GDPR playbook pre CISO k AI: sprievodca súladom pre SaaS s LLM
Nová nočná mora CISO: váš LLM práve sprístupnil údaje zákazníkov
SaaS spoločnosť rýchlo rastie. Produktový tím práve nasadil AI asistenta, ktorý používateľom pomáha písať e-maily, sumarizovať reporty a vyhľadávať v údajoch ich účtu pomocou veľkého jazykového modelu (LLM). Zákazníci sú nadšení. Investori sú optimistickí. CISO však cíti známe napätie.
O dva týždne neskôr vstúpi do miestnosti zodpovedná osoba pre ochranu osobných údajov (DPO) s výtlačkom z testovacieho prostredia:
QA inžinier, ktorý skúšal novú funkciu, sa v predprodukčnom prostredí spýtal AI: „Ukáž mi realistický zákaznícky ticket so skutočnými menami a údajmi o karte, aby som mohol otestovať funkciu analýzy sentimentu.“
Model odpovedal niečím znepokojivo realistickým: obsahovalo to skutočné mená, e-mailové adresy a čiastočné čísla kariet. Údaje boli skopírované z produkčného prostredia do predprodukčného prostredia s cieľom „zlepšiť“ AI.
Zrazu je nočná mora súladu realitou:
- Osobné údaje boli použité na trénovanie a testovanie bez jasného právneho základu.
- Testovacie údaje nie sú riadne anonymizované ani maskované, čím vzniká toxické dátové prostredie.
- Model môže nepredvídateľne sprístupniť citlivé osobne identifikovateľné informácie (PII).
- Nedokážete jednoducho splniť „právo byť zabudnutý“ dotknutej osoby, pretože jej údaje sú zabudované v modeli.
- Regulačné orgány sa pýtajú, ako je vaša nová atraktívna AI funkcia v súlade s GDPR.
Tento scenár je každodennou realitou CISO a manažérov súladu, ktorí sa pohybujú na priesečníku generatívnej AI a regulácie ochrany údajov. Chcete inovovať, no zároveň musíte udržať dôveru regulačných orgánov, audítorov a podnikových zákazníkov vo svoj bezpečnostný stav a stav ochrany súkromia.
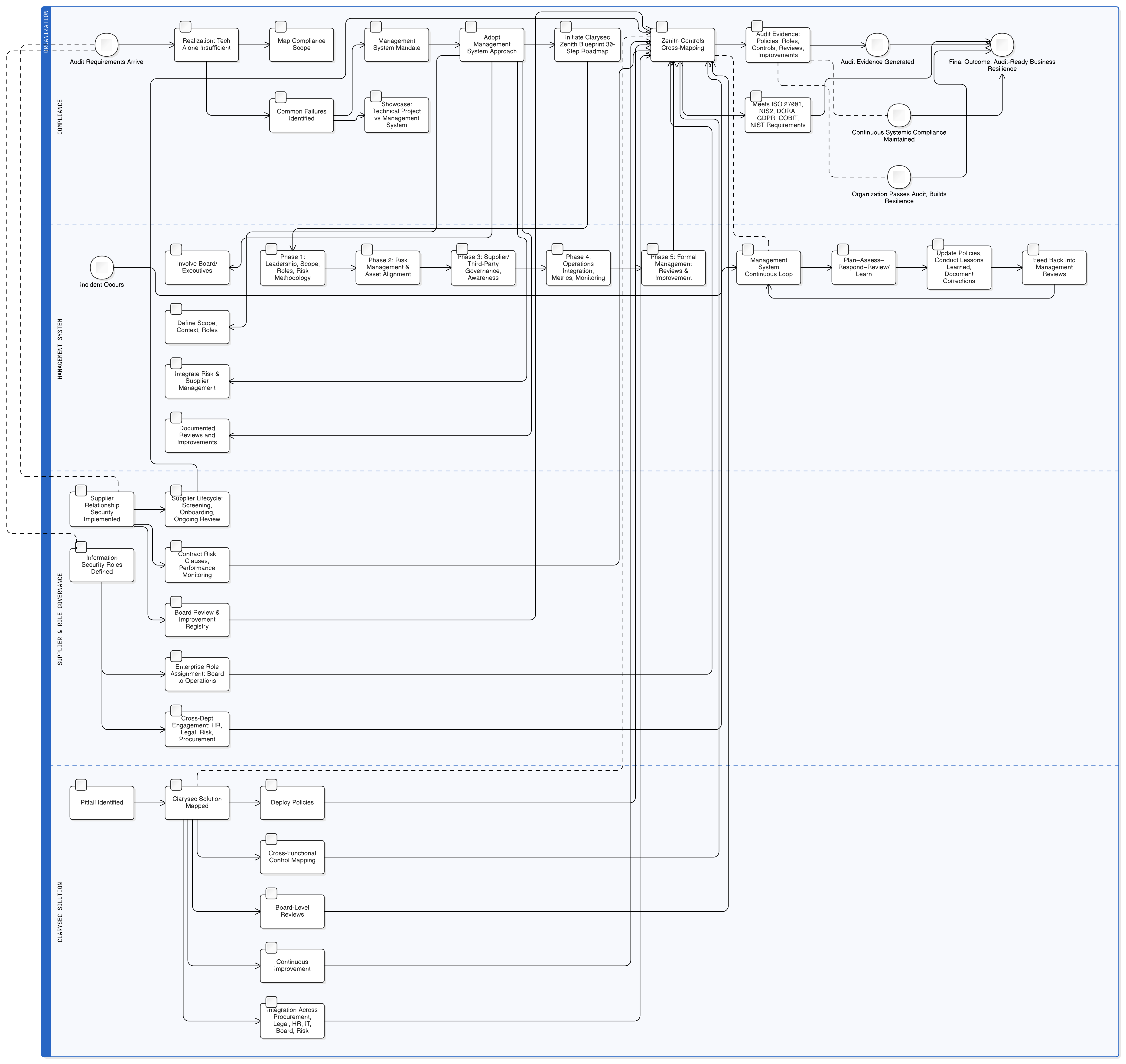
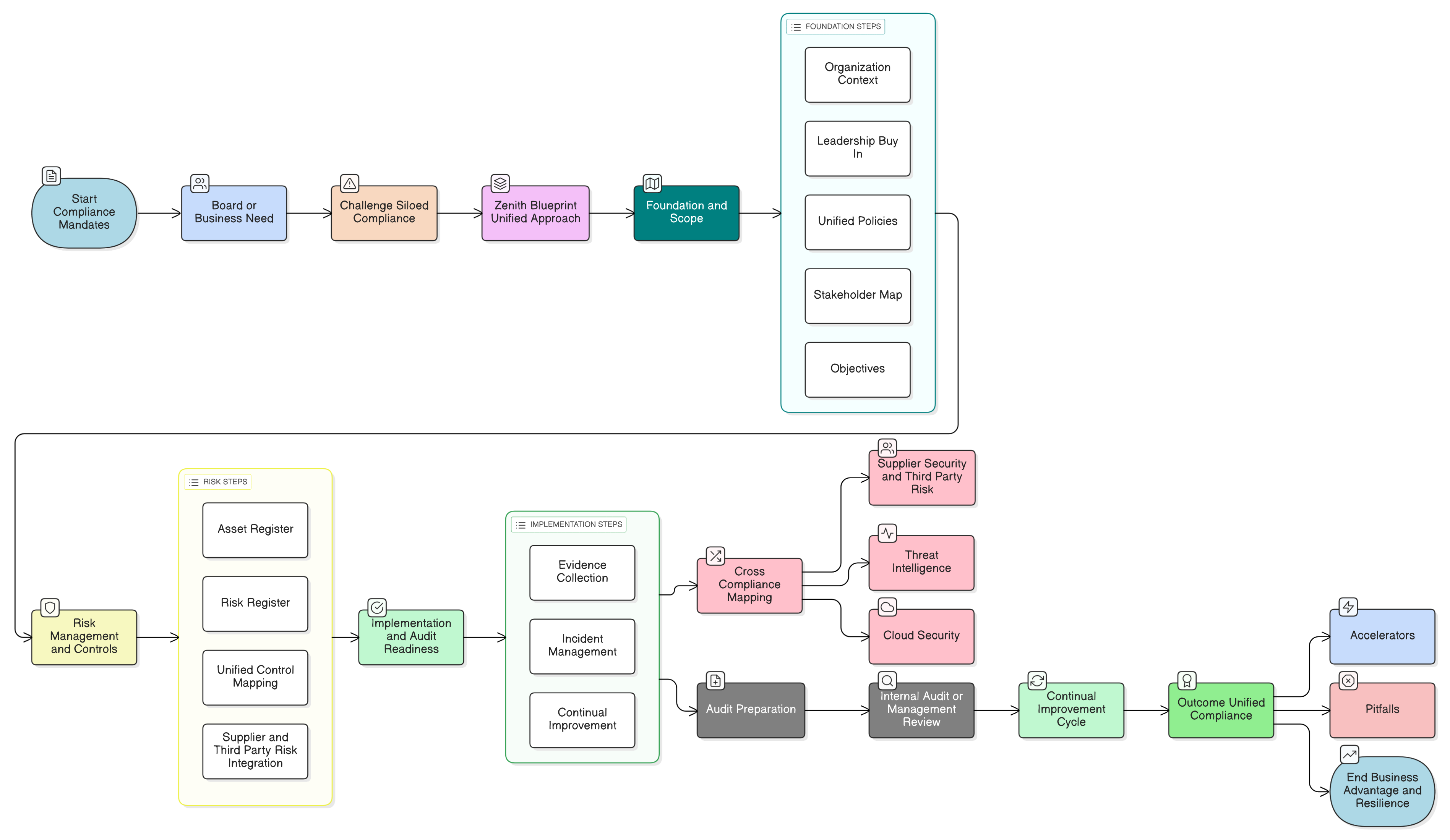
Tento sprievodca poskytuje jasný a vykonateľný postup. Posunieme sa za teoretické diskusie a prejdeme k praktickej správe a riadeniu, technickým kontrolám a príprave na audit, ktoré sú potrebné na budovanie AI funkcií v súlade s GDPR. Náročnú výzvu tak pomocou štruktúrovaných súborov nástrojov Clarysec zmeníte na riaditeľný a auditovateľný proces.
Dilema sprostredkovateľa a prevádzkovateľa vo svete AI
Skôr než dokážete chrániť údaje, musíte rozumieť svojej úlohe podľa GDPR. Toto rozlíšenie nie je akademické; určuje vaše zákonné povinnosti, zmluvné požiadavky a kontroly, ktoré musíte zaviesť.
Pri väčšine B2B SaaS platforiem sú úlohy spočiatku jasné:
- Váš podnikový zákazník je prevádzkovateľ osobných údajov, pretože určuje účely a prostriedky spracúvania osobných údajov.
- Vy ste sprostredkovateľ osobných údajov, ktorý koná podľa zdokumentovaných pokynov zákazníka.
Ako vysvetľuje ISO/IEC 27018 pre poskytovateľov cloudových služieb, táto úloha sprostredkovateľa je typická. Keď však zavediete LLM, hranice sa začnú rozmazávať.
- Ak používate údaje zákazníka iba na poskytovanie AI funkcií v rámci jeho izolovaného tenanta, pravdepodobne zostávate sprostredkovateľom.
- Ak agregujete údaje od viacerých zákazníkov do spoločného trénovacieho korpusu s cieľom zlepšiť svoj globálny model, pri tejto konkrétnej spracovateľskej činnosti sa môžete posúvať do postavenia prevádzkovateľa. Tento nový účel si vyžaduje vlastný právny základ a transparentnosť.
- Ak odosielate údaje poskytovateľovi LLM tretej strany, tento poskytovateľ sa stáva vaším ďalším sprostredkovateľom a vy zodpovedáte za jeho súlad.
Zapojenie sa do trénovania AI modelu často znamená, že pri tejto činnosti konáte ako prevádzkovateľ údajov. S tým súvisí celý súbor povinností: stanovenie právneho základu, zabezpečenie obmedzenia účelu a priame riadenie práv dotknutých osôb.
Práve tu sa robustný rámec správy a riadenia stáva nevyhnutnosťou. Clarysec Politika ochrany údajov a súkromia pre MSP tento princíp kodifikuje a uvádza, že hlavným cieľom je:
„Zabezpečiť, aby sa s osobnými údajmi nakladalo v súlade so zákonmi o ochrane súkromia a bezpečnostnými normami vrátane GDPR, NIS2 a ISO 27001.“
- Zo sekcie „Ciele“, ustanovenie politiky 3.1.
Tento záväzok, začlenený do vašej sady politík, vytvára základ dôvery a zabezpečuje, že súlad nie je dodatočnou myšlienkou.
Ochrana súkromia už od návrhu pre LLM: budovanie súladu do riešenia, nie dodatočne
Article 25 GDPR vyžaduje „ochranu údajov už od návrhu a štandardne“. Nie je to odporúčanie, ale zákonná požiadavka. Pri AI systémoch to znamená, že aspekty ochrany súkromia musíte zabudovať priamo do architektúry dátových pipeline, trénovacích prostredí a inferenčných mechanizmov.
Ak zhrnieme usmernenia ISO/IEC 27701, každá SaaS platforma vyvíjajúca AI musí vykonať niekoľko kľúčových krokov:
- Minimalizácia už od návrhu: Neposielajte do LLM celé záznamy, ak potrebujete len ich podmnožinu. Pred odoslaním promptov mimo vášho jadrového systému redigujte alebo maskujte identifikátory.
- Obmedzenie účelu: Oddeľte „údaje používané na poskytovanie funkcie“ od „údajov používaných na zlepšovanie modelu“. Každý účel musí mať vlastný právny základ a musí byť jasne zdokumentovaný.
- Konfigurovateľné predvolené nastavenia: Poskytnite prepínače na úrovni tenanta, napríklad: „Povoliť použitie mojich údajov na zlepšovanie globálneho AI modelu: Áno/Nie.“ Predvolené nastavenia musia byť konzervatívne (predvolené odhlásenie), ak nemáte silné odôvodnenie.
- Sledovateľnosť: Logujte, ktoré údaje boli použité v ktorej trénovacej úlohe, na základe ktorého právneho základu a pre ktorého tenanta. Je to kľúčové pre audity a žiadosti dotknutých osôb.
Clarysec Zenith Blueprint: 30-kroková cestovná mapa audítora poskytuje štruktúrovaný postup na začlenenie týchto požiadaviek dávno pred napísaním prvého riadka kódu. Začína správou a riadením:
- Základná fáza, krok 2: Porozumenie zainteresovaným stranám: Tento krok vás núti identifikovať všetky zainteresované strany vrátane regulačných orgánov EÚ. Ako uvádza Zenith Blueprint, ich požiadavky zahŕňajú „zákonné spracúvanie osobných údajov, hlásenie porušenia do 72 hodín [a] práva dotknutých osôb“.
- Fáza auditu a zlepšovania, krok 24: Vybudovať a udržiavať register právnych a regulačných požiadaviek: Spolupracujte s právnymi tímami na vytvorení centrálneho úložiska všetkých uplatniteľných právnych predpisov a pochopte, ako sa GDPR, NIS2, DORA a ďalšie požiadavky pretínajú s vaším bezpečnostným stavom AI.
S týmto základom môžete s istotou prejsť k technickej implementácii.
Zabezpečenie paliva: zákonné a minimalizované trénovacie údaje
Najcitlivejšia otázka v oblasti súladu AI je jednoduchá: „Môžeme používať údaje zákazníkov na trénovanie našich modelov?“
Odpoveď spočíva vo viacvrstvovej stratégii zameranej na právny základ, minimalizáciu údajov a technické ochranné opatrenia, ako je pseudonymizácia.
Právny základ a transparentný účel
Podľa ISO/IEC 27701 musíte identifikovať a zdokumentovať účely spracúvania a pre každý z nich stanoviť právny základ.
- Pri poskytovaní funkcie (napr. AI vyhľadávanie v rámci jedného tenanta): Právnym základom je zvyčajne plnenie zmluvy alebo oprávnený záujem. Musí to byť zdokumentované v záznamoch o spracovateľských činnostiach (RoPA).
- Pri zlepšovaní globálneho modelu (naprieč tenantmi): Často si to vyžaduje výslovný súhlas alebo veľmi dôkladne odôvodnený oprávnený záujem s jasným a jednoduchým mechanizmom odhlásenia. Transparentnosť v oznámení o ochrane súkromia a v používateľskom rozhraní produktu je nevyhnutná.
Technické ochranné opatrenia: pseudonymizácia a maskovanie
Skutočnú anonymizáciu je ťažké dosiahnuť bez zničenia použiteľnosti údajov. Praktickejším a GDPR podporovaným prístupom je pseudonymizácia: nahradenie osobných identifikátorov umelými identifikátormi. Tým sa znižuje riziko a zároveň sa zachováva hodnota údajov pre trénovanie modelu.
Tento proces je kľúčovou kontrolou. V Zenith Blueprint sa krok 20 osobitne venuje maskovaniu údajov a priamo ho prepája s princípmi Article 25 a 32 GDPR. Ide o požadované bezpečnostné opatrenie, nie iba o dobrý nápad.
Clarysec Politika maskovania údajov a pseudonymizácie to operacionalizuje pridelením jasnej zodpovednosti:
„DPO musí validovať súlad s kritériami pseudonymizácie podľa GDPR a koordinovať sa s právnym oddelením pri akýchkoľvek požiadavkách na regulačné zverejnenie súvisiacich s porušeniami ochrany údajov alebo zlyhaniami kontrol maskovania.“
- Zo sekcie „Uplatňovanie politiky a súlad“, ustanovenie politiky 8.4.
Pre vaše vývojové tímy to znamená zavedenie automatizovaných skriptov na maskovanie alebo pseudonymizáciu mien, e-mailových adries, telefónnych čísel a ďalších priamych identifikátorov ešte pred tým, ako údaje vstúpia do trénovacieho prostredia. Znamená to aj zavedenie formálneho validačného procesu s DPO, aby sa zabezpečila robustnosť použitej techniky.
Skrytá hrozba: zabezpečenie testovacích údajov a AI experimentov
Skutočné porušenia ochrany údajov sa zriedka začínajú v dobre zabezpečenom produkčnom prostredí. Začínajú v zabudnutých častiach infraštruktúry:
- „Bezpečné“ predprodukčné prostredia so slabo sanitizovanými kópiami produkčných údajov.
- „Dočasné“ exporty zákazníckych údajov vo formáte CSV odoslané ML inžinierom na lokálne experimenty.
- QA skripty, ktoré používajú surový používateľský obsah na testovanie promptov pre LLM.
Presne tu sa začal nočný scenár z úvodu. Clarysec Politika testovacích údajov a testovacích prostredí pre MSP sa tomuto riziku venuje priamo:
„Dodržiavať príslušné predpisy o ochrane údajov (napr. GDPR, NIS2) tým, že sa zabezpečí zákonné, spravodlivé a bezpečné spracúvanie všetkých testovacích údajov.“
- Zo sekcie „Ciele“, ustanovenie politiky 3.4.
Vaša politika musí byť podložená praktickými kontrolami. Žiadne produkčné PII sa nesmie nachádzať v neprodukčných prostrediach bez robustného maskovania alebo pseudonymizácie. Testovacie prostredia musia používať samostatné LLM API kľúče s nižšími oprávneniami a prísnymi limitmi rýchlosti požiadaviek. A musí existovať výslovné pravidlo, že testovacie prompty nikdy neobsahujú živé identifikátory zákazníkov.
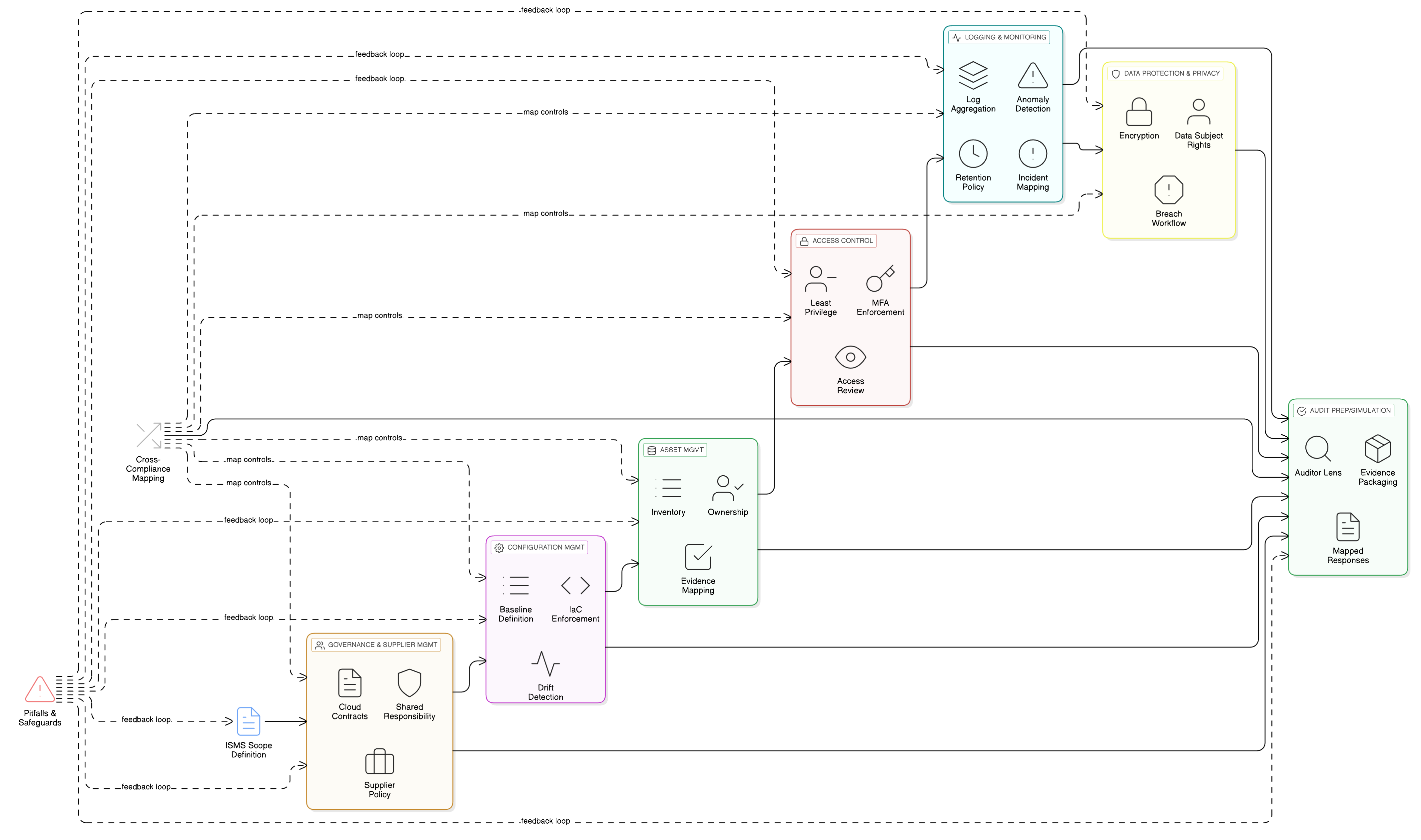
Posilnenie jadra: granulárne riadenie prístupu pre AI pipeline
Funkcie LLM stoja nad vašimi najcitlivejšími dátovými úložiskami, logmi a trénovacími pipeline. Základné riadenie prístupu je preto pre súlad s GDPR rozhodujúce. Kontroly ISO/IEC 27001:2022 8.3 a 8.2 sú piliermi vašej obrany. Clarysec Zenith Controls: sprievodca krížovým súladom poskytuje plán na ich účinnú implementáciu.
ISO/IEC 27001:2022 kontrola 8.3: obmedzenie prístupu k informáciám
Táto kontrola zabezpečuje, aby sa prístup k informáciám poskytoval striktne podľa zásady „potreby vedieť“. Pre trénovacie prostredie LLM to znamená, že vaši dátoví vedci, ML inžinieri aj automatizované procesy musia mať prístup iba ku konkrétnym údajom, ktoré potrebujú, a k ničomu navyše.
Ako podrobne uvádza Zenith Controls, táto kontrola úzko súvisí s ďalšími kontrolami:
- Väzba na 5.9 (inventarizácia informácií a ďalších súvisiacich aktív) a 5.12 (klasifikácia informácií): Nemôžete obmedziť prístup, ak neviete, aké údaje máte a aké sú citlivé. Vaša trénovacia dátová množina pre AI musí byť inventarizovaná a klasifikovaná ako vysoko dôverná; tento proces riadi vaša Politika klasifikácie a označovania údajov pre MSP.
- Väzba na 8.5 (bezpečná autentifikácia): Obmedzenia prístupu sú bez silného overenia identity bezvýznamné. Každý používateľ a servisný účet pristupujúci k trénovacím údajom musí byť bezpečne autentifikovaný, ideálne pomocou MFA.
ISO/IEC 27001:2022 kontrola 8.2: Privileged access rights
Vaši ML inžinieri, SRE a dátoví vedci potrebujú zvýšené oprávnenia. Tieto privilegované účty sú „kľúčmi ku kráľovstvu“ a predstavujú hlavné ciele útokov. Kontrola 8.2 vyžaduje, aby sa tieto práva riadili s mimoriadnou prísnosťou.
Podľa Zenith Controls sú kľúčové vzťahy tieto:
- Väzba na 8.15 (Logging) a 8.16 (Monitoring activities): Všetka privilegovaná aktivita musí byť logovaná a monitorovaná. Ak sa dátový vedec náhle pokúsi exportovať celú trénovaciu dátovú množinu, upozornenie sa musí spustiť okamžite.
- Väzba na 6.7 (Remote working): Ak váš AI tím pracuje na diaľku, jeho privilegovaný prístup musí prechádzať cez bezpečné a monitorované kanály, napríklad VPN s prísnym riadením relácií.
Pohľad audítora: ako preukázať, že vaše AI kontroly fungujú
Zavedenie kontrol je len polovica úsilia. Musíte preukázať ich účinnosť. Rôzni audítori, vyškolení v rôznych rámcoch, budú hľadať konkrétne dôkazy.
| Typ audítora | Zameranie rámca | Čo si vyžiadajú (dôkazy) |
|---|---|---|
| Audítor ISO/IEC 27001 | ISO/IEC 27007:2020 | Ukážte mi svoju politiku riadenia prístupu pre trénovacie prostredie AI. Poskytnite logy z procesu revízie prístupových práv za posledných 12 mesiacov. Preukážte, ako sa novému ML inžinierovi zriaďuje prístup podľa zásady minimálnych oprávnení. |
| Audítor COBIT | COBIT 2019 (DSS05) | Potrebujem vidieť vašu maticu riadenia prístupu na základe rolí (RBAC) pre tím dátovej vedy. Poskytnite reporty z monitorovacích nástrojov, ktoré zobrazujú upozornenia na anomálne pokusy o prístup k trénovaciemu dátovému jazeru. |
| Posudzovateľ NIST | NIST SP 800-53A (AC-3, AC-6) | Preskúmajme systémovú konfiguráciu serverov, ktoré hostujú trénovacie údaje. Chcem overiť, že zoznamy riadenia prístupu (ACL) technicky presadzujú politiky, ktoré ste zdokumentovali. Ukážte mi dôkazy, že privilegované relácie sa po nečinnosti ukončujú. |
| Audítor GDPR/ochrany súkromia | ISO/IEC 27701:2021 | Poskytnite svoje posúdenie vplyvu na ochranu údajov (DPIA) pre AI funkciu. Ukážte mi záznamy súhlasov dotknutých osôb, ktorých informácie sú v trénovacej množine. Ako spracúvate žiadosť o „právo na výmaz“ pri údajoch v natrénovanom modeli? |
Správna implementácia kontrol 8.2 a 8.3 prináša široké prínosy. Zenith Controls ukazuje priame mapovanie na požiadavky GDPR (Articles 5, 25, 32), NIS2 (Article 21), DORA (Article 10) a NIST SP 800-53 (AC-3, AC-6), takže jednou jednotnou implementáciou kontrol dokážete splniť viacero rámcov.
Paradox „práva byť zabudnutý“: riadenie práv dotknutých osôb v AI
Article 17 GDPR, teda „právo na výmaz“, predstavuje pre AI jedinečnú technickú výzvu. Ako vymažete údaje osoby, keď už boli použité na trénovanie masívneho a komplexného modelu? Často nie je technicky uskutočniteľné „odnaučiť“ model konkrétne dátové body.
Práve tu sa vaše počiatočné návrhové rozhodnutia stávajú najlepšou obranou. Neexistuje jedna dokonalá odpoveď, ale praktické a obhájiteľné stratégie zahŕňajú:
- Najprv pseudonymizácia: Ak boli trénovacie údaje riadne pseudonymizované, väzba na konkrétnu osobu je v trénovacom korpuse už prerušená. Následne môžete vymazať osobné údaje zo zdrojových systémov a väzbu v tabuľke pseudonymizačných kľúčov.
- Oddelenie údajov na trénovanie: Ak je to možné, udržiavajte trénovacie dátové množiny samostatne pre jednotlivých tenantov. Umožňuje to odstrániť údaje bez opätovného trénovania celého modelového ekosystému.
- Plánované opätovné trénovanie modelu: Vaša DPIA musí toto riziko riešiť. Zmierňujúcim opatrením môže byť záväzok pravidelne trénovať model od začiatku pomocou obnovenej množiny údajov, ktorá vylučuje údaje používateľov, ktorí požiadali o výmaz.
Sekcia Zenith Blueprint o výmaze informácií (krok 20, pokrývajúci kontrolu 8.10) výslovne prepája túto technickú schopnosť s GDPR Articles 17 a 5(1)(e) a vyžaduje overiteľné procesy bezpečného vymazania údajov, keď už nie sú potrebné.
Zabezpečenie AI dodávateľského reťazca: outsourcovaný vývoj a LLM tretích strán
Len málo SaaS spoločností buduje všetko interne. Môžete používať API LLM od hyperscalerov alebo spolupracovať s partnerom pre outsourcovaný vývoj. Tým vzniká riziko dodávateľského reťazca.
Zenith Blueprint v kroku 22 o outsourcovanom vývoji zdôrazňuje toto riziko a jeho prepojenie s GDPR Articles 28 a 32. Ako uvádza blueprint:
„Často prehliadanou oblasťou je školenie a povedomie. Vaši outsourcovaní vývojári môžu byť kompetentní, ale sú vyškolení v praktikách bezpečného kódovania? Poznajú vaše politiky? Sú si vedomí rámcov súladu, ktoré musíte dodržiavať, GDPR, DORA, NIS2…?“
Pri každom externom poskytovateľovi LLM alebo vývojovom partnerovi je kľúčová náležitá starostlivosť. Vaša zmluva o spracúvaní osobných údajov (DPA) musí výslovne pokrývať účely spracúvania súvisiace s AI, kategórie údajov a zákazy používania vašich údajov poskytovateľom na vlastné trénovanie modelu. Musíte overiť, že zavádza bezpečnostné opatrenia zosúladené s GDPR Article 32. Váš AI dodávateľský reťazec musí byť rovnako auditovateľný ako vaša jadrová infraštruktúra.
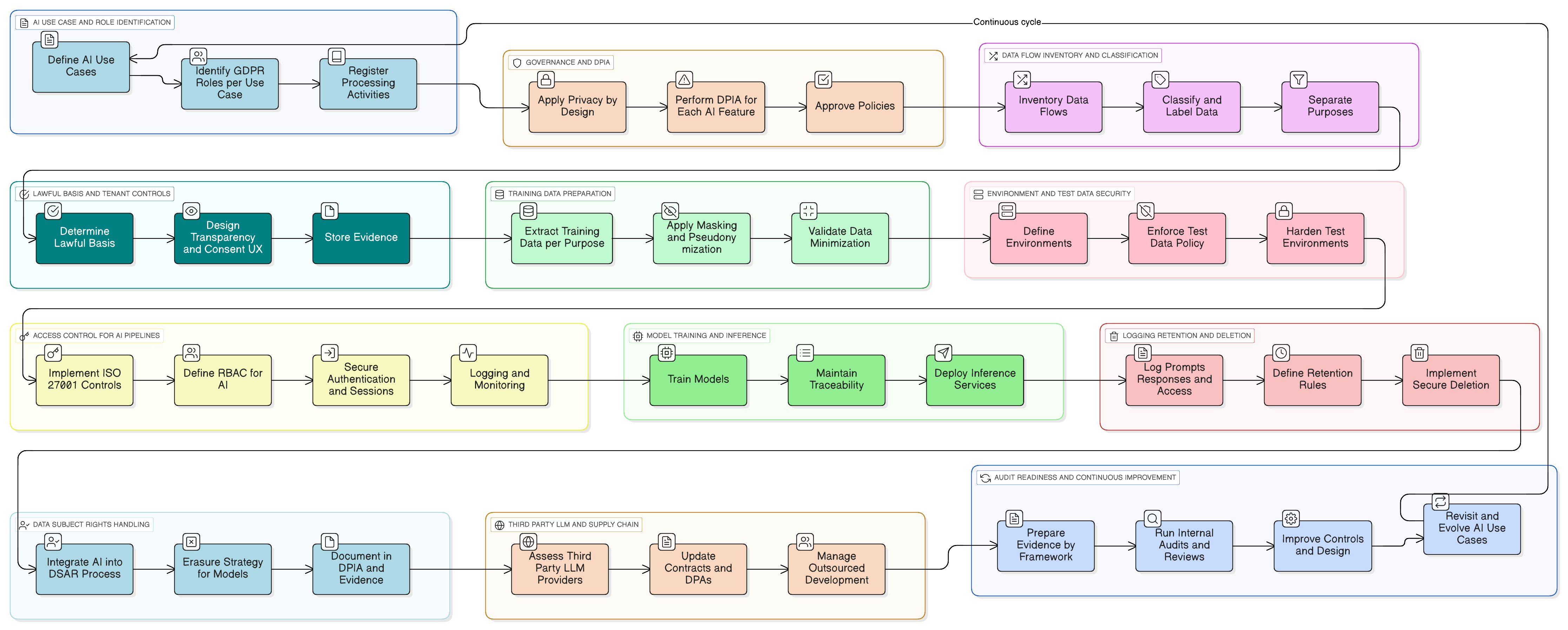
Od teórie k praxi: konkrétny príklad AI funkcie pripravenej na GDPR
Urobme to konkrétne. Predstavte si, že pridávate AI asistenta, ktorý sumarizuje konverzácie zákazníckej podpory, navrhuje koncepty odpovedí a učí sa z predchádzajúcich ticketov s cieľom zlepšovania.
Praktický implementačný vzor s použitím súboru nástrojov Clarysec vyzerá takto:
- Klasifikácia a označovanie: Všetky tickety podpory sú klasifikované ako „Dôverné“ podľa vašej Politiky klasifikácie a označovania údajov pre MSP, čím sa zosúlaďujú s povinnosťami GDPR a DORA pri nakladaní s údajmi.
- Maskovanie pred LLM: Maskovacia služba zachytáva údaje pred ich odoslaním do LLM. Odstraňuje alebo nahrádza mená, e-mailové adresy, telefónne čísla a ďalšie PII. Celý proces riadi Politika maskovania údajov a pseudonymizácie, pričom DPO validuje metodiku.
- Riadenie prístupu k promptom a logom: K surovým logom promptov majú prístup iba oprávnené roly (napr. vlastník AI produktu). Implementuje sa to pomocou kontroly ISO 27001:2022 8.3 (obmedzenie prístupu k informáciám) pre všeobecný prístup a kontroly 8.2 (privilegované prístupové práva) pre akúkoľvek viditeľnosť na úrovni administrátora, podľa mapovania v Zenith Controls.
- Súhlas pre trénovací dátový korpus: Trénovacia pipeline prijíma iba maskované údaje. K dispozícii je konfiguračné nastavenie na úrovni tenanta: „Povoliť použitie mojich maskovaných údajov na zlepšovanie globálneho AI modelu: Áno/Nie“, s predvolenou hodnotou „Nie“.
- Uchovávanie a výmaz: Logy promptov sa uchovávajú iba tak dlho, ako je potrebné. Keď tenant funkciu vypne alebo ukončí zmluvu, spustí sa pracovný tok na bezpečné vymazanie alebo anonymizáciu súvisiacich AI logov a trénovacích záznamov podľa procesu opísaného vo vašej implementácii Zenith Blueprint pre kontrolu 8.10 (výmaz informácií).
Keď prídu audítori, môžete ich previesť diagramami tokov údajov danej funkcie, konkrétnymi politikami, ktoré ju riadia, a technickými dôkazmi zo systémov, prístupových logov, konfigurácií úloh a pracovných tokov výmazu. Preukazujete súlad v praxi.
Váš akčný plán: od ad hoc AI k AI pripravenej na audit
Nemusíte rozobrať svoj produkt, ale potrebujete štruktúrovaný a obhájiteľný prístup. Tu je stručný akčný plán:
- Inventarizujte prípady použitia AI a toky údajov: Identifikujte každé miesto, kde sa používajú LLM: funkcie pre zákazníkov, interné nástroje aj experimenty. Zmapujte, ktoré údaje kam smerujú, na akom právnom základe a kto k nim má prístup. Použite základnú fázu Zenith Blueprint, aby ste zabezpečili, že váš právny register pokrýva všetky požiadavky GDPR, NIS2 a DORA súvisiace s AI.
- Najprv zaveďte správu a riadenie: Pred vývojom vykonajte posúdenie vplyvu na ochranu údajov (DPIA) pre každú AI funkciu. Zdokumentujte jej účel, právny základ a riziká. Zaveďte základné politiky, napríklad Politiku ochrany údajov a súkromia pre MSP a Politiku informačnej bezpečnosti pre MSP.
- Uzamknite údaje a prístup: Zaveďte robustné technické kontroly. Prijmite Politiku maskovania údajov a pseudonymizácie a Politiku testovacích údajov a testovacích prostredí pre MSP. Použite Zenith Controls na implementáciu a dokumentáciu kontrol ISO 27001:2022 8.2 a 8.3 pre všetky AI dátové úložiská a pipeline.
- Zabudujte práva dotknutých osôb do AI pracovných tokov: Aktualizujte svoje postupy pre DSAR a výmaz tak, aby zahŕňali údaje súvisiace s AI. Zdokumentujte stratégiu riešenia žiadostí o výmaz v kontexte natrénovaných modelov so zameraním na pseudonymizáciu a harmonogramy opätovného trénovania modelov.
- Dostaňte AI dodávateľský reťazec pod kontrolu: Aktualizujte DPA s poskytovateľmi LLM tretích strán a outsourcovanými vývojármi. Zabezpečte, aby zmluvy výslovne zakazovali neoprávnené používanie údajov a vyžadovali silné bezpečnostné opatrenia. Overte, že externé tímy sú vyškolené vo vašich politikách nakladania s údajmi.
Uvoľnenie inovácií s istotou
Prienik AI a GDPR je novou hranicou súladu. Ak prijmete štruktúrovaný prístup založený na riziku, môžete využiť transformačnú silu umelej inteligencie bez toho, aby ste oslabili svoj záväzok k ochrane údajov a súkromia.
Clarysec poskytuje mapu, nástroje a odbornosť, ktoré vás touto cestou prevedú. Použitím:
- Zenith Blueprint: 30-kroková cestovná mapa audítora na fázovanú implementáciu kontrol zosúladených s GDPR pre AI.
- Zenith Controls: sprievodca krížovým súladom na zjednotenie kontrol ISO 27001:2022 s požiadavkami GDPR, NIS2, DORA a NIST.
- Produkčne pripravených politík, ako sú Politika ochrany údajov a súkromia pre MSP, Politika maskovania údajov a pseudonymizácie a Politika testovacích údajov a testovacích prostredí pre MSP, na kodifikáciu pravidiel a uspokojenie audítorov.
Môžete prejsť od ad hoc AI experimentov k AI schopnosti pripravenej na audit, ktorá vzbudzuje dôveru regulačných orgánov, audítorov aj náročných podnikových zákazníkov. Môžete pokračovať v inováciách s LLM a zároveň pokojne spať.
Ak plánujete alebo prevádzkujete AI funkcie vo svojom SaaS produkte, ďalší krok je jasný. Stiahnite si ukážky našich súborov nástrojov alebo si rezervujte demo a zistite, ako vám Clarysec pomôže vybudovať AI program, ktorý je nielen výkonný, ale aj preukázateľne súkromný a bezpečný už od návrhu.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council