Mapeamento da resposta a incidentes do NIST para auditorias de 2026
São 07:42 de uma terça-feira. Anya, Diretora de Segurança da Informação de uma plataforma fintech em rápido crescimento, vê o primeiro alerta: deslocação impossível numa conta de administrador. Segue-se uma sequência de autenticações falhadas e, depois, uma sessão bem-sucedida a partir de um dispositivo não gerido. Cinco minutos mais tarde, o apoio ao cliente informa que os utilizadores não conseguem aceder a um fluxo de trabalho SaaS essencial. Às 08:10, o painel de gestão da nuvem mostra chamadas API anómalas contra um bucket de armazenamento que pode conter dados pessoais.
A equipa de segurança da informação atua rapidamente. O SIEM gera o alerta, o engenheiro de cloud revoga uma sessão e o proprietário do serviço começa a restaurar o acesso. Mas a verdadeira crise não é apenas técnica. É de governação.
Anya precisa de responder a três perguntas antes de terminar a primeira hora.
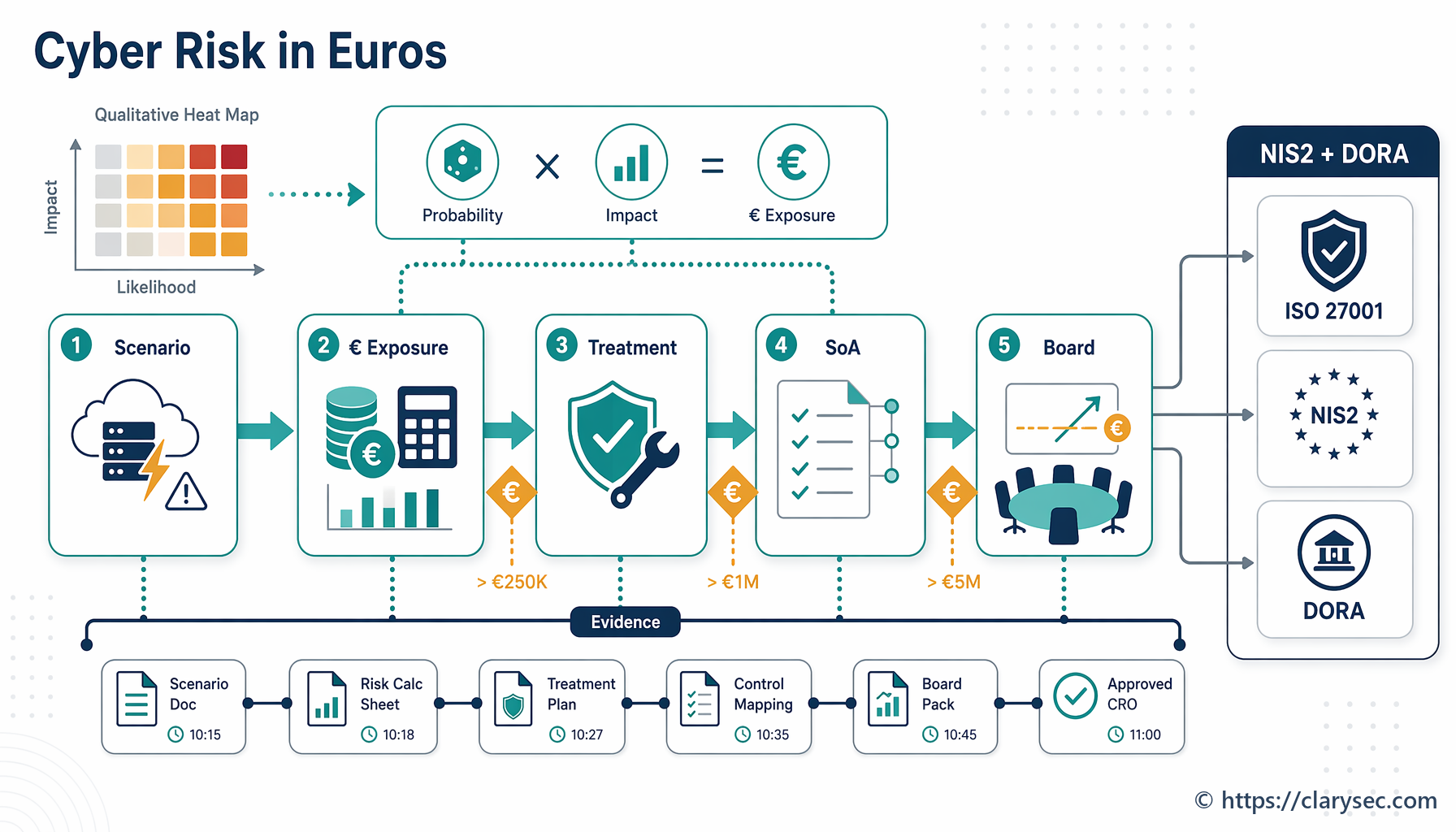
Primeiro, trata-se de um incidente de segurança da informação, uma violação de dados pessoais, um incidente significativo NIS2 ou um incidente de maior gravidade relacionado com TIC ao abrigo da DORA?
Segundo, quem deve ser informado, até quando e com que evidência?
Terceiro, a organização consegue provar que o seu processo de resposta a incidentes foi efetivamente executado conforme concebido?
É nesse momento que muitas organizações descobrem a diferença entre ter um plano de resposta a incidentes e ter um sistema de governação da resposta a incidentes. A resposta a incidentes segundo o NIST SP 800-61 e o NIST CSF 2.0 já não é apenas matéria de playbooks de SOC. Em 2026, está diretamente ligada à responsabilização do conselho de administração, às auditorias ISO/IEC 27001:2022, ao reporte faseado NIS2, à resiliência operacional DORA, às decisões sobre violação de dados pessoais no âmbito do RGPD da UE e à responsabilização de fornecedores.
Os programas mais robustos não criam vias de resposta separadas para cada referencial. Utilizam o NIST CSF 2.0 como mapa operacional, a ISO/IEC 27001:2022 como espinha dorsal do sistema de gestão e um único modelo de evidência capaz de suportar NIS2, DORA e RGPD da UE em simultâneo. Esta é a abordagem da Clarysec: decisões orientadas por políticas, fluxos de trabalho testados em exercícios de tabletop, pacotes de evidência prontos para reguladores e mapeamento entre referenciais através do Zenith Blueprint: roteiro de 30 passos para auditores e do Zenith Controls: guia de conformidade cruzada.
O problema de 2026: um incidente, vários regimes de responsabilização
O incidente que Anya enfrenta não é um único problema de conformidade. São várias vias de decisão sobrepostas.
Se a organização presta serviços de computação em cloud, SaaS, serviços geridos, serviços de segurança geridos, DNS, centro de dados, serviços de confiança ou outros serviços de infraestrutura digital, a NIS2 pode aplicar-se. A classificação como entidade essencial ou importante depende do setor, da dimensão e da transposição nacional, mas a direção é clara: o tratamento de incidentes é agora uma responsabilidade de gestão regulada.
Se a organização for uma entidade financeira, a DORA pode ser o principal referencial de resiliência operacional. A DORA é aplicável desde 17 de janeiro de 2025 e abrange a gestão do risco das TIC, o reporte de incidentes de maior gravidade relacionados com TIC, os testes de resiliência operacional, a partilha de informação, o risco de terceiros de TIC e a supervisão de prestadores terceiros críticos de serviços de TIC. Para entidades financeiras abrangidas que também estejam sujeitas à NIS2, a DORA atua como referencial setorial específico para obrigações sobrepostas de risco de TIC e reporte de incidentes.
Se dados pessoais tiverem sido acedidos, alterados, perdidos, destruídos ou divulgados, o RGPD da UE passa a integrar a árvore de decisão da resposta a incidentes. O RGPD da UE define violação de dados pessoais como uma violação de segurança que provoque, de modo acidental ou ilícito, a destruição, perda, alteração, divulgação não autorizada ou acesso a dados pessoais. O RGPD da UE também exige responsabilização, o que significa que o responsável pelo tratamento deve conseguir demonstrar conformidade com os princípios do tratamento, incluindo integridade e confidencialidade.
Se a empresa estiver certificada pela ISO/IEC 27001:2022, ou em preparação para certificação, o incidente torna-se evidência do SGSI. Os auditores irão analisar o âmbito, as obrigações legais, os papéis, o tratamento de riscos, a seleção de controlos, a execução operacional, a informação documentada, as lições aprendidas e a melhoria contínua. As cláusulas 4.1 a 4.4 da ISO/IEC 27001:2022 exigem que o SGSI reflita o contexto, as partes interessadas, as obrigações, o âmbito e as interações dos processos. As cláusulas 5.1 a 5.3 exigem liderança, responsabilização e responsabilidades atribuídas. As cláusulas 6.1.1 a 6.1.3 exigem avaliação de riscos de segurança da informação, tratamento e uma Declaração de Aplicabilidade. As cláusulas 8.1 a 8.3 exigem operação controlada, evidência de que os processos foram executados conforme planeado, controlo de processos externalizados e implementação do tratamento.
O problema da organização não é a falta de referenciais. É a falta de um modelo operacional único que transforme referenciais em decisões tempestivas e evidência fiável.
Utilizar o NIST CSF 2.0 como linguagem comum
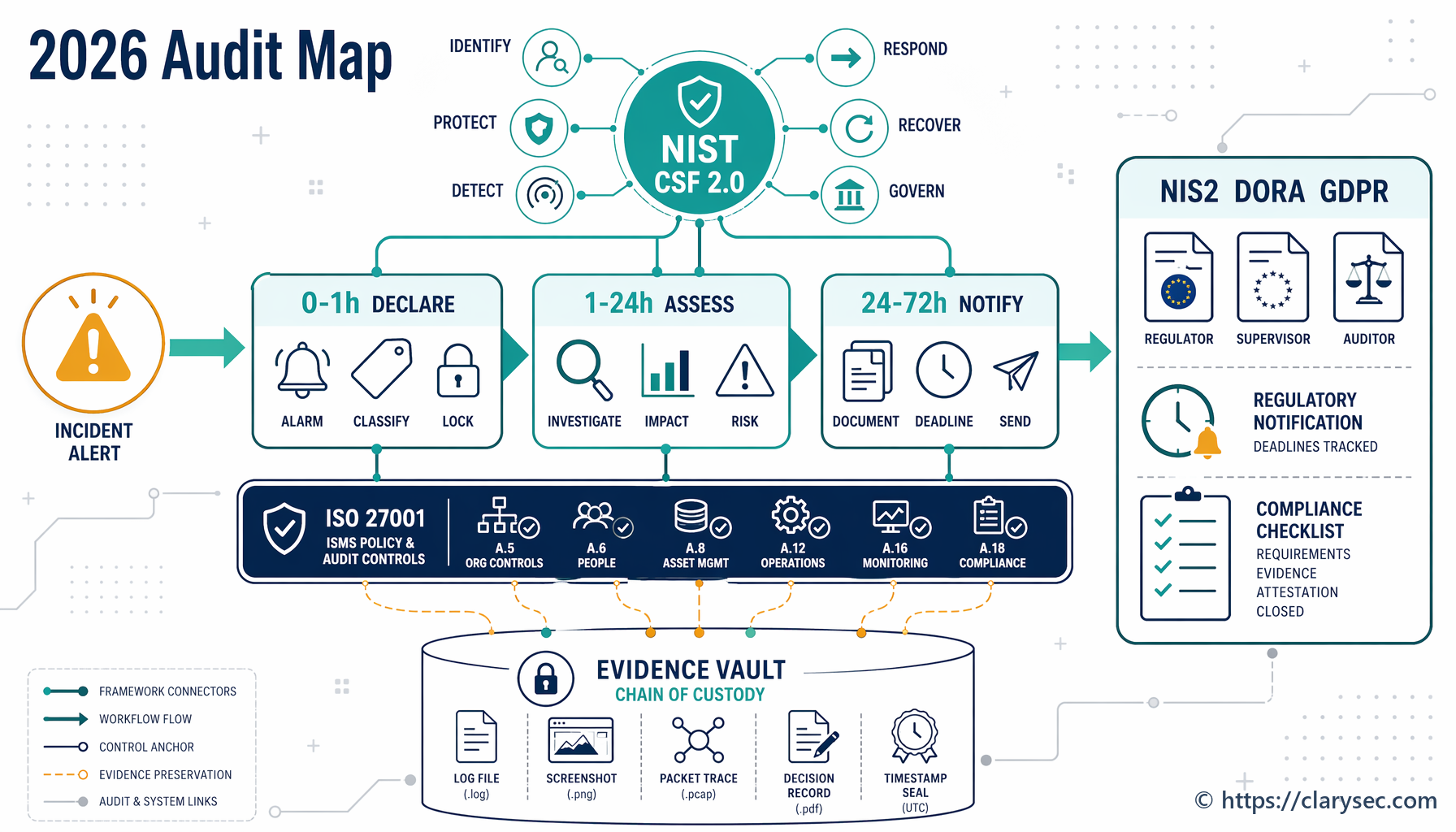
O NIST CSF 2.0 é útil porque fornece à liderança, segurança, jurídico, privacidade, operações e fornecedores uma linguagem comum para resultados de cibersegurança. A função GOVERN é especialmente importante para a resposta a incidentes, porque obriga as organizações a tratar supervisão, política, estratégia de risco, papéis e risco da cadeia de fornecimento antes de a crise começar.
Para a resposta a incidentes, o CSF 2.0 liga a governação ao ciclo de vida operacional: IDENTIFY, PROTECT, DETECT, RESPOND e RECOVER. Esta estrutura ajuda a transformar um incidente ruidoso num fluxo de evidência controlado.
| Pergunta de resposta a incidentes | Área de resultados do CSF 2.0 | Evidência de conformidade produzida |
|---|---|---|
| Quem é responsável pela decisão? | GOVERN, incluindo GV.RR, GV.OV e GV.PO | RACI, registo do comandante do incidente, atualizações à gestão, notificações ao conselho de administração |
| Que ativos e serviços são afetados? | IDENTIFY, incluindo visibilidade de ativos e riscos | inventário de ativos, mapa de serviços, inventário de dados, lista de fornecedores críticos |
| Que controlos falharam ou funcionaram? | PROTECT, incluindo acesso, segurança dos dados, configuração e cópias de segurança | logs de MFA, registos de acessos privilegiados, registos de cópias de segurança, configurações de referência |
| Como foi detetado o evento? | DETECT, incluindo DE.CM e DE.AE | alertas SIEM, alertas EDR, logs de cloud, notas de correlação, registo de declaração |
| Como foi tratado? | RESPOND, incluindo RS.MA, RS.AN, RS.CO e RS.MI | ticket de incidente, classificação de severidade, cronologia, registo de decisões, ações de contenção |
| Como foi restaurado o serviço? | RECOVER, incluindo RC.RP e RC.CO | execução da recuperação, validação de cópias de segurança, evidência de serviço restaurado, comunicações, relatório de encerramento |
Os Perfis Organizacionais do CSF 2.0 tornam isto prático. Um Perfil Atual mostra a capacidade real de resposta a incidentes da organização, incluindo lacunas, ambiguidades e soluções de contorno. Um Perfil-Alvo define o estado pretendido, como classificação de severidade em uma hora, decisões de notificação documentadas, preservação de evidência, coordenação com terceiros e pacotes de reporte prontos para reguladores.
Na fintech de Anya, o Perfil Atual mostrou um padrão comum: ferramentas fortes, governação de decisões fraca. O Perfil-Alvo centrou-se em resultados concretos do CSF 2.0, incluindo:
- RS.MA-01, o plano de resposta a incidentes é executado em coordenação com terceiros relevantes assim que um incidente é declarado.
- RS.MA-02, os relatórios de incidente são triados e validados.
- RS.MA-03, os incidentes são categorizados e priorizados.
- RS.MA-04, os incidentes são escalados ou elevados conforme necessário.
- RS.AN-03, é realizada análise para estabelecer o que ocorreu durante um incidente e a causa raiz.
- RS.AN-06, as ações realizadas durante uma investigação são registadas, e a integridade e proveniência dos registos são preservadas.
- RS.AN-07, os dados e metadados do incidente são recolhidos, e a sua integridade e proveniência são preservadas.
- RS.CO-02, as partes interessadas internas e externas são notificadas dos incidentes.
- RS.MI-01, os incidentes são contidos.
- RS.MI-02, os incidentes são erradicados.
- RC.RP-03, a integridade das cópias de segurança e de outros ativos de restauro é verificada antes da sua utilização no restauro.
Um referencial, por si só, não constitui um programa auditável. Os resultados devem estar integrados num sistema de gestão, e é aqui que a ISO/IEC 27001:2022 fornece a espinha dorsal.
Ancorar a resposta a incidentes na ISO/IEC 27001:2022
O NIST fornece uma linguagem prática para o tratamento de incidentes. A ISO/IEC 27001:2022 fornece a disciplina operacional esperada pelos auditores. O SGSI transforma a resposta a incidentes de um conjunto de playbooks num processo governado, com âmbito, propriedade, tratamento de riscos, avaliação de desempenho e melhoria.
O conjunto de controlos mais relevante do Anexo A é:
| Controlo do Anexo A da ISO/IEC 27001:2022 | Nome do controlo | Finalidade para a resposta a incidentes |
|---|---|---|
| A.5.24 | Planeamento e preparação da gestão de incidentes de segurança da informação | Estabelece o plano, os papéis, o escalonamento e o modelo de comunicação |
| A.5.25 | Avaliação e decisão sobre eventos de segurança da informação | Define critérios de triagem, classificação e decisão |
| A.5.26 | Resposta a incidentes de segurança da informação | Orienta contenção, erradicação, recuperação e comunicações |
| A.5.27 | Aprendizagem com incidentes de segurança da informação | Converte lições aprendidas em ações corretivas e melhoria |
| A.5.28 | Recolha de evidência | Preserva a fiabilidade, proveniência e utilidade legal da evidência |
O guia Zenith Controls da Clarysec mapeia estas referências de controlo da ISO/IEC 27002:2022 para outras normas, expectativas de auditoria e obrigações de conformidade relacionadas. Não é um referencial de controlos separado. É um guia de conformidade cruzada que ajuda as organizações a compreender como as mesmas atividades de controlo suportam múltiplas necessidades de garantia.
O Zenith Blueprint, na fase Controls in Action, passo 23, operacionaliza a espinha dorsal da resposta a incidentes:
Garanta que dispõe de um plano de resposta a incidentes (5.24) atualizado, abrangendo preparação, escalonamento, resposta e comunicação. Defina o que constitui um evento de segurança reportável (5.25) e como o processo de decisão é acionado e documentado. Selecione um evento recente ou realize um exercício de tabletop para validar o seu plano. Capture e registe todas as decisões, papéis e comunicações (5.26), e atualize o plano com as lições aprendidas (5.27). Confirme que existem procedimentos para preservar evidência forense (5.28), incluindo snapshots de logs, cópias de segurança e isolamento seguro dos sistemas afetados.
Esse parágrafo é a ponte prática entre o tratamento de incidentes segundo o NIST e a evidência de auditoria. Preparar a capacidade, classificar o evento, responder de forma controlada, aprender com o resultado e preservar evidência.
Integrar a obrigação de reporte na primeira hora
Os programas de resposta a incidentes falham frequentemente na primeira hora, não por falta de competência dos analistas, mas porque a organização não definiu quem decide, quando é atribuída a severidade, que evidência é preservada e quando são verificados os acionadores legais.
Para PME, a Política de resposta a incidentes para PME da Clarysec estabelece uma expectativa clara de governação:
O Diretor-Geral, com contributo do prestador de TI, deve classificar todos os incidentes por severidade no prazo de uma hora após a notificação.
Este é um requisito forte. Não significa que todos os factos sejam conhecidos no prazo de uma hora. Significa que a organização deve documentar uma severidade inicial, registar a incerteza e acionar o escalonamento enquanto os factos ainda estão a evoluir.
A mesma política também exige que os prazos legais sejam incorporados no processo:
Os prazos de resposta, incluindo recuperação de dados e obrigações de notificação, devem ser documentados e alinhados com os requisitos legais, como o requisito de notificação de violação de dados pessoais no prazo de 72 horas previsto no RGPD da UE.
Para ambientes empresariais, a Política de resposta a incidentes da Clarysec ancora um modelo de resposta mais formal:
A organização deve manter um quadro de resposta a incidentes centralizado e por níveis, alinhado com a ISO/IEC 27035, composto pelas seguintes fases de resposta definidas:
A política empresarial também incorpora referências temporais transregulatórias na cláusula 6.4.1:
RGPD da UE Article 33 (notificação à autoridade de controlo no prazo de 72 horas)
NIS2 Article 23 (notificação no prazo de 24 horas após ter conhecimento do incidente)
DORA Article 17 (reporte de incidentes graves relacionados com TIC)
Esta é a diferença entre um playbook técnico e um quadro de resposta a incidentes preparado para governação. As vias de reporte legal e regulamentar não são improvisadas durante uma crise. São acionadas por pontos de classificação e decisão previamente definidos.
Mapear o reporte NIS2 no fluxo de trabalho de incidentes
A NIS2 exige que as entidades essenciais e importantes notifiquem, sem demora injustificada, o CSIRT ou a autoridade competente sobre incidentes significativos que afetem a prestação de serviços. Um incidente significativo inclui aquele que causou ou é suscetível de causar uma perturbação operacional grave ou perdas financeiras, ou aquele que afetou ou é suscetível de afetar terceiros ao causar danos materiais ou imateriais consideráveis.
O modelo de reporte é faseado.
| Fase NIS2 | Prazo | Evidência que o processo deve produzir |
|---|---|---|
| Alerta precoce | No prazo de 24 horas após a tomada de conhecimento | declaração de incidente, suspeita de atividade maliciosa, verificação de impacto transfronteiriço, visão inicial dos serviços afetados |
| Notificação de incidente | No prazo de 72 horas | avaliação de severidade, análise de impacto, indicadores de compromisso quando disponíveis, registo de incertezas |
| Relatórios intermédios | Mediante pedido | atualizações de estado, ações de contenção, estado de recuperação, comunicações com o regulador |
| Relatório final | No prazo de um mês após a notificação do incidente | severidade e impacto, ameaça provável ou causa raiz, medidas de mitigação, impacto transfronteiriço |
| Relatório de progresso de incidente em curso | Se ainda estiver em curso no momento do relatório final | relatório de progresso e, depois, relatório final no prazo de um mês após o tratamento |
A NIS2 Article 21 também exige medidas técnicas, operacionais e organizacionais adequadas e proporcionadas. A base exigida inclui análise de riscos, tratamento de incidentes, continuidade de negócio, segurança da cadeia de fornecimento, desenvolvimento seguro, tratamento de vulnerabilidades, avaliação da eficácia, higiene de cibersegurança e formação, criptografia, segurança de recursos humanos, controlo de acesso, gestão de ativos e, quando apropriado, autenticação multifator e comunicações seguras.
A NIS2 Article 20 integra os órgãos de gestão na cadeia de responsabilização. Devem aprovar as medidas de gestão do risco de cibersegurança e supervisionar a sua implementação. Para a resposta a incidentes, isto significa que atas do conselho de administração, aprovações da gestão, registos de formação e evidência de escalonamento não são artefactos administrativos opcionais. Fazem parte da defensabilidade regulamentar.
As sanções aumentam a urgência. Para infrações à Article 21 ou à Article 23, as entidades essenciais devem estar sujeitas a coimas máximas de, pelo menos, 10 milhões de EUR ou 2 por cento do volume de negócios anual mundial total, consoante o que for mais elevado. As entidades importantes devem estar sujeitas a coimas máximas de, pelo menos, 7 milhões de EUR ou 1,4 por cento do volume de negócios anual mundial total, consoante o que for mais elevado.
A lição prática é simples: se a hora de tomada de conhecimento, os critérios de severidade, o escalonamento e as decisões de reporte não forem registados, o problema deixa de ser apenas maturidade da resposta a incidentes. Passa a ser um problema de evidência regulamentar.
Tratar a gestão de incidentes DORA como resiliência operacional
A DORA altera a discussão para entidades financeiras porque a gestão de incidentes faz parte da resiliência operacional digital, não apenas das operações de segurança.
A Article 5 exige que o órgão de administração defina, aprove, supervisione e permaneça responsável pelo quadro de gestão do risco das TIC. A Article 6 expande esse quadro para um sistema estruturado de gestão do risco das TIC. A Article 17 exige que as entidades financeiras definam, estabeleçam e implementem um processo de gestão de incidentes relacionados com TIC para detetar, gerir e notificar incidentes relacionados com TIC. O processo deve registar incidentes relacionados com TIC e ameaças cibernéticas significativas, identificar e tratar causas raiz, utilizar indicadores de alerta precoce, classificar incidentes por prioridade, severidade e criticidade dos serviços afetados, atribuir papéis e responsabilidades, estabelecer comunicação e escalonamento, notificar clientes e meios de comunicação quando exigido, reportar pelo menos os incidentes de maior gravidade à direção de topo, informar o órgão de administração e manter procedimentos de resposta para mitigar o impacto e restaurar operações seguras.
A Article 18 exige classificação com base em critérios como clientes ou contrapartes afetados, transações, impacto reputacional, duração e indisponibilidade, dispersão geográfica, perdas de dados que afetem disponibilidade, autenticidade, integridade ou confidencialidade, criticidade dos serviços afetados e impacto económico. A Article 19 exige o reporte de incidentes de maior gravidade relacionados com TIC à autoridade competente, permite a notificação voluntária de ameaças cibernéticas significativas e exige a notificação dos clientes sem demora injustificada quando um incidente de maior gravidade relacionado com TIC afeta os seus interesses financeiros.
Para a fintech de Anya, isto significa que o registo do incidente precisa de mais do que uma cronologia do SOC. Precisa de:
- Serviço afetado e criticidade.
- Clientes, contrapartes ou transações afetados.
- Duração da indisponibilidade e dispersão geográfica.
- Perda de dados ou impacto na integridade.
- Impacto económico.
- Visibilidade pelo órgão de administração.
- Decisão de notificação a clientes.
- Encerramento da causa raiz.
- Restauro de operações seguras.
- Envolvimento de fornecedores e evidência contratual.
A DORA também prolonga a narrativa do incidente para a gestão de fornecedores. As Articles 28 a 30 exigem que as entidades financeiras façam a gestão do risco de terceiros de TIC, mantenham um registo de acordos contratuais de serviços de TIC, avaliem o risco de concentração, realizem diligência prévia, assegurem salvaguardas contratuais, definam direitos de auditoria e inspeção, mantenham direitos de cessação e testem estratégias de saída para funções críticas ou importantes. Se o incidente envolver um prestador de serviços cloud, prestador de serviços geridos ou integração SaaS, a evidência DORA deve demonstrar papéis do fornecedor, obrigações de preservação de logs, apoio ao incidente, deveres de recuperação e cooperação com a supervisão.
Integrar cedo a responsabilização por violação de dados pessoais no âmbito do RGPD da UE
O RGPD da UE aplica-se ao tratamento automatizado de dados pessoais e ao tratamento não automatizado que faça parte de um sistema de ficheiros. Pode aplicar-se a organizações estabelecidas na UE e a responsáveis pelo tratamento ou subcontratantes fora da UE que ofereçam bens ou serviços a pessoas na União ou monitorizem o seu comportamento.
Durante a resposta a incidentes, a análise RGPD da UE deve começar assim que dados pessoais possam estar envolvidos. Esperar pela causa raiz técnica é demasiado tarde se o relógio de 72 horas já estiver a contar.
A equipa de resposta deve responder:
- Que categorias de dados pessoais podem estar envolvidas?
- Que sistemas, aplicações e atividades de tratamento são afetados?
- A organização atua como responsável pelo tratamento, subcontratante, ou ambos?
- Houve acesso, alteração, destruição, perda ou divulgação de dados pessoais?
- As salvaguardas de cifragem, tokenização ou pseudonimização foram eficazes?
- Qual é o risco provável para os titulares dos dados?
- Quem tomou a decisão de notificação e quando?
- Que comunicações foram enviadas a responsáveis pelo tratamento, subcontratantes, autoridades de controlo ou titulares dos dados?
- Se a notificação não foi efetuada, qual foi a fundamentação documentada?
A responsabilização prevista na RGPD da UE Article 5 é essencial. O responsável pelo tratamento deve conseguir demonstrar conformidade com princípios como licitude, lealdade, transparência, limitação das finalidades, minimização dos dados, limitação da conservação, integridade e confidencialidade. Isto significa que o registo de violações, o registo de decisões, a evidência técnica e o histórico de comunicações fazem parte do sistema de controlo de privacidade, não são notas paralelas após a remediação.
Preservar evidência antes que a recuperação a destrua
Uma falha recorrente na resposta a incidentes é a recuperação que destrói a prova. Sistemas são reiniciados. Malware é eliminado. Logs rodam. Contas são alteradas antes da captura de snapshots. Do ponto de vista da disponibilidade, a equipa pode sentir-se bem-sucedida. Do ponto de vista de auditoria, regulador, seguradora ou jurídico, a organização pode ter perdido a capacidade de provar o que aconteceu.
A Política de Recolha de Evidência e Análise Forense da Clarysec estabelece:
Um registo de cadeia de custódia deve acompanhar toda a evidência física ou digital desde o momento da aquisição até ao arquivo ou transferência, e deve documentar:
Para PME, a Política de Recolha de Evidência e Análise Forense para PME inicia o requisito de registo de evidência de forma direta:
Cada item de evidência digital deve ser registado com:
O Zenith Blueprint, na fase Controls in Action, passo 23, explica o princípio por detrás do controlo 5.28 da ISO/IEC 27002:2022:
Quando ocorre um incidente de segurança da informação, um dos elementos mais críticos, embora frequentemente negligenciado, da resposta é a evidência. Não logs, não capturas de ecrã, não narrativas soltas, mas evidência devidamente preservada, respeitando a cadeia de custódia e resistente à adulteração. O controlo 5.28 reconhece que, após um incidente, aquilo que consegue provar é tão importante como aquilo que realmente aconteceu.
Um pacote de evidência pronto para regulador relativo ao incidente de Anya deve incluir:
| Item de evidência | Porque é relevante | Proprietário |
|---|---|---|
| Registo de declaração do incidente | Demonstra a hora de tomada de conhecimento e inicia a análise temporal | Comandante do incidente |
| Classificação de severidade | Suporta decisões de escalonamento, priorização e reporte | Líder de segurança ou prestador de TI |
| Extrato do inventário de ativos e dados | Identifica serviços, sistemas, dados e criticidade afetados | Proprietário de TI e responsável de privacidade |
| Exportações de logs com carimbos temporais | Suportam deteção, cronologia e análise de causa raiz | SOC ou prestador de TI |
| Snapshot do trilho de auditoria da cloud | Demonstra atividade de API, atividade de identidade e ações de armazenamento | Administrador de cloud |
| Registo de cadeia de custódia | Preserva a fiabilidade e a rastreabilidade da evidência | Responsável forense |
| Notificação à gestão | Demonstra escalonamento e visibilidade de governação | Diretor de Segurança da Informação ou Diretor-Geral |
| Registo de decisões regulatórias | Demonstra por que motivo a notificação era ou não exigida | Jurídico, EPD e Diretor de Segurança da Informação |
| Registo de comunicação com fornecedor | Demonstra cooperação de terceiros e resposta contratual | Gestor do fornecedor |
| Registo de comunicação com clientes | Suporta obrigações NIS2, DORA, RGPD da UE e contratuais | Responsável de comunicação |
| Registo de lições aprendidas | Suporta a melhoria contínua da ISO/IEC 27001:2022 | Gestor do SGSI |
A retenção de logs deve ser explícita. A Política de registo em logs e monitorização para PME da Clarysec estabelece:
Os logs de segurança relacionados com incidentes devem ser preservados durante pelo menos 3 anos a contar da data do incidente
O Zenith Blueprint, na fase Controls in Action, passo 19, acrescenta a verdade operacional:
O registo em logs é o sistema circulatório de qualquer ambiente de TI seguro. Sem ele, os incidentes permanecem invisíveis, a responsabilização desvanece-se e as relações de causa e efeito desaparecem sem deixar rasto.
A resposta a incidentes, o registo em logs, a recolha de evidência e o reporte devem, portanto, ser concebidos como um único sistema de controlos interligado.
Executar as primeiras 72 horas como um sprint de evidência
Um sprint prático de evidência de 72 horas ajuda as equipas a responder sem perder auditabilidade.
Hora 0 a 1: declarar, classificar e preservar
Abra o ticket de incidente utilizando a Política de resposta a incidentes. Atribua um comandante do incidente, um responsável técnico, um responsável de comunicação, um responsável jurídico ou de privacidade, um coordenador de fornecedores e um proprietário da evidência.
Utilize o requisito de classificação em uma hora da Política de resposta a incidentes para PME como ponto de controlo, mesmo em organizações maiores. Aplique o quadro por níveis para resposta empresarial e registe a incerteza quando os factos estiverem incompletos.
Preserve imediatamente evidência volátil: logs de identidade, alertas EDR, trilhos de auditoria cloud, registos de acessos privilegiados, logs de sistemas afetados, estado das cópias de segurança, alterações de configuração e histórico de tickets relevante. Inicie o registo de cadeia de custódia utilizando a Política de Recolha de Evidência e Análise Forense.
Resultados de decisão:
- Hora de declaração do incidente.
- Severidade inicial.
- Serviços suspeitos de estarem afetados.
- Dados suspeitos de estarem afetados.
- Lista inicial de vigilância regulamentar, incluindo RGPD da UE, NIS2, DORA e deveres contratuais.
- Lacunas de evidência e proprietários atribuídos.
Hora 1 a 24: análise de impacto e de alerta precoce
Construa a primeira visão de impacto. Determine se o evento afetou a prestação do serviço, causou ou poderia causar perturbação operacional ou perda financeira, afetou terceiros ou criou danos materiais ou imateriais. Isto suporta a análise de incidente significativo NIS2.
Para entidades financeiras, classifique segundo os critérios DORA: clientes afetados, transações, reputação, indisponibilidade, dispersão geográfica, perda de dados, criticidade e impacto económico.
Para o RGPD da UE, determine se estiveram envolvidos dados pessoais e se existe risco provável para os titulares dos dados.
Resultados de decisão:
- Decisão de alerta precoce NIS2.
- Estado de vigilância de incidente de maior gravidade DORA.
- Estado da avaliação de violação de dados pessoais RGPD da UE.
- Vigilância de notificação a clientes, consumidores ou responsáveis pelo tratamento.
- Atualização ao órgão de administração.
- Pedidos de evidência a fornecedores.
Hora 24 a 72: preparar evidência de notificação ao nível regulatório
Se a NIS2 se aplicar, prepare a atualização de notificação do incidente em 72 horas com severidade preliminar, impacto e indicadores de compromisso quando disponíveis. Se a notificação RGPD da UE for exigida, garanta que o pacote para a autoridade de controlo reflete o que é conhecido, o que permanece desconhecido, as consequências prováveis e as medidas tomadas ou propostas. Se a DORA se aplicar, prepare o relatório inicial ou intermédio exigido através do processo da autoridade competente.
Resultados de decisão:
- Cronologia atualizada do incidente.
- Hipótese de causa raiz.
- Ações de contenção e erradicação.
- Evidência de restauro do serviço.
- Pacote de notificação ao regulador.
- Comunicações a clientes ou consumidores.
- Inventário de evidência atualizado.
Este sprint não é documentação por si só. Impede que a equipa de resposta sacrifique evidência enquanto restaura as operações.
Mapeamento entre referenciais: um fluxo de trabalho, muitos consumidores de evidência
Um programa maduro de resposta a incidentes produz evidência uma vez e reutiliza-a entre referenciais.
| Elemento do fluxo de resposta a incidentes | CSF 2.0 | ISO/IEC 27001:2022 e Anexo A | NIS2 | DORA | RGPD da UE |
|---|---|---|---|---|---|
| Governação e propriedade | GV.RR, GV.OV, GV.PO | Cláusulas 5.1 a 5.3, A.5.24 | Article 20 supervisão pela gestão | Articles 5 e 6 responsabilidade do órgão de administração | Article 5 responsabilização |
| Âmbito e obrigações | GV.OC | Cláusulas 4.1 a 4.4 | Âmbito de entidades essenciais e importantes | Âmbito e proporcionalidade das entidades financeiras | Âmbito material e territorial |
| Critérios de risco e severidade | GV.RM, ID.RA, RS.MA-03 | Cláusulas 6.1.1 a 6.1.3, A.5.25 | Critérios de incidente significativo | Article 18 classificação | Risco para os titulares dos dados |
| Deteção e monitorização | DE.CM, DE.AE | A.8.15 registo em logs, A.8.16 monitorização, A.5.25 | Tratamento de incidentes e avaliação da eficácia | Indicadores de alerta precoce e registos de incidentes | Deteção e avaliação de violações |
| Execução da resposta | RS.MA, RS.AN, RS.MI | A.5.26, A.5.28 | Article 23 via de reporte | Articles 17 e 19 processo e reporte de incidentes | Article 33 e Article 34 avaliação |
| Recuperação | RC.RP, RC.CO | A.5.29 preparação das TIC para continuidade de negócio, A.8.13 cópia de segurança da informação | Minimização do impacto no serviço | Restauro de operações seguras | Mitigação e comunicação |
| Lições aprendidas | GV.OV, RS.IM | A.5.27 e cláusula 10 melhoria | Ação corretiva sem demora injustificada | Encerramento da causa raiz e ações corretivas | Registos de responsabilização |
O mapeamento da resposta ISO para NIST é especialmente útil para auditores.
| Atividade ISO/IEC 27002:2022 | Subcategoria NIST CSF 2.0 |
|---|---|
| Execução do plano de resposta a incidentes com terceiros | RS.MA-01 |
| Triagem e validação de relatórios de incidente | RS.MA-02 |
| Categorização e priorização | RS.MA-03 |
| Escalonamento conforme necessário | RS.MA-04 |
| Análise e determinação da causa raiz | RS.AN-03 |
| Registo de ações investigativas e preservação da proveniência | RS.AN-06 |
| Recolha de dados de incidente e preservação da integridade | RS.AN-07 |
| Estimativa e validação da magnitude do incidente | RS.AN-08 |
| Notificação de partes interessadas internas e externas | RS.CO-02 |
| Contenção e erradicação | RS.MI-01 e RS.MI-02 |
| Execução do plano de recuperação e verificação da integridade das cópias de segurança | RC.RP-01 e RC.RP-03 |
A governação da cadeia de fornecimento também deve ser incluída. A NIST CSF 2.0 GV.SC aborda processos de risco da cadeia de fornecimento, papéis dos fornecedores, priorização por criticidade, requisitos contratuais, diligência prévia, monitorização contínua, inclusão de fornecedores no planeamento de incidentes e atividades de fim de relação. Isto alinha diretamente com a segurança da cadeia de fornecimento NIS2, a gestão do risco de terceiros de TIC DORA e os controlos de fornecedores da ISO/IEC 27001:2022.
Como diferentes auditores irão testar o mesmo incidente
Um auditor ISO/IEC 27001:2022 começará pelo SGSI. Perguntará se a gestão de incidentes está no âmbito, se as obrigações das partes interessadas estão documentadas, se os riscos de incidentes são avaliados, se A.5.24 a A.5.28 estão incluídos na Declaração de Aplicabilidade, se o processo foi executado conforme planeado e se o incidente produziu lições aprendidas, ações corretivas e melhoria contínua.
Um avaliador orientado para NIST concentrar-se-á nos resultados do CSF 2.0. Testará governação, visibilidade de ativos, monitorização, declaração de incidente, triagem, escalonamento, integridade da evidência, comunicações com partes interessadas, contenção, erradicação, recuperação e atualização de perfis.
Uma revisão supervisora NIS2 concentrar-se-á na responsabilização da gestão, nas medidas de gestão de riscos da Article 21 e no reporte da Article 23. A evidência da decisão de alerta precoce em 24 horas, do conteúdo da notificação em 72 horas, dos relatórios intermédios e do relatório final será central. O revisor também poderá analisar continuidade de negócio, segurança da cadeia de fornecimento, controlo de acesso, formação, criptografia e avaliação da eficácia.
Um regulador DORA concentrar-se-á na resiliência operacional. Esperará critérios de classificação de incidentes, registos de incidentes relacionados com TIC e ameaças cibernéticas significativas, indicadores de alerta precoce, escalonamento para a direção de topo, visibilidade pelo órgão de administração, notificação a clientes quando os interesses financeiros forem afetados, encerramento da causa raiz, restauro de operações seguras e evidência de fornecedores.
Uma autoridade de controlo do RGPD da UE concentrar-se-á na responsabilização por violação de dados pessoais. Perguntará quando a organização tomou conhecimento, que dados pessoais foram afetados, se a organização era responsável pelo tratamento ou subcontratante, que risco existia para os titulares dos dados, que medidas foram tomadas, por que motivo a notificação foi ou não efetuada e se o registo interno de violações está completo.
Um auditor de estilo COBIT ou ISACA testará objetivos de governação, práticas de gestão, propriedade, métricas e evidência de garantia. Importar-se-á com saber se a resposta a incidentes é governada, medida, melhorada e alinhada com os objetivos empresariais.
O mesmo incidente pode satisfazer todas estas revisões se o fluxo de trabalho for concebido em torno de evidência partilhada, e não de dossiês de conformidade isolados.
Testar o mapeamento com um exercício de tabletop orientado por prazos
A forma mais rápida de perceber se o mapeamento funciona é um exercício de tabletop construído em torno de prazos de reporte.
Utilize este cenário: uma conta privilegiada de engenheiro é comprometida. O atacante acede a uma base de dados de produção, exporta um volume desconhecido de registos, altera uma definição de configuração que causa indisponibilidade parcial para clientes da UE e utiliza um token de API emitido através de uma integração de terceiros.
Execute o exercício em quatro rondas.
Ronda um, deteção e declaração. A equipa consegue identificar a origem do alerta, declarar o incidente, classificar a severidade no prazo de uma hora, preservar logs e atribuir papéis?
Ronda dois, impacto. A equipa consegue identificar serviços afetados, dados afetados, clientes afetados, envolvimento de fornecedores, indisponibilidade, dispersão geográfica e se o incidente afeta interesses financeiros ou dados pessoais?
Ronda três, reporte. O alerta precoce NIS2, a notificação NIS2 em 72 horas, o reporte DORA, a notificação RGPD da UE e os avisos contratuais a clientes são acionados? A equipa consegue documentar decisões de notificação e de não notificação?
Ronda quatro, recuperação e encerramento. Contenção, erradicação, restauro, validação de cópias de segurança, comunicações, lições aprendidas e ações corretivas estão documentadas?
O resultado não deve ser uma apresentação. Deve ser um pacote de evidência: ticket de incidente concluído, cronologia, registo de decisões, registo de comunicações, lista de evidência preservada, matriz de decisões regulatórias, registo de comunicação com fornecedores, registo de validação de recuperação e plano de ações corretivas.
O exercício não termina quando as pessoas explicam o que fariam. Termina quando produzem os registos que um auditor pediria.
Padrões comuns de falha a eliminar antes do próximo alerta
O primeiro padrão de falha é a hora de tomada de conhecimento indefinida. Se ninguém regista quando a organização tomou conhecimento, a análise temporal NIS2, DORA e RGPD da UE torna-se arriscada.
O segundo é severidade sem critérios. Rótulos como médio ou alto são fracos se não estiverem ligados a impacto no serviço, impacto nos dados, impacto financeiro, impacto em clientes ou limiares regulatórios.
O terceiro é a privacidade adicionada demasiado tarde. A avaliação RGPD da UE deve começar quando dados pessoais possam estar envolvidos, não depois de a causa raiz estar concluída.
O quarto é ambiguidade de fornecedores. Se estiver envolvido um prestador de serviços cloud, um prestador de serviços geridos ou uma integração SaaS, os contratos e playbooks devem definir quem preserva logs, quem comunica, quem apoia a análise forense e quem auxilia em pedidos de reguladores.
O quinto é a destruição de evidência durante a recuperação. Reinícios, eliminações e alterações de configuração podem ser necessários, mas devem ser coordenados com a preservação de evidência sempre que viável.
O sexto são lições aprendidas sem tratamento de riscos. A ISO/IEC 27001:2022 espera melhoria quando apropriado. Uma reunião de lições aprendidas sem alteração de controlo, proprietário, data limite ou reavaliação de risco é evidência fraca.
Transformar a resposta a incidentes num sistema de evidência de conformidade cruzada
A preparação para as expectativas de resposta a incidentes do NIST SP 800-61 e para auditorias de 2026 não deve começar com mais um playbook autónomo. Deve começar com o mapeamento de decisões.
A Clarysec pode ajudar a sua equipa a:
- Construir um Perfil Atual e um Perfil-Alvo de resposta a incidentes NIST CSF 2.0.
- Alinhar a resposta a incidentes com as cláusulas da ISO/IEC 27001:2022, o tratamento de riscos e os controlos do Anexo A.
- Incorporar nos fluxos de trabalho os requisitos de evidência NIS2 de 24 horas, 72 horas e um mês.
- Mapear a classificação de incidentes DORA, o reporte ao órgão de administração, a notificação a clientes e a evidência de fornecedores de TIC.
- Integrar a análise de violação de dados pessoais RGPD da UE e os registos de responsabilização.
- Implementar a Política de resposta a incidentes, a Política de resposta a incidentes para PME, a Política de Recolha de Evidência e Análise Forense, a Política de Recolha de Evidência e Análise Forense para PME, a Política de registo em logs e monitorização para PME, o Zenith Blueprint e o Zenith Controls da Clarysec num modelo operacional testado em exercícios de tabletop.
A pergunta para 2026 não é se a sua equipa consegue conter um ataque. A pergunta é se a sua equipa consegue classificar, escalar, reportar, recuperar e provar a resposta em NIST, ISO/IEC 27001:2022, NIS2, DORA e RGPD da UE.
O modelo de implementação de 30 passos e o toolkit de conformidade cruzada da Clarysec foram concebidos para tornar isso possível antes do próximo alerta de terça-feira de manhã. Descarregue as políticas relevantes da Clarysec, execute um exercício de tabletop orientado por prazos e solicite uma avaliação da Clarysec para transformar o seu plano de resposta a incidentes num sistema de evidência preparado para auditoria.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council