Il playbook GDPR per l’IA del CISO: guida alla conformità degli LLM nei prodotti SaaS
Il nuovo incubo del CISO: il tuo LLM ha appena esposto dati dei clienti
La società SaaS cresce rapidamente. Il team di prodotto ha appena rilasciato un assistente IA che aiuta gli utenti a redigere e-mail, sintetizzare report e cercare nei dati del proprio account utilizzando un modello linguistico di grandi dimensioni (LLM). I clienti lo apprezzano. Gli investitori sono ottimisti. Il Chief Information Security Officer (CISO), però, avverte un timore fin troppo familiare.
Due settimane dopo, il responsabile della protezione dei dati (DPO) entra in sala con una stampa proveniente da un ambiente di test:
Un ingegnere QA, nel tentativo di provare una nuova funzionalità, ha chiesto all’IA in ambiente di staging: “Mostrami un ticket cliente realistico con nomi reali e dettagli della carta, così posso testare la funzionalità di analisi del sentiment.”
Il modello ha risposto con un contenuto inquietantemente realistico, contenente nomi, e-mail e numeri parziali di carte effettivi. I dati erano stati copiati dall’ambiente di produzione a un ambiente di staging per “migliorare” l’IA.
All’improvviso, l’incubo di conformità diventa reale:
- Dati personali sono stati usati per addestramento e test senza una base giuridica chiara.
- I dati di test non sono adeguatamente anonimizzati o mascherati, creando un ambiente dati ad alto rischio.
- Il modello può far emergere dati personali identificabili e dati sensibili in modi imprevedibili.
- Non è semplice soddisfare il “diritto all’oblio” di un interessato, perché i suoi dati sono incorporati nel modello.
- Le autorità di controllo chiedono in che modo la nuova funzionalità IA rispetti il GDPR.
Questo scenario è la realtà quotidiana per i CISO e per i responsabili della conformità che gestiscono l’impatto tra IA generativa e normativa sulla protezione dei dati. L’obiettivo è innovare, mantenendo al tempo stesso la fiducia di autorità di controllo, auditor e clienti aziendali nel livello di sicurezza e tutela della privacy dell’organizzazione.
Questa guida fornisce un percorso chiaro e operativo. Supereremo le discussioni teoriche per entrare nella governance, nei controlli tecnici e nella preparazione agli audit necessari per costruire funzionalità IA conformi al GDPR, trasformando una sfida complessa in un processo gestibile, verificabile e documentabile con i toolkit strutturati di Clarysec.
Il dilemma tra titolare e responsabile del trattamento nel mondo dell’IA
Prima di proteggere i dati, è necessario comprendere il proprio ruolo ai sensi del GDPR. Questa distinzione non è accademica: determina gli obblighi legali, i requisiti contrattuali e i controlli da applicare.
Per la maggior parte delle piattaforme SaaS B2B, i ruoli sono inizialmente chiari:
- Il cliente aziendale è il titolare del trattamento dei dati personali, poiché determina le finalità e i mezzi del trattamento dei dati personali.
- Tu sei il responsabile del trattamento dei dati personali, in quanto agisci secondo le istruzioni documentate del cliente.
Come spiega ISO/IEC 27018 per i fornitori di servizi cloud, questo ruolo di responsabile del trattamento è tipico. Tuttavia, quando si introduce un LLM, i confini diventano meno netti.
- Se usi i dati di un cliente solo per fornire funzionalità IA all’interno del suo tenant isolato, con ogni probabilità resti responsabile del trattamento.
- Se aggreghi dati di più clienti in un corpus di addestramento condiviso per migliorare il modello globale, potresti avvicinarti al ruolo di titolare del trattamento per quella specifica attività. Questa nuova finalità richiede una propria base giuridica e adeguata trasparenza.
- Se invii dati a un fornitore LLM di terze parti, tale fornitore diventa il tuo sub-responsabile e tu rispondi della sua conformità.
L’addestramento di modelli IA comporta spesso l’assunzione del ruolo di titolare del trattamento per tale attività, con una serie di obblighi: definire una base giuridica, garantire la limitazione della finalità e gestire direttamente i diritti degli interessati.
In questo contesto, un solido quadro di governance diventa indispensabile. La Politica di protezione dei dati e privacy per PMI di Clarysec codifica questo principio, stabilendo come obiettivo fondamentale:
“Garantire che i dati personali siano gestiti in conformità alle leggi sulla privacy e agli standard di sicurezza, inclusi GDPR, NIS2 e ISO 27001.”
- Dalla sezione ‘Obiettivi’, clausola della politica 3.1.
Questo impegno, integrato nel corpus delle politiche, crea le basi per costruire fiducia e assicurare che la conformità non sia un elemento aggiunto a posteriori.
Privacy by design per gli LLM: incorporare la conformità, non aggiungerla dopo
L’articolo 25 del GDPR impone la “protezione dei dati fin dalla progettazione e per impostazione predefinita”. Non è una raccomandazione: è un requisito legale. Per i sistemi IA, ciò significa integrare le considerazioni di tutela della privacy direttamente nell’architettura delle pipeline di dati, degli ambienti di addestramento e dei motori di inferenza.
Parafrasando le indicazioni di ISO/IEC 27701, ciò comporta diverse azioni chiave per qualsiasi piattaforma SaaS che sviluppi IA:
- Minimizzazione fin dalla progettazione: non inviare record completi al LLM se serve solo un sottoinsieme. Oscurare o mascherare gli identificativi prima che i prompt escano dal sistema core.
- Limitazione della finalità: separare i “dati usati per erogare la funzionalità” dai “dati usati per migliorare il modello”. Ogni finalità deve avere una propria base giuridica ed essere chiaramente documentata.
- Impostazioni predefinite configurabili: prevedere controlli a livello di tenant, ad esempio: “Consenti l’uso dei miei dati per migliorare il modello IA globale: Sì/No”. Le impostazioni predefinite devono essere conservative, con esclusione predefinita, salvo una solida giustificazione.
- Tracciabilità: registrare quali dati sono stati usati in quale attività di addestramento, in base a quale base giuridica e per quale tenant. È un requisito essenziale per audit e richieste degli interessati.
Zenith Blueprint: roadmap in 30 fasi per auditor di Clarysec fornisce un percorso strutturato per incorporare questi requisiti molto prima di scrivere una singola riga di codice. Il percorso parte dalla governance:
- Fase di fondazione, fase 2: comprendere le parti interessate: questa fase impone di identificare tutti gli stakeholder, incluse le autorità di controllo dell’UE. Come evidenzia Zenith Blueprint, i loro requisiti includono “trattamento lecito dei dati personali, notifica delle violazioni entro 72 ore [e] diritti degli interessati”.
- Fase di audit e miglioramento, fase 24: costruire e mantenere un registro dei requisiti legali e normativi: collaborare con i team legali per creare un repository centrale di tutte le leggi applicabili, comprendendo come GDPR, NIS2, DORA e altri requisiti interagiscano con la postura di sicurezza dell’IA.
Con queste basi, è possibile passare all’attuazione tecnica con maggiore sicurezza.
Proteggere il carburante: dati di addestramento leciti e minimizzati
La domanda più delicata nella conformità dell’IA è semplice: “Possiamo usare i dati dei clienti per addestrare i nostri modelli?”
La risposta richiede una strategia multilivello incentrata su base giuridica, minimizzazione dei dati e misure tecniche di sicurezza come la pseudonimizzazione.
Base giuridica e finalità trasparente
Secondo ISO/IEC 27701, occorre identificare e documentare le finalità del trattamento e stabilire una base giuridica per ciascuna.
- Per l’erogazione della funzionalità (ad esempio, ricerca IA all’interno di un singolo tenant): la base giuridica è in genere esecuzione di un contratto o interesse legittimo. Deve essere documentata nel registro delle attività di trattamento (RoPA).
- Per il miglioramento del modello globale (tra tenant): spesso è necessario un consenso esplicito oppure un interesse legittimo giustificato con estrema attenzione e accompagnato da un meccanismo di opposizione o esclusione chiaro e semplice. La trasparenza nell’informativa privacy e nell’interfaccia utente del prodotto è imprescindibile.
Misure tecniche di sicurezza: pseudonimizzazione e mascheramento
La vera anonimizzazione è difficile da ottenere senza compromettere l’utilità dei dati. Un approccio più pratico e coerente con il GDPR è la pseudonimizzazione: sostituire gli identificativi personali con identificativi artificiali. Questo riduce il rischio mantenendo il valore dei dati per l’addestramento del modello.
Questo processo è un controllo fondamentale. In Zenith Blueprint, la fase 20 tratta specificamente il mascheramento dei dati, collegandolo direttamente ai principi degli articoli 25 e 32 del GDPR. È una misura di sicurezza richiesta, non solo una buona pratica.
La Politica di mascheramento dei dati e pseudonimizzazione di Clarysec rende operativo questo principio assegnando responsabilità chiare:
“Il DPO deve validare la conformità ai criteri di pseudonimizzazione del GDPR e coordinarsi con la funzione legale su eventuali requisiti normativi di comunicazione relativi a violazioni dei dati o fallimenti dei controlli di mascheramento.”
- Dalla sezione ‘Applicazione e conformità’, clausola della politica 8.4.
Per i team di sviluppo, ciò significa applicare script automatizzati per mascherare o pseudonimizzare nomi, e-mail, numeri di telefono e altri identificativi diretti prima che i dati entrino nell’ambiente di addestramento. Significa anche istituire un processo formale di convalida con il DPO per assicurare la robustezza della tecnica.
La minaccia nascosta: mettere in sicurezza i dati di test e gli esperimenti IA
Le violazioni dei dati reali raramente iniziano in un ambiente di produzione curato e sottoposto a hardening. Nascono negli angoli dimenticati dell’infrastruttura:
- Ambienti di staging “sicuri” con copie di dati di produzione sanificate in modo insufficiente.
- Esportazioni CSV “temporanee” di dati dei clienti inviate agli ingegneri ML per esperimenti locali.
- Script QA che usano contenuti grezzi degli utenti per testare prompt LLM.
È esattamente qui che ha avuto origine lo scenario critico descritto nell’introduzione. La Politica sui dati di test e sugli ambienti di test per PMI di Clarysec affronta direttamente questo rischio:
“Rispettare le normative applicabili in materia di protezione dei dati (ad esempio, GDPR, NIS2), assicurando che tutti i dati di test siano trattati in modo lecito, corretto e sicuro.”
- Dalla sezione ‘Obiettivi’, clausola della politica 3.4.
La politica deve essere supportata da controlli pratici. Nessun dato personale di produzione deve mai esistere in ambienti non di produzione senza un solido mascheramento o una solida pseudonimizzazione. Gli ambienti di test devono usare chiavi API LLM separate e con privilegi inferiori, soggette a rigorosi limiti di frequenza. Deve inoltre essere stabilito in modo esplicito che i prompt di test non includano mai identificativi di clienti reali.
Rafforzare il nucleo: controllo granulare degli accessi per le pipeline IA
Le funzionalità LLM si appoggiano agli archivi di dati, ai log e alle pipeline di addestramento più sensibili. Il controllo degli accessi di base è quindi essenziale per la conformità al GDPR. I controlli ISO/IEC 27001:2022 8.3 e 8.2 sono i pilastri della difesa. Zenith Controls: guida alla conformità incrociata di Clarysec fornisce il modello per applicarli in modo efficace.
Controllo ISO/IEC 27001:2022 8.3: restrizione dell’accesso alle informazioni
Questo controllo mira a garantire che l’accesso alle informazioni sia concesso rigorosamente secondo il principio del need-to-know. Per un ambiente di addestramento LLM, significa che data scientist, ingegneri ML e processi automatizzati devono accedere solo ai dati specifici di cui hanno bisogno, e a nient’altro.
Come descritto in Zenith Controls, questo controllo è strettamente connesso ad altri controlli:
- Collegamento a 5.9 (Inventario delle informazioni e degli altri asset associati) e 5.12 (Classificazione delle informazioni): non è possibile limitare gli accessi se non si sa quali dati si possiedono e quanto siano sensibili. Il dataset di addestramento IA deve essere inventariato e classificato come altamente riservato, secondo un processo disciplinato dalla Politica di classificazione ed etichettatura dei dati per PMI.
- Collegamento a 8.5 (Autenticazione sicura): le restrizioni di accesso sono inefficaci senza una forte verifica dell’identità. Ogni utente e account di servizio che accede ai dati di addestramento deve essere autenticato in modo sicuro, preferibilmente con MFA.
Controllo ISO/IEC 27001:2022 8.2: diritti di accesso privilegiato
Gli ingegneri ML, gli SRE e i data scientist hanno bisogno di accessi elevati. Questi account privilegiati sono le “chiavi del regno” e rappresentano obiettivi primari. Il controllo 8.2 richiede che tali diritti siano gestiti con il massimo rigore.
Secondo Zenith Controls, le relazioni chiave sono:
- Collegamento a 8.15 (Registrazione) e 8.16 (Attività di monitoraggio): tutte le attività privilegiate devono essere registrate e monitorate. Se un data scientist tenta improvvisamente di esportare l’intero dataset di addestramento, deve scattare immediatamente un’allerta.
- Collegamento a 6.7 (Lavoro da remoto): se il team IA lavora da remoto, gli accessi privilegiati devono transitare attraverso canali sicuri e monitorati, come una VPN con rigorosi controlli di sessione.
La prospettiva dell’auditor: come dimostrare che i controlli IA funzionano
Applicare i controlli è solo metà del lavoro. Occorre dimostrarne l’efficacia. Auditor formati su quadri di riferimento diversi cercheranno evidenze specifiche.
| Tipo di auditor | Focus del quadro di riferimento | Cosa richiederà (evidenze) |
|---|---|---|
| Auditor ISO/IEC 27001 | ISO/IEC 27007:2020 | Mostrami la politica di controllo degli accessi per l’ambiente di addestramento IA. Fornisci i log del processo di riesame degli accessi degli ultimi 12 mesi. Dimostra come viene effettuato il provisioning di un nuovo ingegnere ML con accesso secondo il principio del privilegio minimo. |
| Auditor COBIT | COBIT 2019 (DSS05) | Devo vedere la matrice di controllo degli accessi basato sui ruoli (RBAC) del team di data science. Fornisci report degli strumenti di monitoraggio che mostrino allerte per tentativi di accesso anomali al data lake di addestramento. |
| Valutatore NIST | NIST SP 800-53A (AC-3, AC-6) | Esaminiamo la configurazione di sistema dei server che ospitano i dati di addestramento. Voglio verificare che le liste di controllo degli accessi (ACL) applichino tecnicamente le politiche documentate. Mostrami evidenze del fatto che le sessioni privilegiate vengano terminate dopo un periodo di inattività. |
| Auditor GDPR/privacy | ISO/IEC 27701:2021 | Fornisci la valutazione d’impatto sulla protezione dei dati (DPIA) relativa alla funzionalità IA. Mostrami le registrazioni del consenso degli interessati i cui dati sono presenti nel set di addestramento. Come tratti una richiesta di “diritto alla cancellazione” per dati contenuti in un modello addestrato? |
La corretta applicazione dei controlli 8.2 e 8.3 produce benefici ampi. Zenith Controls mostra una mappatura diretta verso i requisiti del GDPR (articoli 5, 25, 32), NIS2 (articolo 21), DORA (articolo 10) e NIST SP 800-53 (AC-3, AC-6), consentendo di soddisfare più quadri di riferimento con un’unica attuazione dei controlli.
Il paradosso del “diritto all’oblio”: gestire i diritti degli interessati nell’IA
L’articolo 17 del GDPR, il “diritto alla cancellazione”, presenta una sfida tecnica specifica per l’IA. Come cancellare i dati di una persona dopo che sono stati usati per addestrare un modello ampio e complesso? Spesso è tecnicamente impraticabile far “disapprendere” al modello singoli punti dati.
È qui che le scelte iniziali di progettazione diventano la migliore difesa. Non esiste una soluzione perfetta, ma le strategie pratiche e sostenibili includono:
- Prima la pseudonimizzazione: se i dati di addestramento sono stati correttamente pseudonimizzati, il collegamento con l’interessato è già interrotto nel corpus di addestramento. È quindi possibile cancellare i dati personali dai sistemi sorgente e il collegamento nella tabella delle chiavi di pseudonimizzazione.
- Segregazione dei dati per l’addestramento: ove possibile, mantenere separati i dataset di addestramento per tenant. Ciò rende praticabile la rimozione dei dati senza riaddestrare l’intero ecosistema dei modelli.
- Riaddestramento pianificato del modello: la DPIA deve affrontare questo rischio. La misura di mitigazione può consistere nell’impegno a riaddestrare periodicamente il modello da zero usando un dataset aggiornato che escluda i dati degli utenti che hanno richiesto la cancellazione.
La sezione di Zenith Blueprint sulla cancellazione delle informazioni (fase 20, relativa al controllo 8.10) collega esplicitamente questa capacità tecnica agli articoli 17 e 5(1)(e) del GDPR, richiedendo processi verificabili per cancellare in modo sicuro i dati quando non sono più necessari.
Mettere in sicurezza la catena di fornitura IA: sviluppo esternalizzato e LLM di terze parti
Poche società SaaS costruiscono tutto internamente. Potresti usare l’API LLM di un hyperscaler o ingaggiare un partner di sviluppo esternalizzato. Questo introduce rischi nella catena di fornitura.
Zenith Blueprint, nella fase 22 sullo sviluppo esternalizzato, evidenzia questo rischio e il suo collegamento con gli articoli 28 e 32 del GDPR. Come indicato nel blueprint:
“Un’area spesso trascurata è la formazione e sensibilizzazione. Gli sviluppatori esternalizzati possono essere competenti, ma sono formati sulle pratiche di programmazione sicura? Conoscono le tue politiche? Sono consapevoli dei quadri di conformità che devi rispettare, GDPR, DORA, NIS2…?”
Per qualsiasi fornitore LLM esterno o partner di sviluppo, la due diligence è critica. L’accordo sul trattamento dei dati (DPA) deve coprire espressamente le finalità di trattamento correlate all’IA, le categorie di dati e i divieti per il fornitore di usare i tuoi dati per addestrare i propri modelli. Devi verificare che applichi misure di sicurezza allineate all’articolo 32 del GDPR. La catena di fornitura IA deve essere verificabile quanto l’infrastruttura core.
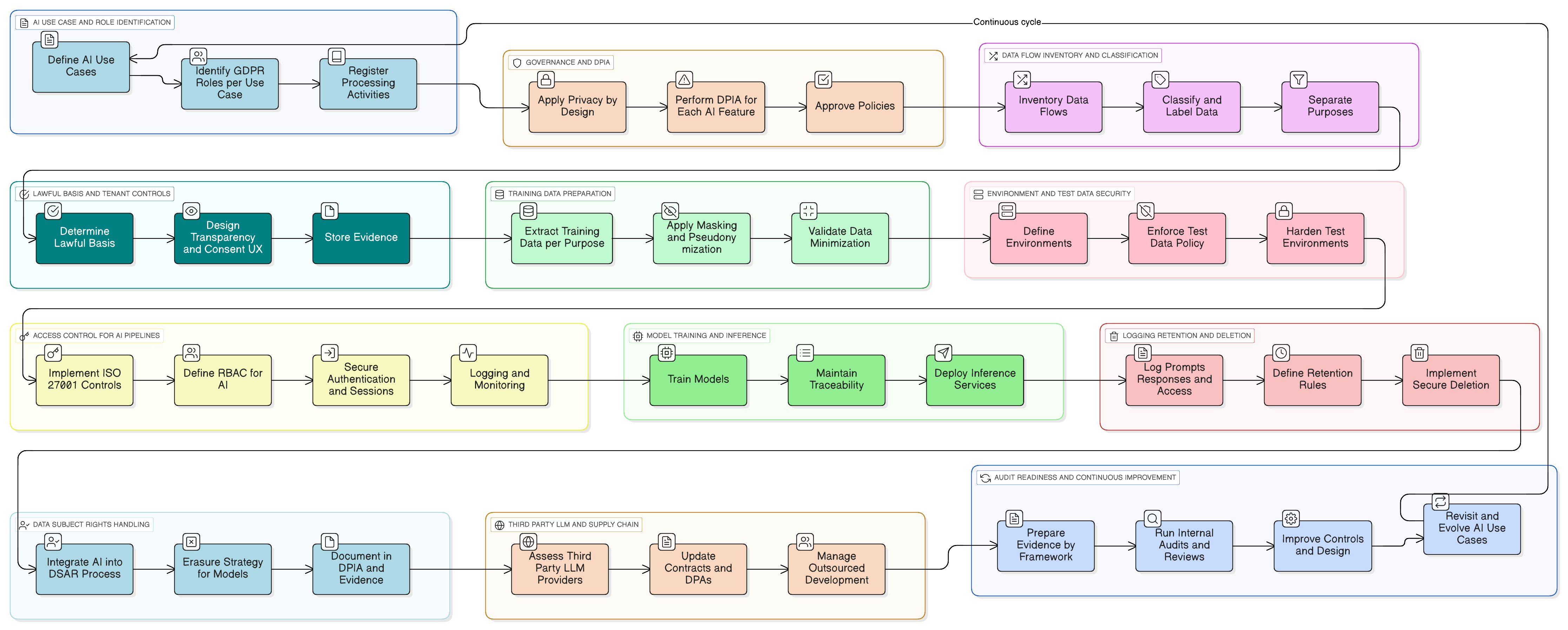
Dalla teoria alla pratica: un esempio concreto di funzionalità IA pronta per il GDPR
Rendiamo il tutto concreto. Immagina di aggiungere un assistente IA che sintetizza conversazioni di assistenza clienti, suggerisce bozze di risposta e apprende dai ticket precedenti per migliorare.
Di seguito un modello pratico di attuazione basato sul toolkit di Clarysec:
- Classificazione ed etichettatura: tutti i ticket di assistenza sono classificati come “Riservato” in base alla Politica di classificazione ed etichettatura dei dati per PMI, in linea con gli obblighi di trattamento dei dati previsti da GDPR e DORA.
- Mascheramento prima del LLM: un servizio di mascheramento intercetta i dati prima dell’invio al LLM. Rimuove o sostituisce nomi, e-mail, numeri di telefono e altri dati personali. L’intero processo è disciplinato dalla Politica di mascheramento dei dati e pseudonimizzazione, con il DPO che valida la metodologia.
- Controlli di accesso per prompt e log: solo i ruoli autorizzati (ad esempio, responsabile del prodotto IA) possono accedere ai log grezzi dei prompt. Questo è realizzato applicando il controllo ISO 27001:2022 8.3 (restrizione dell’accesso alle informazioni) per l’accesso generale e il controllo 8.2 (diritti di accesso privilegiato) per qualsiasi visibilità a livello amministrativo, come mappato in Zenith Controls.
- Consenso per il corpus di dati di addestramento: la pipeline di addestramento acquisisce solo dati mascherati. È disponibile un’impostazione di configurazione a livello di tenant, “Consenti l’uso dei miei dati mascherati per migliorare il modello IA globale: Sì/No”, con valore predefinito “No”.
- Conservazione e cancellazione: i log dei prompt sono conservati solo per il tempo necessario. Quando un tenant disabilita la funzionalità o risolve il contratto, viene attivato un flusso di lavoro per cancellare in modo sicuro o anonimizzare i log IA e le voci di addestramento correlate, seguendo il processo definito nell’attuazione di Zenith Blueprint per il controllo 8.10 (cancellazione delle informazioni).
Quando arrivano gli auditor, puoi illustrare i diagrammi dei flussi di dati della funzionalità, le politiche specifiche che la governano e le evidenze tecniche provenienti da sistemi, log degli accessi, configurazioni delle attività e flussi di lavoro di cancellazione. In questo modo dimostri la conformità operativa.
Piano d’azione: dall’IA ad hoc all’IA pronta per l’audit
Non è necessario smontare il prodotto, ma serve un approccio strutturato e sostenibile. Ecco un piano d’azione sintetico:
- Inventariare casi d’uso IA e flussi di dati: identificare ogni punto in cui vengono usati LLM: funzionalità rivolte ai clienti, strumenti interni ed esperimenti. Mappare quali dati vanno dove, con quale base giuridica e chi vi accede. Usare la fase di fondazione di Zenith Blueprint per assicurare che il registro normativo copra tutti i requisiti GDPR, NIS2 e DORA correlati all’IA.
- Stabilire prima la governance: prima di sviluppare, eseguire una valutazione d’impatto sulla protezione dei dati (DPIA) per ogni funzionalità IA. Documentarne finalità, base giuridica e rischi. Implementare politiche fondamentali come la Politica di protezione dei dati e privacy per PMI e la Politica per la sicurezza delle informazioni per PMI.
- Mettere sotto controllo dati e accessi: applicare controlli tecnici robusti. Adottare la Politica di mascheramento dei dati e pseudonimizzazione e la Politica sui dati di test e sugli ambienti di test per PMI. Usare Zenith Controls per applicare e documentare i controlli ISO 27001:2022 8.2 e 8.3 per tutti gli archivi dati e le pipeline IA.
- Integrare i diritti degli interessati nei flussi di lavoro IA: aggiornare le procedure per le richieste di esercizio dei diritti degli interessati (DSAR) e di cancellazione includendo i dati correlati all’IA. Documentare la strategia per gestire le richieste di cancellazione nel contesto dei modelli addestrati, con focus su pseudonimizzazione e pianificazione dei riaddestramenti del modello.
- Portare sotto controllo la catena di fornitura IA: aggiornare i DPA con fornitori LLM di terze parti e sviluppatori esternalizzati. Assicurare che i contratti vietino esplicitamente l’uso non autorizzato dei dati e richiedano misure di sicurezza robuste. Verificare che i team esterni siano formati sulle politiche di gestione dei dati.
Innovare con fiducia
L’intersezione tra IA e GDPR è la nuova frontiera della conformità. Adottando un approccio strutturato e basato sul rischio, è possibile sfruttare il potenziale trasformativo dell’intelligenza artificiale senza compromettere l’impegno verso la protezione dei dati e la tutela della privacy.
Clarysec fornisce la mappa, gli strumenti e le competenze per guidarti in questo percorso. Utilizzando:
- Zenith Blueprint: roadmap in 30 fasi per auditor per un’attuazione graduale dei controlli allineati al GDPR per l’IA.
- Zenith Controls: guida alla conformità incrociata per unificare i controlli ISO 27001:2022 con i requisiti di GDPR, NIS2, DORA e NIST.
- Politiche pronte per l’uso in produzione, come la Politica di protezione dei dati e privacy per PMI, la Politica di mascheramento dei dati e pseudonimizzazione e la Politica sui dati di test e sugli ambienti di test per PMI, per codificare le regole e soddisfare gli auditor.
Puoi passare da esperimenti IA ad hoc a una capacità IA pronta per l’audit, capace di ispirare fiducia in autorità di controllo, auditor e clienti aziendali esigenti. Puoi continuare a innovare con gli LLM e dormire sonni più tranquilli.
Se stai pianificando o già gestendo funzionalità IA nel tuo prodotto SaaS, il prossimo passo è semplice. Scarica gli esempi dei nostri toolkit o prenota una demo per scoprire come Clarysec può aiutarti a costruire un programma IA non solo potente, ma anche dimostrabilmente privato e sicuro fin dalla progettazione.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council