Audit-Ready Restore Testing for ISO 27001, NIS2 and DORA
It is 07:40 on a Monday morning, and Sarah, the CISO of a fast-growing financial technology firm, is watching a crisis form in real time. The CFO cannot open the payment approval platform. The service desk thinks it is a storage issue. The infrastructure team suspects ransomware because several shared folders now show encrypted filenames. The CEO wants to know whether payroll is safe. Legal asks whether regulators must be notified.
Sarah opens the backup dashboard. It is full of green checkmarks.
That should be comforting, but it is not. A successful backup job is not proof of a successful restore. It is like seeing a fire extinguisher on the wall without knowing whether it is charged, accessible, and usable under pressure.
Sarah’s firm is in scope for ISO 27001:2022, treated as an important entity under NIS2, and subject to DORA as a financial entity. The question is no longer whether the organization runs backups. The question is whether it can restore the right systems, to the right point in time, within approved Recovery Time Objectives and Recovery Point Objectives, with evidence strong enough for an auditor, regulator, customer, insurer, and board.
That is where many backup programs fail. They have backup jobs. They have dashboards. They have snapshots. They may even have cloud storage. But when the pressure arrives, they cannot prove that critical systems are recoverable, that restore tests were performed, that failed tests triggered corrective action, and that the evidence maps cleanly to ISO 27001:2022, NIS2, DORA, NIST, and COBIT 2019 expectations.
Backup and restore testing has become a board-level operational resilience issue. NIS2 raises expectations for cybersecurity risk management and business continuity. DORA makes ICT operational resilience a core obligation for financial entities and their critical ICT service providers. ISO 27001:2022 provides the management system structure for scope, risk, control selection, evidence, audit, and continual improvement.
The practical challenge is turning a technical restore test into audit-ready evidence.
Backup is not evidence until restore is proven
A backup job that completes successfully is only a partial signal. It tells you that data was copied somewhere. It does not prove that the data can be restored, that application dependencies are intact, that encryption keys are available, that identity services still work, or that the recovered system supports real business operations.
Auditors know this. Regulators know this. Attackers know this.
A technically mature auditor will not stop at a screenshot showing 97 percent backup job success. They will ask:
- Which systems are critical or high impact?
- What RTO and RPO apply to each system?
- When was the last restore test?
- Was the test full, partial, application-level, database-level, or file-level?
- Who validated the business process after restoration?
- Were failures recorded as nonconformities or improvement actions?
- How long are logs and restore test records retained?
- Are backup copies segregated across locations?
- How does the evidence map to the risk register and Statement of Applicability?
This is why Clarysec policy language is intentionally direct. The Backup and Restore Policy-sme [BRP-SME], section Governance Requirements, policy clause 5.3.3, requires:
Restore tests are conducted at least quarterly, and the results are documented to verify recoverability
That one sentence changes the audit conversation. It moves the organization from “we have backups” to “we verify recoverability on a defined cadence and retain the results.”
The same Backup and Restore Policy-sme, section Enforcement and Compliance, policy clause 8.2.2, reinforces the evidence obligation:
Logs and restore test records are retained for audit purposes
That clause prevents restore testing from becoming undocumented tribal memory. If an infrastructure engineer says, “We tested that in March,” but no record exists, it is not audit-ready evidence.
The same policy also addresses survivability through storage diversity. In section Policy Implementation Requirements, policy clause 6.3.1.1, backups must be:
Stored in at least two locations (local and cloud)
This is a practical baseline. It does not replace a risk assessment, but it reduces the chance that one physical or logical failure domain destroys both production and backup data.
The ISO 27001:2022 evidence chain starts before the test
Organizations often treat backup compliance as an IT operations topic. In ISO 27001:2022 terms, that is too narrow. Backup and restore testing should be embedded in the Information Security Management System, connected to scope, risk, control selection, monitoring, internal audit, and continual improvement.
Clarysec’s Zenith Blueprint: An Auditor’s 30-Step Roadmap [ZB] starts this evidence chain before any restore test is performed.
In the ISMS Foundation & Leadership phase, Step 2, Stakeholder Needs and ISMS Scope, the Zenith Blueprint instructs organizations to define what is inside the ISMS:
Action Item 4.3: Draft an ISMS scope statement. List what is included (business units, locations, systems) and any exclusions. Share this draft with top management for input – they must agree on what parts of the business will be subject to the ISMS. It’s also wise to sanity-check this scope against your earlier stakeholder requirements list: Does your scope cover all areas needed to fulfill those requirements?
For restore testing, scope defines the recovery universe. If the payment platform, identity provider, ERP database, endpoint management server, and cloud object storage are in scope, the restore evidence must include them or justify why not. If a system is excluded, the exclusion must be defensible against stakeholder requirements, contractual obligations, regulatory duties, and business continuity needs.
The next link is risk. In the Risk Management phase, Step 11, Building and Documenting the Risk Register, the Zenith Blueprint describes the risk register as the master record of risks, assets, threats, vulnerabilities, current controls, owners, and treatment decisions.
A backup-related risk entry should look practical, not theoretical.
| Risk element | Example entry |
|---|---|
| Asset | Payment approval platform and supporting database |
| Threat | Ransomware encryption or destructive administrator action |
| Vulnerability | Backups not restored quarterly and application dependencies not validated |
| Impact | Payroll delay, regulatory exposure, customer trust impact |
| Current controls | Daily backup jobs, immutable cloud storage, quarterly restore test |
| Risk owner | Head of Infrastructure |
| Treatment decision | Mitigate through tested backups, documented restore evidence, and BCP updates |
This is where backup becomes auditable. It is no longer “we have backups.” It is “we identified a business risk, selected controls, assigned ownership, tested the control, and retained evidence.”
The Zenith Blueprint, Risk Management phase, Step 13, Risk Treatment Planning and Statement of Applicability, closes the traceability loop:
Map Controls to Risks and Clauses (Traceability)
Now that you have both the Risk Treatment Plan and the SoA:
✓ Map controls to risks: In your Risk Register’s treatment plan, you listed certain controls for each risk. You can add a column “Annex A Control Reference” to each risk and list the control numbers.
For backup and restore testing, the Statement of Applicability should connect the risk scenario to ISO/IEC 27001:2022 Annex A controls, especially 8.13 Information backup, 5.30 ICT readiness for business continuity, 8.14 Redundancy of information processing facilities, and 5.29 Information security during disruption.
The SoA should not simply mark these controls as applicable. It should explain why they are applicable, what implementation evidence exists, who owns the control, and how exceptions are handled.
The control map that auditors expect to see
Clarysec’s Zenith Controls: The Cross-Compliance Guide [ZC] does not create separate or proprietary controls. It organizes official standards and frameworks into a practical cross-compliance view so organizations can understand how one operational practice, such as restore testing, supports multiple obligations.
For ISO/IEC 27002:2022 control 8.13 Information backup, Zenith Controls classifies the control as Corrective, tied to Integrity and Availability, aligned to the Recover cybersecurity concept, supporting the Continuity operational capability, and sitting in the Protection security domain. That profile reframes backups as a recovery capability, not merely a storage process.
For ISO/IEC 27002:2022 control 5.30 ICT readiness for business continuity, Zenith Controls classifies the control as Corrective, focused on Availability, aligned to Respond, supporting Continuity, and positioned in the Resilience security domain. This is where restore testing connects directly to operational resilience.
For ISO/IEC 27002:2022 control 8.14 Redundancy of information processing facilities, Zenith Controls identifies a Preventive control focused on Availability, aligned to Protect, supporting Continuity and Asset management, and linked to Protection and Resilience domains. Redundancy and backups are not the same. Redundancy helps prevent interruption. Backups enable recovery after loss, corruption, or attack.
For ISO/IEC 27002:2022 control 5.29 Information security during disruption, Zenith Controls shows a broader profile: Preventive and Corrective, covering Confidentiality, Integrity, and Availability, aligned to Protect and Respond, supporting Continuity, and linked to Protection and Resilience. This matters during ransomware recovery because restoration must not create new security failures, such as restoring vulnerable images, bypassing logging, or reactivating excessive privileges.
| ISO/IEC 27001:2022 Annex A control | Resilience role | Evidence auditors expect |
|---|---|---|
| 8.13 Information backup | Proves data and systems can be recovered after loss, corruption, or attack | Backup schedule, restore test records, success criteria, logs, exceptions, retention evidence |
| 5.30 ICT readiness for business continuity | Shows ICT capabilities support continuity objectives | BIA, RTO/RPO mapping, recovery runbooks, test reports, lessons learned |
| 8.14 Redundancy of information processing facilities | Reduces dependency on a single processing facility or service path | Architecture diagrams, failover test results, capacity review, dependency mapping |
| 5.29 Information security during disruption | Maintains security during degraded operations and recovery | Crisis access records, emergency change approvals, logging, incident timeline, post-restore security validation |
The practical lesson is simple. A restore test is not one control in isolation. It is evidence across a resilience chain.
The hidden audit gap: RTO and RPO without proof
One of the most common continuity audit findings is the gap between documented RTO/RPO and real restore capability.
The business continuity plan may state that the customer portal has a four-hour RTO and a one-hour RPO. The backup platform may run every hour. But during the first realistic restore exercise, the team discovers that the database restore takes three hours, DNS changes require another hour, the application certificate has expired, and the identity integration was never included in the runbook. The real recovery time is eight hours.
The documented RTO was fiction.
Clarysec’s Business Continuity Policy and Disaster Recovery Policy-sme [BCDR-SME], section Governance Requirements, policy clause 5.2.1.4, makes the continuity requirement explicit:
Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs) for each system
That matters because “restore critical services quickly” is not measurable. “Restore the payment approval database within four hours with no more than one hour of data loss” is measurable.
The same Business Continuity Policy and Disaster Recovery Policy-sme, section Policy Implementation Requirements, policy clause 6.4.2, turns testing into improvement:
All test results must be documented, and lessons learned must be recorded and used to update the BCP.
A failed restore is not automatically an audit disaster. A failed restore with no documented lesson, owner, correction, and retest is.
For enterprise environments, Clarysec’s Backup and Restore Policy [BRP] provides more formal governance. In section Governance Requirements, policy clause 5.1, it states:
A Master Backup Schedule shall be maintained and reviewed annually. It must specify:
That opening requirement establishes the core governance artifact. A Master Backup Schedule should identify systems, data sets, backup frequency, retention, location, ownership, classification, dependencies, and testing cadence.
The same Backup and Restore Policy, section Governance Requirements, policy clause 5.2, links backup expectations to business impact:
All systems and applications classified as Critical or High impact in the Business Impact Analysis (BIA) must:
This is where BIA and backup governance converge. Critical and high impact systems require stronger recovery assurance, more frequent testing, better dependency mapping, and more disciplined evidence.
One evidence model for ISO 27001:2022, NIS2, DORA, NIST, and COBIT 2019
Compliance teams often struggle with framework duplication. ISO 27001:2022 asks for risk-based control selection and evidence. NIS2 expects cybersecurity risk-management measures, including business continuity. DORA expects ICT operational resilience, response and recovery, backup and restoration procedures, and digital operational resilience testing. NIST and COBIT 2019 use different language again.
The answer is not to build separate backup programs for each framework. The answer is to build one evidence model that can be viewed through multiple audit lenses.
| Framework lens | What backup and restore testing proves | Evidence to keep audit-ready |
|---|---|---|
| ISO 27001:2022 | Risks are treated through selected controls, tested, monitored, and improved through the ISMS | Scope, risk register, SoA, backup schedule, restore records, internal audit results, CAPA log |
| NIS2 | Essential or important services can withstand and recover from cyber disruption | Business continuity plans, crisis procedures, backup tests, incident response links, management oversight |
| DORA | ICT services supporting critical or important functions are resilient and recoverable | ICT asset mapping, RTO/RPO, restore test reports, third-party dependency evidence, recovery procedures |
| NIST CSF | Recovery capabilities support resilient cybersecurity outcomes | Recovery plans, backup integrity checks, communications procedures, lessons learned |
| COBIT 2019 | Governance and management objectives are supported by measurable controls and accountable ownership | Process ownership, metrics, control performance, issue tracking, management reporting |
For NIS2, the most direct reference is Article 21 on cybersecurity risk-management measures. Article 21(2)(c) specifically includes business continuity, such as backup management, disaster recovery, and crisis management. Article 21(2)(f) also matters because it addresses policies and procedures to assess the effectiveness of cybersecurity risk-management measures. Restore testing is exactly that: evidence that the measure works.
For DORA, the strongest links are Article 11 on response and recovery, Article 12 on backup policies and procedures, restoration and recovery procedures and methods, and Article 24 on general requirements for digital operational resilience testing. For financial entities, a database restore test alone may be insufficient if the business service depends on cloud identity, payment gateway connectivity, outsourced hosting, or managed monitoring. DORA-style evidence should be service-level, not just server-level.
| ISO/IEC 27001:2022 control | DORA connection | NIS2 connection |
|---|---|---|
| 8.13 Information backup | Article 12 requires backup policies, restoration and recovery procedures and methods | Article 21(2)(c) includes backup management and disaster recovery as business continuity measures |
| 5.30 ICT readiness for business continuity | Article 11 requires response and recovery capability, and Article 24 requires resilience testing | Article 21(2)(c) includes business continuity and crisis management |
| 8.14 Redundancy of information processing facilities | Articles 6 and 9 support ICT risk management, protection, prevention, and reduction of single points of failure | Article 21 requires appropriate and proportionate measures to manage risks to network and information systems |
| 5.29 Information security during disruption | Article 11 response and recovery requires controlled recovery during incidents | Article 21 risk-management measures require continuity without abandoning security controls |
This is the efficiency of a unified compliance strategy. A quarterly restore test for a payment system can support ISO 27001:2022 Annex A evidence, NIS2 continuity expectations, DORA ICT recovery requirements, NIST CSF Recover outcomes, and COBIT 2019 governance reporting, if the evidence is structured correctly.
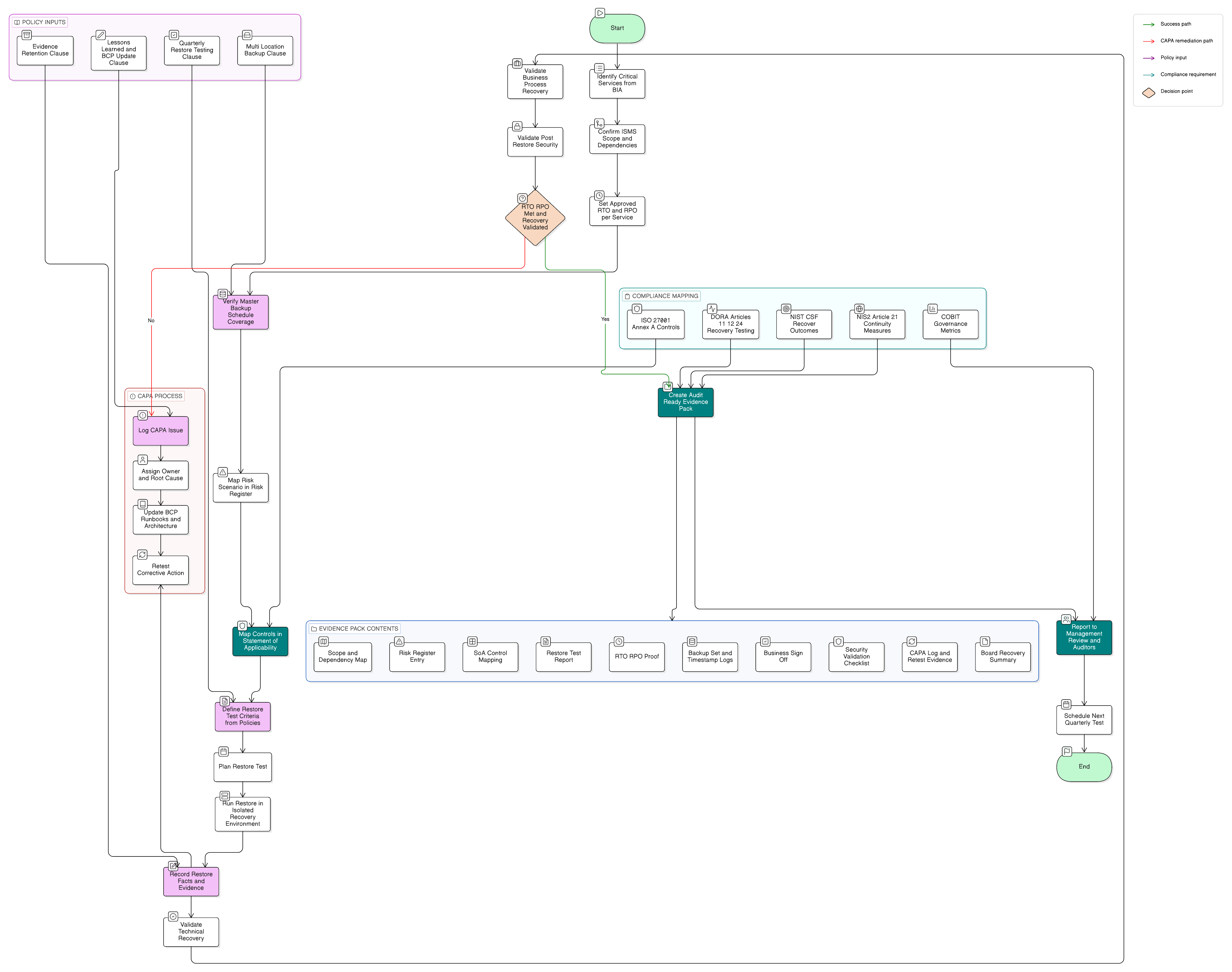
A practical restore test that becomes audit-ready evidence
Return to Sarah’s Monday morning scenario, but imagine her organization prepared using Clarysec’s toolkit.
The payment approval platform is classified as Critical in the BIA. The approved RTO is four hours. The approved RPO is one hour. The platform depends on a database cluster, identity provider, secrets vault, logging pipeline, DNS, certificates, and outbound email relay.
Sarah’s team builds a quarterly restore test around six steps.
Step 1: Confirm scope and dependencies
Using Zenith Blueprint Step 2, Sarah confirms that the payment platform, database, identity integration, backup infrastructure, and recovery environment are inside the ISMS scope. Legal confirms regulatory relevance. Finance confirms business impact. IT confirms dependencies.
This avoids the classic mistake of restoring only the database while ignoring the authentication service required to access the application.
Step 2: Link the test to the risk register
Using Zenith Blueprint Step 11, the risk register includes the scenario: “Loss or encryption of payment approval platform data prevents payment operations and creates regulatory exposure.”
The current controls include daily backups, immutable cloud storage, multi-location backup copies, quarterly restore testing, and documented recovery runbooks. The risk owner is the Head of Infrastructure. The business owner is Finance Operations. The treatment decision is Mitigate.
Step 3: Map the treatment to the SoA
Using Zenith Blueprint Step 13, the SoA maps the risk to ISO/IEC 27001:2022 Annex A controls 8.13, 5.30, 8.14, and 5.29. The SoA explains that backup testing provides corrective recovery capability, ICT continuity procedures support business continuity, redundancy reduces outage probability, and security during disruption prevents insecure recovery shortcuts.
Step 4: Use policy clauses as test criteria
The team uses Backup and Restore Policy-sme clause 5.3.3 for quarterly restore testing, clause 8.2.2 for evidence retention, and clause 6.3.1.1 for multi-location storage. It uses Business Continuity Policy and Disaster Recovery Policy-sme clause 5.2.1.4 for RTO/RPO targets and clause 6.4.2 for lessons learned and BCP updates.
| Test criterion | Target | Evidence |
|---|---|---|
| Restore cadence | Quarterly | Test calendar and approved schedule |
| RTO | 4 hours | Start time, end time, elapsed recovery time |
| RPO | 1 hour | Backup timestamp and transaction validation |
| Locations | Local and cloud backup sources available | Backup repository report |
| Integrity | Database consistency checks pass | Validation logs |
| Application | Finance user can approve test payment | Business validation sign-off |
| Security | Logging, access controls, and secrets validated after restore | Security checklist and screenshots |
Step 5: Run the restore and record facts
The restore is performed in an isolated recovery environment. The team records timestamps, backup set identifiers, restoration steps, errors, validation results, and approvals.
A strong restore test record should include:
| Restore test field | Example |
|---|---|
| Test ID | Q2-2026-PAY-RESTORE |
| System tested | Payment approval platform |
| Backup set used | Payment platform backup from approved recovery point |
| Restore location | Isolated recovery environment |
| RTO target | 4 hours |
| RPO target | 1 hour |
| Actual recovery time | 2 hours 45 minutes |
| Actual recovery point | 42 minutes |
| Integrity validation | Database consistency checks passed |
| Business validation | Finance user approved test payment |
| Security validation | Logging, access controls, secrets, and monitoring confirmed |
| Outcome | Pass with condition |
| Sign-off | CISO, Infrastructure Lead, Finance Operations Owner |
During the test, the team discovers one issue. The restored application cannot send notification emails because the email relay allowlist does not include the recovery subnet. Core payment approval works, but the workflow is degraded.
Step 6: Record lessons learned and corrective action
This is where many organizations stop too early. Clarysec’s approach pushes the issue into the improvement system.
In the Audit, Review & Improvement phase, Step 29, Continual Improvement, the Zenith Blueprint uses a CAPA Log to track issue description, root cause, corrective action, owner, target date, and status.
| CAPA field | Example |
|---|---|
| Issue description | Restored payment platform could not send email notifications from recovery subnet |
| Root cause | Recovery network not included in email relay allowlist design |
| Corrective action | Update recovery architecture and email relay allowlist procedure |
| Owner | Infrastructure Lead |
| Target date | 15 business days |
| Status | Open pending retest |
This single restore test now produces an audit-ready evidence chain: policy requirement, scope confirmation, risk mapping, SoA mapping, test plan, execution record, business validation, security validation, issue record, corrective action, and BCP update.
How different auditors inspect the same evidence
A strong evidence package anticipates the auditor’s lens.
An ISO 27001:2022 auditor will usually start with the management system. They will ask whether backup and restore requirements are scoped, risk-based, implemented, monitored, internally audited, and improved. They will expect traceability from risk register to SoA to operational records. They may also connect failed tests and corrective actions to ISO/IEC 27001:2022 clause 10.2 on nonconformity and corrective action.
A DORA reviewer will focus on ICT operational resilience for critical or important functions. They will want to see service-level recovery, third-party ICT dependencies, scenario-based testing, management body oversight, and evidence that restoration procedures are effective.
A NIS2 supervisory perspective will look for appropriate and proportionate cybersecurity risk-management measures. Backup and disaster recovery evidence should show that essential or important services can maintain or restore operations after incidents, with management aware of residual risk.
A NIST-oriented assessor will focus on cybersecurity outcomes across Identify, Protect, Detect, Respond, and Recover. They may ask about immutable backups, privileged access to backup repositories, restoration into clean environments, communications, and lessons learned.
A COBIT 2019 or ISACA-style auditor will emphasize governance, process ownership, metrics, management reporting, and issue tracking. They will be less impressed by a technically elegant restore if ownership and reporting are unclear.
The same evidence can satisfy all of these perspectives, but only if it is complete.
Common restore testing failures that create audit findings
Clarysec repeatedly sees the same preventable evidence gaps.
| Failure pattern | Why it creates audit risk | Practical fix |
|---|---|---|
| Backup success is treated as restore success | Copy completion does not prove recoverability | Perform documented restore tests with validation |
| RTO and RPO are defined but not tested | Continuity objectives may be unrealistic | Measure actual recovery time and recovery point during tests |
| Only infrastructure validates the restore | Business process may still be unusable | Require business owner sign-off for critical systems |
| Test records are scattered | Auditors cannot verify consistency | Use a standard restore test report template and evidence folder |
| Failed tests are discussed but not tracked | No continual improvement evidence | Log issues in CAPA with owner, due date, and retest |
| Backups are stored in one logical failure domain | Ransomware or misconfiguration can destroy recoverability | Use segregated locations, immutable storage, and access control |
| Dependencies are excluded | Restored applications may not function | Map identity, DNS, secrets, certificates, integrations, and logging |
| Security is ignored during recovery | Restored services may be vulnerable or unmonitored | Include post-restore security validation |
The goal is not bureaucracy. The goal is reliable recovery under pressure and defensible evidence under audit.
Build a board-level recovery evidence pack
Executives do not need raw backup logs. They need assurance that critical services are recoverable, exceptions are known, and improvement actions are progressing.
For each critical service, report:
- Service name and business owner
- Criticality from BIA
- Approved RTO and RPO
- Last restore test date
- RTO and RPO achieved
- Test result
- Open corrective actions
- Third-party dependencies affecting recovery
- Residual risk statement
- Next scheduled test
| Critical service | RTO/RPO | Last test | Result | Open issue | Management message |
|---|---|---|---|---|---|
| Payment approval platform | 4h/1h | 2026-04-12 | Pass with condition | Email relay recovery subnet allowlist | Core payment approval restored within target, notification workflow remediation in progress |
| Customer portal | 8h/2h | 2026-03-20 | Fail | Database restore exceeded RTO by 90 minutes | Capacity and restore process improvement required |
| Identity provider recovery | 2h/15m | 2026-04-05 | Pass | None | Supports recovery of dependent critical services |
This style of reporting creates a bridge between technical teams, auditors, and leadership. It also supports ISMS management review and resilience oversight under NIS2 and DORA.
Practical audit checklist for the next 30 to 90 days
If your audit is approaching, start with the evidence you already have and close the highest-risk gaps first.
- Identify all Critical and High impact systems from the BIA.
- Confirm RTO and RPO for each critical system.
- Verify each critical system appears in the Master Backup Schedule.
- Confirm backup locations, including local, cloud, immutable, or segregated repositories.
- Select at least one recent restore test per critical service or schedule a test immediately.
- Ensure restore test records show scope, timestamps, backup set, result, RTO/RPO achieved, and validation.
- Obtain business owner sign-off for application-level recovery.
- Validate security after restore, including access control, logging, monitoring, secrets, certificates, and vulnerability exposure.
- Map evidence to the risk register and SoA.
- Record issues in CAPA, assign owners, and track retest.
- Summarize results for management review.
- Prepare a cross-compliance view for ISO 27001:2022, NIS2, DORA, NIST CSF, and COBIT 2019 audit conversations.
If you cannot complete every item before the audit, be transparent. Auditors usually respond better to a documented gap with a corrective action plan than to vague claims of maturity.
Make restore testing your strongest resilience evidence
Backup and restore testing is one of the clearest ways to prove operational resilience. It is tangible, measurable, business-relevant, and directly connected to ISO 27001:2022, NIS2, DORA, NIST, COBIT 2019, board reporting, customer assurance, and insurer expectations.
But only if it is documented properly.
Clarysec helps organizations turn backup operations into audit-ready evidence through the Backup and Restore Policy, Backup and Restore Policy-sme, Business Continuity Policy and Disaster Recovery Policy-sme, Zenith Blueprint, and Zenith Controls.
Your next practical move is simple. Choose one critical service this week. Run a restore test against its approved RTO and RPO. Document the result. Map it to the risk register and SoA. Log every lesson learned.
If you want that process to be repeatable across ISO 27001:2022, NIS2, DORA, NIST, and COBIT 2019, Clarysec’s toolkit gives you the structure to prove recovery without building a compliance maze from scratch.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council