Anatomia naruszenia: przewodnik dla producentów po reagowaniu na incydenty zgodnie z ISO 27001
Wyróżniony fragment
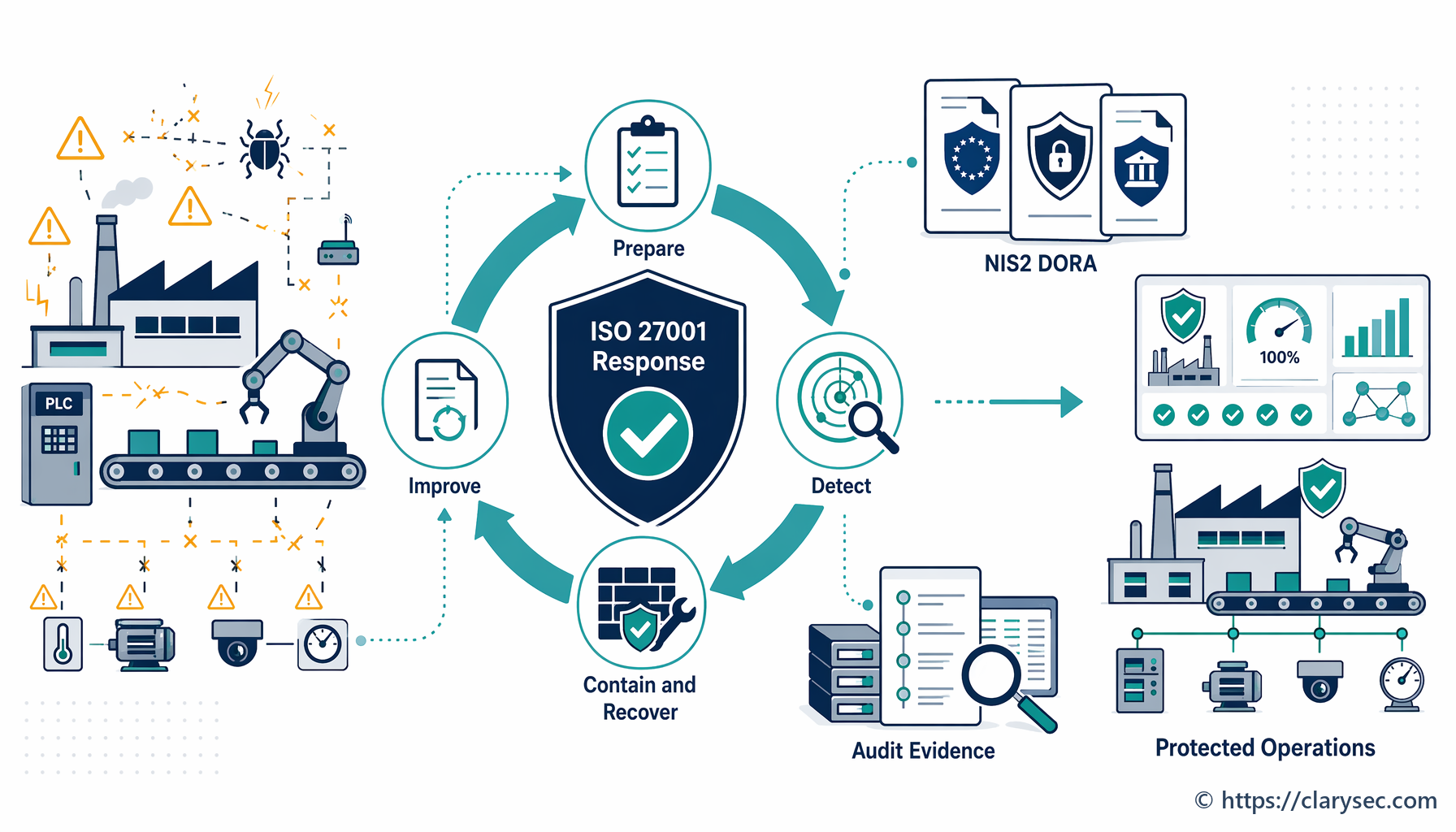
Skuteczne reagowanie na incydenty bezpieczeństwa informacji ogranicza szkody wynikające z naruszeń bezpieczeństwa i zapewnia odporność operacyjną. Ten przewodnik przedstawia krok po kroku podejście oparte na ISO 27001, pomagając producentom przygotować się na rzeczywiste cyberataki, reagować na nie i odtwarzać sprawność działania, przy jednoczesnym spełnianiu złożonych wymagań zgodności, takich jak NIS2 i DORA.
Wprowadzenie
Alert pojawia się o 2:17 w nocy. Centralny serwer średniej wielkości producenta części samochodowych nie odpowiada, a monitory linii produkcyjnej wyświetlają komunikat ransomware. Każda minuta przestoju oznacza tysiące utraconej produkcji i ryzyko naruszenia rygorystycznych SLA w łańcuchu dostaw. To nie są ćwiczenia. Dla dyrektora ds. bezpieczeństwa informacji jest to moment, w którym lata planowania, tworzenia polityk i szkoleń zostają poddane ostatecznej próbie.
Posiadanie planu reagowania na incydenty na serwerze to jedno; wykonanie go pod skrajną presją to zupełnie inna kwestia. W przypadku producentów stawka jest wyjątkowo wysoka. Cyberincydent nie tylko narusza dane; zatrzymuje produkcję, zakłóca fizyczne łańcuchy dostaw i może zagrażać bezpieczeństwu pracowników.
Ten przewodnik wychodzi poza teoretyczne podręczniki postępowania i przedstawia praktyczną, realistyczną ścieżkę budowy oraz prowadzenia skutecznego programu reagowania na incydenty. Przeanalizujemy anatomię reakcji na naruszenie bezpieczeństwa, opierając się na solidnych podstawach ISO/IEC 27001, oraz pokażemy, jak zbudować odporny program, który nie tylko umożliwia odtworzenie sprawności po ataku, lecz także spełnia oczekiwania audytorów i organów regulacyjnych.
Co jest zagrożone: efekt domina po naruszeniu w środowisku produkcyjnym
Gdy systemy producenta zostają naruszone, wpływ wykracza daleko poza pojedynczy serwer. Współzależność nowoczesnej produkcji — od zarządzania zapasami po zrobotyzowane linie montażowe — oznacza, że awaria cyfrowa może doprowadzić do pełnego zatrzymania operacji. Konsekwencje są poważne i wielowymiarowe.
Po pierwsze, straty finansowe pojawiają się natychmiast i są dotkliwe. Wstrzymanie produkcji prowadzi do niedotrzymania terminów, kar umownych ze strony klientów oraz kosztów bezczynności załogi. Odtwarzanie systemów, zaangażowanie ekspertów informatyki śledczej oraz potencjalne negocjacje związane z żądaniem okupu mogą zachwiać finansami średniej wielkości organizacji.
Po drugie, szkoda reputacyjna może utrzymywać się długo. W środowisku B2B niezawodność jest podstawą relacji. Jeden poważny incydent może podważyć zaufanie kluczowych partnerów zależnych od dostaw just-in-time. Jak wskazują nasze wewnętrzne wytyczne, kluczowym celem zarządzania incydentami jest „minimalizacja biznesowego i finansowego wpływu incydentów oraz jak najszybsze przywrócenie normalnego działania” — cel o fundamentalnym znaczeniu w produkcji.
Wreszcie, konsekwencje regulacyjne mogą być bardzo poważne. Wraz z pełnym wejściem w życie takich regulacji jak unijna dyrektywa NIS2 oraz Digital Operational Resilience Act (DORA), organizacje z sektorów krytycznych, w tym producenci, podlegają rygorystycznym wymaganiom zgłaszania incydentów oraz ryzyku znaczących kar za brak zgodności. Źle zarządzany incydent nie jest wyłącznie awarią techniczną; stanowi istotne ryzyko prawne i ryzyko zgodności.
Jak wygląda stan docelowy: od chaosu do kontroli
Skuteczny program reagowania na incydenty przekształca kryzys z chaotycznej, reaktywnej improwizacji w uporządkowany i kontrolowany proces. Celem nie jest wyłącznie usunięcie problemu technicznego, lecz zarządzanie całym zdarzeniem w sposób chroniący organizację. Taki stan docelowy opiera się na zasadach określonych w ISO/IEC 27001, w szczególności na zabezpieczeniach dotyczących zarządzania incydentami bezpieczeństwa informacji.
Dojrzały program charakteryzuje się kilkoma kluczowymi rezultatami:
- Jasność ról: Każdy wie, z kim należy się skontaktować i jakie ma obowiązki. Zespół reagowania na incydenty (IRT) jest zdefiniowany z wyprzedzeniem, z jasno wskazanym kierownictwem oraz wyznaczonymi ekspertami z IT, bezpieczeństwa informacji, obszaru prawnego, komunikacji i kadry zarządzającej.
- Szybkość i precyzja: Organizacja potrafi szybko wykrywać, analizować i powstrzymywać zagrożenia, uniemożliwiając ich rozprzestrzenianie się w sieci oraz zatrzymanie całej hali produkcyjnej.
- Decyzje oparte na informacji: Kierownictwo otrzymuje aktualne i dokładne informacje, co pozwala podejmować krytyczne decyzje dotyczące operacji, komunikacji z klientami i zgłoszeń regulacyjnych.
- Ciągłe doskonalenie: Każdy incydent, duży czy mały, staje się okazją do nauki. Rzetelny proces przeglądu poincydentalnego identyfikuje słabości i przekłada wnioski na usprawnienia programu bezpieczeństwa.
Osiągnięcie takiego poziomu gotowości jest głównym celem zabezpieczeń opisanych w ISO/IEC 27002:2022. Zabezpieczenia te prowadzą organizacje przez planowanie i przygotowanie (A.5.24), ocenę zdarzeń i podejmowanie decyzji (A.5.25), reagowanie na incydenty (A.5.26) oraz uczenie się na ich podstawie (A.5.28). Chodzi o zbudowanie odpornego systemu, który zakłada możliwość awarii i jest przygotowany do jej kontrolowanej obsługi.
Praktyczna ścieżka: przewodnik krok po kroku po reagowaniu na incydenty
Budowa solidnych zdolności reagowania na incydenty wymaga udokumentowanego, systematycznego podejścia. Podstawą jest jasna i możliwa do zastosowania polityka opisująca każdą fazę procesu.
Nasza P16S Information Security Incident Management Planning and Preparation Policy - SME zapewnia kompleksowy wzorzec zgodny z najlepszymi praktykami ISO 27001. Przejdźmy przez kluczowe kroki, wykorzystując tę politykę jako przewodnik.
Krok 1: Planowanie i przygotowanie — fundament odporności
Nie da się tworzyć planu reagowania w środku kryzysu. Przygotowanie jest kluczowe. Ta faza polega na ustanowieniu struktury, narzędzi i wiedzy potrzebnych do zdecydowanego działania w momencie wystąpienia incydentu.
Kluczowym elementem jest powołanie zespołu reagowania na incydenty (IRT). Zgodnie z sekcją 5.1 P16S Information Security Incident Management Planning and Preparation Policy - SME, celem polityki jest „zapewnienie spójnego i skutecznego podejścia do zarządzania incydentami bezpieczeństwa informacji”. Ta spójność zaczyna się od dobrze zdefiniowanego zespołu. Polityka wymaga, aby IRT obejmował przedstawicieli kluczowych obszarów:
- IT i bezpieczeństwo informacji
- obszar prawny i zgodność
- dział personalny
- komunikacja i PR
- kierownictwo wyższego szczebla
Każdy członek musi mieć jasno określone role i odpowiedzialności. Kto ma uprawnienia do wyłączenia systemów? Kto jest wyznaczonym rzecznikiem w komunikacji z klientami lub mediami? Odpowiedzi na te pytania muszą zostać ustalone i udokumentowane na długo przed incydentem.
Krok 2: Wykrywanie i zgłaszanie — system wczesnego ostrzegania
Im szybciej organizacja dowie się o incydencie, tym mniejsze szkody może on wyrządzić. Wymaga to zarówno technicznego monitorowania, jak i kultury, w której pracownicy mają uprawnienia i obowiązek zgłaszania podejrzanej aktywności.
P16S Information Security Incident Management Planning and Preparation Policy - SME jest w tym zakresie jednoznaczna. Sekcja 5.3, „Zgłaszanie zdarzeń bezpieczeństwa informacji”, wymaga:
„Wszyscy pracownicy, wykonawcy i inne właściwe strony są zobowiązani do jak najszybszego zgłaszania wszelkich zaobserwowanych lub podejrzewanych zdarzeń bezpieczeństwa informacji oraz słabości do wyznaczonego punktu kontaktowego.”
Ten „wyznaczony punkt kontaktowy” ma kluczowe znaczenie. Może nim być centrum obsługi IT albo dedykowana linia zgłoszeń bezpieczeństwa. Proces musi być prosty i dobrze zakomunikowany całemu personelowi. Pracownicy powinni być szkoleni, na co zwracać uwagę — na przykład na wiadomości phishingowe, nietypowe zachowanie systemów lub naruszenia bezpieczeństwa fizycznego.
Krok 3: Ocena i wstępna kwalifikacja — określenie skali zagrożenia
Po zgłoszeniu zdarzenia kolejnym krokiem jest szybka ocena jego charakteru i wagi. Czy to fałszywy alarm, drobny problem, czy pełnoskalowy kryzys? Proces wstępnej kwalifikacji określa wymagany poziom reakcji.
Nasza polityka przedstawia w sekcji 5.2, „Klasyfikacja incydentów”, jasny schemat klasyfikacji incydentów na podstawie ich wpływu na poufność, integralność i dostępność. Typowy schemat może wyglądać następująco:
- Niski: Pojedyncza stacja robocza zainfekowana typowym złośliwym oprogramowaniem, łatwa do odizolowania.
- Średni: Serwer działowy jest niedostępny, co wpływa na konkretną funkcję biznesową, ale nie zatrzymuje całej produkcji.
- Wysoki: Szeroko zakrojony atak ransomware wpływający na krytyczne systemy produkcyjne i kluczowe dane biznesowe.
- Krytyczny: Incydent obejmujący naruszenie ochrony danych osobowych wymagających szczególnej ochrony lub własności intelektualnej, ze znaczącymi konsekwencjami prawnymi i reputacyjnymi.
Ta klasyfikacja określa pilność, przydzielone zasoby oraz ścieżkę eskalacji do kierownictwa, zapewniając proporcjonalność reakcji do zagrożenia.
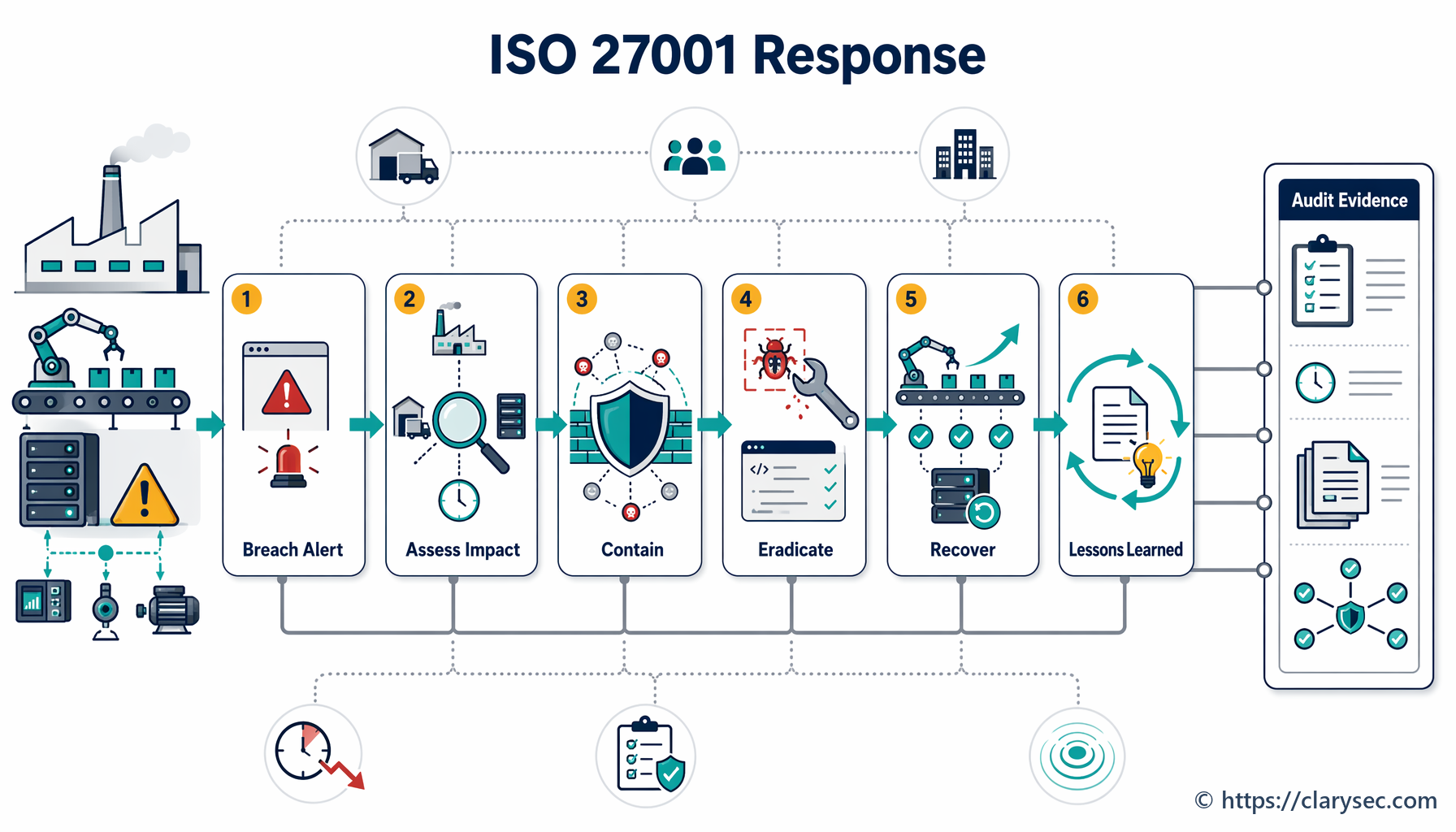
Krok 4: Powstrzymanie, eradykacja i odtwarzanie — gaszenie pożaru
To aktywna faza reagowania, w której IRT działa w celu opanowania incydentu i przywrócenia normalnych operacji.
- Powstrzymanie: Natychmiastowym priorytetem jest zatrzymanie dalszych szkód. Może to obejmować izolację dotkniętych segmentów sieci, odłączenie naruszonych serwerów lub blokowanie złośliwych adresów IP. Celem jest zapobieżenie rozprzestrzenianiu się incydentu i dalszym szkodom.
- Eradykacja: Po powstrzymaniu należy wyeliminować przyczynę źródłową incydentu. Może to oznaczać usunięcie złośliwego oprogramowania, wdrożenie poprawek dla wykorzystanych podatności oraz dezaktywację naruszonych kont użytkowników.
- Odtwarzanie: Ostatnim krokiem jest przywrócenie dotkniętych systemów i danych. Obejmuje to odtwarzanie z czystych kopii zapasowych, odbudowę systemów oraz uważne monitorowanie, aby upewnić się, że zagrożenie zostało całkowicie usunięte przed ponownym uruchomieniem usług.
Sekcja 5.4 P16S Information Security Incident Management Planning and Preparation Policy - SME, „Reagowanie na incydenty bezpieczeństwa informacji”, zapewnia ramy dla tych działań, podkreślając, że „procedury reagowania należy uruchomić po zaklasyfikowaniu zdarzenia bezpieczeństwa informacji jako incydentu”.
Krok 5: Działania poincydentalne — wyciąganie wniosków
Praca nie kończy się po ponownym uruchomieniu systemów. Faza poincydentalna jest prawdopodobnie najważniejsza dla budowania długoterminowej odporności. Obejmuje dwa kluczowe działania: zabezpieczenie materiału dowodowego oraz przegląd wniosków z incydentu.
Polityka podkreśla znaczenie zabezpieczania materiału dowodowego w sekcji 5.5, wskazując, że „należy ustanowić i stosować procedury gromadzenia, pozyskiwania oraz zabezpieczania dowodów związanych z incydentami bezpieczeństwa informacji”. Ma to kluczowe znaczenie dla wewnętrznego dochodzenia, działań organów ścigania oraz ewentualnych czynności prawnych.
Następnie należy przeprowadzić formalny przegląd poincydentalny. Spotkanie powinno obejmować wszystkich członków IRT oraz kluczowych interesariuszy i dotyczyć następujących kwestii:
- Co się wydarzyło i jaka była oś czasu zdarzeń?
- Co zadziałało dobrze podczas reakcji?
- Jakie wyzwania napotkano?
- Co można zrobić, aby zapobiec podobnemu incydentowi w przyszłości?
Wynikiem tego przeglądu powinien być plan działań z przypisanymi właścicielami i terminami, służący usprawnieniu polityk, procedur i technicznych zabezpieczeń. Tworzy to pętlę informacji zwrotnej, która z czasem wzmacnia profil ryzyka bezpieczeństwa organizacji.
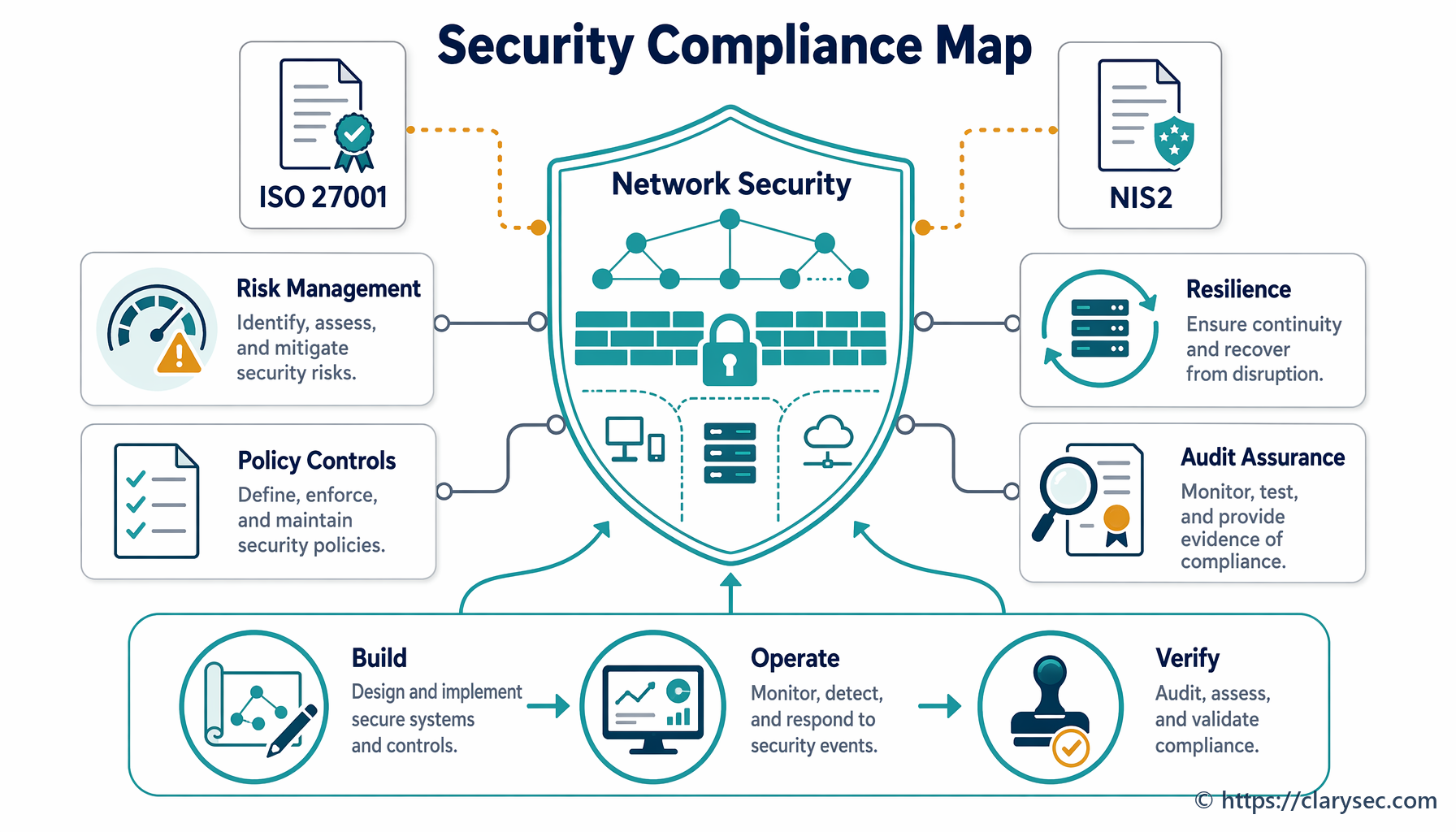
Łączenie wymagań: perspektywa zgodności przekrojowej
Spełnienie wymagań ISO 27001 dotyczących zarządzania incydentami nie tylko wzmacnia bezpieczeństwo; stanowi także solidną podstawę zgodności z rosnącą siecią regulacji międzynarodowych i branżowych. Wiele z tych ram opiera się na tych samych podstawowych zasadach: przygotowaniu, reagowaniu i raportowaniu.
Jak wyjaśniono w Zenith Controls, naszym kompleksowym przewodniku po zgodności przekrojowej, solidny proces zarządzania incydentami jest jednym z filarów odporności cyfrowej. Zobaczmy, jak podejście ISO 27001 łączy się z innymi głównymi ramami.
Zabezpieczenia ISO/IEC 27002:2022: Najnowsza wersja normy ISO/IEC 27002 zapewnia szczegółowe wytyczne dotyczące zarządzania incydentami poprzez dedykowany zestaw zabezpieczeń:
- A.5.24 - Planowanie i przygotowanie zarządzania incydentami bezpieczeństwa informacji: Ustanawia potrzebę zdefiniowanego i udokumentowanego podejścia.
- A.5.25 - Ocena i decyzja dotycząca zdarzeń bezpieczeństwa informacji: Zapewnia właściwą ocenę zdarzeń w celu ustalenia, czy są incydentami.
- A.5.26 - Reagowanie na incydenty bezpieczeństwa informacji: Obejmuje działania związane z powstrzymaniem, eradykacją i odtwarzaniem.
- A.5.27 - Zgłaszanie incydentów bezpieczeństwa informacji: Określa, w jaki sposób i kiedy incydenty są zgłaszane kierownictwu oraz innym interesariuszom.
- A.5.28 - Uczenie się na podstawie incydentów bezpieczeństwa informacji: Wymaga procesu ciągłego doskonalenia.
Te zabezpieczenia tworzą pełny cykl życia, odzwierciedlony również w innych istotnych regulacjach.
Dyrektywa NIS2: Dla operatorów usług kluczowych, w tym wielu producentów, NIS2 nakłada rygorystyczne obowiązki w zakresie bezpieczeństwa i zgłaszania incydentów. Zenith Controls wskazuje bezpośrednie pokrycie wymagań:
„Article 21 dyrektywy NIS2 wymaga, aby podmioty kluczowe i ważne wdrożyły odpowiednie i proporcjonalne środki techniczne, operacyjne i organizacyjne w celu zarządzania ryzykami dla bezpieczeństwa sieci i systemów informatycznych. Obejmuje to wprost polityki i procedury obsługi incydentów. Ponadto Article 23 ustanawia wieloetapowy proces zgłaszania incydentów, wymagający wczesnego ostrzeżenia w ciągu 24 godzin oraz szczegółowego raportu w ciągu 72 godzin do właściwych organów (CSIRT).”
Plan reagowania na incydenty zgodny z ISO 27001 zapewnia dokładnie te mechanizmy, które są potrzebne do dotrzymania krótkich terminów raportowania.
Digital Operational Resilience Act (DORA): Choć DORA koncentruje się na sektorze finansowym, jego zasady odporności stają się punktem odniesienia dla wszystkich branż. Przewodnik podkreśla to powiązanie:
„DORA Article 17 wymaga, aby podmioty finansowe posiadały kompleksowy proces zarządzania incydentami związanymi z ICT, umożliwiający wykrywanie, zarządzanie i zgłaszanie incydentów związanych z ICT. Article 19 wymaga klasyfikacji incydentów na podstawie kryteriów określonych w rozporządzeniu oraz zgłaszania poważnych incydentów właściwym organom z użyciem zharmonizowanych szablonów. Odzwierciedla to wymagania dotyczące klasyfikacji i raportowania występujące w ISO 27001.”
General Data Protection Regulation (GDPR): W przypadku każdego incydentu obejmującego dane osobowe wymagania GDPR mają zasadnicze znaczenie. Szybka i uporządkowana reakcja nie jest opcjonalna. Jak wyjaśnia Zenith Controls:
„Zgodnie z GDPR, Article 33 wymaga, aby administratorzy danych zgłaszali organowi nadzorczemu naruszenie ochrony danych osobowych bez zbędnej zwłoki, a jeżeli to wykonalne, nie później niż w ciągu 72 godzin od uzyskania wiedzy o naruszeniu. Article 34 nakazuje zawiadomienie osoby, której dane dotyczą, o naruszeniu, gdy może ono powodować wysokie ryzyko naruszenia jej praw i wolności. Skuteczny plan reagowania na incydenty jest niezbędny do zebrania informacji koniecznych do dokonania tych zgłoszeń dokładnie i terminowo.”
Budując program reagowania na incydenty na fundamencie ISO 27001, organizacja równolegle rozwija zdolności potrzebne do obsługi złożonych wymagań tych powiązanych regulacji.
Przygotowanie do audytu: o co zapytają audytorzy
Plan reagowania na incydenty, który nigdy nie był testowany ani przeglądany, jest wyłącznie dokumentem. Audytorzy o tym wiedzą i podczas audytu certyfikacyjnego ISO 27001 będą szczegółowo weryfikować, czy program jest żywym, operacyjnym elementem SZBI.
Zgodnie z Zenith Blueprint, naszą mapą drogową audytora, ocena reagowania na incydenty jest krytycznym krokiem w procesie audytu. Podczas „Fazy 3: prace w terenie i gromadzenie dowodów” audytorzy systematycznie przetestują przygotowanie organizacji.
Poniżej przedstawiono, czego można się spodziewać na podstawie kroku 21 Zenith Blueprint, „Ocena reagowania na incydenty i ciągłości działania”:
„Proszę pokazać plan i politykę reagowania na incydenty.” Audytorzy zaczną od dokumentacji. Sprawdzą kompletność polityki, w tym zdefiniowane role i odpowiedzialności, kryteria klasyfikacji, plany komunikacji oraz procedury dla każdej fazy cyklu życia incydentu. Zweryfikują, czy dokument został formalnie zatwierdzony i zakomunikowany właściwemu personelowi.
„Proszę pokazać zapisy z ostatnich trzech incydentów bezpieczeństwa.” To moment praktycznej weryfikacji. Audytorzy muszą zobaczyć dowody, że plan jest rzeczywiście stosowany. Będą oczekiwać logów incydentów lub zgłoszeń dokumentujących:
- datę i godzinę wykrycia;
- opis incydentu;
- przypisany priorytet lub poziom klasyfikacji;
- rejestr działań podjętych w zakresie powstrzymania, eradykacji i odtwarzania;
- datę i godzinę rozwiązania.
„Proszę pokazać protokół i plan działań z ostatniego przeglądu poincydentalnego.” Jak podkreśla Zenith Blueprint, ciągłe doskonalenie jest wymaganiem bezwarunkowym.
„Podczas audytu będziemy poszukiwać obiektywnych dowodów potwierdzających, że przeglądy poincydentalne są prowadzone systematycznie. Obejmuje to przegląd protokołów ze spotkań, rejestrów działań oraz dowodów, że zidentyfikowane usprawnienia zostały wdrożone, takich jak zaktualizowane procedury lub nowe techniczne zabezpieczenia. Bez tej pętli informacji zwrotnej SZBI nie może zostać uznany za »ciągle doskonalony«, jak wymaga tego norma.”
„Proszę pokazać dowody, że plan został przetestowany.” Audytorzy chcą zobaczyć, że organizacja proaktywnie testuje swoje zdolności, a nie czeka na rzeczywisty incydent. Dowody mogą mieć różną formę — od ćwiczeń typu tabletop z udziałem kierownictwa po pełnoskalowe symulacje techniczne. Audytorzy będą oczekiwać raportu z takich testów, opisującego scenariusz, uczestników, wyniki i wnioski.
Przygotowanie takich dowodów pokazuje, że program reagowania na incydenty nie jest pozorny, lecz stanowi solidny, operacyjny i skuteczny element SZBI.
Typowe pułapki, których należy unikać
Nawet przy dobrze udokumentowanym planie wiele organizacji potyka się podczas rzeczywistego incydentu. Oto najczęstsze pułapki, na które należy uważać:
- Syndrom „planu na półce”: Najczęstsza nieskuteczność polega na posiadaniu świetnie napisanego planu, którego nikt nie przeczytał, nie zrozumiał ani nie przećwiczył. Jedynym antidotum są regularne szkolenia i testy.
- Nieokreślone uprawnienia: W kryzysie niejednoznaczność jest wrogiem. Jeżeli IRT nie ma uprzednio zatwierdzonych uprawnień do podjęcia zdecydowanych działań, takich jak wyłączenie krytycznego systemu produkcyjnego, reakcja zostanie sparaliżowana niezdecydowaniem, a szkody będą się rozprzestrzeniać.
- Słaba komunikacja: Brak zarządzania komunikacją to przepis na katastrofę. Obejmuje to niepoinformowanie kierownictwa, przekazywanie pracownikom niespójnych komunikatów lub niewłaściwą komunikację z klientami i organami regulacyjnymi. Niezbędny jest uprzednio zatwierdzony plan komunikacji z szablonami.
- Zaniedbanie zabezpieczenia dowodów: W pośpiechu przywracania usługi zespół techniczny może nieumyślnie zniszczyć kluczowe dowody z zakresu informatyki śledczej. Może to uniemożliwić ustalenie przyczyny źródłowej, zapobieżenie powtórzeniu incydentu lub wsparcie działań prawnych.
- Brak uczenia się: Uznanie incydentu za „zakończony” w chwili ponownego uruchomienia systemu to zmarnowana szansa. Bez rygorystycznej analizy poincydentalnej organizacja jest skazana na powtarzanie tych samych błędów.
Kolejne kroki
Przejście od teorii do praktyki jest najważniejszym krokiem. Solidny program reagowania na incydenty to droga ciągłego doskonalenia, a nie jednorazowy projekt. Oto jak zacząć:
- Sformalizuj podejście: Jeśli nie masz formalnej polityki reagowania na incydenty, teraz jest właściwy moment, aby ją stworzyć. Wykorzystaj naszą P16S Information Security Incident Management Planning and Preparation Policy - SME jako szablon do budowy kompleksowych ram.
- Zrozum krajobraz zgodności: Zmapuj procedury reagowania na incydenty na konkretne wymagania regulacji takich jak NIS2, DORA i GDPR. Nasz przewodnik Zenith Controls zawiera odniesienia krzyżowe potrzebne do zapewnienia pełnego pokrycia wymagań.
- Przygotuj się do audytu: Wykorzystaj perspektywę audytora, aby poddać program testowi odporności. Zenith Blueprint pokazuje od środka, czego będą wymagać audytorzy, aby można było zgromadzić dowody i być gotowym do wykazania skuteczności.
Podsumowanie
Dla nowoczesnego producenta reagowanie na incydenty bezpieczeństwa informacji nie jest problemem IT; jest kluczową funkcją ciągłości działania. Różnica między drobnym zakłóceniem a katastrofalną awarią zależy od przygotowania, ćwiczeń oraz konsekwentnego stosowania uporządkowanego, powtarzalnego procesu.
Opierając program na globalnie uznanej normie ISO 27001, organizacja buduje nie tylko zdolność obronną, lecz także odporność całej organizacji. Tworzy system, który potrafi wytrzymać wstrząs spowodowany naruszeniem, zarządzać kryzysem w sposób kontrolowany i precyzyjny oraz wyjść z niego silniejszy i bezpieczniejszy. Czas na przygotowanie jest teraz — zanim alert o 2:17 stanie się rzeczywistością.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council