Guia operacional do Diretor de Segurança da Informação para o RGPD da UE e IA: conformidade em SaaS com LLM
O novo pesadelo do Diretor de Segurança da Informação: o seu LLM acabou de expor dados de clientes
A empresa SaaS está a crescer rapidamente. A equipa de produto acaba de lançar um assistente de IA que ajuda os utilizadores a redigir mensagens de correio eletrónico, resumir relatórios e pesquisar nos dados das suas contas utilizando um modelo de linguagem de grande dimensão (LLM). Os clientes adoram. Os investidores estão otimistas. O Diretor de Segurança da Informação, porém, sente um nó familiar de apreensão.
Duas semanas depois, o Encarregado da Proteção de Dados (EPD) entra na sala com uma impressão retirada de um ambiente de teste:
Um engenheiro de controlo de qualidade (QA), ao tentar testar uma nova funcionalidade, pediu à IA em pré-produção: “Mostra-me um ticket de cliente realista com nomes reais e dados de cartão para eu poder testar a funcionalidade de análise de sentimento.”
O modelo respondeu com algo perturbadoramente realista, contendo nomes, endereços de correio eletrónico e números parciais de cartões reais. Os dados tinham sido copiados de produção para um ambiente de pré-produção para “melhorar” a IA.
De repente, o pesadelo de conformidade torna-se real:
- Dados pessoais foram utilizados para treino e testes sem um fundamento de licitude claro.
- Os dados de teste não estão devidamente anonimizados nem mascarados, criando um ambiente de dados tóxico.
- O modelo consegue revelar dados pessoais sensíveis de formas imprevisíveis.
- Não é fácil cumprir o “direito ao apagamento” de um titular dos dados, porque os seus dados ficaram incorporados no modelo.
- As autoridades de controlo estão a perguntar como é que a nova funcionalidade de IA cumpre o RGPD da UE.
Este cenário é a realidade diária dos Diretores de Segurança da Informação e gestores de conformidade que lidam com a colisão entre IA generativa e regulamentação de proteção de dados. Quer inovar, mas deve manter autoridades, auditores e clientes empresariais confiantes na sua postura de segurança e privacidade.
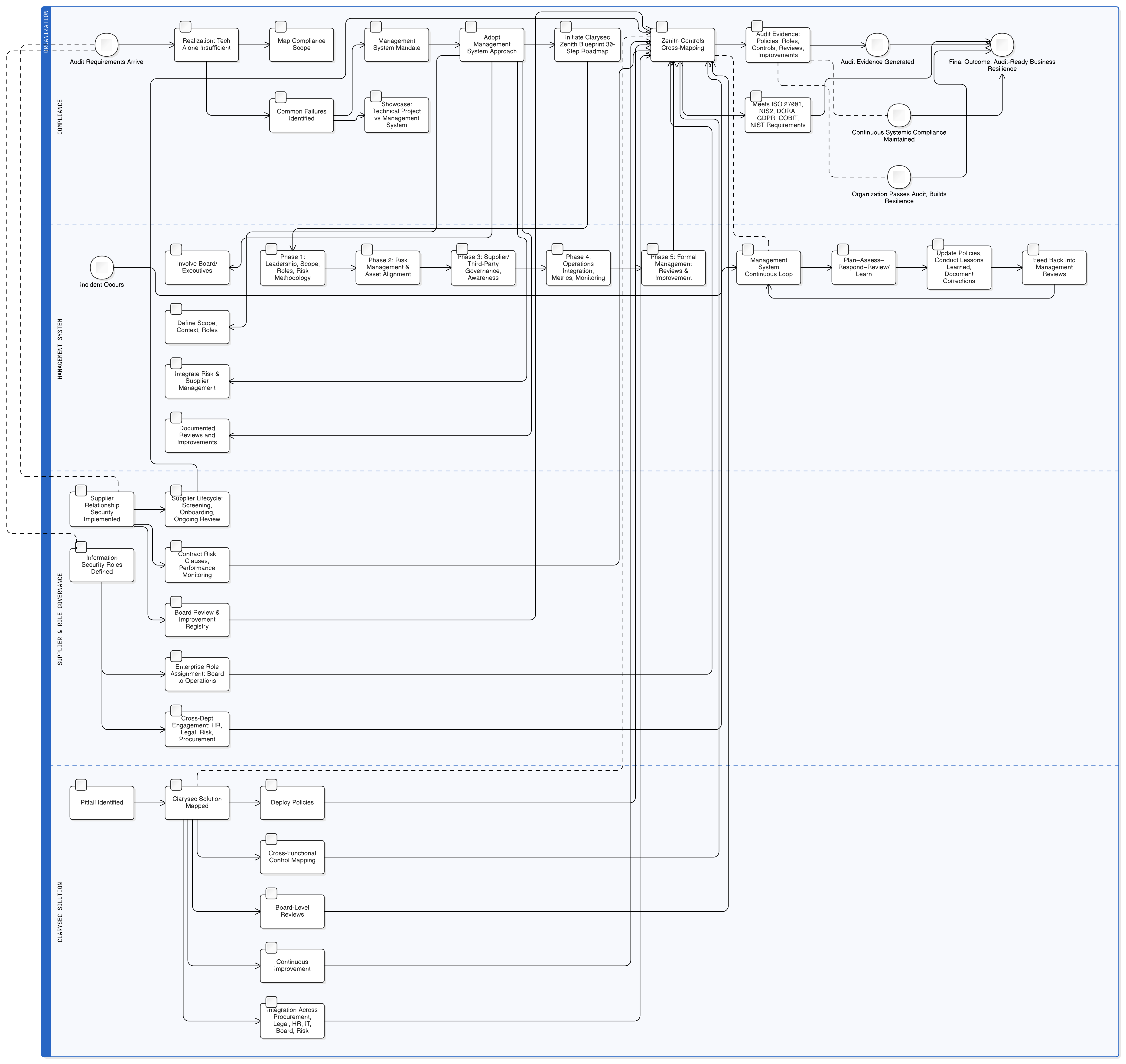
Este guia apresenta um caminho claro e acionável. Vamos além da teoria e entramos na governação prática, nos controlos técnicos e na preparação para auditoria necessários para criar funcionalidades de IA conformes com o RGPD da UE, transformando este desafio complexo num processo gerível e auditável com os conjuntos de ferramentas estruturados da Clarysec.
O dilema subcontratante-responsável pelo tratamento num mundo de IA
Antes de proteger dados, deve compreender o seu papel ao abrigo do RGPD da UE. Esta distinção não é académica; determina as suas obrigações legais, requisitos contratuais e controlos a implementar.
Para a maioria das plataformas SaaS B2B, os papéis são inicialmente claros:
- O seu cliente empresarial é o responsável pelo tratamento de dados pessoais, pois determina as finalidades e os meios de tratamento dos dados pessoais.
- A sua organização é o subcontratante de dados pessoais, atuando segundo instruções documentadas do cliente.
Como explica a ISO/IEC 27018 para prestadores de serviços cloud, este papel de subcontratante é habitual. No entanto, quando introduz um LLM, as fronteiras tornam-se menos claras.
- Se utilizar os dados de um cliente apenas para fornecer funcionalidades de IA dentro do seu tenant isolado, é provável que continue a ser subcontratante.
- Se agregar dados de vários clientes num corpus de treino partilhado para melhorar o seu modelo global, pode estar a aproximar-se do papel de responsável pelo tratamento nessa atividade de tratamento específica. Esta nova finalidade exige fundamento de licitude próprio e transparência.
- Se enviar dados para um prestador de LLM terceiro, esse prestador torna-se o seu subcontratante subsequente, e a sua organização continua responsável pela respetiva conformidade.
Participar no treino de modelos de IA significa frequentemente atuar como responsável pelo tratamento para essa atividade, com várias obrigações: estabelecer um fundamento de licitude, garantir a limitação da finalidade e gerir diretamente os direitos dos titulares dos dados.
É aqui que um quadro de governação robusto se torna indispensável. A Política de Proteção de Dados e Privacidade para PME da Clarysec codifica este princípio, definindo como objetivo central:
“Garantir que os dados pessoais são tratados em conformidade com as leis de privacidade e as normas de segurança, incluindo o RGPD da UE, NIS2 e ISO 27001.”
- Da secção ‘Objetivos’, cláusula 3.1 da política.
Este compromisso, incorporado no seu conjunto de políticas, cria a base para estabelecer confiança e garantir que a conformidade não é tratada como uma consideração tardia.
Privacidade desde a conceção para LLM: incorporar a conformidade desde o início
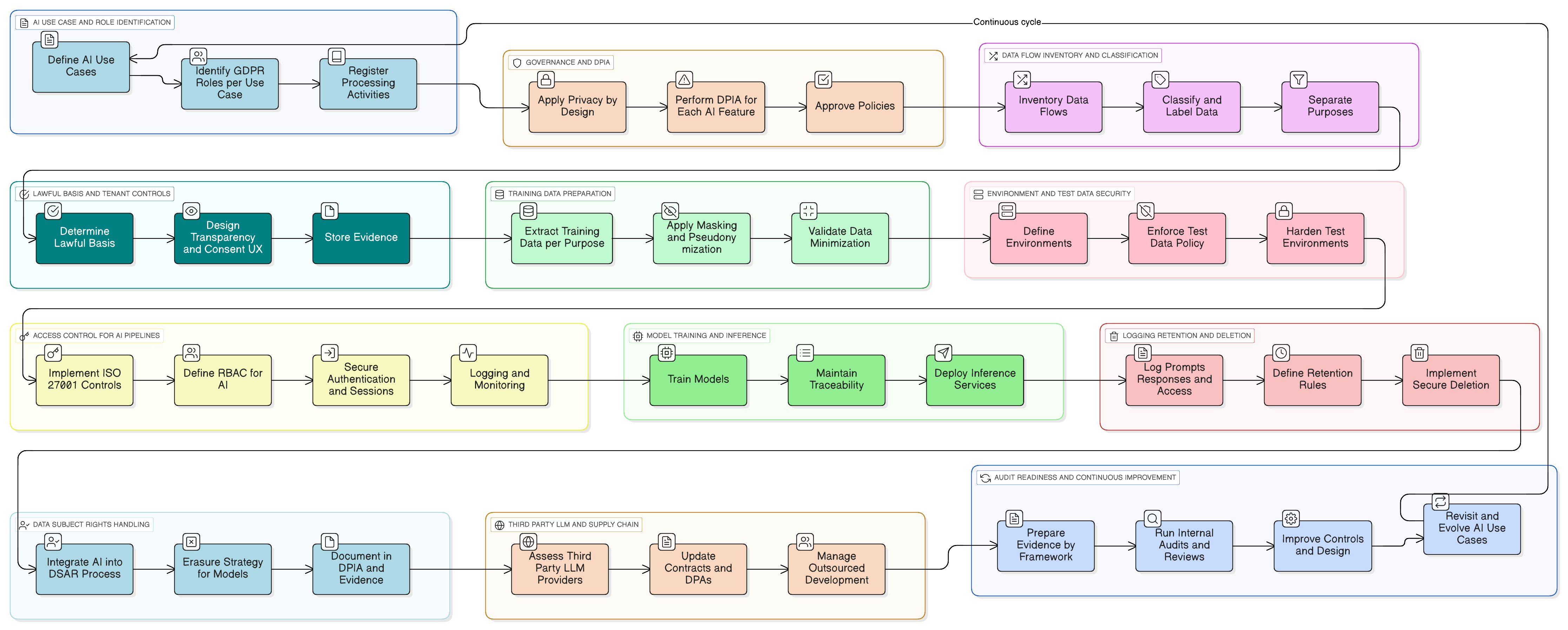
O Artigo 25 do RGPD da UE impõe a “proteção de dados desde a conceção e por defeito”. Não é uma recomendação; é um requisito legal. Para sistemas de IA, isto significa incorporar considerações de privacidade diretamente na arquitetura dos pipelines de dados, ambientes de treino e motores de inferência.
Parafraseando a orientação da ISO/IEC 27701, isto envolve várias ações essenciais para qualquer plataforma SaaS que desenvolva IA:
- Minimização desde a conceção: Não envie registos completos para o LLM se apenas precisar de um subconjunto. Remova ou mascare identificadores antes de os prompts saírem do seu sistema core.
- Limitação da finalidade: Separe “dados utilizados para disponibilizar a funcionalidade” de “dados utilizados para melhorar o modelo”. Cada finalidade deve ter o seu próprio fundamento de licitude e estar claramente documentada.
- Predefinições configuráveis: Disponibilize controlos ao nível do tenant, como “Permitir que os meus dados sejam utilizados para melhoria do modelo global de IA: Sim/Não”. As predefinições devem ser conservadoras, desativadas por defeito, salvo justificação robusta.
- Rastreabilidade: Registe que dados foram utilizados em cada tarefa de treino, ao abrigo de que fundamento jurídico e para que tenant. Isto é essencial para auditorias e pedidos dos titulares dos dados.
O Zenith Blueprint: roteiro de 30 etapas para auditores da Clarysec oferece um caminho estruturado para incorporar estes requisitos muito antes de escrever uma linha de código. Começa pela governação:
- Fase de fundação, etapa 2: compreender as partes interessadas: Esta etapa obriga a identificar todas as partes interessadas, incluindo autoridades de controlo da UE. Como observa o Zenith Blueprint, os seus requisitos incluem “tratamento lícito de dados pessoais, notificação de violações em 72h [e] direitos dos titulares dos dados”.
- Fase de auditoria e melhoria, etapa 24: criar e manter um registo de requisitos legais e regulamentares: Trabalhe com as equipas jurídicas para criar um repositório central de todas as leis aplicáveis, compreendendo como o RGPD da UE, NIS2, DORA e outros referenciais se cruzam com a sua postura de segurança em IA.
Com esta base, pode avançar para a implementação técnica com confiança.
Proteger o combustível: dados de treino lícitos e mínimos
A pergunta mais sensível em conformidade de IA é simples: “Podemos utilizar dados de clientes para treinar os nossos modelos?”
A resposta está numa estratégia em camadas centrada no fundamento de licitude, na minimização de dados e em salvaguardas técnicas como a pseudonimização.
Fundamento de licitude e finalidade transparente
Segundo a ISO/IEC 27701, deve identificar e documentar as finalidades do tratamento e estabelecer um fundamento de licitude para cada uma.
- Para disponibilização da funcionalidade, por exemplo pesquisa de IA dentro de um tenant: O fundamento de licitude é normalmente a execução de um contrato ou o interesse legítimo. Deve ser documentado no seu Registo de Atividades de Tratamento (RoPA).
- Para melhoria do modelo global, entre tenants: Frequentemente exige consentimento explícito ou um interesse legítimo muito cuidadosamente justificado, com um mecanismo de oposição claro e simples. A transparência no aviso de privacidade e na interface do produto é obrigatória.
Salvaguardas técnicas: pseudonimização e mascaramento
A anonimização verdadeira é difícil de alcançar sem destruir a utilidade dos dados. Uma abordagem mais prática e incentivada pelo RGPD da UE é a pseudonimização: substituir identificadores pessoais por identificadores artificiais. Isto minimiza o risco mantendo o valor dos dados para treino de modelos.
Este processo é um controlo essencial. No Zenith Blueprint, a etapa 20 aborda especificamente o mascaramento de dados, ligando-o diretamente aos princípios dos Artigos 25 e 32 do RGPD da UE. É uma medida de segurança obrigatória, não apenas uma boa prática.
A Política de Mascaramento de Dados e Pseudonimização da Clarysec operacionaliza esta exigência ao atribuir responsabilidades claras:
“O EPD deve validar a conformidade com os critérios de pseudonimização do RGPD da UE e coordenar com a função Jurídica quaisquer requisitos de divulgação regulamentar relacionados com violações de dados ou falhas dos controlos de mascaramento.”
- Da secção ‘Aplicação e cumprimento’, cláusula 8.4 da política.
Para as suas equipas de desenvolvimento, isto significa implementar scripts automatizados para mascarar ou pseudonimizar nomes, endereços de correio eletrónico, números de telefone e outros identificadores diretos antes de os dados entrarem no ambiente de treino. Também significa estabelecer um processo formal de validação com o seu EPD para garantir que a técnica é robusta.
A ameaça oculta: proteger dados de teste e experiências de IA
As violações de dados reais raramente começam num ambiente de produção moderno e reforçado. Começam nos cantos esquecidos da infraestrutura:
- Ambientes de pré-produção “seguros” com cópias de dados de produção mal sanitizadas.
- Exportações CSV “temporárias” de dados de clientes enviadas a engenheiros de ML para experiências locais.
- Scripts de QA que utilizam conteúdo bruto de utilizadores para testar prompts de LLM.
Foi precisamente aqui que começou o cenário de pesadelo da introdução. A Política de Dados de Teste e Ambientes de Teste para PME da Clarysec aborda diretamente este risco:
“Cumprir os regulamentos de proteção de dados aplicáveis, por exemplo RGPD da UE e NIS2, garantindo que todos os dados de teste são tratados de forma lícita, leal e segura.”
- Da secção ‘Objetivos’, cláusula 3.4 da política.
A sua política deve ser sustentada por controlos práticos. Nenhum dado pessoal de produção deve existir em ambientes de não produção sem mascaramento ou pseudonimização robustos. Os ambientes de teste devem utilizar chaves de API de LLM separadas, com privilégios reduzidos e limites de débito rigorosos. E deve existir uma regra explícita segundo a qual prompts de teste nunca incluem identificadores reais de clientes.
Reforçar o núcleo: controlo de acesso granular para pipelines de IA
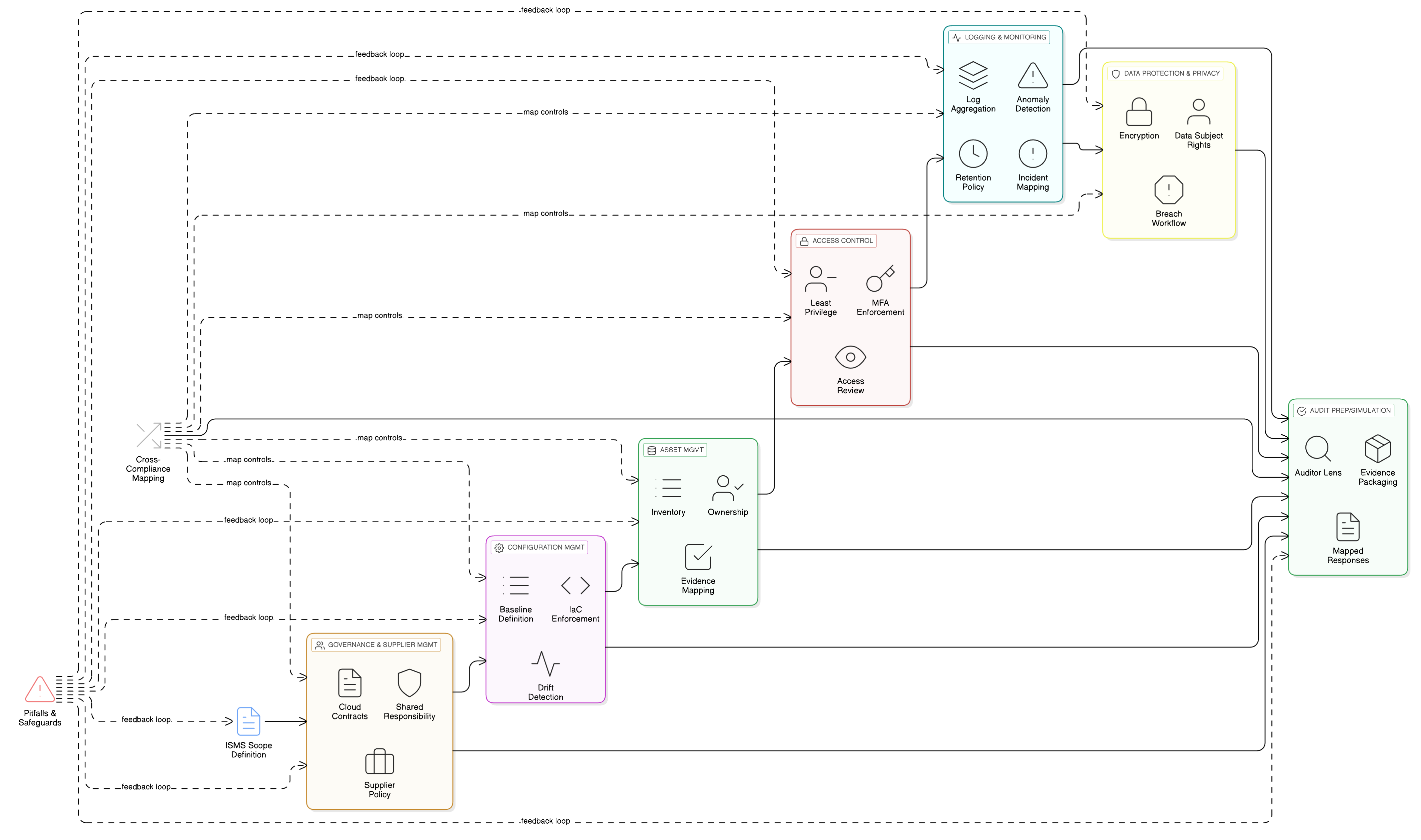
As funcionalidades de LLM assentam sobre os seus repositórios de dados, logs e pipelines de treino mais sensíveis. O controlo de acesso fundamental é, por isso, essencial para a conformidade com o RGPD da UE. Os controlos ISO/IEC 27001:2022 8.3 e 8.2 são os pilares da defesa. O Zenith Controls: guia de conformidade cruzada da Clarysec fornece o modelo para os implementar de forma eficaz.
Controlo ISO/IEC 27001:2022 8.3: restrição de acesso à informação
Este controlo visa garantir que o acesso à informação é concedido estritamente com base no princípio da necessidade de conhecer. Num ambiente de treino de LLM, isto significa que cientistas de dados, engenheiros de ML e os próprios processos automatizados apenas devem ter acesso aos dados específicos de que necessitam, e nada mais.
Como detalhado no Zenith Controls, este controlo está profundamente ligado a outros controlos:
- Ligação aos controlos 5.9 (inventário de informação e outros ativos associados) e 5.12 (classificação da informação): Não é possível restringir acessos se não souber que dados possui e qual é a sua sensibilidade. O seu conjunto de dados de treino de IA deve ser inventariado e classificado como altamente confidencial, num processo regido pela sua Política de Classificação e Rotulagem da Informação para PME.
- Ligação ao controlo 8.5 (autenticação segura): As restrições de acesso são inúteis sem verificação robusta da identidade. Todos os utilizadores e contas de serviço que acedem aos dados de treino devem ser autenticados de forma segura, preferencialmente com MFA.
Controlo ISO/IEC 27001:2022 8.2: privilégios de acesso
Os seus engenheiros de ML, SRE e cientistas de dados precisam de acesso elevado. Estas contas privilegiadas são “as chaves do reino” e alvos prioritários. O controlo 8.2 exige que estes direitos sejam geridos com rigor máximo.
Segundo o Zenith Controls, as relações principais são:
- Ligação aos controlos 8.15 (registo de eventos) e 8.16 (monitorização de atividades): Toda a atividade privilegiada deve ser registada e monitorizada. Se um cientista de dados tentar subitamente exportar todo o conjunto de dados de treino, deve ser gerado um alerta imediato.
- Ligação ao controlo 6.7 (trabalho remoto): Se a sua equipa de IA trabalha remotamente, o acesso privilegiado deve ser encaminhado por canais seguros e monitorizados, como uma VPN com controlos de sessão rigorosos.
A perspetiva do auditor: como demonstrar que os controlos de IA funcionam
Implementar controlos é apenas metade do trabalho. Deve demonstrar a sua eficácia. Auditores diferentes, formados em diferentes referenciais, procurarão evidência específica.
| Tipo de auditor | Foco do referencial | O que irá pedir (evidência) |
|---|---|---|
| Auditor ISO/IEC 27001 | ISO/IEC 27007:2020 | Mostre-me a sua Política de Controlo de Acesso para o ambiente de treino de IA. Disponibilize logs do seu processo de revisão de acessos relativos aos últimos 12 meses. Demonstre como um novo engenheiro de ML recebe acesso segundo o princípio do menor privilégio. |
| Auditor COBIT | COBIT 2019 (DSS05) | Preciso de ver a sua matriz de controlo de acesso baseado em funções (RBAC) para a equipa de ciência de dados. Disponibilize relatórios das suas ferramentas de monitorização que mostrem alertas relativos a tentativas anómalas de acesso ao lago de dados de treino. |
| Avaliador NIST | NIST SP 800-53A (AC-3, AC-6) | Vamos rever a configuração do sistema dos servidores que alojam os dados de treino. Quero verificar se as Listas de Controlo de Acesso (ACLs) aplicam tecnicamente as políticas documentadas. Mostre-me evidência de que as sessões privilegiadas são terminadas após inatividade. |
| Auditor de privacidade/RGPD da UE | ISO/IEC 27701:2021 | Disponibilize a sua Avaliação de Impacto sobre a Proteção de Dados (AIPD) para a funcionalidade de IA. Mostre-me os registos de consentimento dos titulares dos dados cujas informações estão no conjunto de treino. Como processa um pedido de “direito ao apagamento” relativo a dados dentro de um modelo treinado? |
Implementar corretamente os controlos 8.2 e 8.3 traz benefícios amplos. O Zenith Controls demonstra um mapeamento direto para requisitos do RGPD da UE (Artigos 5, 25, 32), NIS2 (Artigo 21), DORA (Artigo 10) e NIST SP 800-53 (AC-3, AC-6), permitindo satisfazer vários referenciais com uma única implementação de controlos unificada.
O paradoxo do “direito ao esquecimento”: gerir direitos dos titulares dos dados em IA
O Artigo 17 do RGPD da UE, o “direito ao apagamento”, apresenta um desafio técnico específico para IA. Como eliminar os dados de uma pessoa depois de terem sido utilizados para treinar um modelo massivo e complexo? Muitas vezes é tecnicamente inviável fazer o modelo “desaprender” pontos de dados específicos.
É aqui que as suas escolhas iniciais de conceção se tornam a melhor defesa. Não existe uma resposta perfeita única, mas estratégias práticas e defensáveis incluem:
- Pseudonimização primeiro: Se os dados de treino foram devidamente pseudonimizados, a ligação ao titular já está quebrada no corpus de treino. Pode então apagar os dados pessoais dos sistemas de origem e a ligação na tabela de chaves de pseudonimização.
- Segregação de dados para treino: Sempre que possível, mantenha conjuntos de dados de treino separados por tenant. Isto torna a remoção de dados viável sem retreinar todo o universo de modelos.
- Retreino programado do modelo: A sua AIPD deve abordar este risco. A mitigação pode consistir no compromisso de retreinar periodicamente o modelo de raiz, utilizando um conjunto de dados atualizado que exclua dados de utilizadores que solicitaram o apagamento.
A secção do Zenith Blueprint sobre eliminação de informação, etapa 20, que abrange o controlo 8.10, liga expressamente esta capacidade técnica aos Artigos 17 e 5(1)(e) do RGPD da UE, exigindo processos verificáveis para apagar dados com segurança quando já não são necessários.
Proteger a cadeia de fornecimento de IA: desenvolvimento externalizado e LLM de terceiros
Poucas empresas SaaS desenvolvem tudo internamente. Pode utilizar uma API de LLM de um prestador cloud hyperscale ou contratar um parceiro de desenvolvimento externalizado. Isto introduz risco na cadeia de fornecimento.
O Zenith Blueprint, na etapa 22 sobre desenvolvimento externalizado, destaca este risco e a sua ligação aos Artigos 28 e 32 do RGPD da UE. Como afirma o blueprint:
“Uma área frequentemente negligenciada é a formação e sensibilização. Os seus programadores externalizados podem ser competentes, mas receberam formação em práticas de codificação segura? Conhecem as suas políticas? Estão conscientes dos referenciais de conformidade que a sua organização deve cumprir, RGPD da UE, DORA, NIS2…?”
Para qualquer prestador externo de LLM ou parceiro de desenvolvimento, a diligência prévia é crítica. O seu Acordo de Tratamento de Dados (DPA) deve cobrir expressamente finalidades de tratamento relacionadas com IA, categorias de dados e proibições de o prestador utilizar os seus dados para treino dos seus próprios modelos. Deve verificar que o prestador implementa medidas de segurança alinhadas com o Artigo 32 do RGPD da UE. A sua cadeia de fornecimento de IA deve ser tão auditável como a sua infraestrutura core.
Da teoria à prática: exemplo concreto de uma funcionalidade de IA preparada para o RGPD da UE
Tornemos isto concreto. Imagine que está a adicionar um assistente de IA que resume conversas de suporte ao cliente, sugere rascunhos de resposta e aprende com tickets anteriores para melhorar.
Segue-se um padrão prático de implementação utilizando o conjunto de ferramentas da Clarysec:
- Classificação e rotulagem: Todos os tickets de suporte são classificados como “Confidencial” ao abrigo da sua Política de Classificação e Rotulagem da Informação para PME, em alinhamento com o RGPD da UE e as obrigações de tratamento de dados da DORA.
- Mascaramento antes do LLM: Um serviço de mascaramento interceta os dados antes de serem enviados para o LLM. Remove ou substitui nomes, endereços de correio eletrónico, números de telefone e outros dados pessoais. Todo este processo é regido pela Política de Mascaramento de Dados e Pseudonimização, com o EPD a validar a metodologia.
- Controlos de acesso para prompts e logs: Apenas funções autorizadas, por exemplo o Responsável pelo Produto de IA, podem aceder a logs brutos de prompts. Isto é implementado com o controlo ISO 27001:2022 8.3 (restrição de acesso à informação) para acesso geral e com o controlo 8.2 (privilégios de acesso) para qualquer visibilidade de nível administrativo, conforme mapeado no Zenith Controls.
- Consentimento para o corpus de dados de treino: O pipeline de treino ingere apenas dados mascarados. É disponibilizada uma definição de configuração ao nível do tenant, “Permitir que os meus dados mascarados sejam utilizados para melhoria do modelo global de IA: Sim/Não”, com a predefinição “Não”.
- Retenção e apagamento: Os logs de prompts são retidos apenas pelo tempo necessário. Quando um tenant desativa a funcionalidade ou termina o contrato, é acionado um fluxo de trabalho para apagar de forma segura ou anonimizar logs de IA e entradas de treino relacionados, seguindo o processo descrito na implementação do Zenith Blueprint para o controlo 8.10 (eliminação de informação).
Quando os auditores chegam, pode guiá-los pelos diagramas de fluxo de dados da funcionalidade, pelas políticas específicas que a regem e pela evidência técnica extraída dos seus sistemas, logs de acesso, configurações de tarefas e fluxos de trabalho de apagamento. Está a demonstrar conformidade em operação.
O seu plano de ação: de IA ad hoc a IA preparada para auditoria
Não precisa de desmontar o produto, mas precisa de uma abordagem estruturada e defensável. Segue-se um plano de ação conciso:
- Inventariar casos de utilização de IA e fluxos de dados: Identifique todos os locais onde são utilizados LLM, incluindo funcionalidades orientadas para clientes, ferramentas internas e experiências. Mapeie que dados seguem para onde, ao abrigo de que fundamento de licitude e quem tem acesso. Utilize a fase de fundação do Zenith Blueprint para garantir que o seu registo legal cobre todos os requisitos relacionados com IA do RGPD da UE, NIS2 e DORA.
- Estabelecer primeiro a governação: Antes de construir, realize uma Avaliação de Impacto sobre a Proteção de Dados (AIPD) para cada funcionalidade de IA. Documente a finalidade, o fundamento de licitude e os riscos. Implemente políticas estruturantes, como a Política de Proteção de Dados e Privacidade para PME e a Política de Segurança da Informação para PME.
- Restringir dados e acessos: Implemente controlos técnicos robustos. Adote a Política de Mascaramento de Dados e Pseudonimização e a Política de Dados de Teste e Ambientes de Teste para PME. Utilize o Zenith Controls para implementar e documentar os controlos ISO 27001:2022 8.2 e 8.3 em todos os repositórios de dados e pipelines de IA.
- Incorporar os direitos dos titulares dos dados nos fluxos de trabalho de IA: Atualize os procedimentos de DSAR e apagamento para incluir dados relacionados com IA. Documente a sua estratégia para tratar pedidos de apagamento no contexto de modelos treinados, com foco em pseudonimização e calendários de retreino de modelos.
- Colocar a cadeia de fornecimento de IA sob controlo: Atualize os DPA com prestadores de LLM terceiros e programadores externalizados. Garanta que os contratos proíbem expressamente utilizações de dados não autorizadas e exigem medidas de segurança robustas. Verifique que as equipas externas receberam formação sobre as suas políticas de tratamento de dados.
Inovar com confiança
A interseção entre IA e RGPD da UE é a nova fronteira da conformidade. Ao adotar uma abordagem estruturada e baseada no risco, pode libertar o poder transformador da inteligência artificial sem comprometer o seu compromisso com a proteção de dados e a privacidade.
A Clarysec fornece o mapa, as ferramentas e a experiência para o orientar nessa jornada. Utilizando:
- Zenith Blueprint: roteiro de 30 etapas para auditores para uma implementação faseada de controlos alinhados com o RGPD da UE para IA.
- Zenith Controls: guia de conformidade cruzada para unificar controlos ISO 27001:2022 com requisitos do RGPD da UE, NIS2, DORA e NIST.
- Políticas prontas para produção, como a Política de Proteção de Dados e Privacidade para PME, a Política de Mascaramento de Dados e Pseudonimização e a Política de Dados de Teste e Ambientes de Teste para PME, para codificar regras e satisfazer auditores.
Pode passar de experiências de IA ad hoc para uma capacidade de IA preparada para auditoria, que inspira confiança em autoridades de controlo, auditores e clientes empresariais exigentes. Pode continuar a inovar com LLM e, ainda assim, dormir descansado.
Se está a planear ou a operar funcionalidades de IA no seu produto SaaS, o próximo passo é simples. Descarregue amostras dos nossos conjuntos de ferramentas ou agende uma demonstração para ver como a Clarysec pode ajudar a criar um programa de IA que não seja apenas poderoso, mas também comprovadamente privado e seguro desde a conceção.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council