Anatomin i ett intrång: en tillverkares vägledning till incidenthantering enligt ISO 27001
Utvalt utdrag
Effektiv incidenthantering inom informationssäkerhet minimerar skadorna från säkerhetsincidenter och säkerställer operativ resiliens. Denna vägledning ger ett steg-för-steg-ramverk baserat på ISO 27001 och hjälper tillverkande företag att förbereda sig för, hantera och återhämta sig från verkliga cyberattacker, samtidigt som komplexa efterlevnadskrav såsom NIS2 och DORA uppfylls.
Introduktion
Larmet blinkar klockan 02:17. Den centrala servern hos en medelstor tillverkare av fordonskomponenter svarar inte, och produktionslinjernas övervakningsskärmar visar ett ransomware-meddelande. Varje minuts driftstopp kostar tusentals kronor i förlorad produktion och riskerar att bryta mot strikta SLA:er i leveranskedjan. Detta är ingen övning. För informationssäkerhetschefen är detta ögonblicket då år av planering, policyarbete och utbildning sätts på sitt yttersta prov.
Att ha en incidenthanteringsplan på en server är en sak; att genomföra den under extrem press är något helt annat. För tillverkande företag är insatserna särskilt höga. En cyberincident komprometterar inte bara data; den stoppar produktionen, stör fysiska leveranskedjor och kan äventyra arbetstagarnas säkerhet.
Denna vägledning går bortom teoretiska åtgärdsplaner och ger en praktisk, verklighetsnära färdplan för att bygga och förvalta ett fungerande incidenthanteringsprogram. Vi går igenom anatomin i responsen på ett intrång, med utgångspunkt i det robusta ramverket ISO/IEC 27001, och visar hur du bygger ett resilient program som inte bara återhämtar sig från en attack utan även uppfyller revisorers och tillsynsmyndigheters krav.
Vad står på spel: ringeffekterna av ett intrång i tillverkningsmiljö
När en tillverkares system komprometteras sträcker sig konsekvenserna långt bortom en enskild server. Den sammanlänkade karaktären i modern produktion, från lagerhantering till robotiserade monteringslinjer, innebär att ett digitalt fel kan orsaka ett fullständigt operativt stopp. Konsekvenserna är allvarliga och mångfacetterade.
För det första uppstår de ekonomiska förlusterna omedelbart och med stor kraft. Produktionsstopp leder till missade tidsfrister, vitesklausuler från kunder och kostnader för outnyttjad personal. Återställning av system, ersättning till digitalforensiska experter och eventuell hantering av lösensummekrav kan slå hårt mot ekonomin i ett medelstort företag.
För det andra kan anseendeskadan bli långvarig. I en B2B-miljö är tillförlitlighet avgörande. En enda större incident kan rasera förtroendet hos nyckelpartner som är beroende av just-in-time-leveranser. Som vår interna vägledning framhåller är ett centralt mål med incidenthantering att “minimera incidenters verksamhetsmässiga och ekonomiska påverkan och återställa normal drift så snabbt som möjligt”, vilket är särskilt avgörande i tillverkningsindustrin.
Slutligen kan de regulatoriska konsekvenserna bli kännbara. Med ramverk som EU:s NIS2-direktiv och DORA-förordningen, som nu får fullt genomslag, omfattas organisationer i kritiska sektorer såsom tillverkning av strikta krav på incidentrapportering och riskerar betydande sanktionsavgifter vid bristande efterlevnad. En dåligt hanterad incident är inte bara ett tekniskt misslyckande; den innebär betydande rättslig risk och efterlevnadsrisk.
Hur god hantering ser ut: från kaos till kontroll
Ett effektivt incidenthanteringsprogram omvandlar en kris från ett kaotiskt, reaktivt agerande till en strukturerad och kontrollerad process. Målet är inte bara att åtgärda det tekniska problemet, utan att hantera hela händelsen så att verksamheten skyddas. Detta önskade läge bygger på principerna i ISO/IEC 27001-ramverket, särskilt kontrollerna för hantering av informationssäkerhetsincidenter.
Ett moget program kännetecknas av flera centrala resultat:
- Tydliga roller: Alla vet vem de ska kontakta och vilket ansvar de har. Incidenthanteringsteamet (IRT) är fördefinierat, med tydligt ledarskap och utsedda experter från IT, juridik, kommunikation och ledning.
- Hastighet och precision: Organisationen kan snabbt detektera, analysera och begränsa hot, vilket förhindrar att de sprids i nätverket och stoppar hela produktionsgolvet.
- Välgrundat beslutsfattande: Ledningen får aktuell och korrekt information, vilket gör det möjligt att fatta kritiska beslut om drift, kundkommunikation och regulatorisk rapportering.
- Ständig förbättring: Varje incident, stor som liten, blir en lärdom. En grundlig process för efterincidentgranskning identifierar säkerhetssvagheter och återför förbättringar till säkerhetsprogrammet.
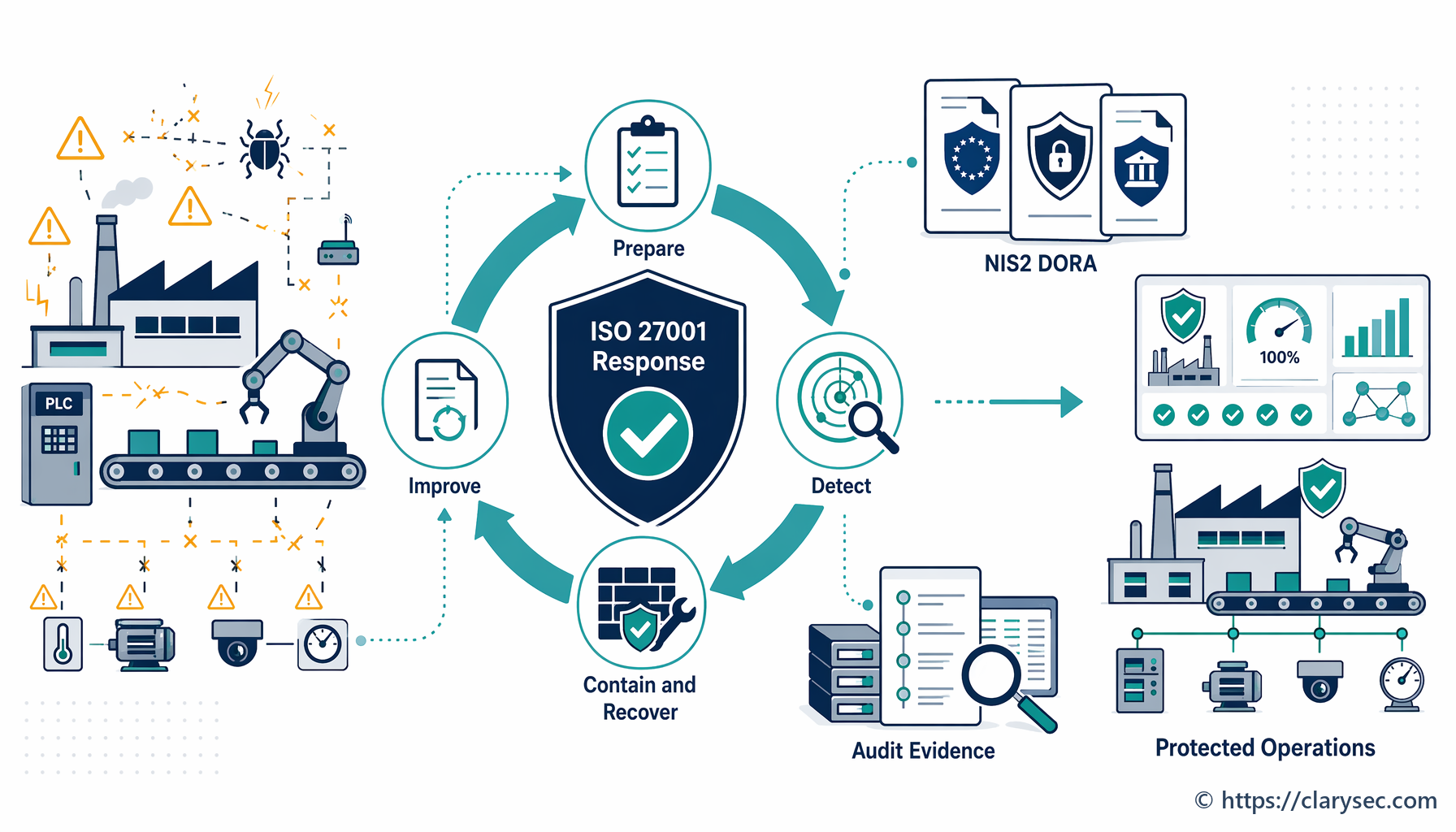
Att uppnå denna beredskap är kärnsyftet med kontrollerna i ISO/IEC 27002:2022. Dessa kontroller vägleder organisationer i planering och förberedelse (A.5.24), bedömning av och beslut om händelser (A.5.25), respons på incidenter (A.5.26) och lärande från dem (A.5.28). Det handlar om att bygga ett resilient system som förutser fel och är strukturerat för att hantera dem kontrollerat.
Den praktiska vägen: en steg-för-steg-vägledning för incidenthantering
Att bygga en robust incidenthanteringsförmåga kräver ett dokumenterat och systematiskt arbetssätt. Grunden är en tydlig och genomförbar policy som beskriver varje fas i processen.
Vår P16S Information Security Incident Management Planning and Preparation Policy - SME ger en heltäckande modell som är anpassad till bästa praxis för ISO 27001. Låt oss gå igenom de kritiska stegen med denna policy som vägledning.
Steg 1: planering och förberedelse – grunden för resiliens
En responsplan kan inte skapas mitt i en kris. Förberedelse är avgörande. Denna fas handlar om att etablera den struktur, de verktyg och den kunskap som krävs för att agera beslutsamt när en incident inträffar.
En central komponent är att etablera ett incidenthanteringsteam (IRT). Som anges i avsnitt 5.1 i P16S Information Security Incident Management Planning and Preparation Policy - SME är policyns syfte att “säkerställa ett konsekvent och effektivt arbetssätt för hantering av informationssäkerhetsincidenter”. Denna konsekvens börjar med ett väldefinierat team. Policyn kräver att IRT omfattar medlemmar från nyckelfunktioner:
- IT och informationssäkerhet
- Juridik och regelefterlevnad
- HR
- Kommunikation/PR
- Högsta ledningen
Varje medlem måste ha tydligt definierade roller och ansvar. Vem har befogenhet att ta system offline? Vem är utsedd talesperson för kommunikation med kunder eller media? Dessa frågor måste vara besvarade och dokumenterade långt innan en incident inträffar.
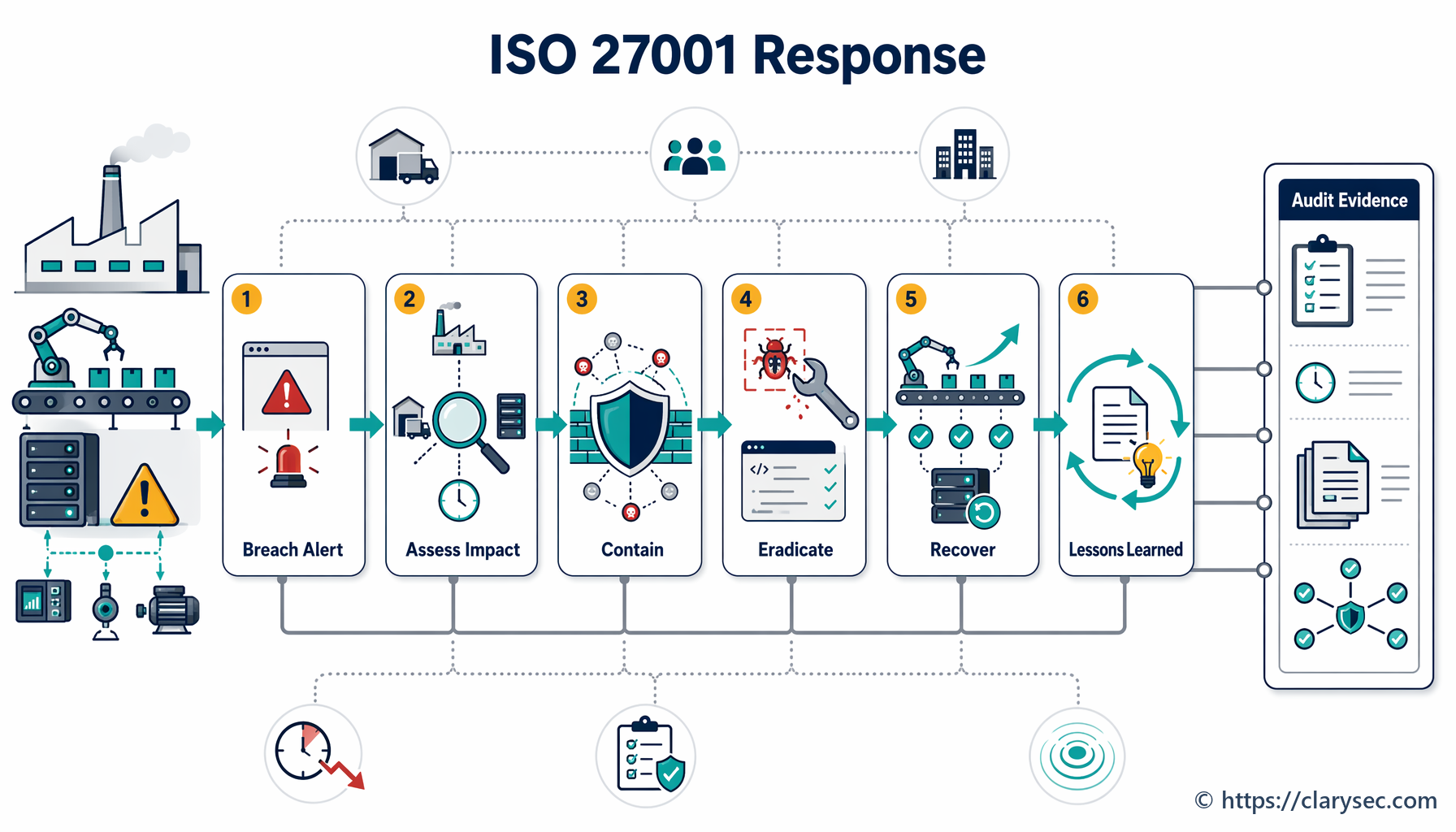
Steg 2: detektering och rapportering – ert system för tidig varning
Ju snabbare ni känner till en incident, desto mindre skada kan den orsaka. Detta kräver både teknisk övervakning och en kultur där anställda har mandat och skyldighet att rapportera misstänkt aktivitet.
P16S Information Security Incident Management Planning and Preparation Policy - SME är tydlig på denna punkt. Avsnitt 5.3, “Rapportering av informationssäkerhetshändelser”, anger:
“Alla anställda, uppdragstagare och andra relevanta parter ska rapportera observerade eller misstänkta informationssäkerhetshändelser och säkerhetssvagheter så snabbt som möjligt till utsedd kontaktpunkt.”
Denna “utsedda kontaktpunkt” är kritisk. Det kan vara IT-servicedesk eller en särskild säkerhetshotline. Processen måste vara enkel och tydligt kommunicerad till all personal. Anställda ska utbildas i vad de ska vara uppmärksamma på, till exempel nätfiskemeddelanden, ovanligt systembeteende eller överträdelser av fysisk säkerhet.
Steg 3: bedömning och triagering – värdera hotets omfattning
När en händelse har rapporterats är nästa steg att snabbt bedöma dess art och allvarlighetsgrad. Är det ett falskt larm, ett mindre problem eller en fullskalig kris? Denna triageringsprocess avgör vilken responsnivå som krävs.
Vår policy beskriver ett tydligt klassificeringsschema i avsnitt 5.2, “Incidentklassificering”, för att kategorisera incidenter utifrån deras påverkan på konfidentialitet, riktighet och tillgänglighet. Ett typiskt schema kan se ut så här:
- Låg: En enskild arbetsstation infekterad med vanligt förekommande skadlig kod, lätt att begränsa.
- Medel: En avdelningsserver är otillgänglig och påverkar en specifik verksamhetsfunktion, men stoppar inte den samlade produktionen.
- Hög: En omfattande ransomwareattack som påverkar kritiska produktionssystem och centrala verksamhetsdata.
- Kritisk: En incident som omfattar en personuppgiftsincident avseende känsliga personuppgifter eller immateriella rättigheter, med betydande rättsliga konsekvenser och anseendekonsekvenser.
Denna klassificering styr brådska, tilldelade resurser och eskaleringsväg till ledningen, och säkerställer att responsen står i proportion till hotet.
Steg 4: begränsning, eliminering och återställning – släcka branden
Detta är den aktiva responsfasen där IRT arbetar för att kontrollera incidenten och återställa normal drift.
- Begränsning: Den omedelbara prioriteringen är att stoppa skadan. Det kan innebära att isolera berörda nätverkssegment, koppla bort komprometterade servrar eller blockera skadliga IP-adresser. Målet är att förhindra att incidenten sprids och orsakar ytterligare skada.
- Eliminering: När incidenten är begränsad måste grundorsaken elimineras. Det kan innebära att ta bort skadlig kod, patcha utnyttjade sårbarheter och inaktivera komprometterade användarkonton.
- Återställning: Det sista steget är att återställa berörda system och data. Detta omfattar återställning från rena säkerhetskopior, återuppbyggnad av system och noggrann övervakning för att säkerställa att hotet är helt borttaget innan tjänster tas i drift igen.
Avsnitt 5.4 i P16S Information Security Incident Management Planning and Preparation Policy - SME, “Respons på informationssäkerhetsincidenter”, ger ramverket för dessa åtgärder och betonar att “responsrutiner ska initieras när en informationssäkerhetshändelse klassificeras som en incident”.
Steg 5: aktiviteter efter incidenten – ta tillvara lärdomarna
Arbetet är inte över när systemen är tillbaka i drift. Efterincidentfasen är sannolikt den viktigaste för att bygga långsiktig resiliens. Den omfattar två centrala aktiviteter: insamling av bevismaterial och en granskning för erfarenhetsåterföring.
Policyn betonar vikten av insamling av bevismaterial i avsnitt 5.5 och anger att “rutiner ska etableras och följas för insamling, inhämtning och bevarande av bevismaterial kopplat till informationssäkerhetsincidenter”. Detta är avgörande för intern utredning, brottsbekämpande myndigheter och eventuella rättsliga åtgärder.
Därefter ska en formell efterincidentgranskning genomföras. Mötet bör omfatta alla IRT-medlemmar och viktiga intressenter för att diskutera:
- Vad hände, och hur såg tidslinjen ut?
- Vad fungerade väl i responsen?
- Vilka utmaningar uppstod?
- Vad kan göras för att förhindra en liknande incident i framtiden?
Resultatet av granskningen bör vara en åtgärdsplan med tilldelade ägare och tidsfrister för att förbättra policyer, rutiner och tekniska kontroller. Detta skapar en återkopplingsloop som stärker organisationens säkerhetsläge över tid.
Koppla samman kraven: insikter om korsvis regelefterlevnad
Att uppfylla kraven i ISO 27001 för incidenthantering stärker inte bara säkerheten; det ger en stark grund för efterlevnad av ett växande nät av internationella och branschspecifika regelverk. Många av dessa ramverk bygger på samma kärnprinciper: förberedelse, respons och rapportering.
Som förklaras i Zenith Controls, vår heltäckande vägledning för korsvis regelefterlevnad, är en robust incidenthanteringsprocess en hörnsten i digital resiliens. Låt oss se hur arbetssättet enligt ISO 27001 överensstämmer med andra centrala ramverk.
Kontroller i ISO/IEC 27002:2022: Den senaste versionen av standarden ISO/IEC 27002 ger detaljerad vägledning om incidenthantering genom en särskild uppsättning kontroller:
- A.5.24 - Planering och förberedelse för hantering av informationssäkerhetsincidenter: Etablerar behovet av ett definierat och dokumenterat arbetssätt.
- A.5.25 - Bedömning av och beslut om informationssäkerhetshändelser: Säkerställer att händelser utvärderas korrekt för att avgöra om de är incidenter.
- A.5.26 - Respons på informationssäkerhetsincidenter: Omfattar aktiviteter för begränsning, eliminering och återställning.
- A.5.27 - Rapportering av informationssäkerhetsincidenter: Definierar hur och när incidenter rapporteras till ledning och andra intressenter.
- A.5.28 - Lärande från informationssäkerhetsincidenter: Kräver en process för ständig förbättring.
Dessa kontroller bildar en komplett livscykel som återspeglas i andra centrala regelverk.
NIS2-direktivet: För leverantörer av samhällsviktiga tjänster, inklusive många tillverkande företag, ställer NIS2 strikta krav på säkerhet och incidentrapportering. Zenith Controls noterar den direkta överlappningen:
“Article 21 i NIS2-direktivet kräver att väsentliga och viktiga entiteter genomför lämpliga och proportionella tekniska, operativa och organisatoriska åtgärder för att hantera risker som påverkar säkerheten i nätverks- och informationssystem. Detta omfattar uttryckligen policyer och rutiner för incidenthantering. Vidare etablerar Article 23 en incidentanmälningsprocess i flera steg, med krav på tidig varning inom 24 timmar och detaljerad rapport inom 72 timmar till behöriga myndigheter (CSIRT).”
En incidenthanteringsplan som är anpassad till ISO 27001 ger exakt de mekanismer som krävs för att uppfylla dessa snäva rapporteringsfrister.
Digital Operational Resilience Act (DORA): Även om DORA är inriktad på finanssektorn håller dess resiliensprinciper på att bli ett riktmärke för alla branscher. Vägledningen framhåller denna koppling:
“DORA:s Article 17 kräver att finansiella entiteter har en heltäckande process för hantering av IKT-relaterade incidenter för att detektera, hantera och anmäla IKT-relaterade incidenter. Article 19 kräver klassificering av incidenter baserat på kriterier som anges i förordningen samt rapportering av större incidenter till behöriga myndigheter med harmoniserade mallar. Detta speglar de krav på klassificering och rapportering som finns i ISO 27001.”
General Data Protection Regulation (GDPR): För varje incident som omfattar personuppgifter är GDPR:s krav avgörande. En snabb och strukturerad respons är inte valfri. Som Zenith Controls förklarar:
“Enligt GDPR kräver Article 33 att personuppgiftsansvariga anmäler en personuppgiftsincident till tillsynsmyndigheten utan onödigt dröjsmål och, där så är möjligt, senast 72 timmar efter att ha fått kännedom om den. Article 34 kräver att incidenten kommuniceras till den registrerade när den sannolikt leder till en hög risk för dennes rättigheter och friheter. En effektiv incidenthanteringsplan är avgörande för att samla in den information som krävs för att göra dessa anmälningar korrekt och i tid.”
Genom att bygga ert incidenthanteringsprogram på en ISO 27001-grund bygger ni samtidigt den förmåga som krävs för att hantera de komplexa kraven i dessa sammankopplade regelverk.
Förberedelse inför granskning: vad revisorer kommer att fråga
En incidenthanteringsplan som aldrig har testats eller granskats är bara ett dokument. Revisorer vet detta, och vid en certifieringsrevision enligt ISO 27001 kommer de att granska på djupet för att verifiera att programmet är en levande och fungerande del av ert ledningssystem för informationssäkerhet.
Enligt Zenith Blueprint, vår färdplan för revisorer, är utvärdering av incidenthantering ett kritiskt steg i revisionsprocessen. Under “Fas 3: fältarbete och inhämtning av bevismaterial” kommer revisorer systematiskt att testa er beredskap.
Här är vad ni kan förvänta er att de begär, baserat på steg 21 i Zenith Blueprint, “Utvärdera incidentrespons och verksamhetskontinuitet”:
“Visa mig er incidenthanteringsplan och policy.” Revisorer börjar med dokumentationen. De granskar policyns fullständighet och kontrollerar definierade roller och ansvar, klassificeringskriterier, kommunikationsplaner och rutiner för varje fas i incidentens livscykel. De verifierar att den har godkänts formellt och kommunicerats till relevant personal.
“Visa mig dokumentationen från era tre senaste säkerhetsincidenter.” Det är här planen möter verkligheten. Revisorer behöver se underlag som visar att planen faktiskt följs. De förväntar sig incidentloggar eller ärenden som dokumenterar:
- Datum och tidpunkt för detektering.
- En beskrivning av incidenten.
- Tilldelad prioritet eller klassificeringsnivå.
- En logg över vidtagna åtgärder för begränsning, eliminering och återställning.
- Datum och tidpunkt för lösning.
“Visa mig protokollet och åtgärdsplanen från er senaste efterincidentgranskning.” Som Zenith Blueprint betonar är ständig förbättring inte förhandlingsbar.
“Under revisionen kommer vi att söka objektivt underlag som visar att efterincidentgranskningar genomförs systematiskt. Detta omfattar granskning av mötesprotokoll, åtgärdsloggar och bevismaterial som visar att identifierade förbättringar har genomförts, såsom uppdaterade rutiner eller nya tekniska kontroller. Utan denna återkopplingsloop kan ledningssystemet för informationssäkerhet inte anses vara föremål för ‘ständig förbättring’ enligt standardens krav.”
“Visa mig underlag som visar att ni har testat er plan.” Revisorer vill se att ni proaktivt testar er förmåga och inte bara väntar på en verklig incident. Detta underlag kan anta många former, från skrivbordsövningar med ledningen till fullskaliga tekniska simuleringar. De vill se en rapport från testerna som beskriver scenario, deltagare, resultat och eventuella lärdomar.
Att vara förberedd med detta underlag visar att ert incidenthanteringsprogram inte bara är till för syns skull, utan är en robust, operativ och effektiv komponent i ert ledningssystem för informationssäkerhet.
Vanliga fallgropar att undvika
Även med en väldokumenterad plan snubblar många organisationer under en verklig incident. Här är några av de vanligaste fallgroparna att vara uppmärksam på:
- Syndromet “planen på hyllan”: Det vanligaste misslyckandet är att ha en välskriven plan som ingen har läst, förstått eller övat. Regelbunden utbildning och testning är det enda motmedlet.
- Otydliga befogenheter: Under en kris är otydlighet en fiende. Om IRT inte har förhandsgodkänd befogenhet att vidta avgörande åtgärder, såsom att ta ett kritiskt produktionssystem offline, förlamas responsen av obeslutsamhet medan skadan sprids.
- Bristfällig kommunikation: Att inte hantera kommunikation är ett recept på haveri. Detta omfattar att inte informera ledningen, att ge otydliga budskap till anställda eller att hantera kommunikation med kunder och tillsynsmyndigheter felaktigt. En förhandsgodkänd kommunikationsplan med mallar är nödvändig.
- Försummat bevarande av bevismaterial: I brådskan att återställa tjänsten kan det tekniska teamet oavsiktligt förstöra avgörande forensisk bevisning. Det kan göra det omöjligt att fastställa grundorsaken, förhindra upprepning eller stödja rättsliga åtgärder.
- Bristande lärande: Att betrakta en incident som “avslutad” så snart systemet är tillbaka i drift är en missad möjlighet. Utan en rigorös efterincidentanalys riskerar organisationen att upprepa sina misstag.
Nästa steg
Att gå från teori till praktik är det mest kritiska steget. Ett robust incidenthanteringsprogram är en resa av ständig förbättring, inte en slutpunkt. Så här kan ni börja:
- Formalisera arbetssättet: Om ni saknar en formell incidenthanteringspolicy är det dags att ta fram en. Använd vår P16S Information Security Incident Management Planning and Preparation Policy - SME som mall för att bygga ett heltäckande ramverk.
- Förstå ert efterlevnadslandskap: Kartlägg era incidenthanteringsrutiner mot de specifika kraven i regelverk som NIS2, DORA och GDPR. Vår vägledning, Zenith Controls, ger de korsreferenser som krävs för att säkerställa full täckning.
- Förbered er för revision: Använd revisorns perspektiv för att stresstesta programmet. Zenith Blueprint ger en inblick i vad revisorer kommer att kräva, så att ni kan samla ert underlag och vara redo att visa effektivitet.
Slutsats
För ett modernt tillverkande företag är incidenthantering inom informationssäkerhet inte en IT-fråga; det är en central funktion för verksamhetskontinuitet. Skillnaden mellan en mindre störning och ett katastrofalt haveri ligger i förberedelse, övning och ett åtagande att följa en strukturerad och repeterbar process.
Genom att förankra programmet i det globalt erkända ramverket ISO 27001 bygger ni inte bara en defensiv förmåga, utan en resilient organisation. Ni skapar ett system som kan stå emot chocken av ett intrång, hantera krisen med kontroll och precision och komma ur den starkare och säkrare. Tiden att förbereda sig är nu, innan larmet klockan 02:17 blir er verklighet.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council