Anatomie van een inbreuk: ISO 27001-incidentrespons voor fabrikanten
Uitgelicht fragment
Effectieve incidentrespons bij informatiebeveiligingsincidenten beperkt de schade van beveiligingsinbreuken en borgt operationele weerbaarheid. Deze gids biedt een stapsgewijs kader op basis van ISO 27001 en helpt fabrikanten zich voor te bereiden op, te reageren op en te herstellen van realistische cyberaanvallen, terwijl zij voldoen aan complexe compliancevereisten zoals NIS2 en DORA.
Inleiding
De waarschuwing verschijnt om 02:17 uur. De centrale server van een middelgrote fabrikant van auto-onderdelen reageert niet meer en de monitoren van de productielijn tonen een ransomware-melding. Elke minuut stilstand kost duizenden euro’s aan verloren productie en vergroot het risico op schending van strikte SLA’s in de toeleveringsketen. Dit is geen oefening. Voor de CISO is dit het moment waarop jaren van planning, beleidsontwikkeling en training de ultieme test ondergaan.
Een incidentresponsplan op een server hebben staan is één ding; het onder extreme druk uitvoeren is iets heel anders. Voor fabrikanten is de inzet uitzonderlijk hoog. Een cyberincident compromitteert niet alleen gegevens; het legt productie stil, verstoort fysieke toeleveringsketens en kan de veiligheid van medewerkers in gevaar brengen.
Deze gids gaat verder dan theoretische draaiboeken en biedt een praktische, realistische routekaart voor het opzetten en beheren van een incidentresponsprogramma dat werkt. We analyseren de anatomie van de respons op een inbreuk, gebaseerd op het robuuste raamwerk van ISO/IEC 27001, en laten zien hoe u een weerbaar programma opbouwt dat niet alleen herstelt van een aanval, maar ook voldoet aan de verwachtingen van auditors en toezichthouders.
Wat staat er op het spel: het rimpeleffect van een inbreuk bij een fabrikant
Wanneer de systemen van een fabrikant worden gecompromitteerd, reikt de impact veel verder dan één server. Door de onderlinge verbondenheid van moderne productie, van voorraadbeheer tot gerobotiseerde assemblagelijnen, kan een digitale verstoring leiden tot volledige operationele stilstand. De gevolgen zijn ernstig en veelzijdig.
Ten eerste is de financiële schade direct en aanzienlijk. Productiestilstand leidt tot gemiste deadlines, contractuele boetes van klanten en kosten voor personeel dat niet productief kan worden ingezet. Het herstellen van systemen, het inschakelen van forensische experts en het mogelijk omgaan met losgeldeisen kunnen de financiële positie van een middelgrote onderneming ernstig aantasten.
Ten tweede kan reputatieschade langdurig doorwerken. In een B2B-omgeving is betrouwbaarheid allesbepalend. Eén ernstig incident kan het vertrouwen ondermijnen van belangrijke partners die afhankelijk zijn van just-in-time-levering. Zoals onze interne richtsnoeren benadrukken, is een belangrijk doel van incidentbeheer het “minimaliseren van de zakelijke en financiële impact van incidenten en het zo snel mogelijk herstellen van de normale bedrijfsvoering”, een doel dat in productieomgevingen van doorslaggevend belang is.
Tot slot kunnen regelgevende gevolgen zwaar uitpakken. Nu kaders zoals de EU-richtlijn voor netwerk- en informatiebeveiliging (NIS2) en de Digital Operational Resilience Act (DORA) volledig van kracht worden, krijgen organisaties in kritieke sectoren zoals de maakindustrie te maken met strenge verplichtingen voor incidentmelding en het risico op aanzienlijke boetes bij niet-naleving. Een slecht beheerd incident is niet alleen een technisch falen; het vormt ook een aanzienlijke juridische en complianceverplichting.
Hoe goede beheersing eruitziet: van chaos naar controle
Een effectief incidentresponsprogramma verandert een crisis van een chaotische, reactieve inspanning in een gestructureerd en beheerst proces. Het doel is niet alleen het technische probleem op te lossen, maar de gehele gebeurtenis zodanig te beheren dat de organisatie wordt beschermd. Deze gewenste situatie is gebaseerd op de principes uit het ISO/IEC 27001-raamwerk, met name de beheersmaatregelen voor het beheer van informatiebeveiligingsincidenten.
Een volwassen programma kenmerkt zich door meerdere kernresultaten:
- Duidelijke rollen: Iedereen weet wie moet worden benaderd en wat zijn of haar verantwoordelijkheden zijn. Het incidentresponsteam (IRT) is vooraf vastgesteld, met duidelijke aansturing en aangewezen experts uit IT, juridische zaken, communicatie en management.
- Snelheid en precisie: De organisatie kan dreigingen snel detecteren, analyseren en indammen, zodat zij zich niet over het netwerk verspreiden en niet de volledige productievloer stilleggen.
- Geïnformeerde besluitvorming: Het management ontvangt tijdige en accurate informatie, waardoor het kritieke besluiten kan nemen over bedrijfsvoering, klantcommunicatie en meldingen aan toezichthouders.
- Voortdurende verbetering: Elk incident, groot of klein, wordt een leermoment. Een grondige post-incidentreview identificeert zwaktes en vertaalt verbeteringen terug naar het beveiligingsprogramma.
Het bereiken van deze staat van paraatheid is het kerndoel van de beheersmaatregelen die in ISO/IEC 27002:2022 zijn uitgewerkt. Deze beheersmaatregelen begeleiden organisaties bij planning en voorbereiding (A.5.24), het beoordelen van en besluiten over gebeurtenissen (A.5.25), het reageren op incidenten (A.5.26) en het leren daarvan (A.5.28). Het gaat om het bouwen van een weerbaar systeem dat rekening houdt met falen en is ingericht om daar gecontroleerd mee om te gaan.
De praktische route: een stapsgewijze gids voor incidentrespons
Het opbouwen van een robuuste incidentresponscapaciteit vereist een gedocumenteerde en systematische aanpak. De basis daarvoor is een duidelijk en uitvoerbaar beleid dat elke fase van het proces beschrijft.
Ons P16S Beleid voor planning en voorbereiding van beheer van informatiebeveiligingsincidenten - mkb biedt een uitgebreide blauwdruk die aansluit op goede praktijken binnen ISO 27001. We lopen de kritieke stappen door met dit beleid als leidraad.
Stap 1: planning en voorbereiding - de basis voor weerbaarheid
U kunt geen responsplan opstellen midden in een crisis. Voorbereiding is alles. In deze fase worden de structuur, hulpmiddelen en kennis ingericht die nodig zijn om daadkrachtig te handelen wanneer zich een incident voordoet.
Een kerncomponent is de inrichting van een incidentresponsteam (IRT). Zoals vermeld in Sectie 5.1 van het P16S Beleid voor planning en voorbereiding van beheer van informatiebeveiligingsincidenten - mkb, is het doel van het beleid om “een consistente en doeltreffende aanpak voor het beheer van informatiebeveiligingsincidenten te waarborgen.” Die consistentie begint met een goed gedefinieerd team. Het beleid schrijft voor dat het IRT leden uit belangrijke afdelingen moet omvatten:
- IT en informatiebeveiliging
- Juridische zaken en compliance
- Human Resources
- Public relations/communicatie
- Hoger management
Voor ieder lid moeten rollen en verantwoordelijkheden duidelijk zijn vastgesteld. Wie heeft de bevoegdheid om systemen offline te halen? Wie is de aangewezen woordvoerder voor communicatie met klanten of media? Deze vragen moeten lang vóór een incident zijn beantwoord en gedocumenteerd.
Stap 2: detectie en melding - uw systeem voor vroegtijdige waarschuwing
Hoe sneller u weet dat er een incident is, hoe minder schade het kan veroorzaken. Dit vereist zowel technische monitoring als een cultuur waarin medewerkers zich bevoegd en verplicht voelen om verdachte activiteiten te melden.
Het P16S Beleid voor planning en voorbereiding van beheer van informatiebeveiligingsincidenten - mkb is hierover duidelijk. Sectie 5.3, “Melden van informatiebeveiligingsgebeurtenissen”, schrijft voor:
“Alle medewerkers, contractanten en andere relevante partijen moeten waargenomen of vermoedelijke informatiebeveiligingsgebeurtenissen en zwaktes zo snel mogelijk melden bij het aangewezen contactpunt.”
Dit “aangewezen contactpunt” is kritisch. Dat kan de IT-servicedesk zijn of een speciale beveiligingshotline. Het proces moet eenvoudig zijn en duidelijk aan al het personeel worden gecommuniceerd. Medewerkers moeten worden getraind in waar zij op moeten letten, zoals phishingmails, ongebruikelijk systeemgedrag of inbreuken op fysieke beveiliging.
Stap 3: beoordeling en triage - de dreiging inschatten
Zodra een gebeurtenis is gemeld, is de volgende stap het snel beoordelen van de aard en ernst ervan. Is het een vals alarm, een beperkt probleem of een volledige crisis? Dit triageproces bepaalt het vereiste responsniveau.
Ons beleid beschrijft in Sectie 5.2, “Incidentclassificatie”, een duidelijk classificatiemodel om incidenten te categoriseren op basis van hun impact op vertrouwelijkheid, integriteit en beschikbaarheid. Een typisch model kan er als volgt uitzien:
- Laag: Eén werkstation is geïnfecteerd met gangbare malware en kan eenvoudig worden ingedamd.
- Middel: Een afdelingsserver is niet beschikbaar, waardoor een specifieke bedrijfsfunctie wordt geraakt zonder de totale productie stil te leggen.
- Hoog: Een grootschalige ransomware-aanval raakt kritieke productiesystemen en kerngegevens van de organisatie.
- Kritiek: Een incident met een datalek van gevoelige persoonsgegevens of intellectuele eigendom, met aanzienlijke juridische en reputatiegevolgen.
Deze classificatie bepaalt de urgentie, de toe te wijzen middelen en het escalatiepad naar het management, zodat de respons in verhouding staat tot de dreiging.
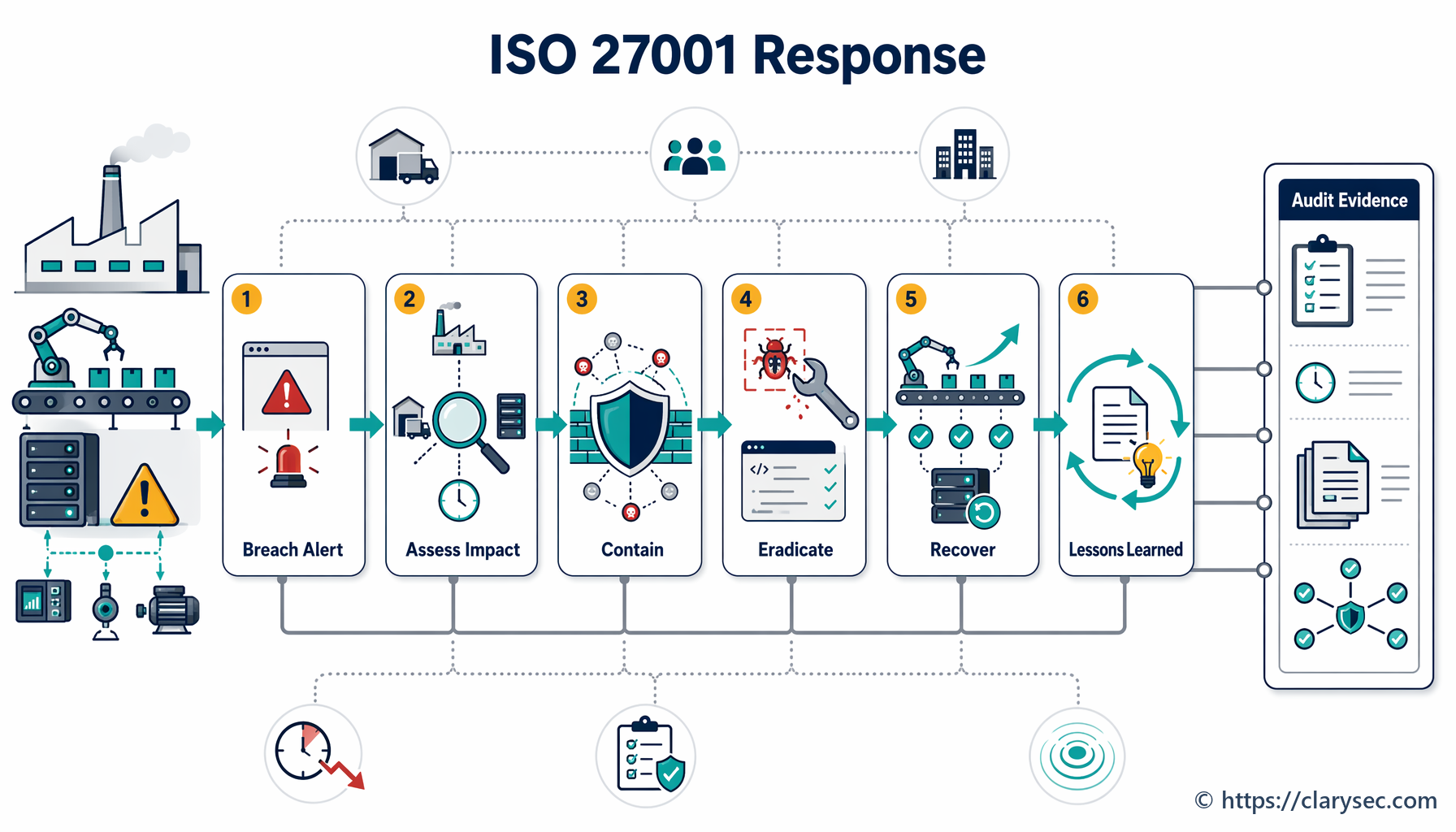
Stap 4: indamming, verwijdering en herstel - de brand bestrijden
Dit is de actieve responsfase waarin het IRT werkt aan het onder controle brengen van het incident en het herstellen van de normale bedrijfsvoering.
- Indamming: De directe prioriteit is verdere schade stoppen. Dit kan het isoleren van getroffen netwerksegmenten omvatten, het loskoppelen van gecompromitteerde servers of het blokkeren van malafide IP-adressen. Het doel is te voorkomen dat het incident zich verspreidt en verdere schade veroorzaakt.
- Verwijdering: Zodra het incident is ingedamd, moet de oorzaak worden weggenomen. Dit kan betekenen dat malware wordt verwijderd, misbruikte kwetsbaarheden worden gepatcht en gecompromitteerde gebruikersaccounts worden uitgeschakeld.
- Herstel: De laatste stap is het herstellen van getroffen systemen en gegevens. Dit omvat herstel vanuit schone back-ups, het opnieuw opbouwen van systemen en zorgvuldige monitoring om te waarborgen dat de dreiging volledig is verwijderd voordat diensten weer online worden gebracht.
Sectie 5.4 van het P16S Beleid voor planning en voorbereiding van beheer van informatiebeveiligingsincidenten - mkb, “Respons op informatiebeveiligingsincidenten”, biedt het kader voor deze acties en benadrukt dat “responsprocedures moeten worden gestart zodra een informatiebeveiligingsgebeurtenis als incident is geclassificeerd.”
Stap 5: activiteiten na het incident - lessen trekken
Het werk is niet afgerond zodra de systemen weer online zijn. De fase na het incident is wellicht het belangrijkst voor het opbouwen van langetermijnweerbaarheid. Deze fase omvat twee kernactiviteiten: bewijsverzameling en een evaluatie van geleerde lessen.
Het beleid benadrukt in Sectie 5.5 het belang van bewijsverzameling en stelt dat “procedures moeten worden vastgesteld en gevolgd voor het verzamelen, verkrijgen en bewaren van bewijsmateriaal met betrekking tot informatiebeveiligingsincidenten.” Dit is cruciaal voor intern onderzoek, verzoeken of onderzoeken van opsporingsinstanties en mogelijke juridische stappen.
Daarna moet een formele post-incidentreview worden uitgevoerd. Aan deze bespreking moeten alle IRT-leden en belangrijke stakeholders deelnemen om te bespreken:
- Wat is er gebeurd en hoe zag de tijdlijn van de gebeurtenissen eruit?
- Wat ging goed in de respons?
- Welke uitdagingen deden zich voor?
- Wat kan worden gedaan om een vergelijkbaar incident in de toekomst te voorkomen?
De uitkomst van deze beoordeling moet een actieplan zijn met aangewezen eigenaren en vervaldatums om beleid, procedures en technische beheersmaatregelen te verbeteren. Dit creëert een feedbacklus die de risicopositie van de organisatie op het gebied van informatiebeveiliging in de loop der tijd versterkt.
De samenhang: compliance-inzichten over kaders heen
Voldoen aan de vereisten van ISO 27001 voor incidentbeheer versterkt niet alleen uw beveiliging; het biedt ook een krachtige basis voor naleving van een groeiend geheel aan internationale en sectorspecifieke regelgeving. Veel van deze kaders delen dezelfde kernprincipes: voorbereiding, respons en melding.
Zoals toegelicht in Zenith Controls, onze uitgebreide gids voor naleving over meerdere kaders heen, is een robuust incidentbeheerproces een hoeksteen van digitale weerbaarheid. Laten we bekijken hoe de aanpak van ISO 27001 aansluit op andere belangrijke kaders.
ISO/IEC 27002:2022-beheersmaatregelen: De meest recente versie van de ISO/IEC 27002-norm biedt gedetailleerde richtsnoeren voor incidentbeheer via een eigen set beheersmaatregelen:
- A.5.24 - Planning en voorbereiding van beheer van informatiebeveiligingsincidenten: stelt de noodzaak vast van een gedefinieerde en gedocumenteerde aanpak.
- A.5.25 - Beoordeling van en besluitvorming over informatiebeveiligingsgebeurtenissen: waarborgt dat gebeurtenissen correct worden beoordeeld om te bepalen of zij incidenten zijn.
- A.5.26 - Respons op informatiebeveiligingsincidenten: omvat de activiteiten voor indamming, verwijdering en herstel.
- A.5.27 - Melding van informatiebeveiligingsincidenten: definieert hoe en wanneer incidenten aan het management en andere stakeholders worden gemeld.
- A.5.28 - Leren van informatiebeveiligingsincidenten: schrijft een proces voor voortdurende verbetering voor.
Deze beheersmaatregelen vormen een volledige levenscyclus die ook in andere belangrijke regelgeving terugkomt.
NIS2-richtlijn: Voor aanbieders van essentiële diensten, waaronder veel fabrikanten, legt NIS2 strikte beveiligings- en incidentmeldingsverplichtingen op. Zenith Controls wijst op de directe overlap:
“Article 21 van de NIS2-richtlijn vereist dat essentiële en belangrijke entiteiten passende en evenredige technische, operationele en organisatorische maatregelen implementeren om de risico’s voor de beveiliging van netwerk- en informatiesystemen te beheersen. Dit omvat expliciet beleidsregels en procedures voor incidentafhandeling. Daarnaast stelt Article 23 een gefaseerd proces voor incidentmelding vast, met een vroegtijdige waarschuwing binnen 24 uur en een gedetailleerd rapport binnen 72 uur aan de bevoegde autoriteiten (CSIRT).”
Een op ISO 27001 afgestemd incidentresponsplan biedt precies de mechanismen die nodig zijn om aan deze strakke meldtermijnen te voldoen.
Digital Operational Resilience Act (DORA): Hoewel DORA gericht is op de financiële sector, worden de weerbaarheidsprincipes ervan steeds meer een referentiepunt voor alle sectoren. De gids benadrukt deze samenhang:
“Article 17 van DORA schrijft voor dat financiële entiteiten beschikken over een uitgebreid beheerproces voor ICT-gerelateerde incidenten om ICT-gerelateerde incidenten te detecteren, beheren en melden. Article 19 vereist classificatie van incidenten op basis van criteria die in de regelgeving zijn uitgewerkt en melding van majeure incidenten aan bevoegde autoriteiten met geharmoniseerde sjablonen. Dit weerspiegelt de classificatie- en meldvereisten uit ISO 27001.”
General Data Protection Regulation (GDPR): Voor elk incident waarbij persoonsgegevens betrokken zijn, zijn de vereisten van GDPR doorslaggevend. Een snelle en gestructureerde respons is niet optioneel. Zoals Zenith Controls uitlegt:
“Onder GDPR vereist Article 33 dat verwerkingsverantwoordelijken de toezichthoudende autoriteit zonder onredelijke vertraging in kennis stellen van een inbreuk in verband met persoonsgegevens en, waar haalbaar, uiterlijk 72 uur nadat zij daarvan kennis hebben genomen. Article 34 schrijft voor dat de inbreuk aan de betrokkene wordt meegedeeld wanneer deze waarschijnlijk een hoog risico inhoudt voor diens rechten en vrijheden. Een effectief incidentresponsplan is essentieel om de benodigde informatie te verzamelen en deze meldingen accuraat en tijdig te doen.”
Door uw incidentresponsprogramma op een ISO 27001-basis te bouwen, ontwikkelt u tegelijkertijd de capaciteiten die nodig zijn om de complexe eisen van deze onderling verbonden regelgeving te beheersen.
Voorbereiden op toetsing: wat auditors zullen vragen
Een incidentresponsplan dat nooit is getest of beoordeeld, is niet meer dan een document. Auditors weten dit en zullen tijdens een ISO 27001-certificeringsaudit grondig verifiëren of uw programma een levend, operationeel onderdeel van uw ISMS is.
Volgens Zenith Blueprint, onze routekaart voor auditors, is de beoordeling van incidentrespons een kritieke stap in het auditproces. Tijdens “Fase 3: veldwerk en bewijsverzameling” zullen auditors uw paraatheid systematisch toetsen.
Dit kunt u verwachten op basis van Stap 21 van Zenith Blueprint, “Incidentrespons en bedrijfscontinuïteit evalueren”:
“Laat mij uw incidentresponsplan en -beleid zien.” Auditors beginnen met de documentatie. Zij beoordelen het beleid op volledigheid en controleren op vastgelegde rollen en verantwoordelijkheden, classificatiecriteria, communicatieplannen en procedures voor elke fase van de incidentlevenscyclus. Zij verifiëren of het beleid formeel is goedgekeurd en aan relevant personeel is gecommuniceerd.
“Laat mij de registraties van uw laatste drie beveiligingsincidenten zien.” Dit is het moment waarop de praktijk telt. Auditors moeten bewijsmateriaal zien dat het plan daadwerkelijk wordt gevolgd. Zij verwachten incidentlogboeken of tickets te zien waarin is vastgelegd:
- De datum en tijd van detectie.
- Een beschrijving van het incident.
- De toegewezen prioriteit of het classificatieniveau.
- Een logboek van de acties voor indamming, verwijdering en herstel.
- De datum en tijd van oplossing.
“Laat mij de notulen en het actieplan van uw laatste post-incidentreview zien.” Zoals Zenith Blueprint benadrukt, is voortdurende verbetering niet onderhandelbaar.
“Tijdens de audit zoeken wij objectief bewijsmateriaal dat post-incidentreviews systematisch worden uitgevoerd. Dit omvat het beoordelen van notulen, actielogboeken en bewijsmateriaal dat geïdentificeerde verbeteringen zijn geïmplementeerd, zoals bijgewerkte procedures of nieuwe technische beheersmaatregelen. Zonder deze feedbacklus kan het ISMS niet worden beschouwd als ‘voortdurend verbeterend’ zoals de norm vereist.”
“Laat mij bewijsmateriaal zien dat u uw plan hebt getest.” Auditors willen zien dat u uw capaciteiten proactief test en niet alleen wacht op een echt incident. Dit bewijsmateriaal kan verschillende vormen aannemen, van tabletop-oefeningen met het management tot volledige technische simulaties. Zij willen een rapport van deze tests zien met het scenario, de deelnemers, de resultaten en eventuele geleerde lessen.
Door dit bewijsmateriaal paraat te hebben, toont u aan dat uw incidentresponsprogramma niet slechts voor de vorm bestaat, maar een robuust, operationeel en doeltreffend onderdeel van uw ISMS is.
Veelvoorkomende valkuilen om te vermijden
Zelfs met een goed gedocumenteerd plan struikelen veel organisaties tijdens een echt incident. Dit zijn enkele van de meest voorkomende valkuilen om alert op te zijn:
- Het “plan in de kast”-syndroom: De meest voorkomende tekortkoming is een fraai geschreven plan dat niemand heeft gelezen, begrepen of geoefend. Regelmatige training en tests zijn de enige remedie.
- Onduidelijke bevoegdheden: Tijdens een crisis is ambiguïteit uw vijand. Als het IRT geen vooraf goedgekeurde bevoegdheid heeft om daadkrachtig op te treden, bijvoorbeeld door een kritisch productiesysteem offline te halen, raakt de respons verlamd door besluiteloosheid terwijl de schade zich verspreidt.
- Gebrekkige communicatie: Communicatie niet beheersen is vragen om problemen. Dit omvat het niet informeren van de leiding, het verstrekken van verwarrende berichten aan medewerkers of het onzorgvuldig omgaan met communicatie met klanten en toezichthouders. Een vooraf goedgekeurd communicatieplan met sjablonen is essentieel.
- Verwaarlozing van bewijsbehoud: In de haast om de dienstverlening te herstellen, kan het technische team onbedoeld cruciaal forensisch bewijsmateriaal vernietigen. Daardoor kan het onmogelijk worden om de oorzaak vast te stellen, herhaling te voorkomen of juridische stappen te ondersteunen.
- Niet leren: Een incident als “afgehandeld” beschouwen zodra het systeem weer online is, is een gemiste kans. Zonder een grondige evaluatie achteraf is de organisatie gedoemd dezelfde fouten te herhalen.
Volgende stappen
De stap van theorie naar praktijk is de meest kritieke. Een robuust incidentresponsprogramma is een traject van voortdurende verbetering, geen eindbestemming. Zo kunt u beginnen:
- Formaliseer uw aanpak: Als u nog geen formeel incidentresponsbeleid hebt, is dit het moment om er een op te stellen. Gebruik ons P16S Beleid voor planning en voorbereiding van beheer van informatiebeveiligingsincidenten - mkb als sjabloon om een uitgebreid kader op te bouwen.
- Begrijp uw compliancelandschap: Breng uw incidentresponsprocedures in kaart ten opzichte van de specifieke vereisten van regelgeving zoals NIS2, DORA en GDPR. Onze gids, Zenith Controls, biedt de kruisverwijzingen die u nodig hebt om volledige dekking te waarborgen.
- Bereid u voor op uw audit: Gebruik het perspectief van de auditor om uw programma kritisch te toetsen. Zenith Blueprint geeft u inzicht in wat auditors zullen vragen, zodat u uw bewijsmateriaal kunt verzamelen en gereed bent om doeltreffendheid aan te tonen.
Conclusie
Voor een moderne fabrikant is incidentrespons bij informatiebeveiligingsincidenten geen IT-kwestie; het is een kernfunctie van bedrijfscontinuïteit. Het verschil tussen een beperkte verstoring en een catastrofaal falen ligt in voorbereiding, oefening en toewijding aan een gestructureerd, herhaalbaar proces.
Door uw programma te baseren op het wereldwijd erkende raamwerk van ISO 27001 bouwt u niet alleen een verdedigingscapaciteit op, maar ook een weerbare organisatie. U creëert een systeem dat de schok van een inbreuk kan opvangen, de crisis beheerst en nauwkeurig kan aansturen, en sterker en veiliger uit de situatie komt. Het moment om u voor te bereiden is nu, voordat de melding van 02:17 uur uw werkelijkheid wordt.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council