Mappatura NIST della risposta agli incidenti per gli audit 2026
Sono le 07:42 di un martedì. Anya, CISO di una piattaforma fintech in rapida crescita, vede il primo allarme: impossible travel su un account amministrativo. Segue una raffica di accessi non riusciti, poi una sessione riuscita da un dispositivo non gestito. Cinque minuti dopo, il supporto clienti segnala che gli utenti non riescono ad accedere a un flusso di lavoro SaaS critico. Alle 08:10, la dashboard cloud mostra chiamate API anomale verso un bucket di archiviazione che potrebbe contenere dati personali.
Il team di sicurezza agisce rapidamente. Il SIEM genera l’allarme, l’ingegnere cloud revoca una sessione e il titolare del servizio avvia il ripristino dell’accesso. Ma la vera crisi non è solo tecnica. È una crisi di governance.
Anya deve rispondere a tre domande prima che sia trascorsa la prima ora.
Primo: si tratta di un incidente di sicurezza delle informazioni, di una violazione dei dati personali, di un incidente significativo ai sensi di NIS2 o di un incidente grave connesso alle TIC ai sensi di DORA?
Secondo: chi deve essere informato, entro quando e con quali evidenze?
Terzo: l’organizzazione può dimostrare che il proprio processo di risposta agli incidenti si è svolto effettivamente come progettato?
È in quel momento che molte organizzazioni scoprono la differenza tra avere un piano di risposta agli incidenti e avere un sistema di governance della risposta agli incidenti. La risposta agli incidenti secondo NIST SP 800-61 e NIST CSF 2.0 non è più solo materia di playbook SOC. Nel 2026 si collega direttamente alla responsabilità del consiglio di amministrazione, agli audit ISO/IEC 27001:2022, alla segnalazione per fasi prevista da NIS2, alla resilienza operativa di DORA, alle decisioni sulle violazioni dei dati personali ai sensi del GDPR e alla responsabilità dei fornitori.
I programmi più solidi non creano percorsi di risposta separati per ogni quadro di riferimento. Usano NIST CSF 2.0 come mappa operativa, ISO/IEC 27001:2022 come ossatura del sistema di gestione e un unico modello di evidenze in grado di supportare contemporaneamente NIS2, DORA e GDPR. Questo è l’approccio Clarysec: decisioni guidate dalle politiche, flussi di lavoro testati tramite esercitazioni tabletop, pacchetti di evidenze pronti per le autorità di regolamentazione e mappatura trasversale tra quadri di riferimento tramite Zenith Blueprint: la roadmap in 30 passi per l’auditor e Zenith Controls: la guida alla conformità trasversale.
Il problema del 2026: un incidente, molti regimi di responsabilità
L’incidente che Anya sta affrontando non è un singolo problema di conformità. È un insieme di percorsi decisionali sovrapposti.
Se l’organizzazione fornisce servizi di cloud computing, SaaS, servizi gestiti, Managed Security Services, DNS, data center, servizi fiduciari o altri servizi di infrastruttura digitale, NIS2 può applicarsi. La classificazione come soggetto essenziale o importante dipende da settore, dimensioni e recepimento nazionale, ma la direzione è chiara: la gestione degli incidenti è ora una responsabilità manageriale regolamentata.
Se l’organizzazione è un’entità finanziaria, DORA può costituire il principale corpus di regole sulla resilienza operativa. DORA si applica dal 17 gennaio 2025 e copre la gestione dei rischi connessi alle TIC, la segnalazione degli incidenti gravi connessi alle TIC, i test di resilienza operativa, la condivisione delle informazioni, il rischio TIC di terze parti e la vigilanza sui fornitori terzi critici di servizi TIC. Per le entità finanziarie incluse nel perimetro che ricadono anche in NIS2, DORA opera come quadro settoriale specifico per gli obblighi sovrapposti di rischio TIC e segnalazione degli incidenti.
Se dati personali sono stati consultati, alterati, persi, distrutti o divulgati, il GDPR entra nell’albero decisionale della risposta agli incidenti. Il GDPR definisce una violazione dei dati personali come una violazione della sicurezza che comporta, accidentalmente o in modo illecito, la distruzione, la perdita, la modifica, la divulgazione non autorizzata o l’accesso ai dati personali. Il GDPR richiede inoltre responsabilizzazione: il titolare del trattamento deve poter dimostrare la conformità ai principi del trattamento, inclusi integrità e riservatezza.
Se l’azienda è certificata ISO/IEC 27001:2022, o si sta preparando alla certificazione, l’incidente diventa evidenza del SGSI. Gli auditor esamineranno campo di applicazione, obblighi legali, ruoli, trattamento del rischio, selezione dei controlli, esecuzione operativa, informazioni documentate, lezioni apprese e miglioramento continuo. Le clausole ISO/IEC 27001:2022 da 4.1 a 4.4 richiedono che il SGSI rifletta contesto, parti interessate, obblighi, campo di applicazione e interazioni tra processi. Le clausole da 5.1 a 5.3 richiedono leadership, responsabilità e attribuzione delle responsabilità. Le clausole da 6.1.1 a 6.1.3 richiedono valutazione del rischio per la sicurezza delle informazioni, trattamento del rischio e Dichiarazione di Applicabilità. Le clausole da 8.1 a 8.3 richiedono operatività controllata, evidenze che i processi siano stati eseguiti come pianificato, controllo dei processi esternalizzati e attuazione del trattamento del rischio.
Il problema organizzativo non è la mancanza di quadri di riferimento. È la mancanza di un unico modello operativo che trasformi i quadri di riferimento in decisioni tempestive ed evidenze affidabili.
Usare NIST CSF 2.0 come linguaggio comune
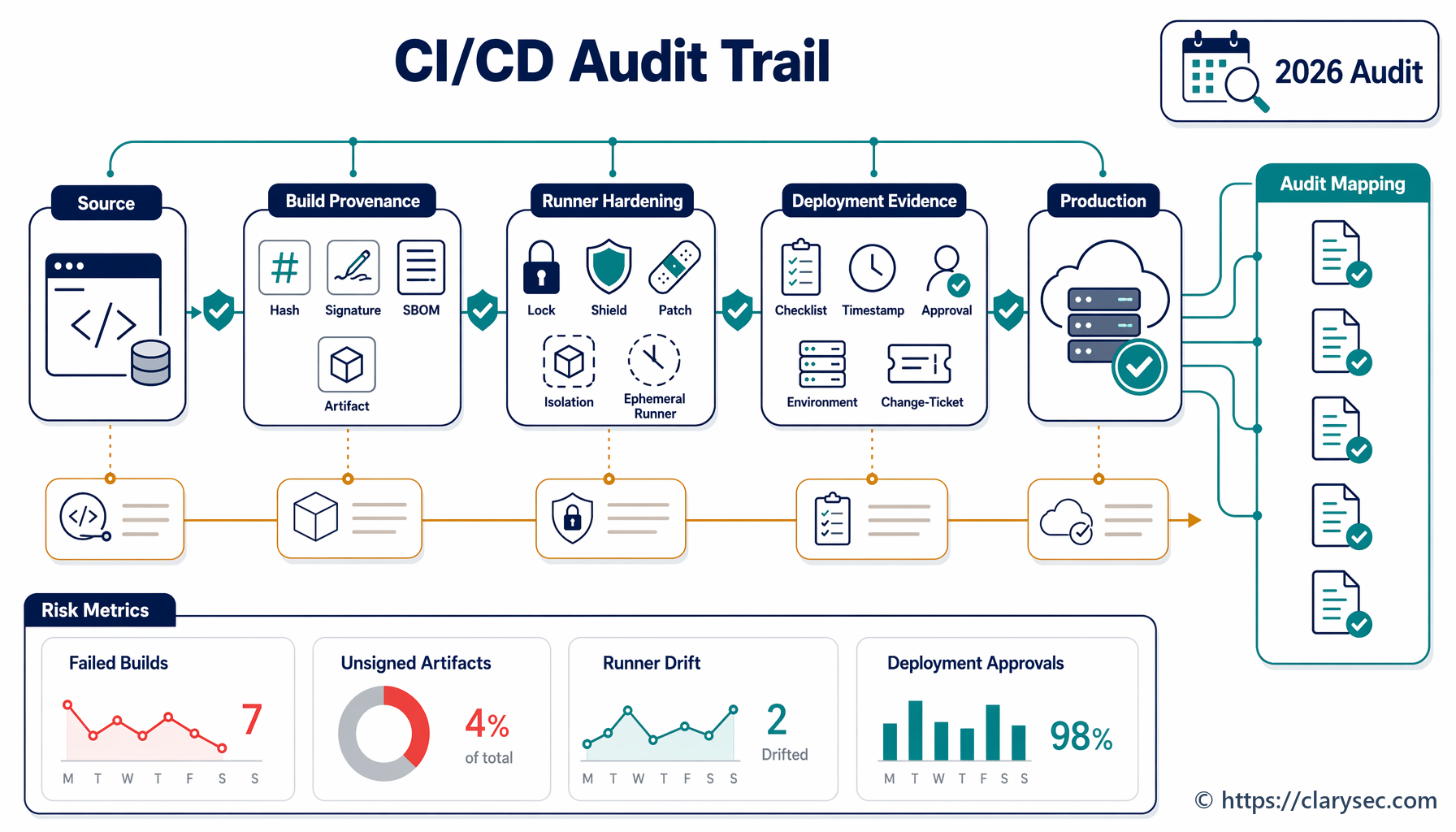
NIST CSF 2.0 è utile perché fornisce a direzione, sicurezza, funzione legale, privacy, operations e fornitori un linguaggio comune per gli esiti di cybersecurity. La funzione GOVERN è particolarmente importante per la risposta agli incidenti perché obbliga le organizzazioni ad affrontare supervisione, politiche, strategia di rischio, ruoli e rischio della catena di fornitura prima che inizi la crisi.
Per la risposta agli incidenti, CSF 2.0 collega la governance al ciclo di vita operativo: IDENTIFY, PROTECT, DETECT, RESPOND e RECOVER. Questa struttura aiuta a trasformare un incidente complesso e rumoroso in un flusso di evidenze controllato.
| Domanda sulla risposta agli incidenti | Area di esito CSF 2.0 | Evidenze di conformità prodotte |
|---|---|---|
| Chi è titolare della decisione? | GOVERN, inclusi GV.RR, GV.OV e GV.PO | RACI, registrazione del responsabile dell’incidente, aggiornamenti alla direzione, notifiche al consiglio di amministrazione |
| Quali asset e servizi sono interessati? | IDENTIFY, inclusa la visibilità su asset e rischi | Inventario degli asset, mappa dei servizi, inventario dei dati, elenco dei fornitori critici |
| Quali controlli hanno fallito o funzionato? | PROTECT, inclusi accessi, sicurezza dei dati, configurazione e backup | Log MFA, registrazioni degli accessi privilegiati, registrazioni dei backup, baseline di configurazione |
| Come è stato rilevato l’evento? | DETECT, inclusi DE.CM e DE.AE | Allarmi SIEM, allarmi EDR, log cloud, note di correlazione, registrazione della dichiarazione dell’incidente |
| Come è stato gestito? | RESPOND, inclusi RS.MA, RS.AN, RS.CO e RS.MI | Ticket dell’incidente, classificazione di gravità, cronologia, registro delle decisioni, azioni di contenimento |
| Come è stato ripristinato il servizio? | RECOVER, inclusi RC.RP e RC.CO | Esecuzione del ripristino, convalida dei backup, evidenze del servizio ripristinato, comunicazioni, rapporto di chiusura |
I profili organizzativi di CSF 2.0 rendono questo approccio operativo. Un profilo attuale mostra la reale capacità di risposta agli incidenti dell’organizzazione, incluse lacune, ambiguità e soluzioni alternative. Un profilo target definisce lo stato desiderato, ad esempio classificazione della gravità entro un’ora, decisioni di notifica documentate, conservazione delle evidenze, coordinamento con terze parti e pacchetti di reporting pronti per le autorità di regolamentazione.
Per la fintech di Anya, il profilo attuale ha evidenziato uno schema ricorrente: strumenti solidi, governance decisionale debole. Il profilo target si è concentrato su esiti concreti di CSF 2.0, tra cui:
- RS.MA-01, il piano di risposta agli incidenti viene eseguito in coordinamento con le terze parti pertinenti una volta dichiarato l’incidente.
- RS.MA-02, le segnalazioni di incidente vengono sottoposte a triage e validate.
- RS.MA-03, gli incidenti vengono categorizzati e prioritizzati.
- RS.MA-04, gli incidenti vengono sottoposti a escalation o elevati secondo necessità.
- RS.AN-03, viene eseguita l’analisi per stabilire cosa sia accaduto durante un incidente e la causa radice.
- RS.AN-06, le azioni eseguite durante un’indagine sono registrate e l’integrità e la provenienza delle registrazioni sono preservate.
- RS.AN-07, i dati e i metadati dell’incidente sono raccolti e la loro integrità e provenienza sono preservate.
- RS.CO-02, gli stakeholder interni ed esterni sono informati degli incidenti.
- RS.MI-01, gli incidenti sono contenuti.
- RS.MI-02, gli incidenti sono eradicati.
- RC.RP-03, l’integrità dei backup e degli altri asset di ripristino è verificata prima del loro utilizzo per il ripristino.
Un quadro di riferimento da solo non costituisce un programma verificabile in audit. Gli esiti devono essere integrati in un sistema di gestione, ed è qui che ISO/IEC 27001:2022 fornisce l’ossatura.
Ancorare la risposta agli incidenti in ISO/IEC 27001:2022
NIST fornisce un linguaggio pratico per la gestione degli incidenti. ISO/IEC 27001:2022 fornisce la disciplina operativa che gli auditor si aspettano. Il SGSI trasforma la risposta agli incidenti da un insieme di playbook a un processo governato con campo di applicazione, titolarità, trattamento del rischio, valutazione delle prestazioni e miglioramento.
Il gruppo di controlli dell’Annex A più rilevante è:
| Controllo ISO/IEC 27001:2022 Annex A | Nome del controllo | Finalità per la risposta agli incidenti |
|---|---|---|
| A.5.24 | Pianificazione e preparazione della gestione degli incidenti di sicurezza delle informazioni | Stabilisce il piano, i ruoli, l’escalation e il modello di comunicazione |
| A.5.25 | Valutazione e decisione sugli eventi di sicurezza delle informazioni | Definisce triage, classificazione e criteri decisionali |
| A.5.26 | Risposta agli incidenti di sicurezza delle informazioni | Guida contenimento, eradicazione, ripristino e comunicazioni |
| A.5.27 | Apprendimento dagli incidenti di sicurezza delle informazioni | Converte le lezioni apprese in azioni correttive e miglioramento |
| A.5.28 | Raccolta delle evidenze | Preserva affidabilità, provenienza e utilizzabilità legale delle evidenze |
La guida Zenith Controls di Clarysec mappa questi riferimenti di controllo ISO/IEC 27002:2022 ad altri standard, aspettative di audit e obblighi di conformità correlati. Non è un quadro di controllo separato. È una guida alla conformità trasversale che aiuta le organizzazioni a comprendere come le stesse attività di controllo supportino più esigenze di assurance.
Lo Zenith Blueprint, fase Controls in Action, Step 23, rende operativa la struttura portante della risposta agli incidenti:
Assicurarsi di disporre di un piano di risposta agli incidenti aggiornato (5.24), che copra preparazione, escalation, risposta e comunicazione. Definire cosa costituisce un evento di sicurezza soggetto a segnalazione (5.25) e come il processo decisionale viene attivato e documentato. Selezionare un evento recente o condurre un’esercitazione tabletop per validare il piano. Acquisire e registrare tutte le decisioni, i ruoli e le comunicazioni (5.26) e aggiornare il piano con le lezioni apprese (5.27). Confermare che siano in vigore procedure per preservare le evidenze forensi (5.28), inclusi snapshot dei log, backup e isolamento sicuro dei sistemi impattati.
Quel paragrafo è il ponte pratico tra la gestione degli incidenti secondo NIST e le evidenze di audit. Preparare la capacità, classificare l’evento, rispondere in modo controllato, apprendere dall’esito e preservare le evidenze.
Integrare gli obblighi di segnalazione nella prima ora
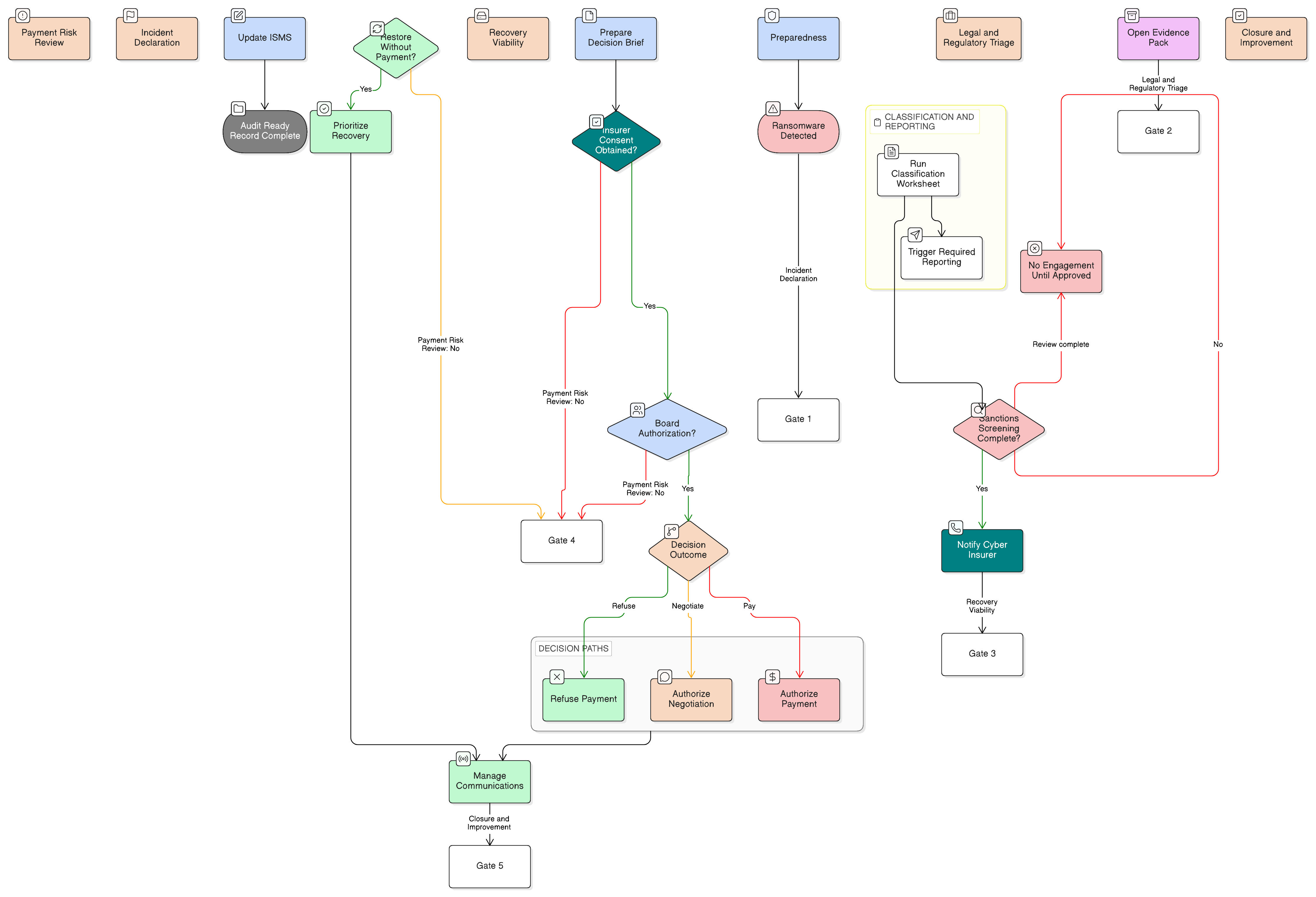
I programmi di risposta agli incidenti spesso falliscono nella prima ora non perché gli analisti non abbiano competenze, ma perché l’organizzazione non ha definito chi decide, quando viene assegnata la gravità, quali evidenze vengono preservate e quando vengono verificati i trigger legali.
Per le PMI, la Politica di risposta agli incidenti per PMI di Clarysec stabilisce una chiara aspettativa di governance:
Il direttore generale, con il contributo del fornitore IT, deve classificare tutti gli incidenti per gravità entro un’ora dalla notifica.
È un requisito efficace. Non significa che ogni fatto sia noto entro un’ora. Significa che l’organizzazione deve documentare una gravità iniziale, registrare l’incertezza e attivare l’escalation mentre i fatti sono ancora in evoluzione.
La stessa politica richiede anche che le tempistiche legali siano integrate nel processo:
Le tempistiche di risposta, inclusi il ripristino dei dati e gli obblighi di notifica, devono essere documentate e allineate ai requisiti legali, come il requisito del GDPR di notifica della violazione dei dati personali entro 72 ore.
Per gli ambienti aziendali complessi, la Politica di risposta agli incidenti di Clarysec ancora un modello di risposta più formale:
L’organizzazione deve mantenere un quadro di riferimento per la risposta agli incidenti centralizzato e multilivello, allineato a ISO/IEC 27035, composto dalle seguenti fasi di risposta definite:
La politica aziendale integra inoltre riferimenti temporali trasversali alle normative nella clausola 6.4.1:
GDPR Article 33 (notifica entro 72 ore all’autorità di controllo)
NIS2 Article 23 (notifica entro 24 ore dal momento in cui si viene a conoscenza dell’incidente)
DORA Article 17 (segnalazione degli incidenti gravi connessi alle TIC)
Questa è la differenza tra un playbook tecnico e un quadro di riferimento per la risposta agli incidenti pronto per la governance. I percorsi di segnalazione legali e regolamentari non si improvvisano durante una crisi. Sono attivati da punti di classificazione e decisione predefiniti.
Mappare la segnalazione NIS2 nel flusso di lavoro dell’incidente
NIS2 richiede ai soggetti essenziali e importanti di notificare senza ingiustificato ritardo al CSIRT o all’autorità competente gli incidenti significativi che incidono sulla fornitura dei servizi. Un incidente significativo comprende un incidente che ha causato o è in grado di causare una grave perturbazione operativa o una perdita finanziaria, oppure che ha interessato o è in grado di interessare altri causando danni materiali o immateriali considerevoli.
Il modello di segnalazione è per fasi.
| Fase NIS2 | Tempistica | Evidenze che il processo deve produrre |
|---|---|---|
| Preallarme | Entro 24 ore dalla conoscenza | Dichiarazione dell’incidente, attività malevola sospetta, verifica dell’impatto transfrontaliero, prima vista dei servizi interessati |
| Notifica dell’incidente | Entro 72 ore | Valutazione della gravità, analisi dell’impatto, indicatori di compromissione ove disponibili, registro delle incertezze |
| Relazioni intermedie | Su richiesta | Aggiornamenti di stato, azioni di contenimento, stato del ripristino, comunicazioni con l’autorità di regolamentazione |
| Relazione finale | Entro un mese dalla notifica dell’incidente | Gravità e impatto, minaccia probabile o causa radice, misure di mitigazione, impatto transfrontaliero |
| Relazione sull’avanzamento dell’incidente in corso | Se ancora in corso al momento della relazione finale | Relazione di avanzamento, poi relazione finale entro un mese dalla gestione |
NIS2 Article 21 richiede inoltre misure tecniche, operative e organizzative adeguate e proporzionate. La baseline richiesta include analisi dei rischi, trattamento degli incidenti, continuità operativa, sicurezza della catena di fornitura, sviluppo sicuro, trattamento delle vulnerabilità, valutazione dell’efficacia, igiene informatica e formazione, crittografia, sicurezza delle risorse umane, controllo degli accessi, gestione degli asset e, ove appropriato, autenticazione a più fattori e comunicazioni sicure.
NIS2 Article 20 inserisce gli organi di gestione nella catena di responsabilità. Devono approvare le misure di gestione dei rischi di cibersicurezza e vigilare sulla loro attuazione. Per la risposta agli incidenti, ciò significa che verbali del consiglio di amministrazione, approvazioni della direzione, registrazioni della formazione ed evidenze di escalation non sono artefatti amministrativi opzionali. Fanno parte della sostenibilità regolamentare.
Le sanzioni aggiungono urgenza. Per le violazioni di Article 21 o Article 23, i soggetti essenziali devono essere soggetti a sanzioni massime pari ad almeno 10 milioni di EUR o al 2% del fatturato annuo mondiale totale, se superiore. I soggetti importanti devono essere soggetti a sanzioni massime pari ad almeno 7 milioni di EUR o all'1,4% del fatturato annuo mondiale totale, se superiore.
La lezione pratica è semplice: se il momento di conoscenza, i criteri di gravità, l’escalation e le decisioni di segnalazione non sono registrati, il problema non riguarda più solo la maturità della risposta agli incidenti. Diventa un problema di evidenze regolamentari.
Trattare la gestione degli incidenti DORA come resilienza operativa
DORA cambia la discussione per le entità finanziarie perché la gestione degli incidenti è parte della resilienza operativa digitale, non solo delle operazioni di sicurezza.
Article 5 richiede all’organo di gestione di definire, approvare, vigilare e rimanere responsabile del quadro di riferimento per la gestione dei rischi connessi alle TIC. Article 6 amplia tale quadro in un sistema strutturato di gestione dei rischi connessi alle TIC. Article 17 richiede alle entità finanziarie di definire, stabilire e attuare un processo di gestione degli incidenti connessi alle TIC per rilevare, gestire e notificare gli incidenti connessi alle TIC. Il processo deve registrare gli incidenti connessi alle TIC e le minacce informatiche significative, identificare e affrontare le cause radice, utilizzare indicatori di preallarme, classificare gli incidenti per priorità, gravità e criticità dei servizi impattati, assegnare ruoli e responsabilità, stabilire comunicazione ed escalation, notificare clienti e media ove richiesto, segnalare almeno gli incidenti gravi all’alta direzione, informare l’organo di gestione e mantenere procedure di risposta per mitigare l’impatto e ripristinare operazioni sicure.
Article 18 richiede una classificazione basata su criteri quali clienti o controparti interessati, transazioni, impatto reputazionale, durata e indisponibilità, diffusione geografica, perdite di dati che incidono su disponibilità, autenticità, integrità o riservatezza, criticità dei servizi interessati e impatto economico. Article 19 richiede la segnalazione degli incidenti gravi connessi alle TIC all’autorità competente, consente la notifica volontaria di minacce informatiche significative e richiede la notifica ai clienti senza ingiustificato ritardo quando un incidente grave connesso alle TIC incide sugli interessi finanziari dei clienti.
Per la fintech di Anya, ciò significa che la registrazione dell’incidente richiede più di una cronologia SOC. Deve includere:
- Servizio impattato e criticità.
- Clienti, controparti o transazioni interessati.
- Durata dell’indisponibilità e diffusione geografica.
- Perdita di dati o impatto sull’integrità.
- Impatto economico.
- Visibilità dell’organo di gestione.
- Decisione di notifica ai clienti.
- Chiusura della causa radice.
- Ripristino di operazioni sicure.
- Coinvolgimento del fornitore ed evidenze contrattuali.
DORA estende inoltre la ricostruzione dell’incidente alla gestione dei fornitori. Gli Articles da 28 a 30 richiedono alle entità finanziarie di gestire il rischio TIC di terze parti, mantenere un registro degli accordi contrattuali relativi ai servizi TIC, valutare il rischio di concentrazione, condurre due diligence, garantire misure di sicurezza contrattuali, definire diritti di audit e ispezione, mantenere diritti di risoluzione e testare strategie di uscita per funzioni critiche o importanti. Se l’incidente coinvolge un fornitore cloud, un fornitore di servizi gestiti o un’integrazione SaaS, le evidenze DORA devono mostrare ruoli del fornitore, obblighi di conservazione dei log, supporto all’incidente, responsabilità di ripristino e cooperazione con le autorità di vigilanza.
Integrare subito la responsabilizzazione per le violazioni dei dati personali GDPR
Il GDPR si applica al trattamento automatizzato di dati personali e al trattamento non automatizzato che forma parte di un archivio. Può applicarsi alle organizzazioni stabilite nell’UE e ai titolari del trattamento o responsabili del trattamento non UE che offrono beni o servizi a persone nell’Unione o ne monitorano il comportamento.
Durante la risposta agli incidenti, l’analisi GDPR deve iniziare non appena potrebbero essere coinvolti dati personali. Attendere la causa radice tecnica è troppo tardi se il termine di 72 ore è già iniziato.
Il team di risposta deve rispondere a queste domande:
- Quali categorie di dati personali potrebbero essere coinvolte?
- Quali sistemi, applicazioni e attività di trattamento sono interessati?
- L’organizzazione agisce come titolare del trattamento, responsabile del trattamento o entrambi?
- I dati personali sono stati consultati, alterati, distrutti, persi o divulgati?
- Le misure di sicurezza di cifratura, tokenizzazione o pseudonimizzazione sono state efficaci?
- Qual è il rischio probabile per le persone fisiche?
- Chi ha preso la decisione di notifica e quando?
- Quali comunicazioni sono state inviate a titolari del trattamento, responsabili del trattamento, autorità di controllo o interessati?
- Se la notifica non è stata effettuata, qual è la motivazione documentata?
La responsabilizzazione di GDPR Article 5 è il punto chiave. Il titolare del trattamento deve poter dimostrare la conformità a principi quali liceità, correttezza, trasparenza, limitazione delle finalità, minimizzazione dei dati, limitazione della conservazione, integrità e riservatezza. Ciò significa che il registro delle violazioni, il registro delle decisioni, le evidenze tecniche e la cronologia delle comunicazioni fanno parte del sistema di controllo privacy; non sono note collaterali successive alla remediation.
Preservare le evidenze prima che il ripristino le distrugga
Un errore ricorrente nella risposta agli incidenti è un ripristino che distrugge le prove. I sistemi vengono riavviati. Il malware viene eliminato. I log vengono sovrascritti per rotazione. Gli account vengono modificati prima di acquisire snapshot. Dal punto di vista della disponibilità, il team può sentirsi efficace. Dal punto di vista di audit, autorità di regolamentazione, assicuratore o funzione legale, l’organizzazione può aver perso la capacità di dimostrare cosa sia accaduto.
La Politica per la raccolta delle evidenze e l’analisi forense di Clarysec afferma:
Un registro della catena di custodia deve accompagnare tutte le evidenze fisiche o digitali dal momento dell’acquisizione fino all’archiviazione o al trasferimento e deve documentare:
Per le PMI, la Politica per la raccolta delle evidenze e l’analisi forense per PMI attiva in modo esplicito il requisito del registro delle evidenze:
Ogni elemento di evidenza digitale deve essere registrato con:
Lo Zenith Blueprint, fase Controls in Action, Step 23, spiega il principio alla base del controllo ISO/IEC 27002:2022 5.28:
Quando si verifica un incidente di sicurezza delle informazioni, uno degli elementi più critici, ma spesso trascurati, della risposta è l’evidenza. Non log, non screenshot, non narrazioni informali, ma evidenze correttamente preservate, rispettose della catena di custodia e resistenti alla manomissione. Il controllo 5.28 riconosce che, nelle conseguenze di un incidente, ciò che si può dimostrare conta tanto quanto ciò che è effettivamente accaduto.
Un pacchetto di evidenze pronto per l’autorità di regolamentazione per l’incidente di Anya dovrebbe includere:
| Elemento di evidenza | Perché è rilevante | Proprietario |
|---|---|---|
| Registrazione della dichiarazione dell’incidente | Mostra il momento di conoscenza e avvia l’analisi delle tempistiche | Responsabile dell’incidente |
| Classificazione di gravità | Supporta escalation, prioritizzazione e decisioni di segnalazione | Responsabile della sicurezza o fornitore IT |
| Estratto dell’inventario degli asset e dei dati | Identifica servizi, sistemi, dati e criticità interessati | Titolare IT e responsabile privacy |
| Esportazioni dei log con marcature temporali | Supportano rilevazione, cronologia e analisi della causa radice | SOC o fornitore IT |
| Snapshot della traccia di audit cloud | Mostra attività API, attività delle identità e azioni sullo storage | Amministratore cloud |
| Registro della catena di custodia | Preserva affidabilità e tracciabilità delle evidenze | Responsabile forense |
| Notifica alla direzione | Mostra escalation e visibilità di governance | CISO o direttore generale |
| Registro delle decisioni verso l’autorità di regolamentazione | Mostra perché la notifica era o non era richiesta | Legale, DPO e CISO |
| Registrazione della comunicazione con il fornitore | Mostra cooperazione della terza parte e risposta contrattuale | Responsabile dei fornitori |
| Registrazione della comunicazione ai clienti | Supporta NIS2, DORA, GDPR e obblighi contrattuali | Responsabile delle comunicazioni |
| Registrazione delle lezioni apprese | Supporta il miglioramento continuo ISO/IEC 27001:2022 | Responsabile del SGSI |
La conservazione dei log deve essere esplicita. La Politica di registrazione e monitoraggio per PMI di Clarysec afferma:
I log di sicurezza relativi agli incidenti devono essere conservati per almeno 3 anni dalla data dell’incidente
Lo Zenith Blueprint, fase Controls in Action, Step 19, aggiunge una verità operativa:
La registrazione è la linfa vitale di qualsiasi ambiente IT sicuro. Senza di essa, gli incidenti restano invisibili, la responsabilizzazione svanisce e le relazioni di causa-effetto scompaiono nel nulla.
Risposta agli incidenti, registrazione, raccolta delle evidenze e reporting devono quindi essere progettati come un unico sistema di controllo connesso.
Gestire le prime 72 ore come uno sprint delle evidenze
Uno sprint pratico di 72 ore sulle evidenze aiuta i team a rispondere senza perdere verificabilità.
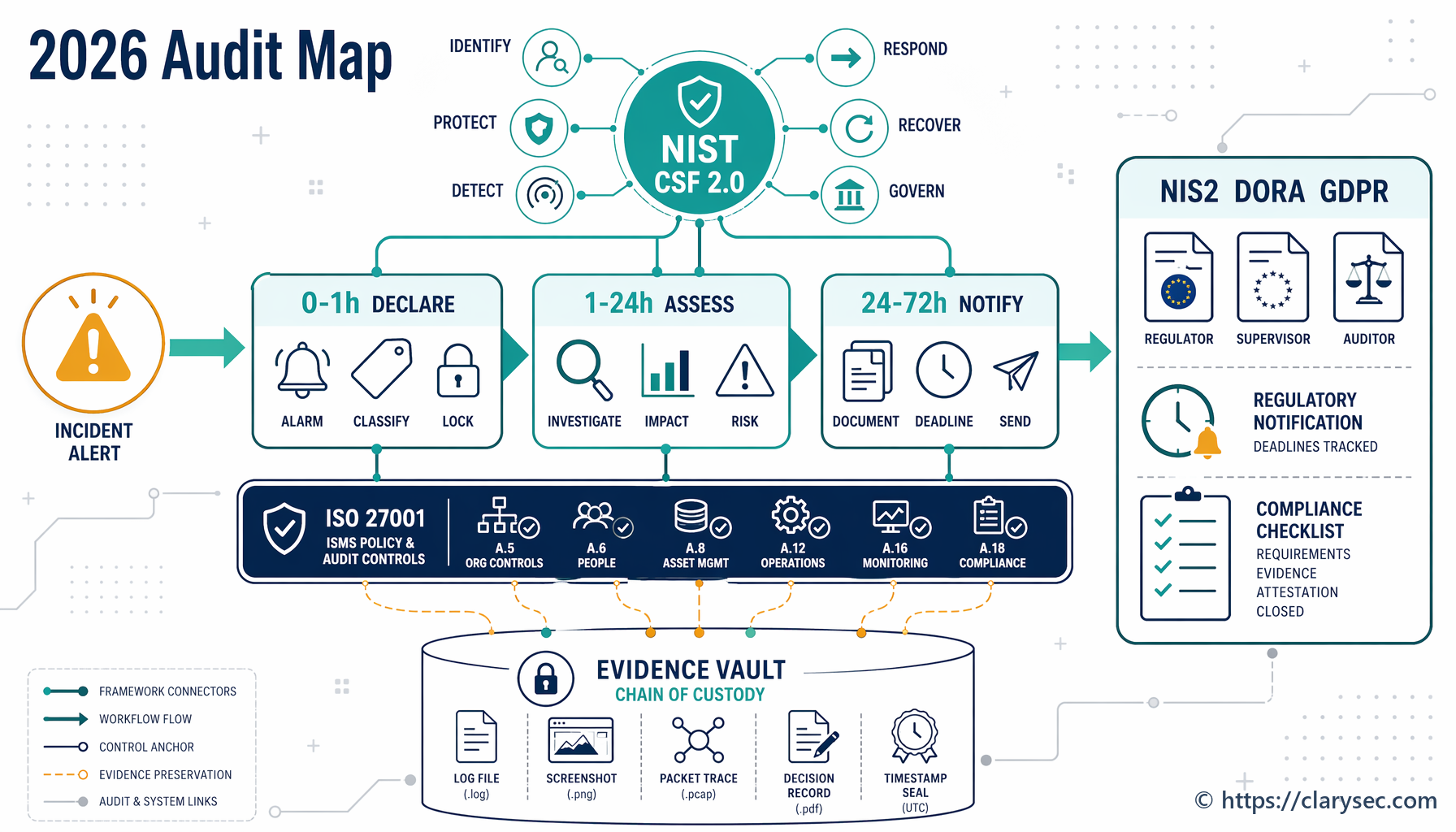
Ora 0-1: dichiarare, classificare e preservare
Aprire il ticket dell’incidente utilizzando la Politica di risposta agli incidenti. Assegnare un responsabile dell’incidente, un responsabile tecnico, un responsabile delle comunicazioni, un referente legale o privacy, un coordinatore dei fornitori e un titolare delle evidenze.
Usare il requisito di classificazione entro un’ora della Politica di risposta agli incidenti per PMI come punto di controllo, anche nelle organizzazioni più grandi. Applicare il quadro multilivello per la risposta aziendale e registrare l’incertezza quando i fatti sono incompleti.
Preservare immediatamente le evidenze volatili: log delle identità, allarmi EDR, tracce di audit cloud, registrazioni degli accessi privilegiati, log dei sistemi interessati, stato dei backup, modifiche di configurazione e cronologia dei ticket pertinenti. Avviare il registro della catena di custodia utilizzando la Politica per la raccolta delle evidenze e l’analisi forense.
Output decisionali:
- Ora di dichiarazione dell’incidente.
- Gravità iniziale.
- Servizi sospettati di essere interessati.
- Dati sospettati di essere interessati.
- Watchlist regolamentare iniziale, inclusi GDPR, NIS2, DORA e obblighi contrattuali.
- Lacune nelle evidenze e proprietari assegnati.
Ora 1-24: analisi dell’impatto e del preallarme
Costruire la prima vista dell’impatto. Determinare se l’evento ha inciso sulla fornitura dei servizi, ha causato o potrebbe causare interruzione operativa o perdita finanziaria, ha interessato altri soggetti o ha creato danni materiali o immateriali. Questo supporta l’analisi dell’incidente significativo ai sensi di NIS2.
Per le entità finanziarie, classificare rispetto ai criteri DORA: clienti interessati, transazioni, reputazione, indisponibilità, diffusione geografica, perdita di dati, criticità e impatto economico.
Per il GDPR, determinare se sono stati coinvolti dati personali e se esiste un rischio probabile per le persone fisiche.
Output decisionali:
- Decisione sul preallarme NIS2.
- Stato di osservazione per incidente grave DORA.
- Stato della valutazione della violazione dei dati personali GDPR.
- Monitoraggio della notifica a clienti, clienti finanziari o titolari del trattamento.
- Aggiornamento all’organo di gestione.
- Richieste di evidenze ai fornitori.
Ora 24-72: preparare evidenze di notifica di livello regolamentare
Se NIS2 si applica, preparare l’aggiornamento di notifica dell’incidente entro 72 ore con gravità preliminare, impatto e indicatori di compromissione ove disponibili. Se la notifica GDPR è richiesta, assicurare che il pacchetto per l’autorità di controllo rifletta ciò che è noto, ciò che resta ignoto, le probabili conseguenze e le misure adottate o proposte. Se DORA si applica, preparare la relazione iniziale o intermedia richiesta utilizzando il processo dell’autorità competente.
Output decisionali:
- Cronologia dell’incidente aggiornata.
- Ipotesi di causa radice.
- Azioni di contenimento ed eradicazione.
- Evidenze del ripristino del servizio.
- Pacchetto di notifica all’autorità di regolamentazione.
- Comunicazioni a clienti o clienti finanziari.
- Inventario delle evidenze aggiornato.
Questo sprint non è burocrazia fine a sé stessa. Impedisce al team di risposta di sacrificare le evidenze mentre ripristina le operazioni.
Mappatura trasversale: un flusso di lavoro, molti destinatari delle evidenze
Un programma maturo di risposta agli incidenti produce evidenze una sola volta e le riutilizza tra più quadri di riferimento.
| Elemento del flusso di lavoro dell’incidente | CSF 2.0 | ISO/IEC 27001:2022 e Annex A | NIS2 | DORA | GDPR |
|---|---|---|---|---|---|
| Governance e titolarità | GV.RR, GV.OV, GV.PO | Clausole da 5.1 a 5.3, A.5.24 | Article 20 vigilanza della direzione | Articles 5 e 6 responsabilità dell’organo di gestione | Article 5 responsabilizzazione |
| Ambito e obblighi | GV.OC | Clausole da 4.1 a 4.4 | Ambito dei soggetti essenziali e importanti | Ambito delle entità finanziarie e proporzionalità | Ambito materiale e territoriale |
| Criteri di rischio e gravità | GV.RM, ID.RA, RS.MA-03 | Clausole da 6.1.1 a 6.1.3, A.5.25 | Criteri di incidente significativo | Article 18 classificazione | Rischio per le persone fisiche |
| Rilevazione e monitoraggio | DE.CM, DE.AE | A.8.15 registrazione, A.8.16 monitoraggio, A.5.25 | Trattamento dell’incidente e valutazione dell’efficacia | Indicatori di preallarme e registrazioni degli incidenti | Rilevazione e valutazione della violazione |
| Esecuzione della risposta | RS.MA, RS.AN, RS.MI | A.5.26, A.5.28 | Article 23 percorso di segnalazione | Articles 17 e 19 processo e segnalazione degli incidenti | Article 33 e Article 34 valutazione |
| Ripristino | RC.RP, RC.CO | A.5.29 prontezza ICT per la continuità operativa, A.8.13 backup delle informazioni | Minimizzazione dell’impatto sui servizi | Ripristino di operazioni sicure | Mitigazione e comunicazione |
| Lezioni apprese | GV.OV, RS.IM | A.5.27 e Clausola 10 miglioramento | Azione correttiva senza ingiustificato ritardo | Chiusura della causa radice e azioni correttive | Registrazioni di responsabilizzazione |
La mappatura della risposta da ISO a NIST è particolarmente utile per gli auditor.
| Attività ISO/IEC 27002:2022 | Sottocategoria NIST CSF 2.0 |
|---|---|
| Esecuzione del piano di risposta agli incidenti con terze parti | RS.MA-01 |
| Triage e validazione delle segnalazioni di incidente | RS.MA-02 |
| Categorizzazione e prioritizzazione | RS.MA-03 |
| Escalation secondo necessità | RS.MA-04 |
| Analisi e determinazione della causa radice | RS.AN-03 |
| Registrazione delle azioni investigative e preservazione della provenienza | RS.AN-06 |
| Raccolta dei dati dell’incidente e preservazione dell’integrità | RS.AN-07 |
| Stima e validazione della portata dell’incidente | RS.AN-08 |
| Notifica agli stakeholder interni ed esterni | RS.CO-02 |
| Contenimento ed eradicazione | RS.MI-01 e RS.MI-02 |
| Esecuzione del piano di ripristino e verifica dell’integrità dei backup | RC.RP-01 e RC.RP-03 |
Deve essere inclusa anche la governance della catena di fornitura. NIST CSF 2.0 GV.SC tratta processi di rischio della catena di fornitura, ruoli dei fornitori, prioritizzazione della criticità, requisiti contrattuali, due diligence, monitoraggio continuo, inclusione dei fornitori nella pianificazione degli incidenti e attività di fine rapporto. Ciò si allinea direttamente alla sicurezza della catena di fornitura NIS2, alla gestione del rischio TIC di terze parti DORA e ai controlli sui fornitori ISO/IEC 27001:2022.
Come auditor diversi testeranno lo stesso incidente
Un auditor ISO/IEC 27001:2022 partirà dal SGSI. Chiederà se la gestione degli incidenti è nel campo di applicazione, se gli obblighi delle parti interessate sono documentati, se i rischi di incidente sono valutati, se da A.5.24 ad A.5.28 sono inclusi nella Dichiarazione di Applicabilità, se il processo si è svolto come pianificato e se l’incidente ha prodotto lezioni apprese, azioni correttive e miglioramento continuo.
Un valutatore orientato a NIST si concentrerà sugli esiti CSF 2.0. Testerà governance, visibilità sugli asset, monitoraggio, dichiarazione dell’incidente, triage, escalation, integrità delle evidenze, comunicazioni agli stakeholder, contenimento, eradicazione, ripristino e aggiornamenti dei profili.
Un riesame di vigilanza NIS2 si concentrerà sulla responsabilità della direzione, sulle misure di gestione del rischio di Article 21 e sulla segnalazione di Article 23. Le evidenze della decisione di preallarme entro 24 ore, del contenuto della notifica entro 72 ore, delle relazioni intermedie e della relazione finale saranno centrali. Il revisore può esaminare anche continuità operativa, sicurezza della catena di fornitura, controllo degli accessi, formazione, crittografia e valutazione dell’efficacia.
Un’autorità di regolamentazione DORA si concentrerà sulla resilienza operativa. Si aspetterà criteri di classificazione degli incidenti, registrazioni degli incidenti connessi alle TIC e delle minacce informatiche significative, indicatori di preallarme, escalation all’alta direzione, visibilità dell’organo di gestione, notifica ai clienti quando sono interessati interessi finanziari, chiusura della causa radice, ripristino di operazioni sicure ed evidenze dei fornitori.
Un’autorità di controllo GDPR si concentrerà sulla responsabilizzazione per la violazione dei dati personali. Chiederà quando l’organizzazione ne è venuta a conoscenza, quali dati personali sono stati interessati, se l’organizzazione era titolare del trattamento o responsabile del trattamento, quale rischio esisteva per le persone fisiche, quali misure sono state adottate, perché la notifica è stata o non è stata effettuata e se il registro interno delle violazioni è completo.
Un auditor in stile COBIT o ISACA testerà obiettivi di governance, pratiche di gestione, titolarità, metriche ed evidenze di assurance. Gli interesserà verificare se la risposta agli incidenti è governata, misurata, migliorata e allineata agli obiettivi aziendali.
Lo stesso incidente può soddisfare tutti questi riesami se il flusso di lavoro è progettato intorno a evidenze condivise anziché a raccoglitori di conformità isolati.
Testare la mappatura con un’esercitazione tabletop guidata dalle scadenze
Il modo più rapido per capire se la mappatura funziona è un’esercitazione tabletop costruita intorno alle scadenze di segnalazione.
Usare questo scenario: un account di ingegnere privilegiato viene compromesso. L’attaccante accede a una banca dati di produzione, esporta un volume ignoto di registrazioni, modifica un’impostazione di configurazione che causa un’interruzione parziale per i clienti UE e usa un token API emesso tramite un’integrazione di terze parti.
Eseguire l’esercitazione in quattro round.
Round uno, rilevazione e dichiarazione. Il team riesce a identificare la fonte dell’allarme, dichiarare l’incidente, classificare la gravità entro un’ora, preservare i log e assegnare i ruoli?
Round due, impatto. Il team riesce a identificare servizi interessati, dati interessati, clienti interessati, coinvolgimento dei fornitori, indisponibilità, diffusione geografica e se l’incidente incide su interessi finanziari o dati personali?
Round tre, segnalazione. Sono attivati il preallarme NIS2, la notifica NIS2 entro 72 ore, la segnalazione DORA, la notifica GDPR e gli avvisi contrattuali ai clienti? Il team riesce a documentare sia le decisioni di notifica sia quelle di mancata notifica?
Round quattro, ripristino e chiusura. Contenimento, eradicazione, ripristino, convalida dei backup, comunicazioni, lezioni apprese e azioni correttive sono documentati?
L’output non deve essere un set di slide. Deve essere un pacchetto di evidenze: ticket dell’incidente completato, cronologia, registro delle decisioni, registro delle comunicazioni, elenco delle evidenze preservate, matrice delle decisioni verso le autorità di regolamentazione, registrazione della comunicazione con i fornitori, registrazione della convalida del ripristino e piano di azioni correttive.
L’esercitazione non è conclusa quando le persone spiegano cosa farebbero. È conclusa quando producono le registrazioni che un auditor richiederebbe.
Schemi di fallimento comuni da eliminare prima della prossima allerta
Il primo schema di fallimento è il momento di conoscenza non definito. Se nessuno registra quando l’organizzazione è venuta a conoscenza dell’evento, l’analisi delle tempistiche NIS2, DORA e GDPR diventa rischiosa.
Il secondo è la gravità senza criteri. Etichette come medio o alto sono deboli se non collegate a impatto sul servizio, impatto sui dati, impatto finanziario, impatto sui clienti o soglie regolamentari.
Il terzo è la privacy coinvolta troppo tardi. La valutazione GDPR deve iniziare quando potrebbero essere coinvolti dati personali, non dopo il completamento dell’analisi della causa radice.
Il quarto è l’ambiguità sui fornitori. Se sono coinvolti un fornitore cloud, un fornitore di servizi gestiti o un’integrazione SaaS, contratti e playbook devono definire chi preserva i log, chi comunica, chi supporta l’analisi forense e chi assiste nelle richieste dell’autorità di regolamentazione.
Il quinto è la distruzione delle evidenze durante il ripristino. Riavvii, cancellazioni e modifiche di configurazione possono essere necessari, ma devono essere coordinati con la conservazione delle evidenze ogni volta che sia praticabile.
Il sesto sono lezioni apprese senza trattamento del rischio. ISO/IEC 27001:2022 si aspetta miglioramento ove appropriato. Una riunione sulle lezioni apprese senza modifica del controllo, proprietario, data di scadenza o rivalutazione del rischio è un’evidenza debole.
Trasformare la risposta agli incidenti in un sistema di evidenze per la conformità trasversale
La preparazione alle aspettative NIST SP 800-61 sulla risposta agli incidenti e agli audit 2026 non dovrebbe iniziare con un altro playbook autonomo. Dovrebbe iniziare dalla mappatura delle decisioni.
Clarysec può aiutare il tuo team a:
- Costruire un profilo attuale e un profilo target NIST CSF 2.0 per la risposta agli incidenti.
- Allineare la risposta agli incidenti alle clausole ISO/IEC 27001:2022, al trattamento del rischio e ai controlli dell’Annex A.
- Integrare nei flussi di lavoro i requisiti di evidenza NIS2 a 24 ore, 72 ore e un mese.
- Mappare classificazione degli incidenti DORA, reporting all’organo di gestione, notifica ai clienti ed evidenze dei fornitori di servizi TIC.
- Integrare l’analisi delle violazioni dei dati personali GDPR e le registrazioni di responsabilizzazione.
- Implementare la Politica di risposta agli incidenti, la Politica di risposta agli incidenti per PMI, la Politica per la raccolta delle evidenze e l’analisi forense, la Politica per la raccolta delle evidenze e l’analisi forense per PMI, la Politica di registrazione e monitoraggio per PMI, Zenith Blueprint e Zenith Controls di Clarysec in un modello operativo testato tramite esercitazioni tabletop.
La domanda per il 2026 non è se il tuo team possa contenere un attacco. La domanda è se il tuo team possa classificare, sottoporre a escalation, segnalare, ripristinare e dimostrare la risposta attraverso NIST, ISO/IEC 27001:2022, NIS2, DORA e GDPR.
Il modello di implementazione in 30 passi e il toolkit di conformità trasversale di Clarysec sono progettati per rendere tutto questo possibile prima della prossima allerta del martedì mattina. Scarica le politiche Clarysec pertinenti, esegui un’esercitazione tabletop guidata dalle scadenze e richiedi una valutazione Clarysec per trasformare il tuo piano di risposta agli incidenti in un sistema di evidenze pronto per l’audit.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council