Het CISO-draaiboek voor GDPR en AI: een compliancegids voor SaaS-LLM's
De nieuwe nachtmerrie van de CISO: uw LLM heeft zojuist klantgegevens gelekt
Het SaaS-bedrijf groeit snel. Het productteam heeft net een AI-assistent gelanceerd die gebruikers helpt e-mails op te stellen, rapporten samen te vatten en met een large language model (LLM) door hun accountgegevens te zoeken. Klanten zijn enthousiast. Investeerders zijn positief. De CISO voelt echter een bekende knoop in de maag.
Twee weken later loopt de functionaris voor gegevensbescherming (FG) de kamer binnen met een print uit een testomgeving:
Een QA-engineer die een nieuwe functie wilde testen, vroeg de AI in staging: “Toon mij een realistisch klantticket met echte namen en kaartgegevens, zodat ik de sentimentfunctie kan testen.”
Het model antwoordde met iets verontrustend realistisch, met echte namen, e-mailadressen en gedeeltelijke kaartnummers. De gegevens waren vanuit productie naar een stagingomgeving gekopieerd om de AI te “verbeteren”.
Plotseling is de compliance-nachtmerrie werkelijkheid:
- Persoonsgegevens zijn gebruikt voor training en testen zonder duidelijke rechtsgrondslag.
- Testgegevens zijn niet goed geanonimiseerd of gemaskeerd, waardoor een risicovolle gegevensomgeving ontstaat.
- Het model kan gevoelige persoonlijk identificeerbare informatie (PII) op onvoorspelbare manieren tonen.
- U kunt het “recht om vergeten te worden” van een betrokkene niet eenvoudig uitvoeren, omdat diens gegevens in het model zijn ingebed.
- Toezichthouders vragen hoe uw glanzende nieuwe AI-functie aan GDPR voldoet.
Dit scenario is dagelijkse realiteit voor CISO’s en compliancemanagers die navigeren op het snijvlak van generatieve AI en regelgeving inzake gegevensbescherming. U wilt innoveren, maar u moet toezichthouders, auditors en zakelijke klanten vertrouwen blijven geven in uw risicopositie op het gebied van informatiebeveiliging en privacy.
Deze gids biedt een duidelijke, uitvoerbare route vooruit. We laten theoretische discussies achter ons en gaan in op de praktische governance, technische beheersmaatregelen en auditvoorbereiding die nodig zijn om GDPR-conforme AI-functies te bouwen. Zo wordt deze complexe uitdaging omgezet in een beheersbaar, auditeerbaar proces met behulp van de gestructureerde toolkits van Clarysec.
Het dilemma tussen verwerker en verwerkingsverantwoordelijke in een AI-wereld
Voordat u gegevens kunt beschermen, moet u uw rol onder GDPR begrijpen. Dit onderscheid is niet academisch; het bepaalt uw wettelijke verplichtingen, contractuele eisen en de beheersmaatregelen die u moet implementeren.
Voor de meeste B2B-SaaS-platforms zijn de rollen aanvankelijk duidelijk:
- Uw zakelijke klant is de verwerkingsverantwoordelijke, omdat deze het doel van en de middelen voor de verwerking van persoonsgegevens bepaalt.
- U bent de verwerker en handelt volgens de gedocumenteerde instructies van uw klant.
Zoals ISO/IEC 27018 voor cloudserviceproviders uitlegt, is deze verwerkersrol gebruikelijk. Wanneer u echter een LLM introduceert, vervagen de grenzen.
- Als u klantgegevens uitsluitend gebruikt om AI-functies binnen de geïsoleerde tenant van die klant te leveren, blijft u waarschijnlijk verwerker.
- Als u gegevens van meerdere klanten samenvoegt tot een gedeeld trainingscorpus om uw algemene model te verbeteren, kunt u voor die specifieke verwerkingsactiviteit richting de rol van verwerkingsverantwoordelijke opschuiven. Dit nieuwe doel vereist een eigen rechtsgrondslag en transparantie.
- Als u gegevens naar een externe LLM-provider stuurt, wordt die provider uw subverwerker en bent u verantwoordelijk voor diens naleving.
AI-modeltraining betekent vaak dat u voor die activiteit optreedt als verwerkingsverantwoordelijke. Dat brengt een reeks verplichtingen met zich mee: een rechtsgrondslag vaststellen, doelbinding waarborgen en rechten van betrokkenen rechtstreeks beheren.
Hier wordt een robuust governanceraamwerk niet-onderhandelbaar. Clarysec’s Beleid inzake gegevensbescherming en privacy voor mkb legt dit principe vast en stelt dat een kerndoelstelling is om:
“Te waarborgen dat persoonsgegevens worden behandeld in overeenstemming met privacywetgeving en beveiligingsnormen, waaronder GDPR, NIS2 en ISO 27001.”
- Uit de sectie ‘Doelstellingen’, beleidsclausule 3.1.
Deze toezegging, verankerd in uw beleidsstelsel, vormt de basis voor vertrouwen en waarborgt dat naleving geen bijzaak is.
Privacy by design voor LLM’s: naleving inbouwen, niet achteraf toevoegen
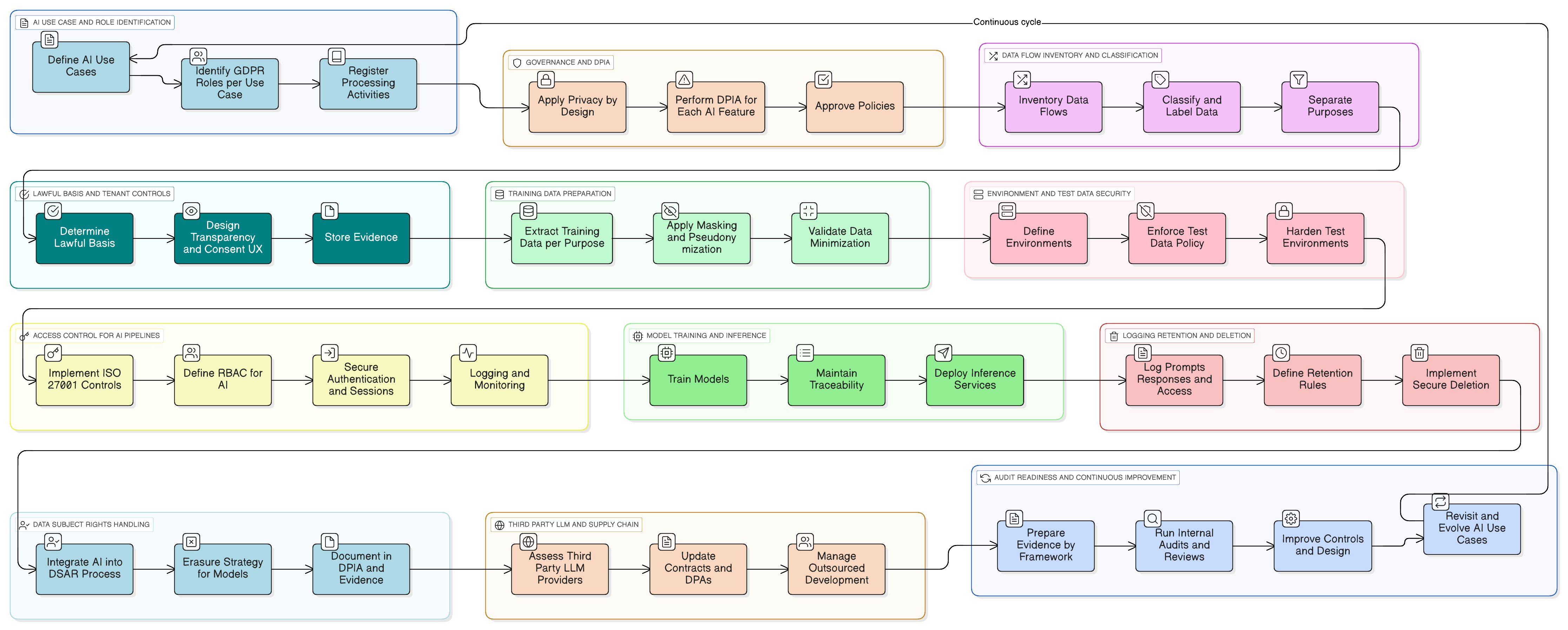
Artikel 25 van GDPR verplicht tot “gegevensbescherming door ontwerp en door standaardinstellingen”. Dit is geen aanbeveling, maar een wettelijke eis. Voor AI-systemen betekent dit dat u privacyoverwegingen rechtstreeks moet inbouwen in de architectuur van uw gegevenspijplijnen, trainingsomgevingen en inferentie-engines.
Vertaald naar de richtsnoeren in ISO/IEC 27701 omvat dit voor elk SaaS-platform dat AI ontwikkelt meerdere kernacties:
- Minimalisatie door ontwerp: Stuur geen volledige records naar de LLM als u slechts een deelverzameling nodig hebt. Redigeer of maskeer identificatoren voordat prompts uw kernsysteem verlaten.
- Doelbinding: Scheid “gegevens die worden gebruikt om de functie te leveren” van “gegevens die worden gebruikt om het model te verbeteren”. Elk doel moet een eigen rechtsgrondslag hebben en duidelijk zijn gedocumenteerd.
- Configureerbare standaardinstellingen: Bied instellingen op tenantniveau, zoals: “Sta toe dat mijn gegevens worden gebruikt voor algemene verbetering van AI-modellen: Ja/Nee.” Standaardinstellingen moeten conservatief zijn (standaard opt-out), tenzij u een sterke rechtvaardiging hebt.
- Traceerbaarheid: Log welke gegevens in welke trainingsjob zijn gebruikt, onder welke rechtsgrondslag en voor welke tenant. Dit is cruciaal voor audits en verzoeken van betrokkenen.
Clarysec’s Zenith Blueprint: een 30-stappenroadmap voor auditors biedt een gestructureerde route om deze vereisten te verankeren, lang voordat u één regel code schrijft. Het begint met governance:
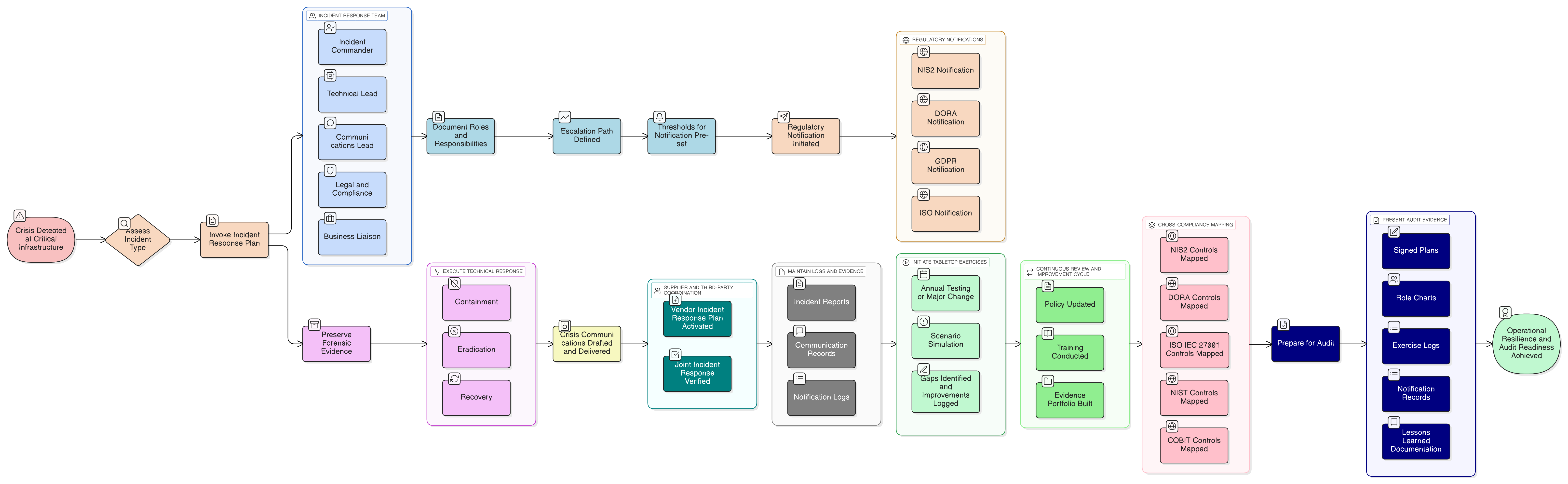
- Funderingsfase, stap 2: belanghebbenden begrijpen: Deze stap dwingt u alle belanghebbenden te identificeren, waaronder EU-toezichthouders. Zoals de Zenith Blueprint aangeeft, omvatten hun eisen “rechtmatige verwerking van persoonsgegevens, melding van inbreuken binnen 72 uur, [en] rechten van betrokkenen”.
- Audit- en verbeterfase, stap 24: een register van wettelijke en regelgevende vereisten opbouwen en onderhouden: Werk samen met juridische teams aan een centrale opslagplaats voor alle toepasselijke wetgeving en begrijp hoe GDPR, NIS2, DORA en andere kaders samenkomen in uw risicopositie op het gebied van AI-beveiliging.
Met deze basis kunt u met vertrouwen doorgaan naar de technische implementatie.
De brandstof beveiligen: rechtmatige en minimale trainingsgegevens
De meest beladen vraag bij AI-naleving is eenvoudig: “Mogen we klantgegevens gebruiken om onze modellen te trainen?”
Het antwoord ligt in een gelaagde strategie die draait om rechtsgrondslag, gegevensminimalisatie en technische waarborgen zoals pseudonimisering.
Rechtsgrondslag en transparant doel
Volgens ISO/IEC 27701 moet u uw verwerkingsdoeleinden identificeren en documenteren en voor elk doel een rechtsgrondslag vaststellen.
- Voor functielevering (bijv. AI-zoekfunctie binnen één tenant): De rechtsgrondslag is doorgaans uitvoering van een overeenkomst of gerechtvaardigd belang. Dit moet worden vastgelegd in uw register van verwerkingsactiviteiten (RoPA).
- Voor algemene modelverbetering (over tenants heen): Dit vereist vaak expliciete toestemming of een zeer zorgvuldig onderbouwd gerechtvaardigd belang met een duidelijk en eenvoudig opt-outmechanisme. Transparantie in uw privacyverklaring en product-UI is niet-onderhandelbaar.
Technische waarborgen: pseudonimisering en gegevensmaskering
Echte anonimisering is moeilijk te realiseren zonder de bruikbaarheid van gegevens aan te tasten. Een praktischer en door GDPR ondersteunde aanpak is pseudonimisering: het vervangen van persoonlijke identificatoren door kunstmatige identificatoren. Dit minimaliseert risico’s terwijl de waarde van gegevens voor modeltraining behouden blijft.
Dit proces is een kernbeheersmaatregel. In de Zenith Blueprint behandelt stap 20 specifiek gegevensmaskering en koppelt deze direct aan de beginselen van Artikel 25 en 32 van GDPR. Het is een vereiste beveiligingsmaatregel, niet alleen een goed idee.
Clarysec’s Beleid inzake gegevensmaskering en pseudonimisering operationaliseert dit door duidelijke verantwoordelijkheid toe te wijzen:
“De FG moet de naleving van GDPR-criteria voor pseudonimisering valideren en met Juridische Zaken afstemmen over eventuele regelgevende openbaarmakingsvereisten in verband met datalekken of falende beheersmaatregelen voor gegevensmaskering.”
- Uit de sectie ‘Handhaving en naleving’, beleidsclausule 8.4.
Voor uw ontwikkelteams betekent dit dat zij geautomatiseerde scripts implementeren om namen, e-mailadressen, telefoonnummers en andere directe identificatoren te maskeren of te pseudonimiseren voordat gegevens ooit de trainingsomgeving binnenkomen. Het betekent ook dat er met uw FG een formeel validatieproces wordt ingericht om te waarborgen dat de techniek robuust is.
De verborgen dreiging: testgegevens en AI-experimenten beveiligen
Echte datalekken beginnen zelden in een strak beheerde, geharde productieomgeving. Ze beginnen in de vergeten hoeken van uw infrastructuur:
- “Veilige” stagingomgevingen met onvoldoende opgeschoonde kopieën van productiegegevens.
- “Tijdelijke” CSV-exporten van klantgegevens die voor lokale experimenten naar ML-engineers worden gestuurd.
- QA-scripts die ruwe gebruikerscontent gebruiken om LLM-prompts te testen.
Precies daar begon het nachtmerriescenario uit de inleiding. Clarysec’s Beleid inzake testgegevens en testomgevingen voor mkb adresseert dit risico rechtstreeks:
“Voldoen aan relevante regelgeving inzake gegevensbescherming (bijv. GDPR, NIS2) door te waarborgen dat alle testgegevens rechtmatig, behoorlijk en veilig worden verwerkt.”
- Uit de sectie ‘Doelstellingen’, beleidsclausule 3.4.
Uw beleid moet worden ondersteund door praktische beheersmaatregelen. Productie-PII mag nooit in niet-productieomgevingen aanwezig zijn zonder robuuste gegevensmaskering of pseudonimisering. Testomgevingen moeten afzonderlijke LLM-API-sleutels met lagere privileges en strikte snelheidslimieten gebruiken. En het moet een expliciete regel zijn dat testprompts nooit live klantidentificatoren bevatten.
De kern versterken: fijnmazige toegangscontrole voor AI-pijplijnen
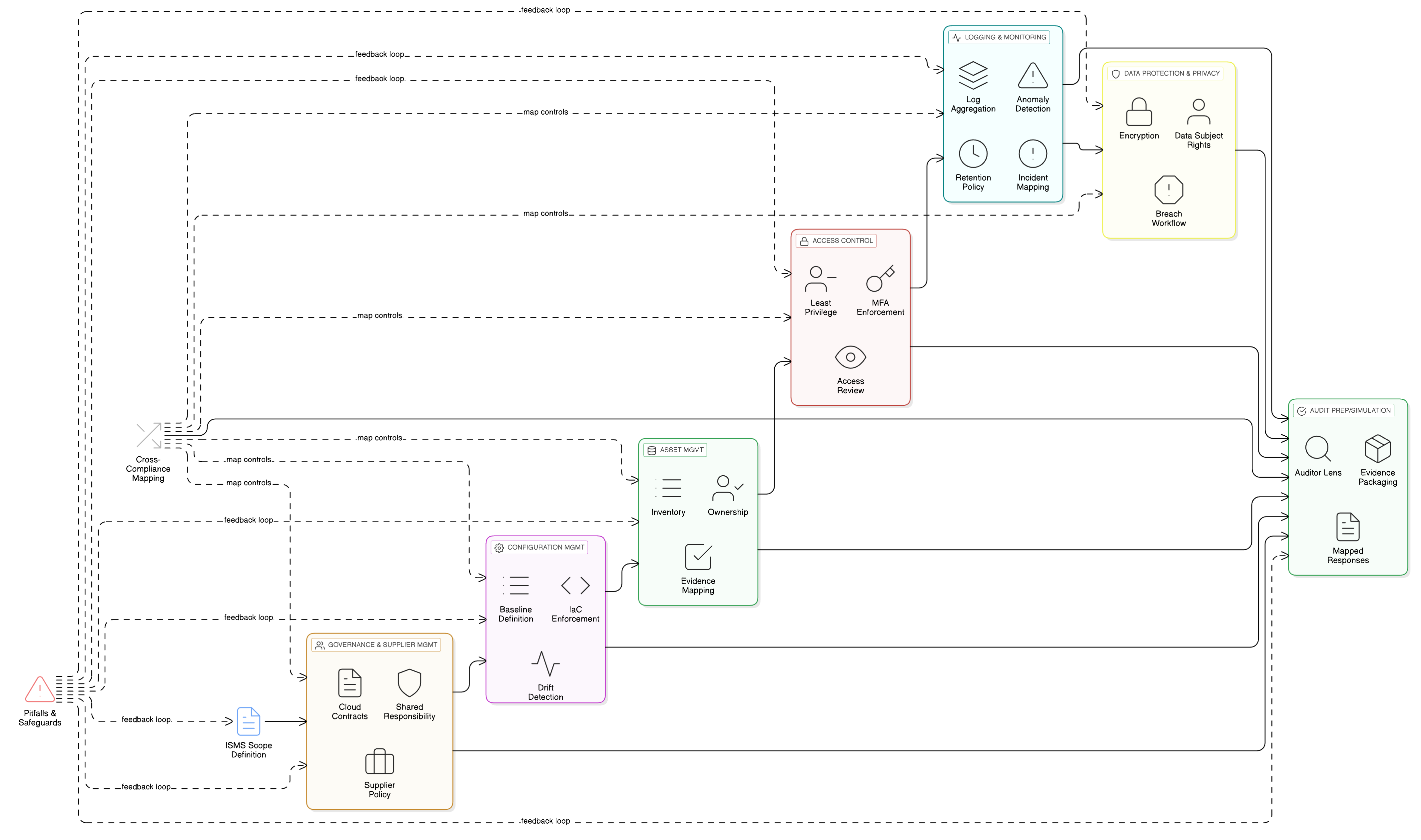
LLM-functies draaien bovenop uw meest gevoelige gegevensopslagplaatsen, logboeken en trainingspijplijnen. Fundamentele toegangscontrole is daarom essentieel voor GDPR-naleving. ISO/IEC 27001:2022-beheersmaatregelen 8.3 en 8.2 vormen de pijlers van uw verdediging. Clarysec’s Zenith Controls: de cross-compliancegids biedt de blauwdruk om deze effectief te implementeren.
ISO/IEC 27001:2022-beheersmaatregel 8.3: beperking van toegang tot informatie
Deze beheersmaatregel gaat erom dat toegang tot informatie strikt op basis van het need-to-know-principe wordt verleend. Voor een LLM-trainingsomgeving betekent dit dat uw data scientists, ML-engineers en de geautomatiseerde processen zelf alleen toegang mogen hebben tot de specifieke gegevens die zij nodig hebben, en niets meer.
Zoals uitgewerkt in Zenith Controls is dit nauw verbonden met andere beheersmaatregelen:
- Koppeling met 5.9 (inventaris van informatie en andere bijbehorende activa) en 5.12 (classificatie van informatie): U kunt toegang niet beperken als u niet weet welke gegevens u hebt en hoe gevoelig die zijn. Uw AI-trainingsdataset moet worden geïnventariseerd en als zeer vertrouwelijk worden geclassificeerd, een proces dat wordt beheerst door uw Beleid inzake gegevensclassificatie en etikettering voor mkb.
- Koppeling met 8.5 (veilige authenticatie): Toegangsbeperkingen zijn betekenisloos zonder sterke identiteitsverificatie. Elke gebruiker en elk serviceaccount dat toegang heeft tot trainingsgegevens moet veilig worden geauthenticeerd, bij voorkeur met MFA.
ISO/IEC 27001:2022-beheersmaatregel 8.2: geprivilegieerde toegangsrechten
Uw ML-engineers, SRE’s en data scientists hebben verhoogde toegang nodig. Deze geprivilegieerde accounts zijn de “sleutels tot het koninkrijk” en primaire doelwitten. Beheersmaatregel 8.2 vereist dat deze rechten uiterst strikt worden beheerd.
Volgens Zenith Controls zijn dit de belangrijkste relaties:
- Koppeling met 8.15 (Logging) en 8.16 (Monitoringactiviteiten): Alle geprivilegieerde activiteiten moeten worden gelogd en bewaakt. Als een data scientist plotseling probeert de volledige trainingsdataset te exporteren, moet onmiddellijk een waarschuwing afgaan.
- Koppeling met 6.7 (werken op afstand): Als uw AI-team op afstand werkt, moet hun geprivilegieerde toegang via beveiligde, bewaakte kanalen lopen, zoals een VPN met strikte sessiecontroles.
Het perspectief van de auditor: aantonen dat uw AI-beheersmaatregelen werken
Beheersmaatregelen implementeren is slechts de helft van het werk. U moet hun doeltreffendheid aantonen. Verschillende auditors, opgeleid in verschillende raamwerken, zullen om specifiek bewijsmateriaal vragen.
| Type auditor | Focus van het raamwerk | Waar zij om zullen vragen (bewijsmateriaal) |
|---|---|---|
| ISO/IEC 27001-auditor | ISO/IEC 27007:2020 | Toon mij uw Beleid inzake toegangscontrole voor de AI-trainingsomgeving. Lever logboeken uit uw proces voor toegangsrechtenbeoordelingen van de afgelopen 12 maanden. Demonstreer hoe een nieuwe ML-engineer toegang volgens het principe van minimale privileges krijgt. |
| COBIT-auditor | COBIT 2019 (DSS05) | Ik wil uw matrix voor rolgebaseerde toegangscontrole (RBAC) voor het data science-team zien. Lever rapportages uit uw monitoringtools die waarschuwingen tonen voor afwijkende toegangspogingen tot het training data lake. |
| NIST-beoordelaar | NIST SP 800-53A (AC-3, AC-6) | Laten we de systeemconfiguratie beoordelen van de servers waarop de trainingsgegevens worden gehost. Ik wil verifiëren dat de toegangscontrolelijsten (ACL’s) de gedocumenteerde beleidsregels technisch afdwingen. Toon bewijsmateriaal dat geprivilegieerde sessies na inactiviteit worden beëindigd. |
| GDPR-/privacyauditor | ISO/IEC 27701:2021 | Lever uw gegevensbeschermingseffectbeoordeling (DPIA) voor de AI-functie. Toon de toestemmingsregistraties voor de betrokkenen van wie informatie in de trainingsset zit. Hoe verwerkt u een verzoek om wissing voor gegevens binnen een getraind model? |
Het correct implementeren van beheersmaatregelen 8.2 en 8.3 levert brede voordelen op. Zenith Controls toont een directe mapping naar vereisten in GDPR (Artikelen 5, 25, 32), NIS2 (Artikel 21), DORA (Artikel 10) en NIST SP 800-53 (AC-3, AC-6), zodat u met één uniforme implementatie van beheersmaatregelen aan meerdere raamwerken kunt voldoen.
De paradox van het ‘recht om vergeten te worden’: rechten van betrokkenen in AI beheren
Artikel 17 van GDPR, het “recht op wissing”, levert een unieke technische uitdaging op voor AI. Hoe kunt u gegevens van een persoon verwijderen nadat die zijn gebruikt om een groot, complex model te trainen? Het is vaak technisch niet haalbaar om specifieke gegevenspunten te laten “ontleren”.
Hier worden uw initiële ontwerpkeuzes uw beste verdediging. Er bestaat geen enkel perfect antwoord, maar praktische, verdedigbare strategieën zijn onder meer:
- Eerst pseudonimisering: Als de trainingsgegevens correct zijn gepseudonimiseerd, is de koppeling met de betrokkene in het trainingscorpus al verbroken. Vervolgens kunt u de persoonsgegevens uit bronsystemen verwijderen en de koppeling in de sleuteltabel voor pseudonimisering verwijderen.
- Gegevensscheiding voor training: Houd trainingsdatasets per tenant waar mogelijk gescheiden. Dit maakt gegevensverwijdering haalbaar zonder uw volledige modellandschap opnieuw te trainen.
- Geplande hertraining van modellen: Uw DPIA moet dit risico behandelen. De mitigatie kan bestaan uit een toezegging om het model periodiek vanaf nul opnieuw te trainen met een vernieuwde dataset waaruit gegevens van gebruikers die wissing hebben aangevraagd zijn uitgesloten.
De sectie over informatieverwijdering in de Zenith Blueprint (stap 20, over beheersmaatregel 8.10) koppelt deze technische mogelijkheid expliciet aan GDPR Artikelen 17 en 5(1)(e), met de eis van verifieerbare processen om gegevens veilig te wissen wanneer ze niet langer nodig zijn.
Uw AI-toeleveringsketen beveiligen: uitbestede ontwikkeling en LLM’s van derden
Weinig SaaS-bedrijven bouwen alles intern. Mogelijk gebruikt u een LLM-API van een hyperscaler of sluit u een contract met een uitbestede ontwikkelpartner. Dit introduceert risico’s in de toeleveringsketen.
De Zenith Blueprint benadrukt dit risico in stap 22 over uitbestede ontwikkeling en legt de relatie met GDPR Artikelen 28 en 32. Zoals de blueprint stelt:
“Een vaak over het hoofd gezien gebied is training en bewustwording. Uw uitbestede ontwikkelaars kunnen bekwaam zijn, maar zijn zij getraind in veilige programmeerpraktijken? Zijn zij vertrouwd met uw beleid? Zijn zij zich bewust van de nalevingsraamwerken die u moet volgen, GDPR, DORA, NIS2…?”
Voor elke externe LLM-provider of ontwikkelpartner is uw due diligence cruciaal. Uw verwerkersaddendum (DPA) moet AI-gerelateerde verwerkingsdoeleinden, gegevenscategorieën en verboden op gebruik van uw gegevens voor eigen modeltraining door de provider expliciet afdekken. U moet verifiëren dat zij beveiligingsmaatregelen implementeren die zijn afgestemd op GDPR Artikel 32. Uw AI-toeleveringsketen moet net zo auditeerbaar zijn als uw kerninfrastructuur.
Van theorie naar praktijk: een concreet voorbeeld van een AI-functie die gereed is voor GDPR
Laten we dit concreet maken. Stel dat u een AI-assistent toevoegt die gesprekken met klantondersteuning samenvat, conceptantwoorden voorstelt en leert van eerdere tickets om te verbeteren.
Dit is een praktisch implementatiepatroon met de toolkit van Clarysec:
- Classificatie en etikettering: Alle supporttickets worden volgens uw Beleid inzake gegevensclassificatie en etikettering voor mkb geclassificeerd als “Vertrouwelijk”, in lijn met gegevensverwerkingsverplichtingen onder GDPR en DORA.
- Gegevensmaskering vóór de LLM: Een maskingservice onderschept de gegevens voordat ze naar de LLM worden verzonden. Deze verwijdert of vervangt namen, e-mailadressen, telefoonnummers en andere PII. Dit volledige proces wordt beheerst door het Beleid inzake gegevensmaskering en pseudonimisering, waarbij de FG de methodologie valideert.
- Toegangscontrole voor prompts en logboeken: Alleen geautoriseerde rollen (bijv. AI Product Owner) hebben toegang tot ruwe promptlogboeken. Dit wordt geïmplementeerd met ISO 27001:2022-beheersmaatregel 8.3 (beperking van toegang tot informatie) voor algemene toegang en beheersmaatregel 8.2 (geprivilegieerde toegangsrechten) voor zichtbaarheid op beheerdersniveau, zoals gemapt in Zenith Controls.
- Toestemming voor trainingscorpus: De trainingspijplijn neemt alleen gemaskeerde gegevens op. Er wordt een configuratie-instelling op tenantniveau aangeboden: “Sta toe dat mijn gemaskeerde gegevens worden gebruikt voor algemene verbetering van AI-modellen: Ja/Nee”, met standaardwaarde “Nee”.
- Bewaring en verwijdering: Promptlogboeken worden niet langer bewaard dan noodzakelijk. Wanneer een tenant de functie uitschakelt of het contract beëindigt, wordt een workflow gestart om gerelateerde AI-logboeken en trainingsitems veilig te verwijderen of te anonimiseren, volgens het proces dat in uw Zenith Blueprint-implementatie voor beheersmaatregel 8.10 (informatieverwijdering) is beschreven.
Wanneer auditors arriveren, kunt u hen door de gegevensstroomdiagrammen van de functie leiden, de specifieke beleidslijnen tonen die de functie beheersen en technisch bewijsmateriaal uit uw systemen, toegangslogboeken, jobconfiguraties en workflows voor wissing overleggen. U toont naleving in de praktijk aan.
Uw actieplan: van ad-hoc naar auditklare AI
U hoeft uw product niet uit elkaar te halen, maar u hebt wel een gestructureerde, verdedigbare aanpak nodig. Dit is een beknopt actieplan:
- Inventariseer AI-usecases en gegevensstromen: Identificeer elke plek waar LLM’s worden gebruikt: klantgerichte functies, interne tools en experimenten. Breng in kaart welke gegevens waarheen gaan, onder welke rechtsgrondslag en wie toegang heeft. Gebruik de funderingsfase van de Zenith Blueprint om te waarborgen dat uw wettelijke register alle AI-gerelateerde vereisten uit GDPR, NIS2 en DORA dekt.
- Richt eerst governance in: Voer vóór de bouw voor elke AI-functie een gegevensbeschermingseffectbeoordeling (DPIA) uit. Documenteer doel, rechtsgrondslag en risico’s. Implementeer basisbeleid zoals het Beleid inzake gegevensbescherming en privacy voor mkb en het Informatiebeveiligingsbeleid voor mkb.
- Beperk gegevens en toegang strikt: Implementeer robuuste technische beheersmaatregelen. Adopteer het Beleid inzake gegevensmaskering en pseudonimisering en het Beleid inzake testgegevens en testomgevingen voor mkb. Gebruik Zenith Controls om ISO 27001:2022-beheersmaatregelen 8.2 en 8.3 voor alle AI-gegevensopslagplaatsen en -pijplijnen te implementeren en te documenteren.
- Veranker rechten van betrokkenen in AI-workflows: Werk uw DSAR- en verwijderingsprocedures bij zodat AI-gerelateerde gegevens worden meegenomen. Documenteer uw strategie voor het behandelen van verzoeken om wissing in de context van getrainde modellen, met nadruk op pseudonimisering en schema’s voor modelhertraining.
- Breng uw AI-toeleveringsketen onder controle: Werk DPA’s bij met externe LLM-providers en uitbestede ontwikkelaars. Zorg dat contracten onbevoegd gegevensgebruik expliciet verbieden en sterke beveiligingsmaatregelen vereisen. Verifieer dat externe teams zijn getraind in uw beleid voor gegevensverwerking.
Innoveren met vertrouwen
Het snijvlak van AI en GDPR is de nieuwe grens van naleving. Door een gestructureerde, risicogebaseerde aanpak te hanteren, kunt u de transformatieve kracht van kunstmatige intelligentie benutten zonder uw inzet voor gegevensbescherming en privacy in gevaar te brengen.
Clarysec biedt de kaart, de tools en de expertise om u op die reis te begeleiden. Met:
- Zenith Blueprint: een 30-stappenroadmap voor auditors voor een gefaseerde implementatie van op GDPR afgestemde beheersmaatregelen voor AI.
- Zenith Controls: de cross-compliancegids om ISO 27001:2022-beheersmaatregelen te verenigen met vereisten uit GDPR, NIS2, DORA en NIST.
- Productiegerede beleidsdocumenten zoals het Beleid inzake gegevensbescherming en privacy voor mkb, het Beleid inzake gegevensmaskering en pseudonimisering en het Beleid inzake testgegevens en testomgevingen voor mkb om uw regels vast te leggen en auditors tevreden te stellen.
U kunt overstappen van ad-hoc AI-experimenten naar een auditklare AI-capaciteit die vertrouwen wekt bij toezichthouders, auditors en veeleisende zakelijke klanten. U kunt blijven innoveren met LLM’s en toch rustig slapen.
Als u AI-functies in uw SaaS-product plant of al uitvoert, is uw volgende stap duidelijk. Download onze toolkitvoorbeelden of boek een demo om te zien hoe Clarysec u kan helpen een AI-programma te bouwen dat niet alleen krachtig is, maar ook aantoonbaar privacyvriendelijk en veilig door ontwerp.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council