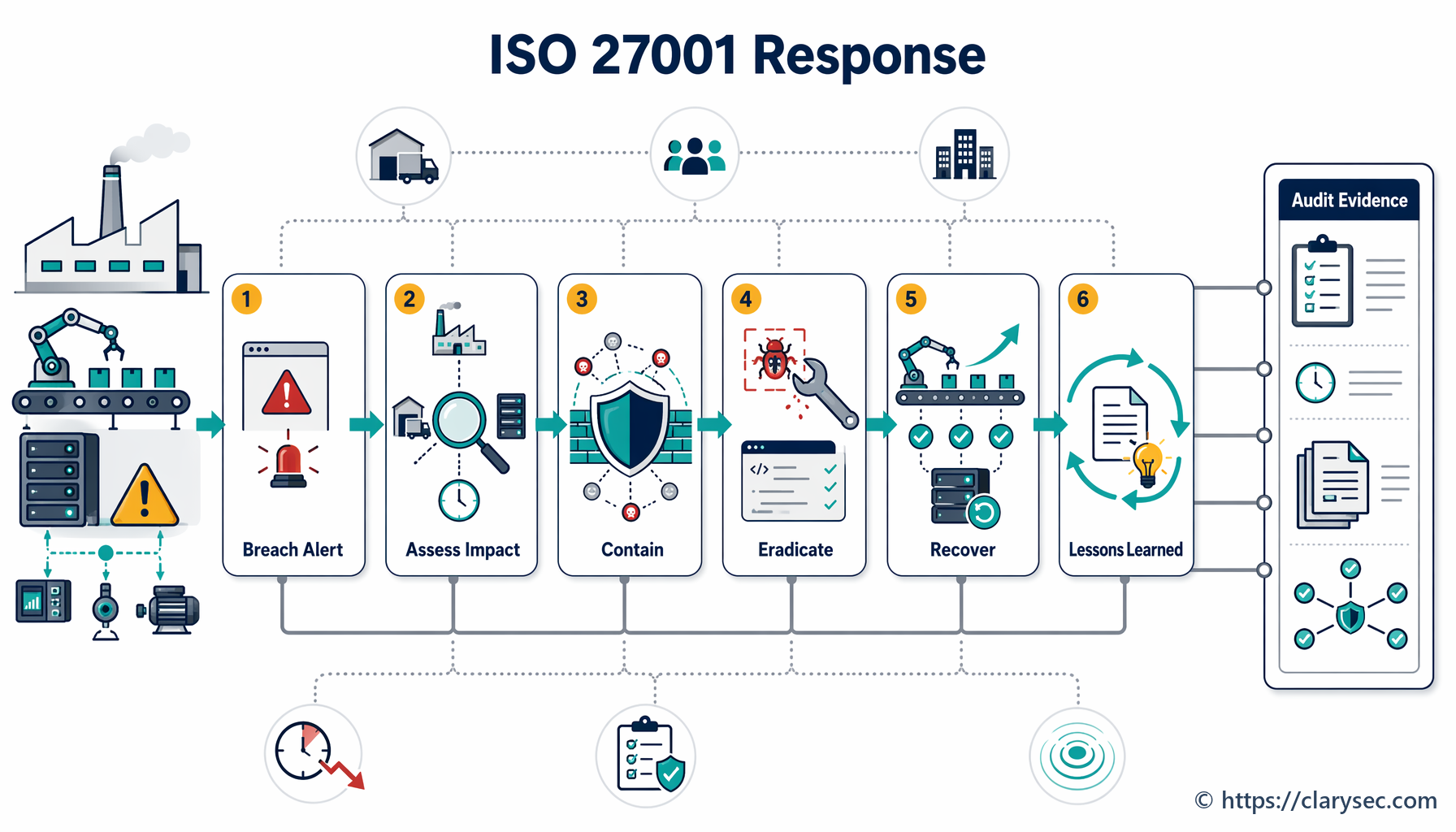
Passaggio 4: contenimento, eradicazione e ripristino - spegnere l’incendio
Questa è la fase di risposta attiva, in cui l’IRT opera per controllare l’incidente e ripristinare le normali operazioni.
- Contenimento: la priorità immediata è fermare l’emorragia. Ciò può comportare l’isolamento dei segmenti di rete interessati, la disconnessione dei server compromessi o il blocco di indirizzi IP malevoli. L’obiettivo è impedire che l’incidente si propaghi e provochi ulteriori danni.
- Eradicazione: una volta contenuto l’incidente, è necessario eliminarne la causa radice. Ciò può significare rimuovere malware, applicare patch alle vulnerabilità sfruttate e disabilitare gli account utente compromessi.
- Ripristino: l’ultimo passaggio consiste nel ripristinare i sistemi e i dati interessati. Ciò include il ripristino da backup puliti, la ricostruzione dei sistemi e un monitoraggio accurato per verificare che la minaccia sia stata completamente rimossa prima di rimettere i servizi in esercizio.
La sezione 5.4 della P16S Politica di pianificazione e preparazione per la gestione degli incidenti di sicurezza delle informazioni - PMI, “Risposta agli incidenti di sicurezza delle informazioni”, fornisce il quadro di riferimento per queste azioni, sottolineando che “le procedure di risposta devono essere avviate quando un evento di sicurezza delle informazioni viene classificato come incidente”.
Passaggio 5: attività post-incidente - apprendere le lezioni
Il lavoro non termina quando i sistemi tornano in esercizio. La fase post-incidente è probabilmente la più importante per costruire resilienza di lungo periodo. Comprende due attività chiave: raccolta delle evidenze e riesame delle lezioni apprese.
La politica evidenzia l’importanza della raccolta delle evidenze nella sezione 5.5, affermando che “devono essere stabilite e seguite procedure per la raccolta, l’acquisizione e la conservazione delle evidenze relative agli incidenti di sicurezza delle informazioni”. Questo è essenziale per l’indagine interna, per eventuali richieste delle forze dell’ordine e per potenziali azioni legali.
A seguire, deve essere condotto un riesame post-incidente formale. La riunione deve coinvolgere tutti i membri dell’IRT e le principali parti interessate per discutere:
- Che cosa è accaduto e qual è stata la cronologia degli eventi?
- Che cosa ha funzionato correttamente nella risposta?
- Quali difficoltà sono state incontrate?
- Che cosa si può fare per prevenire un incidente simile in futuro?
L’esito di questo riesame deve essere un piano d’azione con responsabili assegnati e scadenze, finalizzato a migliorare politiche, procedure e controlli tecnici. Questo crea un ciclo di feedback che rafforza nel tempo il livello di sicurezza dell’organizzazione.
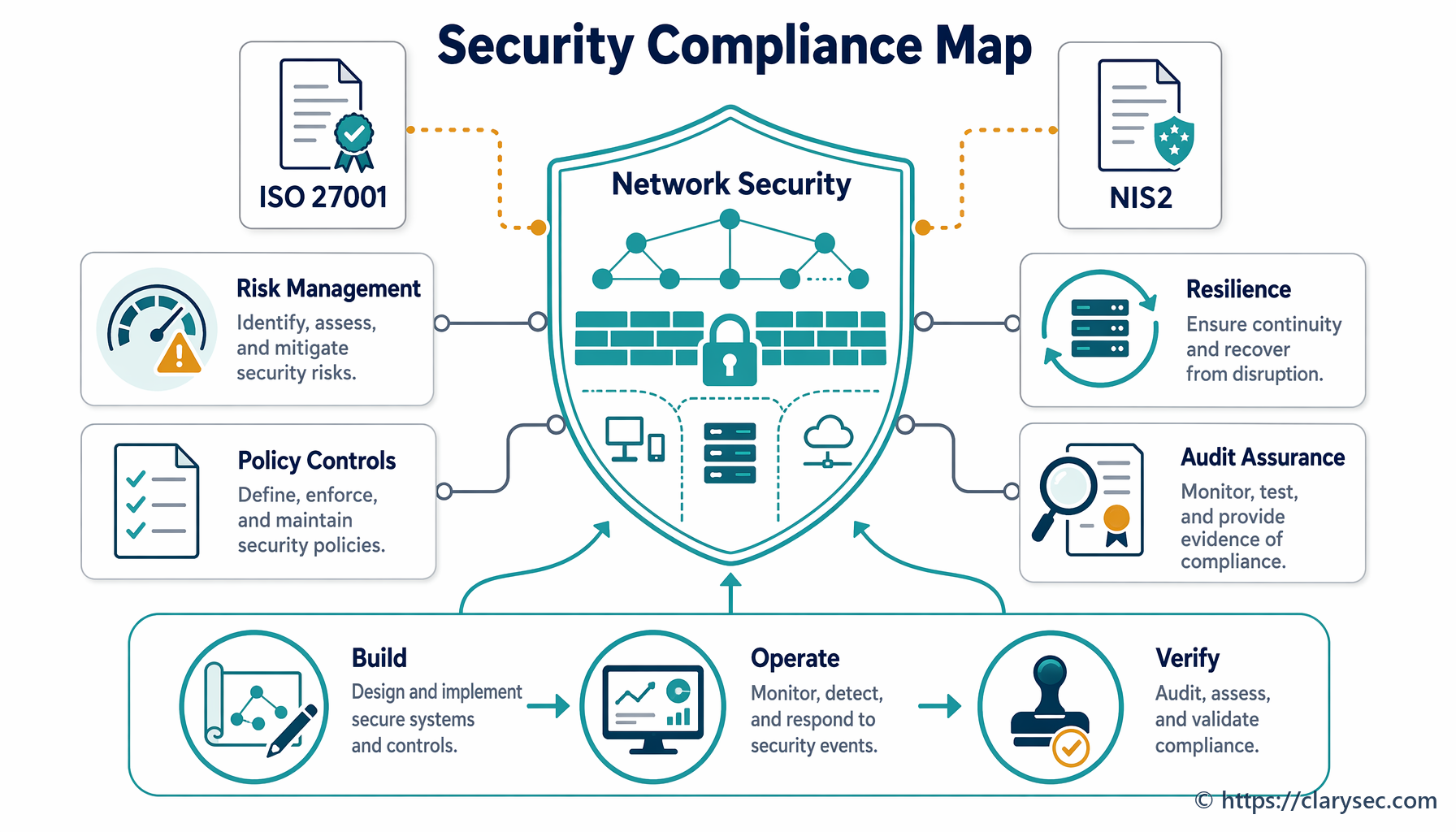
Collegare i punti: indicazioni di conformità trasversale
Soddisfare i requisiti ISO 27001 per la gestione degli incidenti non rafforza soltanto la sicurezza: fornisce una base solida per rispettare una rete crescente di normative internazionali e settoriali. Molti di questi quadri di riferimento condividono gli stessi principi fondamentali di preparazione, risposta e notifica.
Come spiegato in Zenith Controls, la nostra guida completa alla conformità trasversale, un processo robusto di gestione degli incidenti è un pilastro della resilienza digitale. Vediamo come l’approccio ISO 27001 si allinea con altri importanti quadri di riferimento.
Controlli ISO/IEC 27002:2022: L’ultima versione dello standard ISO/IEC 27002 fornisce indicazioni dettagliate sulla gestione degli incidenti attraverso un insieme dedicato di controlli:
- A.5.24 - Pianificazione e preparazione per la gestione degli incidenti di sicurezza delle informazioni: stabilisce la necessità di un approccio definito e documentato.
- A.5.25 - Valutazione e decisione sugli eventi di sicurezza delle informazioni: assicura che gli eventi siano valutati correttamente per determinare se costituiscono incidenti.
- A.5.26 - Risposta agli incidenti di sicurezza delle informazioni: copre le attività di contenimento, eradicazione e ripristino.
- A.5.27 - Segnalazione degli incidenti di sicurezza delle informazioni: definisce come e quando gli incidenti devono essere segnalati alla direzione e alle altre parti interessate.
- A.5.28 - Apprendimento dagli incidenti di sicurezza delle informazioni: richiede un processo di miglioramento continuo.
Questi controlli formano un ciclo di vita completo, riflesso anche in altre normative principali.
Direttiva NIS2: Per gli operatori di servizi essenziali, inclusi molti produttori, NIS2 impone rigorosi obblighi di sicurezza e notifica degli incidenti. Zenith Controls evidenzia la sovrapposizione diretta:
“Article 21 della direttiva NIS2 richiede agli enti essenziali e importanti di attuare misure tecniche, operative e organizzative adeguate e proporzionate per gestire i rischi posti alla sicurezza delle reti e dei sistemi informativi. Ciò include espressamente politiche e procedure di gestione degli incidenti. Inoltre, Article 23 stabilisce un processo di notifica degli incidenti articolato in più fasi, che richiede un’allerta iniziale entro 24 ore e un rapporto dettagliato entro 72 ore alle autorità competenti (CSIRT).”
Un piano di risposta agli incidenti allineato a ISO 27001 fornisce i meccanismi necessari per rispettare queste scadenze di notifica molto stringenti.
Digital Operational Resilience Act (DORA): Pur essendo focalizzati sul settore finanziario, i principi di resilienza di DORA stanno diventando un riferimento per tutti i settori. La guida evidenzia questo collegamento:
“Article 17 di DORA impone agli enti finanziari di disporre di un processo completo di gestione degli incidenti connessi alle ICT per rilevare, gestire e notificare gli incidenti connessi alle ICT. Article 19 richiede la classificazione degli incidenti sulla base dei criteri dettagliati nel regolamento e la segnalazione degli incidenti rilevanti alle autorità competenti utilizzando modelli armonizzati. Ciò rispecchia i requisiti di classificazione e segnalazione presenti in ISO 27001.”
Regolamento generale sulla protezione dei dati (GDPR): Per qualsiasi incidente che coinvolga dati personali, i requisiti del GDPR sono prioritari. Una risposta rapida e strutturata non è facoltativa. Come spiega Zenith Controls:
“Ai sensi del GDPR, Article 33 richiede ai titolari del trattamento di notificare all’autorità di controllo una violazione dei dati personali senza ingiustificato ritardo e, ove possibile, entro 72 ore dal momento in cui ne sono venuti a conoscenza. Article 34 impone la comunicazione della violazione all’interessato quando è probabile che presenti un rischio elevato per i suoi diritti e le sue libertà. Un piano efficace di risposta agli incidenti è essenziale per raccogliere le informazioni necessarie a effettuare tali notifiche in modo accurato e tempestivo.”
Costruendo il programma di risposta agli incidenti su una base ISO 27001, si sviluppano al tempo stesso le capacità necessarie per gestire i requisiti complessi di queste normative interconnesse.
Prepararsi all’esame: cosa chiederanno gli auditor
Un piano di risposta agli incidenti che non è mai stato testato o riesaminato è solo un documento. Gli auditor lo sanno e, durante un audit di certificazione ISO 27001, approfondiranno per verificare che il programma sia una componente viva e operativa del Sistema di gestione della sicurezza delle informazioni (SGSI).
Secondo Zenith Blueprint, il nostro percorso per auditor, la valutazione della risposta agli incidenti è un passaggio critico nel processo di audit. Durante la “Fase 3: attività sul campo e raccolta delle evidenze”, gli auditor testeranno sistematicamente il vostro livello di preparazione.
Ecco cosa potete aspettarvi che richiedano, sulla base del passaggio 21 di Zenith Blueprint, “Valutare la risposta agli incidenti e la continuità operativa”:
“Mostratemi il vostro piano e la vostra politica di risposta agli incidenti.” Gli auditor partiranno dalla documentazione. Esamineranno la politica per verificarne la completezza, controllando ruoli e responsabilità definiti, criteri di classificazione, piani di comunicazione e procedure per ciascuna fase del ciclo di vita dell’incidente. Verificheranno che sia stata formalmente approvata e comunicata al personale interessato.
“Mostratemi le registrazioni degli ultimi tre incidenti di sicurezza.” Questo è il momento della prova concreta. Gli auditor devono vedere evidenze che il piano venga effettivamente seguito. Si aspettano di trovare log degli incidenti o ticket che documentino:
- Data e ora della rilevazione.
- Una descrizione dell’incidente.
- La priorità assegnata o il livello di classificazione.
- Un log delle azioni intraprese per contenimento, eradicazione e ripristino.
- Data e ora della risoluzione.
“Mostratemi i verbali e il piano d’azione dell’ultimo riesame post-incidente.” Come sottolinea Zenith Blueprint, il miglioramento continuo non è negoziabile.
“Durante l’audit, cercheremo evidenze oggettive che i riesami post-incidente siano condotti in modo sistematico. Ciò include il riesame dei verbali di riunione, dei log delle azioni e delle evidenze che i miglioramenti identificati siano stati applicati, come procedure aggiornate o nuovi controlli tecnici. Senza questo ciclo di feedback, il SGSI non può essere considerato ‘in miglioramento continuo’ come richiesto dallo standard.”
“Mostratemi evidenze che avete testato il vostro piano.” Gli auditor vogliono vedere che testate proattivamente le vostre capacità, non che attendete semplicemente un incidente reale. Queste evidenze possono assumere molte forme, dalle esercitazioni tabletop con la direzione a simulazioni tecniche su scala completa. Vorranno vedere una relazione su questi test, con dettaglio dello scenario, dei partecipanti, degli esiti e delle lezioni apprese.
Essere preparati con queste evidenze dimostra che il programma di risposta agli incidenti non è solo formale, ma costituisce una componente robusta, operativa ed efficace del SGSI.
Errori comuni da evitare
Anche con un piano ben documentato, molte organizzazioni incontrano difficoltà durante un incidente reale. Ecco alcuni degli errori più comuni da tenere sotto controllo:
- La sindrome del “piano sullo scaffale”: l’errore più comune è avere un piano scritto molto bene che nessuno ha letto, compreso o provato. Formazione e test regolari sono l’unico antidoto.
- Autorità non definita: durante una crisi, l’ambiguità è il nemico. Se l’IRT non dispone di un’autorità preapprovata per intraprendere azioni decisive, come disconnettere un sistema critico di produzione, la risposta resterà paralizzata dall’indecisione mentre il danno si propaga.
- Comunicazione carente: non gestire correttamente le comunicazioni è una ricetta per il disastro. Ciò include il mancato coinvolgimento della leadership, messaggi confusi ai dipendenti o una gestione inadeguata della comunicazione con clienti e autorità di regolamentazione. Un piano di comunicazione preapprovato, con modelli, è essenziale.
- Trascurare la conservazione delle evidenze: nella fretta di ripristinare il servizio, il team tecnico può distruggere involontariamente evidenze forensi cruciali. Questo può rendere impossibile determinare la causa radice, prevenire il ripetersi dell’evento o supportare azioni legali.
- Mancato apprendimento: considerare un incidente “chiuso” non appena il sistema torna in esercizio è un’occasione persa. Senza una rigorosa analisi post-incidente, l’organizzazione è destinata a ripetere gli stessi errori.
Prossimi passi
Passare dalla teoria alla pratica è il passaggio più critico. Un programma robusto di risposta agli incidenti è un percorso di miglioramento continuo, non un punto di arrivo. Ecco da dove iniziare:
- Formalizzare l’approccio: se non disponete di una politica formale di risposta agli incidenti, questo è il momento di crearne una. Utilizzate la nostra P16S Politica di pianificazione e preparazione per la gestione degli incidenti di sicurezza delle informazioni - PMI come modello per costruire un quadro di riferimento completo.
- Comprendere il panorama della conformità: mappate le vostre procedure di risposta agli incidenti rispetto ai requisiti specifici di normative come NIS2, DORA e GDPR. La nostra guida, Zenith Controls, fornisce i riferimenti incrociati necessari per assicurare una copertura completa.
- Prepararsi all’audit: utilizzate la prospettiva dell’auditor per mettere alla prova il vostro programma. Zenith Blueprint offre uno sguardo interno su ciò che gli auditor richiederanno, così potrete raccogliere le evidenze ed essere pronti a dimostrarne l’efficacia.
Conclusione
Per un’azienda manifatturiera moderna, la risposta agli incidenti di sicurezza delle informazioni non è una questione IT: è una funzione fondamentale di continuità operativa. La differenza tra un’interruzione minore e un guasto catastrofico risiede nella preparazione, nell’esercizio e nell’impegno verso un processo strutturato e ripetibile.
Ancorando il programma al quadro di riferimento ISO 27001, riconosciuto a livello globale, non si costruisce solo una capacità difensiva, ma un’organizzazione resiliente. Si crea un sistema in grado di assorbire l’impatto di una violazione, gestire la crisi con controllo e precisione ed emergere più forte e più sicuro. Il momento per prepararsi è adesso, prima che l’allerta delle 2:17 diventi realtà.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council