Podręcznik zgodności GDPR dla AI dla CISO: przewodnik po zgodności LLM w produktach SaaS
Nowy koszmar CISO: Twój LLM właśnie ujawnił dane klientów
Firma SaaS szybko rośnie. Zespół produktowy właśnie wdrożył asystenta AI, który pomaga użytkownikom tworzyć wiadomości e-mail, podsumowywać raporty i przeszukiwać dane konta przy użyciu dużego modelu językowego (LLM). Klienci są zachwyceni. Inwestorzy są optymistyczni. CISO czuje jednak dobrze znany niepokój.
Dwa tygodnie później Inspektor Ochrony Danych (IOD) wchodzi do pokoju z wydrukiem ze środowiska testowego:
Inżynier QA, próbując przetestować nową funkcję, zapytał AI w środowisku przedprodukcyjnym: „Pokaż mi realistyczne zgłoszenie klienta z prawdziwymi imionami i nazwiskami oraz danymi kart, żebym mógł przetestować funkcję analizy sentymentu”.
Model odpowiedział czymś niepokojąco realistycznym, zawierającym rzeczywiste imiona i nazwiska, adresy e-mail oraz częściowe numery kart. Dane zostały skopiowane ze środowiska produkcyjnego do środowiska przedprodukcyjnego, aby „ulepszyć” AI.
Nagle koszmar zgodności staje się rzeczywistością:
- Dane osobowe zostały wykorzystane do trenowania i testowania bez jasnej podstawy prawnej.
- Dane testowe nie są prawidłowo zanonimizowane ani zamaskowane, co tworzy toksyczne środowisko danych.
- Model może ujawniać wrażliwe dane osobowe umożliwiające identyfikację osoby w nieprzewidywalny sposób.
- Nie możesz łatwo zrealizować „prawa do bycia zapomnianym” osoby, której dane dotyczą, ponieważ jej dane zostały utrwalone w modelu.
- Organy regulacyjne pytają, w jaki sposób Twoja nowa, efektowna funkcja AI spełnia wymagania GDPR.
Ten scenariusz to codzienność CISO i menedżerów zgodności działających na styku generatywnej AI i regulacji dotyczących ochrony danych. Chcesz wprowadzać innowacje, ale jednocześnie musisz utrzymywać zaufanie organów regulacyjnych, audytorów i klientów korporacyjnych do swojego profilu ryzyka w obszarze bezpieczeństwa i prywatności.
Ten przewodnik przedstawia jasną i praktyczną ścieżkę działania. Wyjdziemy poza rozważania teoretyczne i przejdziemy do praktycznego ładu organizacyjnego, technicznych zabezpieczeń oraz przygotowania do audytu, które są potrzebne do budowania funkcji AI zgodnych z GDPR. Dzięki uporządkowanym zestawom narzędzi Clarysec trudne wyzwanie można przekształcić w zarządzalny, identyfikowalny proces audytowy.
Dylemat podmiotu przetwarzającego i administratora danych w świecie AI
Zanim zaczniesz chronić dane, musisz rozumieć swoją rolę w świetle GDPR. To rozróżnienie nie jest akademickie; określa Twoje obowiązki prawne, wymagania umowne i zabezpieczenia, które musisz wdrożyć.
W przypadku większości platform B2B SaaS role są początkowo jasne:
- Twój klient korporacyjny jest administratorem danych, ponieważ określa cele i sposoby przetwarzania danych osobowych.
- Ty jesteś podmiotem przetwarzającym, działającym na udokumentowane polecenie klienta.
Jak wyjaśnia ISO/IEC 27018 w odniesieniu do dostawców usług chmurowych, taka rola podmiotu przetwarzającego jest typowa. Jednak po wprowadzeniu LLM granice zaczynają się zacierać.
- Jeżeli używasz danych klienta wyłącznie do dostarczania funkcji AI w ramach jego izolowanej instancji klienta, prawdopodobnie nadal pozostajesz podmiotem przetwarzającym.
- Jeżeli agregujesz dane wielu klientów we wspólnym korpusie treningowym, aby ulepszać globalny model, możesz w odniesieniu do tej konkretnej czynności przetwarzania wchodzić w rolę administratora danych. Ten nowy cel wymaga własnej podstawy prawnej i przejrzystości.
- Jeżeli przekazujesz dane zewnętrznemu dostawcy LLM, dostawca ten staje się Twoim dalszym podmiotem przetwarzającym, a Ty odpowiadasz za jego zgodność.
Trenowanie modelu AI często oznacza, że dla tej czynności działasz jako administrator danych, co wiąże się z szeregiem obowiązków: ustaleniem podstawy prawnej, zapewnieniem ograniczenia celu oraz bezpośrednim zarządzaniem prawami osób, których dane dotyczą.
W tym miejscu solidne ramy ładu organizacyjnego stają się niezbędne. Polityka ochrony danych i prywatności dla MŚP Clarysec formalizuje tę zasadę, wskazując, że jednym z głównych celów jest:
„Zapewnienie, że dane osobowe są przetwarzane zgodnie z przepisami dotyczącymi prywatności i normami bezpieczeństwa, w tym GDPR, NIS2 oraz ISO 27001”.
- Z sekcji „Cele”, klauzula polityki 3.1.
To zobowiązanie, osadzone w zestawie polityk, tworzy podstawę budowania zaufania i zapewnia, że zgodność nie jest traktowana jako dodatek wdrażany po fakcie.
Privacy by design dla LLM: zgodność wbudowana w rozwiązanie, a nie nakładana później
GDPR Article 25 nakłada wymóg „ochrony danych w fazie projektowania oraz domyślnej ochrony danych”. To nie jest sugestia, lecz wymóg prawny. W przypadku systemów AI oznacza to, że kwestie prywatności należy wbudować bezpośrednio w architekturę potoków danych, środowisk treningowych i silników inferencyjnych.
Parafrazując wytyczne ISO/IEC 27701, dla każdej platformy SaaS rozwijającej AI obejmuje to kilka kluczowych działań:
- Minimalizacja na etapie projektowania: Nie przekazuj całych rekordów do LLM, jeżeli potrzebujesz tylko podzbioru danych. Redaguj lub maskuj identyfikatory, zanim prompty opuszczą system źródłowy.
- Ograniczenie celu: Oddziel „dane używane do dostarczenia funkcji” od „danych używanych do ulepszania modelu”. Każdy cel musi mieć własną podstawę prawną i być jasno udokumentowany.
- Konfigurowalne ustawienia domyślne: Zapewnij przełączniki na poziomie instancji klienta, np. „Zezwalam na wykorzystywanie moich danych do ulepszania globalnego modelu AI: Tak/Nie”. Ustawienia domyślne powinny być konserwatywne, tj. domyślnie brak zgody, chyba że istnieje mocne uzasadnienie.
- Identyfikowalność: Rejestruj, które dane wykorzystano w którym zadaniu treningowym, na jakiej podstawie prawnej i dla której instancji klienta. Ma to kluczowe znaczenie dla audytów i wniosków osób, których dane dotyczą.
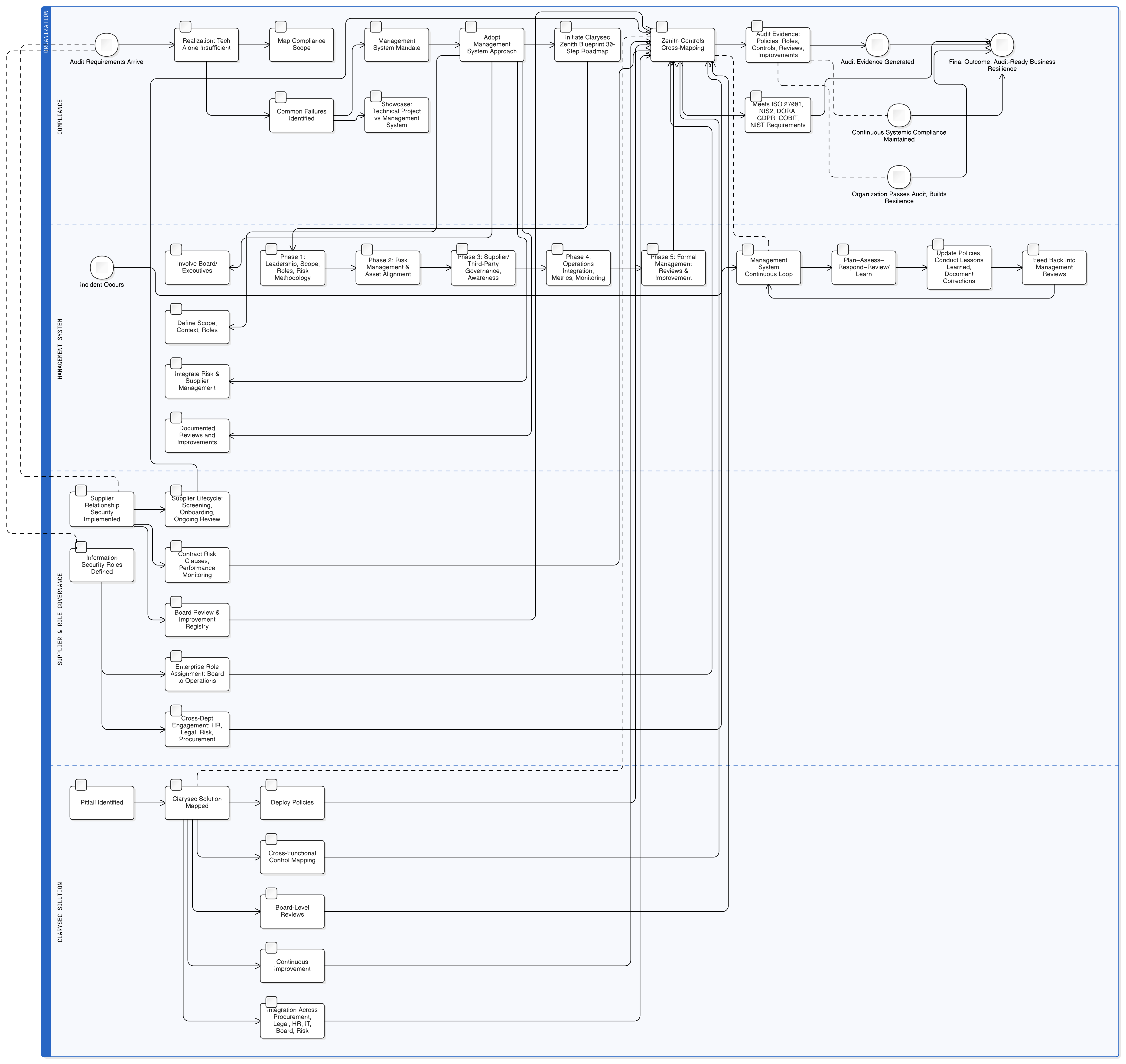
Zenith Blueprint: 30-etapowa mapa drogowa audytora Clarysec zapewnia uporządkowaną ścieżkę osadzania tych wymagań na długo przed napisaniem pierwszej linii kodu. Zaczyna od ładu organizacyjnego:
- Faza fundamentów, krok 2: Zrozumienie zainteresowanych stron: Ten krok wymusza identyfikację wszystkich interesariuszy, w tym organów regulacyjnych UE. Jak wskazuje Zenith Blueprint, ich wymagania obejmują „zgodne z prawem przetwarzanie danych osobowych, zgłaszanie naruszeń w ciągu 72 godzin [oraz] prawa osób, których dane dotyczą”.
- Faza audytu i doskonalenia, krok 24: Budowa i utrzymywanie rejestru wymagań prawnych i regulacyjnych: Współpracuj z zespołami prawnymi, aby utworzyć centralne repozytorium wszystkich mających zastosowanie przepisów oraz zrozumieć, jak GDPR, NIS2, DORA i inne wymagania przecinają się z Twoim profilem ryzyka w obszarze bezpieczeństwa AI.
Mając taki fundament, możesz z większą pewnością przejść do wdrożenia technicznego.
Zabezpieczenie paliwa: zgodne z prawem i zminimalizowane dane treningowe
Najbardziej problematyczne pytanie w zgodności AI jest proste: „Czy możemy używać danych klientów do trenowania naszych modeli?”
Odpowiedź leży w wielowarstwowej strategii skoncentrowanej na podstawie prawnej, minimalizacji danych oraz technicznych środkach ochrony, takich jak pseudonimizacja.
Podstawa prawna i przejrzysty cel
Zgodnie z ISO/IEC 27701 należy zidentyfikować i udokumentować cele przetwarzania oraz ustalić podstawę prawną dla każdego z nich.
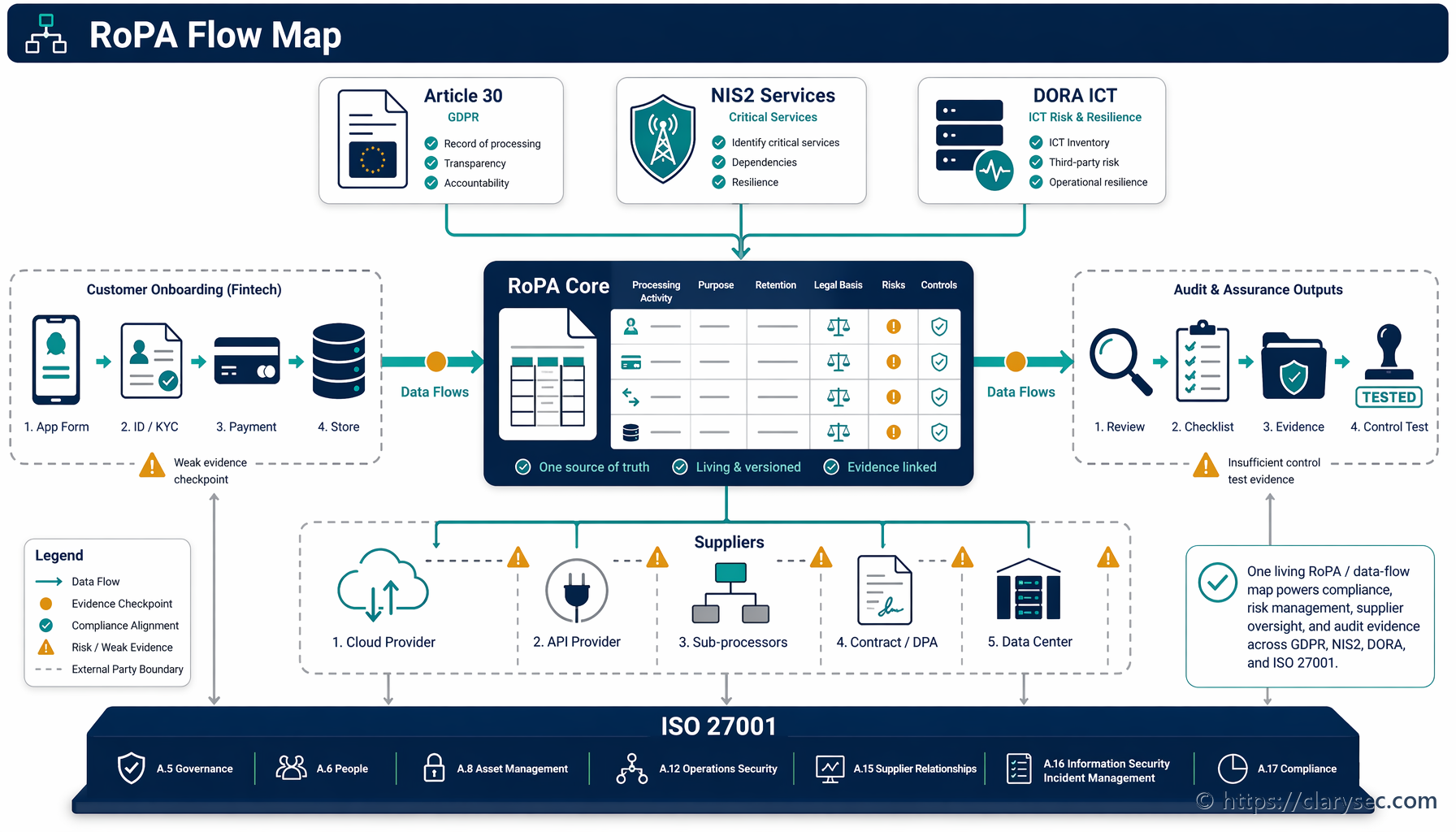
- Dostarczanie funkcji, np. wyszukiwanie AI w ramach jednej instancji klienta: Podstawą prawną jest zwykle wykonanie umowy albo prawnie uzasadniony interes. Należy to udokumentować w Rejestrze czynności przetwarzania (RoPA).
- Ulepszanie globalnego modelu, obejmujące wiele instancji klientów: Często wymaga to wyraźnej zgody albo bardzo starannie uzasadnionego prawnie uzasadnionego interesu, wraz z jasnym i łatwym mechanizmem rezygnacji. Przejrzystość w informacji o prywatności i interfejsie produktu jest obowiązkowa.
Techniczne środki ochrony: pseudonimizacja i maskowanie
Pełna anonimizacja jest trudna do osiągnięcia bez zniszczenia użyteczności danych. Bardziej praktycznym i wspieranym przez GDPR podejściem jest pseudonimizacja: zastąpienie identyfikatorów osobowych sztucznymi identyfikatorami. Ogranicza to ryzyko, zachowując wartość danych dla trenowania modelu.
Ten proces jest kluczowym zabezpieczeniem. W Zenith Blueprint krok 20 odnosi się konkretnie do maskowania danych, bezpośrednio wiążąc je z zasadami GDPR Article 25 oraz Article 32. Jest to wymagany środek bezpieczeństwa, a nie tylko dobra praktyka.
Polityka maskowania danych i pseudonimizacji Clarysec operacjonalizuje to podejście przez przypisanie jasnej odpowiedzialności:
„IOD powinien walidować zgodność z kryteriami pseudonimizacji wynikającymi z GDPR oraz koordynować działania z działem prawnym w zakresie wszelkich wymagań dotyczących ujawnień regulacyjnych związanych z naruszeniami ochrony danych lub nieskutecznością kontroli maskowania”.
- Z sekcji „Egzekwowanie i zgodność”, klauzula polityki 8.4.
Dla zespołów programistycznych oznacza to wdrożenie zautomatyzowanych skryptów maskujących lub pseudonimizujących imiona i nazwiska, adresy e-mail, numery telefonów oraz inne bezpośrednie identyfikatory, zanim dane trafią do środowiska treningowego. Oznacza to również ustanowienie formalnego procesu walidacji z udziałem IOD, aby zapewnić odporność zastosowanej techniki.
Ukryte zagrożenie: zabezpieczenie danych testowych i eksperymentów AI
Rzeczywiste naruszenia ochrony danych rzadko zaczynają się w dopracowanym, utwardzonym środowisku produkcyjnym. Zaczynają się w zapomnianych częściach infrastruktury:
- „Bezpieczne” środowiska przedprodukcyjne ze słabo oczyszczonymi kopiami danych produkcyjnych.
- „Tymczasowe” eksporty CSV danych klientów przekazywane inżynierom ML do lokalnych eksperymentów.
- Skrypty QA wykorzystujące surowe treści użytkowników do testowania promptów LLM.
To dokładnie miejsce, w którym zaczął się koszmarny scenariusz opisany na początku. Polityka danych testowych i środowisk testowych dla MŚP Clarysec odnosi się bezpośrednio do tego ryzyka:
„Zapewnienie zgodności z właściwymi regulacjami dotyczącymi ochrony danych, np. GDPR, NIS2, przez zapewnienie, że wszystkie dane testowe są przetwarzane zgodnie z prawem, rzetelnie i bezpiecznie”.
- Z sekcji „Cele”, klauzula polityki 3.4.
Polityka musi być wsparta praktycznymi zabezpieczeniami. Produkcyjne dane osobowe nie powinny nigdy występować w środowiskach nieprodukcyjnych bez solidnego maskowania lub pseudonimizacji. Środowiska testowe powinny używać oddzielnych kluczy API LLM o niższych uprawnieniach i z rygorystycznymi limitami liczby żądań. Należy też jednoznacznie ustanowić zasadę, że prompty testowe nigdy nie mogą zawierać rzeczywistych identyfikatorów klientów.
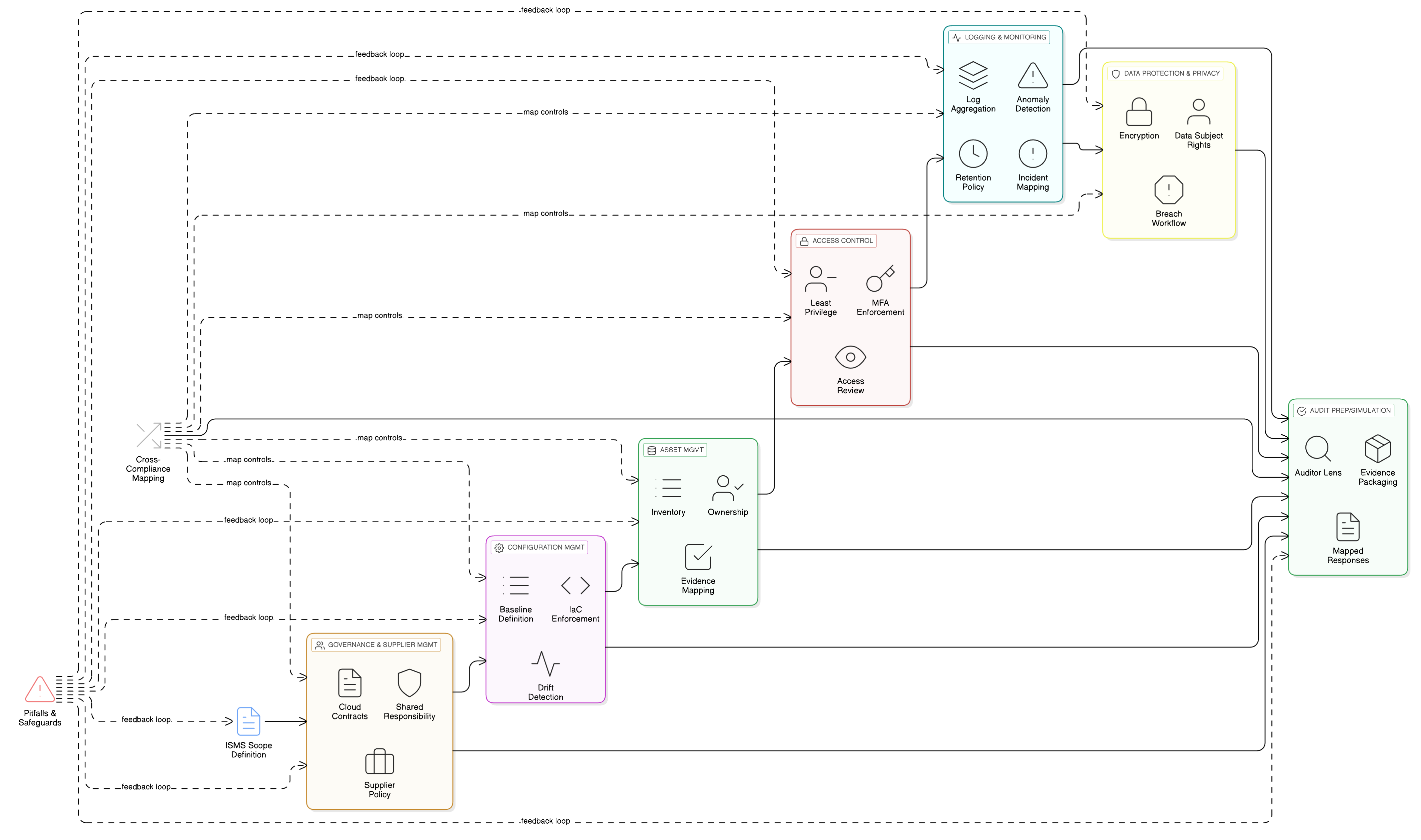
Wzmocnienie rdzenia: granularna kontrola dostępu dla potoków AI
Funkcje LLM działają na najbardziej wrażliwych magazynach danych, logach i potokach treningowych. Dlatego podstawowa kontrola dostępu ma zasadnicze znaczenie dla zgodności z GDPR. Zabezpieczenia ISO/IEC 27001:2022 8.3 i 8.2 są filarami obrony. Zenith Controls: przewodnik po zgodności między ramami Clarysec przedstawia plan ich skutecznego wdrożenia.
ISO/IEC 27001:2022 zabezpieczenie 8.3: ograniczenie dostępu do informacji
To zabezpieczenie dotyczy zapewnienia, że dostęp do informacji jest przyznawany ściśle według zasady wiedzy koniecznej. W środowisku trenowania LLM oznacza to, że specjaliści ds. data science, inżynierowie ML oraz same procesy zautomatyzowane powinni mieć dostęp wyłącznie do konkretnych danych, których wymagają — i do niczego więcej.
Jak opisano w Zenith Controls, zabezpieczenie to jest ściśle powiązane z innymi kontrolami:
- Powiązanie z 5.9 (inwentarz informacji i innych powiązanych aktywów) oraz 5.12 (klasyfikacja informacji): Nie da się ograniczać dostępu, jeśli nie wiadomo, jakie dane posiadasz i jak bardzo są wrażliwe. Zbiór danych treningowych AI musi być zinwentaryzowany i sklasyfikowany jako wysoce poufny, zgodnie z procesem określonym w Polityce klasyfikacji i oznaczania informacji dla MŚP.
- Powiązanie z 8.5 (bezpieczne uwierzytelnianie): Ograniczenia dostępu są bez znaczenia bez silnej weryfikacji tożsamości. Każdy użytkownik i każde konto serwisowe uzyskujące dostęp do danych treningowych musi być bezpiecznie uwierzytelniane, najlepiej z użyciem MFA.
ISO/IEC 27001:2022 zabezpieczenie 8.2: uprawnienia dostępu uprzywilejowanego
Inżynierowie ML, SRE i specjaliści ds. data science potrzebują uprawnień podwyższonych. Te konta uprzywilejowane są „kluczami do królestwa” i głównymi celami ataków. Zabezpieczenie 8.2 wymaga zarządzania tymi uprawnieniami z najwyższą starannością.
Według Zenith Controls kluczowe zależności są następujące:
- Powiązanie z 8.15 (rejestrowanie) i 8.16 (monitorowanie aktywności): Cała aktywność uprzywilejowana musi być rejestrowana i monitorowana. Jeśli specjalista ds. data science nagle próbuje wyeksportować cały zbiór danych treningowych, alert powinien zostać wyzwolony natychmiast.
- Powiązanie z 6.7 (praca zdalna): Jeżeli zespół AI pracuje zdalnie, jego dostęp uprzywilejowany musi przechodzić przez bezpieczne, monitorowane kanały, takie jak VPN z rygorystyczną kontrolą sesji.
Perspektywa audytora: jak wykazać, że zabezpieczenia AI działają
Wdrożenie zabezpieczeń to tylko połowa zadania. Musisz wykazać ich skuteczność. Różni audytorzy, szkoleni w różnych ramach, będą oczekiwać konkretnych dowodów.
| Typ audytora | Ramy odniesienia | O co poprosi audytor (dowody) |
|---|---|---|
| Audytor ISO/IEC 27001 | ISO/IEC 27007:2020 | Pokaż politykę kontroli dostępu dla środowiska treningowego AI. Przedstaw logi z procesu przeglądów uprawnień za ostatnie 12 miesięcy. Zademonstruj, w jaki sposób nowemu inżynierowi ML nadawany jest dostęp zgodny z zasadą najmniejszych uprawnień. |
| Audytor COBIT | COBIT 2019 (DSS05) | Potrzebuję zobaczyć macierz kontroli dostępu opartej na rolach (RBAC) dla zespołu data science. Przedstaw raporty z narzędzi monitorowania pokazujące alerty dotyczące anomalnych prób dostępu do jeziora danych treningowych. |
| Asesor NIST | NIST SP 800-53A (AC-3, AC-6) | Przejrzyjmy konfigurację systemową serwerów hostujących dane treningowe. Chcę zweryfikować, czy listy kontroli dostępu (ACL) technicznie egzekwują udokumentowane polityki. Pokaż dowody, że sesje uprzywilejowane są kończone po okresie bezczynności. |
| Audytor GDPR/prywatności | ISO/IEC 27701:2021 | Przedstaw ocenę skutków dla ochrony danych (DPIA) dla funkcji AI. Pokaż zapisy zgód osób, których dane znajdują się w zbiorze treningowym. Jak przetwarzasz wniosek o „prawo do usunięcia” danych znajdujących się w wytrenowanym modelu? |
Prawidłowe wdrożenie zabezpieczeń 8.2 i 8.3 przynosi szerokie korzyści. Zenith Controls pokazuje bezpośrednie mapowanie do wymagań GDPR (Articles 5, 25, 32), NIS2 (Article 21), DORA (Article 10) oraz NIST SP 800-53 (AC-3, AC-6), co pozwala spełnić wymagania wielu ram za pomocą jednego, spójnego wdrożenia kontroli.
Paradoks „prawa do bycia zapomnianym”: zarządzanie prawami osób, których dane dotyczą, w AI
GDPR Article 17, czyli „prawo do usunięcia”, stanowi szczególne wyzwanie techniczne dla AI. Jak usunąć dane osoby, gdy zostały już wykorzystane do trenowania ogromnego, złożonego modelu? Często technicznie niewykonalne jest „oduczenie” modelu konkretnych punktów danych.
Właśnie tutaj początkowe decyzje projektowe stają się najlepszą linią obrony. Nie ma jednej idealnej odpowiedzi, ale praktyczne i możliwe do obrony strategie obejmują:
- Najpierw pseudonimizacja: Jeżeli dane treningowe zostały prawidłowo spseudonimizowane, powiązanie z osobą fizyczną jest już przerwane w korpusie treningowym. Możesz następnie usunąć dane osobowe z systemów źródłowych oraz powiązanie w tabeli kluczy pseudonimizacji.
- Separacja danych na potrzeby trenowania: Tam, gdzie to możliwe, utrzymuj zbiory danych treningowych oddzielnie dla poszczególnych instancji klientów. Ułatwia to usunięcie danych bez ponownego trenowania całego ekosystemu modeli.
- Zaplanowane ponowne trenowanie modelu: Twoja DPIA powinna obejmować to ryzyko. Środkiem ograniczającym ryzyko może być zobowiązanie do okresowego trenowania modelu od zera na odświeżonym zbiorze danych, z wyłączeniem danych użytkowników, którzy zażądali usunięcia.
Sekcja Zenith Blueprint dotycząca usuwania informacji (krok 20, obejmujący zabezpieczenie 8.10) wyraźnie wiąże tę zdolność techniczną z GDPR Articles 17 and 5(1)(e), wymagając weryfikowalnych procesów bezpiecznego wymazywania danych, gdy nie są już potrzebne.
Zabezpieczenie łańcucha dostaw AI: rozwój w outsourcingu i zewnętrzne LLM
Niewiele firm SaaS buduje wszystko samodzielnie. Możesz korzystać z API LLM dostawcy hyperscale albo zawrzeć umowę z partnerem prowadzącym rozwój w modelu outsourcingowym. Wprowadza to ryzyko łańcucha dostaw.
Zenith Blueprint, w kroku 22 dotyczącym rozwoju realizowanego w modelu outsourcingowym, wskazuje to ryzyko i jego powiązanie z GDPR Articles 28 and 32. Jak stwierdza blueprint:
„Jednym z często pomijanych obszarów są szkolenia i świadomość. Twoi zewnętrzni programiści mogą być kompetentni, ale czy są przeszkoleni w zakresie praktyk bezpiecznego kodowania? Czy znają Twoje polityki? Czy są świadomi ram zgodności, których musisz przestrzegać — GDPR, DORA, NIS2…?”
W przypadku każdego zewnętrznego dostawcy LLM lub partnera programistycznego kluczowe znaczenie ma należyta staranność. Twoja umowa lub aneks powierzenia przetwarzania danych (DPA) musi wyraźnie obejmować cele przetwarzania związane z AI, kategorie danych oraz zakaz wykorzystywania Twoich danych przez dostawcę do trenowania jego własnych modeli. Musisz zweryfikować, że wdraża środki bezpieczeństwa zgodne z GDPR Article 32. Łańcuch dostaw AI musi być równie identyfikowalny audytowo jak Twoja podstawowa infrastruktura.
Od teorii do praktyki: konkretny przykład funkcji AI gotowej na GDPR
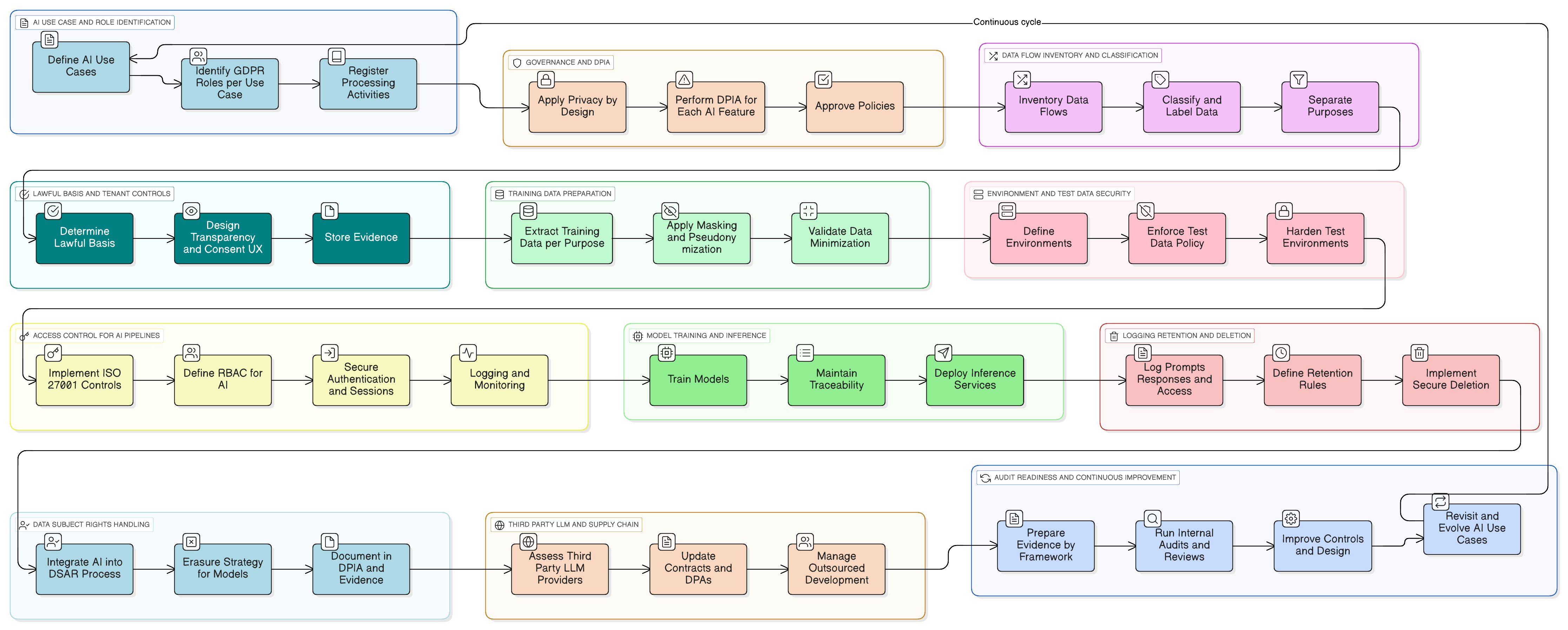
Uczyńmy to konkretnym. Wyobraź sobie, że dodajesz asystenta AI, który podsumowuje rozmowy z obsługą klienta, sugeruje szkice odpowiedzi i uczy się na podstawie wcześniejszych zgłoszeń, aby się doskonalić.
Oto praktyczny wzorzec wdrożenia z wykorzystaniem zestawu narzędzi Clarysec:
- Klasyfikacja i oznaczanie: Wszystkie zgłoszenia do wsparcia są klasyfikowane jako „Poufne” zgodnie z Polityką klasyfikacji i oznaczania informacji dla MŚP, w zgodzie z obowiązkami dotyczącymi postępowania z danymi wynikającymi z GDPR i DORA.
- Maskowanie przed LLM: Usługa maskowania przechwytuje dane przed wysłaniem ich do LLM. Usuwa lub zastępuje imiona i nazwiska, adresy e-mail, numery telefonów oraz inne dane osobowe. Cały proces jest regulowany przez Politykę maskowania danych i pseudonimizacji, a IOD waliduje metodykę.
- Kontrole dostępu do promptów i logów: Tylko upoważnione role, np. właściciel produktu AI, mogą uzyskać dostęp do surowych logów promptów. Jest to wdrażane przy użyciu zabezpieczenia ISO 27001:2022 8.3 (ograniczenie dostępu do informacji) dla dostępu ogólnego oraz zabezpieczenia 8.2 (uprawnienia dostępu uprzywilejowanego) dla widoczności na poziomie administracyjnym, zgodnie z mapowaniem w Zenith Controls.
- Zgoda na korpus danych treningowych: Potok treningowy przyjmuje wyłącznie dane zamaskowane. Udostępniane jest ustawienie konfiguracyjne na poziomie instancji klienta: „Zezwalam na wykorzystywanie moich zamaskowanych danych do ulepszania globalnego modelu AI: Tak/Nie”, z domyślną wartością „Nie”.
- Okres przechowywania i usuwanie: Logi promptów są przechowywane tylko tak długo, jak jest to konieczne. Gdy klient wyłącza funkcję albo rozwiązuje umowę, uruchamiany jest przepływ pracy bezpiecznego usunięcia lub anonimizacji powiązanych logów AI i wpisów treningowych, zgodnie z procesem opisanym we wdrożeniu Zenith Blueprint dla zabezpieczenia 8.10 (usuwanie informacji).
Gdy pojawią się audytorzy, możesz przeprowadzić ich przez diagramy przepływu danych tej funkcji, konkretne polityki, które ją regulują, oraz techniczne dowody z systemów, logów dostępu, konfiguracji zadań i przepływów pracy związanych z usuwaniem. Wykazujesz zgodność w działaniu.
Twój plan działania: od działań ad hoc do AI gotowej do audytu
Nie musisz rozbierać produktu na części, ale potrzebujesz uporządkowanego, możliwego do obrony podejścia. Oto zwięzły plan działania:
- Zinwentaryzuj przypadki użycia AI i przepływy danych: Zidentyfikuj każde miejsce użycia LLM: funkcje dostępne dla klientów, narzędzia wewnętrzne i eksperymenty. Zmapuj, jakie dane trafiają dokąd, na jakiej podstawie prawnej i kto ma do nich dostęp. Wykorzystaj fazę fundamentów Zenith Blueprint, aby upewnić się, że rejestr prawny obejmuje wszystkie wymagania związane z AI wynikające z GDPR, NIS2 i DORA.
- Najpierw ustanów ład organizacyjny: Przed budową przeprowadź ocenę skutków dla ochrony danych (DPIA) dla każdej funkcji AI. Udokumentuj jej cel, podstawę prawną i ryzyka. Wdróż polityki bazowe, takie jak Polityka ochrony danych i prywatności dla MŚP oraz Polityka bezpieczeństwa informacji dla MŚP.
- Zabezpiecz dane i dostęp: Wdróż solidne techniczne zabezpieczenia. Przyjmij Politykę maskowania danych i pseudonimizacji oraz Politykę danych testowych i środowisk testowych dla MŚP. Wykorzystaj Zenith Controls, aby wdrożyć i udokumentować zabezpieczenia ISO 27001:2022 8.2 i 8.3 dla wszystkich magazynów danych i potoków AI.
- Wbuduj prawa osób, których dane dotyczą, w przepływy pracy AI: Zaktualizuj procedury DSAR i usuwania tak, aby obejmowały dane związane z AI. Udokumentuj strategię obsługi wniosków o usunięcie w kontekście wytrenowanych modeli, koncentrując się na pseudonimizacji i harmonogramach ponownego trenowania modeli.
- Obejmij kontrolą łańcuch dostaw AI: Zaktualizuj DPA z zewnętrznymi dostawcami LLM i wykonawcami prowadzącymi rozwój w outsourcingu. Zapewnij, aby umowy wyraźnie zakazywały nieuprawnionego wykorzystania danych i wymagały silnych środków bezpieczeństwa. Zweryfikuj, czy zespoły zewnętrzne zostały przeszkolone z Twoich polityk postępowania z danymi.
Odblokowanie innowacji z poczuciem pewności
Styk AI i GDPR to nowa granica zgodności. Przyjmując uporządkowane, oparte na ryzyku podejście, możesz wykorzystać transformacyjny potencjał sztucznej inteligencji bez naruszania zobowiązań dotyczących ochrony danych i prywatności.
Clarysec zapewnia mapę, narzędzia i wiedzę ekspercką, które poprowadzą Cię w tej podróży. Korzystając z:
- Zenith Blueprint: 30-etapowej mapy drogowej audytora do etapowego wdrożenia zabezpieczeń dla AI zgodnych z GDPR.
- Zenith Controls: przewodnika po zgodności między ramami do ujednolicenia zabezpieczeń ISO 27001:2022 z wymaganiami GDPR, NIS2, DORA i NIST.
- Gotowych do użycia w środowisku produkcyjnym polityk, takich jak Polityka ochrony danych i prywatności dla MŚP, Polityka maskowania danych i pseudonimizacji oraz Polityka danych testowych i środowisk testowych dla MŚP, aby skodyfikować reguły i spełnić oczekiwania audytorów.
Możesz przejść od eksperymentów AI ad hoc do zdolności AI gotowej do audytu, która budzi zaufanie organów regulacyjnych, audytorów i wymagających klientów korporacyjnych. Możesz nadal wprowadzać innowacje z użyciem LLM i spać spokojnie.
Jeżeli planujesz lub prowadzisz funkcje AI w swoim produkcie SaaS, kolejny krok jest prosty. Pobierz próbki naszych zestawów narzędzi albo zarezerwuj demo, aby zobaczyć, jak Clarysec może pomóc Ci zbudować program AI, który jest nie tylko skuteczny, lecz także możliwy do wykazania jako prywatny i bezpieczny już na etapie projektowania.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council