Priročnik CISO za GDPR pri umetni inteligenci: vodnik za skladnost SaaS z LLM
Nova nočna mora CISO: vaš LLM je pravkar razkril podatke strank
Podjetje SaaS hitro raste. Produktna ekipa je pravkar uvedla pomočnika z umetno inteligenco, ki uporabnikom pomaga pripravljati e-poštna sporočila, povzemati poročila in iskati po podatkih njihovih računov z uporabo velikega jezikovnega modela (LLM). Stranke so navdušene. Vlagatelji so optimistični. CISO pa čuti znan občutek nelagodja.
Dva tedna pozneje pooblaščena oseba za varstvo podatkov (DPO) vstopi v sobo z izpisom iz testnega okolja:
Inženir za zagotavljanje kakovosti je pri testiranju nove funkcionalnosti v pripravljalnem okolju vprašal umetno inteligenco: »Prikaži mi realističen zahtevek stranke z resničnimi imeni in podatki o kartici, da lahko testiram funkcijo analize sentimenta.«
Model je odgovoril z nečim zaskrbljujoče realističnim, kar je vsebovalo dejanska imena, e-poštne naslove in delne številke kartic. Podatki so bili kopirani iz produkcije v pripravljalno okolje, da bi »izboljšali« umetno inteligenco.
Naenkrat je nočna mora skladnosti resnična:
- Osebni podatki so bili uporabljeni za učenje in testiranje brez jasne pravne podlage.
- Testni podatki niso ustrezno anonimizirani ali maskirani, kar ustvarja tvegano podatkovno okolje.
- Model lahko na nepredvidljive načine razkrije občutljive osebno določljive podatke (PII).
- »Pravice do pozabe« posameznika, na katerega se nanašajo osebni podatki, ne morete enostavno izpolniti, ker so njegovi podatki vgrajeni v model.
- Regulatorji sprašujejo, kako je vaša nova funkcionalnost umetne inteligence skladna z GDPR.
Ta scenarij je vsakodnevna realnost za CISO in vodje skladnosti, ki se ukvarjajo s trkom generativne umetne inteligence in predpisov o varstvu podatkov. Želite inovirati, vendar morate ohraniti zaupanje regulatorjev, revizorjev in poslovnih strank v svoj profil tveganja na področju varnosti in zasebnosti.
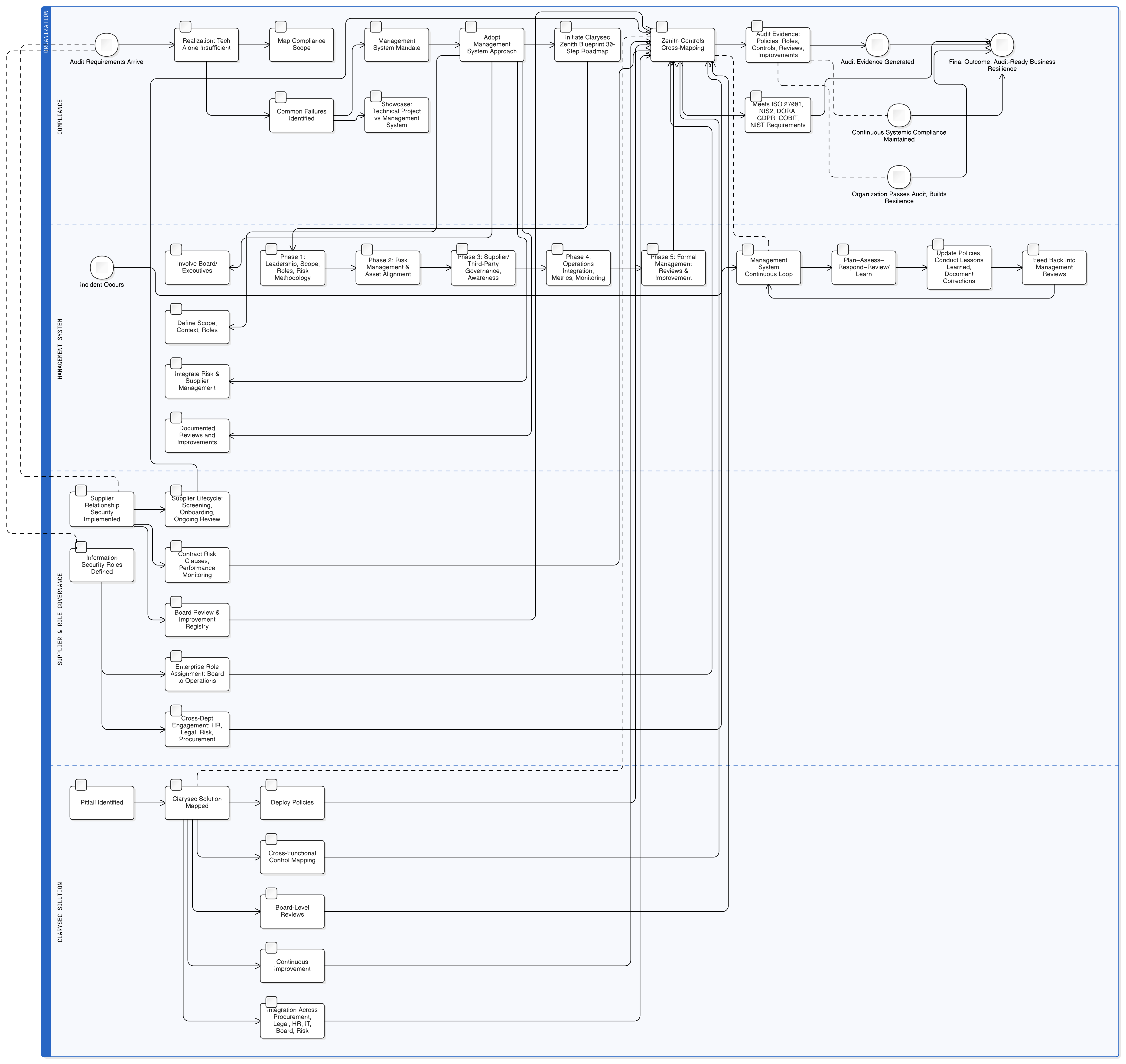
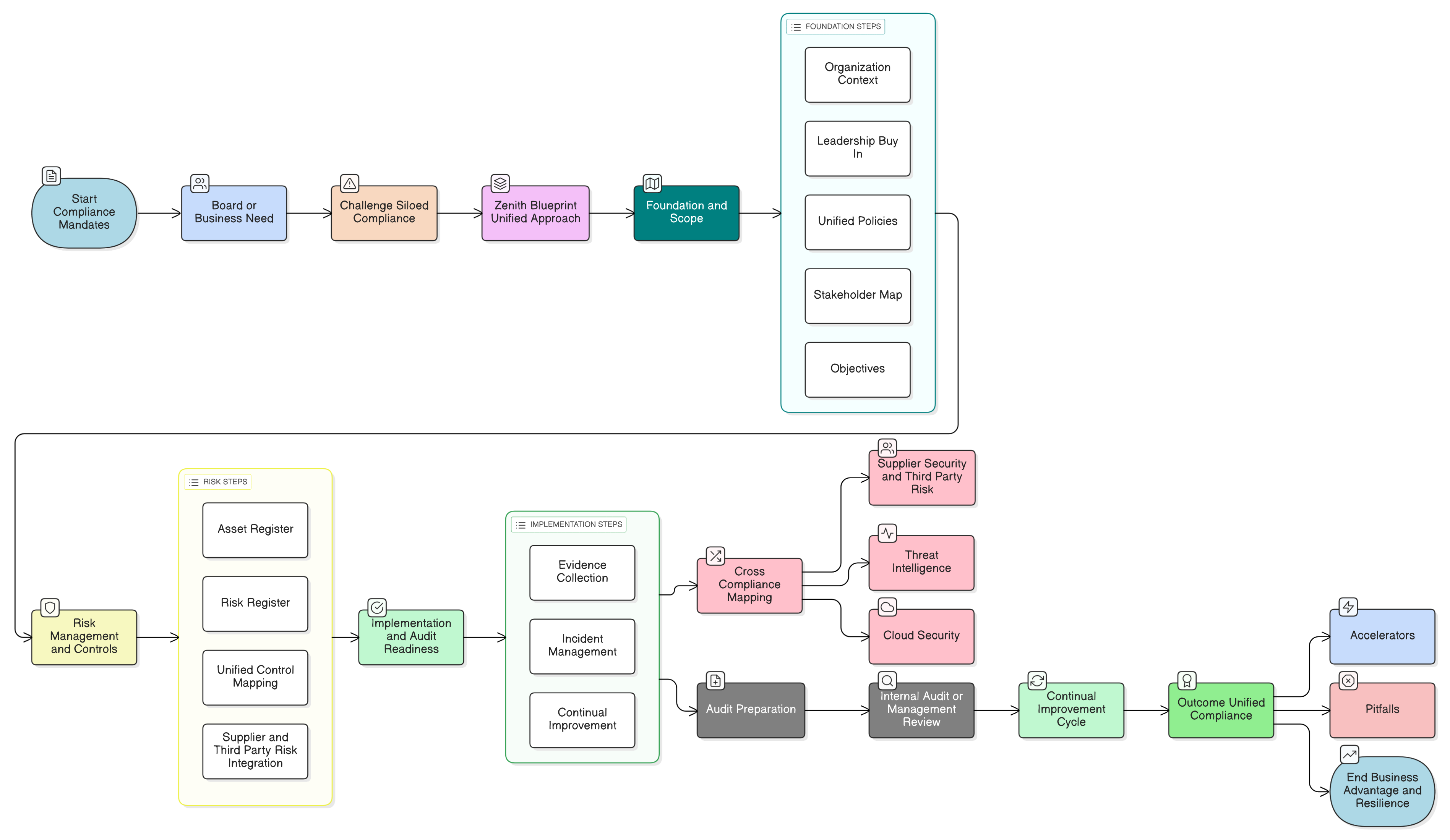
Ta vodnik ponuja jasno in izvedljivo pot naprej. Presegli bomo teoretične razprave ter se osredotočili na praktično upravljanje, tehnične kontrole in pripravo na revizijo, potrebno za gradnjo funkcionalnosti umetne inteligence, skladnih z GDPR. Zahteven izziv bomo preoblikovali v obvladljiv, preverljiv proces z uporabo strukturiranih naborov orodij Clarysec.
Dilema obdelovalec–upravljavec v svetu umetne inteligence
Preden lahko zaščitite podatke, morate razumeti svojo vlogo po GDPR. Ta razlika ni akademska; določa vaše zakonske obveznosti, pogodbene zahteve in kontrole, ki jih morate uvesti.
Pri večini B2B platform SaaS so vloge sprva jasne:
- Vaša poslovna stranka je upravljavec osebnih podatkov, saj določa namene in sredstva obdelave osebnih podatkov.
- Vi ste obdelovalec osebnih podatkov, ki ravna po dokumentiranih navodilih svoje stranke.
Kot ISO/IEC 27018 pojasnjuje za ponudnike storitev v oblaku, je ta vloga obdelovalca običajna. Ko pa uvedete LLM, se meje zabrišejo.
- Če podatke stranke uporabljate samo za zagotavljanje funkcionalnosti umetne inteligence znotraj njenega izoliranega najemnika, najverjetneje ostajate obdelovalec.
- Če podatke več strank združujete v skupni učni korpus za izboljšanje svojega globalnega modela, se lahko pri tej specifični dejavnosti obdelave premaknete na področje upravljavca. Ta novi namen zahteva lastno pravno podlago in preglednost.
- Če podatke posredujete zunanjemu ponudniku LLM, ta ponudnik postane vaš podobdelovalec, vi pa ste odgovorni za njegovo skladnost.
Učenje modela umetne inteligence pogosto pomeni, da za to dejavnost nastopate kot upravljavec osebnih podatkov, kar prinaša številne obveznosti: določitev pravne podlage, zagotavljanje omejitve namena in neposredno upravljanje pravic posameznikov, na katere se nanašajo osebni podatki.
Tu postane zanesljiv okvir upravljanja nujen. Clarysecova Politika varstva podatkov in zasebnosti za MSP kodificira to načelo in kot osrednji cilj določa:
»Zagotoviti ravnanje z osebnimi podatki v skladu z zakonodajo o zasebnosti in varnostnimi standardi, vključno z GDPR, NIS2 in ISO 27001.«
- Iz razdelka »Cilji«, klavzula politike 3.1.
Ta zaveza, vgrajena v vaš sklop politik, postavlja temelje za gradnjo zaupanja in zagotavlja, da skladnost ni naknadna misel.
Privacy by design za LLM: skladnost vgradite, ne dodajajte
GDPR Article 25 zahteva »vgrajeno in privzeto varstvo podatkov«. To ni priporočilo, temveč zakonska zahteva. Za sisteme umetne inteligence to pomeni, da morate vidike zasebnosti neposredno vgraditi v arhitekturo svojih podatkovnih tokov, učnih okolij in mehanizmov sklepanja.
Če povzamemo usmeritve iz ISO/IEC 27701, to za vsako platformo SaaS, ki razvija umetno inteligenco, vključuje več ključnih ukrepov:
- Minimizacija že pri načrtovanju: Celotnih zapisov ne pošiljajte v LLM, če potrebujete samo njihov del. Identifikatorje zakrijte ali maskirajte, preden pozivi zapustijo vaš ključni sistem.
- Omejitev namena: Ločite »podatke, uporabljene za izvajanje funkcionalnosti«, od »podatkov, uporabljenih za izboljšanje modela«. Vsak namen mora imeti lastno pravno podlago in biti jasno dokumentiran.
- Privzete nastavitve: Omogočite nastavitve na ravni najemnika, kot je: »Dovolim uporabo svojih podatkov za izboljšanje globalnega modela umetne inteligence: Da/Ne.« Privzete vrednosti morajo biti konservativne (privzeto brez sodelovanja), razen če imate trdno utemeljitev.
- Sledljivost: Beležite, kateri podatki so bili uporabljeni v katerem učnem opravilu, na kateri pravni podlagi in za katerega najemnika. To je ključno za revizije in zahteve posameznikov, na katere se nanašajo osebni podatki.
Clarysecov Zenith Blueprint: 30-stopenjski revizijski časovni načrt ponuja strukturirano pot za vgradnjo teh zahtev veliko prej, preden napišete prvo vrstico kode. Začne se z upravljanjem:
- Temeljna faza, korak 2: razumevanje zainteresiranih strani: Ta korak vas prisili, da identificirate vse zainteresirane strani, vključno z regulatorji EU. Kot navaja Zenith Blueprint, njihove zahteve vključujejo »zakonito obdelavo osebnih podatkov, poročanje o kršitvah v 72 urah [in] pravice posameznikov, na katere se nanašajo osebni podatki«.
- Faza revizije in izboljšav, korak 24: vzpostavitev in vzdrževanje evidence pravnih in regulativnih zahtev: S pravno službo vzpostavite centralni repozitorij vseh veljavnih predpisov ter razumite, kako se GDPR, NIS2, DORA in drugi okviri prepletajo z vašim profilom tveganja na področju varnosti umetne inteligence.
S tem temeljem lahko samozavestno preidete na tehnično izvedbo.
Varovanje goriva: zakoniti in minimalni podatki za učenje
Najbolj zahtevno vprašanje pri skladnosti umetne inteligence je preprosto: »Ali lahko podatke strank uporabimo za učenje svojih modelov?«
Odgovor je v večplastni strategiji, osredotočeni na pravno podlago, minimizacijo podatkov in tehnične zaščitne ukrepe, kot je psevdonimizacija.
Pravna podlaga in pregleden namen
V skladu z ISO/IEC 27701 morate opredeliti in dokumentirati namene obdelave ter za vsakega določiti pravno podlago.
- Za izvajanje funkcionalnosti (npr. iskanje z umetno inteligenco znotraj enega najemnika): Pravna podlaga je običajno izvajanje pogodbe ali zakoniti interes. To mora biti dokumentirano v vaši evidenci dejavnosti obdelave (RoPA).
- Za izboljšanje globalnega modela (med najemniki): To pogosto zahteva izrecno privolitev ali zelo skrbno utemeljen zakoniti interes z jasnim in enostavnim mehanizmom zavrnitve sodelovanja. Preglednost v obvestilu o zasebnosti in uporabniškem vmesniku produkta je obvezna.
Tehnični zaščitni ukrepi: psevdonimizacija in maskiranje
Pravo anonimizacijo je težko doseči, ne da bi uničili uporabnost podatkov. Bolj praktičen pristop, ki ga GDPR podpira, je psevdonimizacija: zamenjava osebnih identifikatorjev z umetnimi. S tem se tveganje zmanjša, vrednost podatkov za učenje modela pa se ohrani.
Ta proces je ključna kontrola. V Zenith Blueprint korak 20 posebej obravnava maskiranje podatkov in ga neposredno povezuje z načeli GDPR Article 25 in 32. Gre za zahtevan varnostni ukrep, ne zgolj za dobro prakso.
Clarysecova Politika maskiranja podatkov in psevdonimizacije to operacionalizira z jasno dodelitvijo odgovornosti:
»DPO mora preveriti skladnost z merili GDPR za psevdonimizacijo ter se s pravno službo uskladiti glede vseh zahtev za regulativno razkritje, povezanih s kršitvami varstva podatkov ali odpovedmi kontrol maskiranja.«
- Iz razdelka »Uveljavljanje in skladnost«, klavzula politike 8.4.
Za vaše razvojne ekipe to pomeni uvedbo avtomatiziranih skript za maskiranje ali psevdonimizacijo imen, e-poštnih naslovov, telefonskih številk in drugih neposrednih identifikatorjev, preden podatki sploh vstopijo v učno okolje. Pomeni tudi vzpostavitev formalnega postopka preverjanja z DPO, da se zagotovi robustnost tehnike.
Skrita grožnja: varovanje testnih podatkov in eksperimentov z umetno inteligenco
Resnične kršitve varstva podatkov se redko začnejo v urejenem, utrjenem produkcijskem okolju. Začnejo se v pozabljenih delih infrastrukture:
- »Varna« pripravljalna okolja s slabo sanitiziranimi kopijami produkcijskih podatkov.
- »Začasni« izvozi CSV podatkov strank, poslani inženirjem strojnega učenja za lokalne eksperimente.
- Skripte za zagotavljanje kakovosti, ki za testiranje pozivov LLM uporabljajo surovo uporabniško vsebino.
Prav tu se je začel scenarij nočne more iz uvoda. Clarysecova Politika testnih podatkov in testnega okolja za MSP neposredno naslavlja to tveganje:
»Upoštevati relevantne predpise o varstvu podatkov (npr. GDPR, NIS2) z zagotavljanjem, da se vsi testni podatki obdelujejo zakonito, pošteno in varno.«
- Iz razdelka »Cilji«, klavzula politike 3.4.
Vašo politiko morajo podpirati praktične kontrole. Produkcijski PII ne sme nikoli obstajati v neprodukcijskih okoljih brez robustnega maskiranja ali psevdonimizacije. Testna okolja morajo uporabljati ločene ključe API za LLM z nižjimi privilegiji in strogimi omejitvami hitrosti zahtevkov. Izrecno pravilo mora biti tudi, da testni pozivi nikoli ne vključujejo živih identifikatorjev strank.
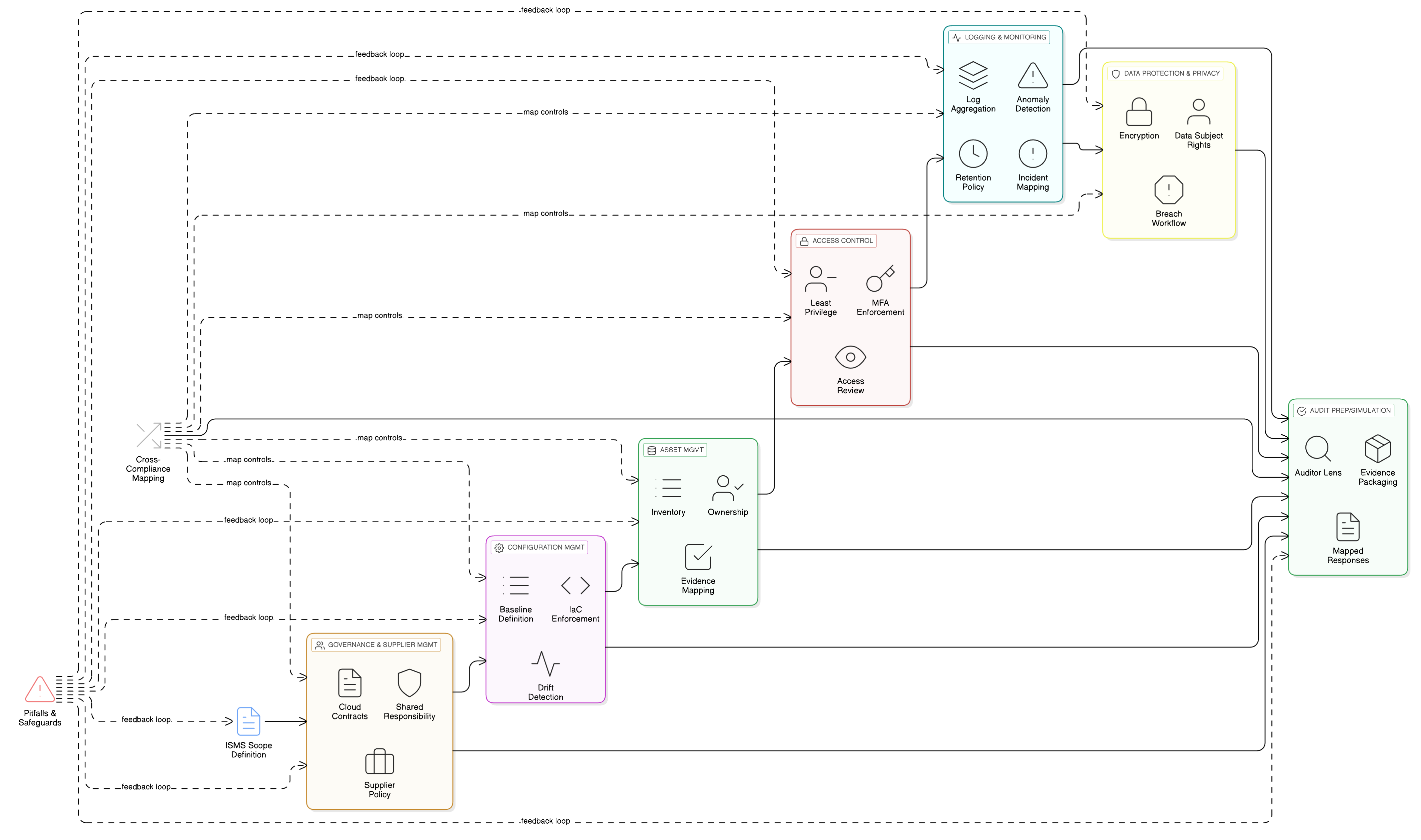
Utrjevanje jedra: granularni nadzor dostopa za cevovode umetne inteligence
Funkcionalnosti LLM delujejo nad vašimi najobčutljivejšimi shrambami podatkov, dnevniki in učnimi cevovodi. Temeljni nadzor dostopa je zato ključen za skladnost z GDPR. Kontroli ISO/IEC 27001:2022 8.3 in 8.2 sta stebra vaše obrambe. Clarysecov Zenith Controls: vodnik za skladnost med okviri ponuja načrt za njuno učinkovito uvedbo.
Kontrola ISO/IEC 27001:2022 8.3: omejitev dostopa do informacij
Ta kontrola zagotavlja, da se dostop do informacij dodeljuje strogo po načelu »potrebe po seznanitvi«. Za učno okolje LLM to pomeni, da morajo vaši podatkovni znanstveniki, inženirji strojnega učenja in sami avtomatizirani procesi imeti dostop samo do specifičnih podatkov, ki jih potrebujejo, in ničesar več.
Kot podrobno opisuje Zenith Controls, je to tesno povezano z drugimi kontrolami:
- Povezava s 5.9 (popis informacij in drugih povezanih sredstev) in 5.12 (razvrščanje informacij): Dostopa ne morete omejiti, če ne veste, katere podatke imate in kako občutljivi so. Vaš podatkovni niz za učenje umetne inteligence mora biti evidentiran in razvrščen kot visoko zaupen, ta proces pa ureja vaša Politika klasifikacije in označevanja podatkov za MSP.
- Povezava z 8.5 (varna avtentikacija): Omejitve dostopa so brez pomena brez močnega preverjanja identitete. Vsak uporabnik in storitveni račun, ki dostopa do podatkov za učenje, mora biti varno avtenticiran, po možnosti z MFA.
Kontrola ISO/IEC 27001:2022 8.2: pravice privilegiranega dostopa
Vaši inženirji strojnega učenja, inženirji SRE in podatkovni znanstveniki potrebujejo povišan dostop. Ti privilegirani računi so »ključi kraljestva« in glavne tarče. Kontrola 8.2 zahteva, da se te pravice upravljajo z izjemno strogostjo.
Po Zenith Controls so ključne povezave naslednje:
- Povezava z 8.15 (beleženje) in 8.16 (spremljanje dejavnosti): Vsa privilegirana dejavnost mora biti zabeležena in spremljana. Če podatkovni znanstvenik nenadoma poskuša izvoziti celoten podatkovni niz za učenje, se mora opozorilo sprožiti takoj.
- Povezava s 6.7 (delo na daljavo): Če vaša ekipa za umetno inteligenco dela na daljavo, mora biti njen privilegirani dostop speljan prek varnih, spremljanih kanalov, kot je VPN s strogim nadzorom sej.
Revizorjev pogled: kako dokazati, da vaše kontrole umetne inteligence delujejo
Uvedba kontrol je le polovica naloge. Dokazati morate njihovo učinkovitost. Različni revizorji, usposobljeni za različne okvire, bodo iskali specifična dokazila.
| Vrsta revizorja | Poudarek okvira | Kaj bodo zahtevali (dokazila) |
|---|---|---|
| Revizor ISO/IEC 27001 | ISO/IEC 27007:2020 | Pokažite mi svojo politiko nadzora dostopa za učno okolje umetne inteligence. Predložite dnevnike iz procesa pregledov pravic dostopa za zadnjih 12 mesecev. Prikažite, kako se novemu inženirju strojnega učenja dodeli dostop po načelu najmanjših privilegijev. |
| Revizor COBIT | COBIT 2019 (DSS05) | Potrebujem matriko nadzora dostopa na podlagi vlog (RBAC) za ekipo podatkovne znanosti. Predložite poročila iz orodij za spremljanje, ki prikazujejo opozorila za anomalne poskuse dostopa do podatkovnega jezera za učenje. |
| Ocenjevalec NIST | NIST SP 800-53A (AC-3, AC-6) | Preglejmo konfiguracijo sistemov za strežnike, ki gostijo podatke za učenje. Želim preveriti, da seznami za nadzor dostopa (ACL) tehnično uveljavljajo politike, ki ste jih dokumentirali. Pokažite mi dokazila, da se privilegirane seje po neaktivnosti prekinejo. |
| Revizor GDPR/zasebnosti | ISO/IEC 27701:2021 | Predložite oceno učinka v zvezi z varstvom podatkov (DPIA) za funkcionalnost umetne inteligence. Pokažite mi evidence privolitev posameznikov, na katere se nanašajo osebni podatki in katerih informacije so v učnem naboru. Kako obdelate zahtevo za »pravico do izbrisa« za podatke v naučenem modelu? |
Pravilna uvedba kontrol 8.2 in 8.3 prinaša široke koristi. Zenith Controls prikazuje neposredno preslikavo na zahteve v GDPR (Articles 5, 25, 32), NIS2 (Article 21), DORA (Article 10) in NIST SP 800-53 (AC-3, AC-6), kar vam omogoča izpolnjevanje več okvirov z eno, poenoteno izvedbo kontrol.
Paradoks »pravice do pozabe«: upravljanje pravic posameznikov, na katere se nanašajo osebni podatki, v umetni inteligenci
GDPR Article 17, »pravica do izbrisa«, predstavlja edinstven tehnični izziv za umetno inteligenco. Kako izbrišete podatke posameznika, ko so bili že uporabljeni za učenje obsežnega, kompleksnega modela? Pogosto tehnično ni izvedljivo, da bi model »odučili« posameznih podatkovnih točk.
Tu postanejo vaše začetne odločitve pri zasnovi najboljša obramba. Popolnega odgovora ni, vendar praktične in zagovorljive strategije vključujejo:
- Najprej psevdonimizacija: Če so bili podatki za učenje pravilno psevdonimizirani, je povezava s posameznikom v učnem korpusu že prekinjena. Nato lahko izbrišete osebne podatke iz izvornih sistemov in povezavo v tabeli ključev za psevdonimizacijo.
- Ločevanje podatkov za učenje: Kjer je mogoče, ohranite učne podatkovne nize po najemnikih ločene. To omogoča odstranitev podatkov brez ponovnega učenja celotnega nabora modelov.
- Načrtovano ponovno učenje modela: Vaša DPIA mora to tveganje obravnavati. Ukrep za zmanjševanje tveganja je lahko zaveza k periodičnemu ponovnemu učenju modela od začetka z osveženim podatkovnim nizom, iz katerega so izključeni podatki uporabnikov, ki so zahtevali izbris.
Razdelek Zenith Blueprint o brisanju informacij (korak 20, ki zajema kontrolo 8.10) to tehnično zmožnost izrecno povezuje z GDPR Articles 17 in 5(1)(e) ter zahteva preverljive postopke za varni izbris podatkov, ko ti niso več potrebni.
Varovanje dobavne verige umetne inteligence: zunanji razvoj in LLM tretjih oseb
Le malo podjetij SaaS vse razvija interno. Morda uporabljate API za LLM hiperskalnega ponudnika ali sklenete pogodbo z zunanjim razvojnim partnerjem. To uvaja tveganja dobavne verige.
Zenith Blueprint v koraku 22 o zunanjem razvoju poudarja to tveganje in njegovo povezavo z GDPR Articles 28 in 32. Kot navaja načrt:
»Pogosto spregledano področje je usposabljanje in ozaveščanje. Vaši zunanji razvijalci so lahko usposobljeni, toda ali so usposobljeni za prakse varnega razvoja kode? Ali poznajo vaše politike? Ali se zavedajo okvirov skladnosti, ki jih morate upoštevati, GDPR, DORA, NIS2 …?«
Za vsakega zunanjega ponudnika LLM ali razvojnega partnerja je skrbni pregled ključen. Vaš dodatek k pogodbi o obdelavi podatkov (DPA) mora izrecno zajemati namene obdelave, povezane z umetno inteligenco, kategorije podatkov in prepovedi, da bi ponudnik vaše podatke uporabljal za učenje svojih modelov. Preveriti morate, da izvaja varnostne ukrepe, usklajene z GDPR Article 32. Vaša dobavna veriga umetne inteligence mora biti enako preverljiva kot vaša ključna infrastruktura.
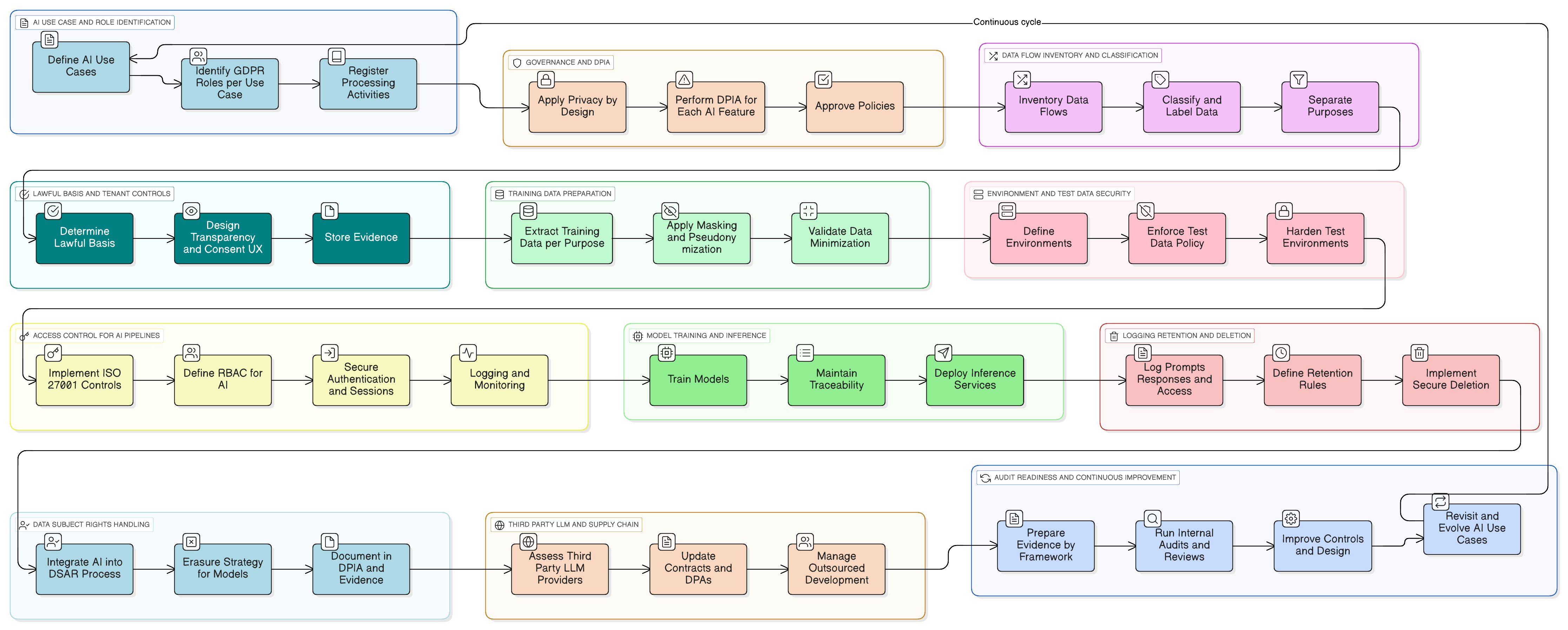
Od teorije k praksi: konkreten primer funkcionalnosti umetne inteligence, pripravljene na GDPR
Naj bo to konkretno. Predstavljajte si, da dodajate pomočnika z umetno inteligenco, ki povzema pogovore s podporo strankam, predlaga osnutke odgovorov in se uči iz preteklih zahtevkov za izboljšanje.
To je praktičen vzorec izvedbe z uporabo nabora orodij Clarysec:
- Razvrščanje in označevanje: Vsi zahtevki podpore so razvrščeni kot »Zaupno« v skladu z vašo Politiko klasifikacije in označevanja podatkov za MSP, usklajeno z obveznostmi glede ravnanja s podatki po GDPR in DORA.
- Maskiranje pred LLM: Storitev maskiranja prestreže podatke, preden se pošljejo v LLM. Odstrani ali nadomesti imena, e-poštne naslove, telefonske številke in druge PII. Celoten proces ureja Politika maskiranja podatkov in psevdonimizacije, pri čemer DPO potrdi metodologijo.
- Nadzor dostopa do pozivov in dnevnikov: Do surovih dnevnikov pozivov lahko dostopajo samo pooblaščene vloge (npr. lastnik produkta za umetno inteligenco). To se izvaja s kontrolo ISO 27001:2022 8.3 (omejitev dostopa do informacij) za splošni dostop in kontrolo 8.2 (pravice privilegiranega dostopa) za vsak vpogled na administratorski ravni, kot je preslikano v Zenith Controls.
- Privolitev za učni podatkovni korpus: Učni cevovod zajema samo maskirane podatke. Na ravni najemnika je na voljo konfiguracijska nastavitev »Dovolim uporabo svojih maskiranih podatkov za izboljšanje globalnega modela umetne inteligence: Da/Ne«, privzeto nastavljena na »Ne«.
- Hramba in izbris: Dnevniki pozivov se hranijo samo toliko časa, kot je potrebno. Ko najemnik onemogoči funkcionalnost ali prekine pogodbo, se sproži delovni tok za varni izbris ali anonimizacijo povezanih dnevnikov umetne inteligence in učnih zapisov, skladno s procesom, opisanim v vaši izvedbi Zenith Blueprint za kontrolo 8.10 (brisanje informacij).
Ko pridejo revizorji, jih lahko vodite skozi diagrame tokov podatkov funkcionalnosti, specifične politike, ki jo urejajo, in tehnična dokazila iz vaših sistemov, dnevnikov dostopa, konfiguracij opravil in delovnih tokov izbrisa. Dokazujete skladnost v praksi.
Vaš akcijski načrt: od ad hoc pristopa do umetne inteligence, pripravljene na revizijo
Produkta vam ni treba razstaviti, potrebujete pa strukturiran in zagovorljiv pristop. Tukaj je kratek akcijski načrt:
- Popišite primere uporabe umetne inteligence in tokove podatkov: Identificirajte vsako mesto, kjer se uporabljajo LLM: funkcionalnosti za stranke, interna orodja in eksperimenti. Preslikajte, kateri podatki gredo kam, na kateri pravni podlagi in kdo ima dostop. Uporabite temeljno fazo Zenith Blueprint, da zagotovite, da vaša pravna evidenca zajema vse zahteve GDPR, NIS2 in DORA, povezane z umetno inteligenco.
- Najprej vzpostavite upravljanje: Pred gradnjo za vsako funkcionalnost umetne inteligence izvedite oceno učinka v zvezi z varstvom podatkov (DPIA). Dokumentirajte njen namen, pravno podlago in tveganja. Uvedite temeljne politike, kot sta Politika varstva podatkov in zasebnosti za MSP ter Politika informacijske varnosti za MSP.
- Zaklenite podatke in dostop: Uvedite robustne tehnične kontrole. Sprejmite Politiko maskiranja podatkov in psevdonimizacije ter Politiko testnih podatkov in testnega okolja za MSP. Uporabite Zenith Controls za uvedbo in dokumentiranje kontrol ISO 27001:2022 8.2 in 8.3 za vse shrambe podatkov umetne inteligence in cevovode.
- Vgradite pravice posameznikov, na katere se nanašajo osebni podatki, v delovne tokove umetne inteligence: Posodobite postopke za zahteve posameznikov za uveljavljanje pravic (DSAR) in izbris, da vključujejo podatke, povezane z umetno inteligenco. Dokumentirajte strategijo obravnave zahtev za izbris v kontekstu naučenih modelov, s poudarkom na psevdonimizaciji in razporedih ponovnega učenja modelov.
- Dobavno verigo umetne inteligence postavite pod nadzor: Posodobite DPA z zunanjimi ponudniki LLM in zunanjimi razvijalci. Zagotovite, da pogodbe izrecno prepovedujejo nepooblaščeno uporabo podatkov in zahtevajo močne varnostne ukrepe. Preverite, da so zunanje ekipe usposobljene za vaše politike ravnanja s podatki.
Sproščanje inovacij z zaupanjem
Presečišče umetne inteligence in GDPR je nova meja skladnosti. S strukturiranim pristopom na podlagi tveganj lahko izkoristite preobrazbeno moč umetne inteligence, ne da bi ogrozili svojo zavezanost varstvu podatkov in zasebnosti.
Clarysec zagotavlja zemljevid, orodja in strokovno znanje, ki vas vodijo na tej poti. Z uporabo:
- Zenith Blueprint: 30-stopenjski revizijski časovni načrt za fazno uvedbo kontrol, usklajenih z GDPR za umetno inteligenco.
- Zenith Controls: vodnik za skladnost med okviri za poenotenje kontrol ISO 27001:2022 z zahtevami GDPR, NIS2, DORA in NIST.
- Produkcijsko pripravljenih politik, kot so Politika varstva podatkov in zasebnosti za MSP, Politika maskiranja podatkov in psevdonimizacije in Politika testnih podatkov in testnega okolja za MSP, za kodifikacijo vaših pravil in izpolnitev pričakovanj revizorjev.
Od ad hoc eksperimentov z umetno inteligenco lahko preidete na zmožnost umetne inteligence, pripravljeno na revizijo, ki vzbuja zaupanje regulatorjev, revizorjev in zahtevnih poslovnih strank. Z LLM lahko še naprej inovirate in obenem mirno spite.
Če načrtujete ali izvajate funkcionalnosti umetne inteligence v svojem produktu SaaS, je vaš naslednji korak jasen. Prenesite vzorce naših naborov orodij ali rezervirajte predstavitev, da vidite, kako vam Clarysec lahko pomaga zgraditi program umetne inteligence, ki ni le zmogljiv, temveč tudi dokazano zaseben in varen že po zasnovi.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council