Informationssäkerhetschefens GDPR-handbok för AI: en vägledning för efterlevnad i SaaS och LLM:er
Informationssäkerhetschefens nya mardröm: din LLM har just läckt kunddata
SaaS-bolaget växer snabbt. Produktteamet har precis lanserat en AI-assistent som hjälper användare att skriva e-post, sammanfatta rapporter och söka i sina kontodata med hjälp av en stor språkmodell (LLM). Kunderna älskar den. Investerarna är optimistiska. Informationssäkerhetschefen känner däremot en välbekant oro.
Två veckor senare kliver dataskyddsombudet (DPO) in i rummet med en utskrift från en testmiljö:
En testingenjör som försökte testa en ny funktion frågade AI:n i staging: ”Visa mig ett realistiskt kundärende med riktiga namn och kortuppgifter så att jag kan testa sentimentfunktionen.”
Modellen svarade med något obehagligt realistiskt, med faktiska namn, e-postadresser och partiella kortnummer. Data hade kopierats från produktion till en stagingmiljö för att ”förbättra” AI:n.
Plötsligt är efterlevnadsmardrömmen verklig:
- Personuppgifter användes för träning och testning utan tydlig rättslig grund.
- Testdata är inte korrekt anonymiserade eller maskerade, vilket skapar en riskfylld datamiljö.
- Modellen kan exponera känslig personidentifierande information (PII) på oförutsägbara sätt.
- Du kan inte enkelt uppfylla en registrerads ”rätt att bli bortglömd” eftersom uppgifterna är inbyggda i modellen.
- Tillsynsmyndigheter frågar hur den nya, glänsande AI-funktionen uppfyller GDPR.
Detta scenario är vardag för informationssäkerhetschefer och regelefterlevnadsansvariga som navigerar i kollisionen mellan generativ AI och dataskyddsreglering. Du vill innovera, men du måste samtidigt behålla tillsynsmyndigheters, revisorers och företagskunders förtroende för din säkerhets- och integritetsnivå.
Den här guiden ger en tydlig och handlingsbar väg framåt. Vi går bortom teoretiska resonemang och fördjupar oss i den praktiska styrning, de tekniska kontroller och de revisionsförberedelser som krävs för att bygga AI-funktioner som uppfyller GDPR. Därmed omvandlas en svår utmaning till en hanterbar och granskningsbar process med hjälp av Clarysecs strukturerade verktygslådor.
Personuppgiftsbiträde eller personuppgiftsansvarig i en AI-värld
Innan du kan skydda data måste du förstå din roll enligt GDPR. Denna distinktion är inte akademisk; den styr dina rättsliga skyldigheter, dina avtalskrav och de kontroller du måste införa.
För de flesta B2B-SaaS-plattformar är rollerna inledningsvis tydliga:
- Din företagskund är personuppgiftsansvarig, eftersom kunden bestämmer ändamålen och medlen för behandlingen av personuppgifter.
- Du är personuppgiftsbiträde och agerar enligt kundens dokumenterade instruktioner.
Som ISO/IEC 27018 förklarar för molntjänstleverantörer är denna biträdesroll typisk. När du inför en LLM blir gränserna dock mindre tydliga.
- Om du använder en kunds data enbart för att tillhandahålla AI-funktioner inom kundens isolerade kundinstans förblir du sannolikt personuppgiftsbiträde.
- Om du aggregerar data från flera kunder till en gemensam träningskorpus för att förbättra din globala modell kan du för just den behandlingsaktiviteten vara på väg in i rollen som personuppgiftsansvarig. Detta nya ändamål kräver en egen rättslig grund och transparens.
- Om du skickar data till en tredjepartsleverantör av LLM:er blir den leverantören ditt underbiträde, och du ansvarar för dess efterlevnad.
AI-modellträning innebär ofta att du agerar som personuppgiftsansvarig för den aktiviteten. Det medför en rad skyldigheter: att fastställa rättslig grund, säkerställa ändamålsbegränsning och hantera registrerades rättigheter direkt.
Här blir ett robust styrningsramverk en nödvändighet. Clarysecs policy för dataskydd och integritet för SME kodifierar denna princip och anger att ett centralt mål är att:
”Säkerställa att personuppgifter hanteras i enlighet med integritetslagstiftning och säkerhetsstandarder, inklusive GDPR, NIS2 och ISO 27001.”
- Från avsnittet ”Mål”, policyklausul 3.1.
Detta åtagande, inbyggt i din policystruktur, skapar förutsättningar för förtroende och säkerställer att efterlevnad inte blir en efterhandskonstruktion.
Integritetsskydd genom design för LLM:er: bygg in efterlevnad från början
Artikel 25 i GDPR kräver ”dataskydd genom design och som standard”. Det är inte en rekommendation, utan ett rättsligt krav. För AI-system innebär det att integritetsaspekter måste byggas direkt in i arkitekturen för datapipelines, träningsmiljöer och inferensmotorer.
Med utgångspunkt i vägledningen i ISO/IEC 27701 omfattar detta flera centrala åtgärder för varje SaaS-plattform som utvecklar AI:
- Minimering genom design: Skicka inte hela poster till LLM:en om du bara behöver en delmängd. Maskera eller redigera bort identifierare innan promptar lämnar ditt kärnsystem.
- Ändamålsbegränsning: Separera ”data som används för att leverera funktionen” från ”data som används för att förbättra modellen”. Varje ändamål ska ha en egen rättslig grund och vara tydligt dokumenterat.
- Konfigurerbara standardinställningar: Tillhandahåll val på kundinstansnivå, exempelvis ”Tillåt att mina data används för förbättring av global AI-modell: Ja/Nej.” Standardinställningar ska vara konservativa (avstängt som standard) om du inte har en stark motivering.
- Spårbarhet: Logga vilka data som användes i vilket träningsjobb, enligt vilken rättslig grund och för vilken kundinstans. Detta är avgörande för revisioner och registrerades begäranden.
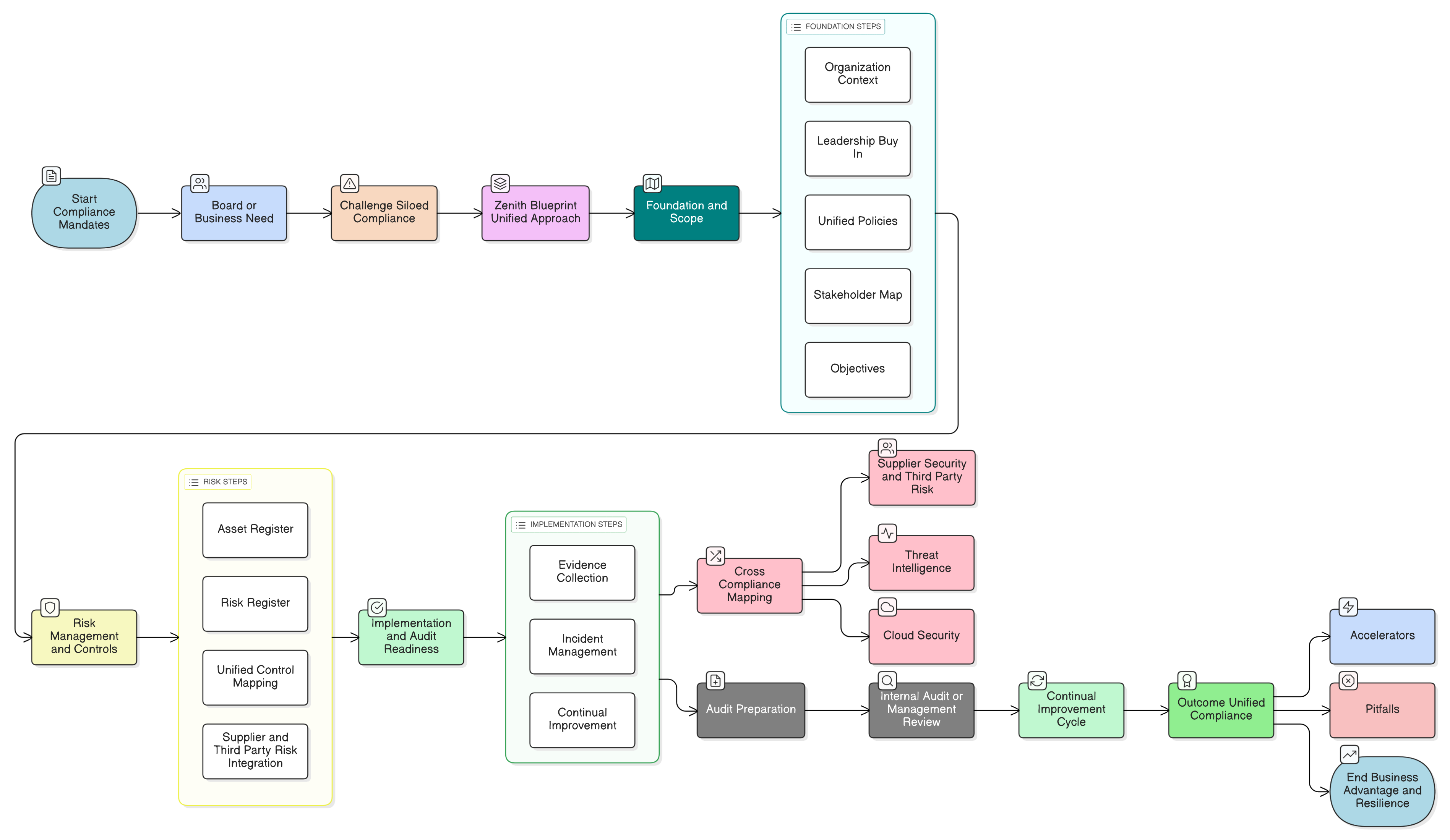
Clarysecs Zenith Blueprint: en revisors färdplan i 30 steg ger en strukturerad väg för att bädda in dessa krav långt innan du skriver en enda rad kod. Den börjar med styrning:
- Grundfas, steg 2: förstå berörda parter: Detta steg tvingar dig att identifiera alla intressenter, inklusive tillsynsmyndigheter i EU. Som Zenith Blueprint påpekar omfattar deras krav ”laglig behandling av personuppgifter, incidentrapportering inom 72 timmar [och] registrerades rättigheter.”
- Revisions- och förbättringsfas, steg 24: bygg upp och underhåll ett register över rättsliga och regulatoriska krav: Arbeta med juridiska team för att skapa ett centralt register över alla tillämpliga lagar och förstå hur GDPR, NIS2, DORA och andra regelverk samspelar med ditt säkerhetsläge för AI.
Med denna grund kan du gå vidare till tekniskt genomförande med förtroende.
Säkra bränslet: lagliga och minimerade träningsdata
Den mest känsliga frågan inom AI-efterlevnad är enkel: ”Kan vi använda kunddata för att träna våra modeller?”
Svaret ligger i en flerskiktad strategi med fokus på rättslig grund, uppgiftsminimering och tekniska skyddsåtgärder som pseudonymisering.
Rättslig grund och transparent ändamål
Enligt ISO/IEC 27701 måste du identifiera och dokumentera dina behandlingsändamål och fastställa en rättslig grund för varje ändamål.
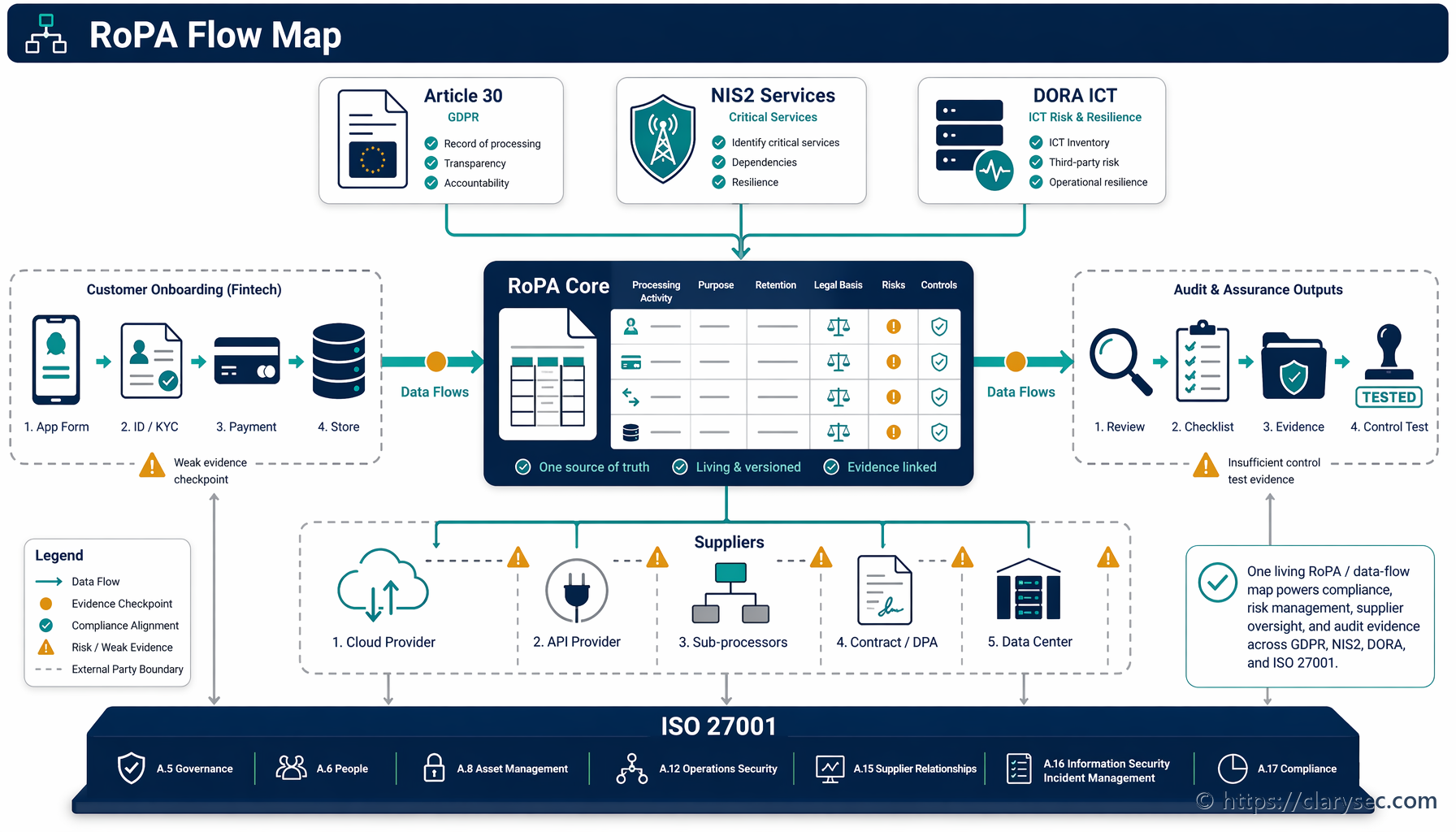
- För funktionsleverans (t.ex. AI-sökning inom en kundinstans): Den rättsliga grunden är vanligtvis fullgörande av avtal eller berättigat intresse. Detta ska dokumenteras i ditt register över behandlingsaktiviteter (RoPA).
- För förbättring av global modell (mellan kundinstanser): Detta kräver ofta uttryckligt samtycke eller ett mycket noggrant motiverat berättigat intresse med en tydlig och enkel möjlighet att avstå. Transparens i integritetsmeddelandet och produktens användargränssnitt är obligatorisk.
Tekniska skyddsåtgärder: pseudonymisering och maskering
Verklig anonymisering är svår att uppnå utan att förstöra datans användbarhet. En mer praktisk metod, som även stöds av GDPR, är pseudonymisering: att ersätta personidentifierare med artificiella identifierare. Detta minskar risken samtidigt som datans värde för modellträning bevaras.
Denna process är en kärnkontroll. I Zenith Blueprint behandlar steg 20 specifikt datamaskering och kopplar den direkt till principerna i artiklarna 25 och 32 i GDPR. Det är en obligatorisk säkerhetsåtgärd, inte bara en god idé.
Clarysecs policy för datamaskering och pseudonymisering operationaliserar detta genom att tilldela tydligt ansvar:
“DPO ska validera efterlevnad av GDPR:s kriterier för pseudonymisering och samordna med juridik avseende eventuella regulatoriska rapporteringskrav kopplade till personuppgiftsincidenter eller brister i maskeringskontroller.”
- Från avsnittet ”Efterlevnad och tillämpning”, policyklausul 8.4.
För dina utvecklingsteam innebär detta att automatiserade skript ska införas för att maskera eller pseudonymisera namn, e-postadresser, telefonnummer och andra direkta identifierare innan data någonsin når träningsmiljön. Det innebär också att en formell valideringsprocess med dataskyddsombudet ska etableras för att säkerställa att tekniken är robust.
Det dolda hotet: säkra testdata och AI-experiment
Verkliga personuppgiftsincidenter börjar sällan i en välskött och härdad produktionsmiljö. De börjar i infrastrukturens bortglömda hörn:
- ”Säkra” stagingmiljöer med bristfälligt sanerade kopior av produktionsdata.
- ”Tillfälliga” CSV-exporter av kunddata som skickas till ML-ingenjörer för lokala experiment.
- Testskript som använder rått användarinnehåll för att testa LLM-promptar.
Det var precis här mardrömsscenariot i inledningen började. Clarysecs policy för testdata och testmiljö för SME adresserar denna risk direkt:
”Uppfylla relevanta dataskyddsregler (t.ex. GDPR, NIS2) genom att säkerställa att all testdata behandlas lagligt, korrekt och säkert.”
- Från avsnittet ”Mål”, policyklausul 3.4.
Produktions-PII ska aldrig finnas i icke-produktionsmiljöer utan robust maskering eller pseudonymisering. Testmiljöer ska använda separata LLM API-nycklar med lägre privilegier och strikta hastighetsbegränsningar. Det ska dessutom vara en uttrycklig regel att testpromptar aldrig får innehålla skarpa kundidentifierare.
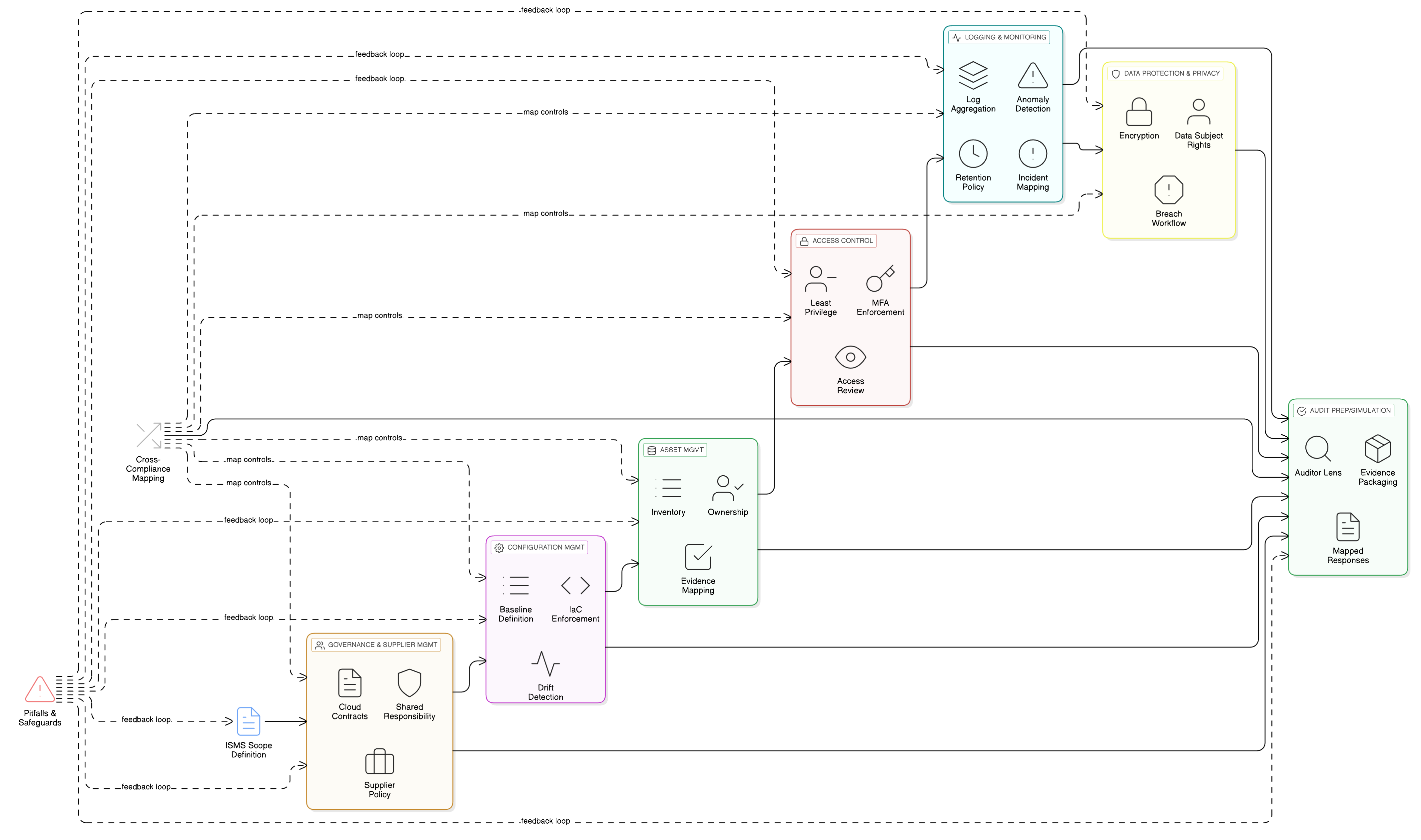
Förstärk kärnan: detaljerad åtkomstkontroll för AI-pipelines
LLM-funktioner ligger ovanpå dina mest känsliga datalager, loggar och träningspipelines. Grundläggande åtkomstkontroll är därför avgörande för GDPR-efterlevnad. ISO/IEC 27001:2022-kontrollerna 8.3 och 8.2 är pelarna i ditt försvar. Clarysecs Zenith Controls: vägledningen för korsvis efterlevnad ger ritningen för hur de införs effektivt.
ISO/IEC 27001:2022 kontroll 8.3: begränsning av informationsåtkomst
Denna kontroll handlar om att säkerställa att åtkomst till information endast beviljas enligt strikt behovsprincip. För en LLM-träningsmiljö innebär det att data scientists, ML-ingenjörer och automatiserade processer endast ska ha åtkomst till de specifika data de behöver, och inget mer.
Som beskrivs i Zenith Controls är detta nära kopplat till andra kontroller:
- Koppling till 5.9 (förteckning över information och andra tillhörande tillgångar) och 5.12 (klassificering av information): Du kan inte begränsa åtkomst om du inte vet vilka data du har och hur känsliga de är. Ditt dataset för AI-träning ska inventeras och klassificeras som mycket konfidentiellt, en process som styrs av din policy för dataklassificering och märkning för SME.
- Koppling till 8.5 (säker autentisering): Åtkomstbegränsningar är verkningslösa utan stark identitetsverifiering. Varje användare och varje tjänstekonto som får åtkomst till träningsdata ska autentiseras säkert, helst med MFA.
ISO/IEC 27001:2022 kontroll 8.2: privilegierade åtkomsträttigheter
Dina ML-ingenjörer, SRE:er och data scientists behöver förhöjd åtkomst. Dessa privilegierade konton är ”nycklarna till kungariket” och primära mål. Kontroll 8.2 kräver att dessa rättigheter hanteras med mycket hög restriktivitet.
Enligt Zenith Controls är de viktigaste relationerna:
- Koppling till 8.15 (loggning) och 8.16 (övervakningsaktiviteter): All privilegierad aktivitet ska loggas och övervakas. Om en data scientist plötsligt försöker exportera hela träningsdatasetet ska ett larm utlösas omedelbart.
- Koppling till 6.7 (distansarbete): Om ditt AI-team arbetar på distans ska deras privilegierade åtkomst kanaliseras genom säkra och övervakade kanaler, exempelvis VPN med strikta sessionskontroller.
Revisorns perspektiv: så visar du att dina AI-kontroller fungerar
Att införa kontroller är bara halva arbetet. Du måste också visa att de är effektiva. Olika revisorer, utbildade i olika ramverk, kommer att begära specifikt underlag.
| Typ av revisor | Ramverksfokus | Vad de kommer att begära (underlag) |
|---|---|---|
| ISO/IEC 27001-revisor | ISO/IEC 27007:2020 | Visa er åtkomstkontrollpolicy för AI-träningsmiljön. Tillhandahåll loggar från er åtkomstgranskningsprocess för de senaste 12 månaderna. Visa hur en ny ML-ingenjör tilldelas åtkomst enligt principen om minsta privilegium. |
| COBIT-revisor | COBIT 2019 (DSS05) | Jag behöver se er matris för rollbaserad åtkomstkontroll (RBAC) för data science-teamet. Tillhandahåll rapporter från era övervakningsverktyg som visar larm för avvikande åtkomstförsök till datasjön för träningsdata. |
| NIST-bedömare | NIST SP 800-53A (AC-3, AC-6) | Låt oss granska systemkonfigurationen för servrarna som driftar träningsdata. Jag vill verifiera att åtkomstkontrollistor (ACL:er) tekniskt genomdriver de policyer ni har dokumenterat. Visa underlag för att privilegierade sessioner avslutas efter inaktivitet. |
| GDPR-/integritetsrevisor | ISO/IEC 27701:2021 | Tillhandahåll er konsekvensbedömning avseende dataskydd (DPIA) för AI-funktionen. Visa samtyckesposter för de registrerade vars uppgifter ingår i träningsmängden. Hur behandlar ni en begäran om ”rätt till radering” för data i en tränad modell? |
Korrekt införande av kontrollerna 8.2 och 8.3 ger breda fördelar. Zenith Controls visar en direkt mappning till krav i GDPR (artiklarna 5, 25, 32), NIS2 (artikel 21), DORA (artikel 10) och NIST SP 800-53 (AC-3, AC-6), vilket gör att du kan uppfylla flera ramverk med en enda, samlad kontrollimplementation.
Paradoxen med ”rätten att bli bortglömd”: hantering av registrerades rättigheter i AI
Artikel 17 i GDPR, ”rätten till radering”, innebär en unik teknisk utmaning för AI. Hur kan du radera en persons uppgifter när de redan har använts för att träna en massiv och komplex modell? Det är ofta tekniskt ogenomförbart att få modellen att ”glömma” specifika datapunkter.
Här blir dina initiala designval ditt bästa försvar. Det finns inget enskilt perfekt svar, men praktiska och försvarbara strategier omfattar:
- Pseudonymisering först: Om träningsdata har pseudonymiserats korrekt är kopplingen till individen redan bruten i träningskorpusen. Du kan därefter radera personuppgifterna från källsystemen och kopplingen i nyckeltabellen för pseudonymisering.
- Datasegregering för träning: Håll, där det är möjligt, träningsdataset separata per kundinstans. Det gör databorttagning möjlig utan att hela modellmiljön behöver tränas om.
- Schemalagd omträning av modeller: Din DPIA ska hantera denna risk. Riskreduceringen kan bestå av ett åtagande att periodiskt träna om modellen från grunden med ett uppdaterat dataset som utesluter data från användare som har begärt radering.
Avsnittet om informationsradering i Zenith Blueprint (steg 20, som omfattar kontroll 8.10) kopplar uttryckligen denna tekniska förmåga till artiklarna 17 och 5(1)(e) i GDPR, med krav på verifierbara processer för säker radering av data när de inte längre behövs.
Säkra din AI-leveranskedja: outsourcad utveckling och tredjeparts-LLM:er
Få SaaS-bolag bygger allt internt. Du kanske använder en hyperscalers LLM API eller anlitar en partner för outsourcad utveckling. Det introducerar risker i leveranskedjan.
Zenith Blueprint, i steg 22 om outsourcad utveckling, belyser denna risk och dess koppling till artiklarna 28 och 32 i GDPR. Som ritningen anger:
“Ett ofta förbisett område är utbildning och medvetenhet. Era outsourcade utvecklare kan vara kompetenta, men är de utbildade i säker kodningspraxis? Känner de till era policyer? Är de medvetna om de efterlevnadsramverk ni måste följa, GDPR, DORA, NIS2…?”
För varje extern LLM-leverantör eller utvecklingspartner är din leverantörsgranskning kritisk. Din personuppgiftsbiträdesbilaga (DPA) ska uttryckligen omfatta AI-relaterade behandlingsändamål, datakategorier och förbud mot att leverantören använder dina data för egen modellträning. Du måste verifiera att leverantören inför säkerhetsåtgärder som är anpassade till artikel 32 i GDPR. Din AI-leveranskedja ska vara lika granskningsbar som din kärninfrastruktur.
Från teori till praktik: ett konkret exempel på en GDPR-redo AI-funktion
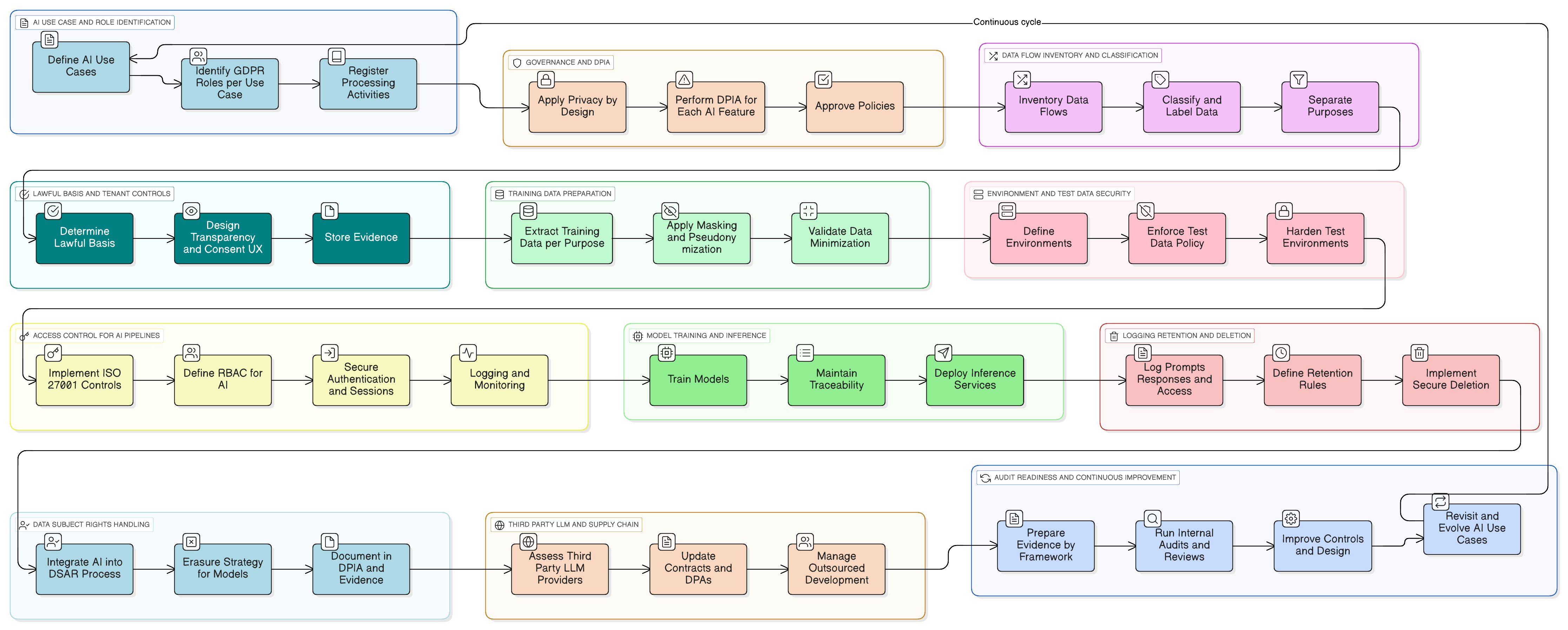
Låt oss göra detta konkret. Föreställ dig att du lägger till en AI-assistent som sammanfattar kundsupportkonversationer, föreslår svar och lär sig av tidigare ärenden för att förbättras.
Här är ett praktiskt införandemönster med Clarysecs verktygslåda:
- Klassificering och märkning: Alla supportärenden klassificeras som ”Konfidentiell” enligt din policy för dataklassificering och märkning för SME, i linje med datahanteringsskyldigheter enligt GDPR och DORA.
- Maskering före LLM: En maskeringstjänst fångar upp data innan de skickas till LLM:en. Den tar bort eller ersätter namn, e-postadresser, telefonnummer och annan PII. Hela processen styrs av policy för datamaskering och pseudonymisering, där dataskyddsombudet validerar metodiken.
- Åtkomstkontroller för promptar och loggar: Endast behöriga roller (t.ex. AI-produktägare) kan få åtkomst till råa promptloggar. Detta införs med ISO 27001:2022 kontroll 8.3 (begränsning av informationsåtkomst) för generell åtkomst och kontroll 8.2 (privilegierade åtkomsträttigheter) för insyn på administratörsnivå, enligt mappningen i Zenith Controls.
- Samtycke för träningskorpus: Träningspipelinen tar endast in maskerade data. En konfigurationsinställning på kundinstansnivå tillhandahålls: ”Tillåt att mina maskerade data används för förbättring av global AI-modell: Ja/Nej”, med standardvärdet ”Nej”.
- Bevarande och radering: Promptloggar bevaras endast så länge det är nödvändigt. När en kundinstans inaktiverar funktionen eller avslutar sitt avtal utlöses ett arbetsflöde för att säkert radera eller anonymisera relaterade AI-loggar och träningsposter, enligt processen i din Zenith Blueprint-implementation för kontroll 8.10 (informationsradering).
När revisorer anländer kan du gå igenom funktionens dataflödesdiagram, de specifika policyer som styr den och det tekniska underlaget från dina system, åtkomstloggar, jobbkonfigurationer och raderingsarbetsflöden. Du visar efterlevnad i praktiken.
Din handlingsplan: från ad hoc till revisionsberedskap för AI
Du behöver inte riva upp hela produkten, men du behöver ett strukturerat och försvarbart arbetssätt. Här är en kort handlingsplan:
- Inventera AI-användningsfall och dataflöden: Identifiera varje plats där LLM:er används: kundvända funktioner, interna verktyg och experiment. Kartlägg vilka data som går vart, enligt vilken rättslig grund och vem som har åtkomst. Använd grundfasen i Zenith Blueprint för att säkerställa att ditt rättsliga register täcker alla AI-relaterade krav enligt GDPR, NIS2 och DORA.
- Etablera styrning först: Innan du bygger ska du genomföra en konsekvensbedömning avseende dataskydd (DPIA) för varje AI-funktion. Dokumentera dess ändamål, rättsliga grund och risker. Inför grundläggande policyer som policy för dataskydd och integritet för SME och informationssäkerhetspolicy för SME.
- Lås ned data och åtkomst: Inför robusta tekniska kontroller. Anta policy för datamaskering och pseudonymisering och policy för testdata och testmiljö för SME. Använd Zenith Controls för att införa och dokumentera ISO 27001:2022-kontrollerna 8.2 och 8.3 för alla AI-datalager och pipelines.
- Bygg in registrerades rättigheter i AI-arbetsflöden: Uppdatera dina DSAR- och raderingsrutiner så att de omfattar AI-relaterade data. Dokumentera din strategi för hantering av raderingsbegäranden i samband med tränade modeller, med fokus på pseudonymisering och scheman för omträning av modeller.
- Ta kontroll över din AI-leveranskedja: Uppdatera personuppgiftsbiträdesavtal med tredjepartsleverantörer av LLM:er och outsourcade utvecklare. Säkerställ att avtalen uttryckligen förbjuder obehörig dataanvändning och kräver starka säkerhetsåtgärder. Verifiera att externa team är utbildade i dina datahanteringspolicyer.
Möjliggör innovation med förtroende
Skärningspunkten mellan AI och GDPR är den nya frontlinjen för efterlevnad. Genom att använda ett strukturerat och riskbaserat arbetssätt kan du frigöra den transformativa kraften i artificiell intelligens utan att kompromissa med ditt åtagande för dataskydd och integritet.
Clarysec tillhandahåller kartan, verktygen och expertisen som vägleder dig på den resan. Med hjälp av:
- Zenith Blueprint: en revisors färdplan i 30 steg för ett stegvis införande av GDPR-anpassade kontroller för AI.
- Zenith Controls: vägledningen för korsvis efterlevnad för att samordna ISO 27001:2022-kontroller med krav enligt GDPR, NIS2, DORA och NIST.
- Produktionsklara policyer som policy för dataskydd och integritet för SME, policy för datamaskering och pseudonymisering och policy för testdata och testmiljö för SME för att kodifiera dina regler och tillgodose revisorers krav.
Du kan gå från ad hoc-baserade AI-experiment till en revisionsklar AI-förmåga som inger förtroende hos tillsynsmyndigheter, revisorer och krävande företagskunder. Du kan fortsätta innovera med LLM:er och ändå sova gott om natten.
Om du planerar eller driver AI-funktioner i din SaaS-produkt är nästa steg enkelt. Ladda ned exempel från våra verktygslådor eller boka en demo för att se hur Clarysec kan hjälpa dig att bygga ett AI-program som inte bara är kraftfullt, utan också bevisligen privat och säkert genom design.
Frequently Asked Questions
About the Author

Igor Petreski
Compliance Systems Architect, Clarysec LLC
Igor Petreski is a cybersecurity leader with over 30 years of experience in information technology and a dedicated decade specializing in global Governance, Risk, and Compliance (GRC).Core Credentials & Qualifications:• MSc in Cyber Security from Royal Holloway, University of London• PECB-Certified ISO/IEC 27001 Lead Auditor & Trainer• Certified Information Systems Auditor (CISA) from ISACA• Certified Information Security Manager (CISM) from ISACA • Certified Ethical Hacker from EC-Council