Anatomia de uma violação: guia para fabricantes sobre resposta a incidentes segundo a ISO 27001
Excerto em destaque
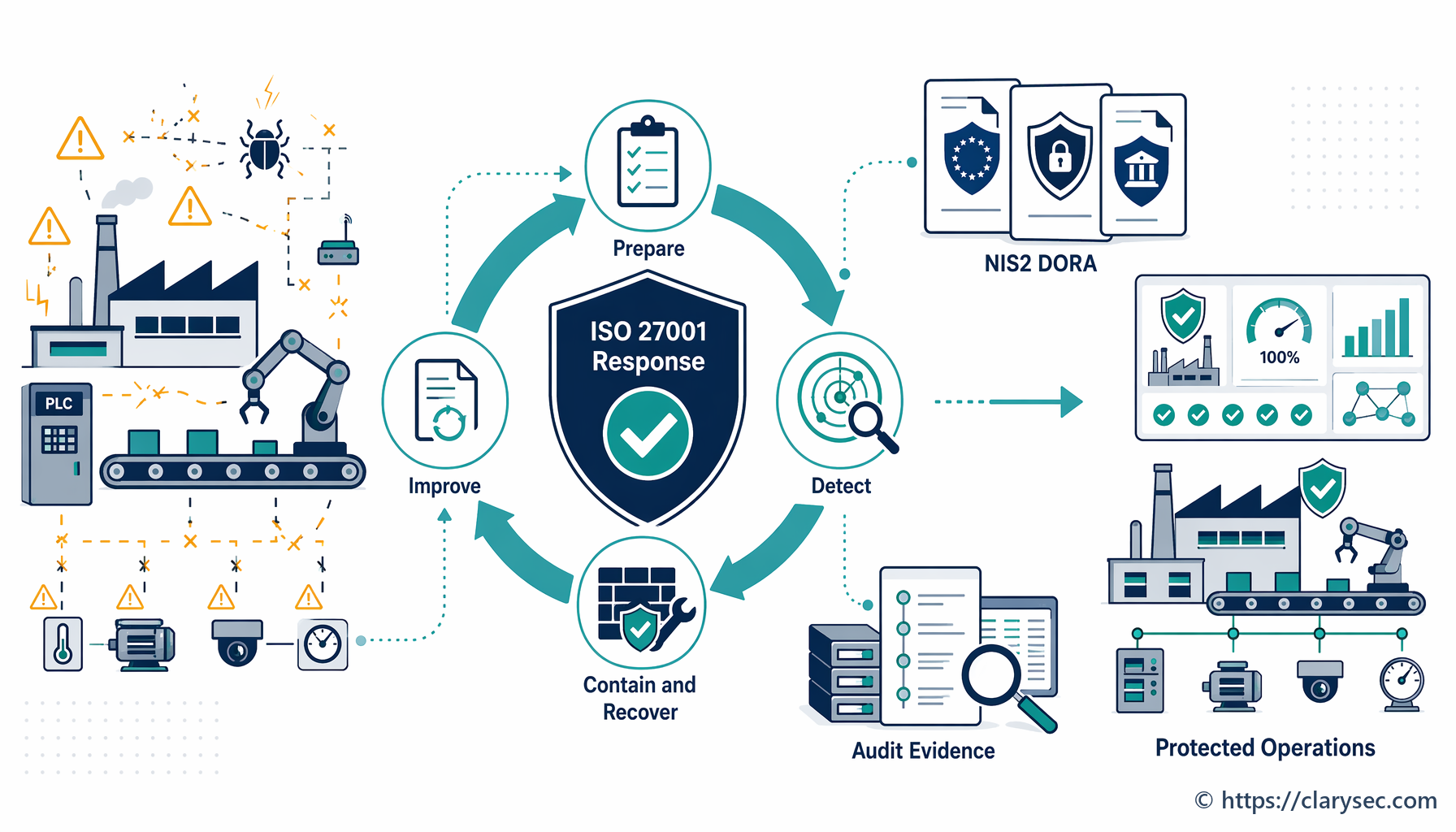
A resposta eficaz a incidentes de segurança da informação minimiza os danos causados por violações de segurança e assegura a resiliência operacional. Este guia apresenta um referencial passo a passo baseado na ISO 27001, ajudando fabricantes a preparar-se, responder e recuperar de ciberataques reais, ao mesmo tempo que cumprem exigências complexas de conformidade, como NIS2 e DORA.
Introdução
O alerta surge às 2:17. O servidor central de um fabricante de componentes automóveis de média dimensão não responde, e os monitores da linha de produção apresentam uma nota de ransomware. Cada minuto de indisponibilidade custa milhares em produção perdida e aumenta o risco de incumprimento de acordos de nível de serviço (SLA) rigorosos da cadeia de abastecimento. Isto não é um exercício. Para o Diretor de Segurança da Informação, este é o momento em que anos de planeamento, redação de políticas e formação são postos à prova no limite.
Ter um plano de resposta a incidentes num servidor é uma coisa; executá-lo sob pressão extrema é outra completamente diferente. Para os fabricantes, o nível de risco é particularmente elevado. Um ciberincidente não compromete apenas dados; interrompe a produção, perturba cadeias de abastecimento físicas e pode colocar em risco a segurança dos trabalhadores.
Este guia vai além dos procedimentos operacionais teóricos e apresenta um roteiro prático e realista para criar e gerir um programa de resposta a incidentes que funciona. Vamos analisar a anatomia da resposta a uma violação, assente no referencial robusto da ISO/IEC 27001, e demonstrar como construir um programa resiliente que não só recupera de um ataque, como também satisfaz auditores e reguladores.
O que está em causa: o efeito em cadeia de uma violação no setor industrial
Quando os sistemas de um fabricante são comprometidos, o impacto vai muito além de um único servidor. A natureza interligada da produção moderna, desde a gestão de inventário até às linhas de montagem robotizadas, significa que uma falha digital pode causar uma paragem operacional completa. As consequências são graves e multifacetadas.
Em primeiro lugar, o impacto financeiro é imediato e intenso. A paragem da produção leva a prazos falhados, cláusulas de penalização impostas por clientes e custos com mão de obra parada. Restaurar sistemas, contratar especialistas forenses e eventualmente lidar com exigências de resgate pode comprometer as finanças de uma empresa de média dimensão.
Em segundo lugar, o dano reputacional pode ser duradouro. Num ambiente B2B, a fiabilidade é essencial. Um único incidente relevante pode destruir a confiança de parceiros-chave que dependem de entregas just-in-time. Como salientam as nossas orientações internas, um objetivo central da gestão de incidentes é “minimizar o impacto comercial e financeiro dos incidentes e restaurar as operações normais tão rapidamente quanto possível”, um objetivo crítico no setor industrial.
Por fim, a resposta regulatória pode ser severa. Com referenciais como a Diretiva relativa à segurança das redes e da informação da UE (NIS2) e o Regulamento DORA a entrarem plenamente em vigor, organizações em setores críticos, como a indústria transformadora, enfrentam requisitos rigorosos de notificação de incidentes e a ameaça de coimas substanciais em caso de incumprimento. Um incidente mal gerido não é apenas uma falha técnica; é uma responsabilidade jurídica e de conformidade significativa.
Como deve ser: do caos ao controlo
Um programa eficaz de resposta a incidentes transforma uma crise, que poderia ser caótica e reativa, num processo estruturado e controlado. O objetivo não é apenas corrigir o problema técnico, mas gerir todo o evento para proteger o negócio. Este estado-alvo assenta nos princípios definidos no referencial da ISO/IEC 27001, em particular nos seus controlos de gestão de incidentes de segurança da informação.
Um programa maduro caracteriza-se por vários resultados-chave:
- Clareza de funções: todos sabem quem contactar e quais são as suas responsabilidades. A Equipa de Resposta a Incidentes (IRT) está previamente definida, com liderança clara e especialistas designados das áreas de TI, jurídico, comunicações e gestão.
- Rapidez e precisão: a organização consegue detetar, analisar e conter ameaças rapidamente, impedindo a sua propagação pela rede e a paragem de toda a área de produção.
- Tomada de decisão informada: a gestão recebe informação tempestiva e rigorosa, permitindo decisões críticas sobre operações, comunicação com clientes e divulgação regulatória.
- Melhoria contínua: cada incidente, grande ou pequeno, torna-se uma oportunidade de aprendizagem. Um processo rigoroso de revisão pós-incidente identifica fragilidades e alimenta melhorias no programa de segurança.
Alcançar este nível de preparação é a finalidade central dos controlos detalhados na ISO/IEC 27002:2022. Estes controlos orientam as organizações no planeamento e preparação (A.5.24), na avaliação e decisão sobre eventos (A.5.25), na resposta a incidentes (A.5.26) e na aprendizagem decorrente dos mesmos (A.5.28). Trata-se de construir um sistema resiliente, que antecipa falhas e está estruturado para as gerir de forma controlada.
O caminho prático: guia passo a passo para resposta a incidentes
Construir uma capacidade robusta de resposta a incidentes exige uma abordagem documentada e sistemática. A base é uma política clara e acionável que descreva todas as fases do processo.
A nossa P16S Política de Planeamento e Preparação para a Gestão de Incidentes de Segurança da Informação - PME fornece um modelo abrangente alinhado com as melhores práticas da ISO 27001. Vejamos os passos críticos utilizando esta política como referência.
Passo 1: planeamento e preparação — a base da resiliência
Não é possível criar um plano de resposta no meio de uma crise. A preparação é determinante. Esta fase consiste em estabelecer a estrutura, as ferramentas e o conhecimento necessários para atuar de forma decisiva quando ocorre um incidente.
Um componente essencial é a constituição de uma Equipa de Resposta a Incidentes (IRT). Conforme indicado na Secção 5.1 da P16S Política de Planeamento e Preparação para a Gestão de Incidentes de Segurança da Informação - PME, a finalidade da política é “assegurar uma abordagem consistente e eficaz à gestão de incidentes de segurança da informação”. Esta consistência começa com uma equipa bem definida. A política determina que a IRT deve incluir membros de áreas-chave:
- TI e Segurança da Informação
- Jurídico e Conformidade
- Recursos Humanos
- Relações Públicas/Comunicações
- Gestão de topo
Cada membro deve ter funções e responsabilidades claramente definidas. Quem tem autoridade para retirar sistemas de operação? Quem é o porta-voz designado para comunicar com clientes ou com os meios de comunicação? Estas questões devem ser respondidas e documentadas muito antes de ocorrer um incidente.
Passo 2: deteção e reporte — o seu sistema de alerta precoce
Quanto mais cedo a organização souber que ocorreu um incidente, menor será o dano potencial. Isto exige monitorização técnica e uma cultura em que os colaboradores se sintam habilitados e obrigados a reportar atividade suspeita.
A P16S Política de Planeamento e Preparação para a Gestão de Incidentes de Segurança da Informação - PME é clara neste ponto. A Secção 5.3, “Reporte de eventos de segurança da informação”, determina:
“Todos os trabalhadores, contratados e outras partes relevantes devem reportar quaisquer eventos e fragilidades de segurança da informação observados ou suspeitos, tão rapidamente quanto possível, ao ponto de contacto designado.”
Este “ponto de contacto designado” é crítico. Pode ser o balcão de apoio de TI ou uma linha direta dedicada de segurança. O processo deve ser simples e claramente comunicado a todo o pessoal. Os colaboradores devem receber formação sobre o que observar, como mensagens de correio eletrónico de phishing, comportamento anómalo dos sistemas ou violações de segurança física.
Passo 3: avaliação e triagem — dimensionar a ameaça
Depois de um evento ser reportado, o passo seguinte é avaliar rapidamente a sua natureza e severidade. Trata-se de um falso positivo, de um problema menor ou de uma crise em plena escala? Este processo de triagem determina o nível de resposta necessário.
A nossa política define um esquema de classificação claro na Secção 5.2, “Classificação de incidentes”, para categorizar incidentes com base no seu impacto sobre confidencialidade, integridade e disponibilidade. Um esquema típico pode ser:
- Baixo: um único posto de trabalho infetado com malware comum, facilmente contido.
- Médio: um servidor departamental está indisponível, afetando uma função de negócio específica, mas sem interromper a produção no seu todo.
- Alto: um ataque de ransomware generalizado que afeta sistemas críticos de produção e dados essenciais do negócio.
- Crítico: um incidente que envolve uma violação de dados pessoais sensíveis ou propriedade intelectual, com implicações jurídicas e reputacionais significativas.
Esta classificação determina a urgência, os recursos alocados e a via de escalonamento para a gestão, garantindo que a resposta é proporcional à ameaça.
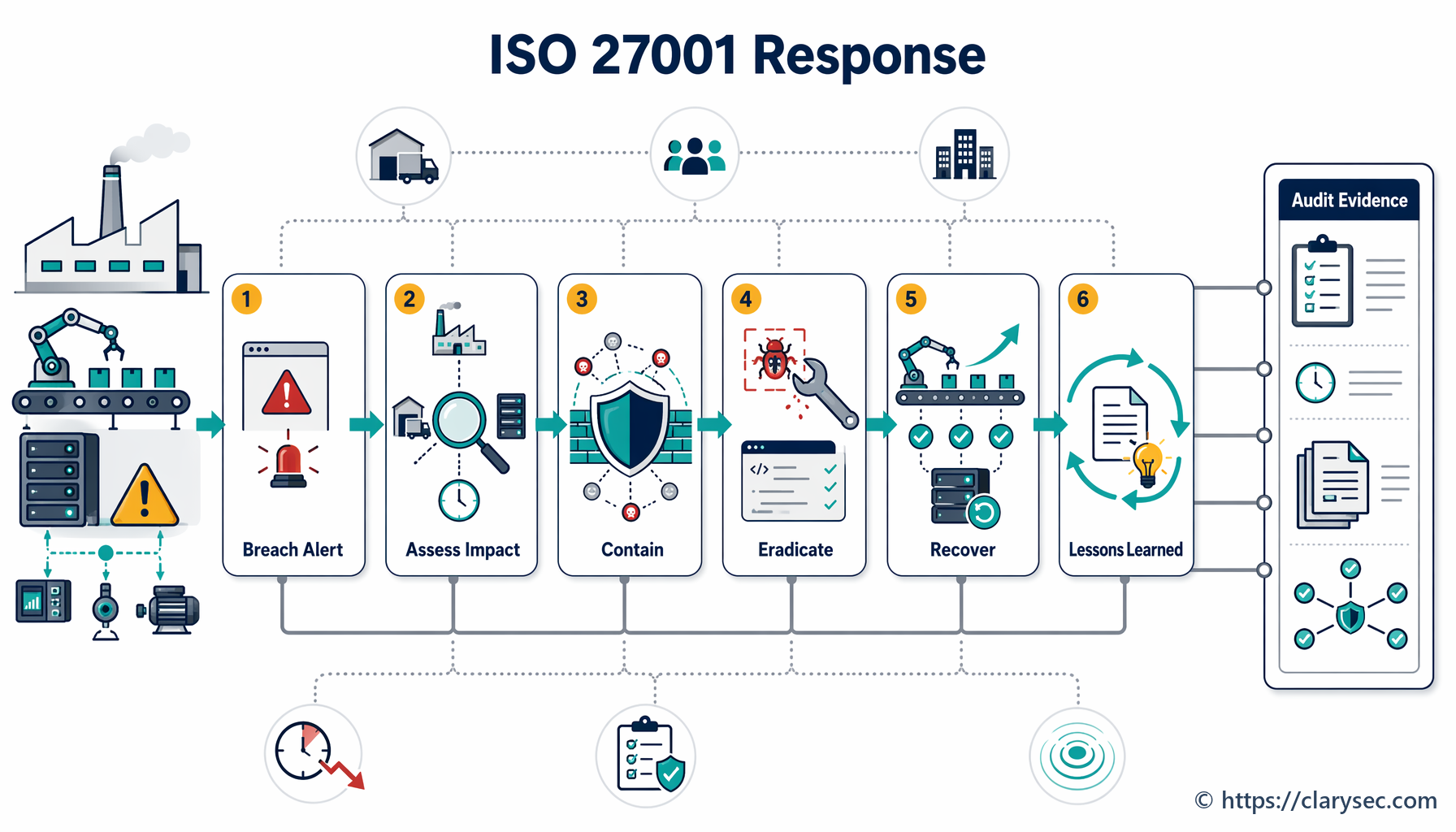
Passo 4: contenção, erradicação e recuperação — combater o incêndio
Esta é a fase ativa da resposta, na qual a IRT trabalha para controlar o incidente e restaurar as operações normais.
- Contenção: a prioridade imediata é travar a propagação do dano. Isto pode envolver isolar segmentos de rede afetados, desligar servidores comprometidos ou bloquear endereços IP maliciosos. O objetivo é impedir que o incidente se propague e cause danos adicionais.
- Erradicação: uma vez contido, a causa raiz do incidente deve ser eliminada. Isto pode significar remover malware, aplicar patches a vulnerabilidades exploradas e desativar contas de utilizador comprometidas.
- Recuperação: o passo final é restaurar os sistemas e dados afetados. Isto envolve restaurar a partir de cópias de segurança limpas, reconstruir sistemas e monitorizar cuidadosamente para assegurar que a ameaça foi totalmente removida antes de repor os serviços online.
A Secção 5.4 da P16S Política de Planeamento e Preparação para a Gestão de Incidentes de Segurança da Informação - PME, “Resposta a incidentes de segurança da informação”, fornece o enquadramento para estas ações, salientando que “os procedimentos de resposta devem ser iniciados após a classificação de um evento de segurança da informação como incidente”.
Passo 5: atividades pós-incidente — aprender as lições
O trabalho não termina quando os sistemas voltam a estar online. A fase pós-incidente é, provavelmente, a mais importante para construir resiliência de longo prazo. Envolve duas atividades-chave: recolha de evidência e uma revisão de lições aprendidas.
A política salienta a importância da recolha de evidência na Secção 5.5, indicando que “devem ser estabelecidos e seguidos procedimentos para a recolha, aquisição e preservação de evidência relacionada com incidentes de segurança da informação”. Isto é crucial para investigação interna, autoridades policiais e eventual ação judicial.
Em seguida, deve ser realizada uma revisão pós-incidente formal. Esta reunião deve envolver todos os membros da IRT e as partes interessadas-chave para discutir:
- O que aconteceu e qual foi a cronologia dos eventos?
- O que correu bem na resposta?
- Que desafios foram encontrados?
- O que pode ser feito para prevenir um incidente semelhante no futuro?
O resultado desta revisão deve ser um plano de ação com responsáveis designados e prazos para melhorar políticas, procedimentos e controlos técnicos. Isto cria um ciclo de feedback que reforça a postura de segurança da organização ao longo do tempo.
Ligar os pontos: perspetivas de conformidade cruzada
Cumprir os requisitos da ISO 27001 para gestão de incidentes não reforça apenas a segurança; fornece também uma base poderosa para cumprir uma rede crescente de regulamentos internacionais e setoriais. Muitos destes referenciais partilham os mesmos princípios fundamentais de preparação, resposta e reporte.
Como explicado em Zenith Controls, o nosso guia abrangente de conformidade cruzada, um processo robusto de gestão de incidentes é uma pedra angular da resiliência digital. Vejamos como a abordagem da ISO 27001 se alinha com outros referenciais importantes.
Controlos da ISO/IEC 27002:2022: A versão mais recente da norma ISO/IEC 27002 fornece orientação detalhada sobre gestão de incidentes através de um conjunto dedicado de controlos:
- A.5.24 - Planeamento e preparação da gestão de incidentes de segurança da informação: estabelece a necessidade de uma abordagem definida e documentada.
- A.5.25 - Avaliação e decisão sobre eventos de segurança da informação: assegura que os eventos são devidamente avaliados para determinar se constituem incidentes.
- A.5.26 - Resposta a incidentes de segurança da informação: abrange as atividades de contenção, erradicação e recuperação.
- A.5.27 - Reporte de incidentes de segurança da informação: define como e quando os incidentes são reportados à gestão e a outras partes interessadas.
- A.5.28 - Aprendizagem decorrente de incidentes de segurança da informação: exige um processo de melhoria contínua.
Estes controlos formam um ciclo de vida completo que se reflete noutros regulamentos relevantes.
Diretiva NIS2: Para operadores de serviços essenciais, incluindo muitos fabricantes, a NIS2 impõe obrigações rigorosas de segurança e reporte de incidentes. Zenith Controls assinala a sobreposição direta:
“O Article 21 da Diretiva NIS2 exige que entidades essenciais e importantes implementem medidas técnicas, operacionais e organizacionais adequadas e proporcionais para gerir os riscos colocados à segurança dos sistemas de rede e informação. Isto inclui explicitamente políticas e procedimentos de tratamento de incidentes. Além disso, o Article 23 estabelece um processo de notificação de incidentes em várias fases, exigindo um alerta precoce no prazo de 24 horas e um relatório detalhado no prazo de 72 horas às autoridades competentes (CSIRT).”
Um plano de resposta a incidentes alinhado com a ISO 27001 fornece os mecanismos exatos necessários para cumprir estes prazos rigorosos de reporte.
Regulamento DORA: Embora centrado no setor financeiro, os princípios de resiliência do DORA estão a tornar-se uma referência para todos os setores. O guia destaca esta ligação:
“O Article 17 do DORA exige que as entidades financeiras disponham de um processo abrangente de gestão de incidentes relacionados com as TIC para detetar, gerir e notificar incidentes relacionados com as TIC. O Article 19 exige a classificação de incidentes com base em critérios detalhados no regulamento e o reporte de incidentes de maior impacto às autoridades competentes através de modelos harmonizados. Isto reflete os requisitos de classificação e reporte existentes na ISO 27001.”
Regulamento Geral sobre a Proteção de Dados (RGPD da UE): Para qualquer incidente que envolva dados pessoais, os requisitos do RGPD da UE são essenciais. Uma resposta rápida e estruturada não é opcional. Como explica Zenith Controls:
“Nos termos do RGPD da UE, o Article 33 exige que os responsáveis pelo tratamento notifiquem a autoridade de controlo de uma violação de dados pessoais sem demora injustificada e, sempre que possível, no prazo máximo de 72 horas após dela terem tomado conhecimento. O Article 34 exige a comunicação da violação ao titular dos dados quando seja suscetível de resultar num risco elevado para os seus direitos e liberdades. Um plano eficaz de resposta a incidentes é essencial para recolher a informação necessária para efetuar estas notificações de forma rigorosa e atempada.”
Ao construir o seu programa de resposta a incidentes sobre uma base ISO 27001, está simultaneamente a desenvolver as capacidades necessárias para responder às exigências complexas destes regulamentos interligados.
Preparar-se para o escrutínio: o que os auditores vão pedir
Um plano de resposta a incidentes que nunca foi testado nem revisto é apenas um documento. Os auditores sabem disso e, durante uma auditoria de certificação ISO 27001, irão verificar em profundidade se o programa é uma parte viva e operacional do seu SGSI.
De acordo com Zenith Blueprint, o nosso roteiro para auditores, a avaliação da resposta a incidentes é uma etapa crítica do processo de auditoria. Durante a “Fase 3: trabalho de campo e recolha de evidência”, os auditores irão testar sistematicamente a sua preparação.
Eis o que pode esperar que solicitem, com base no Passo 21 do Zenith Blueprint, “Avaliar a resposta a incidentes e a continuidade de negócio”:
“Mostre-me o seu plano e a sua política de resposta a incidentes.” Os auditores começam pela documentação. Irão analisar a política quanto à sua completude, verificando funções e responsabilidades definidas, critérios de classificação, planos de comunicação e procedimentos para cada fase do ciclo de vida dos incidentes. Irão confirmar que foi formalmente aprovada e comunicada ao pessoal relevante.
“Mostre-me os registos dos seus últimos três incidentes de segurança.” É aqui que se comprova a execução na prática. Os auditores precisam de ver evidência de que o plano está efetivamente a ser seguido. Esperam encontrar logs de incidentes ou tickets que documentem:
- A data e hora da deteção.
- Uma descrição do incidente.
- A prioridade atribuída ou o nível de classificação.
- Um registo das ações realizadas para contenção, erradicação e recuperação.
- A data e hora de resolução.
“Mostre-me a ata e o plano de ação da sua última revisão pós-incidente.” Como o Zenith Blueprint salienta, a melhoria contínua é inegociável.
“Durante a auditoria, procuraremos evidência objetiva de que as revisões pós-incidente são realizadas de forma sistemática. Isto inclui a análise de atas de reunião, registos de ações e evidência de que as melhorias identificadas foram implementadas, como procedimentos atualizados ou novos controlos técnicos. Sem este ciclo de feedback, o SGSI não pode ser considerado em ‘melhoria contínua’, conforme exigido pela norma.”
“Mostre-me evidência de que testou o seu plano.” Os auditores querem verificar que a organização testa proativamente as suas capacidades, e não que espera por um incidente real. Esta evidência pode assumir várias formas, desde exercícios de mesa com a gestão até simulações técnicas em escala completa. Irão querer ver um relatório destes testes, detalhando o cenário, os participantes, os resultados e quaisquer lições aprendidas.
Estar preparado com esta evidência demonstra que o seu programa de resposta a incidentes não existe apenas para cumprir formalidades, mas é um componente robusto, operacional e eficaz do seu SGSI.
Armadilhas comuns a evitar
Mesmo com um plano bem documentado, muitas organizações falham durante um incidente real. Eis algumas das armadilhas mais comuns a evitar:
- A síndrome do “plano na gaveta”: a falha mais comum é ter um plano muito bem escrito que ninguém leu, compreendeu ou praticou. Formação e testes regulares são o único antídoto.
- Autoridade indefinida: durante uma crise, a ambiguidade é o inimigo. Se a IRT não tiver autoridade previamente aprovada para tomar medidas decisivas, como retirar de operação um sistema crítico de produção, a resposta ficará paralisada pela indecisão enquanto o dano se propaga.
- Comunicação deficiente: não gerir as comunicações é uma receita para o desastre. Isto inclui não informar a liderança, transmitir mensagens confusas aos colaboradores ou gerir mal a comunicação com clientes e reguladores. Um plano de comunicação previamente aprovado, com modelos, é essencial.
- Negligenciar a preservação de evidência: na pressa de restaurar o serviço, a equipa técnica pode destruir inadvertidamente evidência forense crucial. Isto pode tornar impossível determinar a causa raiz, prevenir recorrências ou apoiar uma ação judicial.
- Não aprender: tratar um incidente como “encerrado” assim que o sistema volta a estar online é uma oportunidade perdida. Sem uma análise pós-incidente rigorosa, a organização fica condenada a repetir os mesmos erros.
Próximos passos
Passar da teoria à prática é o passo mais crítico. Um programa robusto de resposta a incidentes é uma jornada de melhoria contínua, não um destino. Pode começar da seguinte forma:
- Formalize a sua abordagem: se ainda não tem uma política formal de resposta a incidentes, este é o momento para a criar. Utilize a nossa P16S Política de Planeamento e Preparação para a Gestão de Incidentes de Segurança da Informação - PME como modelo para construir um referencial abrangente.
- Compreenda o seu panorama de conformidade: mapeie os seus procedimentos de resposta a incidentes face aos requisitos específicos de regulamentos como NIS2, DORA e RGPD da UE. O nosso guia, Zenith Controls, fornece as referências cruzadas necessárias para assegurar cobertura integral.
- Prepare-se para a auditoria: utilize a perspetiva do auditor para testar a robustez do seu programa. Zenith Blueprint oferece uma visão interna do que os auditores irão exigir, para que possa reunir a sua evidência e estar preparado para demonstrar eficácia.
Conclusão
Para um fabricante moderno, a resposta a incidentes de segurança da informação não é um tema de TI; é uma função central de continuidade de negócio. A diferença entre uma perturbação menor e uma falha catastrófica está na preparação, na prática e no compromisso com um processo estruturado e repetível.
Ao assentar o seu programa no referencial globalmente reconhecido da ISO 27001, constrói não apenas uma capacidade defensiva, mas uma organização resiliente. Cria um sistema capaz de resistir ao choque de uma violação, gerir a crise com controlo e precisão e sair mais forte e mais seguro. O momento de preparar é agora, antes que o alerta das 2:17 se torne a sua realidade.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council