Från kaos till kontroll: en vägledning för tillverkande företag om incidenthantering enligt ISO 27001
En effektiv incidenthanteringsplan är inte förhandlingsbar för tillverkande företag som möter cyberhot som kan stoppa produktionen. Denna vägledning ger en stegvis metod för att bygga upp en robust incidenthanteringsförmåga anpassad till ISO 27001, säkerställa operativ resiliens och uppfylla strikta, överlappande efterlevnadskrav från ramverk som NIS2 och DORA.
Inledning
Ljudet av maskiner på fabriksgolvet är ljudet av verksamhet. För ett medelstort tillverkande företag är det rytmen av intäkter, stabilitet i leveranskedjan och kundernas förtroende. Föreställ dig nu att ljudet ersätts av en oroande tystnad. Ett enskilt larm blinkar på en skärm i ett Security Operations Center (SOC): “Ovanlig nätverksaktivitet upptäckt – produktionsnätverkssegment.” Inom några minuter slutar styrsystemen att svara. Produktionslinjen stannar. Detta är inte ett hypotetiskt scenario; det är verkligheten vid en modern cyberincident i tillverkningsindustrin, där konvergensen mellan informationsteknik (IT) och operativ teknik (OT) har skapat ett nytt hotlandskap med mycket höga insatser.
En informationssäkerhetsincident är inte längre bara ett IT-problem; den är ett kritiskt verksamhetsavbrott som kan lamslå driften. För CISO:er och företagsledare inom tillverkning är frågan inte om en incident inträffar, utan hur organisationen ska agera när den gör det. En kaotisk ad hoc-reaktion leder till längre avbrott, regulatoriska böter och irreparabel anseendeskada. En strukturerad och väl inövad respons kan däremot omvandla en potentiell katastrof till en hanterad händelse och visa resiliens och kontroll. Detta är kärnprincipen i hantering av informationssäkerhetsincidenter, en kritisk del av varje robust ledningssystem för informationssäkerhet (LIS) baserat på ISO/IEC 27001.
Vad som står på spel
För ett tillverkande företag sträcker sig konsekvenserna av en säkerhetsincident långt bortom dataförlust. Den största risken är avbrott i verksamhetskritiska processer. När OT-system komprometteras blir konsekvenserna omedelbara och påtagliga: stoppade produktionslinjer, försenade leveranser och brutna åtaganden i leveranskedjan. De ekonomiska förlusterna börjar omedelbart, med kostnader som ackumuleras genom avbrottstid, avhjälpande åtgärder och möjliga avtalsviten.
Det regulatoriska landskapet ökar pressen ytterligare. En bristfälligt hanterad incident kan utlösa betydande böter enligt flera olika ramverk. Som Clarysecs heltäckande vägledning Zenith Controls framhåller är insatserna mycket höga:
“Det primära målet med incidenthantering är att minimera den negativa påverkan som säkerhetsincidenter har på verksamheten och att säkerställa en snabb, effektiv och ordnad respons. Underlåtenhet att hantera incidenter effektivt kan leda till betydande ekonomiska förluster, anseendeskada och regulatoriska sanktioner.”
Det handlar inte bara om en enskild reglering. Den sammanlänkade karaktären hos modern regelefterlevnad innebär att en enda incident kan få kaskadeffekter inom flera regelverk. En personuppgiftsincident som omfattar uppgifter om anställda eller kunder kan innebära en överträdelse av GDPR. Ett avbrott i tjänster till kunder i finanssektorn kan leda till granskning enligt DORA. För organisationer som klassificeras som väsentliga eller viktiga entiteter ställer NIS2 strikta krav på incidentrapportering och säkerhet.
Utöver de omedelbara ekonomiska och regulatoriska följderna uppstår en urholkning av förtroendet. Kunder, partner och leverantörer är beroende av tillverkarens förmåga att leverera. En incident som stör detta flöde skadar förtroendet och kan leda till förlorade affärer. Att återuppbygga detta anseende är ofta en längre och mer krävande process än att återställa de berörda systemen. Den slutliga kostnaden är därför inte bara summan av böter och förlorade produktionstimmar, utan den långsiktiga påverkan på företagets marknadsposition och varumärkesintegritet.
Hur god förmåga ser ut
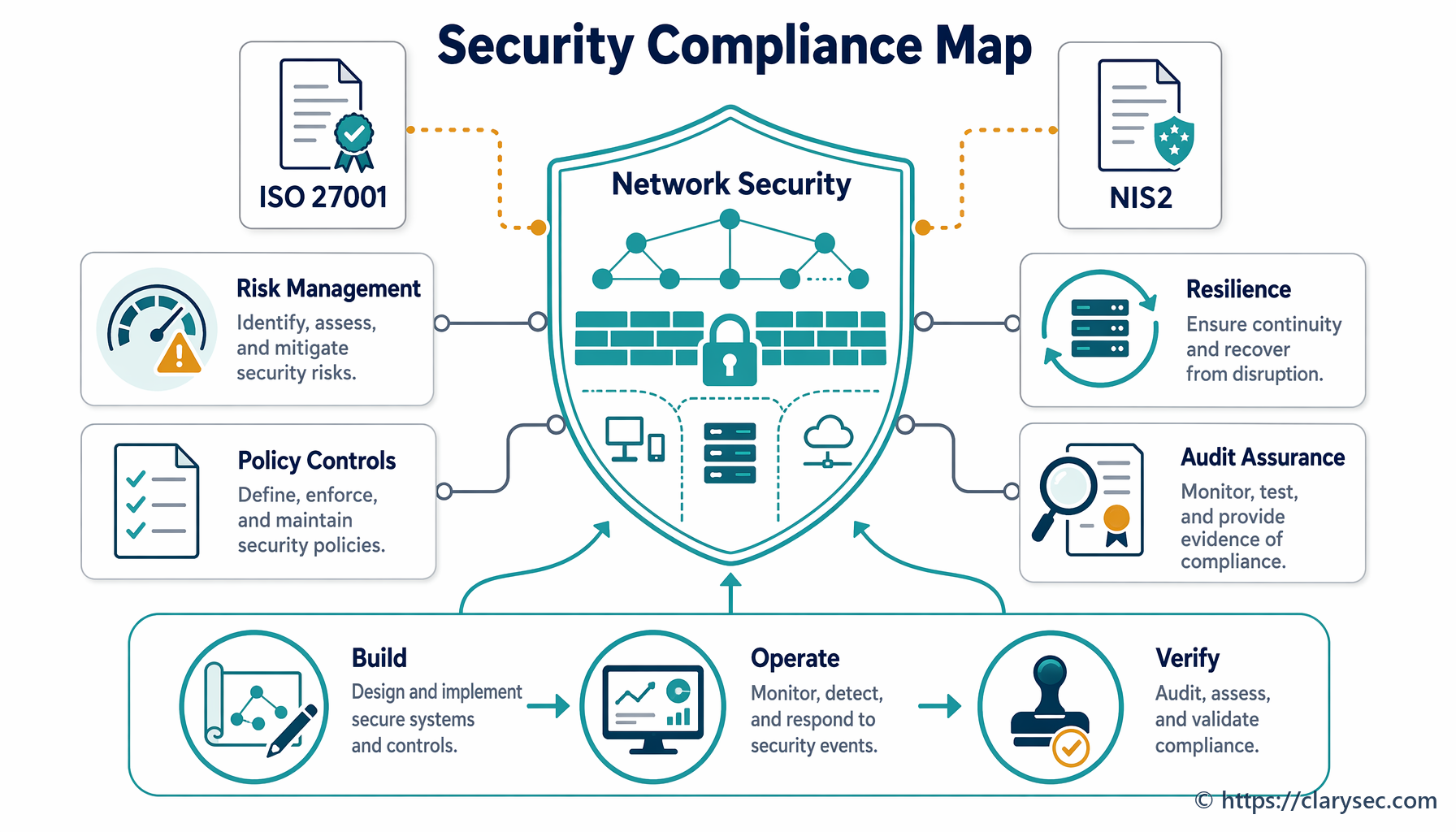
Mot bakgrund av dessa betydande risker: hur ser en effektiv incidenthanteringsförmåga ut? Det är ett läge av förberedd beredskap, där kaos ersätts av en tydlig och metodisk process. Det är förmågan att detektera, hantera och återhämta sig från en incident på ett sätt som minimerar skada och stödjer verksamhetskontinuitet. Detta önskade läge bygger på grunderna i ISO/IEC 27001, särskilt kontrollerna i bilaga A.
Ett moget incidenthanteringsprogram, styrt av en formell policy, säkerställer att alla känner till sin roll. Vår P16S policy för hantering av informationssäkerhetsincidenter – SME betonar denna tydlighet i sin syftesbeskrivning:
“Syftet med denna policy är att etablera ett strukturerat och effektivt ramverk för hantering av informationssäkerhetsincidenter. Ramverket säkerställer en snabb och samordnad respons på säkerhetshändelser, minimerar påverkan på organisationens verksamhet, tillgångar och anseende samt uppfyller rättsliga, lagstadgade, regulatoriska och avtalsmässiga krav.”
Detta strukturerade ramverk ger konkreta fördelar:
- Kortare avbrottstid: En väldefinierad plan möjliggör snabbare begränsning och återställning, så att produktionslinjer kan tas i drift igen tidigare.
- Kontrollerade kostnader: Genom att minimera incidentens varaktighet och påverkan minskar även kostnader för avhjälpande åtgärder, intäktsbortfall och möjliga böter väsentligt.
- Stärkt resiliens: Organisationen lär sig av varje incident genom att använda granskningar efter incidenter för att stärka skyddet och förbättra framtida respons. Detta ligger i linje med ISO 27001:s fokus på ständig förbättring.
- Påvisbar efterlevnad: En dokumenterad och testad incidenthanteringsprocess ger tydligt underlag till revisorer och tillsynsmyndigheter som visar att organisationen tar sina säkerhetsförpliktelser på allvar.
- Förtroende hos intressenter: En professionell och effektiv respons försäkrar kunder, partner och försäkringsgivare om att organisationen är en tillförlitlig och säker aktör att göra affärer med.
I praktiken innebär “bra” att organisationen inte bara är reaktiv utan proaktiv, och att incidenthantering behandlas som en central verksamhetsfunktion snarare än som en teknisk uppgift – en funktion som är avgörande för överlevnad och tillväxt i en digital värld.
Den praktiska vägen: stegvis vägledning
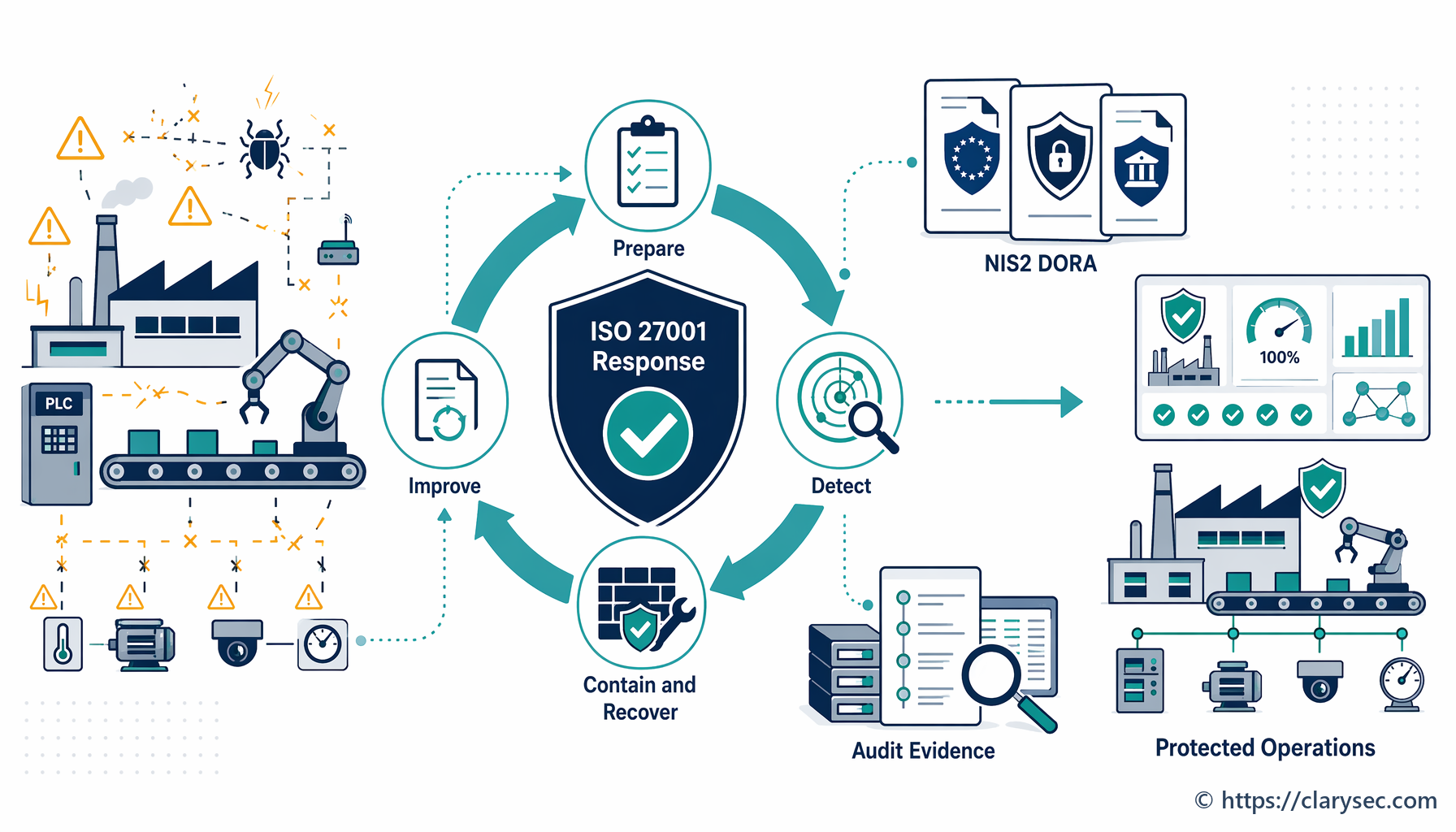
Att bygga en resilient incidenthanteringsförmåga kräver mer än ett dokument; det kräver en praktisk och genomförbar plan som är integrerad i organisationens kultur. Processen kan delas in i den klassiska livscykeln för incidenthantering, där varje fas stöds av tydliga policyer och rutiner.
Fas 1: Förberedelse och planering
Detta är den mest kritiska fasen. Effektiv respons är omöjlig utan grundlig förberedelse. Grunden är en heltäckande policy som fastställer förutsättningarna för alla efterföljande åtgärder. P16S policy för hantering av informationssäkerhetsincidenter – SME anger det väsentliga första steget i avsnitt 5.1, “Incidenthanteringsplan”:
“Organisationen ska utveckla, införa och underhålla en plan för hantering av informationssäkerhetsincidenter. Planen ska vara integrerad med planerna för verksamhetskontinuitet och katastrofåterställning för att säkerställa en samordnad respons på störande händelser.”
Planen är inte ett statiskt dokument. Den ska definiera hela processen, från initial detektering till slutlig lösning. En central komponent är att etablera en dedikerad incidenthanteringsgrupp (IRT). Gruppens roller och ansvar ska vara uttryckligen definierade för att undvika oklarheter under en kris. Policyn förtydligar detta ytterligare i avsnitt 5.2, “Incidenthanteringsgruppens (IRT) roller”, där det anges: “IRT ska bestå av medlemmar från relevanta avdelningar, inklusive IT, säkerhet, juridik, HR och kommunikation. Varje medlems roller och ansvar under en incident ska vara tydligt dokumenterade.”
Förberedelse innebär också att säkerställa att teamet har nödvändiga verktyg och resurser, inklusive säkra kommunikationskanaler, analysprogramvara och tillgång till forensisk kompetens.
Fas 2: Detektering och analys
En incident kan inte hanteras om den inte detekteras. Denna fas fokuserar på att identifiera och validera möjliga säkerhetsincidenter. Enligt vår P16S policy för hantering av informationssäkerhetsincidenter – SME kräver avsnitt 5.3, “Incidentdetektering och rapportering”, att “alla anställda, uppdragstagare och andra relevanta parter omedelbart ska rapportera observerade eller misstänkta informationssäkerhetsbrister eller hot.”
Detta kräver en kombination av teknisk övervakning och mänsklig medvetenhet. Automatiserade system som Security Information and Event Management (SIEM) är avgörande för att upptäcka avvikelser, men en välutbildad personalstyrka är den första försvarslinjen. Vår P08S policy för medvetenhet och utbildning inom informationssäkerhet – SME förstärker detta och anger i sitt policyuttalande: “Alla anställda och, där det är relevant, uppdragstagare ska få lämplig medvetenhetsutbildning och utbildning samt regelbundna uppdateringar om organisationens policyer och rutiner, i den mån detta är relevant för deras arbetsuppgifter.”
När en händelse har rapporterats ska IRT snabbt analysera och klassificera den för att fastställa allvarlighetsgrad och möjlig påverkan. Denna initiala triagering är avgörande för att prioritera responsinsatsen.
Fas 3: Begränsning, eliminering och återställning
Vid en bekräftad incident är det omedelbara målet att begränsa skadan. Strategin för begränsning är avgörande, särskilt i en tillverkningsmiljö. Det kan innebära att isolera det berörda nätverkssegment som styr produktionsutrustningen för att förhindra att skadlig kod sprids från IT-nätverket till OT-nätverket.
Efter begränsning arbetar IRT med att eliminera hotet. Det kan omfatta att ta bort skadlig kod, inaktivera komprometterade användarkonton och patcha sårbarheter. Det sista steget i denna fas är återställning, där systemen återförs till normal drift. Detta ska ske metodiskt, och organisationen ska säkerställa att hotet är helt borttaget innan systemen tas i drift igen. Som anges i avsnitt 5.5 i P16S policy för hantering av informationssäkerhetsincidenter – SME: “Återställningsaktiviteter ska prioriteras utifrån Business Impact Analysis (BIA) för att återställa kritiska verksamhetsfunktioner så snabbt som möjligt.”
Under hela denna fas är bevisinsamling avgörande. Korrekt hantering av digital bevisning är nödvändig för analys efter incidenten och för möjliga rättsliga eller regulatoriska åtgärder. Vår policy anger i avsnitt 5.6, “Bevisinsamling och hantering”, att “allt bevismaterial som rör en informationssäkerhetsincident ska samlas in, hanteras och bevaras på ett forensiskt korrekt sätt för att bibehålla dess integritet.”
Fas 4: Aktiviteter efter incidenten och ständig förbättring
Arbetet är inte avslutat när systemen åter är i drift. Fasen efter incidenten är den fas där det mest värdefulla lärandet sker. En formell granskning efter incidenten, eller ett möte för erfarenhetsåterföring, är nödvändigt. Syftet, enligt vår vägledning för genomförande, är att analysera incidenten och responsen för att identifiera förbättringsområden.
“Erfarenheterna från analys och lösning av informationssäkerhetsincidenter bör användas för att förbättra detektering, respons och förebyggande av framtida incidenter. Detta omfattar uppdatering av riskbedömningar, policyer, rutiner och tekniska kontroller.”
Denna återkopplingsslinga är motorn i ständig förbättring, en hörnsten i ISO 27001-ramverket. Iakttagelserna från granskningen bör användas för att uppdatera incidenthanteringsplanen, förfina säkerhetskontroller och stärka utbildningen av medarbetare. På så sätt blir organisationen starkare och mer resilient efter varje incident och omvandlar en negativ händelse till en positiv drivkraft för förändring.
Koppla ihop delarna: insikter om överlappande efterlevnad
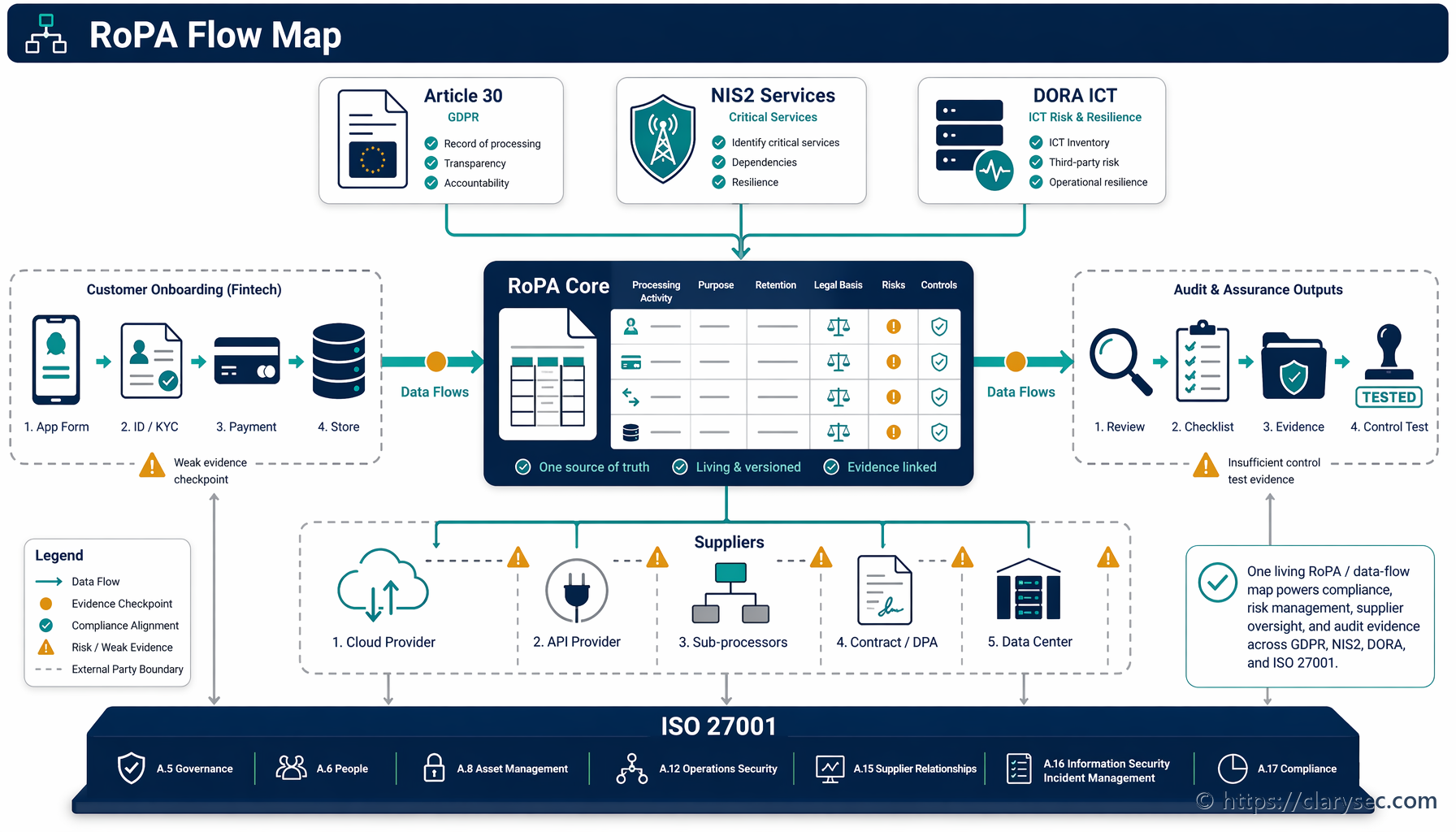
En effektiv incidenthanteringsplan uppfyller inte bara ISO 27001; den utgör ryggraden i efterlevnaden av ett växande antal överlappande regelverk. Moderna ramverk erkänner att en snabb och strukturerad respons är grundläggande för att skydda data, tjänster och kritisk infrastruktur. CISO:er och chefer för regelefterlevnad behöver förstå dessa samband för att bygga ett verkligt heltäckande program.
De centrala kontrollerna i ISO/IEC 27002:2022 för incidenthantering (5.24, 5.25, 5.26 och 5.27) ger en universell grund. Kontrollerna omfattar planering och förberedelse, bedömning och beslut om händelser, respons på incidenter och lärande från dem. Samma struktur återspeglas i andra större regelverk.
NIS2-direktivet: För tillverkare som bedöms vara väsentliga eller viktiga entiteter är NIS2 en betydande förändring. Direktivet kräver strikta säkerhetsåtgärder och incidentrapportering. Clarysec Zenith Controls lyfter fram denna direkta koppling:
“NIS2 kräver att organisationer har förmåga till incidenthantering, inklusive rutiner för att rapportera betydande incidenter till behöriga myndigheter inom strikta tidsramar, till exempel en tidig varning inom 24 timmar.”
Det innebär att en tillverkares responsplan anpassad till ISO 27001 måste omfatta de specifika notifieringsflöden och tidslinjer som NIS2 kräver.
DORA (Digital Operational Resilience Act): Även om DORA fokuserar på finanssektorn sträcker sig dess påverkan till kritiska IKT-tredjepartsleverantörer, vilket kan omfatta tillverkare som levererar teknik eller tjänster till finansiella entiteter. DORA lägger stor vikt vid hantering av IKT-relaterade incidenter. Som Clarysec Zenith Controls förklarar:
“DORA kräver en heltäckande process för hantering av IKT-relaterade incidenter. Detta omfattar klassificering av incidenter utifrån särskilda kriterier och rapportering av större incidenter till tillsynsmyndigheter. Fokus ligger på att säkerställa resiliens i digitala verksamheter i hela det finansiella ekosystemet.”
GDPR (General Data Protection Regulation): Varje incident som omfattar personuppgifter utlöser omedelbart skyldigheter enligt GDPR. En personuppgiftsincident ska rapporteras till tillsynsmyndigheten inom 72 timmar. En effektiv incidenthanteringsplan ska ha en tydlig process för att identifiera om personuppgifter berörs och för att utan dröjsmål initiera rapporteringsprocessen enligt GDPR.
NIST Cybersecurity Framework (CSF): NIST CSF är brett tillämpat, och dess fem funktioner (Identify, Protect, Detect, Respond, Recover) ligger väl i linje med livscykeln för incidenthantering. Funktionerna “Respond” och “Recover” är helt inriktade på incidenthanteringsaktiviteter, vilket gör en plan baserad på ISO 27001 till ett direkt stöd för införandet av NIST CSF.
COBIT 2019: Detta ramverk för IT-styrning och IT-ledning betonar också incidentrespons. Clarysec Zenith Controls beskriver överensstämmelsen:
“COBIT 2019:s domän ‘Deliver, Service and Support’ (DSS) omfattar processen DSS02, ‘Manage service requests and incidents.’ Processen säkerställer att incidenter löses i rätt tid och inte stör verksamheten, vilket direkt ligger i linje med målen för incidenthanteringskontrollerna i ISO 27001.”
Genom att bygga ett robust incidenthanteringsprogram baserat på ISO 27001 uppnår organisationer inte bara efterlevnad av en standard; de skapar en resilient operativ förmåga som uppfyller kärnkraven i flera överlappande regulatoriska ramverk.
Förberedelse inför granskning: vad revisorer kommer att fråga
En incidenthanteringsplan är bara så bra som dess genomförande och dokumentation. När en revisor kommer på plats söker denne konkreta underlag som visar att planen inte bara är ett dokument som ligger på hyllan, utan en levande del av organisationens säkerhetsläge. Revisorn vill se en mogen och repeterbar process.
Själva revisionsprocessen är strukturerad och metodisk. Enligt den heltäckande färdplanen i Zenith Blueprint kommer revisorer systematiskt att testa effektiviteten i era incidenthanteringskontroller. Under fas 2, “Fältarbete och insamling av revisionsbevis”, kommer revisorerna att avsätta särskilda steg för detta område.
Steg 15: Granska rutiner för incidenthantering: Revisorerna börjar med att begära den formella incidenthanteringsplanen och tillhörande rutiner. De granskar dokumenten noggrant avseende fullständighet och tydlighet. Som Zenith Blueprint anger för detta steg:
“Granska organisationens dokumenterade rutiner för hantering av informationssäkerhetsincidenter. Verifiera att rutinerna definierar roller, ansvar och kommunikationsplaner för hantering av incidenter.”
De kommer att fråga:
- Finns det en formellt dokumenterad incidenthanteringsplan?
- Finns en incidenthanteringsgrupp (IRT) definierad med tydliga roller och kontaktuppgifter?
- Finns tydliga rutiner för att rapportera, klassificera och eskalera incidenter?
- Omfattar planen kommunikationsrutiner för interna och externa intressenter?
Steg 16: Utvärdera testning av incidentrespons: En plan som aldrig har testats är sannolikt en plan som kommer att misslyckas. Revisorer kommer att kräva underlag som visar att planen fungerar i praktiken. Zenith Blueprint betonar detta:
“Verifiera att incidenthanteringsplanen testas regelbundet genom övningar såsom skrivbordssimuleringar eller fullskaliga övningar. Granska resultaten från dessa tester och kontrollera om erfarenheter har använts för att uppdatera planen.”
De kommer att begära:
- Dokumentation från skrivbordsövningar eller simuleringsövningar.
- Testrapporter som beskriver vad som fungerade väl och vad som behövde förbättras.
- Underlag som visar att incidenthanteringsplanen uppdaterades utifrån dessa iakttagelser.
Steg 17: Granska incidentloggar och rapporter: Slutligen vill revisorerna se planen i praktisk tillämpning genom att granska dokumentation från tidigare incidenter. Detta är det yttersta testet av programmets effektivitet. De granskar incidentloggar, IRT:s kommunikationsposter och rapporter från granskningar efter incidenter. Målet är att verifiera att organisationen följde sina egna rutiner under en verklig händelse.
De kommer att fråga:
- Kan ni tillhandahålla en logg över alla säkerhetsincidenter under de senaste 12 månaderna?
- För ett urval incidenter, kan ni visa hela dokumentationen från detektering till lösning?
- Finns det rapporter efter incidenter som analyserar grundorsaken och identifierar korrigerande åtgärder?
- Hanterades bevismaterial enligt den dokumenterade rutinen?
Att vara förberedd på dessa frågor med välordnad dokumentation och tydliga underlag är avgörande för en framgångsrik revision och visar en verklig kultur av säkerhetsresiliens.
Vanliga fallgropar
Även med en plan på plats misslyckas många organisationer under en faktisk incident. Att undvika dessa vanliga fallgropar är lika viktigt som att ha en bra plan.
- Avsaknad av en formell och testad plan: Det vanligaste misslyckandet är att inte ha någon plan alls, eller att ha en plan som aldrig har testats. En otestad plan är en samling antaganden som väntar på att motbevisas vid sämsta möjliga tidpunkt.
- Otydliga roller och ansvar: Under en kris är oklarhet fienden. Om teammedlemmar inte vet exakt vad de ska göra blir responsen långsam, kaotisk och ineffektiv.
- Bristande kommunikation: Att hålla intressenter i ovisshet skapar panik och misstro. En tydlig kommunikationsplan för anställda, kunder, tillsynsmyndigheter och även media är nödvändig för att styra kommunikationen och upprätthålla förtroendet.
- Otillräckligt bevarande av bevismaterial: I brådskan att återställa tjänster förstör team ofta avgörande forensisk bevisning. Detta försvårar inte bara utredningen efter incidenten utan kan också få allvarliga rättsliga konsekvenser och konsekvenser för regelefterlevnaden.
- Att glömma erfarenhetsåterföringen: Det enskilt största misstaget är att inte lära av en incident. Utan en grundlig granskning efter incidenten och ett åtagande att genomföra korrigerande åtgärder riskerar organisationen att upprepa tidigare misslyckanden.
- Att ignorera OT-miljön: För tillverkare är det ett kritiskt fel att behandla incidentrespons som en ren IT-fråga. Planen måste uttryckligen hantera de särskilda utmaningarna i OT-miljön, inklusive säkerhetskonsekvenser och andra återställningsprotokoll för industriella styrsystem.
Nästa steg
Att gå från en reaktiv hållning till proaktiv beredskap är en resa, men det är en resa som varje tillverkande organisation måste göra. Vägen framåt kräver ett åtagande att bygga en strukturerad, policystyrd incidenthanteringsförmåga.
Vi rekommenderar att börja med en stabil grund. Våra policymallar ger en heltäckande utgångspunkt för att definiera ert ramverk för incidenthantering.
- Etablera en tydlig och genomförbar plan med P16S policy för hantering av informationssäkerhetsincidenter – SME.
- Säkerställ att teamet är förberett genom att införa P08S policy för medvetenhet och utbildning inom informationssäkerhet – SME.
För en djupare förståelse av hur dessa kontroller passar in i ett bredare efterlevnadslandskap och hur ni förbereder er för rigorösa revisioner är våra expertvägledningar mycket värdefulla resurser.
- Mappa era kontroller mot flera ramverk med Zenith Controls.
- Förbered er för revisorns granskning med Zenith Blueprint.
Slutsats
För ett medelstort tillverkande företag är tystnaden från en stoppad produktionslinje det dyraste ljudet i världen. I dagens sammanlänkade miljö är hantering av informationssäkerhetsincidenter inte längre en teknisk funktion som delegeras till IT-avdelningen; den är en grundläggande pelare för operativ resiliens och verksamhetskontinuitet.
Genom att tillämpa den strukturerade metoden i ISO 27001 kan organisationer gå från kaotisk reaktion till kontrollerad och metodisk respons. En väldokumenterad och regelbundet testad incidenthanteringsplan, med stöd av en utbildad och medveten personalstyrka, är den yttersta skyddsåtgärden. Den minimerar avbrottstid, kontrollerar kostnader, säkerställer efterlevnad av ett komplext nät av regelverk som NIS2 och DORA och, viktigast av allt, bevarar kunders och partners förtroende. Investeringen i att bygga denna förmåga är inte en kostnad; den är en investering i verksamhetens framtida livskraft och resiliens.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council